






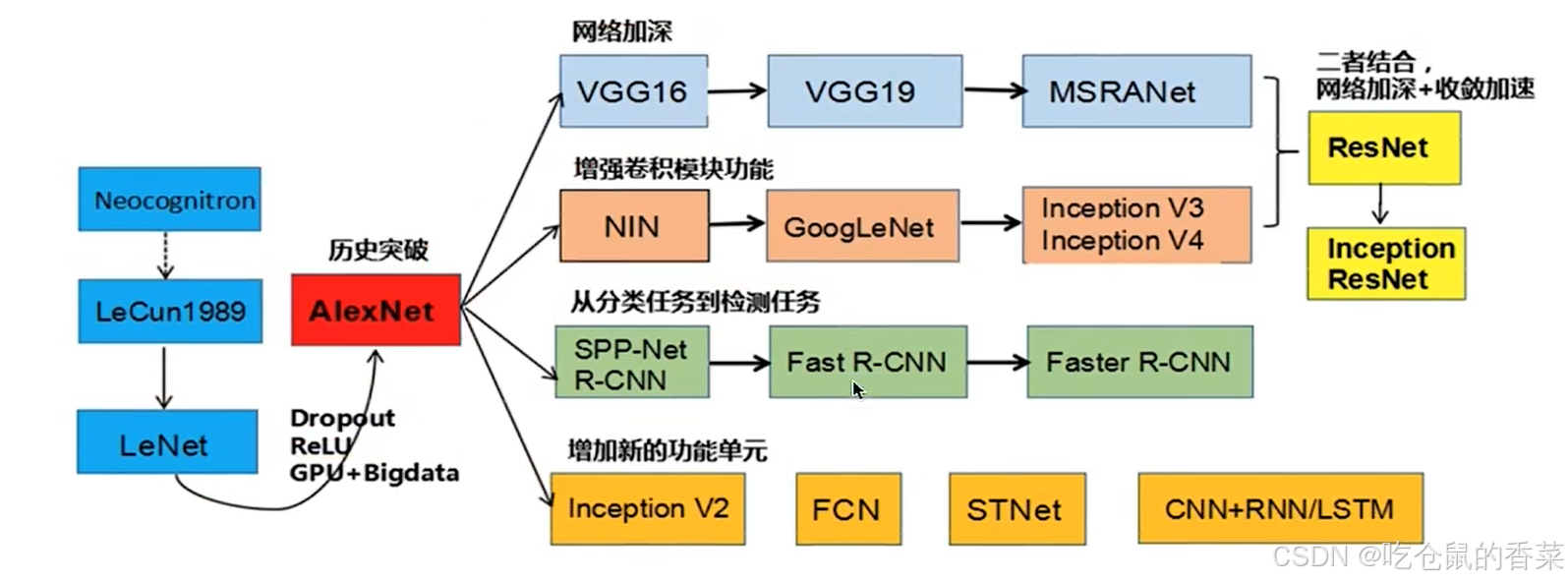
分类网路的发展流程主要如下图所示,由最初的 LeNet 网络开始,经过一次重大的技术突破,发展到 AlexNet ,如今的各大主流热门分类网络便都是基于此发展而来的变体,因此我们首先介绍LeNet
LeNet
首先看一下LeNet的网络结构,如下图所示
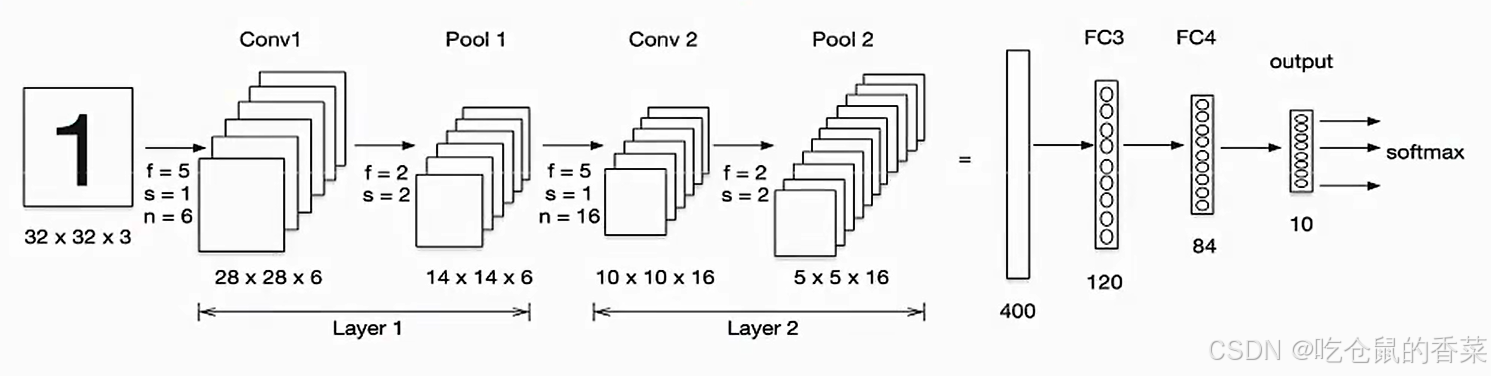
注:激活层默认不花在图中,LeNet 网络使用的是sigmoid 和tanh激活函数,因为当时简单又好用的relu函数还没被发明出来。卷积,激活,池化视为一个层次。进行的分类任务是手写数字识别。
可以看到网络的结构较为简单,仅仅使用了两个卷积层,之后将卷积环节得到的的特征向量拉伸为一维,再通过含有2个隐层的全连接层,得到输出值,在末尾的softmax激活函数会将输出值映射为0~1的多个概率值(每个类别对应一个概率值),再选择概率值最大的分类类别作为输出。
其中使用的是 5*5 大小的卷积核,步长stride为1,一层的卷积核个数为6个(注意因为输入的图像有3个通道,所以一个卷积核也有三层,共有18层卷积核)
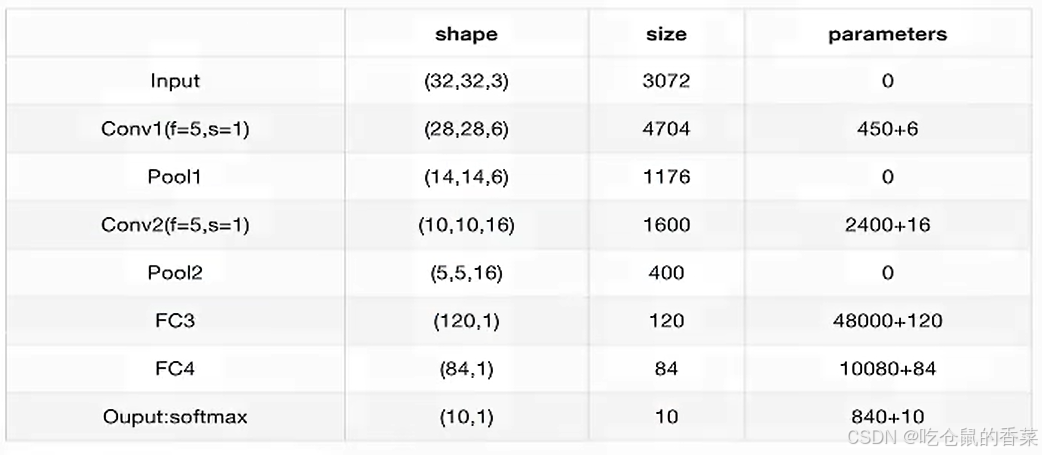
这样的一个网络共有多少个待学习的参数呢?
首先看卷积核,一个卷积核有5*5*3个权重参数 w ,且一个卷积核里的所有w公用一个偏置 b,又一层有6个卷积核,所以b的个数为6,则参数数量为5*5*3*6+6,一共有两个layer,则参数数量再乘2。
在全连接部分,输入为32*32*3,使用5*5的卷积核,没有使用 padding 0 填充方法,则一次卷积,会把输入图像的长宽变为28*28(可以手动比划着理解一下,也有计算公式公式),6个卷积核产生6个输出特征层,那么就可以得到 6*6*28的输出,以此类推,最后得到 5*5*16 的特征输出,拉伸为5*5*6=400的一维向量,再进行全连接操作,则在全连接部分有 400*120 + 120*80 + 80*10个待学习的权重参数 w ,和 120+84+10个偏置参数 b。
计算图如下

参数数量和网络内部结构形状总结
AlexNet
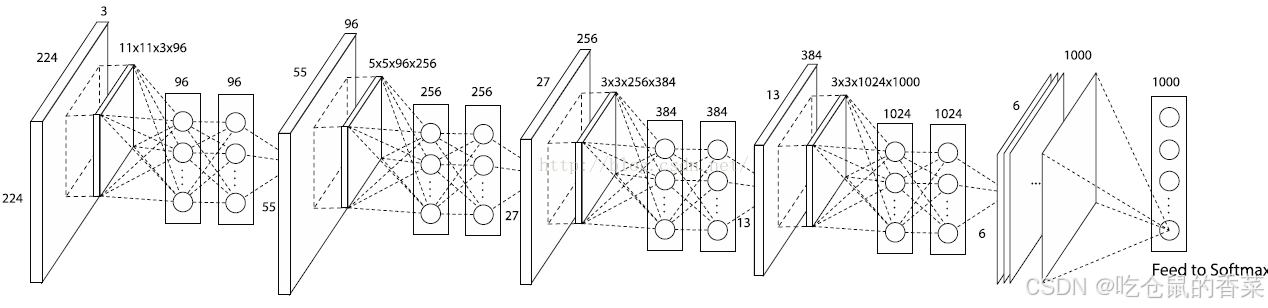
AlexNet是非常有历史意义的一个网络架构,夺得了2012年的 ImageNet LESVRC的冠军,且准确率远超第二名,引起了很大的轰动
同样先看网络架构
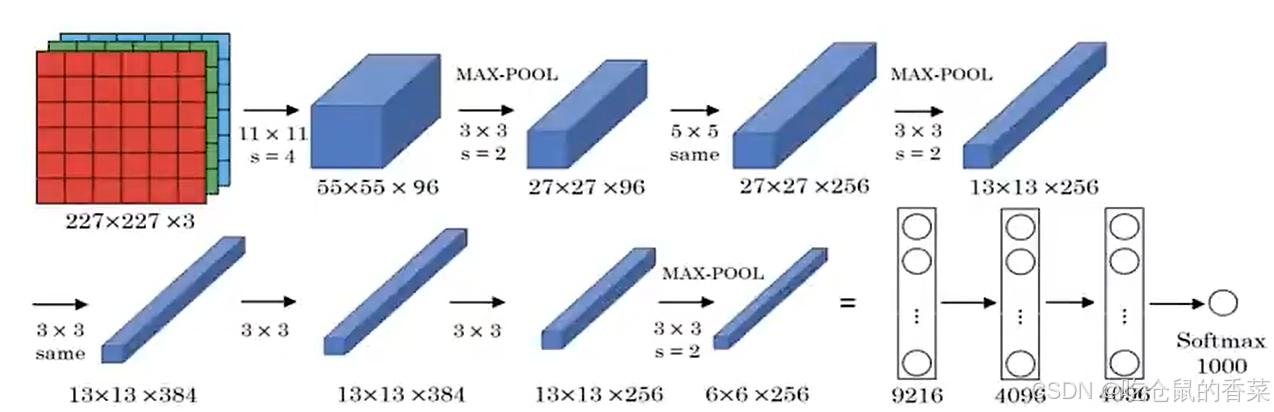
这里先说一下为什么输入为227*227*3,因为网络架构是先固定的网络架构,从输出端的1000分类开始向前倒推,得到需要的输入数据大小,再使用resize等图像缩放函数进行统一的标准化输入。
- 总参数量 6000万个,5层卷积+3层全连接
- 使用了非线性激活函数Relu
- 使用了正则化方法(防止过拟合方法):Dropout,数据扩充
- 使用了BN批标准化层。
我列一下权重参数个数的计算公式
w的个数 =
11*11*3*96 + 5*5*96*256 + 3*3*384*256 + 3*3*384*384 + 3*3*384*256 +
9216*4096 + 4096*4096=58271716(每个因式对应一个层次的权重参数)
可以看到这个网络的参数量实在是太大了,在当时这样的计算量是非常庞大的,因此后续基于ALexNet 的改进优化主要就侧重在计算量和计算速度上,同时保证分类效果不降低。
NIN
在NIN网络中,最大的特点就是创新型的使用了1*1的卷积核,有人可能会说这有个毛用,其实不然。先来看看1*1卷积核的工作方式。
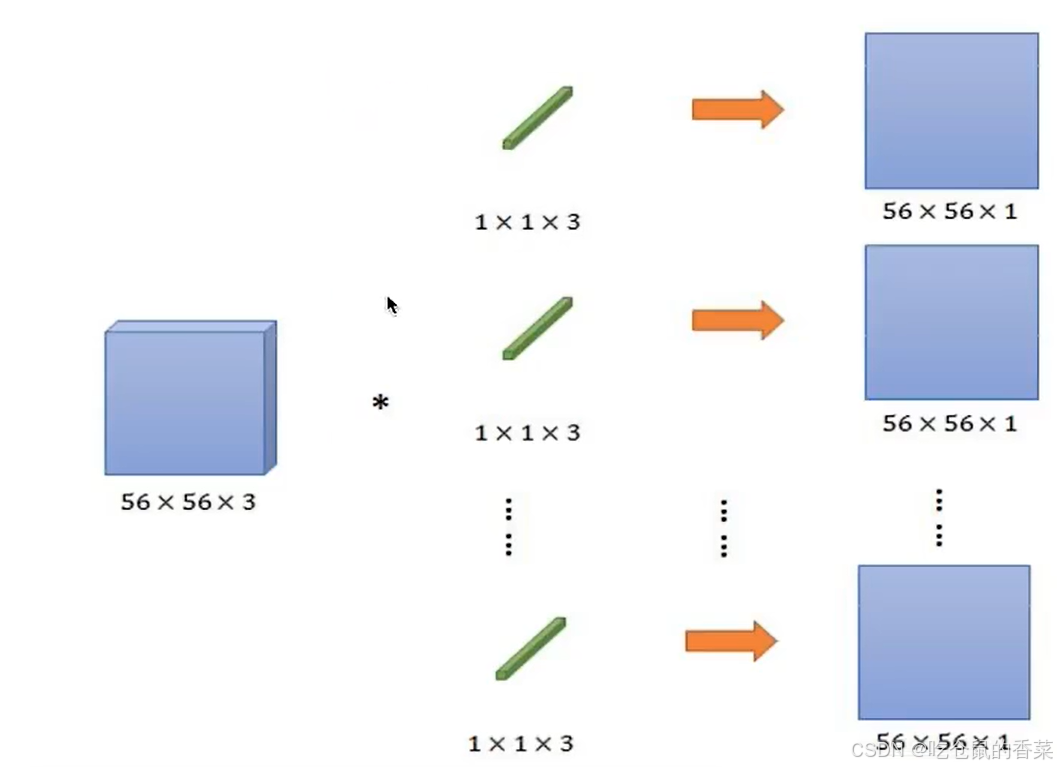
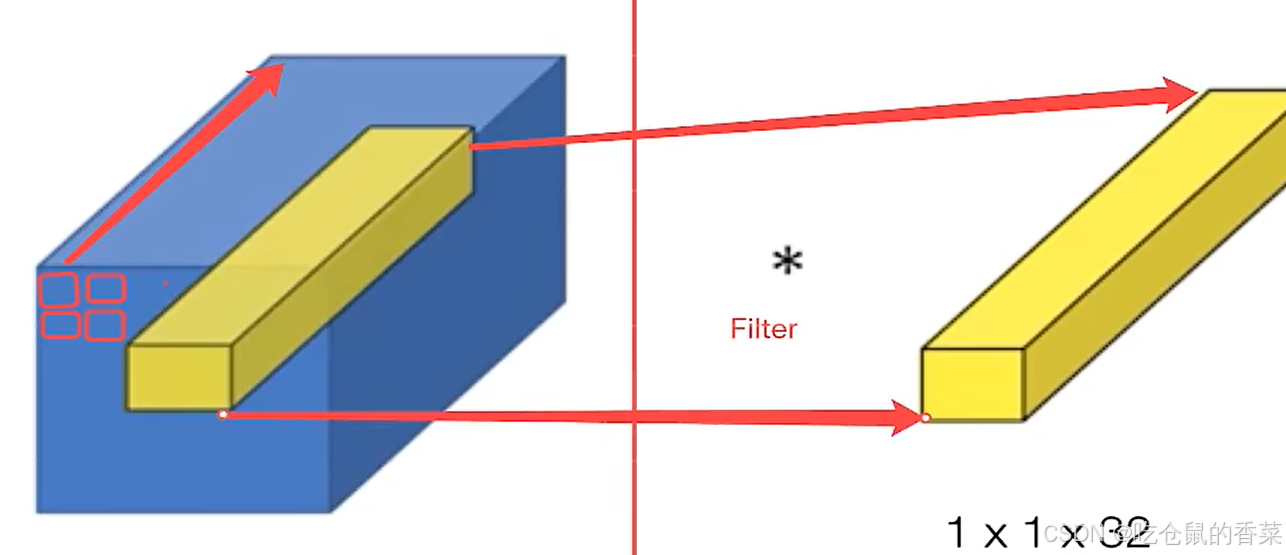
1*1卷积也称为MLP卷积,计算方式和普通卷积一样,先逐个计算所有通道的卷积值,再求和得到一个值,然而当卷积核大小变为1*1时,则退化为了各个通道上特征值的线性组合,在一个通道的一个点上,相当于线性回归了,这样做有什么用呢?这样做,能够强化模型提取和学习各个通道之间的逻辑关系,例如一个通道表示光泽特征,一个通道表示纹理特征,一个通道表示颜色特征,那么可能就能提取到“苹果皮”或“西瓜皮”等类似的特征(当然这只是一个比喻)。专业点讲,就是,将特征图(feature map)由多通道的线性组合,变为非线性组合,提高了模型的特征抽取能力。
另外,它还有一个极为关键的特点是,可以用很少的参数,实现通道数的增加或减少(不需要3*3或者5*5了,因为本身通道数可能会很高,再乘个9或者25,参数数量会很多,VGG甚至能有1.4亿个参数),降低参数数量,提高模型的训练速度。
VggNet
VggNet在2014年的图像分类与定位挑战赛中,取得了分类第二(第一是GoogleNet),定位第一的好成绩,相较于AlexNet,Vgg的成功在于使用了更深层次的网络,足足16层,证明了增加网络的深度对网络性能有积极的影响(注意但它没证明浅层的网络效果不好)。
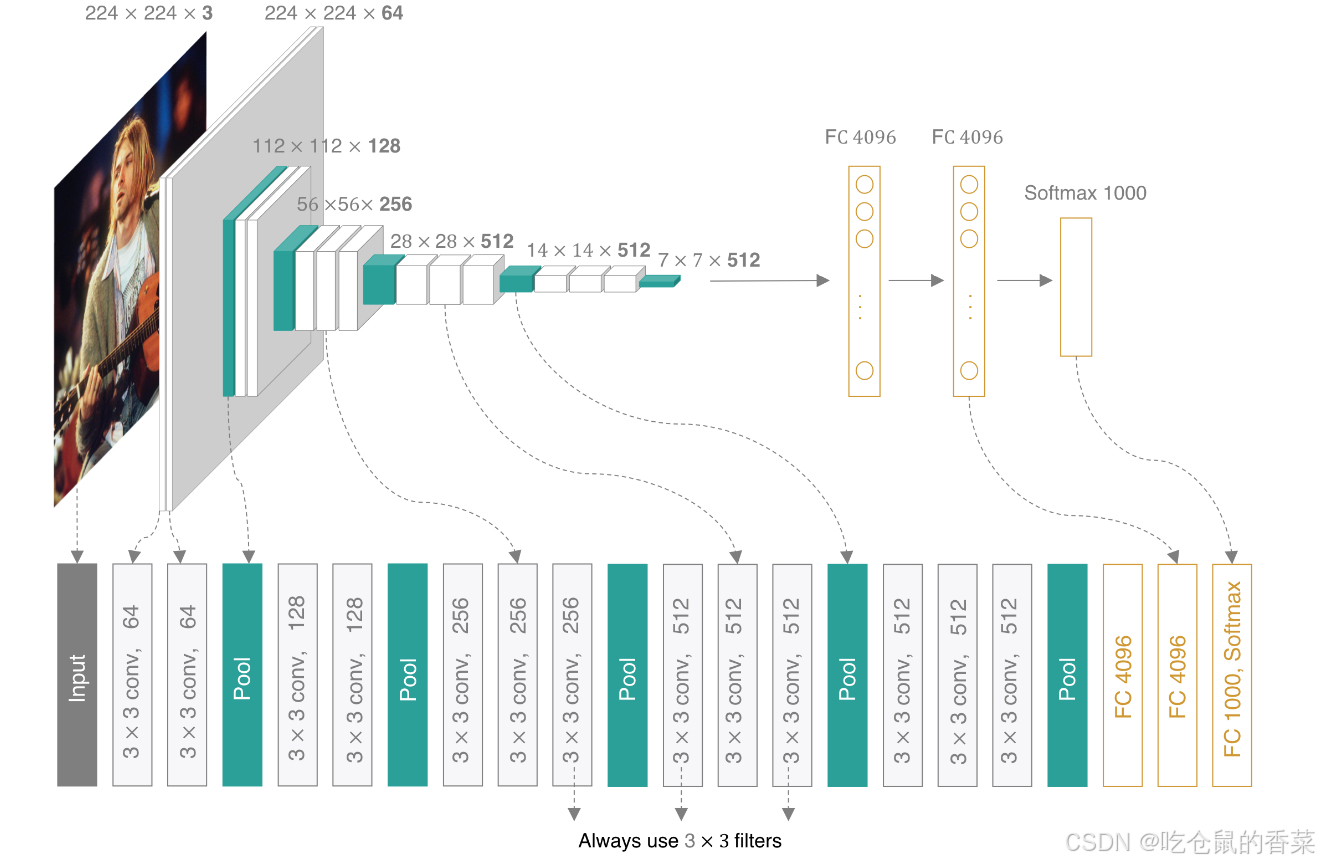
VggNet主要的特点是使用小卷积核(3*3或1*1)来代替大的5*5卷积核,2个3*3便可代替一个5*5,但使用的参数量会更少。并且专注于把特征图做的更宽(通道数更多)更细(图的宽高更小) 使得模型更宽更深的同时,计算量也能够不断地放缓。
事实上,VggNet给与我们的启发,不仅仅限于网络层次的深度,还有极为重要的一点,那便是3*3的小卷积核。我们原本使用卷积核的目的之一便是因为没办法将图片这种特征数据量很大的样本,直接拉伸成一维向量,这会导致全连接的参数量过于巨大,而采用卷积核便可以使用少量的参数对输入进行处理,这是由于算力不足而做出的妥协。因此我们往往会直觉的认为,感受野(卷积核)越大,一次性看到的信息越多,那肯定是越好,而VggNet告诉我们,根本不用组合一大堆乱七八糟的卷积核大小,就3*3就非常好用了,这也是为什么后续神经网络都特别爱用3*3卷积核的原因。
除此之外呢,通过多个小卷积核代替大卷积核这一操作,还还有一个好处:首先,三个非线性的修正层,会使得决策函数更具判别性(说人话就是,多个不同的卷积核可以捕捉多种不同的的feature),其次又能大大的减少参数的数量,可以减少多少呢?假设通道数为C,那么应用在此模型需要27C的平方个参数,而单个7*7卷积核则需要49C的平方个参数,多了足足81%。
GoogleNet
首先我么来了解一下GoogleNet最具代表性的一个层次结构。
Inception层
作用:可以代替人手工去确定,到底用1*1,3*3,还是5*5的卷积核,以及是否需要max_pooling层,可由网络自动的寻找最合适的网络结构。
下图为inception层的结构
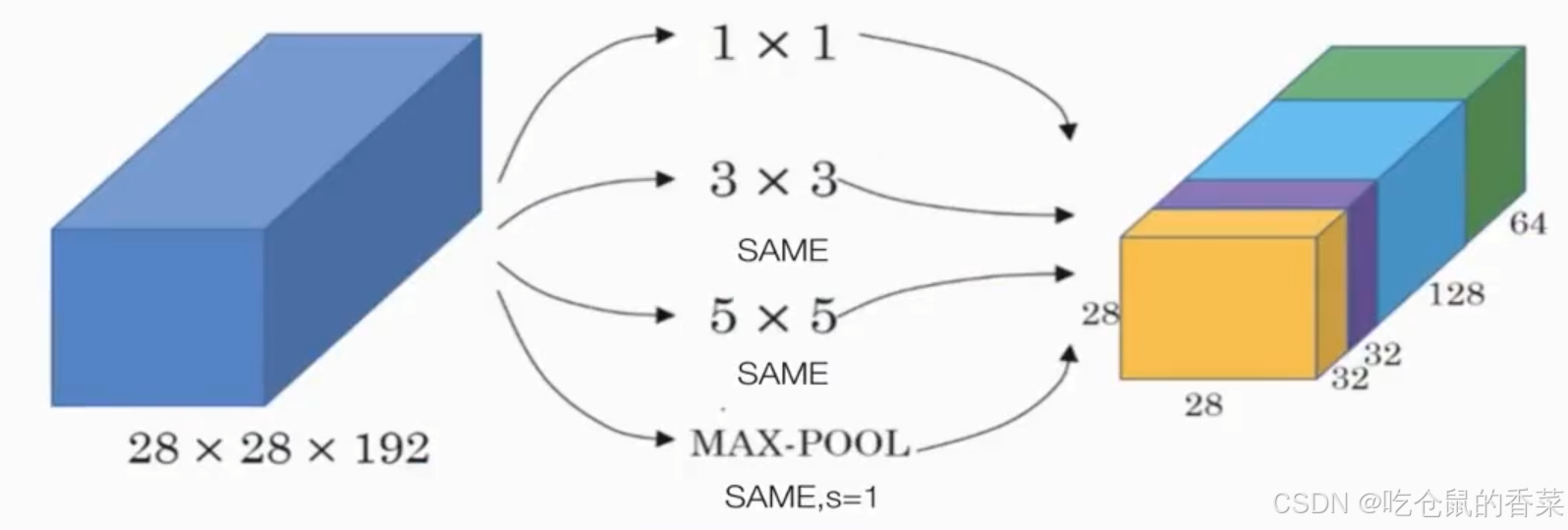
inception层具体做的事其实就是,直接用多种卷积核进行卷积操作,并设置same参数为true,以便能直接将多个卷积结果(再包括一个max_pooling层的结果)拼在一起,这样做其实就相当与一步吧Alexnet的前三个卷积层的处理效果一并完成了,以达到使用更少的参数得到类似(或者说相差不大)的输出的目的。
虽然有了一定的提升(参数两减少了),但事实上这还是不够优秀,参数量依然庞大,于是就又有了inception的改进。
Inception改进
改进目的:再次减少计算量(参数量)
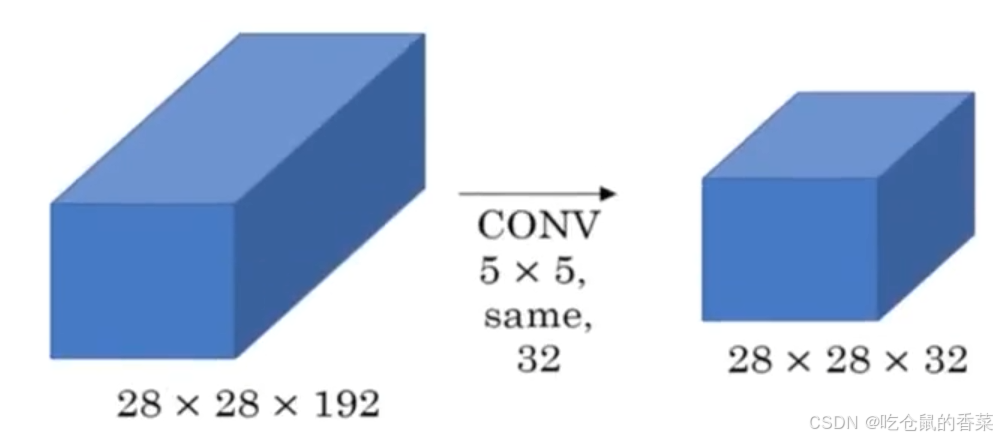
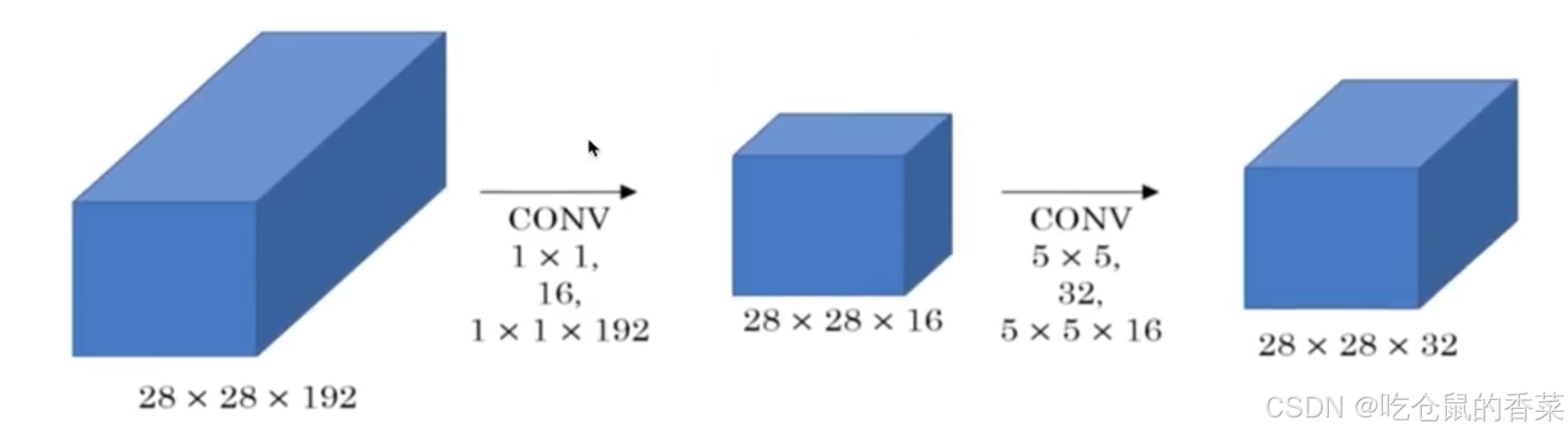
上两图分别为改进前的5*5卷积部分和改进后的卷积部分(就改进了inception图示那里的第三行),可以看到在输出相同网络网络结构的情况加下(28*28*32),加入了一个1*1的卷积层,却使用了更少的参数量,不信我们计算一下
图一:5*5*32*192=153600
图二:192*16+5*5*16*32=15872
参数量整整减少了10倍,真是非常的amazing。那么肯定有人要问了,这样做对模型性能有什么应影响吗,显然googleNet团队早已帮我们做过实验验证,这样做依然可以获得非常好的效果(指拿到分类比赛的冠军)
我们管这种改进方式称之为网络的“瓶颈”,先缩小网络规模,再放大,可缩小参数量但不影响整体网络架构。
网络结构
最后再看一下GoogleNet的整体网络结构(了解)
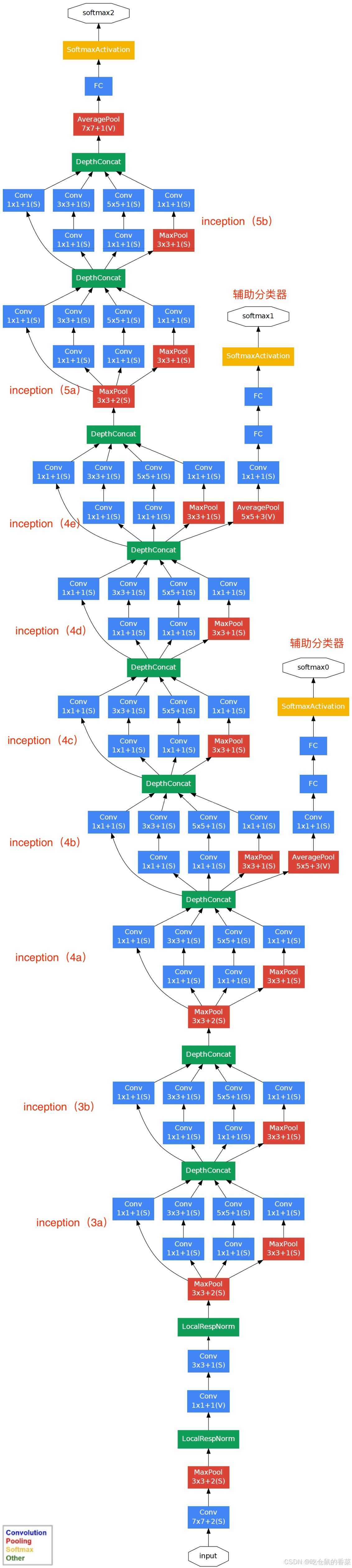
可以看到,GoogleNet的网络非常复杂,但其实大多还是用我们非常熟悉的模块和层次进行叠加,卷积,最大池化,本地标准化(LocalRestNorm,后被替换为更好用的Batch Normalization批标准化)得到了一个非常好的模型效果。
总结
本文主要概述了一些较早的且非常具有代表性的网络结构,但并未细致的讲解每一个网络,主要的目的是对比各个网络的优缺点,以及各自之间的差异,以作启发,例如有的人通过加深深度提高正确率,有的人通过缩小卷积核提高正确率,减少参数量,有的人引入1*1卷积核减少参数量,又或者是在每层之间都加入标准化操作,或是训练时随机抛弃一些神经元(分别对应Batch Normally和Dropout算法)来提高模型的效率与泛用性,借此对比来给读者包括我自己一些思绪和启发。
虽然但是,这些ideas看起来似乎都是那么的简单平平无奇,给人一种《就这?我也想得出来》的感觉,都没有包含什么高深的理论或技术。但深度学习就是这样,你大可以给一些网络架构方案强加一些看似合理的解释,你可以说VggNet因为层次多,所以可以学习到更深层次的输入数据的逻辑和特征,但却无法解释凭什么偏偏是在层次达到16时,模型性能就有了飞跃性的提升,13,14,甚至15层都不行;也解释不了为什么继续大幅增加深度却再也无法取得阶段性的突破,甚至毫无提升(当然你也可以说再多会过拟合),你不知道到底怎么做,他就莫名其妙的变好了,或莫名其妙的变差了,好似一个黑箱,只能看到输入输出的差异,只能尽力去尝试不同的网络组合,却看不到这家伙的肚子里到底卖着什么关子。
后续我也会根据自己的学习需要,详细的介绍各个网络架构。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









