







1. Agent总览
在CrewAI框架中,Agent是一个能具备下列能力的自主单元:
1. 执行特定的任务
2. 基于它的角色和目标进行决策
3. 使用工具完成任务
4. 与其他Agent交流协作
5. 维持交互时的记忆
6. 条件允许的情况下委派任务
2. Agent属性
| 属性 | 参数 | 类型 | 含义 |
|---|---|---|---|
| 角色 | role | str | 定义Agent在Crew中的能力 |
| 目标 | goal | str | 指导Agent进行决策 |
| 背景信息 | backstory | str | 为Agent提供上下文和个性特征,丰富交互 |
| 大语言模型 | llm | Union[str, LLM, any] | 增强Agent的大语言模型,默认为OPENAI_MODEL_NAME环境变量指定的模型或GPT-4 |
| 工具 | tools | List[BaseTool] | Agent可用的工具,默认为空列表 |
| 函数调用的大语言模型 | function_calling_llm | Optional[Any] | 用于调用工具的大语言模型,如果指定,将会覆盖crew的llm |
| 最大迭代 | max_iter | int | Agent提供最佳答案之前的最大迭代数,默认为20 |
| 每分钟最大请求数 | max_rpm | Optional[int] | 每分钟最大请求限制以避免速率限制 |
| 最大执行时间 | max_execution_time | Optional[int] | 任务执行的最大时间 |
| 记忆(疑似参数不存在) | memory | bool | Agent是否应该保持交互时的记忆 |
| 详细日志 | verbose | bool | 打开详细的执行日志以便调试,默认为false |
| 允许委派任务 | allow_delegation | bool | 允许Agent将任务委派给其他Agent,默认为False |
| 步骤回调 | step_callback | Optional[Any] | 每个Agent步骤调用的函数,覆盖crew回调 |
| Cache | cache | bool | 为工具启用缓存,默认为True |
| 系统提示词模板 | system_template | Optional[str] | 自定义Agent系统提示词模板 |
| 提示词模板 | prompt_template | Optional[str] | 自定义Agent提示词模板 |
| 响应模板 | response_template | Optional[str] | 自定义Agent响应模板 |
| 允许代码执行 | allow_code_execution | Optional[bool] | 为Agent启用代码执行,默认为False |
| 最大重试限制 | max_retry_limit | int | 发生错误时重试的最大次数,默认值为2 |
| 尊重上下文窗口 | respect_context_window | bool | 通过总结将消息保持在上下文窗口大小之内,默认为True |
| 代码执行模式 | code_execution_mode | Literal[“safe”, “unsafe”] | 代码执行模式:safe(Docker)或unsafe(直接),默认为safe |
| 嵌入器 | embedder | Optional[Dict[str, Any]] | Agent使用的嵌入器的配置 |
| 知识来源 | knowledge_sources | Optional[List[BaseKnowledgeSource]] | Agent使用的知识来源 |
| 使用系统提示词模板 | use_system_prompt | Optional[bool] | 是否使用系统提示词模板(支持o1模型),默认为True |
3. 创建Agent
3.1 YAML配置
通过crewai create crew <your-project-name>后,在<your-project-name>/src/<your-project-name>/config/agents.yaml中以如下的形式定义Agents:
code_assistant:
role: >
高级Python开发工程师
goal: >
编写和调试Python代码
backstory: >
有10年开发经验的Python开发专家
在<your-project-name>/src/<your-project-name>/config/tasks.yaml中以如下的形式定义Tasks:
coding_task:
description: >
1. 根据用户的要求编写Python代码。
2. 解释用户给出的Python代码。
3. 调试并修改用户给出的Python代码
expected_output: >
根据用户的要求或代码{code},给出一份正确且高效的Python代码
agent: code_assistant
library_used: ['scikit-learn', 'numpy', 'matplotlib']
在<your-project-name>/src/<your-project-name>/crew.py中创建一个继承CrewBase的类:
from crewai import Agent, Crew, Process, Task
from crewai.project import CrewBase, agent, crew, task
# If you want to run a snippet of code before or after the crew starts,
# you can use the @before_kickoff and @after_kickoff decorators
# https://docs.crewai.com/concepts/crews#example-crew-class-with-decorators
@CrewBase
class CodeAssistant():
"""CodeAssistant crew"""
# Learn more about YAML configuration files here:
# Agents: https://docs.crewai.com/concepts/agents#yaml-configuration-recommended
# Tasks: https://docs.crewai.com/concepts/tasks#yaml-configuration-recommended
agents_config = 'config/agents.yaml'
tasks_config = 'config/tasks.yaml'
# If you would like to add tools to your agents, you can learn more about it here:
# https://docs.crewai.com/concepts/agents#agent-tools
@agent
def code_assistant(self) -> Agent:
return Agent(
config=self.agents_config['code_assistant'],
allow_code_execution=True,
code_execution_mode='safe',
max_execution_time=300,
max_retry_limit=3,
verbose=True
)
@task
def coding_task(self) -> Task:
return Task(
config=self.tasks_config['coding_task'],
)
@crew
def crew(self) -> Crew:
"""Creates the CodeAssistant crew"""
# To learn how to add knowledge sources to your crew, check out the documentation:
# https://docs.crewai.com/concepts/knowledge#what-is-knowledge
return Crew(
agents=self.agents, # Automatically created by the @agent decorator
tasks=self.tasks, # Automatically created by the @task decorator
process=Process.sequential,
verbose=True,
# process=Process.hierarchical, # In case you wanna use that instead https://docs.crewai.com/how-to/Hierarchical/
)
在<your-project-name>/src/<your-project-name>/main.py中修改inputs:
mycode = """
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
plt.style.use("deeplearning.mplstyle")
plt.rcParams["font.family"] = "sans-serif"
plt.rcParams["font.sans-serif"] = ["SimHei", "Microsoft YaHei"] # 设置中文字体
plt.rcParams["axes.unicode_minus"] = False # 正确显示负号
class MySoftMaxRegression:
def __init__(self, alpha, la=1, penalty=None, epoch=1e3):
self.m = None
self.c = None # 类别个数
self.w = None
self.b = None
self.dict = None
self.reverse_dict = None
self.alpha = alpha
self.la = la
self.e = epoch
self.ln = penalty is None
self.l1 = penalty == "l1"
self.l2 = penalty == "l2"
self.jwb = []
def _onehotencoder(self, y):
y_unique = np.unique(y)
t = tuple(zip(y_unique, np.arange(len(y_unique))))
self.dict = {key: value for key, value in t}
self.reverse_dict = {key: value for value, key in t}
y_temp = np.zeros((len(y), len(np.unique(y))))
for i in range(len(y)):
y_temp[i][self.dict.get(y[i])] = 1
return y_temp
def _softmax(self, x):
x_temp = np.exp(np.dot(x, self.w.T) + self.b.T)
x_sum = np.sum(x_temp, axis=1).reshape(len(x), 1)
return x_temp / x_sum
def _loss(self, x, y):
loss = -np.sum(np.log(self._softmax(x)) * y)
if self.ln:
return loss
if self.l1:
return loss + np.sum(np.abs(self.w))
if self.l2:
return loss + np.sum(self.w ** 2)
def plotlearingcurve(self, st=0, end=None):
end = int(self.e) if end is None else end
plt.figure(1)
plt.plot(np.arange(st, end + 1), self.jwb[st:end + 1])
plt.xlabel("迭代次数")
plt.ylabel("代价函数值")
plt.title(f"学习曲线图从迭代次数{st}开始")
def fit(self, x, y):
self.m = len(x)
self.c = len(np.unique(y))
self.w = np.zeros((self.c, len(x[0])))
self.b = np.zeros((self.c, 1))
y_onehot = self._onehotencoder(y)
self.jwb.append(self._loss(x, y_onehot))
count = 0
while count < self.e:
w_temp = self.w - self.alpha * np.dot(((self._softmax(x) - 1) * y_onehot).T, x) / self.m
if self.l1:
w_temp = w_temp - self.alpha * self.la * np.sign(w_temp)
if self.l2:
w_temp = w_temp - 2 * self.alpha * self.la * w_temp
self.b = self.b - self.alpha * np.sum((self._softmax(x) - 1) * y_onehot, axis=0).reshape(self.c, 1) / self.m
self.w = w_temp
self.jwb.append(self._loss(x, y_onehot))
count += 1
print(self.jwb)
def predict(self, x):
return self._softmax(x)
def parameters(self):
return self.w, self.b
# 加载数据集,这里以鸢尾花数据集为例
iris = load_iris()
X = iris.data
y = iris.target
# 分割数据集,60%作为训练集,40%作为测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=42)
scaler = StandardScaler()
Xn_train = scaler.fit_transform(X_train)
Xn_test = scaler.transform(X_test)
SoftReg = MySoftMaxRegression(1)
SoftReg.fit(Xn_train, y_train)
SoftReg.plotlearingcurve()
y_pred = np.argmax(SoftReg.predict(Xn_test), axis=1)
print(np.sum(y_pred == y_test) / len(y_test))
print(SoftReg.parameters())
"""
def run():
"""
Run the crew.
"""
inputs = {
"code": mycode
}
try:
CodeAssistant().crew().kickoff(inputs=inputs)
except Exception as e:
raise Exception(f"An error occurred while running the crew: {e}")
def train():
"""
Train the crew for a given number of iterations.
"""
inputs = {
"code": mycode
}
try:
CodeAssistant().crew().train(n_iterations=int(sys.argv[1]), filename=sys.argv[2], inputs=inputs)
except Exception as e:
raise Exception(f"An error occurred while training the crew: {e}")
def replay():
"""
Replay the crew execution from a specific task.
"""
try:
CodeAssistant().crew().replay(task_id=sys.argv[1])
except Exception as e:
raise Exception(f"An error occurred while replaying the crew: {e}")
def test():
"""
Test the crew execution and returns the results.
"""
inputs = {
"code": mycode
}
try:
CodeAssistant().crew().test(n_iterations=int(sys.argv[1]), openai_model_name=sys.argv[2], inputs=inputs)
except Exception as e:
raise Exception(f"An error occurred while testing the crew: {e}")
3.2 直接用代码定义
Agent需要按如下方式定义(后面会将如何用代码定义Task和Crew):
code_assistant = Agent(
role='高级Python开发工程师',
goal='编写和调试Python代码',
backstory='有10年开发经验的Python开发专家',
allow_code_execution=True,
code_execution_mode='safe',
max_execution_time=300,
max_retry_limit=3,
verbose=True
)
3.3 运行结果
在项目路径下先安装依赖,然后运行:
crewai install
crewai run
由于设置了allow_code_execution=True和code_execution_mode=‘safe’,因此需要在电脑上安装docker,否则将无法运行。
总的来说,CrewAI的代码执行相当差劲,从接下来的运行结果图中就可以看出。
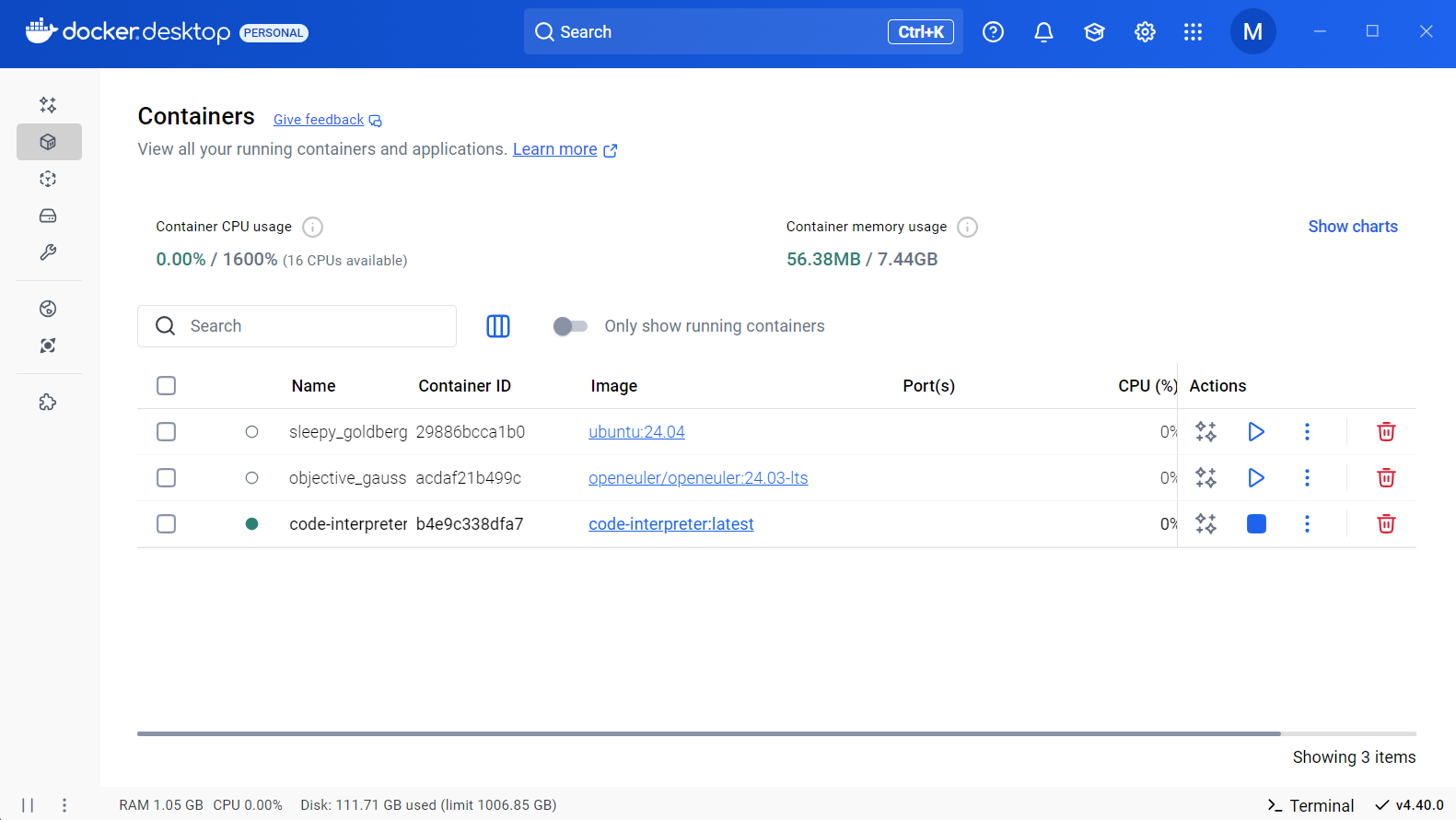
下图是运行过程创建的docker容器,容器名为code-interpreter。
下面是运行结果:
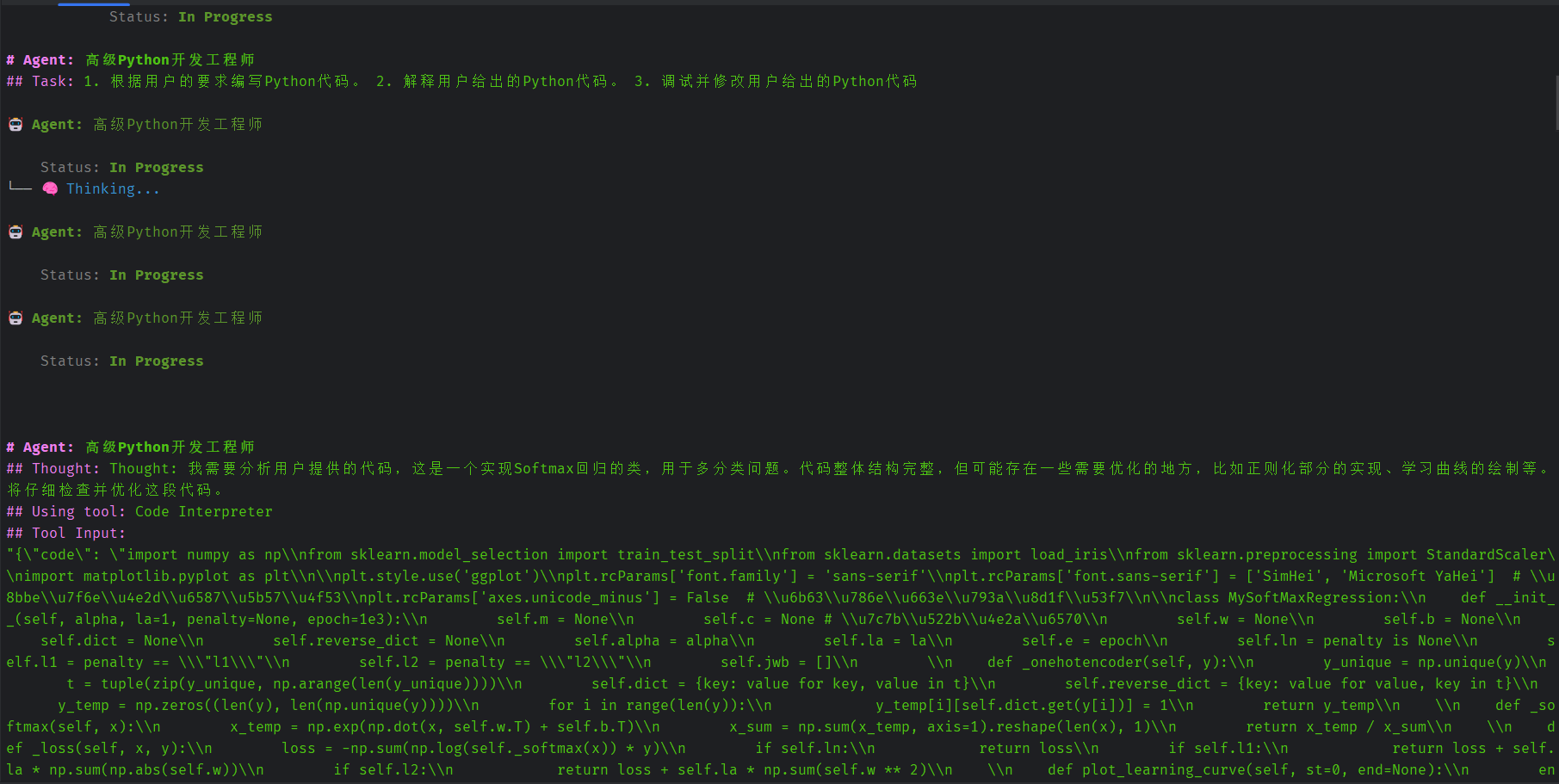
这里对inputs中的code进行了分析,得到了这段代码的目的是实现softmax回归的分析。
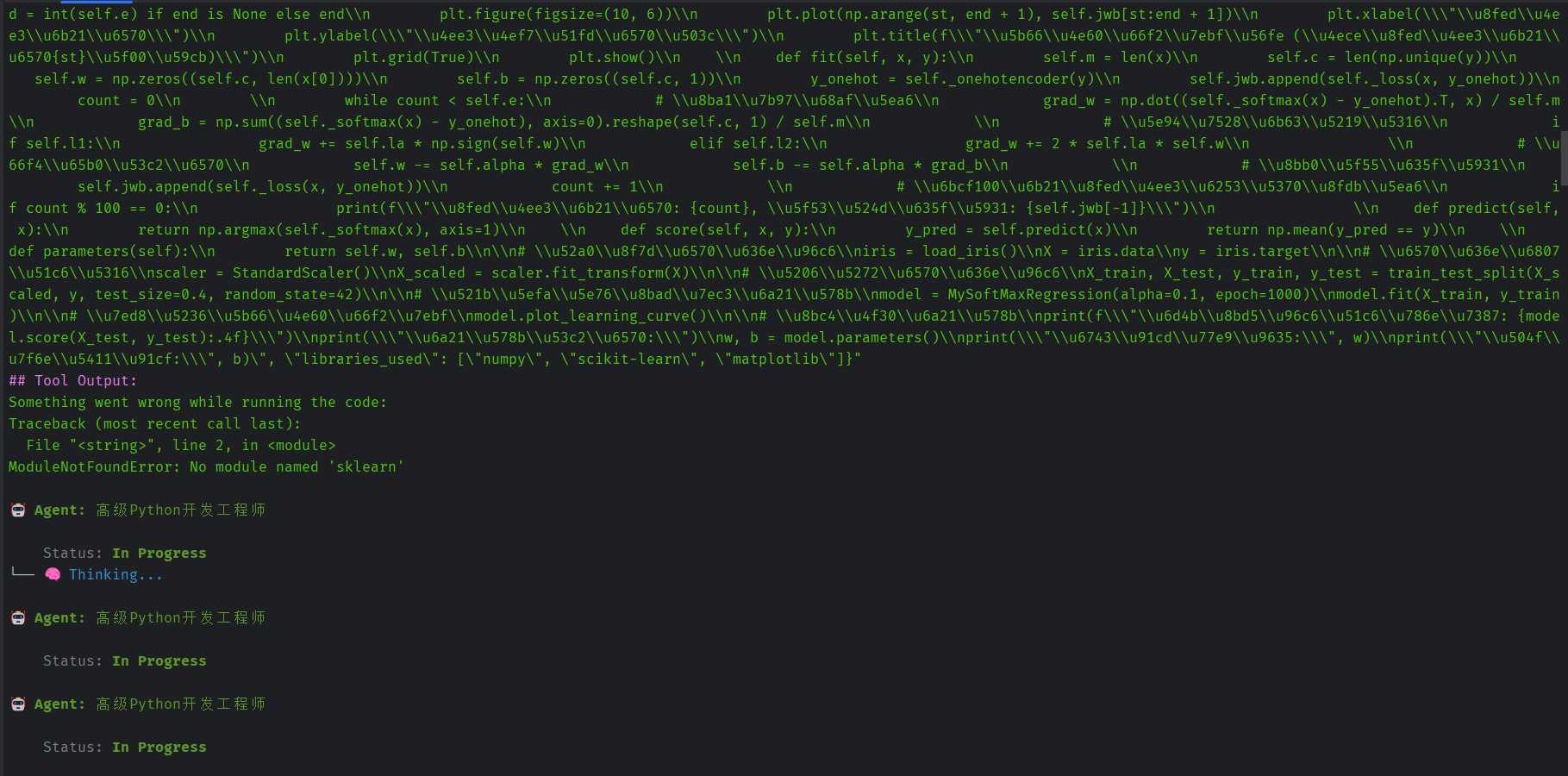
这里执行代码,发现缺少sklearn即scikit-learn库。
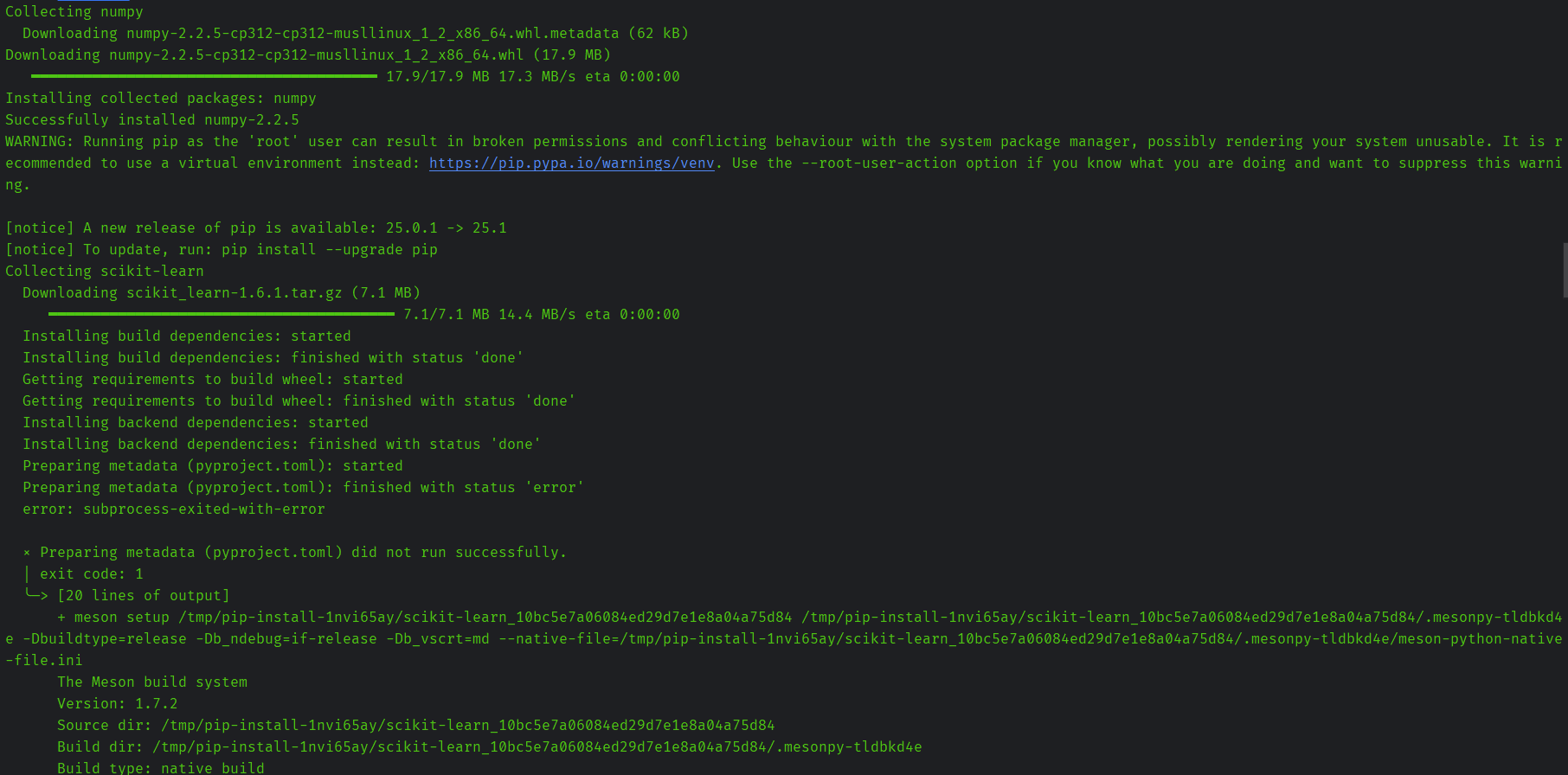
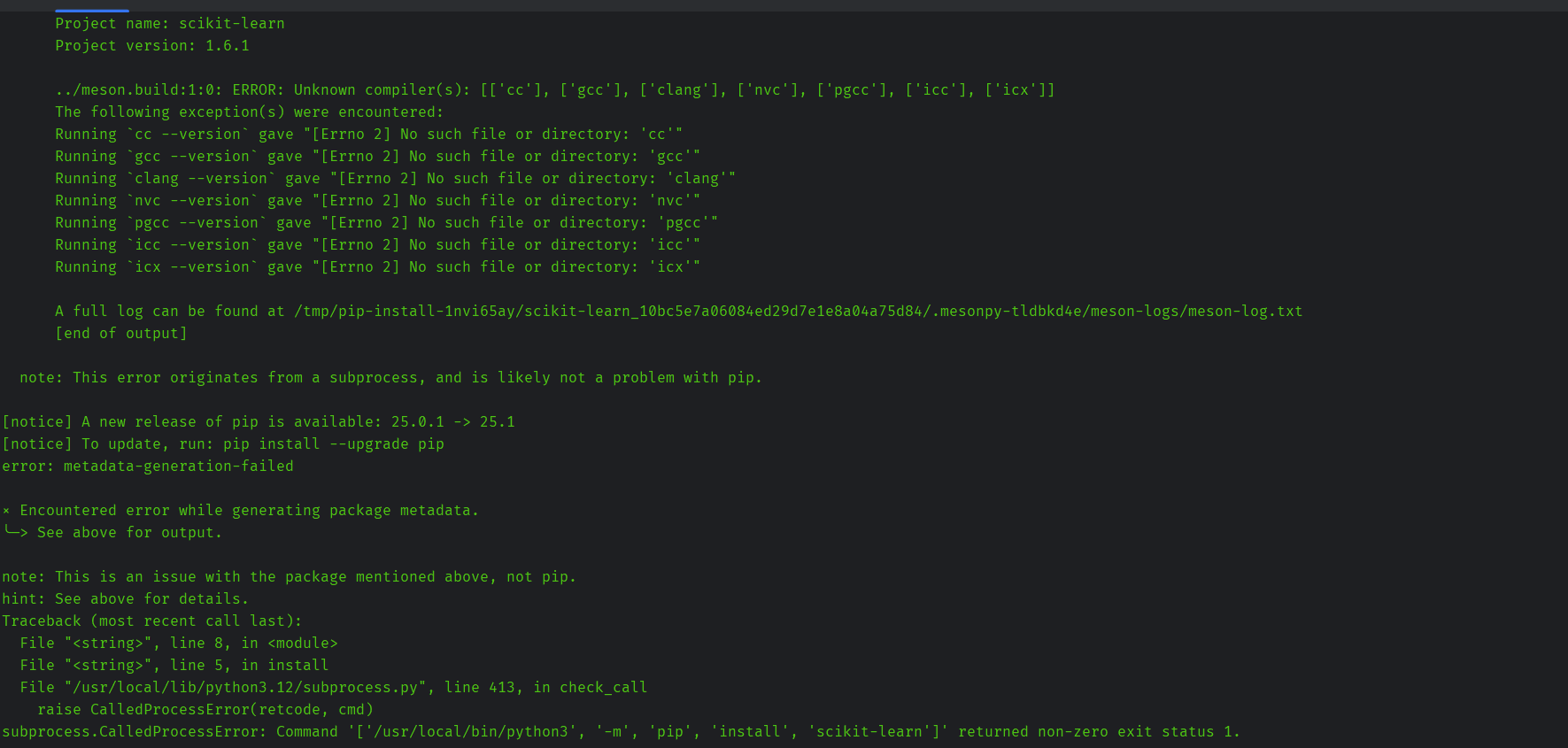
下面三张图都在尝试解决依赖问题,但是发现安装scikit-learn的时候缺少C++编译。
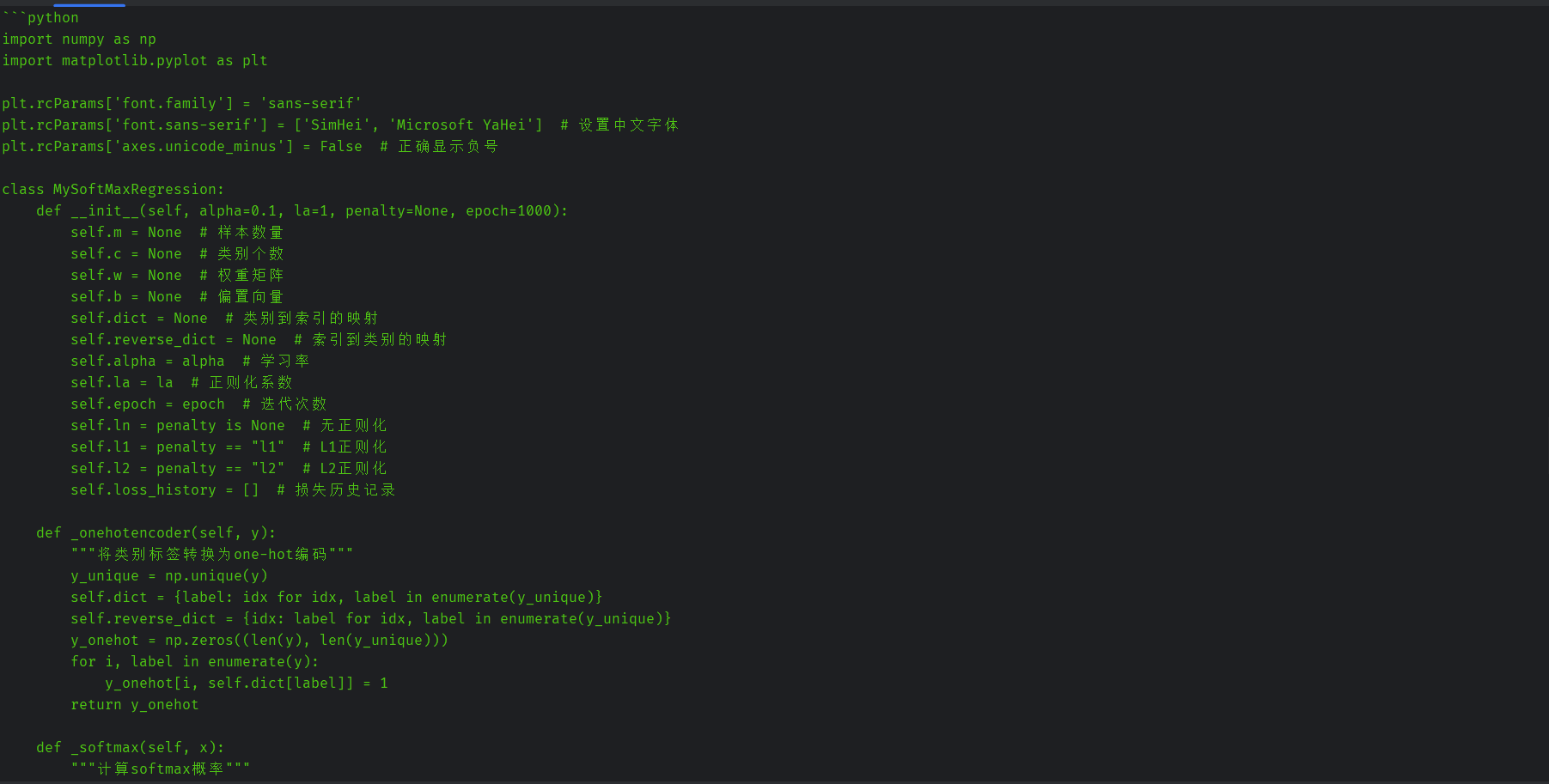
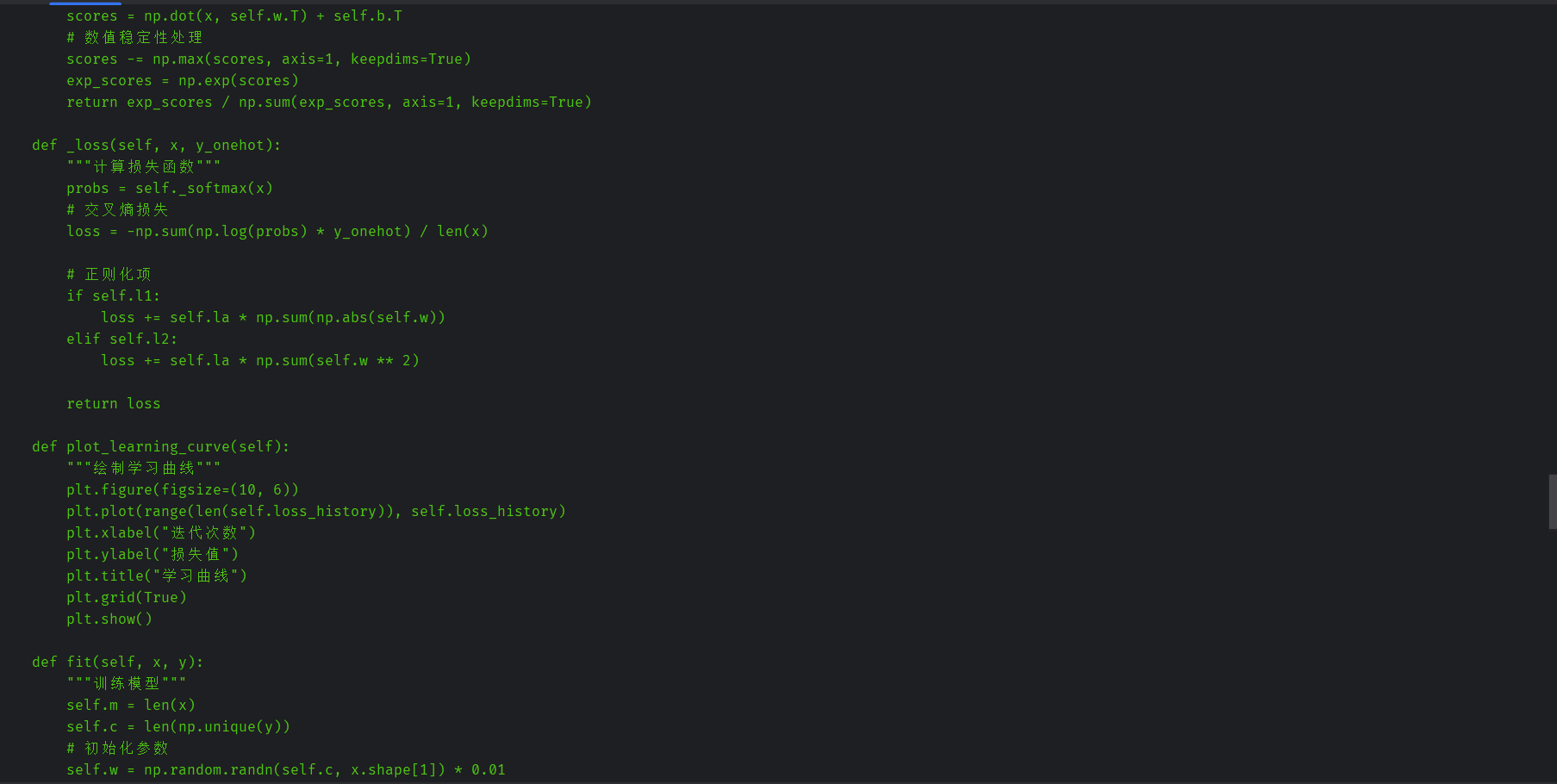
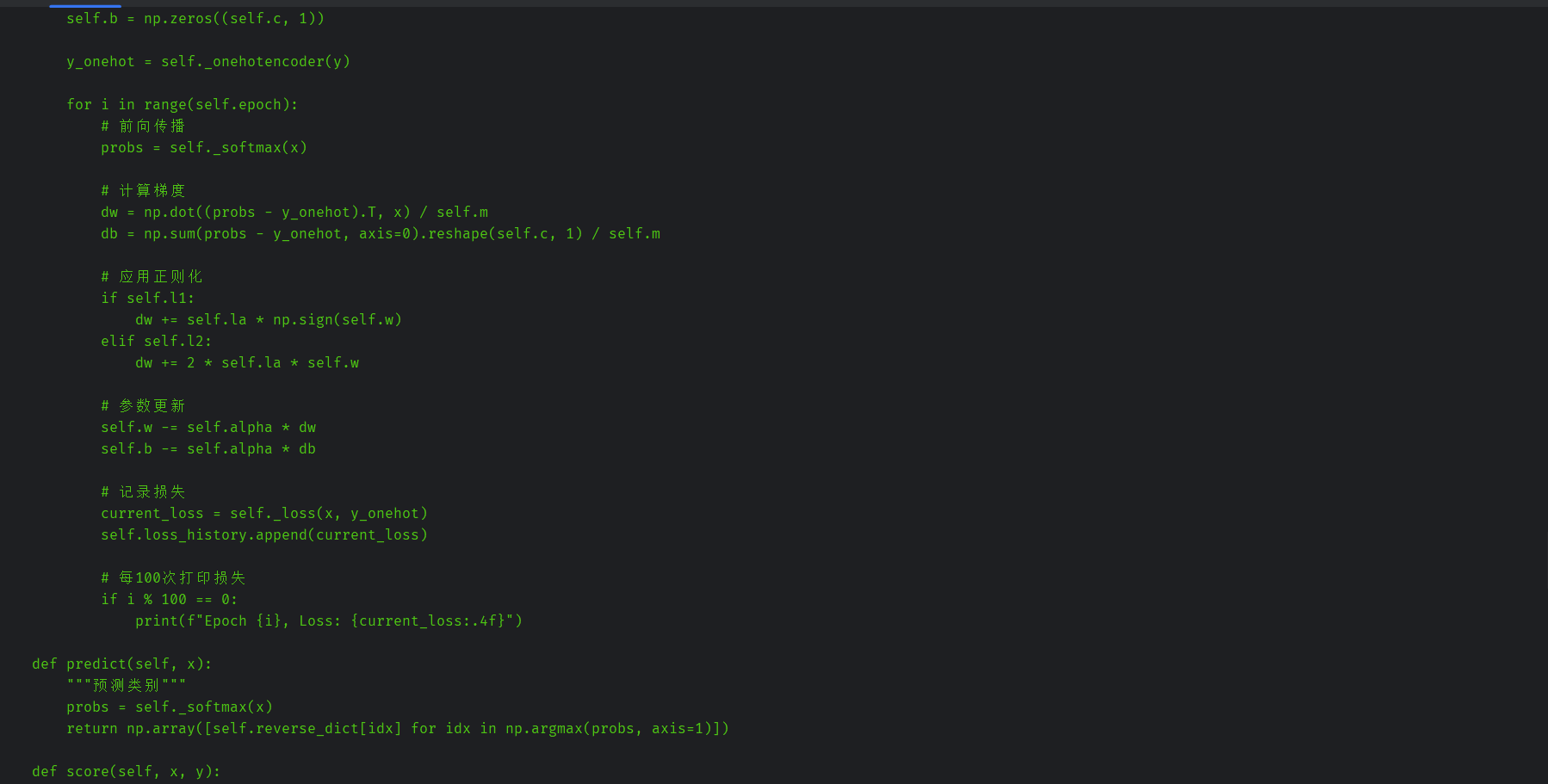
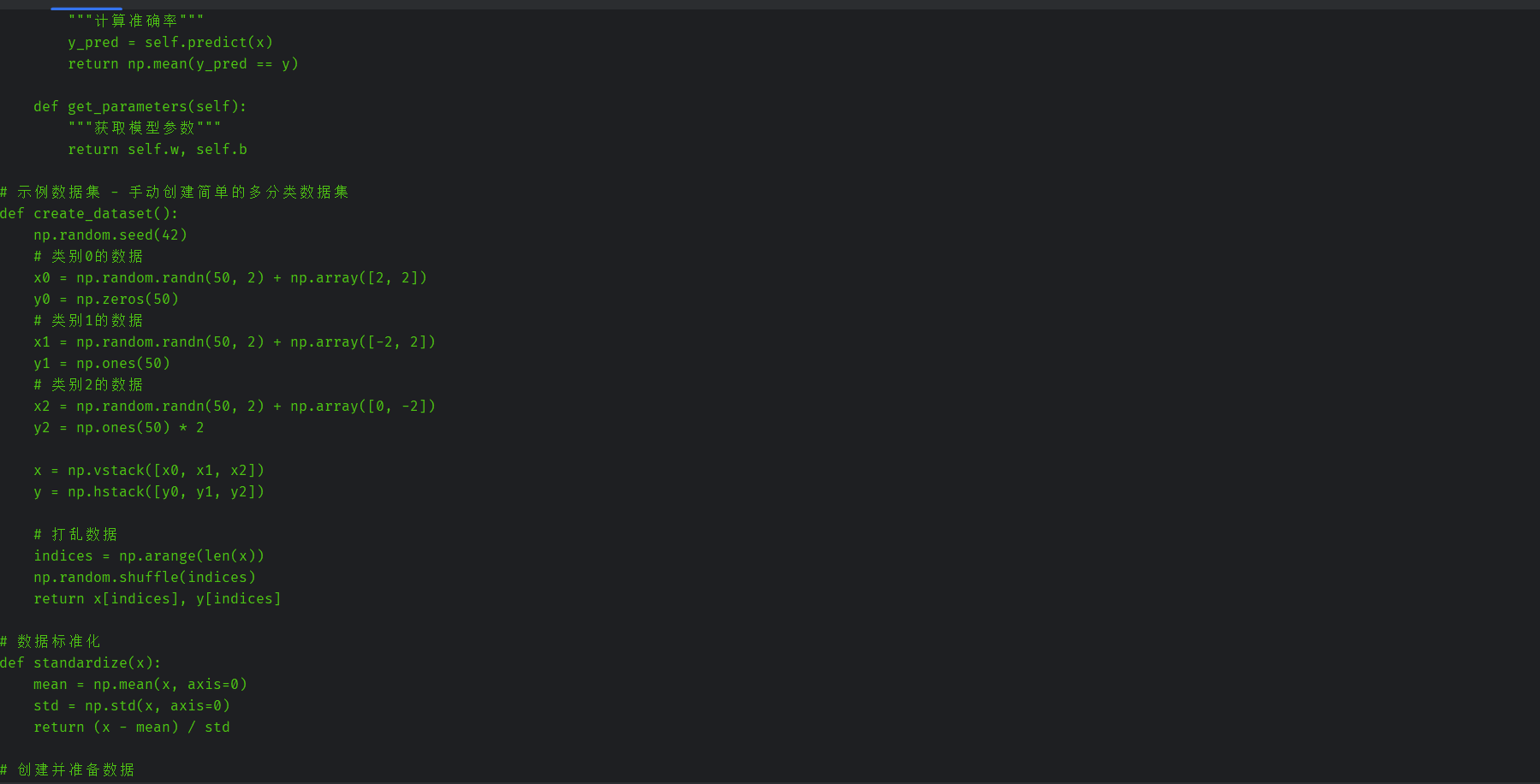
修改后的代码:
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei'] # 设置中文字体
plt.rcParams['axes.unicode_minus'] = False # 正确显示负号
class MySoftMaxRegression:
def __init__(self, alpha=0.1, la=1, penalty=None, epoch=1000):
self.m = None # 样本数量
self.c = None # 类别个数
self.w = None # 权重矩阵
self.b = None # 偏置向量
self.dict = None # 类别到索引的映射
self.reverse_dict = None # 索引到类别的映射
self.alpha = alpha # 学习率
self.la = la # 正则化系数
self.epoch = epoch # 迭代次数
self.ln = penalty is None # 无正则化
self.l1 = penalty == "l1" # L1正则化
self.l2 = penalty == "l2" # L2正则化
self.loss_history = [] # 损失历史记录
def _onehotencoder(self, y):
"""将类别标签转换为one-hot编码"""
y_unique = np.unique(y)
self.dict = {label: idx for idx, label in enumerate(y_unique)}
self.reverse_dict = {idx: label for idx, label in enumerate(y_unique)}
y_onehot = np.zeros((len(y), len(y_unique)))
for i, label in enumerate(y):
y_onehot[i, self.dict[label]] = 1
return y_onehot
def _softmax(self, x):
"""计算softmax概率"""
scores = np.dot(x, self.w.T) + self.b.T
# 数值稳定性处理
scores -= np.max(scores, axis=1, keepdims=True)
exp_scores = np.exp(scores)
return exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
def _loss(self, x, y_onehot):
"""计算损失函数"""
probs = self._softmax(x)
# 交叉熵损失
loss = -np.sum(np.log(probs) * y_onehot) / len(x)
# 正则化项
if self.l1:
loss += self.la * np.sum(np.abs(self.w))
elif self.l2:
loss += self.la * np.sum(self.w ** 2)
return loss
def plot_learning_curve(self):
"""绘制学习曲线"""
plt.figure(figsize=(10, 6))
plt.plot(range(len(self.loss_history)), self.loss_history)
plt.xlabel("迭代次数")
plt.ylabel("损失值")
plt.title("学习曲线")
plt.grid(True)
plt.show()
def fit(self, x, y):
"""训练模型"""
self.m = len(x)
self.c = len(np.unique(y))
# 初始化参数
self.w = np.random.randn(self.c, x.shape[1]) * 0.01
self.b = np.zeros((self.c, 1))
y_onehot = self._onehotencoder(y)
for i in range(self.epoch):
# 前向传播
probs = self._softmax(x)
# 计算梯度
dw = np.dot((probs - y_onehot).T, x) / self.m
db = np.sum(probs - y_onehot, axis=0).reshape(self.c, 1) / self.m
# 应用正则化
if self.l1:
dw += self.la * np.sign(self.w)
elif self.l2:
dw += 2 * self.la * self.w
# 参数更新
self.w -= self.alpha * dw
self.b -= self.alpha * db
# 记录损失
current_loss = self._loss(x, y_onehot)
self.loss_history.append(current_loss)
# 每100次打印损失
if i % 100 == 0:
print(f"Epoch {i}, Loss: {current_loss:.4f}")
def predict(self, x):
"""预测类别"""
probs = self._softmax(x)
return np.array([self.reverse_dict[idx] for idx in np.argmax(probs, axis=1)])
def score(self, x, y):
"""计算准确率"""
y_pred = self.predict(x)
return np.mean(y_pred == y)
def get_parameters(self):
"""获取模型参数"""
return self.w, self.b
# 示例数据集 - 手动创建简单的多分类数据集
def create_dataset():
np.random.seed(42)
# 类别0的数据
x0 = np.random.randn(50, 2) + np.array([2, 2])
y0 = np.zeros(50)
# 类别1的数据
x1 = np.random.randn(50, 2) + np.array([-2, 2])
y1 = np.ones(50)
# 类别2的数据
x2 = np.random.randn(50, 2) + np.array([0, -2])
y2 = np.ones(50) * 2
x = np.vstack([x0, x1, x2])
y = np.hstack([y0, y1, y2])
# 打乱数据
indices = np.arange(len(x))
np.random.shuffle(indices)
return x[indices], y[indices]
# 数据标准化
def standardize(x):
mean = np.mean(x, axis=0)
std = np.std(x, axis=0)
return (x - mean) / std
# 创建并准备数据
x, y = create_dataset()
x = standardize(x)
# 分割训练集和测试集
split = int(0.8 * len(x))
x_train, y_train = x[:split], y[:split]
x_test, y_test = x[split:], y[split:]
# 创建并训练模型
model = MySoftMaxRegression(alpha=0.1, epoch=1000)
model.fit(x_train, y_train)
# 评估模型
print(f"训练集准确率: {model.score(x_train, y_train):.4f}")
print(f"测试集准确率: {model.score(x_test, y_test):.4f}")
# 绘制学习曲线
model.plot_learning_curve()
虽然修改后的代码仍然能执行并没有错误修改,但是没有在docker里执行并得到结果,因此根据需求编写代码任务得到的代码可信度存疑。

















 1933
1933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









