







 本文介绍了链式前向星数据结构,它是图论中一种用数组模拟链表邻接表的方法,用于存储无向图和有向图。链式前向星在稀疏图上对于最短路问题有良好表现,但不支持直接通过起点和终点定位边。相比使用`vector<Edge>`的邻接表,链式前向星在空间效率和某些操作速度上有所牺牲,但在需要节省空间或处理大量边时更有优势。文章还讨论了无向图的存储,以及在BFS、DFS和最短路径算法中的应用。
本文介绍了链式前向星数据结构,它是图论中一种用数组模拟链表邻接表的方法,用于存储无向图和有向图。链式前向星在稀疏图上对于最短路问题有良好表现,但不支持直接通过起点和终点定位边。相比使用`vector<Edge>`的邻接表,链式前向星在空间效率和某些操作速度上有所牺牲,但在需要节省空间或处理大量边时更有优势。文章还讨论了无向图的存储,以及在BFS、DFS和最短路径算法中的应用。
链式前向星
通常用在点的数目太多,或两点之间有多条弧的时候。一般在别的数据结构不能使用的时候才考虑用前向星。除了不能直接用起点终点定位以外,前向星几乎是完美的。【引自百度百科】
链式前向星(本质是用数组模拟链表的邻接表)
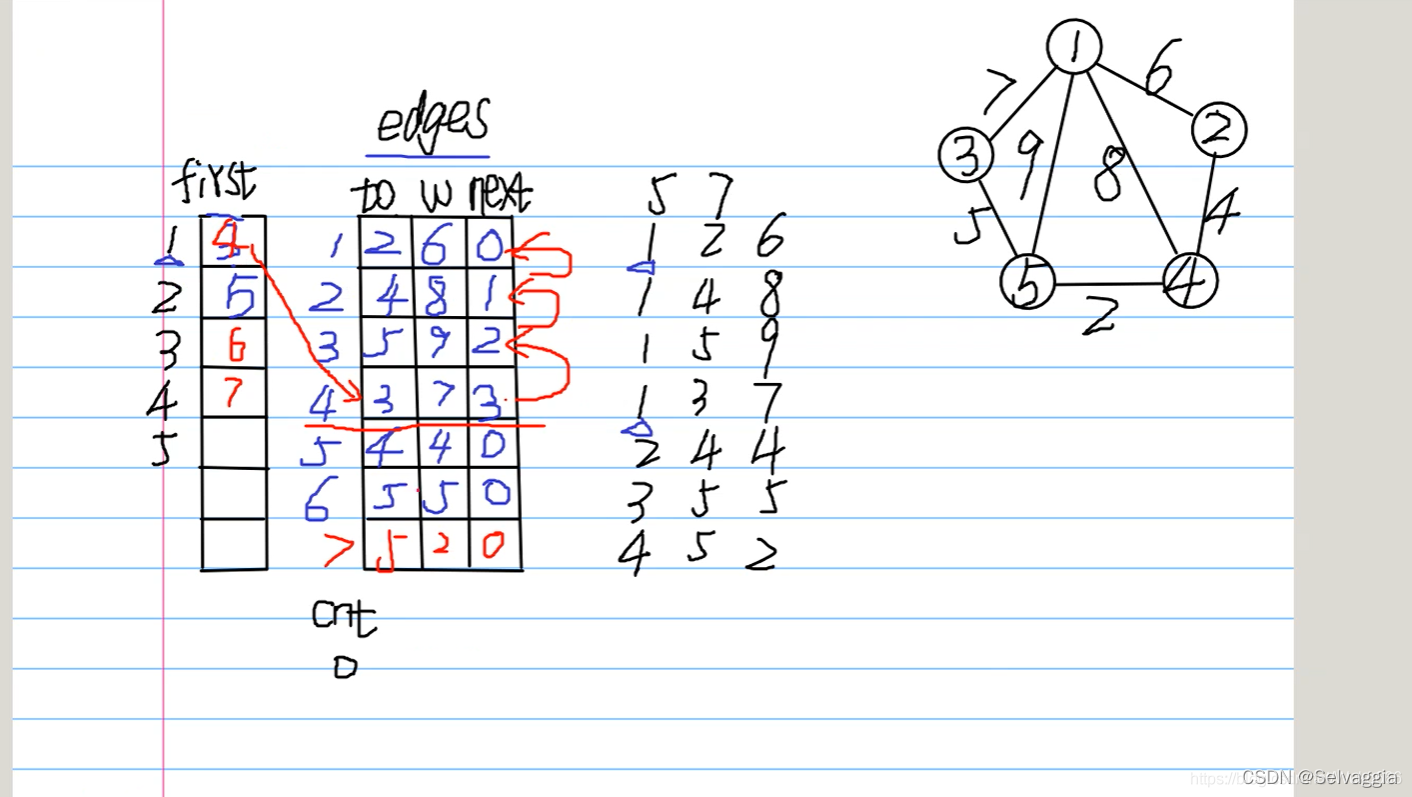
链式前向星其实就是
链表写法的邻接表改成数组来实现,不直接使用指针,用数组下标间接代替指针的作用
参考了链表头插法实现邻接表的思路:
1.链表中每插入一个边,是采用头插的方法,这里的思路也是头插;(第一条输入的边它的next指向就是-1,输入边的信息时它前面没有,输出时他后面也不再有边)
2.链表访问的结尾采用的是NULL,这里采用的是-1
而且我们经常直接使用(~i)作为循环的结束,因为对-1进行取反操作,可以直接得到0
(-1在计算机内以补码存储,为11111111,取反即00000000
edge.w——权重
edge.to——这条边的终点
edge.next——它指向同一起点的上一条边
那head数组是干啥的呢——head[u]代表以u为起点的边上一次出现的边的编号(我们可以使用它进行一个bfs)
#include <iostream>
#include <string.h>
using namespace std;
const int maxn=1e5;//顶点最大数目
const int maxe=1e5;//边的最大数目
int n,e;
struct edge{
int to;//这条边的终点
int next;//输入时同一起点上一条边的信息,输出时的下一条边,从输入角度上考虑,叫做from更加贴切
int w;//边的权重
}edge[maxe];
int cnt;//表示边的编号(第几条边,从1开始计数
int head[maxn];
//head[i]表示值(编号)为i的顶点为起点的边
//在edge[maxe]中的下标编号(输出、搜索时能找到的第一条边的序号,也是
//输入边的信息时,输入的最后一条以i为起点的边
void add(int u,int v,int w){
edge[++cnt].to=v;
edge[cnt].w=w;
edge[cnt].next=head[u];//输入时(以u为起点)上一条边的信息
head[u]=cnt;
}
//数组head[],它是用来表示以i为起点的第一条边存储的位置,
//实际上你会发现这里的第一条边存储的位置其实在以i为起点的
//所有边的最后输入的那个编号
void print(int s){
for(int i=head[s];~i;i=edge[i].next){
//i!=-1,-1在计算机内以补码存储,为11111111,取反即00000000
cout<<s<<" "<<edge[i].to<<" "<<edge[i].w<<endl;
}
}
int main(){
memset(head,-1,sizeof(head));
cin>>n>>e;//顶点个数、边的条数
int u,v,w;
for(int i=1;i<=e;i++){
cin>>u>>v>>w;
add(u,v,w);
}
print(1);//遍历以1为起点的所有边的信息
return 0;
}
无向图edge数组要开有向图的两倍
给出一条边的信息u,v,w
如果是有向边,只需要add(u,v,w);
如果存储无向边是只需要拆成两条相反的有向边就可以,注意数组要开二倍
add(u,v,w);
add(v,u,w);
全都是有向边还好,有无向边就要判断即将dfs的节点x的终点是否是x的起点, 少了这个判断就死循环了,由于层层递归,x取决于to的情况,而以to为起点发出去的一条边终点又是x,像拓扑排序里形成了个圈,互为前提
https://www.luogu.com.cn/problem/P2016
#include <iostream>
//#include <vector>
using namespace std;
const int MAX=1500;
//vector<int> son[MAX];
int vis[MAX];
int dp[MAX<<1][2];//dp[x][0]以x为根节点的子树上 在x上不妨士兵 共需士兵数
struct edge{
int to;
int next;
}e[MAX<<1];
int head[MAX<<1];
int cnt;
void add(int u,int v){
e[++cnt].to=v;
e[cnt].next=head[u];
head[u]=cnt;
}
void dfs(int x,int from){//全都是有向边还好,有无向边就要判断即将dfs的节点x的终点是否是x的起点, 少了这个判断就死循环了,由于层层递归,x取决于to的情况,而以to为起点发出去的一条边终点又是x,像拓扑排序里形成了个圈,互为前提
dp[x][1]=1;
dp[x][0]=0;//不放就只花0个士兵
// if(son[x].size()==0)return;
// for(int i=0;i<son[x].size();i++){
// int s=son[x][i];
for(int i=head[x];i;i=e[i].next){
int s=e[i].to;
if(s!=from){//由于视作了无向边a->b,b->a
dfs(s,x);
dp[x][1]+=min(dp[s][1],dp[s][0]);
dp[x][0]+=dp[s][1];
}
}
}
int main(){
int n;
cin>>n;
int x,y,k;//x节点有k个节点与他相连(k个孩子
for(int i=0;i<n;i++){
cin>>x>>k;
for(int i=0;i<k;i++){
cin>>y;
// son[x].push_back(y);
add(x,y);
add(y,x);
vis[y]=1;
}
}
int root;
for(int i=0;i<n;i++){
if(!vis[i]){
root=i;
break;
}
}
dfs(root,0);
cout<<min(dp[root][1],dp[root][0]);
return 0;
}
vector < Edge > G[]与链式前向星( 算法竞赛中存图最常见的两种方法)优缺点对比
其实区别也就是每个顶点的出边是用数组存储还是用链表存储。
我们对比一下这两种方法:
vector < Edge > G[]:
优点:
1.写起来比链式前向星快(大概
2.每个顶点的出边都是用vector存储的,方便执行一些STL中的函数(比如排序)
缺点
1.STL会略慢一些
2.浪费空间,由于vector申请空间的方式是两倍扩容,遇到卡空间的题目的时候会跪
3.数组可以random access的优点在图问题中通常没有什么卵用,但是数组不能O(1)删除元素的缺点在某些应用场合下非常致命
然后把上面的取个反大概也就是链式前向星的特点了…
所以在没有删边操作的情况下,以写的爽的角度来看的话应该是vector < Edge > G[]这种方式更爽一点,遇到需求删边操作或者对时间空间要求比较高的问题用链式前向星比较稳妥
只想O(1)删的话可以swap到尾部然后pop_back();
主要还是vector数组会卡时间空间,这里据说STL不止慢一点儿
来自https://www.zhihu.com/question/59676094


图的存储
https://oi-wiki.org/graph/save/
对链式前向星存储的边进行bfs、dfs
https://www.cnblogs.com/kirai/p/4956844.html


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









