






生成数据集
读取数据集
data.TensorDataset(*data_arrays)
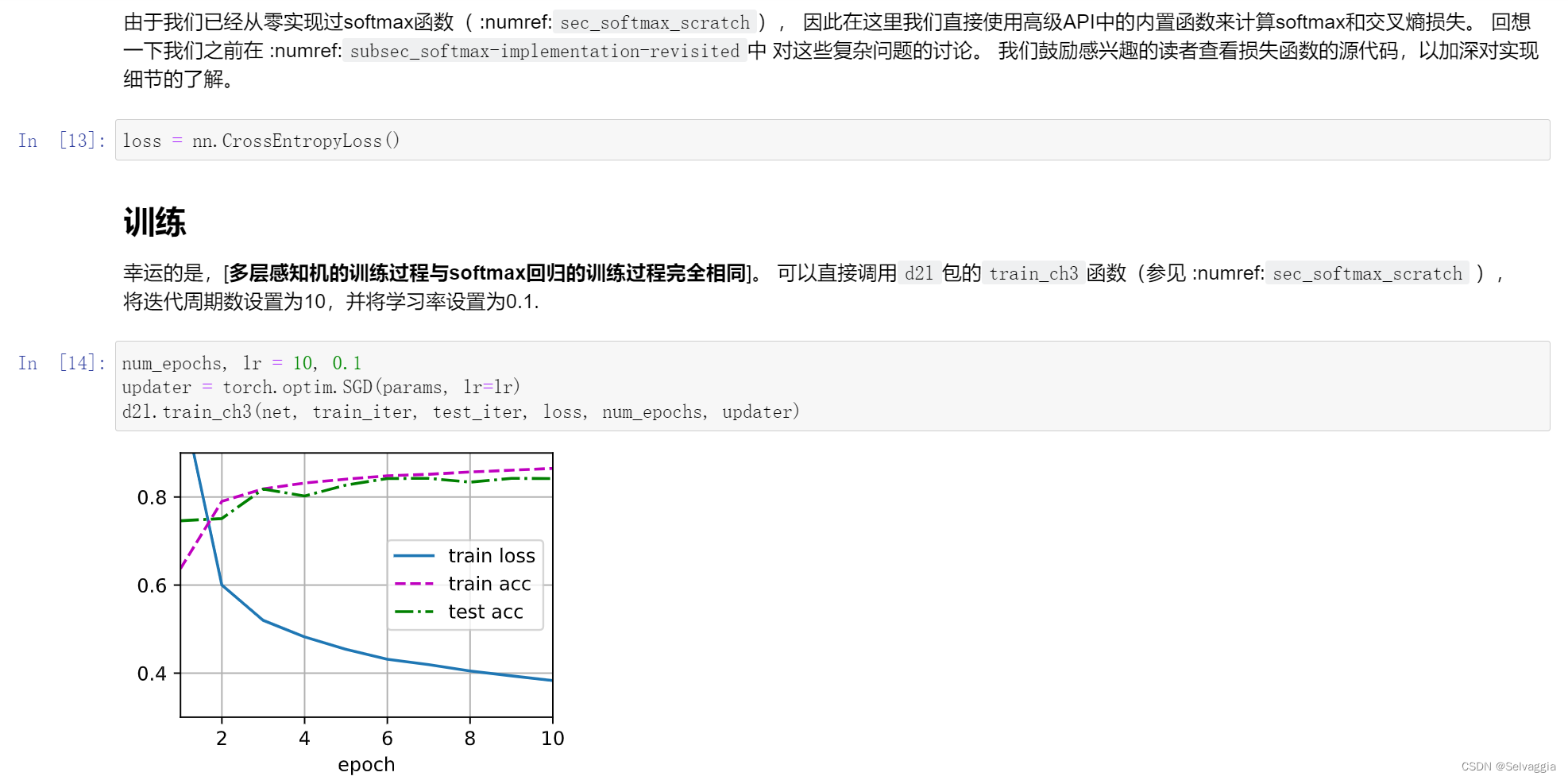
mlp训练
loss = nn.CrossEntropyLoss(reduction='none')
我要掌握所有人脖颈上的绳
权重衰减
简单概述就是在标准意义的loss函数(label值和计算值的差别)中再加上一个 惩罚项,为什么要加,
有种loss函数,或许我说的是SVM,在进行分类任务时,分类结果,正确类别要比别的类别 概率高,且要高过一个阈值,🔺theta,就算这个类别贡献的loss为0
这样一来,因为我们要训练优化的是我们的权重矩阵和偏置向量嘛,权重矩阵 的可能性就会很多,权重矩阵乘上一个标量照样可以使得 loss值一样小,改为0的项还是为0
可能会导致,过拟合(参数复杂,数据过少),于是 权重衰减,降低模型的复杂度,于是给loss函数加上一项,权重举证的L2范数正则化
暂退法
以p的概率将隐藏单元置为零时
不能过度依赖于h1, . . . , h5的任何一个元素
assert 0 <= dropout <= 1 断言语句
详细介绍assert model[i].weight_g is not None用法
assert(断言),判断assert后的表达式是否为true,若为true就继续执行下面的代码,若为false,则触发异常
在给定的代码中,assert model[i].weight_g is not None 是一个断言语句,用于在代码中进行条件检查。它用于确保模型 model 的第 i 个子模块具有名为 “weight_g” 的属性,并且该属性的值不为 None。
断言语句在程序中用于检查条件是否满足,如果条件为真,则程序继续执行;如果条件为假,则会引发 AssertionError 异常,并中断程序的执行。
在给定的断言语句中,model[i] 表示模型 model 的第 i 个子模块。model[i].weight_g 表示第 i 个子模块的属性 “weight_g”。通过检查 is not None,断言语句确保该属性的值不为 None。
这种用法通常在开发和调试过程中使用,用于验证程序的假设和前提条件。在深度学习中,断言语句常用于检查模型的属性、参数或状态,以确保模型的正确性和一致性。
下面是一个示例,演示了断言语句的使用:
class MyClass:
def __init__(self, value):
self.value = value
my_obj = MyClass(10)
assert my_obj.value > 0
print("Assertion passed") # 输出: Assertion passed
assert my_obj.invalid_attr is not None
print("Assertion passed") # 不会执行,引发 AssertionError
需要注意的是,断言语句在生产环境中通常是关闭的,因为它们会对程序的性能产生一定的影响。因此,断言通常在开发、调试和测试阶段使用,用于验证程序的正确性和健壮性。
来自此处
1.assert断言函数
assert断言是声明其布尔值必须为真的判定,如果发生异常就说明表达示为假。用来测试表示式,其返回值为假,就会触发异常。
assert os.path.exists(root), "dataset root: {} does not exist.".format(root)
#os.path.exists(root)为false是执行逗号后语句
assert os.path.exists(json_path), json_path + " does not exist."
原文链接:https://blog.csdn.net/lxh248866/article/details/121458354
mask = (torch.rand(X.shape) > dropout).float()
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1
# 在本情况中,所有元素都被丢弃
if dropout == 1:
return torch.zeros_like(X)
# 在本情况中,所有元素都被保留
if dropout == 0:
return X
mask = (torch.rand(X.shape) > dropout).float()
return mask * X / (1.0 - dropout)
mask可以理解成一个布尔型的张量,每一个值表示X对应下标的值是否要dropout
多敲了个n,randn是正态分布(均值为0方差为1的高斯分布),rand均匀分布
应该是rand吧?randn会出现小于0的值
前面说的应该有问题,randn是输出的是标准正态分布,rand才是输出的0到1的均匀分布
- 之后用该0 1矩阵乘以原矩阵,形状一致对应位置元素相乘,乘1保持不变,乘0就变0,相当于数据被dropout了,个人理解是这个过程
randn是mean=0,std=1的正态分布
大于dropout就是留下,小于等于dropout就是丢弃,所以丢弃的概率就是dropout
nn.Linear(输入输出neurals两个参数?)
self.lin1 = nn.Linear(num_inputs, num_hiddens1)
self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)
self.lin3 = nn.Linear(num_hiddens2, num_outputs)
self.relu = nn.ReLU()
深度学习框架的高级API
nn.Sequential 把各层封装起来的容器? 记得是lists of layers
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
# 在第一个全连接层之后添加一个dropout层
nn.Dropout(dropout1),
nn.Linear(256, 256),
nn.ReLU(),
# 在第二个全连接层之后添加一个dropout层
nn.Dropout(dropout2),
nn.Linear(256, 10))
梯度,导数是对角矩阵?
输出层为向量,其中一个标量只对应一列权重,对其他输出标量的权重列导数为零,所以是对角矩阵
假设Wh输出一个向量, Relu相当于把向量中大于0的保留, 小于0的变成零。 也就是一个对角矩阵(除了对角线全是0)乘以Wh的效果。这里求导用了链式法则。

pandas真好,还能把列的名称告诉你哈哈哈哈
train_data = pd.read_csv(d2l.download('kaggle_house_train', cache_dir='./pytorch_data'))
all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:]))
【技巧1】把认为没关系的特征给去掉!
这里的traindata不是干掉了第一列和最后一列吗
train提取除了第1列(即代码的第0列)和最后一列之外的数据
列表的1:-1表示从第二个元素开始到倒数第二个元素结束,即不包括第一个和最后一个元素
因为后面那个本身就缺少价格特征,所以少了一列,而前面那个加了-1,但是不会取-1这一列,所以这样这俩列数就相等了
train比test多最后一列标号,所以多删掉最后一列
train_data的最后一列是label,就是房价,不是训练用的特征,所以要拿掉;但是在test_data里面没有
这里为什么要把train_data和test_data合并呢?
特征缩放:使得特征的值在[-1,1]之间。好处是梯度下降的快一点
pandas的object是python里的str,不是str文本就是数值
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
因为是比赛,可以得到测试集,就把测试集和训练集一起算方差
归一化其实不应该用训练和测试集的期望和方差,,这里只不过把官方给的训练和测试集统一变成训练集了
all_features[numeric_features] = all_features[numeric_features].apply(
lambda x: (x - x.mean()) / (x.std()))
把均值变成0方差变成1
这个地方其实是要注意的,因为normalization应该统一用train set的均值和方差
为什么不在算均值之前先填充na值呢
先归一化再填补0不会让数据产生误差(从均值和方差的公式中可以得出),反而可以减少运算量
pandas算均值时会自动忽略值为NaN的项,不能先用0填充,否则求均值的时候就不是原先数据的均值了















 1313
1313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









