







- Mybatis大致使用流程
- xml常用标签符号解析
- 执行流程和Mapper代理
- Mybatis一二级缓存
- Mybatis-plus逆向工程代码生成
- Mybatis-plus基本使用方法
- MP快捷带来的方法
- 条件构造器和区别
- MP主键生成策略
- MP逻辑删除
- MP字段自动填充
- MP乐观锁
- MP分页
更多内容见:全球顶级java开发面试宝典
Mybatis大致使用流程
- 导入对应包。(mybatis-plus也是)
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.2.2</version>
</dependency>
- 编写对应配置文件。(普通项目在mybatis-config.xml中配置)
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: 123456
url: jdbc:mysql://localhost:3306/mybatis?userUnicode=true&characterEncoding=utf-8
mybatis:
type-aliases-package: com.xin.pojo #对包下pojo起别名
mapper-locations: classpath:mybatis/mapper/*.xml #注册mapper的xml地址
@MapperScan后指定mapper包下接口可以不使用@Mapper注解。
- 对一个pojo类创建一个xxxMapper接口,在classpath下建立一个放xxxMapper.xml的包来写其sql和配置,大致结构如下:
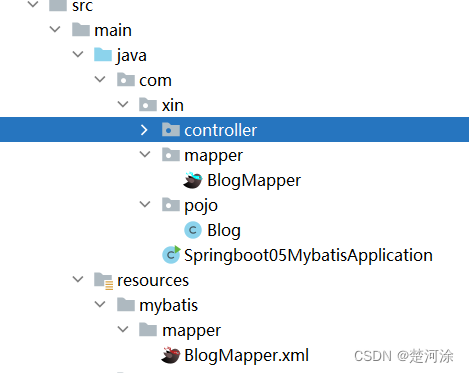
- 在xxxMapper.xml中编写对应接口方法的sql,返回正确的结果。或者在接口上使用注解进行sql处理但复杂sql无法处理。
xml常用标签符号解析
id,parameterType,resultType,#{},${}
<select id="getUserById" parameterType="_int" resultType="com.xin.pojo.User"><!--只有一个参数可以不写parameterType="int"-->
select * from mybatis.user where id=#{id}
</select> <!-- #{} ${}都行,#{}预编译防止SQL注入-->
id指定实现的的接口方法。
parameterType指定参数类型,可以使基本数据类型如int,也可以是其他数据结构如map,或其他对象如java.lang.Integer。
#{}和${}都可以从方法参数中取得值,且mapper接口方法参数尽量用@Param指定参数名,使用时可以直接解构对象。#{}在处理数据时会进行预编译,屏蔽掉关键字和防止SQL注入,因此在想传递关键字时使用${}进行直接替换,传递数据时使用#{}更加安全。
resultType指定返回的结果集类型,结果集为List则指定List中的泛型对象,结果集为Map则指定为java中的Map。
resultMap,type,column,property
<resultMap id="UserMap" type="com.xin.pojo.User">
<!-- 数据库中的列 映射类的属性 -->
<result column="name" property="name"/> <!--同名的不会出错,不需映射-->
<result column="pwd" property="password"/>
</resultMap>
<select id="getUserById" parameterType="int" resultMap="UserMap">
select * from mybatis.user where id=#{id}
</select> <!-- 或者查出来的结果修改别名as什么,查出来的数据列名就是什么,名字一样就可以映射到User的属性中-->
resultMap为对查询返回的结果进行与其他类的映射,防止数据库列名与实体类名不对应,或者需要处理的其他情况。
type在resultMap中表示映射到的结果集类型。
column,property分别表示数据库中的列名和对应类中的属性名。
foreach,item,collection,open,separator,close
<select id="queryBlogForeach" parameterType="map" resultType="com.xin.pojo.Blog">
select * from mybatis.blog
<where> <!--集合名,不是取值-->
<foreach index="key" item="value" collection="map.entrySet()" open="(" separator="or" close=")">
id=#{key},id=#{value}
</foreach>
</where>
</select>
foreach为循环处理拼接标签,可进行批量处理。
item为类似for i in list中的i,用来迭代取值的变量。
collect为传入的参数结构类型如map、list、array,也可用@Param指定参数名。参数类型为map时需要传入要遍历哪个map的东西,如collection=“map.entrySet()”,使用index=“key” item="value"来指定key,value进行取值。
open,separator,close分别为在拼接时整个前面使用什么符号开始,每次拼接用什么连接,整个拼接结束用什么符号结束。
association 一对一处理
一对一处理为一个pojo类中中存在一个其他pojo类。
处理方式为嵌套查询和嵌套结果。
嵌套查询为在resultMap中映射时对集合那一列进行额外的再次查询。嵌套结果为将所有结果查出来进行一一映射。
<resultMap id="student" type="com.xin.pojo.Student" >
<result property="id" column="id"/>
<result property="name" column="name"/>
<!-- 联合映射,属性为teacher,teacher属性类型为java类类型(不是varchar啊啥的),再用getTeacher的select方法查询出来映射到teacher上 ,查询参数对应为student表里的tid(外键)-->
<association property="teacher" javaType="com.xin.pojo.Teacher" select="getTeacher" column="tid"/>
</resultMap>
<select id="getStudent" resultMap="student" >
select * from mybatis.student
</select>
<select id="getTeacher" resultType="com.xin.pojo.Teacher"><!-- id会自动匹配,但不建议随意写 -->
select * from mybatis.teacher where id=#{tid}
</select>
<!--嵌套查询-->
<!--//-->
<!--嵌套结果-->
<resultMap id="Student2" type="com.xin.pojo.Student">
<result property="id" column="sid"/>
<result property="name" column="sname"/>
<association property="teacher" javaType="com.xin.pojo.Teacher">
<result property="name" column="tname"/> <!--别名注意区分-->
</association>
</resultMap>
<select id="getStudent2" resultMap="Student2">
select student.id sid,student.name sname,teacher.name tname
from student,teacher
where student.tid=teacher.id
</select>
collection 一对多处理
一对多处理为一个pojo对象中存在一个集合,集合中有很多同类型该对象。
<resultMap id="teacher" type="com.xin.pojo.Teacher">
<result property="id" column="teacherid"/>
<result property="name" column="tname"/> <!-- ofType里面的类型 -->
<collection property="students" ofType="com.xin.pojo.Student">
<result property="id" column="sid"/>
<result property="name" column="sname"/>
<result property="tid" column="tid"/>
</collection>
</resultMap>
<select id="getTeacherById" resultMap="teacher">
select student.id sid,student.name sname,student.tid,teacher.id teacherid,teacher.name tname
from teacher,student
where teacher.id=#{tid}
</select>
<resultMap id="teacher2" type="com.xin.pojo.Teacher">
<result property="id" column="id"/>
<result property="name" column="name"/> <!--id,tid,#{tid}都可以-->
<collection property="students" javaType="ArrayList" ofType="com.xin.pojo.Student" select="getStudentByTid" column="#{tid}"/>
</resultMap>
<select id="getTeacherById2" resultMap="teacher2">
select * from mybatis.teacher where id=#{tid}
</select>
<select id="getStudentByTid" resultType="com.xin.pojo.Student">
select * from mybatis.student where tid=#{tid}
</select>
<if ,<choose ,<when ,<where ,<set ,<sql
if标签起判断作用,表达式成立才会进行if标签中的sql拼接。
choose标签类似switch,配合when进行判断使用哪些sql进行拼接。
set中拼接set时的sql,并且每一个都会用逗号隔开。
sql标签来定义sql片段,在引用时<include refid=“片段id”/>相当于将此段sql进行拼接。
where标签拼接where条件。
<select id="queryBlogIF" parameterType="map" resultType="com.xin.pojo.Blog">
<include refid="selectAll"/> from blog
<where>
<if test="title!=null"> <!-- where会自动拼接and,不管你加没加 -->
and title=#{title}
</if>
<if test="author!=null">
and author=#{author}
</if>
</where>
</select>
<sql id="selectAll"> <!--sql拼接可以是语句,也可以是JSTL标签-->
select *
</sql>
<!-- choose -->
<select id="queryBlogChoose" parameterType="map" resultType="com.xin.pojo.Blog">
select * from blog
<where>
<choose>
<when test="title!=null">
and title=#{title}
</when>
<when test="author!=null"> <!--满足才会选择,不会像switch那样满足后后面都会选择-->
and author=#{author}
</when>
<otherwise> <!-- 都不满足才会选择 ,满足一个都不会选择-->
and views>9909
</otherwise>
</choose>
</where>
</select>
<update id="update" parameterType="map" >
update mybatis.blog
<set> <!--set会自动拼接逗号,不管你加没加-->
<if test="title!=null">
title=#{title},
</if>
<if test="views!=null">
views=#{views},
</if>
</set>
where author=#{author}
</update>
其他
<!-- 算法(FIFO先进先出) 6000ms刷新一次缓存 最多512个缓存 只读 -->
<cache eviction="FIFO" flushInterval="6000" size="512" readOnly="true"/>
执行流程和Mapper代理
- 流读取配置文件,实例化SqlSessionFactoryBuilder,XMLConfigBuilder解析文件信息到Configuration里然后实例化SqlSessionFactory(SqlSessionFactory是接口,实际是DefaultSqlSessionFactory干好给他的,DefaultSqlSessionFactory里面有属性叫Configuration)
- 然后SqlSessionFactory有相应的transactional事务管理器,创建executor执行器,创建SqlSession实现CRUD,然后回滚或提交事务
Mapper 接口的工作原理是JDK动态代理,Mybatis运行时会使用JDK动态代理为Mapper接口生成代理对象 MappedProxy,代理对象会拦截接口方法,根据类的全限定名+方法名,唯一定位到一个MapperStatement并调用执行器执行所代表的sql,然后将sql执行结果返回。
Mapper接口里的方法,是不能重载的,因为是使用 全限名+方法名 的保存和寻找策略。
在Mybatis中,每一个SQL标签,都会被解析为一个MapperStatement对象。
Mybatis一二级缓存
- 一级缓存(默认),从sqlSession开启到关闭,其中查询的数据都会缓存进Map,再次查询从Map中拿,除查询外的操作都会刷新缓存同步数据库中。
- 二级缓存是mapper级别即namespace级别的,在每一个mapper中手动开启,里面每一个statement都可以设置是否使用二级缓存。开启二级缓存后查询优先级为二级缓存>一级缓存>持久层。
Mybatis-plus逆向工程代码生成
官网有更详细的配置:
https://baomidou.com/pages/d357af/#%E7%BC%96%E5%86%99%E9%85%8D%E7%BD%AE
Mybatis-plus基本使用方法
-
像Mybatis那样导入配置好后,在Mapper接口里继承一个BaseMapper,泛型传入这个Mapper对应的pojo类,即可使用mybatis-plus带来的快捷操作。
-
注入Mapper后,可直接使用注入的mapper使用快捷方法。其中复杂查询有QueryWrapper(UpdateWrapper) 和 LambdaQueryWrapper(LambdaUpdateWrapper) ,用来构造复杂的查询语句进行操作。查看是否要使用条件构造器可以看方法源码。
警告:
不支持以及不赞成在 RPC 调用中把 Wrapper 进行传输。
原因:
wrapper 很重,正确的 RPC 调用是写一个 DTO 进行传输,被调用方再根据 DTO 执行相应的操作,官网拒绝接受任何关于 RPC 传输 Wrapper 报错相关的 issue 甚至 pr。
快捷带来的方法
Mapper的bean可以使用的方法
通用 CRUD 封装BaseMapper (opens new window)接口,为 Mybatis-Plus 启动时自动解析实体表关系映射转换为 Mybatis 内部对象注入容器。
----------------------Insert-------------------------
// 插入一条记录
int insert(T entity);
----------------------Delete-------------------------
// 根据 entity 条件,删除记录
int delete(@Param(Constants.WRAPPER) Wrapper<T> wrapper);
// 删除(根据ID 批量删除)
int deleteBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);
// 根据 ID 删除
int deleteById(Serializable id);
// 根据 columnMap 条件,删除记录
int deleteByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);
----------------------Update-------------------------
// 根据 whereWrapper 条件,更新记录
int update(@Param(Constants.ENTITY) T updateEntity, @Param(Constants.WRAPPER) Wrapper<T> whereWrapper);
// 根据 ID 修改
int updateById(@Param(Constants.ENTITY) T entity);
----------------------Select-------------------------
// 根据 ID 查询
T selectById(Serializable id);
// 根据 entity 条件,查询一条记录
T selectOne(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 查询(根据ID 批量查询)
List<T> selectBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);
// 根据 entity 条件,查询全部记录
List<T> selectList(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 查询(根据 columnMap 条件)
List<T> selectByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);
// 根据 Wrapper 条件,查询全部记录
List<Map<String, Object>> selectMaps(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录。注意: 只返回第一个字段的值
List<Object> selectObjs(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 entity 条件,查询全部记录(并翻页)
IPage<T> selectPage(IPage<T> page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录(并翻页)
IPage<Map<String, Object>> selectMapsPage(IPage<T> page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询总记录数
Integer selectCount(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
Service的bean可以使用的方法
通用 Service CRUD 封装IService (opens new window)接口,进一步封装 CRUD 采用 get 查询单行 remove 删除 list 查询集合 page 分页 前缀命名方式区分 Mapper 层避免混淆。
----------------------Save-------------------------
// 插入一条记录(选择字段,策略插入)
boolean save(T entity);
// 插入(批量)
boolean saveBatch(Collection<T> entityList);
// 插入(批量)
boolean saveBatch(Collection<T> entityList, int batchSize);
----------------------SaveOrUpdate-------------------------
// 存在该entity的TableId则更新记录,否则插入一条记录
boolean saveOrUpdate(T entity);
// 根据updateWrapper尝试更新,否继续执行saveOrUpdate(T)方法
boolean saveOrUpdate(T entity, Wrapper<T> updateWrapper);
// 批量修改插入
boolean saveOrUpdateBatch(Collection<T> entityList);
// 批量修改插入
boolean saveOrUpdateBatch(Collection<T> entityList, int batchSize);
----------------------Remove-------------------------
// 根据条件,删除记录
boolean remove(Wrapper<T> queryWrapper);
// 根据 ID 删除
boolean removeById(Serializable id);
// 根据 columnMap 条件,删除记录
boolean removeByMap(Map<String, Object> columnMap);
// 删除(根据ID 批量删除)
boolean removeByIds(Collection<? extends Serializable> idList);
----------------------Update-------------------------
// 根据 UpdateWrapper 条件,更新记录 需要设置sqlset
boolean update(Wrapper<T> updateWrapper);
// 根据 whereWrapper 条件,更新记录
boolean update(T updateEntity, Wrapper<T> whereWrapper);
// 根据 ID 选择修改
boolean updateById(T entity);
// 根据ID 批量更新
boolean updateBatchById(Collection<T> entityList);
// 根据ID 批量更新
boolean updateBatchById(Collection<T> entityList, int batchSize);
----------------------Get-------------------------
// 根据 ID 查询
T getById(Serializable id);
// 根据 Wrapper,查询一条记录。结果集,如果是多个会抛出异常,随机取一条加上限制条件 wrapper.last("LIMIT 1")
T getOne(Wrapper<T> queryWrapper);
// 根据 Wrapper,查询一条记录
T getOne(Wrapper<T> queryWrapper, boolean throwEx);
// 根据 Wrapper,查询一条记录
Map<String, Object> getMap(Wrapper<T> queryWrapper);
// 根据 Wrapper,查询一条记录
<V> V getObj(Wrapper<T> queryWrapper, Function<? super Object, V> mapper);
----------------------List-------------------------
// 查询所有
List<T> list();
// 查询列表
List<T> list(Wrapper<T> queryWrapper);
// 查询(根据ID 批量查询)
Collection<T> listByIds(Collection<? extends Serializable> idList);
// 查询(根据 columnMap 条件)
Collection<T> listByMap(Map<String, Object> columnMap);
// 查询所有列表
List<Map<String, Object>> listMaps();
// 查询列表
List<Map<String, Object>> listMaps(Wrapper<T> queryWrapper);
// 查询全部记录
List<Object> listObjs();
// 查询全部记录
<V> List<V> listObjs(Function<? super Object, V> mapper);
// 根据 Wrapper 条件,查询全部记录
List<Object> listObjs(Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录
<V> List<V> listObjs(Wrapper<T> queryWrapper, Function<? super Object, V> mapper);
----------------------Page-------------------------
// 无条件分页查询
IPage<T> page(IPage<T> page);
// 条件分页查询
IPage<T> page(IPage<T> page, Wrapper<T> queryWrapper);
// 无条件分页查询
IPage<Map<String, Object>> pageMaps(IPage<T> page);
// 条件分页查询
IPage<Map<String, Object>> pageMaps(IPage<T> page, Wrapper<T> queryWrapper);
----------------------Count-------------------------
// 查询总记录数
int count();
// 根据 Wrapper 条件,查询总记录数
int count(Wrapper<T> queryWrapper);
条件构造器
条件构造器QueryWrapper和 LambdaQueryWrapper的区别就是:在指定数据库记录字段时,QueryWrapper使用的是字符串(如"name"),LambdaQueryWrapper使用的是方法引用(如User:getName)。
allEq 全部等于
allEq({id:1,name:"老王",age:null}, false) //为false为忽略age,为true则不忽略age
==>
id = 1 and name = '老王'
eq 等于
ne 不等于
gt 大于
ge 大于等于
lt 小于
le 小于等于
between 在x~y之间
notBetween 不在在x~y之间
like 模糊匹配到的
notLike 模糊匹配不到的
likeLeft 左边为这个
likeRight 右边为这个
notLikeLeft 左边不为这个
notLikeRight 右边不为这个
isNull 是空
isNotNull 不是空
in 在这些之中的
notIn 不在在这些之中的
inSql 在该sql查询之中的
notInSql 不在该sql查询之中的
notInSql("id", "select id from table where id < 3")
==>
id not in (select id from table where id < 3)
groupBy 分组
orderByAsc 从小大排序
orderByDesc 从大到小排序
orderBy 自定义排序
having 分组过滤
having("sum(age) > {0}", 11) // 也可以直接写值
==>
having sum(age) > 11
func 主要方便在出现if…else下调用不同方法能不断链
func(i -> if(true) {i.eq("id", 1)} else {i.ne("id", 1)})
or 或者
or(i -> i.eq("name", "李白").ne("status", "活着"))
==>
or (name = '李白' and status <> '活着')
and 并且
and(i -> i.eq("name", "李白").ne("status", "活着"))
==>
and (name = '李白' and status <> '活着')
nested 正常嵌套
nested(i -> i.eq("name", "李白").ne("status", "活着"))
==>
(name = '李白' and status <> '活着')
apply 拼接sql
apply("date_format(dateColumn,'%Y-%m-%d') = {0}", "2008-08-08")
==>
date_format(dateColumn,'%Y-%m-%d') = '2008-08-08'")
last 在最后添加什么
exists 该sql结果存在
notExists 该sql结果不存在
条件构造器有很多,在使用时去想对应的sql语句,然后尝试点出对应意思的方法进行构造,可以用日志输出查看构造的sql是否满意。
MP主键生成策略
在pojo类上标上注解,其中:
- AUTO : 数据库id自增
- NONE : 数据库未设置主键
- INPUT : 手动输入,需要自己写id
- ASSIGN_ID : 雪花算法全局唯一id
- ASSIGN_UUID : 全局唯一id
/*
* AUTO : 数据库id自增
* NONE : 数据库未设置主键
* INPUT : 手动输入,需要自己写id
* ASSIGN_ID : 雪花算法全局唯一id 1.第一位 占用1bit,其值始终是0,没有实际作用。 2.时间戳 占用41bit,精确到毫秒,总共可以容纳约69年的时间。 3.工作机器id 占用10bit,其中高位5bit是数据中心ID,低位5bit是工作节点ID,做多可以容纳1024个节点。 4.序列号 占用12bit,每个节点每毫秒0开始不断累加,最多可以累加到4095,一共可以产生4096个ID。
* ASSIGN_UUID : 全局唯一id
* */
@TableId(type = IdType.AUTO) //auto的话 表里也要自增
private Long id;
MP逻辑删除
逻辑删除即在逻辑上已经删除,物理上仍旧存在。一般用一个字段表示,例如0为删除了则在删除时改变该字段为0,在查找时不查找该字段为0的数据记录。
- 在pojo类上标记代表逻辑删除的属性对应数据库中的属性。
@TableLogic // 逻辑删除
private Integer deleted;
- 在配置文件中配置mybatis-plus逻辑删除配置。
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
# 逻辑删除
global-config: # 这里可以不配置,因为默认是这样的
db-config:
logic-delete-value: 1 #代表已经删除
logic-not-delete-value: 0 #代表未删除
- 在使用mybatis-plus操作时会自动转换sql。
处理雪花算法精度丢失
雪花算法id的java的Long类型为18位,比前端Number类型16位精度要高,当后端传Long类型给前端,前端拿到的数据第16位会四舍五入,17位后的数据自动用0代替,在Json中就会出现精度丢失的情况。
解决方法:
使用注解转换成String传前端,传回时转换成Long。但是在使用Redis或其他缓存时该注解可能会失效!
@JsonSerialize(using = ToStringSerializer.class)
private Long id;
或直接全部使用String类型。
字段拼接自动赋值问题
基本数据类型有默认值,而MP在有值的时候就会加入一起修改导致传错误或不需要的值,值为null就不加入匹配。
基本数据类型默认为0,更新时就自动使用0来更新。
解决方法
统一使用包装类型字段。
MP字段自动填充
- 自动填充原理是使用handler给在新增或更新或其他时候对字段进行赋值。
@Slf4j // 官网例子
@Component
public class MyMetaObjectHandler implements MetaObjectHandler {
@Override
public void insertFill(MetaObject metaObject) {
log.info("start insert fill ....");
this.strictInsertFill(metaObject, "createTime", LocalDateTime.class, LocalDateTime.now()); // 起始版本 3.3.0(推荐使用)
// 或者
this.strictInsertFill(metaObject, "createTime", () -> LocalDateTime.now(), LocalDateTime.class); // 起始版本 3.3.3(推荐)
// 或者
this.fillStrategy(metaObject, "createTime", LocalDateTime.now()); // 也可以使用(3.3.0 该方法有bug)
}
@Override
public void updateFill(MetaObject metaObject) {
log.info("start update fill ....");
this.strictUpdateFill(metaObject, "updateTime", LocalDateTime.class, LocalDateTime.now()); // 起始版本 3.3.0(推荐)
// 或者
this.strictUpdateFill(metaObject, "updateTime", () -> LocalDateTime.now(), LocalDateTime.class); // 起始版本 3.3.3(推荐)
// 或者
this.fillStrategy(metaObject, "updateTime", LocalDateTime.now()); // 也可以使用(3.3.0 该方法有bug)
}
}
- 当然在字段上也要进行标注。
@TableField(fill=FieldFill.INSERT) // 对应到Handler
private Date createTime;
@TableField(fill=FieldFill.UPDATE)
private Date updateTime;
- 这样在处理该字段时会使用对应handler进行填充赋值。
MP乐观锁
乐观锁的一般实现是CAS,但是普通的CAS容易出现ABA问题,需要指定一个乐观锁字段,每次修改进行新增,利用该字段进行比较。
- 在乐观锁字段上注解标记。
@Version
private Integer version;
- 配置类或xml中进行配置
@Bean
public MybatisPlusInterceptor myOptimisticLockerInnerInterceptor(){
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());
return interceptor;
}
<bean class="com.baomidou.mybatisplus.extension.plugins.inner.OptimisticLockerInnerInterceptor" id="optimisticLockerInnerInterceptor"/>
<bean id="mybatisPlusInterceptor" class="com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor">
<property name="interceptors">
<list>
<ref bean="optimisticLockerInnerInterceptor"/>
</list>
</property>
</bean>
MP分页
分页在sql中一般是使用limit 1,2,意思是从第1个记录开始往后显示2个记录。
- 分页使用注册导入插件。
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor(){
MybatisPlusInterceptor mybatisPlusInterceptor = new MybatisPlusInterceptor();
mybatisPlusInterceptor.addInnerInterceptor(new PaginationInnerInterceptor());
return mybatisPlusInterceptor;
}
- 使用时通过定义Page和条件构造器等进行分页查询。
Page<User> page = new Page<>(1,3); // 三个为一页,查第一页
userMapper.selectPage(page,null); // 传入Page后会自动分页数据,查出所要的数据
PageHelper
MyBatis-Plus自带有分页PaginationInterceptor对象,但想要用MyBatis-Plus自带的分页功能的话需要在mapper对象中传入一个Page对象才可以实现分页,这样耦合度有点高,从web到service到mapper,这个Page对象一直都在传入,这样的使用让人感觉有点麻烦。使用PageHelper只要一行代码就能实现分页。
- 导入PageHelper包。
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.2.5</version>
</dependency>
- 配置文件中配置。
pagehelper:
auto-dialect: mysql #分页插件会自动检测当前的数据库链接,自动选择合适的分页方式。 你可以配置helperDialect 属性来指定分页插件使用哪种方言。
reasonable: true #分页合理化参数,默认值为 false 。当该参数设置为 true 时, pageNum<=0 时会查询第一页, pageNum>pages (超过总数时),会查询最后一页。
support-methods-arguments: true #支持通过Mapper接口参数传递page参数,默认值为false
page-size-zero: true #默认值为 false ,当该参数设置为 true 时,如果 pageSize=0 或者 RowBounds.limit =0 就会查询出全部的结果(相当于没有执行分页查询,但是返回结果仍然是 Page 类型)。
params: count=countSql #为了支持 startPage(Object params) 方法,增加了该参数来配置参数映射,用于从对象中根据属性名取值
- 使用时应该会拦截吧。
if (page > 0 && size > 0){
PageHelper.startPage(page, size); // 表示对接下来的数据进行分页操作
}
List<User> list = userService.list();
PageInfo pageInfo = new PageInfo<>(list); // 传入自动进行了分页
return ResultUtil.success(pageInfo);
}















 266
266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









