






预览(可以根据循环次数爬取大量图片)

一、网页分析
1
点击F12进入检查,将小箭头移到网页中随便一张图片上
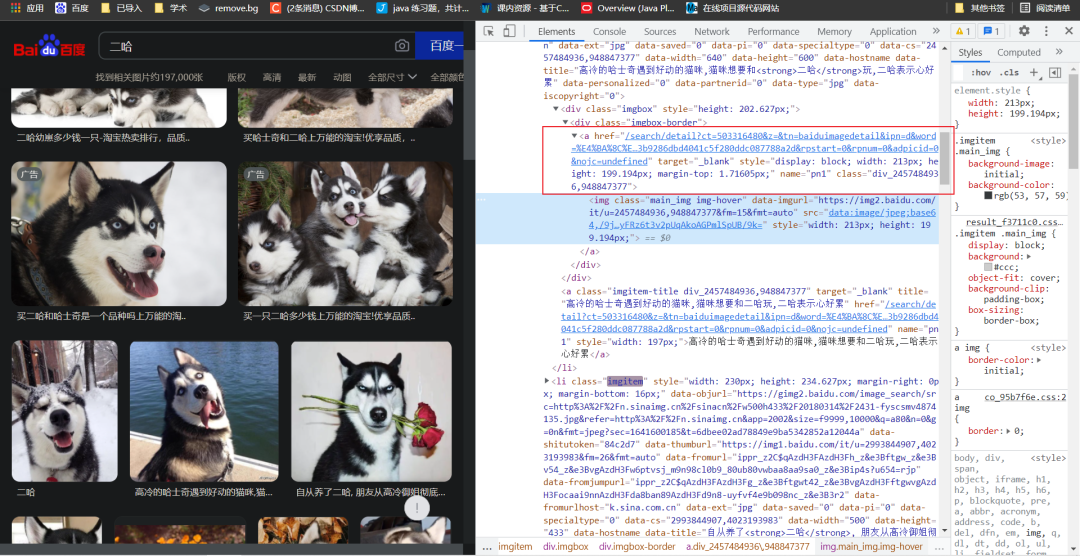
2
进一步我们可以发现每一张图片的链接都包含在<ul>标签的子标签<li>中
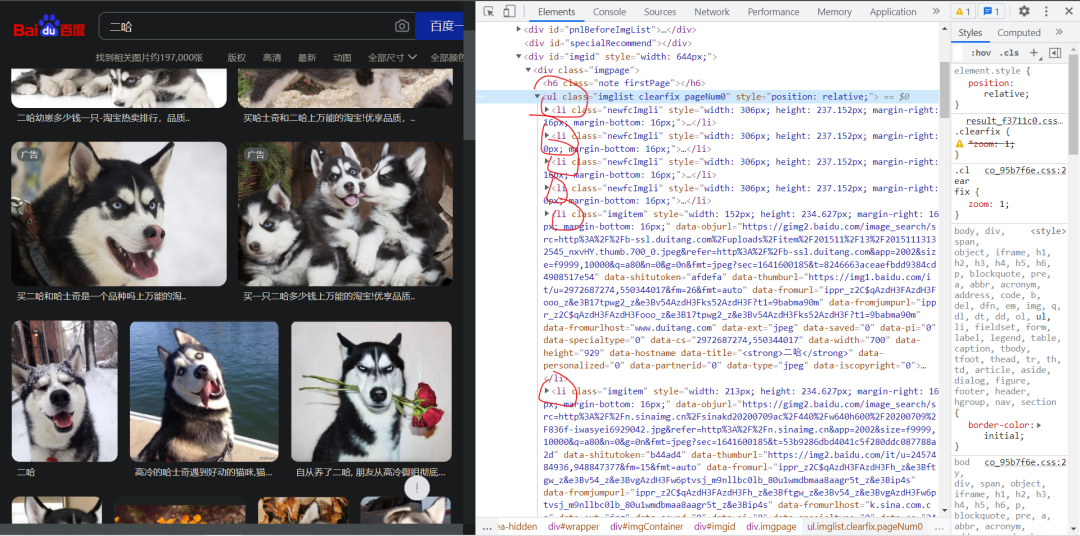
3
图片的url也可以在<li>中获得,但是在这里获得到的图片url并不是高清的,图中二哈的图片仅有30kb
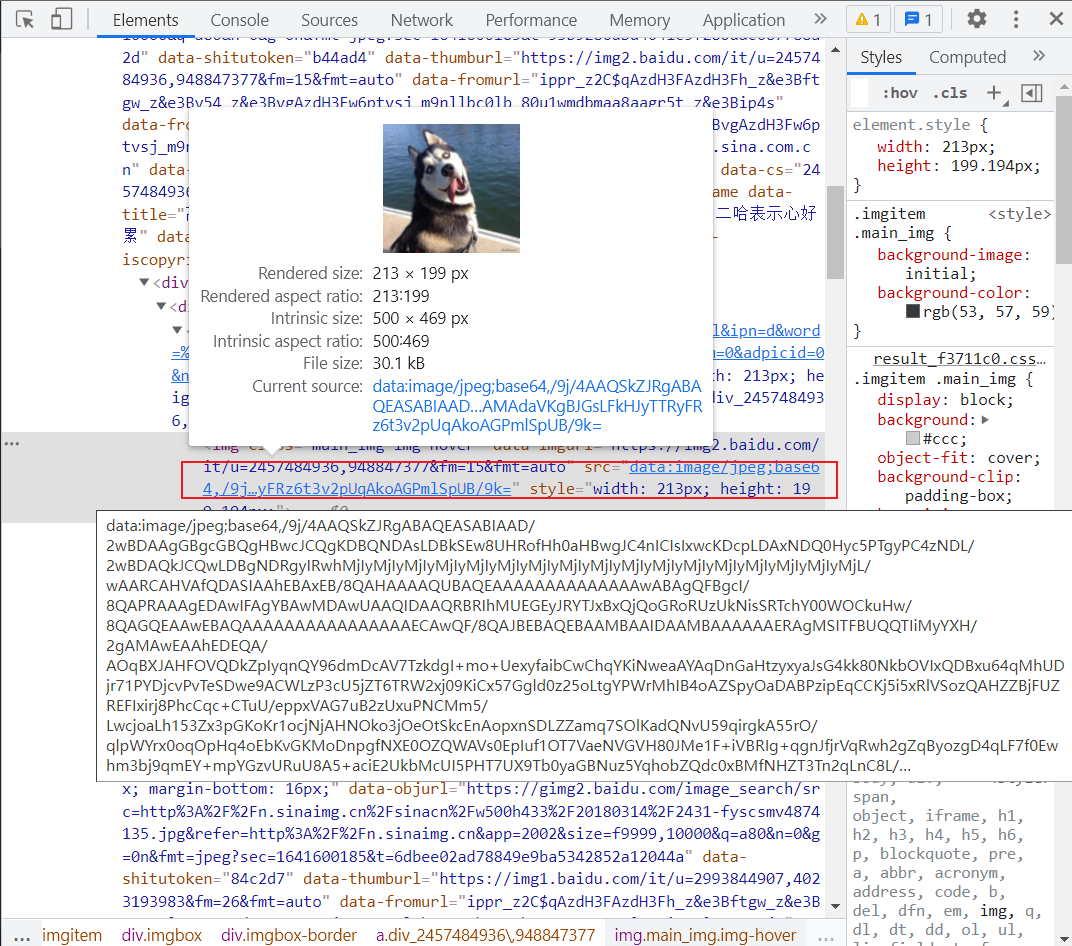
4
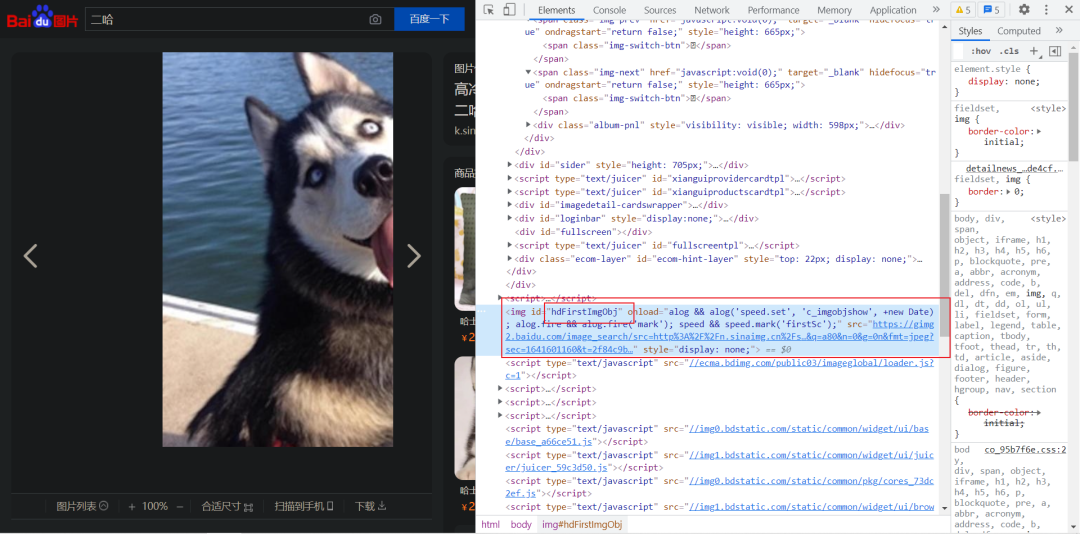
所以再进一步在<div class = "imgbox-border">中找到<a href = "····">该链接能获取高清版本的图片,点击进入该图片的详情页面,可以找到一<a id = "hdFirstImgObj">标签,其中src后边的链接就是高清版本的图片。
5、总结
网页分析中我们要获得两个url,第一个是在百度图片首页上找到<div class = "imgbox-border">中<a>标签href后边的链接;第二个是进入第一个链接后找到<a id = "hdFirstImgObj">标签,获取src后的链接,即图片的高清版本的链接。
二、selenium导入&添加驱动
1、通过maven
<!-- https://mvnrepository.com/artifact/org.seleniumhq.selenium/selenium-java --> <dependency> <groupId>org.seleniumhq.selenium</groupId> <artifactId>selenium-java</artifactId> <version>3.141.59</version> </dependency>
2、通过jar包直接导入
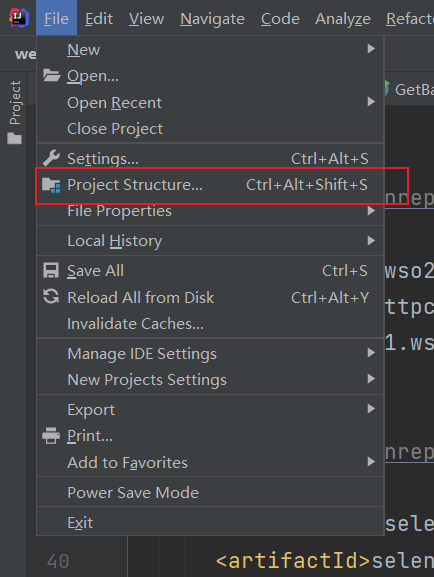
到selenium官网下载想要使用的版本(我用的是3.141.59),然后打开idea,点开File,找到Project Structure点击
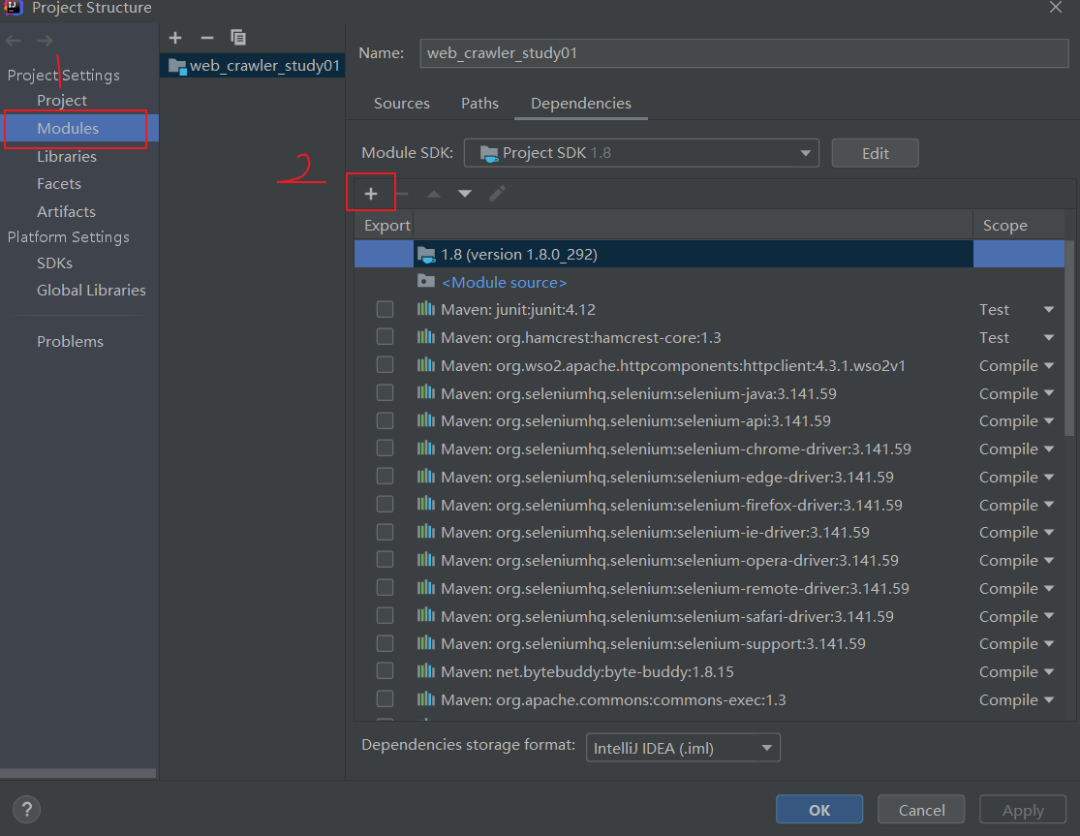
将刚刚下载的selenium jar 包直接添加上就OK了。
3、添加驱动
我们需要下载selenium和浏览器及对应浏览器驱动,下面以下载chrome和chromedriver为例。
谷歌浏览器驱动安装:https://npm.taobao.org/mirrors/chromedriver?spm=a2c6h.14029880.0.0.735975d7jW7LC2
安装版本与自己浏览器对应的版本要一样,下载目录一般是与浏览器的相同目录下。
三、最喜欢的编程阶段
1、两个重要的集合
首先要声明两个List集合用来保存我们从网页上获取到的两个url
//保存第一层链接,称外部链接 private List<String> outUrlList ; //保存图片链接 private List<String> picUrlList;
2、利用selenium自动化搜索某类型图片
以二哈为例
/**
* 获取外部的链接
* @param url 百度图片首页
* @param word 图片关键词
* @throws Exception
*/
public void getOutUrl(String url,String word) throws Exception{
//设置不显示浏览器页面
ChromeOptions chromeOptions=new ChromeOptions();
chromeOptions.addArguments("-headless");
//创建浏览器驱动对象
WebDriver driver = new ChromeDriver(chromeOptions);
driver.manage().window().maximize();
driver.get(url);
driver.findElement(By.id("kw")).sendKeys(word);//word在这就能设置成“二哈”。
driver.findElement(By.className("s_btn_wr")).click();
····
//最后要将浏览器驱动退出
driver.quit();
}
3、获取外部链接
找到网页上所有<div class = "imgbox-border">,直接获取我们想要图片详情页
//返回一个webElement的List集合
List<WebElement> webEList = driver.findElements(By.className("imgbox-border"));
//通过该元素集合进行foreach循环找到<a>标签,添加href到outUrlList集合中
for(WebElement outUrl : webList){
String furtherUrl = outUrl.fingElement(By.tagName("a")).getAttribute("href");
outUrlList.add(furtherUrl);
}
这样一来我们就将网页上出现的所有图片详情页获得到了
3、获取高清图片url
/**
* 通过获取到的图片详情页面URL得到图片的URL
* @param outUrlList
*/
public void getPicUrl(List<String> outUrlList){
//设置不显示浏览器页面
ChromeOptions chromeOptions=new ChromeOptions();
chromeOptions.addArguments("-headless");
WebDriver driver = new ChromeDriver(chromeOptions);
//通过for循环将外部链接自动化打开,然后找到我们要的元素(高清图片链接),添加到picUrlList中
for (i = 0;i<outUrlList.size();i++) {
String picDetail = outUrlList.get(i);
String picUrl = "";
driver.get(picDetail);
picUrl = driver.findElement(By.id("hdFirstImgObj")).getAttribute("src");
picUrlList.add(picUrl);
}
driver.quit();
}
4、下载图片
这个阶段还要用到IO流和网络编程的知识,不过很简单。
/**
* 下载图片到硬盘
* @param picUrlList 图片链接的集合
* @param picSrc的保存路径
*/
public void downtown(List<String> picUrlList,String picSrc){
//设置图片排号
int i = 0;
//判断picSrc存不存在,不存在接得先建立
File file = new File(picSrc);
if(!file.exists()){
file.mkdirs();
}
//输入输出流
InputStream in = null;
FileOutputStream fos = null;
//循环下载
for(String picUrl : picUrlList){
try{
//一般下载图片的流程是这样固定不变的,比较简单
System.out.println("正在下载:"+picUrl);
byte[] bytes = new byte[1024];
in = new URL(picUrl).openConnection().getInputStream();
fos = new FileOutputStream(path+"\\"+i+++".jpg");
int readLine = 0;
while ((readLine = in.read(bytes))!=-1){
fos.write(bytes,0,readLine);
}
System.out.println("第" + i + "张图片下载完成");
}catch(Exception e){
e.printStackTrace();
}finally{
//最后要记得关闭输入输出流
try {
fos.flush();
} catch (IOException e) {
e.printStackTrace();
}
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
四、编程过程中我遇到的问题
1、图片不够多
由于selenium这个框架是实时地模仿浏览器操作的,百度图片加载的时候是一种ajax机制(局部刷新),所以我在获取第一个链接的时候会加上这么一段代码,用来获取更多的图片。
//每隔0.5秒模仿浏览器滚动上下进度条,让程序能够加载网页
Thread.sleep(400);
for (int i = 0; i <8 ; i++) {
((JavascriptExecutor) driver).executeScript("window.scrollTo(0.5,document.body.scrollHeight)");
Thread.sleep(500);
}
Thread.sleep(1000);
2、总是抛no such element 异常
这个异常其实也很容易找到原因,点开百度图片的首页就能知道了
一般查询的图片,前边几张都是广告,那就没有我们要的元素在它的<div>中,如下图所示,<dic>标签中是空的

然而selenium框架并没有可以判断元素是否存在的方法,我们就得自己写
//判断元素是否存在方法,用浏览器驱动查找
public Boolean isElemExist(WebDriver driver,By seletor) {
try {
driver.findElement(seletor);
return true;
} catch (Exception e) {
// TODO: handle exception
return false;
}
}
//方法重写,用元素查找
public Boolean isElemExist(WebElement element,By seletor) {
try {
element.findElement(seletor);
return true;
} catch (Exception e) {
// TODO: handle exception
return false;
}
}
方法调用实例:
//在获取外部元素时调用,如果没有含<a>标签的元素就跳过
for (WebElement outUrl : webEList) {
if(isElemExist(outUrl,By.cssSelector(".imgbox-border>a"))){
String furtherUrl = outUrl.findElement(By.tagName("a")).getAttribute("href");
outUrlList.add(furtherUrl);
}else{
continue;
}
}
//在获取高清图片链接时调用,没有高清版本链接就跳过。
····
if(isElemExist(driver,By.id("hdFirstImgObj"))){
picUrl = driver.findElement(By.id("hdFirstImgObj")).getAttribute("src");
}
else{
continue;
}
····
五、总结
源码:
package indi.pic_clawer;
import org.openqa.selenium.By;
import org.openqa.selenium.JavascriptExecutor;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
public class AutoGetBaiDuPicTest {
//保存第一层链接
List<String> outUrlList ;
//保存图片链接
List<String> picUrlList;
public AutoGetBaiDuPicTest(){
outUrlList = new ArrayList<>();
picUrlList = new ArrayList<>();
}
/**
* 获取外部的链接
* @param url 百度图片首页
* @param word 图片关键词
* @throws Exception
*/
public void getOutUrl(String url,String word) throws Exception{
//设置不显示浏览器页面
ChromeOptions chromeOptions=new ChromeOptions();
chromeOptions.addArguments("-headless");
WebDriver driver = new ChromeDriver(chromeOptions);
driver.manage().window().maximize();
driver.get(url);
driver.findElement(By.id("kw")).sendKeys(word);
driver.findElement(By.className("s_btn_wr")).click();
Thread.sleep(400);
for (int i = 0; i <8 ; i++) {
((JavascriptExecutor) driver).executeScript("window.scrollTo(0.5,document.body.scrollHeight)");
Thread.sleep(500);
}
Thread.sleep(1000);
List<WebElement> webEList = driver.findElements(By.className("imgbox-border"));
for (WebElement outUrl : webEList) {
if(isElemExist(outUrl,By.cssSelector(".imgbox-border>a"))){
String furtherUrl = outUrl.findElement(By.tagName("a")).getAttribute("href");
outUrlList.add(furtherUrl);
}else{
continue;
}
}
driver.quit();
}
/**
* 通过获取到的图片详情页面URL得到图片的URL然后下载
* @param outUrlList 外部链接
* @param word 图片关键词
*/
public void getPicUrl1(List<String> outUrlList,String word){
int i ;
String path = "D:\\program study\\爬虫\\BaiDuPic\\"+word;
File file = new File(path);
if(!file.exists()){
file.mkdirs();
}
InputStream in = null;
FileOutputStream fos = null;
//设置不显示浏览器页面
ChromeOptions chromeOptions=new ChromeOptions();
chromeOptions.addArguments("-headless");
WebDriver driver = new ChromeDriver(chromeOptions);
for (i = 0;i<outUrlList.size();i++) {
String picDetail = outUrlList.get(i);
String picUrl = "";
driver.get(picDetail);
if(isElemExist(driver,By.id("hdFirstImgObj"))){
picUrl = driver.findElement(By.id("hdFirstImgObj")).getAttribute("src");
}
else{
continue;
}
// picUrlList.add(driver.findElement(By.id("hdFirstImgObj")).getAttribute("src"));
// System.out.println(driver.findElement(By.id("hdFirstImgObj")).getAttribute("src"));
try{
System.out.println("正在下载:"+picUrl);
byte[] bytes = new byte[1024];
in = new URL(picUrl).openConnection().getInputStream();
fos = new FileOutputStream(path+"\\"+i+".jpg");
int readLine = 0;
while ((readLine = in.read(bytes))!=-1){
fos.write(bytes,0,readLine);
}
System.out.println("第" + i + "张图片下载完成");
} catch(Exception e){
// e.printStackTrace();
System.out.println("第" + i + "张图片下载失败");
continue;
} finally{
try {
fos.flush();
} catch (IOException e) {
e.printStackTrace();
}
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
driver.quit();
}
//判断元素是否存在方法
public Boolean isElemExist(WebDriver driver,By seletor) {
try {
driver.findElement(seletor);
return true;
} catch (Exception e) {
// TODO: handle exception
return false;
}
}
//方法重写
public Boolean isElemExist(WebElement element,By seletor) {
try {
element.findElement(seletor);
return true;
} catch (Exception e) {
// TODO: handle exception
return false;
}
}
public static void main(String[] args) {
long startTime = System.currentTimeMillis(); //获取开始时间
String url = "https://image.baidu.com/";
AutoGetBaiDuPicTest a = new AutoGetBaiDuPicTest();
try{
System.out.println("请输入图片关键字");
String word = new Scanner(System.in).next();
a.getOutUrl(url,word);
a.getPicUrl1(a.outUrlList,word);
}catch(Exception e){
e.printStackTrace();
}
long endTime = System.currentTimeMillis(); //获取开始时间
System.out.println("程序运行时间为"+(endTime-startTime)/1000+"秒");
}
}














 686
686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









