









Java爬虫

以sougou图片为例:https://pic.sogou.com/
JDK17、SpringBoot3.2.X、hutool5.8.24实现Java爬虫,爬取页面图片
项目介绍
开发工具:
IDEA2023.2.5JDK:
Java17SpringBoot:
3.2.x
通过 SpringBoot 快速构建开发环境,通过 Jsoup 实现对网页的解析,并获取想要的资源数据
使用 hutool 工具,将所需要的字符串转成 JSON 对象,并从 JSON 对象中获取对应的数据资源
爬取网页图片资源,并将爬取到的资源下载到本地文件夹,对于大量的资源使用多线程下载
核心Jar包
<!-- 解html析 -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>
项目依赖
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.1</version>
<relativePath/>
</parent>
<groupId>cn.molu</groupId>
<artifactId>jsoup</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>jsoup</name>
<description>
java网络爬虫;更多技术分享地址请关注:https://blog.csdn.net/qq_51076413
</description>
<properties>
<java.version>17</java.version>
<java.source.version>17</java.source.version>
<java.target.version>17</java.target.version>
<java.compiler.version>17</java.compiler.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
</properties>
<dependencies>
<!-- hutool工具包 -->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.24</version>
</dependency>
<!-- jsoup解析包,核心 -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>
<!-- web依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 热加载,修改代码后不需要手动重启(如果配置了JRebel可以不使用该插件) -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<!-- lombok简化实体类 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>·
</build>
</project>
爬取思路
一、解析网页:获取资源网页,从网页中解析想要的资源数据;
- 查看网页资源的位置,分析资源渲染到页面的规律;
- 根据分析到的规律,统一提取资源数据,得到列表;
- 对列表数据进行进一步解析,最终拿到想要的资源;
- 对资源数据进行处理,保存到数据库或是下载资源;
二、调用接口:直接获取想要的图片资源;
- 需要分析资源网站,获取资源数据加载的时机和请求接口;
- 分析接口的请求参数,入参是否有加密,是否有请求限制;
- 测试接口,拿到结果,查看结果是否是自己所需要的资源;
- 处理资源数据,保存到数据库或者将资源文件下载到本地;
三、缓存资源:从页面JS中直接获取资源
- 页面加载后,我们下滑或者分页时,没有请求日志;
- 页面没有重新加载,但是数据在不断更新和加载中;
- 当超过一定数量时,会有一次的请求日志显示出来;
- 最后分析得到,数据是缓存到页面中的JS变量中了;
一、解析网页
1.1、过程与思路
分析资源:
- 打开资源网站,分析和定位资源所在位置,并分析资源渲染到页面的规律;
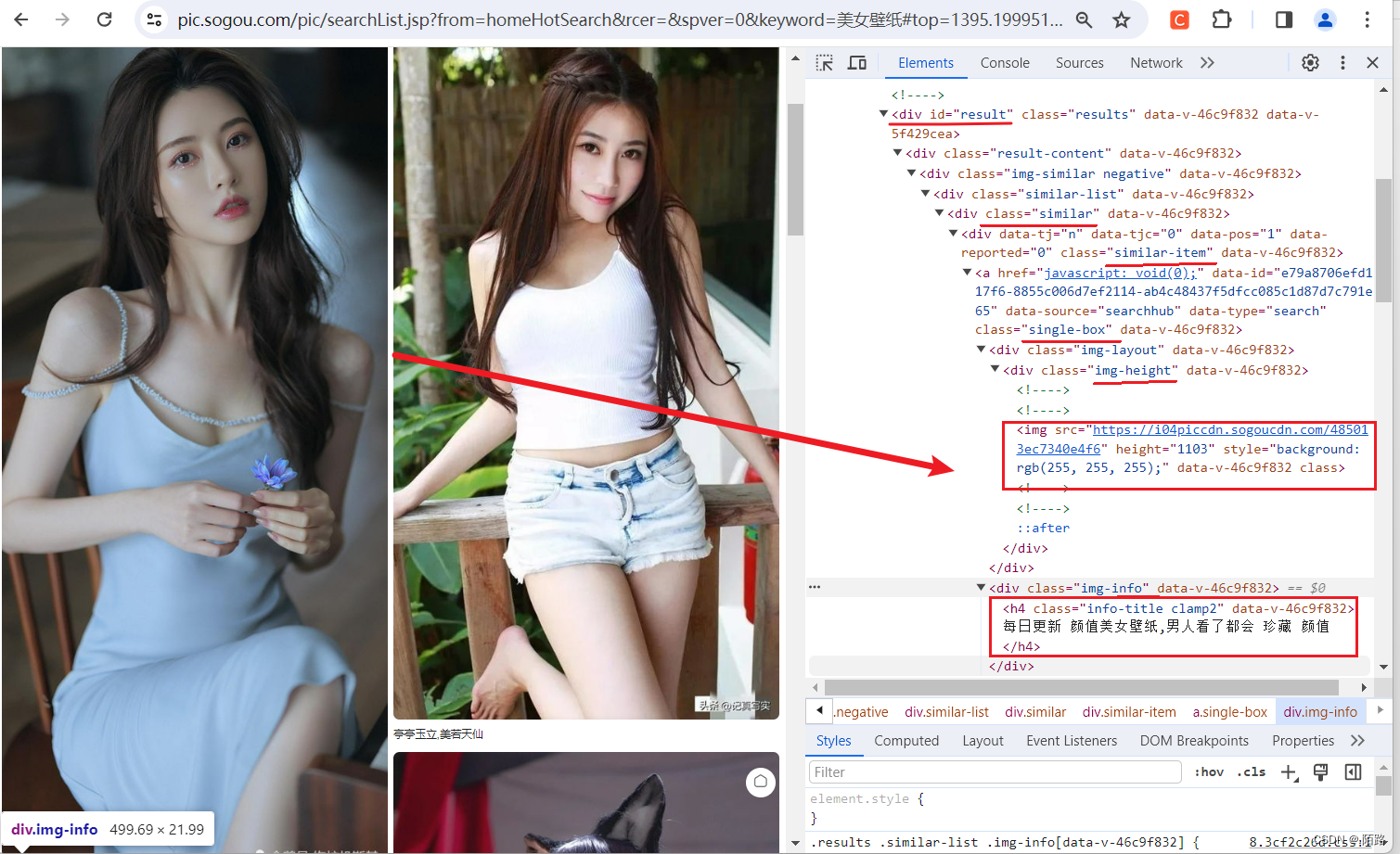
- 如图,定位到资源位置,并发现了资源渲染的规律,使用
document.querySelectorAll('xxx')可以得到页面中所有的资源
网站地址:https://pic.sogou.com/pic/searchList.jsp?from=homeHotSearch&rcer=&spver=0&keyword=美女壁纸#top=1395.199951171875&more=false
定位资源所在位置
使用css选择器获取资源:
- 根据分析到的规律,统一提取资源数据,得到列表;
document.querySelectorAll('div#result div.similar div.similar-item a.single-box')得到所有的资源列表
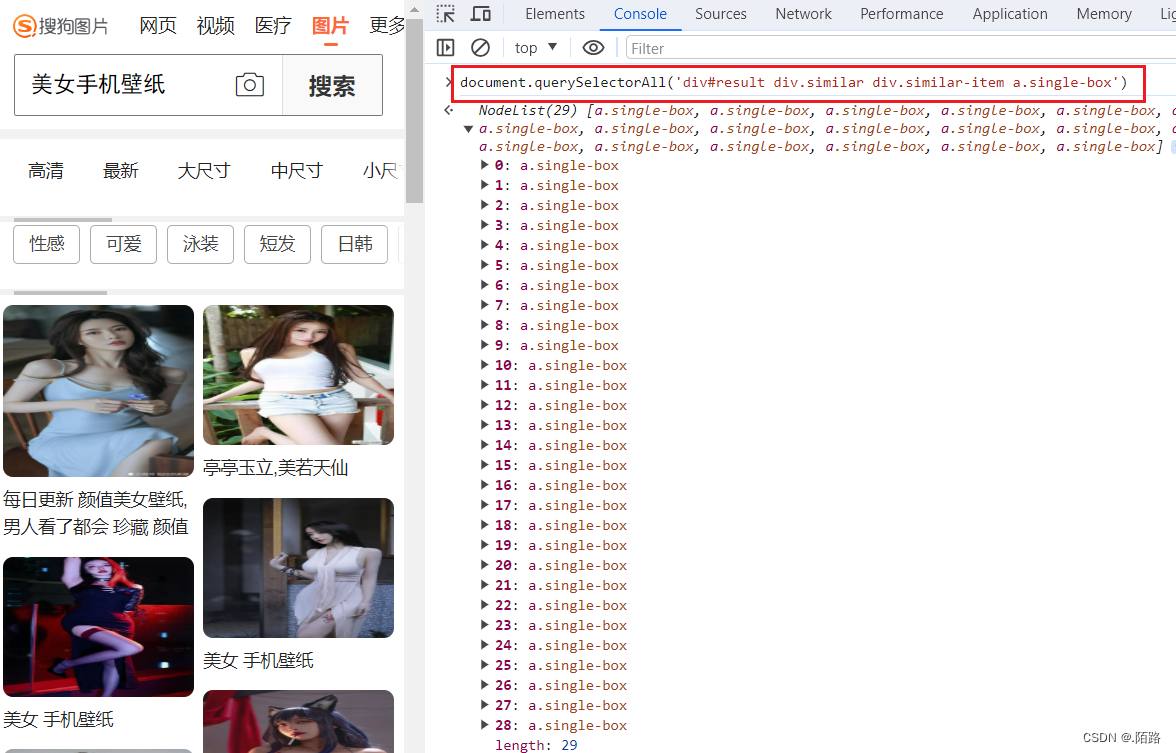
获取资源链接和标题:
- 对列表数据进行进一步解析,最终拿到想要的资源;
document.querySelector('xxx')提取资源标题和资源链接
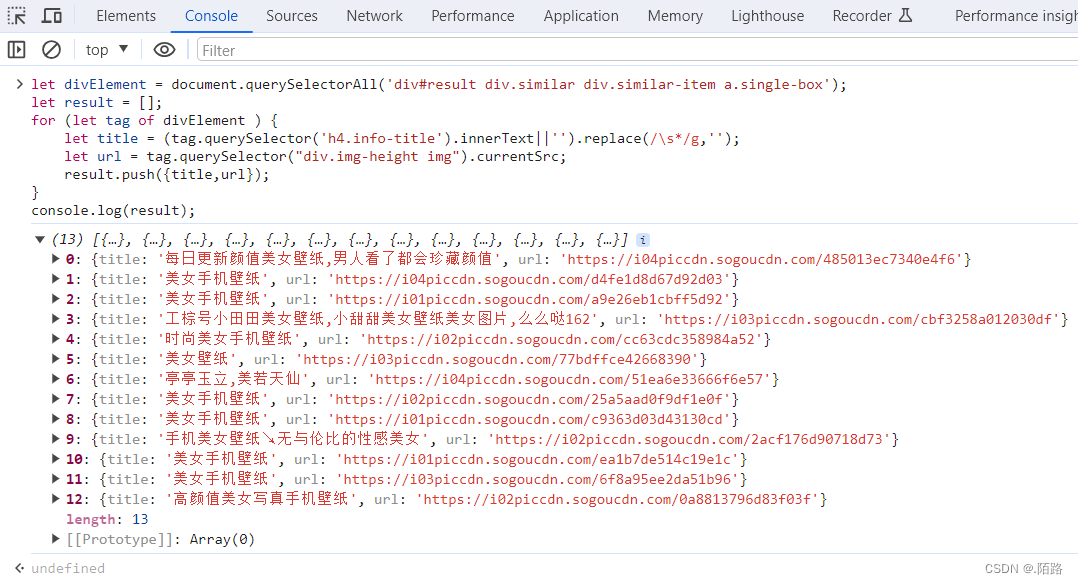
示例代码如下:
let divElement = document.querySelectorAll('div#result div.similar div.similar-item a.single-box'), result = [];
for (let tag of divElement ) {
let title = (tag.querySelector('h4.info-title').innerText||'').replace(/\s*/g,''); // 拿到标题,去除所有空格和特殊字符
let url = tag.querySelector("div.img-height img").currentSrc||''; // 拿到资源链接
result.push({title,url}); // 收集资源数据
}
console.log(result); // 打印资源列表
处理资源数据:
- 对资源数据进行处理,保存到数据库或是下载资源;
1.2、Java代码实现
按照以上思路,我们使用
Java代码来实现以上操作;页面地址:
https://pic.sogou.com/pic/searchList.jsp?from=homeHotSearch&rcer=&spver=0&keyword=美女壁纸#top=1395.199951171875&more=false
public static void main(String[] args) {
// 获取网页资源
Document document = Jsoup.parse(HttpUtil.get("https://pic.sogou.com/pic/searchList.jsp?from=homeHotSearch&rcer=&spver=0&keyword=美女壁纸#top=1395.199951171875&more=false", 15000));
// 只获取<body>标签中的元素
Element body = document.body();
// 使用css选择器提取所有资源,得到列表数据
Elements aElements = Optional.of(body.select("div#result"))
.orElseGet(Elements::new).select("div.similar div.similar-item a.single-box");
// 进一步解析,获取资源链接和标题,将资源收集成集合中
Set<JSONObject> result = aElements.stream().map(tag -> {
JSONObject resource = new JSONObject();
String title = tag.select("div.img-info h4.info-title").text();
String src = tag.select("div.img-height img").attr("src");
return resource.set("title", title).set("src", src);
}).filter(ObjUtil::isNotEmpty).collect(Collectors.toSet());
// 打印数据集
System.out.println(result);
System.out.println("共获取到:" + result.size() + "条数据");
}
1.3、爬取结果展示
[{"title":"每日更新 颜值美女壁纸,男人看了都会 珍藏 颜值","src":"https://i04piccdn.sogoucdn.com/485013ec7340e4f6"},
{"title":"美女 手机壁纸","src":"https://i02piccdn.sogoucdn.com/25a5aad0f9df1e0f"},
{"title":"美女 手机壁纸","src":"https://i04piccdn.sogoucdn.com/d4fe1d8d67d92d03"},
{"title":"美女 手机壁纸","src":"https://i01piccdn.sogoucdn.com/c9363d03d43130cd"},
{"title":"亭亭玉立,美若天仙","src":"https://i04piccdn.sogoucdn.com/51ea6e33666f6e57"}]
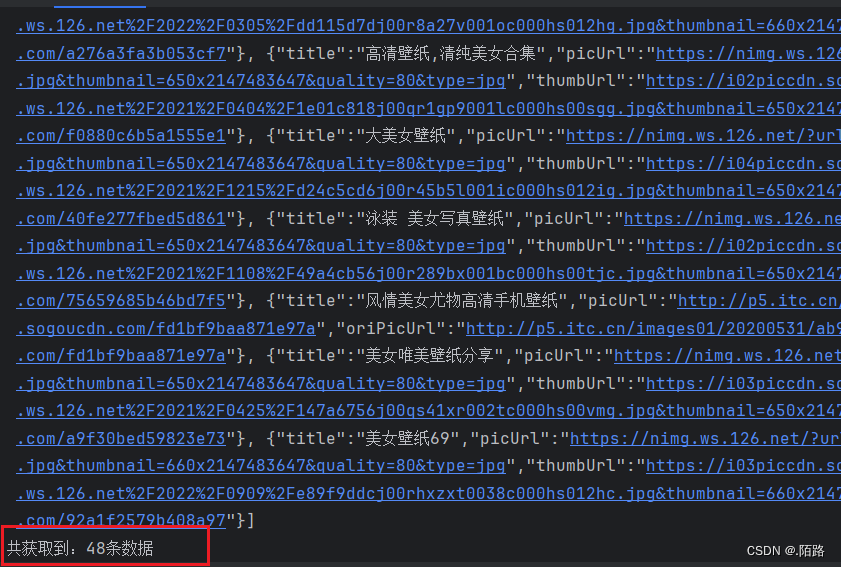
共获取到:5条数据
二、调用接口
2.1、过程与思路
分析网站资源得到资源接口:
- 需要分析资源网站,获取资源数据加载的时机和请求接口;
- 分析接口的请求参数,入参是否有加密,是否有请求限制;
- 测试接口,拿到结果,查看结果是否是自己所需要的资源;
- 处理资源数据,保存到数据库或者将资源文件下载到本地;
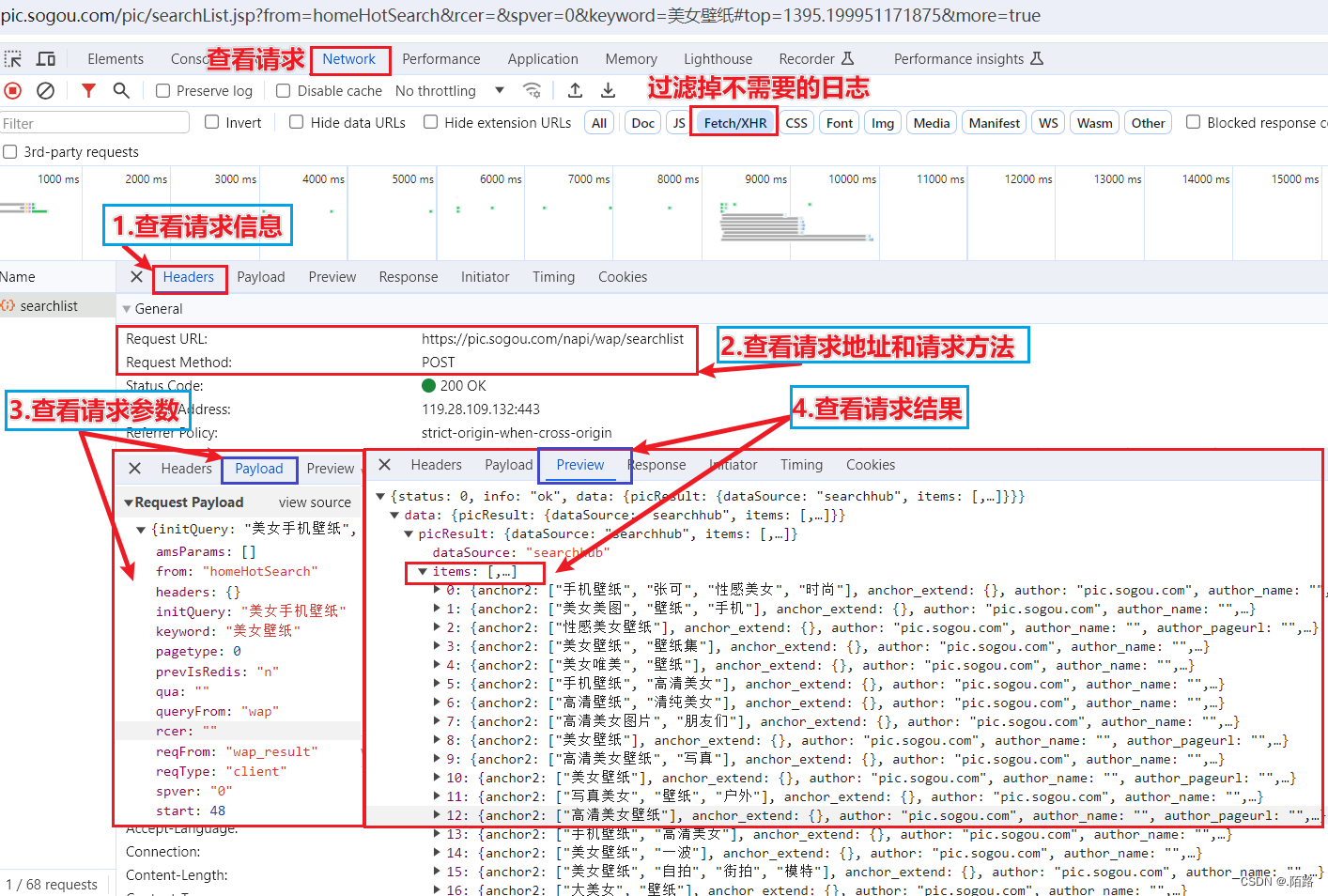
2.2、Java代码实现
按照上述,找到接口
https://pic.sogou.com/napi/wap/searchlist,拿到参数,直接发起POST请求,得到资源;
请求参数
{
"initQuery": "美女手机壁纸",
"queryFrom": "wap",
"from": "homeHotSearch",
"rcer": "",
"spver": "0",
"keyword": "美女壁纸",
"start": 48,
"reqType": "client",
"reqFrom": "wap_result",
"prevIsRedis": "n",
"qua": "",
"headers": {},
"pagetype": 0,
"amsParams": []
}
Java代码
接口地址:
https://pic.sogou.com/napi/wap/searchlist请求方式:
POST
public static void main(String[] args) {
// 查询接口
String postUrl = "https://pic.sogou.com/napi/wap/searchlist";
// 查询参数
String params = """
{
"initQuery": "美女手机壁纸",
"queryFrom": "wap",
"from": "homeHotSearch",
"rcer": "",
"spver": "0",
"keyword": "美女壁纸",
"start": 48,
"reqType": "client",
"reqFrom": "wap_result",
"prevIsRedis": "n",
"qua": "",
"headers": {},
"pagetype": 0,
"amsParams": []
}
""";
// 发起post请求,得到上图所述的结果数据
String json = HttpUtil.post(postUrl, params, 15000);
// 解析结果数据,拿到最终的资源节点
JSONArray jsonArray = JSONUtil.parseObj(json).getJSONObject("data").getJSONObject("picResult").getJSONArray("items");
// 进一步解析提取所需要的资源数据,排除不需要的数据,将资源收集成集合中
Set<JSONObject> result = jsonArray.stream().map(item -> {
JSONObject resource = new JSONObject();
if (item instanceof JSONObject jsonObject) {
String title = jsonObject.getStr("title"); // 资源标题
String picUrl = jsonObject.getStr("picUrl"); // 图片链接
String thumbUrl = jsonObject.getStr("thumbUrl"); // 缩略图链接
String oriPicUrl = jsonObject.getStr("oriPicUrl"); // 原图链接
String locImageLink = jsonObject.getStr("locImageLink"); // 原图链接
return resource.set("title", title).set("picUrl", picUrl)
.set("thumbUrl", thumbUrl).set("oriPicUrl", oriPicUrl)
.set("locImageLink", locImageLink);
}
return null;
}).filter(ObjUtil::isNotEmpty).collect(Collectors.toSet());
// 打印数据集
System.out.println(result);
System.out.println("共获取到:" + result.size() + "条数据");
}
2.3、爬取结果展示
三、缓存资源
3.1、过程与思路
- 页面加载后,我们下滑或者分页时,没有请求日志;
- 页面没有重新加载,但是数据在不断更新和加载中;
- 当超过一定数量时,会有一次的请求日志显示出来;
- 最后分析得到,数据是缓存到页面中的JS变量中了;
3.2、Java代码实现
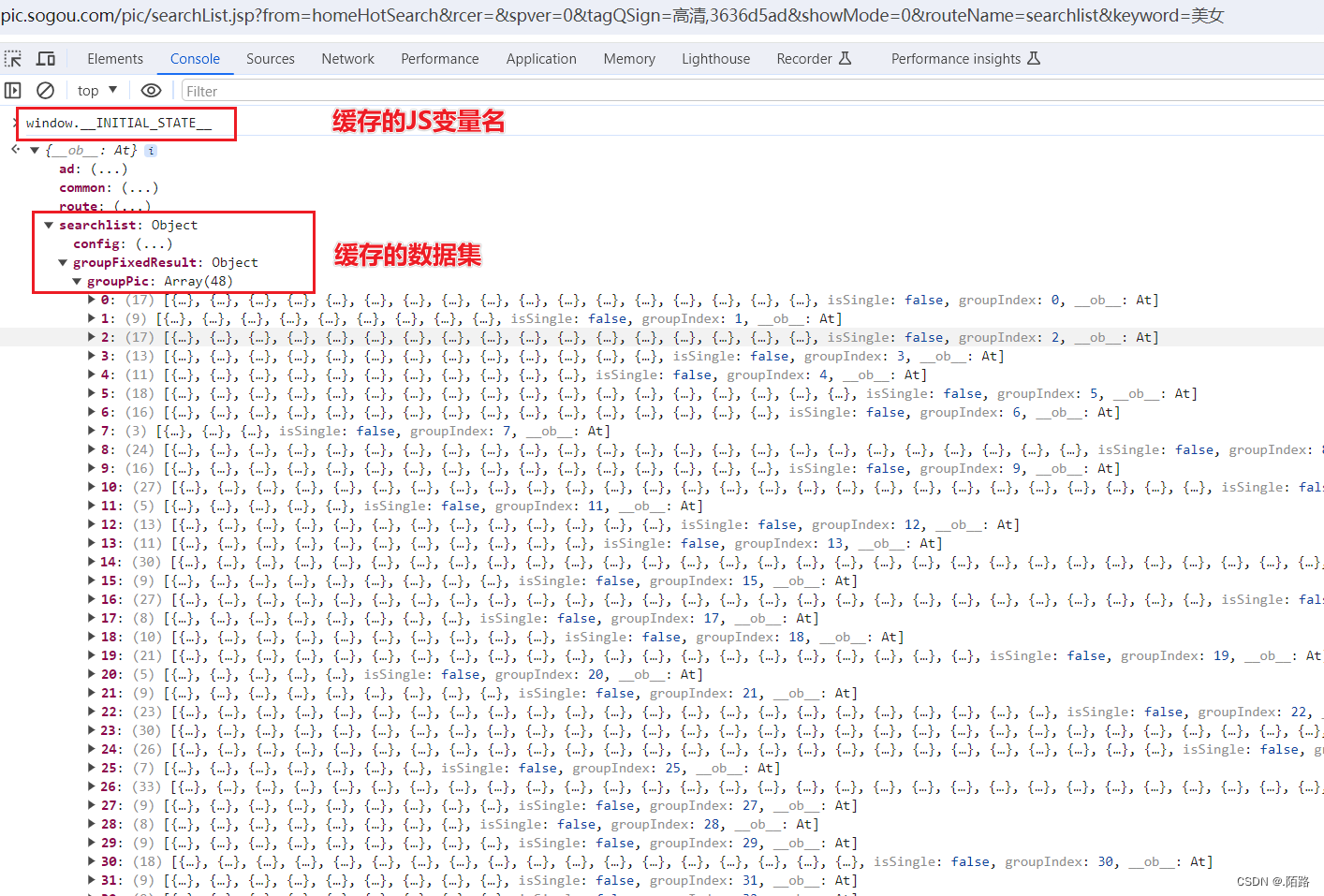
变量名:
window.__INITIAL_STATE__缓存中有很多数据,我们以
searchlist -> groupFixedResult -> groupPic中的数据为例,获取并解析里面的资源资源地址:
https://pic.sogou.com/pic/searchList.jsp?from=homeHotSearch&rcer=&spver=0&tagQSign=%E9%AB%98%E6%B8%85,3636d5ad&showMode=0&routeName=searchlist&keyword=美女
public static void main(String[] args) {
// 请求资源地址得到页面数据
Document document = Jsoup.parse(HttpUtil.get("https://pic.sogou.com/pic/searchList.jsp?from=homeHotSearch&rcer=&spver=0&tagQSign=%E9%AB%98%E6%B8%85,3636d5ad&showMode=0&routeName=searchlist&keyword=美女", 15000));
String variableName = "window.__INITIAL_STATE__";
// 解析得到所有的<script>
Elements scriptTags = document.getElementsByTag("script");
// 过滤得到包含'__INITIAL_STATE__'的<script>
List<String> collects = scriptTags.stream().map(Element::data)
.filter(data -> data.contains(variableName))
.filter(StrUtil::isNotEmpty)
.toList();
String scriptData = CollectionUtil.isEmpty(collects) ? "" : collects.get(0);
// 截取js中'__INITIAL_STATE__'变量内容
int startIndex = scriptData.indexOf("{");
int endIndex = scriptData.lastIndexOf("}");
// 得到js中'__INITIAL_STATE__'的json数据
String jsonData = scriptData.substring(startIndex, endIndex + 1);
// 将JS数据转为Java的JSON对象
JSONObject jsonObject = JSONUtil.parseObj(jsonData);
jsonObject = jsonObject.getJSONObject("searchlist");
jsonObject = jsonObject.getJSONObject("groupFixedResult");
JSONArray groupPicArray = jsonObject.getJSONArray("groupPic");
Set<Map<String, String>> list = new HashSet<>();
// 从JSON对象中提取资源数据
getSource(groupPicArray, list);
// 打印数据集
System.out.println(list);
System.out.println("共获取到:" + list.size() + "条数据");
}
/**
* 解析资源,获取资源数据
*
* @param jsonArray 资源数据集
* @param list 结果数据集
*/
private static void getSource(JSONArray jsonArray, Set<Map<String, String>> list) {
for (Object object : jsonArray) {
if (object instanceof JSONArray item) {
getSource(item, list);
}
if (object instanceof JSONObject item) {
var map = new HashMap<String, String>();
map.put("thumbUrl", item.getStr("thumbUrl"));
map.put("title", item.getStr("title"));
map.put("pageUrl", item.getStr("pageUrl"));
map.put("picUrl", item.getStr("picUrl"));
list.add(map);
}
}
}
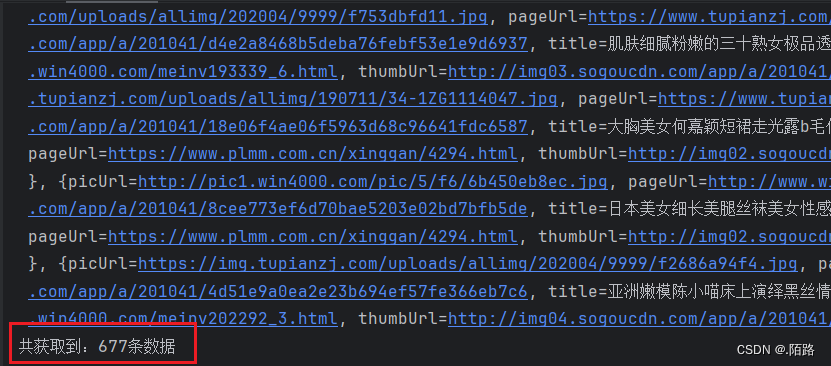
3.3、爬取结果展示
四、完整测试代码
import cn.hutool.core.collection.CollectionUtil;
import cn.hutool.core.util.ObjUtil;
import cn.hutool.core.util.StrUtil;
import cn.hutool.http.HttpUtil;
import cn.hutool.json.JSONArray;
import cn.hutool.json.JSONObject;
import cn.hutool.json.JSONUtil;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.util.*;
import java.util.stream.Collectors;
/**
* @author 陌路
* @apiNote 解析网页资源
* @date 2024/1/15 19:55
* @tool Created by IntelliJ IDEA
*/
public class GetWebResourceTest {
/**
* 通过解析网页获取资源
*/
public static void main(String[] args) {
// 获取网页资源
Document document = Jsoup.parse(HttpUtil.get("https://pic.sogou.com/pic/searchList.jsp?from=homeHotSearch&rcer=&spver=0&keyword=%E7%BE%8E%E5%A5%B3%E5%A3%81%E7%BA%B8#top=1395.199951171875&more=true", 15000));
// 只获取<body>标签中的元素
Element body = document.body();
// 使用css选择器提取所有资源,得到列表数据
Elements aElements = Optional.of(body.select("div#result"))
.orElseGet(Elements::new)
.select("div.similar div.similar-item a.single-box");
// 进一步解析,获取资源链接和标题,将资源收集成集合中
Set<JSONObject> result = aElements.stream().map(tag -> {
JSONObject resource = new JSONObject();
String title = tag.select("div.img-info h4.info-title").text();
String src = tag.select("div.img-height img").attr("src");
return resource.set("title", title).set("src", src);
}).filter(ObjUtil::isNotEmpty).collect(Collectors.toSet());
// 打印数据集
System.out.println(result);
System.out.println("共获取到:" + result.size() + "条数据");
}
/**
* 通过API接口获取资源
*/
public static void main1(String[] args) {
// 查询接口
String postUrl = "https://pic.sogou.com/napi/wap/searchlist";
// 查询参数
String params = """
{
"initQuery": "美女手机壁纸",
"queryFrom": "wap",
"from": "homeHotSearch",
"rcer": "",
"spver": "0",
"keyword": "美女壁纸",
"start": 48,
"reqType": "client",
"reqFrom": "wap_result",
"prevIsRedis": "n",
"qua": "",
"headers": {},
"pagetype": 0,
"amsParams": []
}
""";
// 发起post请求,得到上图所述的结果数据
String json = HttpUtil.post(postUrl, params, 15000);
// 解析结果数据,拿到最终的资源节点
JSONArray jsonArray = JSONUtil.parseObj(json).getJSONObject("data").getJSONObject("picResult").getJSONArray("items");
// 进一步解析提取所需要的资源数据,排除不需要的数据,将资源收集成集合中
Set<JSONObject> result = jsonArray.stream().map(item -> {
JSONObject resource = new JSONObject();
if (item instanceof JSONObject jsonObject) {
String title = jsonObject.getStr("title"); // 标题
String picUrl = jsonObject.getStr("picUrl"); // 图片链接
String thumbUrl = jsonObject.getStr("thumbUrl"); // 缩略图链接
String oriPicUrl = jsonObject.getStr("oriPicUrl"); // 原图链接
String locImageLink = jsonObject.getStr("locImageLink"); // 原图链接
return resource.set("title", title).set("picUrl", picUrl)
.set("thumbUrl", thumbUrl).set("oriPicUrl", oriPicUrl)
.set("locImageLink", locImageLink);
}
return null;
}).filter(ObjUtil::isNotEmpty).collect(Collectors.toSet());
// 打印数据集
System.out.println(result);
System.out.println("共获取到:" + result.size() + "条数据");
}
/**
* 通过js获取数据资源
*/
public static void main2(String[] args) {
// 请求资源地址得到页面数据
Document document = Jsoup.parse(HttpUtil.get("https://pic.sogou.com/pic/searchList.jsp?from=homeHotSearch&rcer=&spver=0&tagQSign=%E9%AB%98%E6%B8%85,3636d5ad&showMode=0&routeName=searchlist&keyword=美女", 15000));
String variableName = "window.__INITIAL_STATE__";
// 解析得到所有的<script>
Elements scriptTags = document.getElementsByTag("script");
// 过滤得到包含'__INITIAL_STATE__'的<script>
List<String> collects = scriptTags.stream().map(Element::data)
.filter(data -> data.contains(variableName))
.filter(StrUtil::isNotEmpty)
.toList();
String scriptData = CollectionUtil.isEmpty(collects) ? "" : collects.get(0);
// 截取js中'__INITIAL_STATE__'变量内容
int startIndex = scriptData.indexOf("{");
int endIndex = scriptData.lastIndexOf("}");
// 得到js中'__INITIAL_STATE__'的json数据
String jsonData = scriptData.substring(startIndex, endIndex + 1);
// 将JS数据转为Java的JSON对象
JSONObject jsonObject = JSONUtil.parseObj(jsonData);
jsonObject = jsonObject.getJSONObject("searchlist");
jsonObject = jsonObject.getJSONObject("groupFixedResult");
JSONArray groupPicArray = jsonObject.getJSONArray("groupPic");
Set<Map<String, String>> list = new HashSet<>();
// 从JSON对象中提取资源数据
getSource(groupPicArray, list);
// 打印数据集
System.out.println(list);
System.out.println("共获取到:" + list.size() + "条数据");
}
/**
* 解析资源,获取资源数据
*
* @param jsonArray 资源数据集
* @param list 结果数据集
*/
private static void getSource(JSONArray jsonArray, Set<Map<String, String>> list) {
for (Object object : jsonArray) {
if (object instanceof JSONArray item) {
getSource(item, list);
}
if (object instanceof JSONObject item) {
var map = new HashMap<String, String>();
map.put("thumbUrl", item.getStr("thumbUrl"));
map.put("title", item.getStr("title"));
map.put("pageUrl", item.getStr("pageUrl"));
map.put("picUrl", item.getStr("picUrl"));
list.add(map);
}
}
}
}
五、下载资源
5.1、过程与思路
本案例仅以获取并解析JS资源为例来下载资源
下载图片资源,并将资源列表以
json格式写入到本地(存入到数据库也可以,这里只写入到文件)
- 根据上述代码,将获取到的数据资源下载到本地;
- 将所有收集到的资源写入到文件中,方便于查看;
5.2、操作文件工具类
import cn.hutool.core.date.DatePattern;
import cn.hutool.core.date.DateTime;
import cn.hutool.core.util.StrUtil;
import cn.hutool.crypto.digest.MD5;
import cn.hutool.http.HttpUtil;
import cn.hutool.json.JSONUtil;
import lombok.extern.slf4j.Slf4j;
import java.io.File;
import java.io.FileWriter;
import java.nio.charset.StandardCharsets;
import java.util.Collection;
import java.util.Map;
/**
* @author 陌路
* @apiNote 操作文件工具类
* @date 2024/1/16 12:10
* @tool Created by IntelliJ IDEA
*/
@Slf4j
public class FileUtil {
/**
* 文件保存路径地址(修改为自己的地址)
*/
public static final String FILE_PATH = "D:/Code/picture/sougou/";
/**
* 写入文件
*
* @param pathName 文件路径
* @param suffix 文件类型,后缀名
* @param data 数据集
*/
public static void write(String pathName, String suffix, String data) {
File file = new File(pathName + suffix);
try (FileWriter writer = new FileWriter(file)) {
writer.write(JSONUtil.toJsonStr(data));
writer.flush();
} catch (Exception e) {
log.error("写入数据出错了:" + e.getMessage(), e);
}
}
/**
* 获取文件路径
*
* @param filePath 文件路径
* @return 文件路径
*/
public static String getFilePath(String filePath) {
filePath = StrUtil.isBlank(filePath) ? "" : filePath + "/";
DateTime dateTime = new DateTime();
String currentDate = dateTime.toString(DatePattern.NORM_DATE_PATTERN);
return FILE_PATH + filePath + currentDate + "/";
}
/**
* 获取文件名
*
* @param title 标题
* @return 文件名
*/
public static String getFileName(String title) {
return StrUtil.isBlank(title) ? "" : MD5.create().digestHex(title, StandardCharsets.UTF_8);
}
/**
* 下载文件
*
* @param url 文件地址
* @param filePath 文件路径
* @param fileName 文件名
* @param picUrl 图片地址
*/
@SuppressWarnings("all")
public static void downloadFile(String url, String filePath, String fileName, String picUrl, boolean isDownload) {
fileName = FileUtil.getFileName(fileName);
File file = new File(filePath + "/" + fileName + ".jpg");
try {
if (!file.exists()) {
file.getParentFile().mkdirs();
file.createNewFile();
}
HttpUtil.downloadFile(url, file, 5000);
} catch (Exception e) {
if (!isDownload) {
downloadFile(picUrl, filePath, fileName, picUrl, true);
}
log.error("下载文件出错:" + e.getMessage(), e);
}
}
/**
* 下载文件
*
* @param filePath 文件路径
* @param list 数据集
*/
public static void downloadFile(String filePath, Collection<Map<String, String>> list) {
list.forEach(item -> FileUtil.downloadFile(item.get("thumbUrl"), filePath, item.get("title") + item.get("picUrl"), item.get("picUrl"), false));
}
}
5.3、资源下载实现类
本案例仅以获取
JS中的资源实现下载
/**
* 解析html
* @param keyword 搜索关键字
* @return 爬取结果
*/
public Set<Map<String, String>> parseHtmlByKeyword(String keyword) {
Document document = Jsoup.parse(HttpUtil.get(UrlConstant.APP_BASE_URL + keyword, 15000));
String variableName = "window.__INITIAL_STATE__";
String scriptData = getJsonByScript(document.getElementsByTag("script"), variableName);
int startIndex = scriptData.indexOf("{");
int endIndex = scriptData.lastIndexOf("}");
String jsonData = scriptData.substring(startIndex, endIndex + 1);
JSONObject jsonObject = JSONUtil.parseObj(jsonData);
jsonObject = jsonObject.getJSONObject("searchlist");
jsonObject = jsonObject.getJSONObject("groupFixedResult");
JSONArray groupPicArray = jsonObject.getJSONArray("groupPic");
Set<Map<String, String>> list = new HashSet<>();
getSource(groupPicArray, list);
String filePath = FileUtil.getFilePath(keyword);
// 资源数量小于100,直接下载,否则使用多线程下载
long start = System.currentTimeMillis();
// 是否使用多线程下载,资源数量>100的时候使用多线程
if (list.size() < 100) {
list.forEach(item -> FileUtil.downloadFile(item.get("thumbUrl"), filePath, item.get("title") + item.get("picUrl"), item.get("picUrl"), false));
} else {
multiThreaded(new ArrayList<>(list), keyword); // 多线程下载
}
long time = System.currentTimeMillis()- start;
// 打印下载资源所耗时长
log.info("共耗时:{}ms、{}s、{}m", time, (time / 1000), ((time / 1000) / 60));
// 将资源数据写入到source.json文件中
FileUtil.write(filePath + "/source", ".json", JSONUtil.toJsonStr(list));
return list;
}
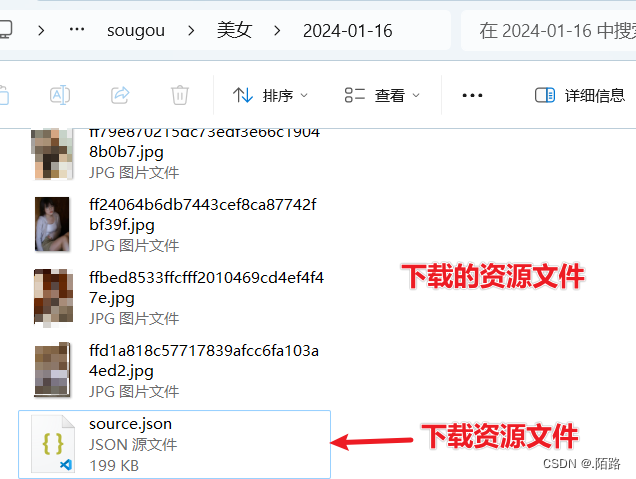
5.4、下载结果展示
5.5、调用示例
/**
* @author 陌路
* @apiNote 解析网页资源控制器
* @date 2024/1/16 15:36
* @tool Created by IntelliJ IDEA
*/
@RestController
@RequiredArgsConstructor
@RequestMapping("/api/v1/parseHtml")
public class ParseHtmlController {
private final ParseHtmlService parseHtmlService;
/**
* 根据关键字爬取数据
*
* @param keyword 搜索关键字
* @return 结果集
*/
@GetMapping("/query/{keyword}")
public ResultVo<Collection<Map<String, String>>> parseHtml(@PathVariable String keyword) {
if (StrUtil.isBlank(keyword)) return ResultVo.fail("请输入搜索关键字!");
return ResultVo.ok(parseHtmlService.parseHtmlByKeyword(keyword));
}
}
六、完整代码
完整代码:
https://gitee.com/mmolu/open-source/tree/master/jsoup
七、说明
本实例仅学习供参考使用
请勿用来牟利或非法使用
本示例仅供学习参考,请勿用来牟利或非法使用!
本示例仅供学习参考,请勿用来牟利或非法使用!
本示例仅供学习参考,请勿用来牟利或非法使用!
更多技术分享请关注:.陌路-CSDN博客
创作不易,采集、转发请注明出处:https://blog.csdn.net/qq_51076413?type=blog
.














 844
844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









