






一、Redis持久化
1.什么是Redis的持久化
redis的所有数据都是保存在内存中,redis崩掉数据会丢失。redis持久化就是把数据保存在磁盘上。利用永久性存储介质将数据进程保存,在特定的时间将保存的数据进行恢复的工作机制称为持久化。
2.Redis持久化策略
Redis的持久化策略有两种,分别是AOF和RDB。
-
AOF:默认每秒对数据进行持久化
-
RDB:按条件触发持久化操作,满足任意一个条件
-
900 1 900秒中修改1次
-
300 10 300秒中修改10次
-
60 10000 60秒中修改10000次
-
3.配置方法
在redis.conf中配置RDB持久化

启动AOF的配置
appendonly yes 开启AOF
appendfsync everysec 每秒保存
4.Redis持久化机制的选择
如何选择两种持久化机制就需要根据业务需求来决定了
-
允许少量数据丢失,性能要求高,选择RDB
-
只允许很少数据丢失,选择AOF
-
几乎不允许数据丢失,选择RDB + AOF
二、Redis的淘汰策略
1.淘汰机制的原理
Redis是一个基于内存的数据库,因此其内存资源是有限的。当Redis的内存使用达到一定阈值时,就需要对数据进行淘汰,以释放部分内存空间。而淘汰机制就是根据一定的策略,选择需要被淘汰的数据,从而保证 Redis的内存使用在可控范围内。
2.淘汰策略的分类
2.1配置最大内存:
max-memory 配置0就是无上限(默认)
2.2配置淘汰策略
maxmemory-policy
它的值有:
-
noevication(默认)不淘汰
-
volatile-ttl 在过期键中淘汰存活时间短的键
-
allkeys-lru (推荐)使用LRU算法淘汰比较少使用的键 LRU算法:Least Recently Used 最近最少使用算法,淘汰长期不用的缓存
LFU算法:Least Frequently Used 频率最少使用算法,淘汰使用频率少的缓存
-
volatile-lru 在过期的键中淘汰较少使用的
-
allkeys-random 在所有键中随机淘汰
-
volatile-random 在过期键中随机淘汰
-
allkeys-lfu
-
volatile-lfu
三、Redis的并发问题
1.Redis常见的并发问题及解决方案
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 雪崩 | 1. Redis热点数据同时过期,大量请求全部打到MySQL,MySQL宕机 2. 单个Redis服务出现问题或重启 | 1. 将热点数据过期时间设置为随机值,避免同时过期 2. 配置Redis集群,解决单点故障问题 |
| 击穿 | 大量并发请求访问Redis同一个数据,还没有向Redis保存,有大量线程同时访问,导致MySQL压力过大 | 通过上锁(双检锁)实现线程同步执行 |
| 穿透 | 大量请求访问MySQL没有的数据,Redis缓存无法命中,导致数据库压力过大 | 1. 在Redis中保存空对象,给空对象设置过期时间 2. 使用布隆过滤器筛选掉不存在的数据 |
2.击穿问题
某个 key 非常非常热,访问非常的频繁,高并发访问的情况下,当这个 key在失效(可能expire过期了,也可能LRU淘汰了)的瞬间,大量的请求进来,这时候就击穿了缓存,直接请求到了数据库,一下子来这么多,数据库肯定受不了,这就叫缓存击穿。
2.1线程并发案例
@Service
public class StudentServiceImpl extends ServiceImpl<StudentMapper, Student> implements StudentService {
public static final String PREFIX = "Student-";
@Autowired
private StudentMapper studentMapper;
@Autowired
private RedisTemplate<String,Object> redisTemplate;
@Override
public Student getStudentById(Long id) {
//获得字符串操作对象
ValueOperations<String, Object> ops = redisTemplate.opsForValue();
//先查询Redis
Student stu = (Student) ops.get(PREFIX + id);
//如果Redis缓存存在数据,就直接返回
if(stu != null){
System.out.println("Redis查到,返回" + stu);
return stu;
}
//如果Redis没有查到数据,就查询MySQL
stu = studentMapper.selectById(id);
//MySQL查到数据,就保存到Redis
if(stu != null){
System.out.println("MySQL查到,返回" + stu);
ops.set(PREFIX + id,stu);
return stu;
}
//MySQL没有数据,就返回null
System.out.println("MySQL没有数据,就返回null");
return null;
}
}@RestController
public class StudentController {
@Autowired
private StudentService studentService;
@GetMapping("/student/{id}")
public ResponseResult<Student> getStudentById(@PathVariable Long id){
return ResponseResult.ok(studentService.getStudentById(id));
}
}2.2JMter工具
为了方便模拟多个线程同时对一个数据进行访问,这里使用JMeter工具
下载地址
https://github.com/apache/jmeter
下载完成后,双击进入文件夹找到bin目录下的jmeter.bat,双击该文件

1)添加线程组

2) 配置线程数量

3) 添加http测试
4) 配置http连接
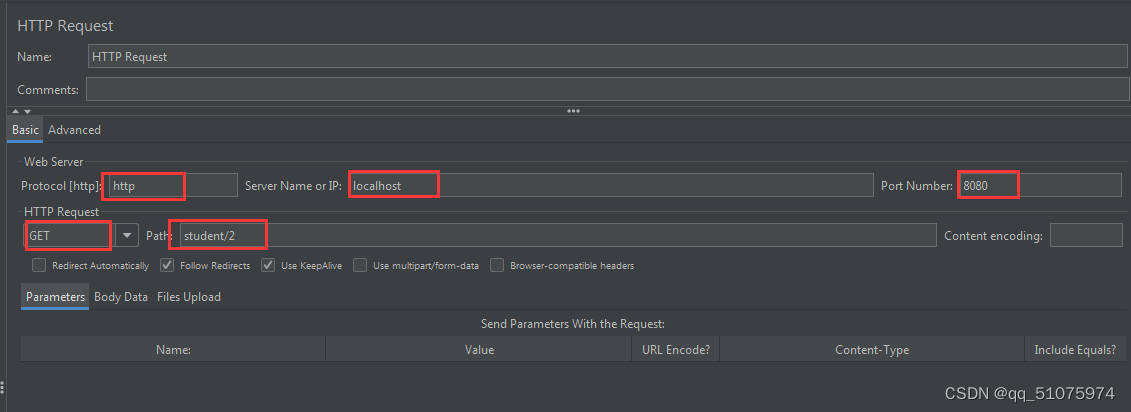 5) 添加结果视图
5) 添加结果视图

2.3使用双检索解决上述案例问题
@Override
public Student getStudentById(Long id) {
//获得字符串操作对象
ValueOperations<String, Object> ops = redisTemplate.opsForValue();
//先查询Redis
Student stu = (Student) ops.get(PREFIX + id);
if(stu == null) {
synchronized (this) {
System.out.println("进入了同步锁");
//先查询Redis
stu = (Student) ops.get(PREFIX + id);
//如果Redis缓存存在数据,就直接返回
if (stu != null) {
System.out.println("Redis查到,返回" + stu);
return stu;
}
//如果Redis没有查到数据,就查询MySQL
stu = studentMapper.selectById(id);
//MySQL查到数据,就保存到Redis
if (stu != null) {
System.out.println("MySQL查到,返回" + stu);
ops.set(PREFIX + id, stu);
return stu;
}
//MySQL没有数据,就返回null
System.out.println("MySQL没有数据,就返回null");
}
}else {
System.out.println("没有执行同步锁");
}
return stu;
}3.穿透问题
是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次无用的查询)。这样请求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题。有如下两种方法:
3.1 保存空对象设置过期时间
@Override
public Student getStudentById(Long id) {
//获得字符串操作对象
ValueOperations<String, Object> ops = redisTemplate.opsForValue();
//先查询Redis,如果存在数据就不执行同步代码块,直接返回
Student stu = (Student) ops.get(PREFIX + id);
if(stu == null) {
synchronized (this) {
System.out.println("进入了同步锁");
//先查询Redis
stu = (Student) ops.get(PREFIX + id);
//如果Redis缓存存在数据,就直接返回
if (stu != null) {
System.out.println("Redis查到,返回" + stu);
return stu;
}
//如果Redis没有查到数据,就查询MySQL
stu = studentMapper.selectById(id);
//MySQL查到数据,就保存到Redis
if (stu != null) {
System.out.println("MySQL查到,返回" + stu);
ops.set(PREFIX + id, stu);
return stu;
}else {
//MySQL没有数据,在Redis保存空对象,设置过期时间
System.out.println("MySQL没有数据");
Student student = new Student();
ops.set(PREFIX + id, student,5, TimeUnit.SECONDS);
}
}
}else {
System.out.println("没有执行同步锁");
}
return stu;
}3.2布隆 过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
redission
redission基于Redis工具包,提供了大量功能
1) 引入依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.16.6</version>
</dependency>2) 创建布隆过滤器
@Configuration
public class RedissonConfig {
@Bean
public RBloomFilter<String> bloomFilter(){
Config config = new Config();
config.setTransportMode(TransportMode.NIO);
SingleServerConfig singleServerConfig = config.useSingleServer();
//可以用"rediss://"来启用SSL连接
singleServerConfig.setAddress("redis://127.0.0.1:6379");
RedissonClient redisson = Redisson.create(config);
//创建布隆过滤器
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("student-filter");
//初始化 参数1 向量长度 参数2 误识别率
bloomFilter.tryInit(10000000L,0.03);
return bloomFilter;
}
}3) 将数据的id保存到过滤器中
@Autowired
private RBloomFilter<String> rBloomFilter;
/**
* 初始化布隆过滤器
* @return
*/
@GetMapping("init-student-filter")
public ResponseResult<String> initStudentFilter(){
List<Student> list = studentService.list();
//将所有id保存到过滤器中
list.forEach(student -> {
rBloomFilter.add(String.valueOf(student.getStuId()));
});
return ResponseResult.ok("ok");
}4) 使用过滤器排除不存在的数据
@Autowired
private RBloomFilter<String> rBloomFilter;
@Override
public Student getStudentById(Long id) {
//获得字符串操作对象
ValueOperations<String, Object> ops = redisTemplate.opsForValue();
//先查询Redis
Student stu = (Student) ops.get(PREFIX + id);
if(stu == null) {
synchronized (this) {
System.out.println("进入了同步锁");
//先查询Redis
stu = (Student) ops.get(PREFIX + id);
//如果Redis缓存存在数据,就直接返回
if (stu != null) {
System.out.println("Redis查到,返回" + stu);
return stu;
}
//使用布隆过滤器判断数据库中是否存在该id
if(rBloomFilter.contains(String.valueOf(id))) {
//如果Redis没有查到数据,就查询MySQL
stu = studentMapper.selectById(id);
//MySQL查到数据,就保存到Redis
if (stu != null) {
System.out.println("MySQL查到,返回" + stu);
ops.set(PREFIX + id, stu);
return stu;
}
}else{
System.out.println("布隆过滤器判断id数据库不存在,直接返回");
}
}
}else {
System.out.println("没有执行同步锁");
}
return stu;
}四、总结
Redis 的出色之处不仅仅是性能,Redis 最大的魅力是支持保存多种数据结构,redis支持set,zset,list,hash,string这五种数据类型,此外单个 Value 的最大限制是1GB,不像 Memcached只能保存1MB的数据,因此Redis可以用来实现很多有用的功能。
Redis还具有丰富的特性,订阅发布 Pub / Sub 功能、Key 过期策略、事务、支持多个 DB
计数等,总之,使用Redis能够为开发带来更多的便捷。















 207
207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









