







目录
习题4-2 试设计一个前馈神经网络来解决 XOR 问题,要求该前馈神经网络具有两个隐藏神经元和一个输出神经元,并使用 ReLU 作为激活函数.
习题4-3 试举例说明“死亡ReLU问题”,并提出解决方法.
习题4-7 为什么在神经网络模型的结构化风险函数中不对偏置b进行正则化?
习题 4-8 为什么在用反向传播算法进行参数学习时要采用随机参数初始化的方式而不是直接令 w= 0, 𝒃 = 0?
1.4 正则化_哔哩哔哩_bilibili(吴恩达老师老版本)
4.3 正则化_哔哩哔哩_bilibili(吴恩达老师最新版本)编辑
习题4-2 试设计一个前馈神经网络来解决 XOR 问题,要求该前馈神经网络具有两个隐藏神经元和一个输出神经元,并使用 ReLU 作为激活函数.
前馈神经网络基础可见上个博客。
代码实现如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
from sklearn.metrics import accuracy_score
import numpy as np
from sklearn.svm import SVC
# XOR问题由两个全连接层构成
class XORModule(nn.Module):
def __init__(self):
super(XORModule, self).__init__()
self.fc1 = nn.Linear(2, 2)
self.fc2 = nn.Linear(2, 1)
self.relu = nn.ReLU()
def forward(self, x):
x = x.view(-1, 2)
x = self.relu((self.fc1(x)))
x = self.fc2(x)
return x
# 输入和输出数据
input_x = torch.Tensor([[0, 0], [0, 1], [1, 0], [1, 1]]).to(torch.float32)
label = torch.Tensor([[0], [1], [1], [0]]).to(torch.float32)
# 设置损失函数和参数优化函数
module = XORModule()
learing_rate = 0.1
epochs = 10000
loss_function = nn.MSELoss(reduction='mean') # MSE损失函数
optimizer = torch.optim.SGD(module.parameters(), lr=learing_rate) # SGD优化器
# 进行训练
for epoch in range(epochs):
out_y = module(input_x)
loss = loss_function(out_y, label) # 计算损失函数
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 参数更新
out_test = module(input_x)
print("前馈神经网络的准确率:{}%".format(accuracy_score(out_test.detach().numpy().astype(np.int64), label1.detach().numpy())*100))
from sklearn.neural_network import MLPClassifier
# MLP
x_train = [[0, 0], [0, 1], [1, 0], [1, 1]]
y_train = [0, 1, 1, 0]
# 生成模型,迭代次数max_iter少了会有一个警告
model = MLPClassifier(hidden_layer_sizes=(20,), max_iter=10000)
# 训练与预测
model.fit(x_train, y_train)
predict = model.predict([[1, 0]])
# print(predict)
print("机器学习库MLP的准确率:{}%".format(model.score(x_train, y_train) * 100))
# 知识向量机
svm_model = SVC(kernel='rbf', gamma=0.1)
svm_model.fit(x_train, y_train)
predict1 = svm_model.predict(x_train)
accuracy1 = accuracy_score(y_train, predict1)
print('SVM(高斯核)的准确率:{}%'.format(accuracy1 * 100))
# 逻辑回归
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
mm = LogisticRegression()
mm.fit(x_train, y_train)
y_hat = mm.predict(x_train)
acc = accuracy_score(y_hat, y_train)
print("逻辑回归的准确率:{}%".format(acc * 100))
手写前馈神经网络,顺便拿包装好的MLP模型测试了一下,发现两个隐藏层神经元不太行,调节了lr仍然准确率仍然不能达到百分百,如下:
所以微调了隐藏层神经元的个数,实现XOR问题的解决:
SVM是上学期机器学习的知识,采用的是高斯核,不需要调节超参数,对当前问题来说,我觉得要比MLP好用。至于为什么逻辑回归的准确率是50%,老生常谈,他是一个线性二分类器。
习题4-3 试举例说明“死亡ReLU问题”,并提出解决方法.
梯度消失:在神经网络的构建过程中,随着网络层数的增加,理论上网络的拟合能力也应该是越来越好的。但是随着网络变深,参数学习更加困难,容易出现梯度消失问题。由于Sigmoid型函数的饱和性,饱和区的导数更接近于0,误差经过每一层传递都会不断衰减。当网络层数很深时,梯度就会不停衰减,甚至消失,使得整个网络很难训练,这就是所谓的梯度消失问题。
在深度神经网络中,减轻梯度消失问题的方法有很多种,一种简单有效的方式就是使用导数比较大的激活函数,如:ReLU,但ReLu会出现“死亡ReLU”问题。

死亡ReLU问题:ReLU激活函数可以一定程度上改善梯度消失问题,但是ReLU函数在某些情况下容易出现死亡 ReLU问题,使得网络难以训练。这是由于当x<0时,ReLU函数的输出恒为0。在训练过程中,如果参数在一次不恰当的更新后,某个ReLU神经元在所有训练数据上都不能被激活(即输出为0),那么这个神经元自身参数的梯度永远都会是0,在以后的训练过程中永远都不能被激活。
代码层面:拿上个博客的实验举例死亡ReLU问题:
当神经层的偏置被初始化为一个相对于权重较大的负值时,可以想像,输入经过神经层的处理,最终的输出会为负值,从而导致死亡ReLU现象。上节实验为4个隐藏层和1个输出层,初始权重初始化为-8,如下(其余代码见上个博客):
# 定义多层前馈神经网络
class Model_MLP_L5(torch.nn.Module):
def __init__(self, input_size, output_size, act='relu'):
super(Model_MLP_L5, self).__init__()
self.fc1 = torch.nn.Linear(input_size, 3)
w_ = torch.normal(0, 0.01, size=(3, input_size), requires_grad=True)
self.fc1.weight = nn.Parameter(w_)
# self.fc1.bias = nn.init.constant_(self.fc1.bias, val=1.0)
self.fc1.bias = nn.init.constant_(self.fc1.bias, val=-8.0)
w= torch.normal(0, 0.01, size=(3, 3), requires_grad=True)
self.fc2 = torch.nn.Linear(3, 3)
self.fc2.weight = nn.Parameter(w)
# self.fc2.bias = nn.init.constant_(self.fc2.bias, val=1.0)
self.fc1.bias = nn.init.constant_(self.fc1.bias, val=-8.0)
self.fc3 = torch.nn.Linear(3, 3)
self.fc3.weight = nn.Parameter(w)
# self.fc3.bias = nn.init.constant_(self.fc2.bias, val=1.0)
self.fc3.bias = nn.init.constant_(self.fc3.bias, val=-8.0)
self.fc4 = torch.nn.Linear(3, 3)
self.fc4.weight = nn.Parameter(w)
# self.fc4.bias = nn.init.constant_(self.fc2.bias, val=1.0)
self.fc4.bias = nn.init.constant_(self.fc4.bias, val=-8.0)
self.fc5 = torch.nn.Linear(3, output_size)
w1 = torch.normal(0, 0.01, size=(output_size, 3), requires_grad=True)
self.fc5.weight = nn.Parameter(w1)
# self.fc5.bias = nn.init.constant_(self.fc2.bias, val=1.0)
self.fc5.bias = nn.init.constant_(self.fc5.bias, val=-8.0)
# 定义网络使用的激活函数
if act == 'sigmoid':
self.act = F.sigmoid
elif act == 'relu':
self.act = F.relu
elif act == 'lrelu':
self.act = F.leaky_relu
else:
raise ValueError("Please enter sigmoid relu or lrelu!")
经过训练后,debug查看第五层、第三层、第一层的权重梯度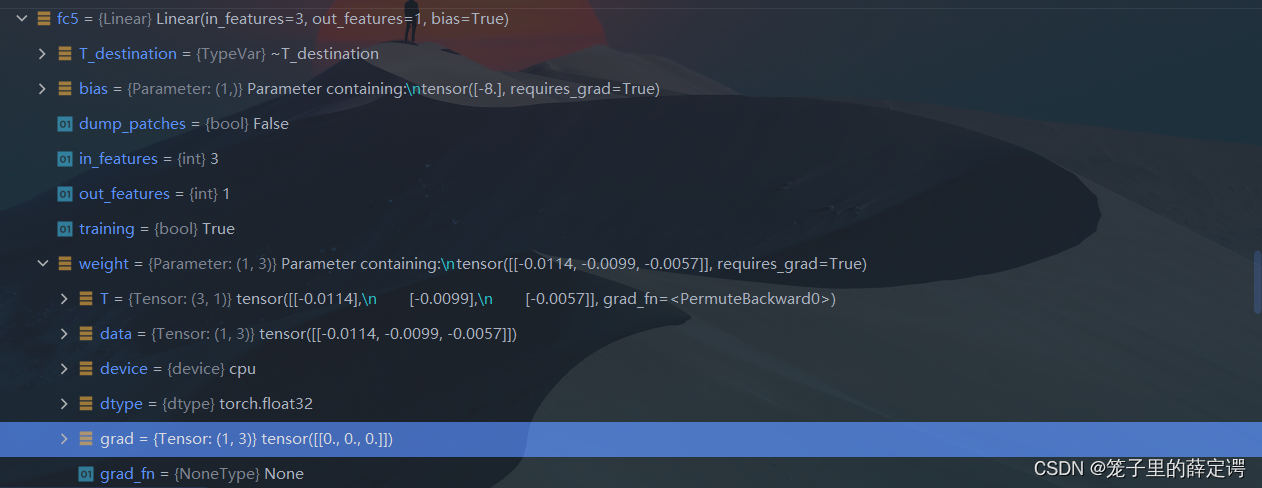

 可以很清晰的看到,网络训练过程中 ReLU 神经元权重的梯度始终为0,参数无法更新。
可以很清晰的看到,网络训练过程中 ReLU 神经元权重的梯度始终为0,参数无法更新。
针对死亡ReLU问题,一种简单有效的优化方式就是将激活函数更换为Leaky ReLU、ELU等ReLU 的变种。
接下来,观察将激活函数更换为 Leaky ReLU时的梯度情况
代码如下(详细代码请见上个博客):
# 定义网络,激活函数使用lrelu
model = Model_MLP_L5(input_size=2, output_size=1, act='lrelu')
然后 Debug查看fc5、fc3与fc1的权重与梯度:

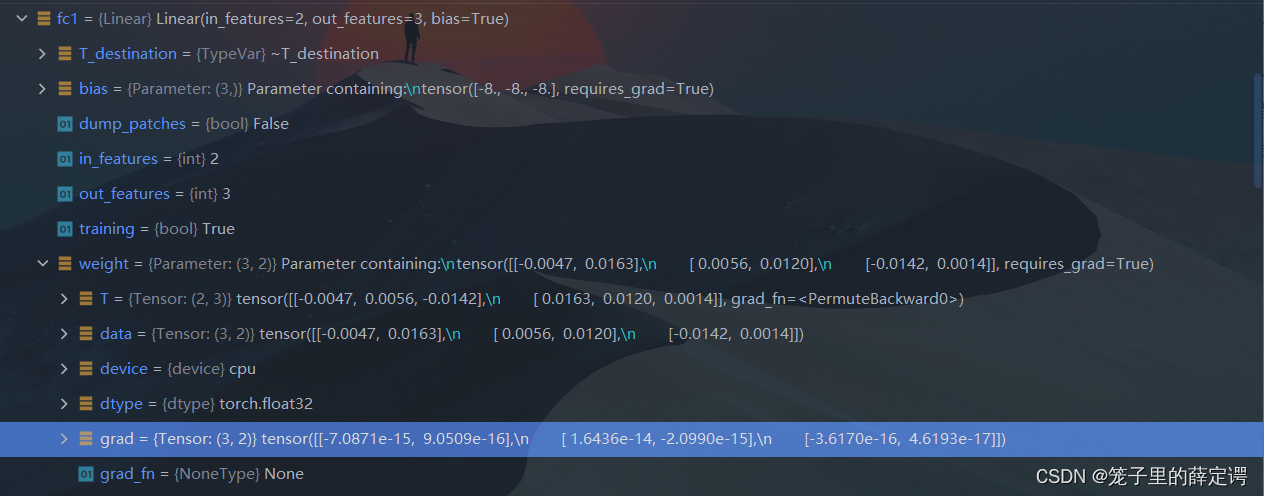
从输出结果可以看到,将激活函数更换为Leaky ReLU后,死亡ReLU问题得到了改善,梯度恢复正常,参数也可以正常更新。但是由于 Leaky ReLU 中,x<0 时的斜率默认只有0.01,所以反向传播时,随着网络层数的加深,梯度值越来越小(可以看到到第一全连接层梯度只剩下)。如果想要改善这一现象,将 Leaky ReLU 中,x<0 时的斜率调大即可。
数学推导:
向前传播公式:
损失函数为 L,反向传播公式为:

对固定的学习率lr,梯度,权重
更新也就越快,梯度更新公式:
如果梯度太大,而学习率又不小心设置得太大,就会导致权重一下子更新过多。
而我们又想使得损失函数最小,就有可能出现这种情况:对于任意训练样本,网络的输出都是小于0的,用数学描述为:
此时:,即与该神经元相连得参数都得不到更新,神经元进入“休眠状态”
习题4-7 为什么在神经网络模型的结构化风险函数中不对偏置b进行正则化?
加入正则化项的目的是为了防止过拟合, 防止它对于输入的微小变化过于敏感,而过拟合一般表现为模型对于输入的微小改变产生了输出的较大差异,这主要是由于有些参数w过大的关系,通过对||w||进行惩罚,可以缓解这种问题。
而如果对||b||进行惩罚,其实是没有作用的,因为在对输出结果的贡献中,参数b对于输入的改变是不敏感的,不管输入改变是大还是小,参数b的贡献就只是加个偏置而已。举个例子,如果你在训练集中,w和b都表现得很好,但是在测试集上发生了过拟合,b是不背这个锅的,因为它对于所有的数据都是一视同仁的(都只是给它们加个偏置),要背锅的是w,因为它会对不同的数据产生不一样的加权。即模型对于输入的微小改变产生了输出的较大差异,这是因为模型的“曲率”太大,而模型的曲率是由w决定的,b不贡献曲率(对输入进行求导,b是直接约掉的)
在AI圣经花书第七章里面提到:
原文:Before delving into the regularization behavior of different norms, we note that for neural networks, we typically choose to use a parameter norm penalty Ω that penalizes only the weights of the affine transformation at each layer and leaves the biases unregularized. The biases typically require less data to fit accurately than the weights. Each weight specifies how two variables interact. Fitting the weight well requires observing both variables in a variety of conditions. Each bias controls only a single variable. This means that we do not induce too much variance by leaving the biases unregularized.Also,regularizing the bias parameters can introduce a significant amount of underfitting.
读花书原文读不懂?看吴恩达老师怎么用通俗的语言解释:
老师的解释是:可以加上,但是没必要。因为W通常是一个高维参数矢量,已经可以表达高偏差问题,W可能含有很多参数,我们不可能拟合所有参数,而b只是单个数字,所以w几乎涵盖所有参数,而不是b。加了参数b,也没有什么太大的影响,因为b只是众多参数中的一个。如果想加入偏置b这个正则化,完全没问题。
注:我看的是老版本吴恩达老师得解释,新版貌似又更新了一些说法,大体意思都差不多
收集了一些网友的帖子:
网友1:从贝叶斯的角度来讲,正则化项通常都包含一定的先验信息,神经网络倾向于较小的权重以便更好地泛化,但是对偏置就没有这样一致的先验知识。另外,很多神经网络更倾向于区分方向信息(对应于权重),而不是位置信息(对应于偏置),所以对偏置加正则化项对控制过拟合的作用是有限的,相反很可能会因为不恰当的正则强度影响神经网络找到最优点。
网友2:过拟合会使得模型对异常点很敏感,即准确插入异常点,导致拟合函数中的曲率很大(即函数曲线的切线斜率非常高),而偏置对模型的曲率没有贡献(对多项式模型进行求导,为W的线性加和),所以正则化他们也没有什么意义。
习题 4-8 为什么在用反向传播算法进行参数学习时要采用随机参数初始化的方式而不是直接令 w= 0, 𝒃 = 0?
反向传播就是要将神经网络的输出误差,一级一级地传播到输入。在计算过程中,计算每一个 w对总的损失函数的影响,即损失函数对每个 w的偏导。根据 w 的误差的影响,再乘以步长(学习率),就可以更新整个神经网络的权重。当一次反向传播完成之后,网络的参数模型就可以得到更新。更新一轮之后,接着输入下一个样本,算出误差后又可以更新一轮,再输入一个样本,又来更新一轮,通过不断地输入新的样本迭代地更新模型参数,就可以缩小计算值与真实值之间的误差,最终完成神经网络的训练。当直接令 w=0,b=0时,会让下一层神经网络中所有神经元进行着相同的计算,具有同样的梯度,同样权重更新,这样会导致隐藏层神经元没有差异性,出现对称权重现象。
拿上节实验举例(详细代码请见上个博客):
# import torch
import torch.nn as nn
import torch.nn.functional as F
# 定义多层前馈神经网络
class Model_MLP_L2_V4(torch.nn.Module):
def __init__(self, input_size, hidden_size,output_size):
super(Model_MLP_L2_V4, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
# w1=torch.normal(0,0.1,size=(hidden_size,input_size),requires_grad=True)
# self.fc1.weight = nn.Parameter(w1)
self.fc1.weight=nn.init.constant_(self.fc1.weight,val=0.0)
# self.fc1.bias = nn.init.constant_(self.fc1.bias, val=1.0)
self.fc1.bias = nn.init.constant_(self.fc1.bias, val=0.0)
self.fc2 = nn.Linear(hidden_size, output_size)
# w2 = torch.normal(0, 0.1, size=(output_size, hidden_size), requires_grad=True)
# self.fc2.weight = nn.Parameter(w2)
self.fc2.weight = nn.init.constant_(self.fc2.weight, val=0.0)
self.fc2.bias = nn.init.constant_(self.fc2.bias, val=0.0)
# 使用'torch.nn.functional.sigmoid'定义 Logistic 激活函数
self.act_fn = torch.sigmoid
# 前向计算
def forward(self, inputs):
z1 = self.fc1(inputs.to(torch.float32))
a1 = self.act_fn(z1)
z2 = self.fc2(a1)
a2 = self.act_fn(z2)
return a2

由上图可知,对于同一隐藏层的不同神经元,它们之间没有差异性,出现对称权重现象。
后果就是二分类准确率维持为50%左右,说明模型没有学到任何内容。训练和验证loss几乎没有怎么下降。
为解决这个问题,一般使用高斯分布或均匀分布初始化神经网络的参数。
习题4-9 梯度消失问题是否可以通过增加学习率来缓解?
梯度消失问题:在神经网络的构建过程中,随着网络层数的增加,理论上网络的拟合能力也应该是越来越好的。但是随着网络变深,参数学习更加困难,容易出现梯度消失问题。由于Sigmoid型函数的饱和性,饱和区的导数更接近于0,误差经过每一层传递都会不断衰减。当网络层数很深时,梯度就会不停衰减,甚至消失,使得整个网络很难训练,这就是所谓的梯度消失问题。
深度学习,实验为王,先有结果再想解释。我先拿上节的sigmoid梯度消失梯度试一下,如下:
lr=0.01
lr=0.1

此时lr=10
发现啥也看不出,甚至变得更坏了?我猜测是优化器的缘故,去翻了一下 torch.optim.SGD()函数文档,发现你就算微改了lr,效果也很微小,而如果你改的很大,可能会跳过全局极小,甚至可能发生梯度爆炸现象。
梯度爆炸对于网络浅倒是不太可能,所以我觉得网络层浅的话,将步长调大是有效果的,网络层深的话,还是老老实实使用relu、leaky-relu激活函数吧。
在上个学期训练复杂模型的时候就有思考过调节学习率超参数这个问题,因为在训练时,学习率稍微大一点,很容易模型输出全为NAN值,很苦恼,所以当时打听了一下,貌似现在用动态学习率的很多,像Adam这一类的优化算法,省得去逐层设置学习率了
总结
这次作业题五个有三个都是上个实验做过得,剩下两个还有一个问题是在上学期机器学习做过,所以作业量不大,做起来也很容易。收获最大的便是正则化项为什么不带偏置b,复习了吴恩达老师视频,又查了很多的资料,最终觉得吴恩达老师解释的关于W是高维参数矢量,包含了很多参数,而b只是一个常数的角度以及网友从拟合曲线的曲率角度出发的角度最容易理解,花书并不是太能理解。














 9719
9719











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









