







目录
3.4. Java Mission Control:可持续在线的监控工具
-------------------------------------------
-------------------------------------------
学习前言
通过上⼀章讲解我们对JVM调优有了整体的认知,接下来我们对在调优过程中所使⽤的⼯具逐⼀介绍。
讲解一:理论篇(深入理解JVM第三版)
一、虚拟机性能监控、故障处理工具
Java与C++之间有一堵由内存动态分配和垃圾收集技术所围成的高墙,
墙外面的人想进去,墙里 面的人却想出来。
1. 基本介绍
经过前面对于虚拟机内存分配与回收技术各方面的介绍,相信读者已经建立了一个比较系统、完整的理论基
础。理论总是作为指导实践的工具,把这些知识应用到实际工作中才是我们的最终 目的。接下来的内容,我们将
从实践的角度去认识虚拟机内存管理的世界。
给一个系统定位问题的时候,知识、经验是关键基础,数据是依据,工具是运用知识处理数据的手段。这里
说的数据包括但不限于异常堆栈、虚拟机运行日志、垃圾收集器日志、线程快照 (threaddump/javacore文
件)、堆转储快照(heapdump/hprof文件)等。恰
当地使用虚拟机故障处理、 分析的工具可以提升我们分析数据、定位并解决问题的效率,但我们在学习工具前,
也应当意识到工 具永远都是知识技能的一层包装,没有什么工具是“秘密武器”,拥有了就能“包治百病”。
2. 基础故障处理工具
Java开发人员肯定都知道JDK的bin目录中有java.exe、javac.exe这两个命令行工具,但并非所有程序 员都了
解过JDK的bin目录下其他各种小工具的作用。
随着JDK版本的更迭,这些小工具的数量和功能 也在不知不觉地增加与增强。除了编译和运行Java程序外,
打包、部署、签名、调试、监控、运维等 各种场景都可能会用到它们,这些工具如图4-1所示。
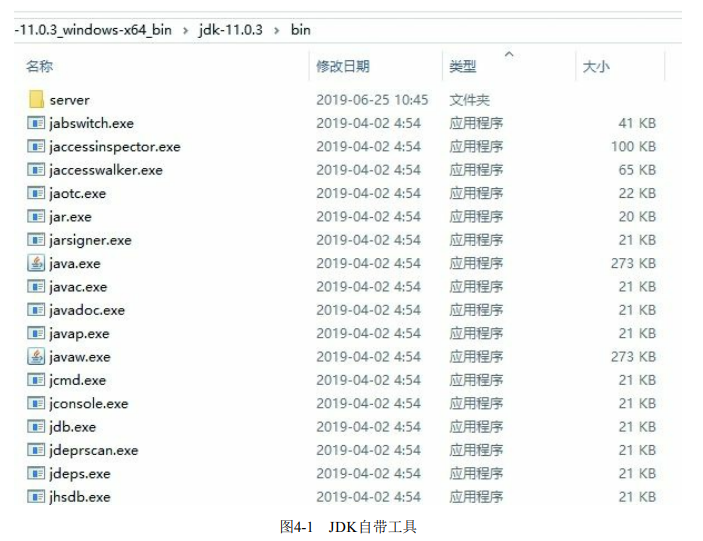
在本章,笔者将介绍这些工具中的一部分,主要是用于监视虚拟机运行状态和进行故障处理的工 具。这些故
障处理工具并不单纯是被Oracle公司作为“礼物”附赠给JDK的使用者,根据软件可用性和授 权的不同,可以把
它们划分成三类:
商业授权工具:主要是JMC(Java Mission Control)及它要使用到的JFR(Java Flight Recorder),JMC
这个原本来自于JRockit的运维
监控套件从JDK 7 Update 40开始就被集成到OracleJDK
中,JDK 11之前都无须独立下载,但是在商业环境中使用它则是要付费的[1]。
正式支持工具:这一类工具属于被长期支持的工具,不同平台、不同版本的JDK之间,这类工具 可能会
略有差异,但是不会出现某一个工具突然消失的情况
实验性工具:这一类工具在它们的使用说明中被声明为“没有技术支持,并且是实验性质 的”(Unsupported and Experimental)产品,日后可能会转正,也可能会在某个JDK版本中无声无息地 消
失。但事实上它们通常都非常稳定而且功能强大,也能在处理应用程序性能问题、定位故障时发挥 很大的作用。
读者如果比较细心的话,还可能会注意到这些工具程序大多数体积都异常小。假如之前没注意 到,现在不妨
再看看图4-1中的最后一列“大小”,各个工具的体积基本上都稳定在21KB左右。并非JDK开发团队刻意把它们制
作得如此精炼、统一,而是因为这些命令行工具大多仅是一层薄包装而 已,真正的功能代码是实现在JDK的工具
类库中的,读者把图4-1和图4-2两张图片对比一下就可以看 得很清楚。
假如读者使用的是Linux版本的JDK,还可以发现这些工具中不少是由Shell脚本直接写 成,可以用文本编辑器
打开并编辑修改它们。
JDK开发团队选择采用Java语言本身来实现这些故障处理工具是有特别用意的:当应用程序部署 到生产环境
后,无论是人工物理接触到服务器还是远程Telnet到服务器上都可能会受到限制。借助这些 工具类库里面的接口
和实现代码,开发者可以选择直接在应用程序中提供功能强大的监控分析功能[4]。
本章所讲解的工具大多基于Windows平台下的JDK进行演示,如果读者选用的JDK版本、操作系 统不同,那
么工具不仅可能数量上有所差别,同一个工具所支持的功能范围和效果都可能会不一样。 本章提及的工具,如无
特别说明,是JDK 5中就已经存在的,但为了避免运行环境带来的差异和兼容 性问题,建议读者使用更高版本的
JDK来验证本章介绍的内容。通常高版本JDK的工具有可能向下兼容运行于低版本JDK的虚拟机上的程序,反之则
一般不行。
注意 如果读者在工作中需要监控运行于JDK 5的虚拟机之上的程序,在程序启动时请添加参数
“-Dcom.sun.management.jmxremote”开启JMX管理功能,否则由于大部分工具都是基于或者要用到JMX
(包括下一节的可视化工具),它们都将无法使用,如果被监控程序运行于JDK 6或以上版本的 虚拟机之上,那
JMX管理默认是开启的,虚拟机启动时无须再添加任何参数。
下面要介绍的这些工具,全部在 jdk/bin/ 目录下。配置了 java 环境变量后,可以直接在 dos 窗口运行启动。
jps:虚拟机进程状况工具
jps(JVM Process Status Tool)可以列出正在运行的虚拟机进 程,并显示虚拟机执行主类(Main Class,
main()函数所在的类)名称以及这些进程的本地虚拟机唯一 ID(LVMID,Local Virtual Machine Identifier).
jps 命令格式
jps [ options ] [ hostid ] jps 还可以通过 RMI 协议查询开启了 RMI 服务的远程虚拟机进程状态,参数 hostid 为 RMI 注册表中注册的主机
名。
options 参数如下表:
| 选项 | 作用 |
| -q | 只输出 LVMID,省略主类名称 |
| -m | 输出虚拟机进程启动时传递给主类 main()函数的参数 |
| -l | 输出主类的全名。如果进程执行的是 jar 包,则输出 jar 包路径 |
| -v | 输出虚拟机进程启动时的 JVM 参数 |
示例:

jstat:虚拟机统计信息监视工具
jstat(JVM Statistics Monitoring Tool)是用于监视虚拟机各种运行状态信息的命令行工具。它可以显示本地或
者远程虚拟机进程中的类加载、内存、垃圾收集、即时编译等运行时数据,
命令格式
jstat [ option vmid [interval[s|ms] [count]] ]对于命令格式中的 VMID 与 LVMID 需要特别说明一下:如果是本地虚拟机进程,VMID 与 LVMID
是一致的;如果是远程虚拟机进程,那 VMID 的格式应当是:
[protocol:][//]lvmid[@hostname[:port]/servername] 参数 interval 和 count 代表查询间隔和次数,如果省略这 2 个参数,说明只查询一次。
假设需要每 250 毫秒查询一次进程 2764 垃圾收集状况,一共查询 20 次,那命令应当是:
jstat -gc 2764 250 20选项 option 代表用户希望查询的虚拟机信息,主要分为三类:类加载、垃圾收集、运行期编译状 况。
参数 option 参考下表:
| 选项 | 作用 |
| -class | 监视类加载,卸载数量,总空间以及类加载所耗费的时间 |
| -gc | 监视 Java 堆状况,包括 Eden 区、2 个 Survivor 区(from 和 to)、老年代、永久代等的容量,已用空间,垃圾收集时间合计等信息 |
| -gccapacity | 监视内容与-gc 基本相同,但输出主要关注 Java 堆各个区域使用到的最大、最小空间 |
| -gcutil | 监视内容与-gc 基本相同,但输出主要关注已使用空间占总空间的百分比。 |
| -gccause | 与-gcutil 功能一样,但是会额外输出导致上一次垃圾收集产生的原因 |
| -gcnew | 监视新生代垃圾收集状况 |
| -gcnewcapacity | 监视内容与-gcnew 基本相同,输出主要关注使用到的最大、最小空间 |
| -gcold | 监视老年代垃圾收集状况 |
示例如下图:
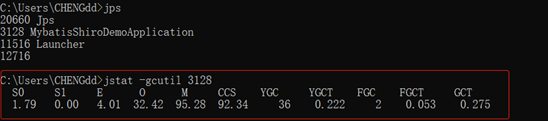
查询结果表明这台服务器
新生代 Eden 区(E,表示 Eden)使用了 4.01%的空间;
2 个 Survivor 区 (S0、S1,表示 Survivor0、Survivor1)各使用了 1.79%、0%;
老年代(O,表示 Old),使用 32.42%;
元数据区(M, 表实 Mete),使用 95.28%;
压缩使用比例(CCS),使用 92.34%;
程序运行以来共发生
Minor GC(YGC,表示 Young GC)36 次,耗时(YGCT, 表示 Young GC TIme)0.222 秒;
发生 Full GC(FGC,表示 Full GC)2 次,耗时(FGCT,表示 Full GC Time)为 0.053 秒;
所有 GC 总耗时(GCT,表示 GC Time)为 0.275 秒。
jinfo:Java配置信息工具
jinfo(Configuration Info for Java)的作用是实时查看和调整虚拟机各项参数。
命令格式:
jinfo [ option ] pid使用如下:

jmap:Java内存映像工具
jmap(Memory Map for Java)命令用于生成堆转储快照(一般称为 heapdump 或 dump 文件)。
如果不使用 jmap 命令,要想获取 Java 堆转储快照也还有一些比较“暴力”的手段:譬如 XX:
+HeapDumpOnOutOfMemoryError 参数,可以让虚拟机在内存溢出异常出现之后自动生成堆转储快照文件,
通过-XX:+HeapDumpOnCtrlBreak 参数则可以使用[Ctrl]+[Break]键让虚拟机生成堆转储快照文件,又或者在
Linux 系统下通过 Kill-3 命令发送进程退出信号“恐吓”一下虚拟机,也能顺利拿到堆转储快照。
命令格式
jmap [ option ] vmid上面 vmid 为进程号,option 参数可选如下表:
| 选项 | 作用 |
| -dump | 生成 java 堆转储快照。格式为:-dump:[live,]format=b,file=,其中 live 子参数说明是否只 dump 出存活对象。 |
| -finalizerinfo | 显示在 F-Queue 中等待 Finalizer 线程执行 finalize 方法的对象。只在 Linux/Solaris 平台下有效 |
| -heap | 显示 java 堆详细信息,如使用那种回收器、参数配置、分代状况等。只在 Linux/Solaris 平台下有效。 |
| -histo | 显示堆中对象统计信息,包括类、实例数量、合计容量 |
| -permstat | 以 ClassLoader 为统计口径显示永久代内存状态。只在 Linux/Solaris 平台下有效 |
| -F | 当虚拟进程对-dump 选项没有响应时,可使用这个选项强制生成 dump 快照。只在 Linux/Solaris 平台下有效。 |
示例:
现在我的 idea 正跑着一个 springboot 项目,用-jps 查看其进程号为 3128

生成的文件在 C:\Users\CHENGdd\目录下,如下图:

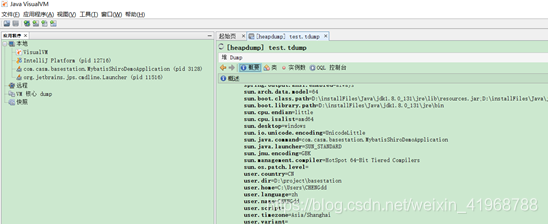
Dump 出来的文件建议用 JDK 自带的 VisualVM 或 Eclipse 的 MAT 插件打开(当然也可以用下面 8.1.5 将要介绍的方法打开)。
下面我们在 VisualVM 中打开如下:
jhat:虚拟机堆转储快照分析工具
JDK 提供 jhat(JVM Heap Analysis Tool)命令与 jmap 搭配使用,来分析 jmap 生成的堆转储快照。jhat 内置
了一个微型的 HTTP/Web 服务器,生成堆转储快照的分析结果后,可以在浏览器中查看。
一般很少用 jhat 分析堆转储快照。功能简陋,多使用后面将要介绍到的 VisualVM。
格式
jhat dump 文件示例:
浏览器访问:localhost:7000,如下:
jstack:Java堆栈跟踪工具
jstack(Stack Trace for Java)命令用于生成虚拟机当前时刻的线程快照
(一般称为 threaddump 或者 javacore 文件)。
线程快照就是当前虚拟机内每一条线程正在执行的方法堆栈的集合,生成线程快照的目的通常是定位线程出现长
时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间挂起等,都是导致线程长时间停顿的常见
原因。
线程出现停顿时通过 jstack 来查看各个线程的调用堆栈,就可以获知没有响应的线程到底在后台做些什么事情,
或者等待着什么资源。
格式
jstack [ option ] vmidoption 选项的合法值与具体含义如下表:
| 选项 | 作用 |
| -F | 当正常输出的请求不被响应时,强制输出线程堆栈 |
| -l | 除堆栈外显示锁的附加信息 |
| -m | 如果调用本地方法的话,可以显示 C/C++的堆栈 |
示例
3128 为 idea 上运行的一个 springboot 项目进程号,可用 jps 命令查看
其它基础工具
请参考深入理解 JVM 第三版书籍
3. JVM 故障诊断:可视化工具(WIP)
JDK中除了附带大量的命令行工具外,还提供了几个功能集成度更高的可视化工具(上一章重点讲解了命令
行工具),用户可以使 用这些可视化工具以更加便捷的方式进行进程故障诊断和调试工作。
这类工具主要包括JConsole、 JHSDB、VisualVM和JMC四个。
本篇者准备了一些代码样例,稍后将会使用几款工具去监控、分析这些代码存在的问题,算是本节简单的 实
战演练。读者可以把在可视化工具观察到的数据、现象,与前面两章中讲解的理论知识进行互相验 证。
3.1. JHSDB:基于服务性代理的调试工具
JHSDB是一款基于服务性代理实现的进程外调试工具。服务性代理是 HotSpot虚拟机中一组用于映射Java虚
拟机运行信息的、主要基于Java语言(含少量JNI代码)实现的 API集合。
1> 要验证的代码
本次,我们要借助JHSDB来分析一下下面代码,并通过实验来回答一个简单问 题:staticObj、
instanceObj、localObj这三个变量本身(而不是它们所指向的对象)存放在哪里?
答案了解过JVM模型的应该都知道:首先所指的对象,毫无疑问肯定是堆当中,staticObj随着Test的类型信
息存放在方法区,instanceObj随着Test的对象实 例存放在Java堆,localObject则是存放在foo()方法栈帧的局部
变量表中。现在要做的是通过JHSDB来实践验证这一点。
启动参数:
-Xmx10m -XX:+UseSerialGC -XX:-UseCompressedOops-XX:-UseCompressedOops:开启普通对象指针压缩,会在内存中消耗20个字节,o指针占4个字节,Object对象占16个字节。不开启
的话,会在内存中消耗24个字节,o 指针占8个字节,Object对象占16个字节。
public class JHSDB_TestCase {
static class Test {
static ObjectHolder staticObj = new ObjectHolder();
ObjectHolder instanceObj = new ObjectHolder();
void foo() {
ObjectHolder localObj = new ObjectHolder();
System.out.println("done"); // 这里设一个断点
}
}
private static class ObjectHolder {
}
public static void main(String[] args) {
Test test = new JHSDB_TestCase.Test();
test.foo();
}
}首先,我们要确保这三个变量已经在内存中分配好,然后将程序暂停下来,以便有空隙进行实 验,这只要把
断点设置在固定的地方,然后在调试模式下运行程序即可。
2> 启动JHSDB
启动方式:JHSDB使用 - 某人人莫 - 博客园
然后 jps -l 查询要监控应用的进程id

通过以下步骤我们就可以开启监控该进程下的项目情况:
3> 在堆当中寻找对象
既然我们要查找引用这三个对象的指针存放在哪里,不妨从这三个对象开 始着手,先把它们从Java堆中找出来。
运行参数中指定了使 用的是Serial收集器,图中我们看到了典型的Serial的分代内存布局,Heap Parameters窗口
中清楚列出了 新生代的Eden、S1、S2和老年代的容量(单位为字节)以及它们的虚拟内存地址起止范围。
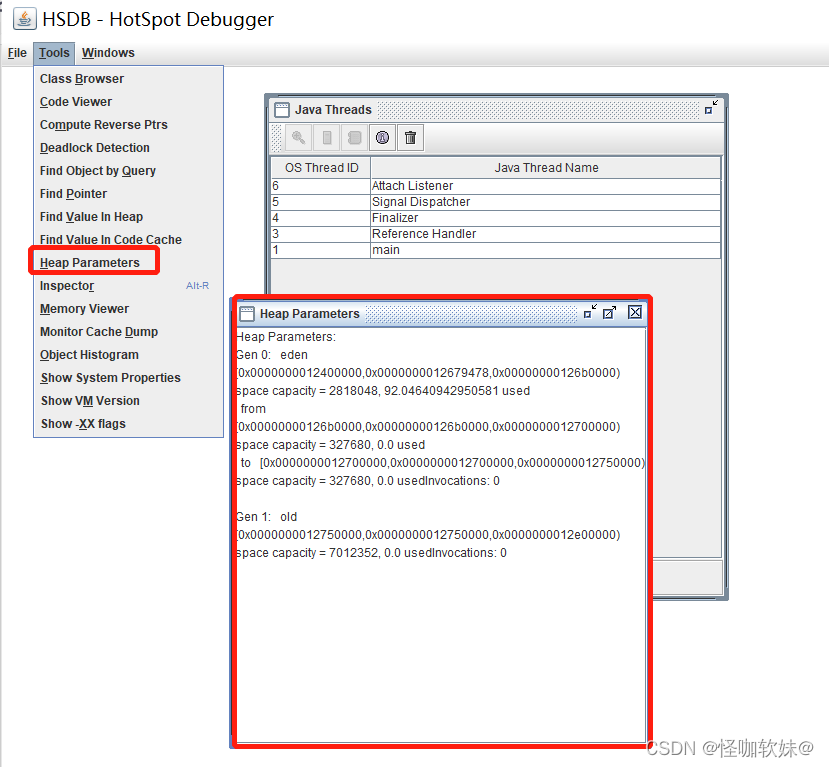
打开Windows->Console窗 口,使用scanoops命令在Java堆的新生代(从Eden起始地址到To Survivor结束地
址)范围内查找 ObjectHolder的实例,结果如下所示:
在内存当中,内存首先都是连着的,而下面这个命令的意思就是查找堆当中0x0000000012400000 到
0x0000000012750000 内存当中的对象位置。
scanoops 0x0000000012400000 0x0000000012750000 com/gzl/cn/JHSDB_TestCase$ObjectHolder- com/gzl/cn/是包名
- JHSDB_TestCase是类名
- $只是一个类名和对象名的连接符
- ObjectHolder对象的类名
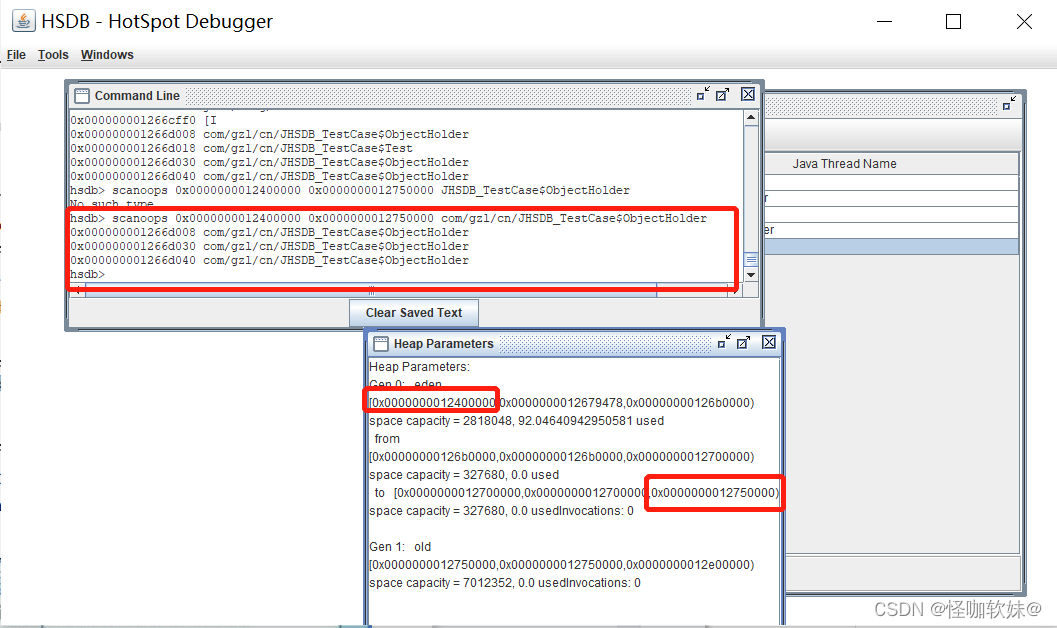
果然找出了三个实例的地址,而且它们的地址都落到了Eden的范围之内,算是顺带验证了一般情 况下新对
象在Eden中创建的分配规则。
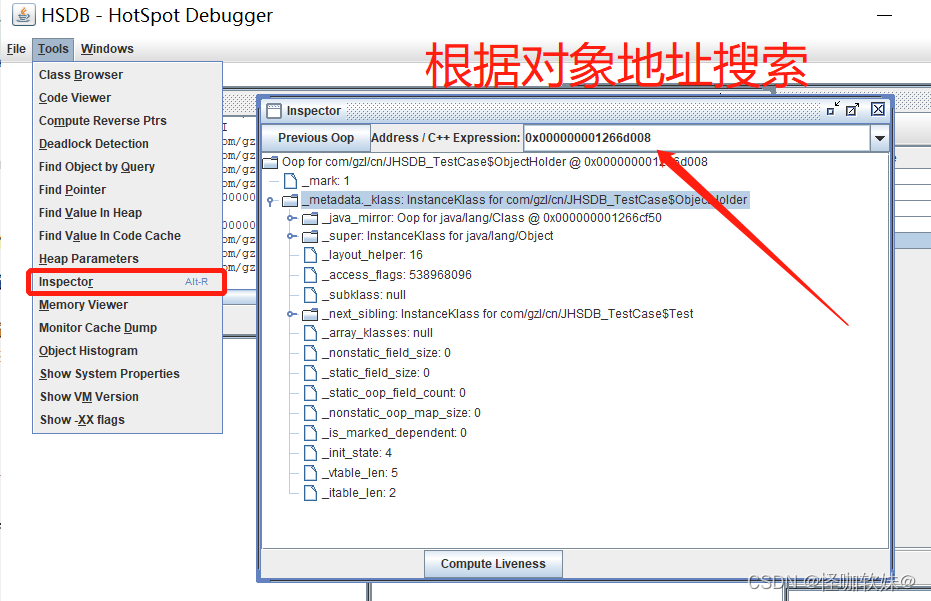
再使用Tools->Inspector功能确认一下这三个地址中存放的对 象,结果如图所示。
3> 查看对象详情
Inspector就是可以查看指定内存的对象的详情。也可以查看变量指向的地址。
也可以查看对象属性当中指向的别的对象的地址。
但是有一点不能查出,就是哪个指针指向了他,在这块是查不出来的。
Inspector为我们展示了对象头和指向对象元数据的指针,里面包括了Java类型的名字、继承关 系、实现接口关
系,字段信息、方法信息、运行时常量池的指针、内嵌的虚方法表(vtable)以及接口 方法表(itable)等。
由于我们的确没有在ObjectHolder上定义过任何字段,所以图中并没有看到任何 实例字段数据,读者在做实验时
不妨定义一些不同数据类型的字段,观察它们在HotSpot虚拟机里面是 如何存储的。
4> 找出 堆中 引用它们的指针
接下来要根据堆中对象实例地址找出引用它们的指针,还是在window界面的console界面当中使用命令查询:
revptrs 命令的功能就是根据内存地址 查找 堆当中 哪个变量地址 指向了这个对象地址。
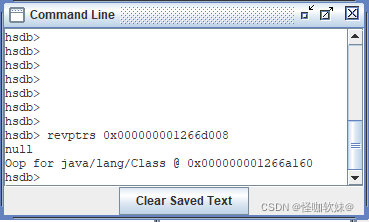
果然找到了一个引用该对象的地方,是在一个java.lang.Class的实例里,并且给出了这个实例的地 址,通过
Inspector查看该对象实例,可以清楚看到这确实是一个java.lang.Class类型的对象实例,里面 有一个名为
staticObj的实例字段,如图所示。并且staticObj指向了刚刚查到的对象。
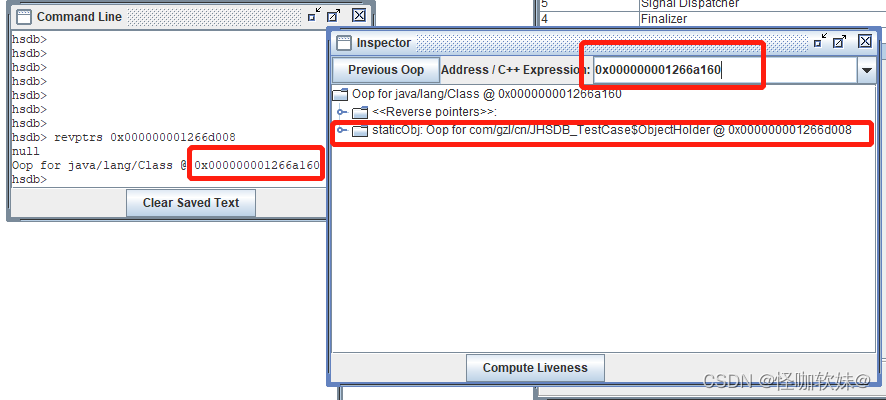
JDK 7及其以后版本的HotSpot虚拟机选择把静态变量与类型在Java语言一端的映射Class对 象存放在一起,存储
于Java堆之中,从我们的实验中也明确验证了这一点。接下来继续查找第二个 对象实例:
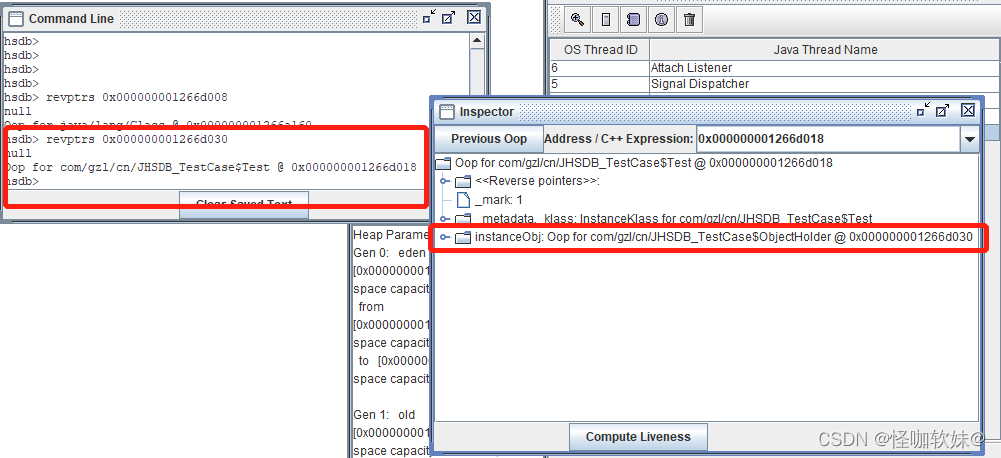
这个结果完全符合我们的预期,第二个ObjectHolder的指针是在Java堆中JHSDB_TestCase$Test对 象的
instanceObj字段上。但是我们采用相同方法查找第三个ObjectHolder实例时,JHSDB返回了一个 null,表示未
查找到任何结果:
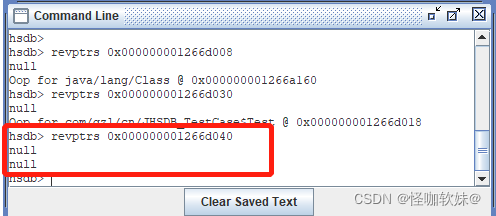
找出 栈中 引用它们的指针
看来revptrs命令并不支持查找栈上的指针引用,不过没有关系,得益于我们测试代码足够简洁, 人工也可以来完
成这件事情。在Java Thread窗口选中main线程后点击Stack Memory按钮查看该线程的 栈内存。
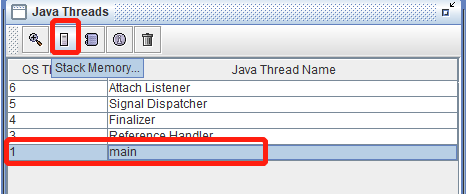
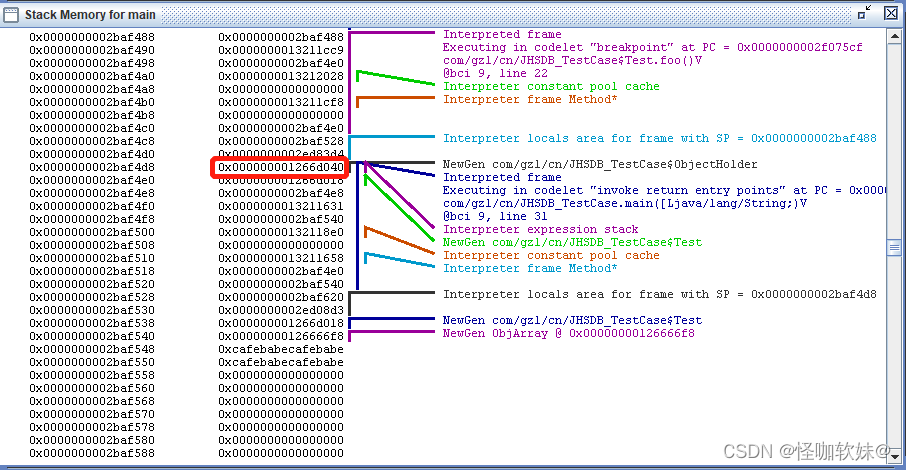
这个线程只有两个方法栈帧,尽管没有查找功能,但通过肉眼观察在地址0x0000000002baf4d8上 的值正好就是
0x000000001266d040,而且JHSDB在旁边已经自动生成注释,说明这里确实是引用了一ObjectHolder对象。
至此,本次实验中三个对象均已找到,并成功追 溯到引用它们的地方,也就实践验证了开篇中提出的这些对象的
引用是存储在什么地方的问题。
注意:在JDK 7以前,即还没有开始“去永久代”行动时,这些静态变量是存放在永久代上的,JDK 7起把 静态变
量、字符常量这些从永久代移除出去。
3.2. JConsle:Java监视与管理控制台
JConsole(Java Monitoring and Management Console)是一款基于JMX(Java Manage-ment
Extensions)的可视化监视、管理工具。
它的主要功能是通过JMX的MBean(Managed Bean)对系统进 行信息收集和参数动态调整。
JMX是一种开放性的技术,不仅可以用在虚拟机本身的管理上,还可以 运行于虚拟机之上的软件中,典型的如中
间件大多也基于JMX来实现管理与监控。
虚拟机对JMX MBean的访问也是完全开放的,可以使用代码调用API、支持JMX协议的管理控制台,或者其他符
合 JMX规范的软件进行访问。
1> 启动JConsole
通过JDK/bin目录下的jconsole.exe启动JCon-sole后,会自动搜索出本机运行的所有虚拟机进程,而不需要用户
自己使用jps来查询。双击选择其中一个进程便可进入主界面开始监控。 JMX支持跨服务器的管理,也可以使用下
面的“远程进程”功能来连接远程服务器,对远程虚拟机进行监控。
双击它进入JConsole主界面,可以看到主 界面里共包括“概述”“内存”“线程”“类”“VM摘
要”“MBean”六个页签,如图所示。
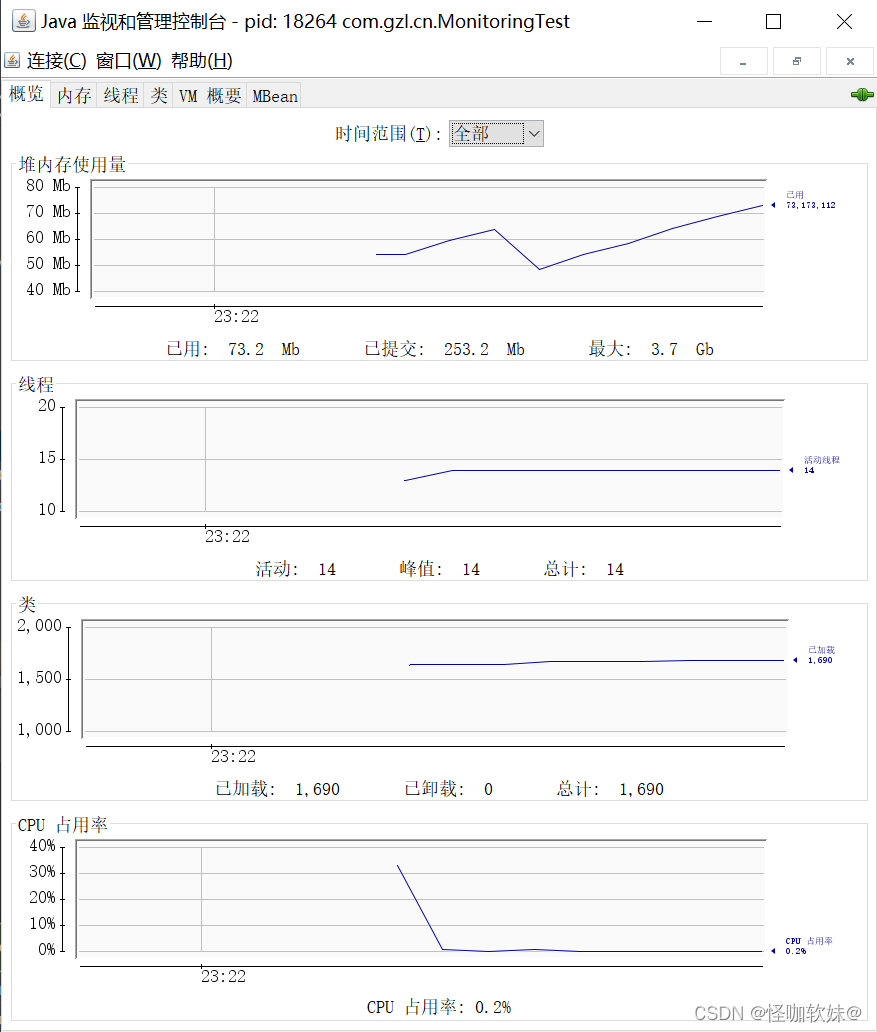
“概述”页签里显示的是整个虚拟机主要运行数据的概览信息,包括“堆内存使用情况”“线 程”“类”“CPU
使用情况”四项信息的曲线图。
2> 内存监控
“内存”页签的作用相当于可视化的jstat命令,用于监视被收集器管理的虚拟机内存(被收集器直 接管理的Java
堆和被间接管理的方法区)的变化趋势。我们通过运行代码来体验一下 它的监视功能。
运行时设置的虚拟机参数为:
-Xms100m -Xmx100m -XX:+UseSerialGC这里MonitoringTest是笔者准备的“反面教材”代码之一,代码如下:
import java.util.ArrayList;
import java.util.List;
public class MonitoringTest {
/*** 内存占位符对象,一个OOMObject大约占64KB */
static class OOMObject {
public byte[] placeholder = new byte[64 * 1024];
}
public static void fillHeap(int num) throws InterruptedException {
List<OOMObject> list = new ArrayList<OOMObject>();
for (int i = 0; i < num; i++) {
// 稍作延时,令监视曲线的变化更加明显
Thread.sleep(50);
list.add(new OOMObject());
}
System.gc();
}
public static void main(String[] args) throws Exception {
fillHeap(1000);
}
}这段代码的作用是以64KB/50ms的速度向Java堆中填充数据,一共填充1000次,使用JConsole 的“内存”页签
进行监视,观察曲线和柱状指示图的变化。
注意:由于打开JConsole 还需要一定的时间,可以进行打断点拦截,然后等打开连接上之后再放开断点。
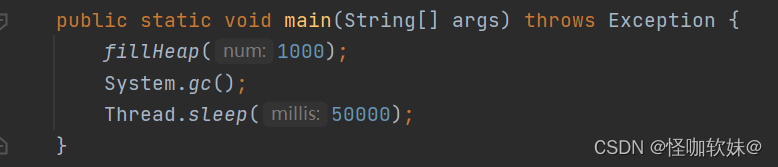
程序运行后,在“内存”页签中可以看到内存池Eden区的运行趋势呈现折线状,如下图所示。监 视范围扩大至整
个堆后,会发现曲线是一直平滑向上增长的。从柱状图可以看到,在1000次循环执行 结束,运行了System.gc()
后,虽然整个新生代Eden被清空了,但是代表老年代的柱 状图仍然保持峰值状态,说明被填充进堆中的数据在
System.gc()方法执行之后仍然存活。笔者的分析 就到此为止,提两个小问题供读者思考一下,答案稍后公布。
- 虚拟机启动参数只限制了Java堆为100MB,但没有明确使用-Xmn参数指定新生代大小,读者 能否从监控图中估算出新生代的容量?
- 为何执行了System.gc()之后,下中代表老年代的柱状图仍然显示峰值状态,代码需要如何 调整才能让System.gc()回收掉填充到堆中的对象?
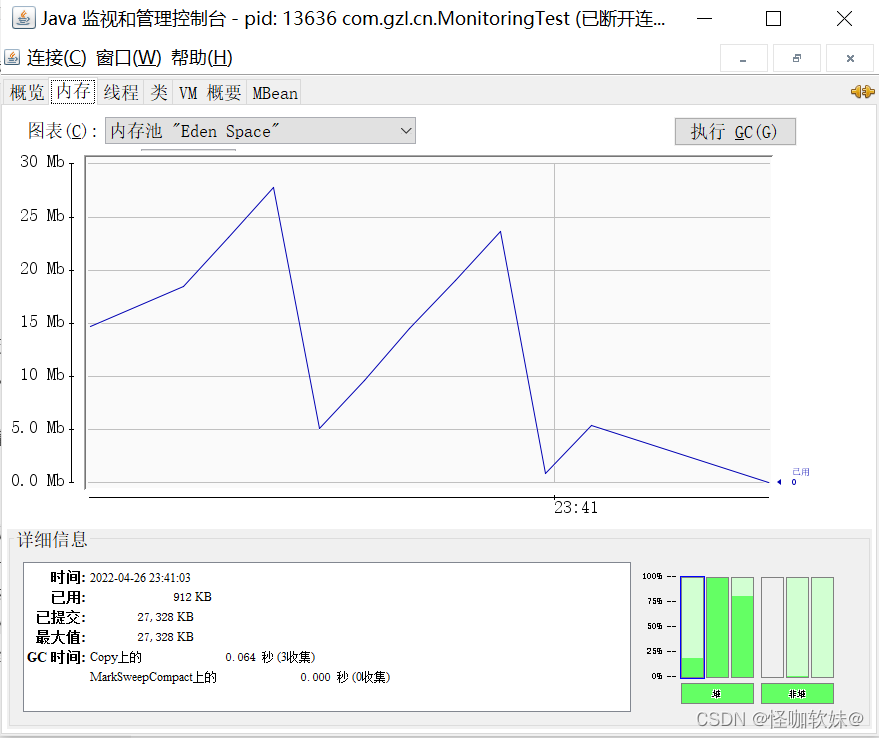
从这里还可以发现一点,survivor当中一直是满的状态,原因就是对象一直存活,导致只能担保向老年代存放。
问题1答案:上图显示Eden空间为27328KB,因为没有设置-XX:SurvivorRadio参数,所以Eden 与Survivor空
间比例的默认值为8∶1,因此整个新生代空间大约为27328KB×125%=34160KB。
问题2答案:执行System.gc()之后,空间未能回收是因为Listlist对象仍然存活, fillHeap()方法仍然没有退出,因
此list对象在System.gc()执行时仍然处于作用域之内。如果把 System.gc()移动到fillHeap()方法外调用就可以回收
掉全部内存。
通过以下试验,确实可以清空内存,但是要注意记着要GC过后,进行等待一段时间,不然他可能垃圾没清理完,
垃圾收集是单独的线程,主线程已经终止了,会导致你看到老年代根本没释放出去。
3> 线程监控
如果说JConsole的“内存”页签相当于可视化的jstat命令的话,那“线程”页签的功能就相当于可视化 的jstack
命令了,遇到线程停顿的时候可以使用这个页签的功能进行分析。线程长时间停顿的主要原因有等待外部资源
(数据库连接、网络资源、设备资源等)、死循环、锁等 待等,以下代码将分别演示这几种情况。
代码示例:
import java.io.BufferedReader;
import java.io.InputStreamReader;
public class ThreadTest {
/*** 线程死循环演示 */
public static void createBusyThread() {
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
while (true)
{
;
}
}
}, "testBusyThread");
thread.start();
}
/*** 线程锁等待演示 */
public static void createLockThread(final Object lock) {
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
synchronized (lock) {
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}, "testLockThread");
thread.start();
}
public static void main(String[] args) throws Exception {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
br.readLine();
createBusyThread();
br.readLine();
Object obj = new Object();
createLockThread(obj);
}
}Object的方法:Wait()方法和notify()方法:当一个线程执行到wait()方法时,它就进入到一个和该对象相关的等
待池中,同时失去了对象的机锁。
当它被一个notify()方法唤醒时,等待池中的线程就被放到了锁池中。该线程从锁池中获得机锁,然后回到wait()
前的中断现场。
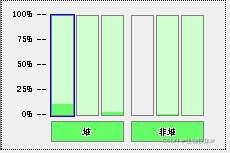
程序运行后,首先在“线程”页签中选择main线程,如下图所示。堆栈追踪显示BufferedReader的 readBytes()
方法正在等待System.in的键盘输入,这时候线程为Runnable状态,Runnable状态的线程仍会 被分配运行时间,
但readBytes()方法检查到流没有更新就会立刻归还执行令牌给操作系统,然后等待输入到控制台,并且点击回车
键告诉流写完了,而readBytes就是读的控制台的,这种等待 只消耗很小的处理器资源。
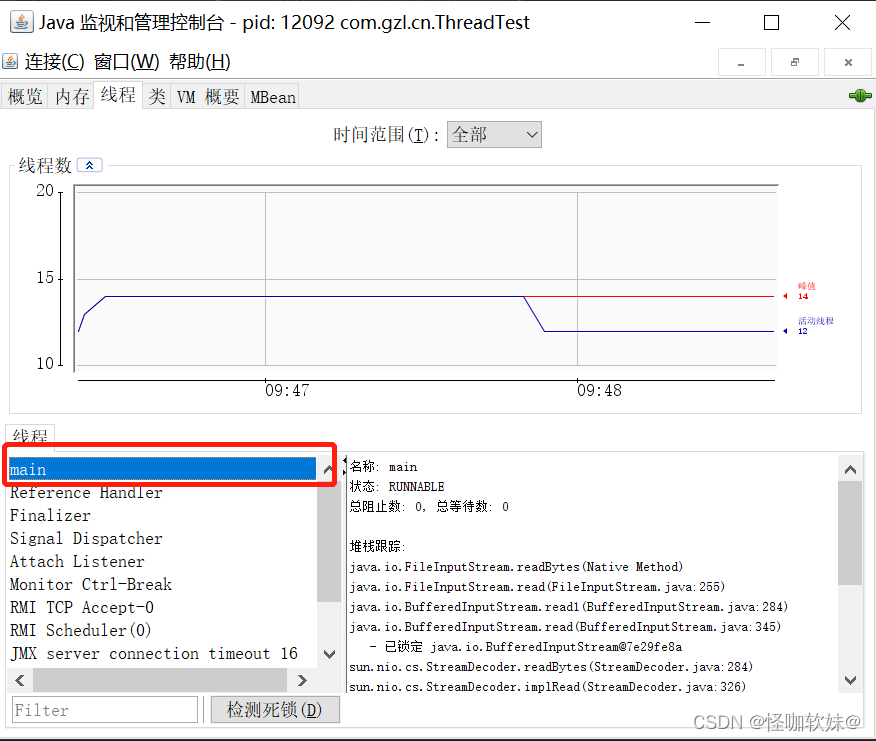
接着监控testBusyThread线程,如下图所示。testBusyThread线程一直在执行空循环,从堆栈追 踪中看到一直在
MonitoringTest.java代码的12行停留,12行的代码为while(true)。这时候线程为Runnable 状态,而且没有归还
线程执行令牌的动作,所以会在空循环耗尽操作系统分配给它的执行时间,直到 线程切换为止,这种等待会消耗
大量的处理器资源。
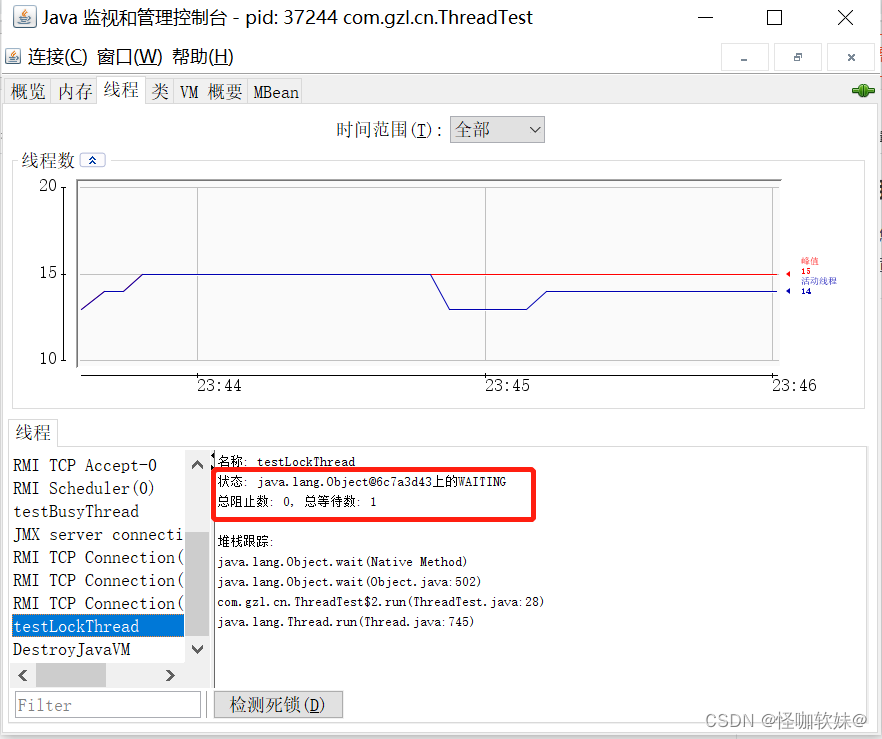
再次控制台输入字符,然后点击enter开启testLockThread线程,显示testLockThread线程在等待lock对象的
notify()或notifyAll()方法的出现,线程这时候处于 WAITING状态,在重新唤醒前不会被分配执行时间。
testLockThread线程正处于正常的活锁等待中,只要lock对象的notify()或notifyAll()方法被调用, 这个线程便能
激活继续执行。
4> 监控死锁
下面演示了一个无法再被激活的死锁等待。
代码示例:
public class ThreadTest1 {
/*** 线程死锁等待演示 */
static class SynAddRunalbe implements Runnable {
int a, b;
public SynAddRunalbe(int a, int b) {
this.a = a;
this.b = b;
}
@Override
public void run() {
synchronized (Integer.valueOf(a)) {
synchronized (Integer.valueOf(b)) {
System.out.println(a + b);
}
}
}
}
public static void main(String[] args) {
for (int i = 0; i < 100; i++) {
new Thread(new SynAddRunalbe(1, 2)).start();
new Thread(new SynAddRunalbe(2, 1)).start();
}
}
}这段代码开了200个线程去分别计算1+2以及2+1的值,理论上for循环都是可省略的,两个线程也 可能会导致死
锁,不过那样概率太小,需要尝试运行很多次才能看到死锁的效果。如果运气不是特别 差的话,上面带for循环的
版本最多运行两三次就会遇到线程死锁,程序无法结束。
造成死锁的根本原 因是Integer.valueOf()方法出于减少对象创建次数和节省内存的考虑,会对数值为-128~127
之间的 Integer对象进行缓存,如果valueOf()方法传入的参数在这个范围之内,就直接返回缓存中的对象。 也就
是说代码中尽管调用了200次Integer.valueOf()方法,但一共只返回了两个不同的Integer对象(1和2对象)。假
如 某个线程的两个synchronized块之间发生了一次线程切换,那就会出现线程A在等待被线程B持有的
Integer.valueOf(1),线程B又在等待被线程A持有的Integer.valueOf(2),结果大家都跑不下去的情况。
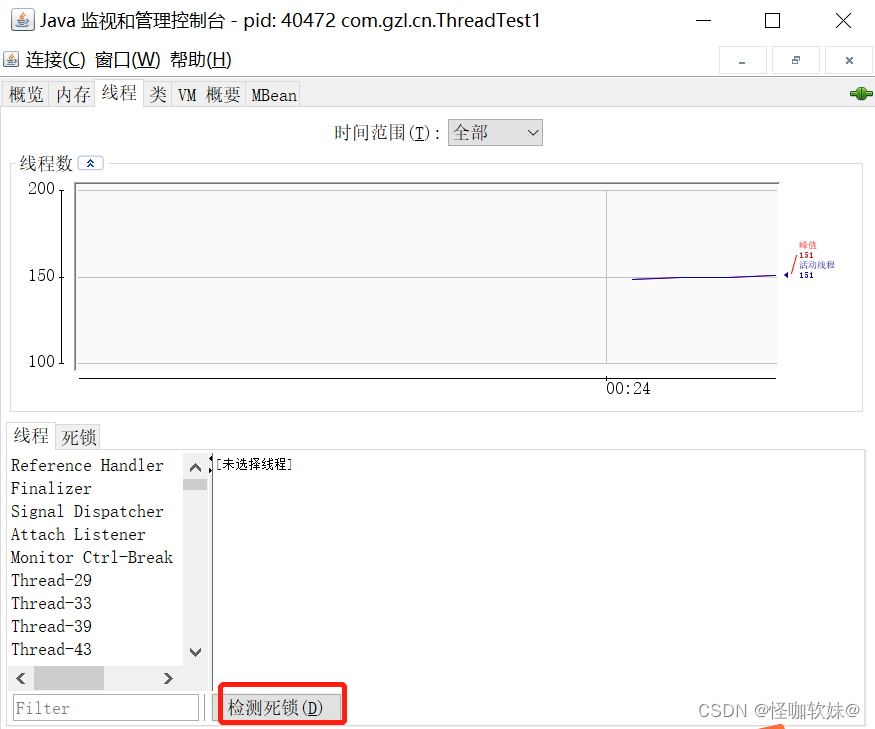
运行结果:
运行之后会发现程序卡着不动了,没错就是死锁了。打开JConsole,点击检测死锁。
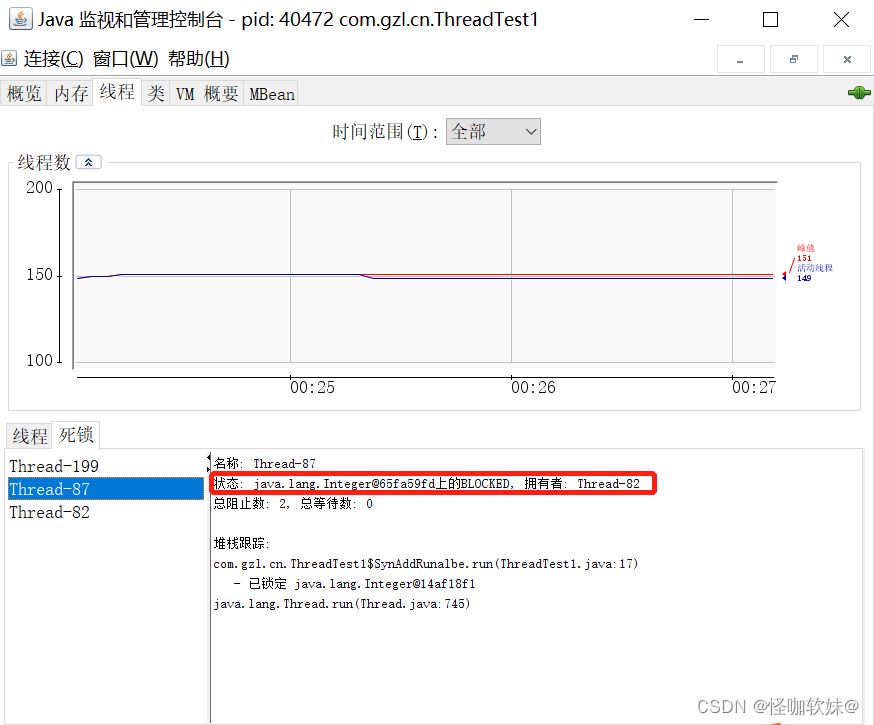
线程Thread-87在等待一个被线程Thread-82持有的Integer对象,而点击线 程Thread-82则显示它也在等待一个
被线程Thread-87持有的Integer对象,这样两个线程就互相卡住,除 非牺牲其中一个,否则死锁无法释放。
3.3. VisualVM:多合-故障处理工具
VisualVM(All-in-One Java Troubleshooting Tool)是功能最强大的运行监视和故障处理程序之一, 曾经在很
长一段时间内是Oracle官方主力发展的虚拟机故障处理工具。
VisualVM中“概述”“监视”“线程”“MBeans”的功能与前面介绍的JConsole差别不大,读者可根据上 一节
内容类比使用,这里笔者挑选几个有特色的功能和插件进行简要介绍。
https://jingyan.baidu.com/article/6525d4b102c3c0ec7c2e9416.html
1> 启动VisualVM
在jdk的bin目录下,不用安装就可以使用
打开之后的样子
通过命令也可以直接打开 jvisualvm
2> VisualVM插件安装
VisualVM基于NetBeans平台开发工具,所以一开始它就具备了通过插件扩展功能的能力,有了插 件扩展支持,VisualVM可以做到:
- 显示虚拟机进程以及进程的配置、环境信息(jps、jinfo)。
- 监视应用程序的处理器、垃圾收集、堆、方法区以及线程的信息(jstat、jstack)。
- dump以及分析堆转储快照(jmap、jhat)。
- 方法级的程序运行性能分析,找出被调用最多、运行时间最长的方法。
- 离线程序快照:收集程序的运行时配置、线程dump、内存dump等信息建立一个快照,可以将快 照发送开发者处进行Bug反馈。
- 其他插件带来的无限可能性。
初始状态下的VisualVM并没有加载 任何插件,虽然基本的监视、线程面板的功能主程序都以默认插件的形式提
供,但是如果不在 VisualVM上装任何扩展插件,就相当于放弃它最精华的功能,和没有安装任何应用软件的操作
系统差 不多。
怎么安装插件?
点击工具-》然后有插件选项,这里我在检测可用插件的时候直接报错了。
这是因为插件中心的地址不可用,处理方式如下:
1、打开网址:https://visualvm.github.io/pluginscenters.html
2、在右侧选择JDK版本
3、我用的jdk1.8.0_101版本,然后复制的上面那段保存后就可以了。
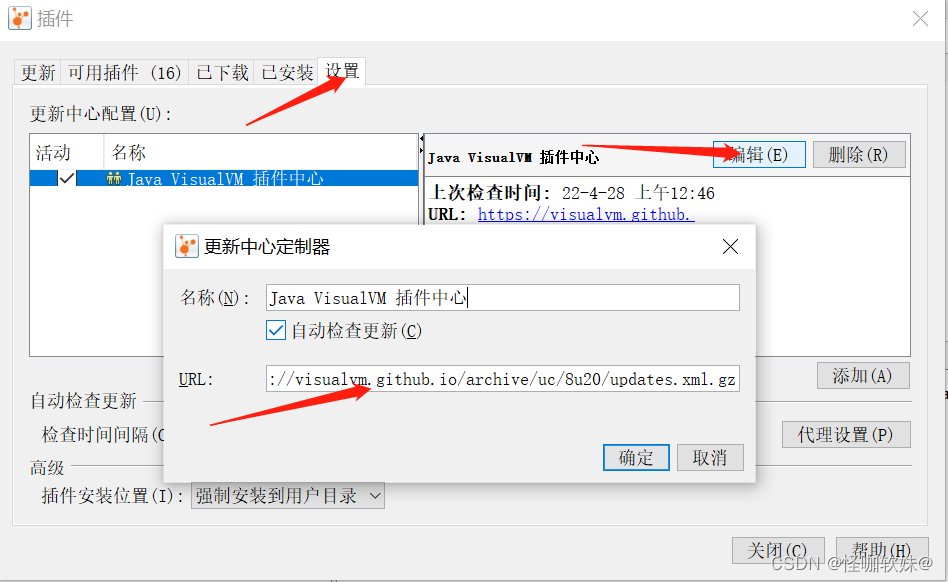
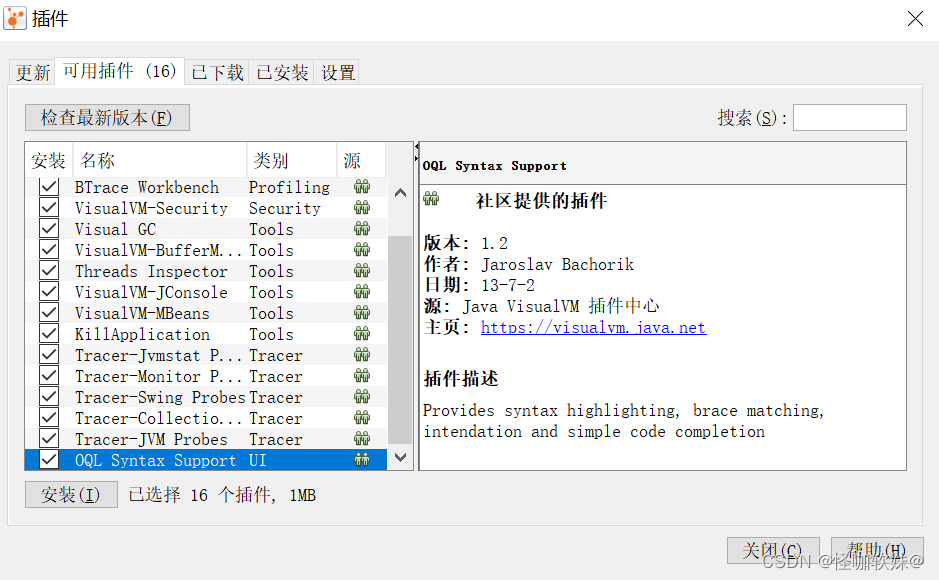
3> 开始安装插件
可根据自己的工作需要和兴趣选择合适的插件,然后点击“安装”按钮,弹出如下图所示的 下载进度窗口,跟着
提示操作即可完成安装。
VisualVM中“概述”“监视”“线程”“MBeans”的功能与前面介绍的JConsole差别不大,读者可根据上 一节内容类比使用,这里笔者挑选几个有
特色的功能和插件进行简要介绍。
4> 生成、浏览堆转储快照
在VisualVM中生成堆转储快照文件有两种方式,可以执行下列任一操作:
- 在“应用程序”窗口中右键单击应用程序节点,然后选择“堆Dump”。
- 在“应用程序”窗口中双击应用程序节点以打开应用程序标签,然后在“监视”标签中单击“堆 Dump”。
生成堆转储快照文件之后,应用程序页签会在该堆的应用程序下增加一个以[heap-dump]开头的子 节点,并且在主页签中打开该转储快
照,如下图所示。如果需要把堆转储快照保存或发送出去,就 应在heapdump节点上右键选择“另存为”菜单,否则当VisualVM关闭时,
生成的堆转储快照文件会被当 作临时文件自动清理掉。打开一个已经存在的堆转储快照文件,通过文件菜单中的“装入”功能, 选择硬盘上
的文件即可。
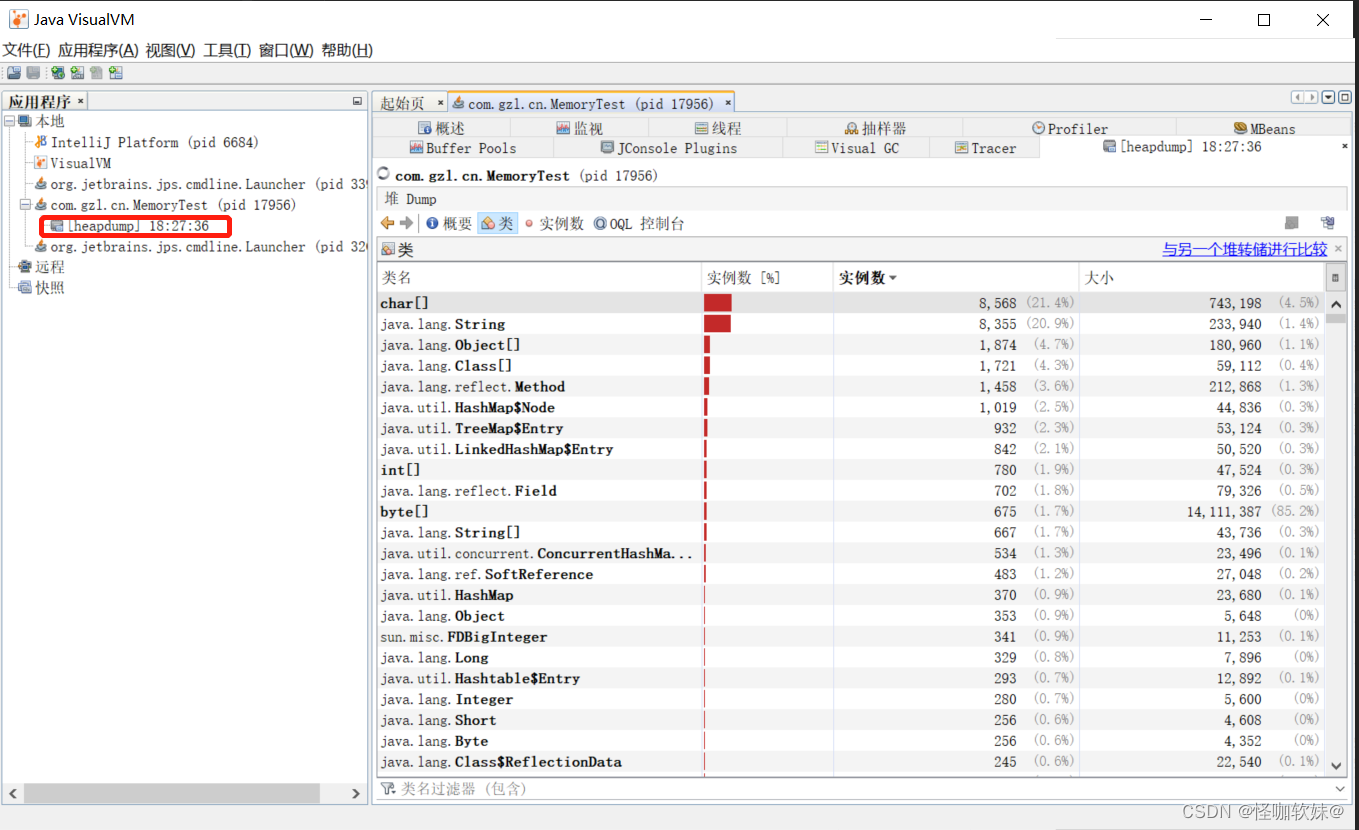
- 概要面板可以看到应用程序dump时的运行时参数、System.getPro-perties()的内容、 线程堆栈等信息
- 类面板则是以类为统计口径统计类的实例数量、容量信息;
- 实例面板不能直接 使用,因为VisualVM在此时还无法确定用户想查看哪个类的实例,所以需要通过“类”面板进入, 在“类”中选择一需要查看的类,然后双击即可在“实例”里面看到此类的其中500个实例的具体属性信 息;
- OQL控制台面板则是运行OQL查询语句的,同jhat中介绍的OQL功能一样。
5> 分析程序性能
在Profiler页签中,VisualVM提供了程序运行期间方法级的处理器执行时间分析以及内存分析。做 Profiling分析
肯定会对程序运行性能有比较大的影响,所以一般不在生产环境使用这项功能,或者改用 JMC来完成,JMC的
Profiling能力更强,对应用的影响非常轻微。
要开始性能分析,先选择“CPU”和“内存”按钮中的一个,然后切换到应用程序中对程序进行操 作,VisualVM
会记录这段时间中应用程序执行过的所有方法。
- 如果是进行处理器执行时间分析,将会 统计每个方法的执行次数、执行耗时;
- 如果是内存分析,则会统计每个方法关联的对象数以及这些对 象所占的空间。等要分析的操作执行结束后,点击“停止”按钮结束监控过程,如下所示。
注意 在JDK 5之后,在客户端模式下的虚拟机加入并且自动开启了类共享——这是一个在多 虚拟机进程共享rt.jar中类数据以提高加载速度
和节省内存的优化,而根据相关Bug报告的反映, VisualVM的Profiler功能会因为类共享而导致被监视的应用程序崩溃,所以读者进行
Profiling前,最好在 被监视程序中使用-Xshare:off参数来关闭类共享优化。
发现问题:点击开始分析的时候不管-Xshare:off关闭没关闭,都连不上,直接一直如下图一样在转圈。
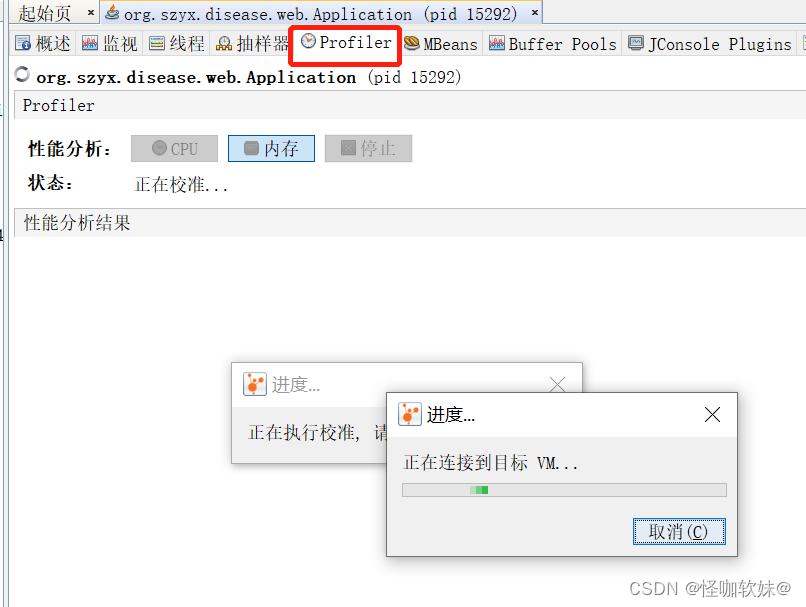
使用如下命令进行启动VisualVM即可解决:
jvisualvm -J-Dorg.netbeans.profiler.separateConsole=true -J即表示JVM OPTION:允许带JVM参数启动
连上之后程序当中会出现如下日志:

这个是分析的内存
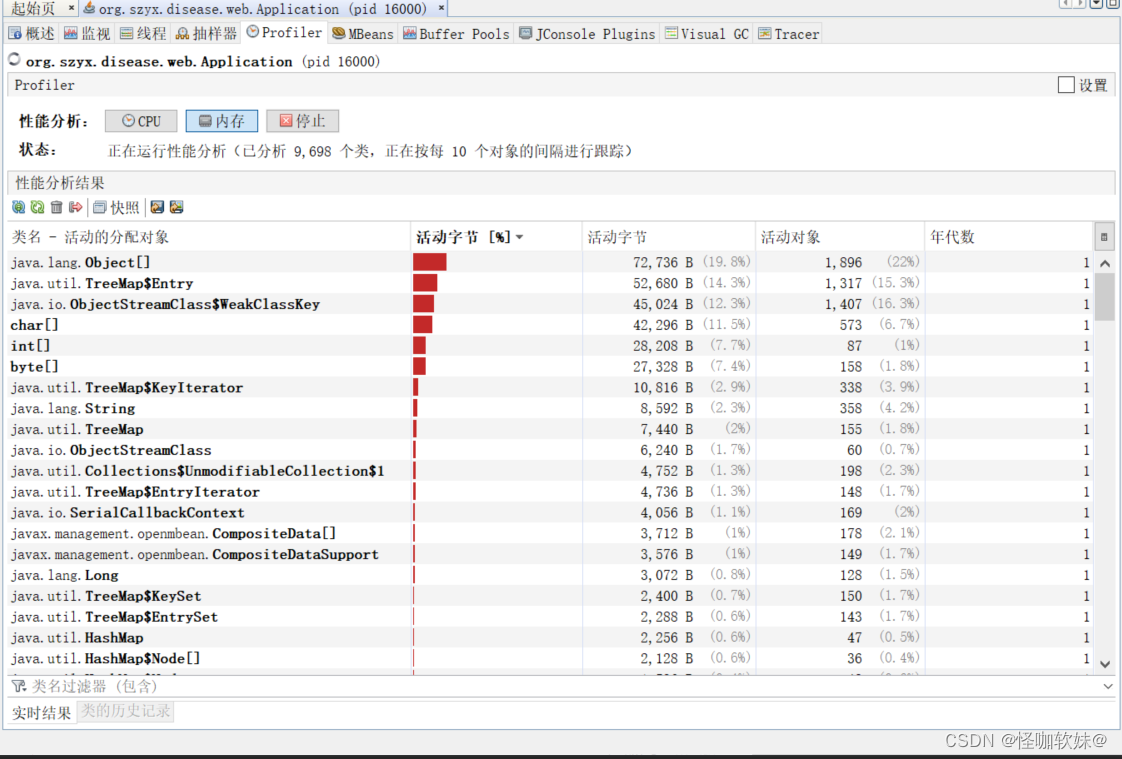
这是分析的cpu:
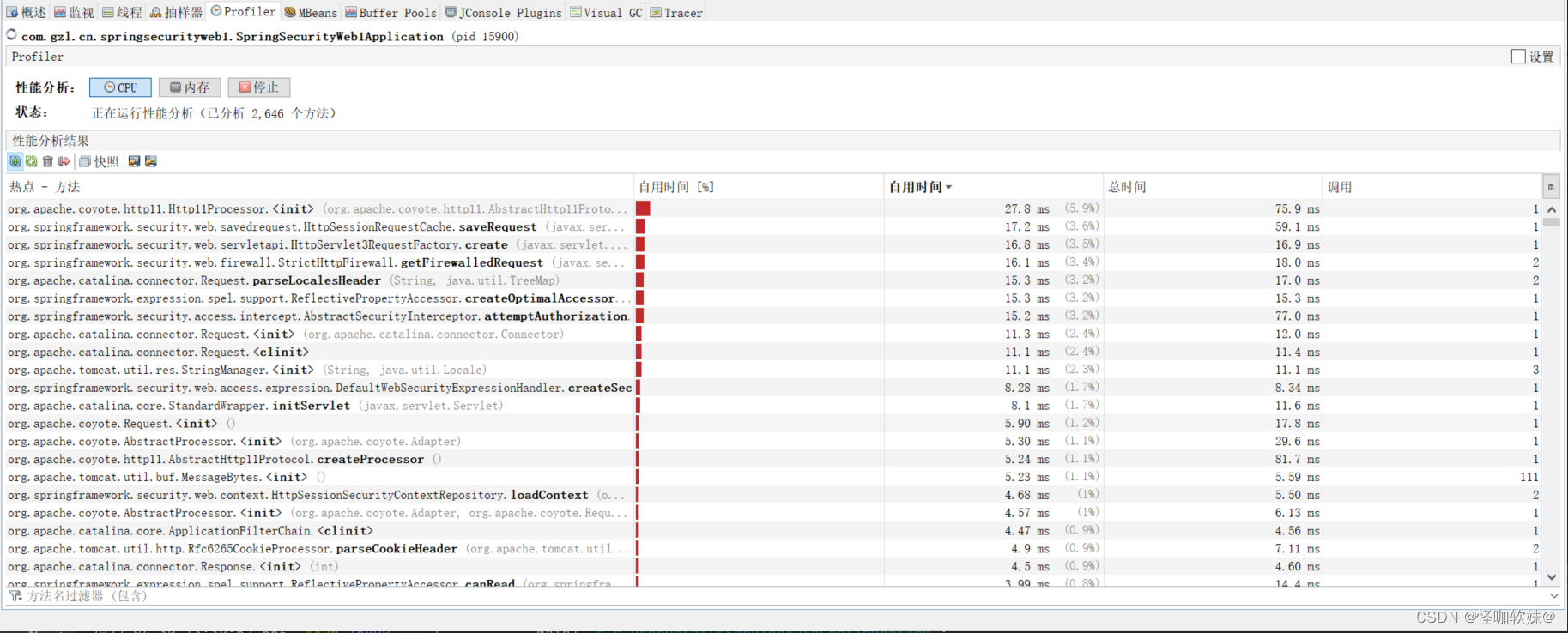
注意:当点击开始分析的时候,我们需要运行方法。当进入一个方法时,线程会发出一个“method entry”的事件,当退出方法时同样会发
出一个“method exit”的事件,这些事件都包含了时间戳。然后 VisualVM 会把每个被调用方法的总的执行时间
和调用的次数按照运行时长展示出来。
6> BTrace动态日志跟踪
当程序出现问题时,排查错误的一些必要信息时 (譬如方法参数、返回值等),在开发时并没有打印到日志之中
以至于不得不停掉服务时,都可以通过调试增量来加入日志代码以解决问题。
笔者准备了一段简单的Java代码来演示BTrace的功能:产生两个1000以内的随机整数,输出这两 个数字相加的结
果。
代码示例:这段代码是要放到ider里面执行的。
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class TraceTest {
public int add(int a, int b) {
return a + b;
}
public static void main(String[] args) throws IOException {
TraceTest test = new TraceTest();
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
for (int i = 0; i < 10; i++) {
reader.readLine();
int a = (int) Math.round(Math.random() * 1000);
int b = (int) Math.round(Math.random() * 1000);
System.out.println(test.add(a, b));
}
}
}假设上面这段程序已经上线运行,而我们现在又有了新的需求,想要知道程序中生成的两个随机数是 什么,但程
序并没有在执行过程中输出这一点。这时候我们就可以通过Trace来跟踪。
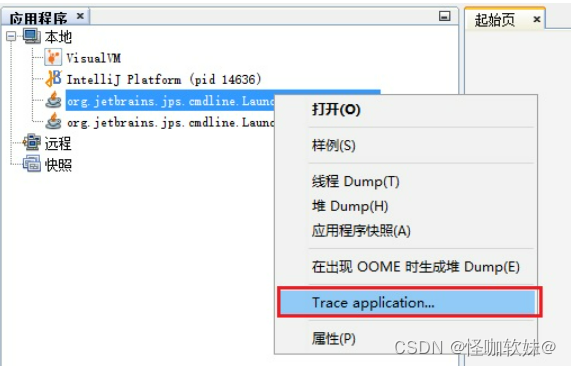
选中一个我们要进行监控的jvm实例,右键点击,然后选择 Trace application:
代码示例:这里的com.gzl.cn.TraceTest是刚刚那段代码的全类名。注意下面这段代码是要放到VisualVM当中
的,而不是ide当中的。
import com.sun.btrace.annotations.*;
import static com.sun.btrace.BTraceUtils.*;
@BTrace
public class TracingScript {
@OnMethod(clazz = "com.gzl.cn.TraceTest", method = "add", location = @Location(Kind.RETURN))
public static void func(@Self com.gzl.cn.TraceTest instance, int a, int b, @Return int result) {
println("调用堆栈:");
jstack();
println(strcat("方法参数A:", str(a)));
println(strcat("方法参数B:", str(b)));
println(strcat("方法结果:", str(result)));
}
}点击Start按钮后稍等片刻,便可以监控生成的随机数参数。
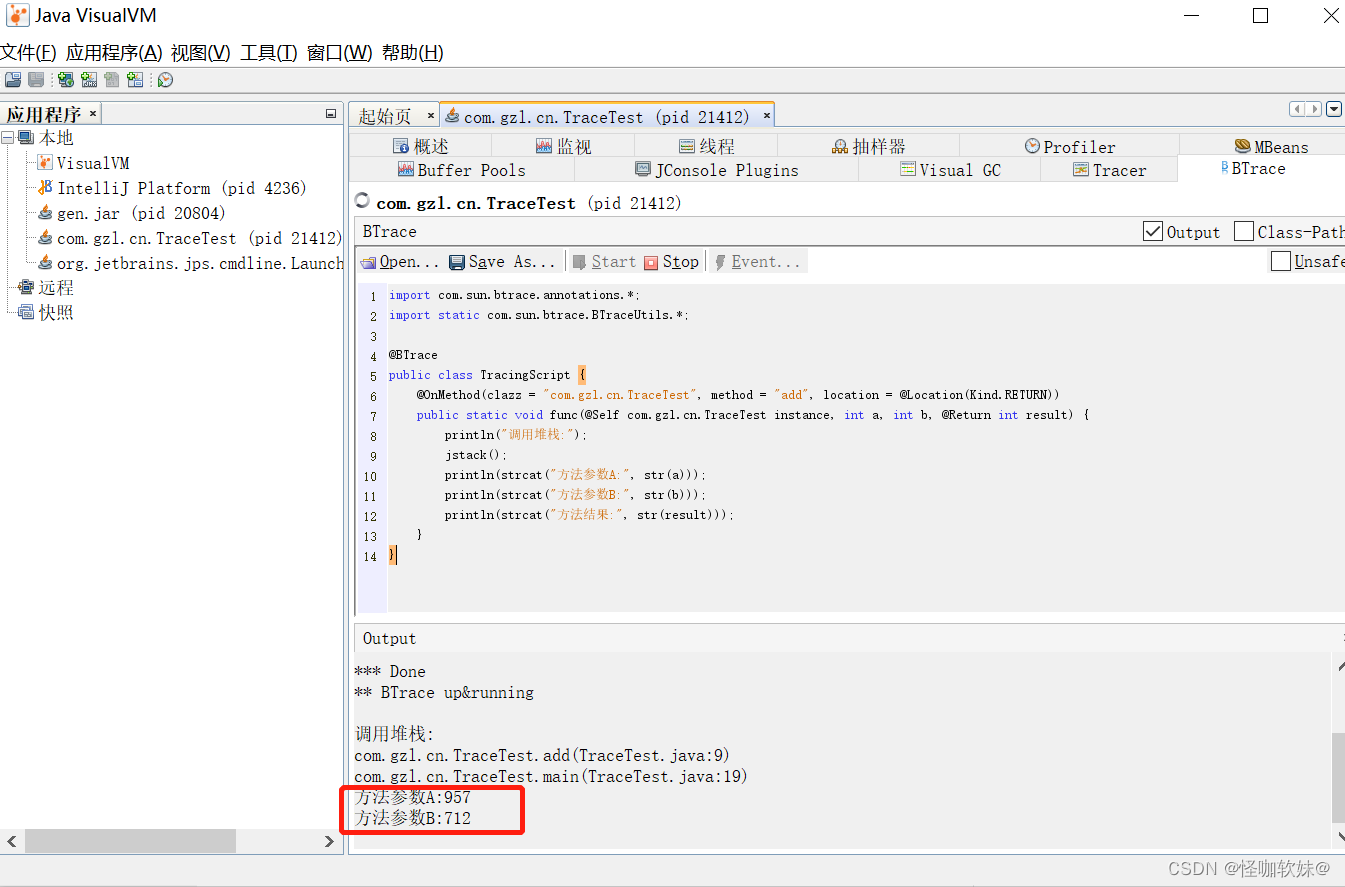
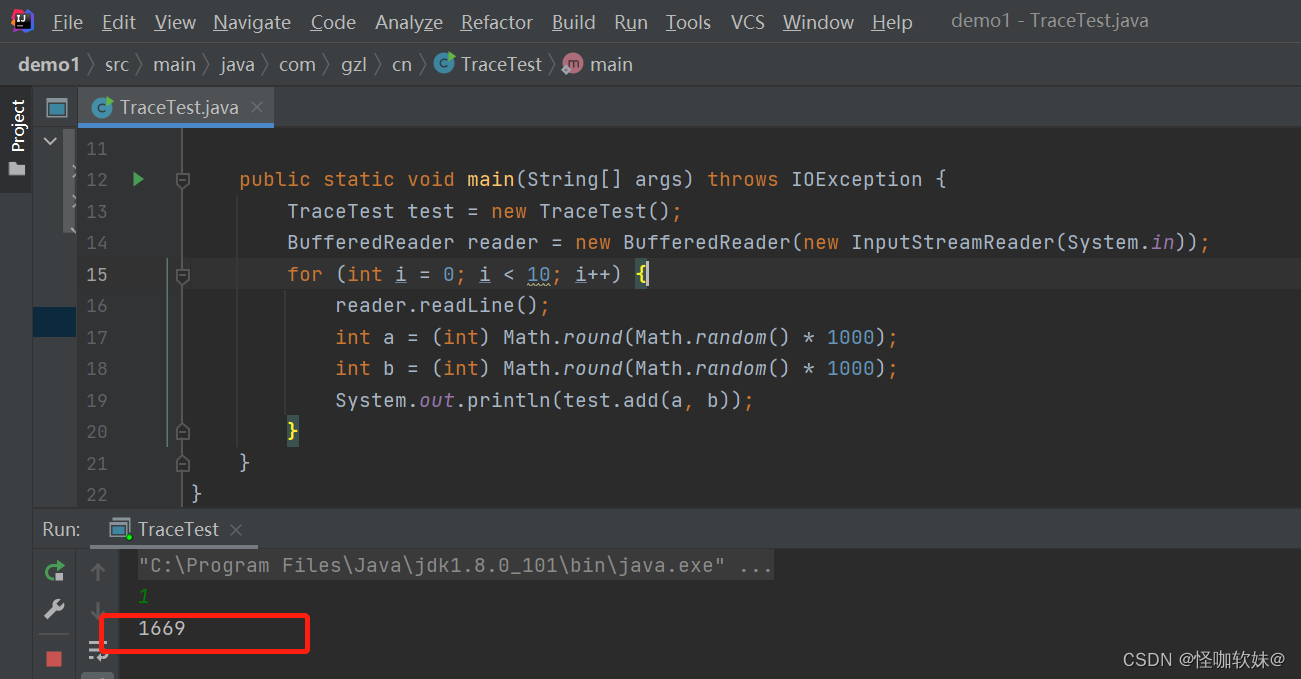
BTrace的用途很广泛,打印调用堆栈、参数、返回值只是它最基础的使用形式,在它的网站上有 使用BTrace进行
性能监视、定位连接泄漏、内存泄漏、解决多线程竞争问题等的使用案例,有兴趣的 读者可以去网上了解相关信
息。
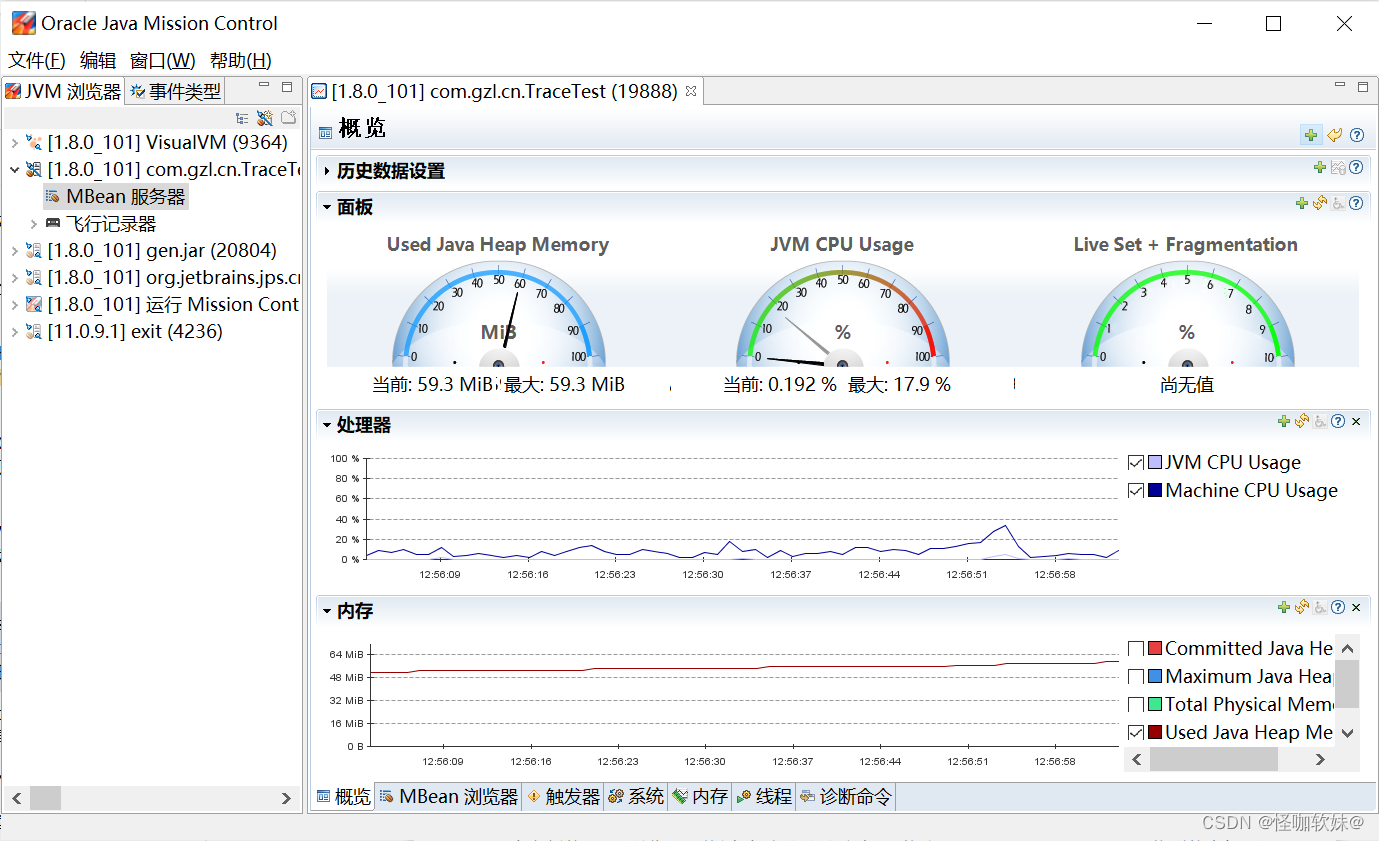
3.4. Java Mission Control:可持续在线的监控工具
Java Mission Control简称JMC,JMC不仅可以下载到独立程序,更常 见的是作为Eclipse的插件来使用。JMC与
虚拟机之间同样采取JMX协议进行通信。
- JMC一方面作为 JMX控制台,显示来自虚拟机MBean提供的数据;
- 另一方面作为JFR的分析工具,展示来自JFR的数 据。启动后JMC的主界面如下图所示。
什么是JFR?
JFR就是下面所显示的飞行记录器数据,JFR是一套内建在HotSpot虚拟机里面的监控和基于事件的信息搜集框
架,与其他的监控工具(如 JProfiling)相比,Oracle特别强调它“可持续在线”(Always-On)的特性。JFR在
生产环境中对吞吐量 的影响一般不会高于1%(甚至号称是Zero Performance Overhead),而且JFR监控过程的
开始、停止都 是完全可动态的,即不需要重启应用。JFR的监控对应用也是完全透明的,即不需要对应用程序的
源 码做任何修改,或者基于特定的代理来运行。
1> 远程连接
如果需要监控其他服务器上的虚拟机,可在“文件->连接”菜单中创建远 程连接。
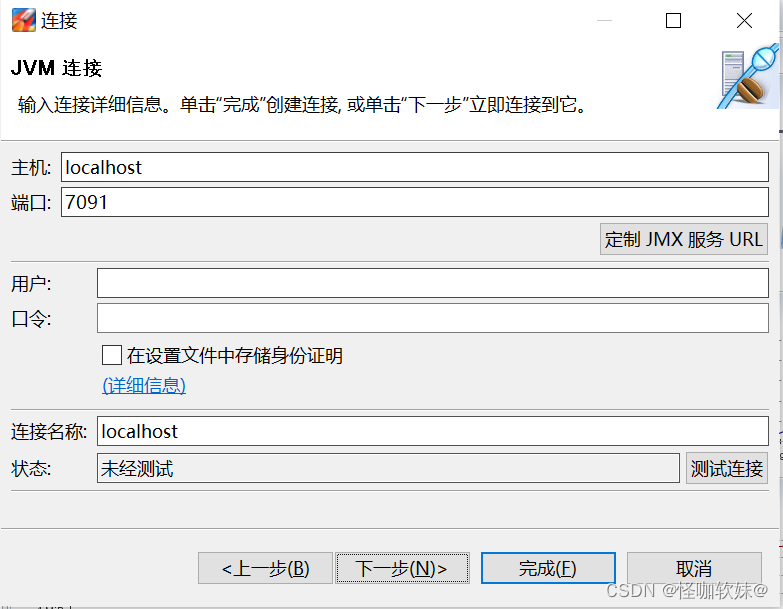
这里要填写的信息应该在被监控虚拟机进程启动的时候以虚拟机参数的形式指定,
以下是一份被 监控端的启动参数样例:
-Dcom.sun.management.jmxremote.port=9999
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.authenticate=false
-Djava.rmi.server.hostname=192.168.31.4
-XX:+UnlockCommercialFeatures
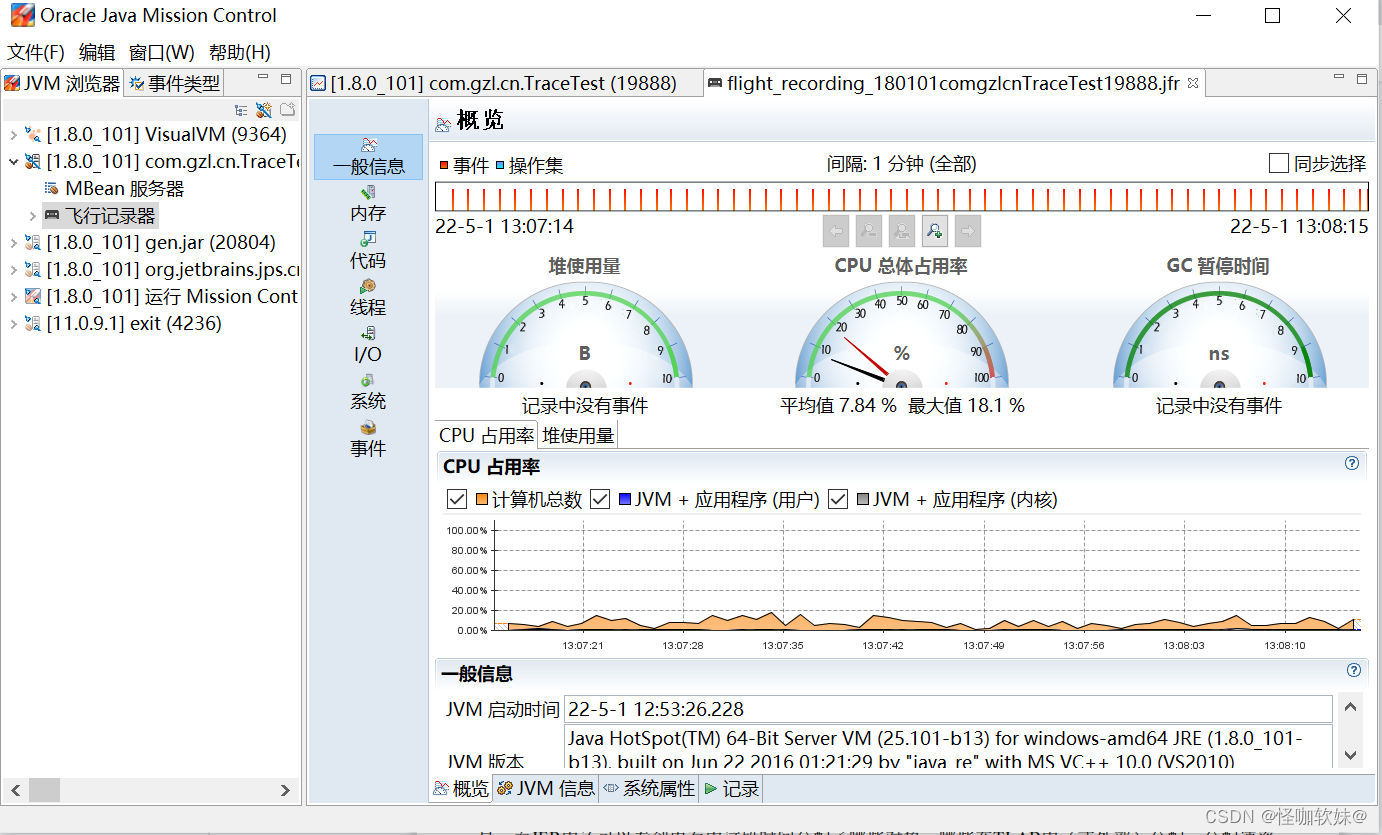
-XX:+FlightRecorder2> 飞行记录器
飞行记录报告里包含以下几类信息:
- 一般信息:关于虚拟机、操作系统和记录的一般信息。
- 内存:关于内存管理和垃圾收集的信息。
- 代码:关于方法、异常错误、编译和类加载的信息。
- 线程:关于应用程序中线程和锁的信息。
- I/O:关于文件和套接字输入、输出的信息。
- 系统:关于正在运行Java虚拟机的系统、进程和环境变量的信息。
- 事件:关于记录中的事件类型的信息,可以根据线程或堆栈跟踪,按照日志或图形的格式查看
JFR的基本工作逻辑是开启一系列事件的录制动作,当某个事件发生时,这个事件的所有上下文 数据将会以循环日
志的形式被保存至内存或者指定的某个文件当中,循环日志相当于数据流被保留在 一个环形缓存中,所以只有最
近发生的事件的数据才是可用的。JMC从虚拟机内存或者文件中读取并 展示这些事件数据,并通过这些数据进行
性能分析。
通俗点理解可以把它当成飞机上的黑匣子。
JFR提供的数据质量通常也要比其他工具通过代 理形式采样获得或者从MBean中取得的数据高得多。以垃圾搜集
为例,HotSpot的MBean中一般有各个 分代大小、收集次数、时间、占用率等数据(根据收集器不同有所差
别),这些都属于“结果”类的信 息,而JFR中还可以看到内存中这段时间分配了哪些对象、哪些在TLAB中(或
外部)分配、分配速率 和压力大小如何、分配归属的线程、收集时对象分代晋升的情况等,这些就是属于“过
程”类的信息, 对排查问题的价值是难以估量的。
3.5. 其他工具
1> Flame Graphs(火焰图)
在追求极致性能的场景下,了解你的程序运行过程中cpu在干什么很重要,火焰图就是一种非常直观的展示CPU在
程序整个生命周期过程中时间分配的工具。火焰图对于现代的程序员不应该陌生,这个工具可以非常直观的显示
出调用找中的CPU消耗瓶颈。
网上的关于Java火焰图的讲解大部分来自于Brenden Gregg的博客
http://new.brendangregg.com/flamegraphs.html

火焰图,简单通过x轴横条宽度来度量时间指标,y轴代表线程栈的层次。
2> Tprofiler
案例: 使用JDK自身提供的工具进行JVM调优可以将下 TPS 由2.5提升到20(提升了7倍),并准确 定位系统瓶
颈。
系统瓶颈有:应用里释态对象不是太多、有大量的业务线程在频繁创建一些生命周期很长的临时对象,代码里有
问题。
那么,如何在海量业务代码里边准确定位这些性能代码?这里使用阿里开源工具 Tprofiler 来定位 这些性能代码,
成功解决掉了GC 过于频繁的性能瓶预,并最终在上次优化的基础上将 TPS 再提升了4倍,即提升到100。
- Tprofiler配置部署、远程操作、 日志阅谈都不太复杂,操作还是很简单的。但是其却是能够 起到一针见血、立竿见影的效果,帮我们解决了GC过于频繁的性能瓶预。
- Tprofiler最重要的特性就是能够统汁出你指定时间段内 JVM 的 top method 这些 top method 极有可能就是造成你 JVM 性能瓶颈的元凶。这是其他大多数 JVM 调优工具所不具备的,包括 JRockit Mission Control。JRokit 首席开发者 Marcus Hirt 在其私人博客《 Lom Overhead Method Profiling cith Java Mission Control》下的评论中曾明确指出 JRMC 井不支持 TOP 方法的统计。
官方地址:GitHub - alibaba/TProfiler: TProfiler是一个可以在生产环境长期使用的性能分析工具
Btrace
常见的动态追踪工具有BTrace、HouseHD(该项目己经停止开发)、Greys-Anatomy(国人开发 个人开发
者)、Byteman(JBoss出品),注意Java运行时追踪工具井不限干这几种,但是这几个是相对比较常用的。
BTrace是SUN Kenai 云计算开发平台下的一个开源项目,旨在为java提供安全可靠的动态跟踪分析工具。
先看一下日志Trace的官方定义:

大概意思是一个 Java 平台的安全的动态追踪工具,可以用来动态地追踪一个运行的 Java 程序。
BTrace动态调整目标应用程序的类以注入跟踪代码(“字节码跟踪“)。
4. JVM 故障诊断:HotSpot虚拟机插件及工具
在 HotSpot 研发过程中,开发团队曾经编写(或收集)过不少 JVM 插件和辅助工具,
它们存放在 HotSpot 源码 hotspot/src/share/tools 目录下;
将编译好的插件放到 JDK_HOME/jre/bin/server 目录(JDK 9以下)或 JDK_HOME/lib/amd64/server(JDK 9
或以上)即可使用;
- Ideal Graph Visualizer: 用于可视化展示 C2 即时编译器将字节码转化为理想图,然后转化为机器码的过程;
- Client Compiler Visualizer: 用于查看 C1 即时编译器生成高级中间表示(HIR),转换成低级中间表示(LIR)和做物理寄存器分配的过程;
- MakeDeps: 帮助处理 HotSpot 的编译依赖;
- Project Creator: 帮忙生成 Visual Studio 的 .project;
- LogCompilation: 将 -XX:+LogCompilation 输出的日志整理成易读的格式;
- HSDIS: 即时编译器的反汇编插件;
4.1 HSDIS
即时编译器的反汇编插件;把即时编译器动态生成的本地代码还原成汇编代码输出,附带大量注释;
代码示例
public class Bar {
int a = 1;
static int b = 2;
public int sum(int c) {
return a + b + c;
}
public static void main(String[] args) {
new Bar().sum(3);
}
}执行编译
# -Xcomp 以编译模式执行代码,直接触发即时编译
# -XX:CompileCommand 让编译器不要内联 sum() 并只编译 sum()
# 输出反编译内容
# Product 版 VM 需要额外开启
java -XX:+PrintAssembly -XX:+UnlockDiagnosticVMOptions -Xcomp -XX:CompileCommand=dontinline,*Bar.sum -XX:CompileCommand=compileonly,*Bar.sum反汇编结果
[Disassembling for mach='i386']
[Entry Point]
[Constants]
# {method} 'sum' '(I)I' in 'test/Bar'
# this: ecx = 'test/Bar'
# parm0: edx = int
# [sp+0x20] (sp of caller)
......
0x01cac407: cmp 0x4(%ecx),%eax
0x01cac40a: jne 0x01c6b050 ; {runtime_call}
[Verified Entry Point]
0x01cac410: mov %eax,-0x8000(%esp)
0x01cac417: push %ebp
0x01cac418: sub $0x18,%esp ; *aload_0
; - test.Bar::sum@0 (line 8)
;; block B0 [0, 10]
0x01cac41b: mov 0x8(%ecx),%eax ; *getfield a
; - test.Bar::sum@1 (line 8)
0x01cac41e: mov $0x3d2fad8,%esi ; {oop(a 'java/lang/Class' = 'test/Bar')}
0x01cac423: mov 0x68(%esi),%esi ; *getstatic b
; - test.Bar::sum@4 (line 8)
0x01cac426: add %edx,%eax
0x01cac428: add %esi,%eax
0x01cac42a: add $0x18,%esp
0x01cac42d: pop %ebp
0x01cac42e: test %eax,0x2b0100 ; {poll_return}
0x01cac434: ret- mov %eax,-0x8000(%esp): 检查栈溢;
- push %ebp: 保存上一栈帧基址;
- sub $0x18,%esp: 给新帧分配空间
- mov 0x8(%ecx),%eax: 取实例变量 a,这里 0x8(%ecx) 就是 ecx+0x8 的意思,前面代码片段 [Constants] 中提示了
- this:ecx='test/Bar',即 ecx 寄存器中放的就是 this 对象的地址;偏移 0x8 是越过 this 对象的对象头,之后就是实例变量 a 的内存位置;这次是访问 Java 堆中的数据;
- mov $0x3d2fad8,%esi: 取 test.Bar 在方法区的指针;
- mov 0x68(%esi),%esi: 取类变量 b,这次是访问方法区中的数据;
- add %esi,%eax、add%edx,%eax: 做 2 次加法,求 a+b+c 的值,前面的代码把 a 放在 eax 中,把 b 放在 esi 中,而 c 在 [Constants] 中提示了,parm0:edx=int,说明 c 在 edx 中;
- add $0x18,%esp: 撤销栈帧;
- pop %ebp: 恢复上一栈帧;
- test %eax,0x2b0100: 轮询方法返回处的 SafePoint;
- ret: 方法返回;
4.2 JITWatch
经常与 HSDIS 搭配使用的可视化变异日志分析工具,可以方便的查看相应类和方法的 Java 源码、字节码、即时
编译生成的汇编代码等;
VM Arguments 设置
-XX:+UnlockDiagnosticVMOptions
-XX:+TraceClassLoading
-XX:+LogCompilation
-XX:LogFile=/tmp/logfile.log
-XX:+PrintAssembly5. JVM 参数分类
5.1 标准参数
标准参数,顾名思义,标准参数中包括功能以及输出的结果都是很稳定的。
基本上不会随着 JVM 版本的变化而变化。
我们可以通过 java -help 命令查看所有的标准参数。
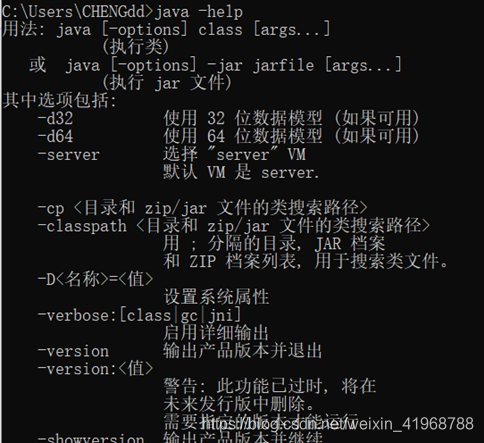
这些命令的详细解释可以看官网:
https://docs.oracle.com/javase/7/docs/technotes/tools/solaris/java.html
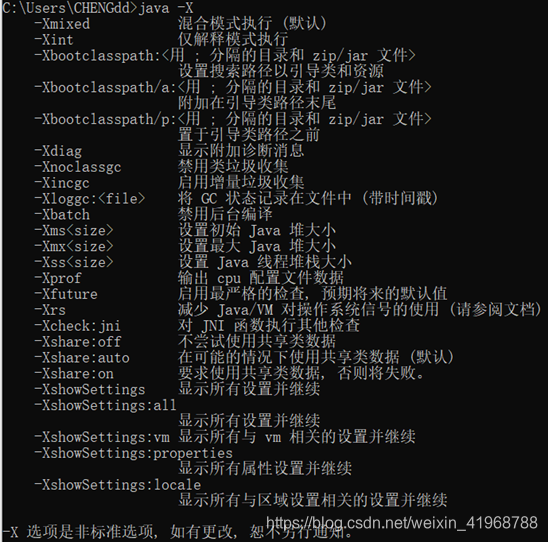
5.2 X 参数
前面说了标准参数,这里我们来看非标准参数。即,在以后的 JVM 版本中可能会发生改变,这类以 -X 开始的参
数变化的比较小。
我们可以通过 java -X 命令查看所有的非标准参数。
如下:
5.3 XX 参数
这是我们日常开发中接触到最多的参数类型。这也是非标准化参数,相对来说不稳定随着 JVM 版本的变化可能会
发生变化,主要用于JVM 调优和 debug。按书写形式分为两大类,接着往下看:
注意:这种参数是我们后续介绍 JVM 调优讲解最多的参数。
1. boolean 类型
格式:-XX:[+-]<name> 表示启用或者禁用 name 属性。
例子:-XX:+UseG1GC(表示启用 G1 垃圾收集器)2. key/value 类型
格式:-XX:<name>=<value> 表示 name 的属性值为 value。
例子:-XX:MaxGCPauseMillis=500(表示设置 GC 的最大停顿时间是 500ms)6. JVM 参数说明
6.1 堆的分配参数
1. 最小最大堆容量
-Xms256M:设置堆内存初始值为 256M(最小堆容量)
-Xmx512M:设置堆内存最大值为 512M这里的 ms 是 memory start 的简称,mx 是 memory max 的简称,分别代表最小堆容量和最大堆容量。
但是别看这里是-X 参数,其实这是-XX 参数,等价于:
-XX:InitialHeapSize
-XX:MaxHeapSize在通常情况下,服务器项目在运行过程中,堆空间会不断的收缩与扩张,势必会造成不必要的系统压力。
所以在生产环境中,JVM 的 Xms 和 Xmx 要设置成一样的,能够避免 GC 在调整堆大小带来的不必要的压力。
2. 年轻代的分配参数
(1)设置年轻代大小
格式:-Xmn 数值+容量单位
例如:-Xmn10m //年轻代为 10m(2)年轻代和老年代的比例
新生代(eden+2 个 survivor)和老年代(不包含永久区)的比值
格式:-XX:NewRatio=数值
例如:-XX:NewRatio=1 //表示新生代:老年代=1:1,即新生代占整个堆的一半(3)survivor 区和 eden 区的比例
设置两个 Survivor 区总的大小和 eden 的比值
格式:-XX:SurvivorRatio=数值
例如:-XX:SurvivorRatio=8 //表示 1 个 Survivor:eden=1:8,表示两个 Survivor:eden=2:8,即一个 Survivor 占年轻代的 1/106.2 栈的分配参数
设置栈空间的大小。通常只有几百 K,决定了函数调用的深度。
栈空间是每个线程私有的区域。栈里面的主要内容是栈帧,而栈帧存放的是局部变量表、操作数栈、动态链接、返回地址。
格式:-Xss 数值+容量单位
例如:-Xmn128k //年轻代为 128kb6.3 永久代参数配置
设置永久区的初始空间和最大空间。也就是说,jvm 启动时,永久区一开始就占用了初始大小的空间,如果空间
还不够,可以继续扩展,但是不能超过 MaxPermSize,否则会 OOM
-XX:PermSize // 永久代初始空间
-XX:MaxPermSize // 永久代最大空间
例如:永久代最大空间设置为 128m
-XX:MaxPermSize=120m在 JDK1.7 以及以前的版本中,只有 Hotspot 才有 Perm 区,称为永久代,
它在启动时固定大小,很难进行调优。
在某些情况下,如果动态加载类过多,容易产生 Perm 区的 OOM。比如某个实际 Web 工程中,因为功能点较
多,在运行过程中,要不断动态加载很多类,就会出现类似错误:
“Exception in thread ‘dubbo client x.x.connect’ java.lang.OutOfMemoryError:PermGenspace”
为了解决这个问题,就需要在项目启动时,设定运行参数-XX:MaxPermSize。
注意:在 JDK1.8 以后面的版本,使用元空间来代替永久代。在 JDK1.8 以及后面的版本中,如果设定参数-
XX:MaxPermSize,启动 JVM 不会报错,但是会提示:Java Hotspot 64Bit Server VM warning:ignoring option MaxPermSize=1280m:support was removed in 8.0
6.4 gc 日志
1. 打印 gc 日志简要信息
-verbose:gc
或
-XX:+printGC2. 打印 gc 日志详细信息
-XX:+PrintGCDetails // 打印 GC 详细信息
-XX:+PrintGCTimeStamps // 打印 GC 详细信息 带时间戳
-XX:+PrintGCDateStamps // 打印 GC 详细信息 带日期戳例如:
[GC[DefNew: 4416K->0K(4928K), 0.0001897 secs] 4790K->374K(15872K), 0.0002232 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]上方日志的意思是说:这是一个新生代的 GC.
方括号内部的“4416K->0K(4928K)”含义是:“GC 前该内存区域已使用容量->GC 后该内存区域已使用容量
(该内存区域总容量)”。
0.0001897 secs”表示该内存区域 GC 所占用的时间,单位是秒
而在方括号之外的“4790K->374K(15872K)”表示“GC 前 java 堆已使用容量->GC 后 Java 堆已使用容量
(Java 堆总容量)”。
0.0002232 secs”表示该 java 堆 GC 所占用的时间,单位是秒
3. 指定 gc log 位置
解释:指定 GC log 的位置,以文件输出。帮助开发人员分析问题。
-Xloggc:./gc.log6.5 其他
1. 打印已经配置 jvm 参数
-XX:+PrintCommandLineFlags如下:
![]()
2. Dump 异常快照以及以文件形式导出
-XX:+HeapDumpOnOutOfMemoryError //内存发生错误时打印堆转储快照
-XX:HeapDumpPath //设置堆内存溢出快照输出的文件地址例如:
-Xmx20m -Xms5m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=d:/a.dump3. 发生 OOM 时执行一个脚本
-XX:OnOutOfMemoryError例如:
-XX:OnOutOfMemoryError="C:\Program Files\Java\jdk1.8.0_152\bin\jconsole.exe"4. 垃圾收集器配置
请参考 “垃圾收集器全解“部分,所介绍的参数配置方式。
-------------------------------------------
讲解二:实践篇
一、jdk命令⾏
1. jps:虚拟机进程状况工具
jps:Java Virtual Machine Process Status Tool
查看Java进程 ,相当于Linux下的ps命令,只不过它只列出Java进程。
jps :列出Java程序进程ID和Main函数名称
jps -q :只输出进程ID
jps -m :输出传递给Java进程(主函数)的参数
jps -l :输出主函数的完整路径
jps -v :显示传递给Java虚拟的参数
2. jstat:虚拟机统计信息监视工具
jstat:JVM Statistics Monitoring Tool
jstat可以查看Java程序运⾏时相关信息,可以通过它查看堆信息的相关情况
jstat -<options> [-t] [-h<lines>] <vmid> [<interval> [<count>]]options:由以下值构成
-class:显示ClassLoader的相关信息
-compiler:显示JIT编译的相关信息
-gc:显示与GC相关信息
-gccapacity:显示各个代的容量和使⽤情况
-gccause:显示垃圾收集相关信息(同-gcutil),同时显示最后⼀次或当前正在发⽣的垃圾收集的诱发原因
-gcnew:显示新⽣代信息
-gcnewcapacity:显示新⽣代⼤⼩和使⽤情况
-gcold:显示⽼年代信息
-gcoldcapacity:显示⽼年代⼤⼩
-gcpermcapacity:显示永久代⼤⼩
-gcutil:显示垃圾收集信息
-printcompilation:输出JIT编译的⽅法信息
-t:在输出信息前加上⼀个Timestamp列,显示程序的运⾏时间
-h:可以在周期性数据输出后,输出多少⾏数据后,跟着⼀个表头信息
interval:⽤于指定输出统计数据的周期,单位为毫秒
count:⽤于指定⼀个输出多少次数据package com.wclass.example;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
/**
-Xms500m -Xmx500m
*/
public class HeapInstanceTest {
byte[] buffer = new byte[new Random().nextInt(1024*200)];
public static void main(String[] args) {
List<HeapInstanceTest> list = new ArrayList<HeapInstanceTest>();
while (true){
list.add(new HeapInstanceTest());
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}示例⼀
jstat -gc 7063 500 4**下⾯输出的是GC相关信息,**7063 是 进程ID ,采样时间间隔为500ms,采样数为4。

S0C:年轻代中第⼀个survivor(幸存区)的容量 (字节)
S1C:年轻代中第⼆个survivor(幸存区)的容量 (字节)
S0U:年轻代中第⼀个survivor(幸存区)⽬前已使⽤空间 (字节)
S1U :年轻代中第⼆个survivor(幸存区)⽬前已使⽤空间 (字节)
EC :年轻代中Eden(伊甸园)的容量 (字节)
EU :年轻代中Eden(伊甸园)⽬前已使⽤空间 (字节)
OC :Old代的容量 (字节)
OU :Old代⽬前已使⽤空间 (字节)
MC:metaspace(元空间)的容量 (字节)
MU:metaspace(元空间)⽬前已使⽤空间 (字节)
CCSC:压缩类空间⼤⼩
CCSU:压缩类空间使⽤⼤⼩
YGC :从应⽤程序启动到采样时年轻代中gc次数
YGCT :从应⽤程序启动到采样时年轻代中gc所⽤时间(s)
FGC :从应⽤程序启动到采样时old代(全gc)gc次数
FGCT :从应⽤程序启动到采样时old代(全gc)gc所⽤时间(s)
GCT:从应⽤程序启动到采样时gc⽤的总时间(s)示例⼆
类的装载信息
jstat -class 7737
Loaded : 已经装载的类的数量
Bytes : 装载类所占⽤的字节数
Unloaded:已经卸载类的数量
Bytes:卸载类的字节数
Time:装载和卸载类所花费的时间示例三
显示垃圾收集信息
~ jstat -gcutil 7737 5s 5
S0 年轻代中第⼀个survivor(幸存区)已使⽤的占当前容量百分⽐
S1 年轻代中第⼆个survivor(幸存区)已使⽤的占当前容量百分⽐
E 年轻代中Eden(伊甸园)已使⽤的占当前容量百分⽐
O old代已使⽤的占当前容量百分⽐
M metaspace已使⽤的占当前容量百分⽐
CCS 压缩使⽤⽐例
YGC 从应⽤程序启动到采样时年轻代中gc次数
YGCT 从应⽤程序启动到采样时年轻代中gc所⽤时间(s)
FGC 从应⽤程序启动到采样时old代(全gc)gc次数
FGCT 从应⽤程序启动到采样时old代(全gc)gc所⽤时间(s)
GCT 从应⽤程序启动到采样时gc⽤的总时间(s)3. jinfo:Java配置信息工具
jinfo:Java Configuration Info
jinfo可以⽤来查看正在运⾏的java程序的扩展参数,甚⾄⽀持运⾏时,修改部分参数
jinfo [option] <pid>-flag <name> to print the value of the named VM flag
-flag [+|-]<name> to enable or disable the named VM flag
-flag <name>=<value> to set the named VM flag to the given value
-flags to print VM flags
-sysprops to print Java system properties
<no option> to print both of the above
-h | -help to print this help messagepackage com.wclass.example;
import java.util.ArrayList;
import java.util.List;
/**
* -Xms10m -Xmx10m -XX:+PrintCommandLineFlags -XX:+UseConcMarkSweepGC
*/
public class GCUseTest {
public static void main(String[] args) {
List<byte[]> list = new ArrayList<>();
while (true){
byte[] arr = new byte[100];
list.add(arr);
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}示例⼀:查看堆的最⼤值
➜ ~ jinfo -flag MaxHeapSize 8384
-XX:MaxHeapSize=10485760示例二:查看所有参数
➜ ~ jinfo -flags 8384
Attaching to process ID 8384, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.121-b13
Non-default VM flags: -XX:CICompilerCount=4 -XX:InitialHeapSize=10485760 -
XX:MaxHeapSize=10485760 -XX:MaxNewSize=3145728 -XX:MinHeapDeltaBytes=524288 -
XX:NewSize=3145728 -XX:OldSize=7340032 -XX:+UseCompressedClassPointers -
XX:+UseCompressedOops -XX:+UseFastUnorderedTimeStamps -XX:+UseParallelGC
Command line: -Xms10m -Xmx10m -Dfile.encoding=UTF-8示例三:查看使⽤的垃圾回收器
➜ ~ jinfo -flag UseParallelGC 8384
-XX:+UseParallelGC
➜ ~ jinfo -flag UseConcMarkSweepGC 8384
-XX:-UseConcMarkSweepGC示例三:设置⽇志打印
➜ ~ jinfo -flag PrintGCDetails 8384
-XX:-PrintGCDetails
➜ ~ jinfo -flag +PrintGCDetails 8384
➜ ~ jinfo -flag PrintGCDetails 8384
-XX:+PrintGCDetails
➜ ~ jinfo -flag -PrintGCDetails 8384
➜ ~ jinfo -flag PrintGCDetails 8384
-XX:-PrintGCDetails4. jmap:Java内存映像工具
jmap:Memory Map
jmap⽤来查看堆内存使⽤状况,⼀般结合jhat使⽤。
jmap语法格式如下:
Usage:
jmap [option] <pid>
(to connect to running process)
jmap [option] <executable <core>
(to connect to a core file)
jmap [option] [server_id@]<remote server IP or hostname>
(to connect to remote debug server)
where <option> is one of:
<none> to print same info as Solaris pmap
-heap to print java heap summary
-histo[:live] to print histogram of java object heap; if the "live"
suboption is specified, only count live objects
-clstats to print class loader statistics
-finalizerinfo to print information on objects awaiting finalization
-dump:<dump-options> to dump java heap in hprof binary format
dump-options:
live dump only live objects; if not
specified,
all objects in the heap are dumped.
format=b binary format
file=<file> dump heap to <file>
Example: jmap -dump:live,format=b,file=heap.bin <pid>
-F force. Use with -dump:<dump-options> <pid> or -histo
to force a heap dump or histogram when <pid> does not
respond. The "live" suboption is not supported
in this mode.
-h | -help to print this help message
-J<flag> to pass <flag> directly to the runtime system参数:
option: 选项参数。
pid: 需要打印配置信息的进程ID。
executable: 产⽣核⼼dump的Java可执⾏⽂件。
core: 需要打印配置信息的核⼼⽂件。
server-id: 可选的唯⼀id,如果相同的远程主机上运⾏了多台调试服务器,⽤此选项参数标识服务器。
remote server IP or hostname 远程调试服务器的IP地址或主机名。
option
no option: 查看进程的内存映像信息,类似 Solaris pmap 命令。
heap: 显示Java堆详细信息
histo[:live]: 显示堆中对象的统计信息
clstats:打印类加载器信息
finalizerinfo: 显示在F-Queue队列等待Finalizer线程执⾏finalizer⽅法的对象
dump:<dump-options>:⽣成堆转储快照
F: 当-dump没有响应时,使⽤-dump或者-histo参数. 在这个模式下,live⼦参数⽆效.
help:打印帮助信息
J<flag>:指定传递给运⾏jmap的JVM的参数package com.wclass.example;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
/**
-Xms500m -Xmx500m
*/
public class HeapInstanceTest {
byte[] buffer = new byte[new Random().nextInt(1024*200)];
public static void main(String[] args) {
List<HeapInstanceTest> list = new ArrayList<HeapInstanceTest>();
while (true){
list.add(new HeapInstanceTest());
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}示例⼀:显示Java堆详细信息
命令:jmap -heap pid
描述:显示Java堆详细信息
打印⼀个堆的摘要信息,包括使⽤的GC算法、堆配置信息和各内存区域内存使⽤信息
28.79711191157351% used
2156 interned Strings occupying 152440 bytes.➜ ~ jmap -heap 8985
Attaching to process ID 8985, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.121-b13
using thread-local object allocation.
Parallel GC with 8 thread(s)
Heap Configuration:
MinHeapFreeRatio = 0
MaxHeapFreeRatio = 100
MaxHeapSize = 524288000 (500.0MB)
NewSize = 174587904 (166.5MB)
MaxNewSize = 174587904 (166.5MB)
OldSize = 349700096 (333.5MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
PS Young Generation
Eden Space:
capacity = 131596288 (125.5MB)
used = 127090976 (121.20339965820312MB)
free = 4505312 (4.296600341796875MB)
96.57641407028137% used
From Space:
capacity = 21495808 (20.5MB)
used = 21477712 (20.482742309570312MB)
free = 18096 (0.0172576904296875MB)
99.91581614424543% used
To Space:
capacity = 21495808 (20.5MB)
used = 0 (0.0MB)
free = 21495808 (20.5MB)
0.0% used
PS Old Generation
capacity = 349700096 (333.5MB)
used = 100703528 (96.03836822509766MB)
free = 248996568 (237.46163177490234MB)
28.79711191157351% used
2156 interned Strings occupying 152440 bytes.示例⼆:显示堆中对象的统计信息
命令:jmap -histo:live pid
描述:显示堆中对象的统计信息
其中包括每个Java类、对象数量、内存⼤⼩(单位:字节)、完全限定的类名。
打印的虚拟机内部 的类名称将会带有⼀个’*’前缀。如果指定了live⼦选项,则只计算活动的对象。
➜ ~ jmap -histo:live 8985
num #instances #bytes class name
----------------------------------------------
1: 3682 339156840 [B
2: 3806 408160 [C
3: 3794 91056 java.lang.String
4: 593 67480 java.lang.Class
5: 587 54568 [Ljava.lang.Object;
6: 3273 52368 com.wclass.example.HeapInstanceTest示例三:打印类加载器信息
命令:jmap -clstats pid
描述:打印类加载器信息
-clstats是-permstat的替代⽅案,在JDK8之前,-permstat⽤来打印类加载器的数据 打印Java堆内存的永久保存
区域的类加载器的智能统计信息。
对于每个类加载器⽽⾔,它的名称、活跃 度、地址、⽗类加载器、它所加载的类的数量和⼤⼩都会被打印。
此外,包含的字符串数量和⼤⼩也会 被打印。
➜ ~ jmap -clstats 8985
Attaching to process ID 8985, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.121-b13
finding class loader instances ..done.
computing per loader stat ..done.
please wait.. computing
liveness......................................................................
.............................done.
class_loader classes bytes parent_loader alive? type
<bootstrap> 517 969116 null live <internal>
0x00000007af095a08 0 0 0x00000007ae86f288 live
java/util/ResourceBundle$RBClassLoader@0x00000007c00555e8
0x00000007ae86f288 9 29861 0x00000007ae8770f8 live
sun/misc/Launcher$AppClassLoader@0x00000007c000f6a0
0x00000007ae8770f8 0 0 null live
sun/misc/Launcher$ExtClassLoader@0x00000007c000fa48
total = 4 526 998977 N/A alive=4, dead=0 N/A示例四:打印正等候回收的对象的信息
命令:jmap -finalizerinfo pid
描述:打印正等候回收的对象的信息
➜ ~ jmap -finalizerinfo 10067
Attaching to process ID 10067, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.121-b13
Number of objects pending for finalization: 0Number of objects pending for finalization: 0 说明当前F-QUEUE队列中并没有等待Fializer线程执⾏final
示例五:生成堆转储快照dump文件
命令:jmap -dump:format=b,file=heapdump.dump pid
描述:⽣成堆转储快照dump⽂件。
以hprof⼆进制格式转储Java堆到指定filename的⽂件中。live⼦选项是可选的。
如果指定了live⼦选项,堆中只有活动的对象会被转储。想要浏览heap dump,你可以使⽤jhat(Java堆分析⼯具)
读取 ⽣成的⽂件。
这个命令执⾏,JVM会将整个heap的信息dump写⼊到⼀个⽂件,heap如果⽐较⼤的话,就会导 致这个过程⽐较
耗时,并且执⾏的过程中为了保证dump的信息是可靠的,所以会暂停应⽤, 线上系统 慎⽤。
➜ ~ jmap -dump:format=b,file=heapdump.dump 10067
Dumping heap to /Users/hadoop/heapdump.dump ...5. jhat:虚拟机堆转储快照分析工具
jhat:Java Heap Analysis Tool,jhat 命令解析Java堆转储⽂件,并启动⼀个 web server.
然后⽤浏览 器来查看/浏览 dump 出来的 heap. jhat 命令⽀持预先设计的查询, ⽐如显示某个类的所有实例.
还⽀持 对象查询语⾔(OQL, Object Query Language)。
OQL有点类似SQL,专⻔⽤来查询堆转储。
OQL相关的 帮助信息可以在 jhat 命令所提供的服务器⻚⾯最底部.
如果使⽤默认端⼝, 则OQL帮助信息⻚⾯为: http://localhost:7000/oqlhelp/
Java⽣成堆转储的⽅式有多种:
- 使⽤ jmap -dump 选项可以在JVM运⾏时获取 heap dump.
- 使⽤ jconsole 选项通过 HotSpotDiagnosticMXBean 从运⾏时获得堆转储。
- 在虚拟机启动时如果指定了 -XX:+HeapDumpOnOutOfMemoryError 选项, 则抛出 OutOfMemoryError 时, 会⾃动执⾏堆转储。
- 使⽤ hprof 命令。
jhat [ options ] heap-dump-file参数:
- options 可选命令⾏参数,请参考下⾯的 Options
- heap-dump-file 要查看的⼆进制Java堆转储⽂件(Java binary heap dump file)。 如果某个转储⽂ 件中包含了多份 heap dumps, 可在⽂件名之后加上 # 的⽅式指定解析哪⼀个 dump, 如: myfile.hprof#3
Options
- -stack false|true关闭对象分配调⽤栈跟踪(tracking object allocation call stack)。 如果分配位置信息在堆转储中不可⽤,则必须将此标志设置为 false. 默认值为 true .
- -refs false|true关闭对象引⽤跟踪(tracking of references to objects),默认值为 true . 默认情况下, 返回的指针是指 向其他特定对象的对象,如反向链接或输⼊引⽤(referrers or incoming references), 会统计/计算堆中的 所有对象。
- -port port-number设置 jhat HTTP server 的端⼝号. 默认值 7000 .
- -exclude exclude-file指定对象查询时需要排除的数据成员列表⽂件(a file that lists data members that should be excluded from the reachable objects query)。 例如, 如果⽂件列列出了 java.lang.String.value , 那么当从 某个特定对象 Object o 计算可达的对象列表时, 引⽤路径涉及 java.lang.String.value 的都会被排除。
- *-baseline exclude-file指定⼀个基准堆转储(baseline heap dump)。 在两个 heap dumps 中有相同 object ID 的对象会被标 记为不是新的(marked as not being new). 其他对象被标记为新的(new),在⽐较两个不同的堆转储时很 有⽤.
- -debug int设置 debug 级别. 0 表示不输出调试信息。 值越⼤则表示输出更详细的 debug 信息.
- -version启动后只显示版本信息就退出
- -h显示帮助信息并退出. 同 -help
- -help显示帮助信息并退出. 同 -h
- -J< flag >因为 jhat 命令实际上会启动⼀个JVM来执⾏, 通过 -J 可以在启动JVM时传⼊⼀些启动参数. 例如, -JXmx512m 则指定运⾏ jhat 的Java虚拟机使⽤的最⼤堆内存为 512 MB. 如果需要使⽤多个JVM启动参数,则传⼊多个 -Jxxxxxx.
示例⼀
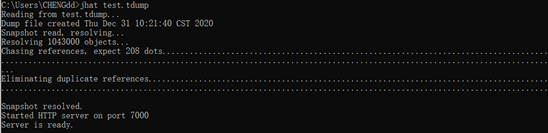
利⽤jhat分析刚刚jmap输出的堆⽂件:
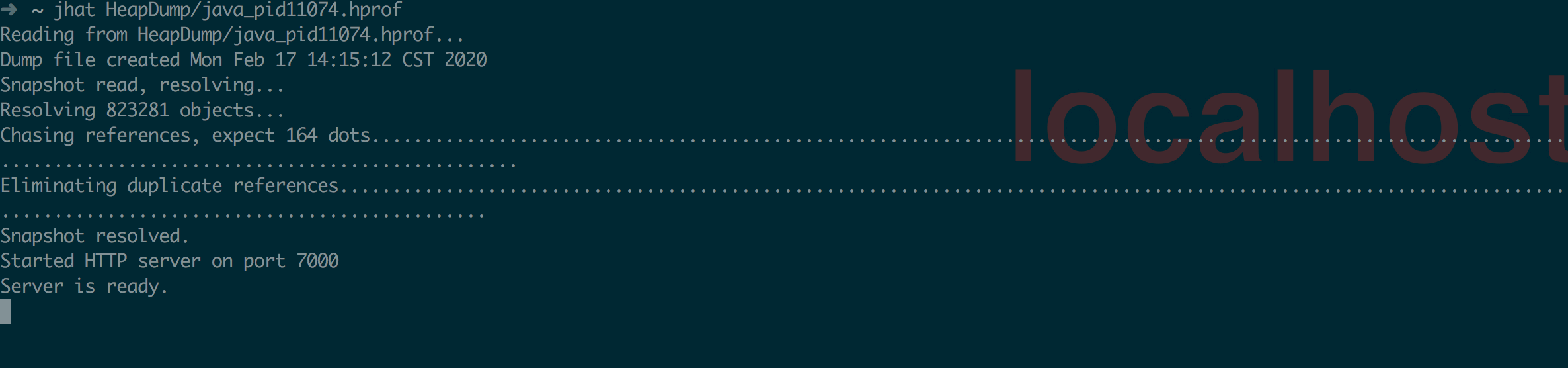
这样就启动起来了⼀个简易的HTTP服务,端⼝号是7000,尝试⼀下⽤浏览器访问⼀下它,
本地的 可以通过http://localhost:7000就可以得到这样的⻚⾯:
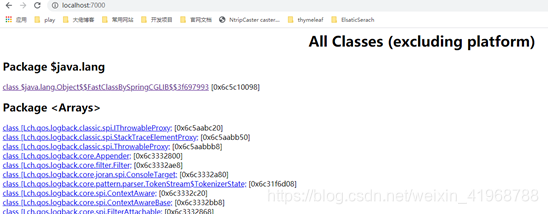
jhat 启动后显示的 html ⻚⾯中包含有:
- All classes including platform:显示出堆中所包含的所有的类
- Show all members of the rootset :从根集能引⽤到的对象
- Show instance counts for all classes (including platform/excluding platform):显示平台包括的 所有类的实例数量
- Show heap histogram:堆实例的分布表
- Show finalizer summary:Finalizer 摘要
- Execute Object Query Language (OQL) query:执⾏对象查询语句(OQL)
select a from [I a where a.length > 256 //查询⻓度⼤于256的数组6. jstack:Java堆栈跟踪工具
jstack:Java Stack Trace,jstack是java虚拟机⾃带的⼀种堆栈跟踪⼯具。
jstack⽤于⽣成java虚拟 机当前时刻的线程快照。
线程快照是当前java虚拟机内每⼀条线程正在执⾏的⽅法堆栈的集合,⽣成线 程快照的主要⽬的是定位线程出现
⻓时间停顿的原因,
如线程间死锁、死循环、请求外部资源导致的⻓时间等待等。
线程出现停顿的时候通过jstack来查看各个线程的调⽤堆栈,就可以知道没有响应的线程 到底在后台做什么事情,
或者等待什么资源。
如果java程序崩溃⽣成core⽂件,jstack⼯具可以⽤来获得core⽂件的java stack和native stack的 信息,从⽽可
以轻松地知道java程序是如何崩溃和在程序何处发⽣问题。
另外,jstack⼯具还可以附属 到正在运⾏的java程序中,看到当时运⾏的java程序的java stack和native stack的信
息, 如果现在运⾏的java程序呈现hung的状态,jstack是⾮常有⽤的。
在thread dump中,要留意下⾯⼏种状态
- 死锁,Deadlock(重点关注)
- 等待资源,Waiting on condition(重点关注)
- 等待获取监视器,Waiting on monitor entry(重点关注)
- 阻塞,Blocked(重点关注)
- 执⾏中,Runnable
- 暂停,Suspended
- 对象等待中,Object.wait() 或 TIMED_WAITING
- 停⽌,Parked
使用方式
jstack [ option ] pid 查看当前时间点,指定进程的dump堆栈信息。
jstack [ option ] pid > ⽂件 将当前时间点的指定进程的dump堆栈信息,写⼊到指定⽂件中。
注:若该⽂件不存在,则会⾃动⽣成;若该⽂件存在,则会覆盖源⽂件。
jstack [ option ] executable core 查看当前时间点,core⽂件的dump堆栈信息。
jstack [ option ] [server_id@]<remote server IP or hostname> 查看当前时间点,远程机器的dump堆栈信息。可选参数说明
-F 当进程挂起了,此时'jstack [-l] pid'是没有相应的,这时候可使⽤此参数来强制打印堆栈信息,强制jstack),⼀般情况不需要使⽤。
-m 打印java和native c/c++框架的所有栈信息。可以打印JVM的堆栈,以及Native的栈帧,⼀般应⽤排查不需要使⽤。
-l ⻓列表. 打印关于锁的附加信息。例如属于java.util.concurrent的ownable synchronizers列表,会使得JVM停顿得⻓久得多(可能会差很多倍,⽐如普通的jstack可能⼏毫秒和⼀次GC没区别,加了-l 就是近⼀秒的时间),-l 建议不要⽤。⼀般情况不需要使⽤。
-h or -hel 打印帮助信息package com.wclass.example;
import java.util.concurrent.Executor;
import java.util.concurrent.Executors;
public class JStackCase {
public static Executor executor = Executors.newFixedThreadPool(3);
public static Object lock = new Object();
public static void main(String[] args) {
StackTask task1 = new StackTask();
StackTask task2 = new StackTask();
executor.execute(task1);
executor.execute(task2);
}
static class StackTask implements Runnable{
public void run(){
synchronized (lock){
cal();
}
}
public void cal(){
int i=0;
while(true){
i++;
}
}
}
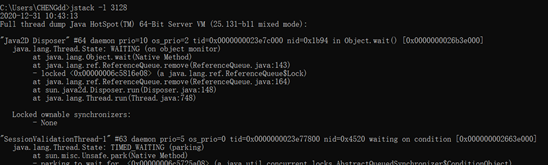
}示例一
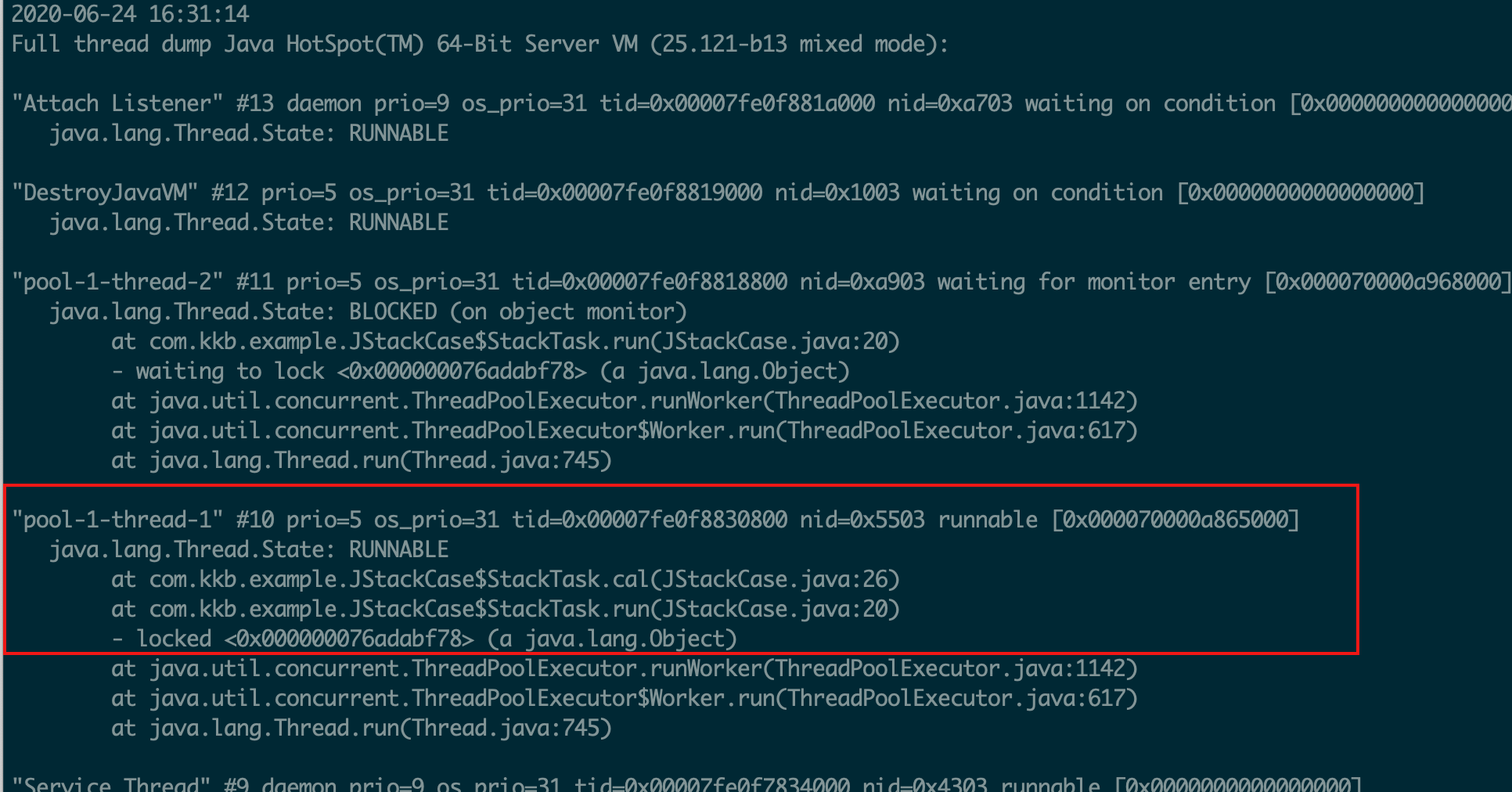
示例二
将指定进程的当前堆栈情况记录到某个⽂件中:

示例三
统计线程数
jstack -l 28367 | grep 'java.lang.Thread.State' | wc -l
示例四
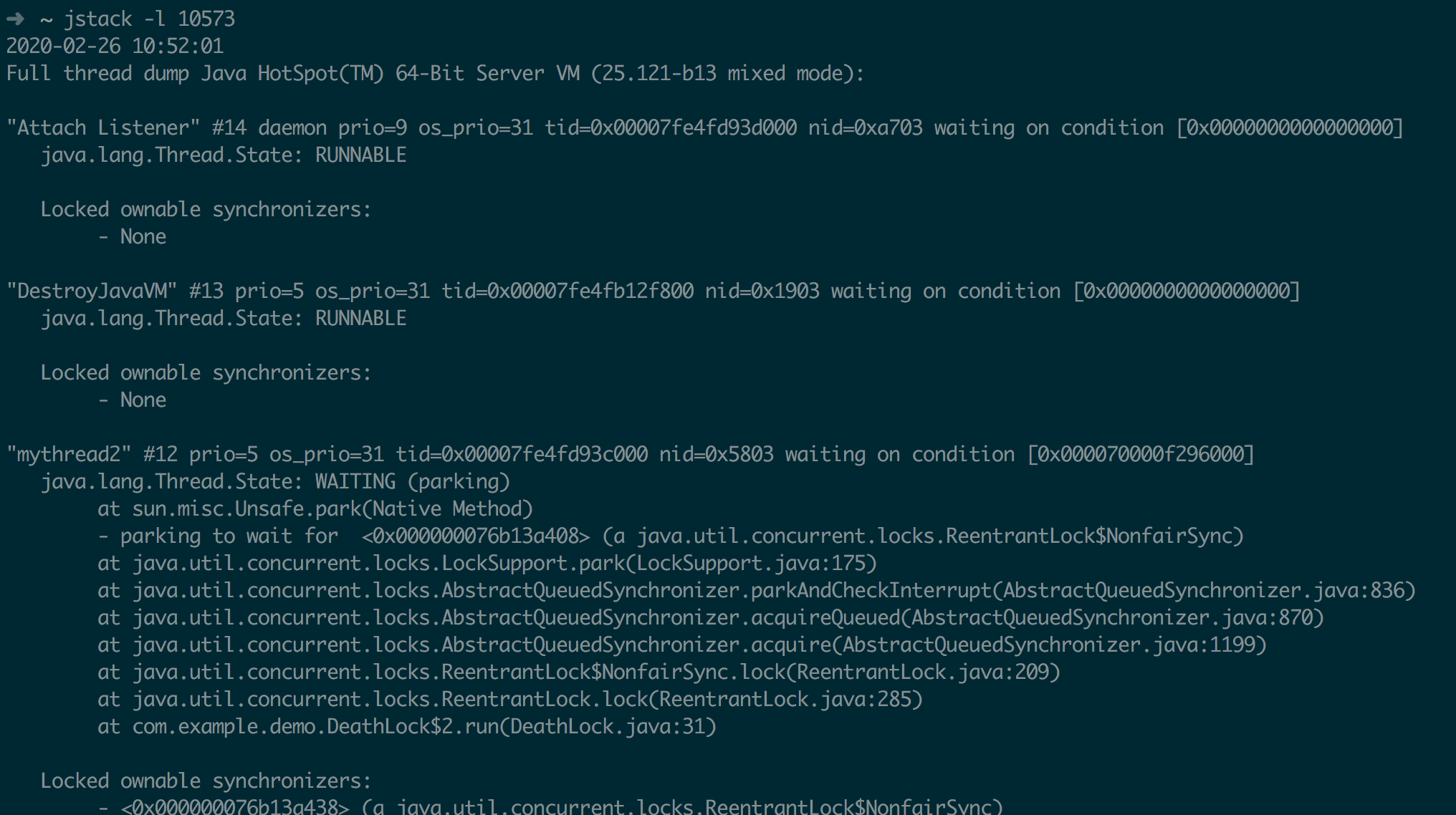
检测死锁
public class DeathLock {
private static Lock lock1 = new ReentrantLock();
private static Lock lock2 = new ReentrantLock();
public static void deathLock() {
Thread t1 = new Thread() {
@Override
public void run() {
try {
lock1.lock();
TimeUnit.SECONDS.sleep(1);
lock2.lock();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
Thread t2 = new Thread() {
@Override
public void run() {
try {
lock2.lock();
TimeUnit.SECONDS.sleep(1);
lock1.lock();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
t1.setName("mythread1");
t2.setName("mythread2");
t1.start();
t2.start();
}
public static void main(String[] args) {
deathLock();
}
}
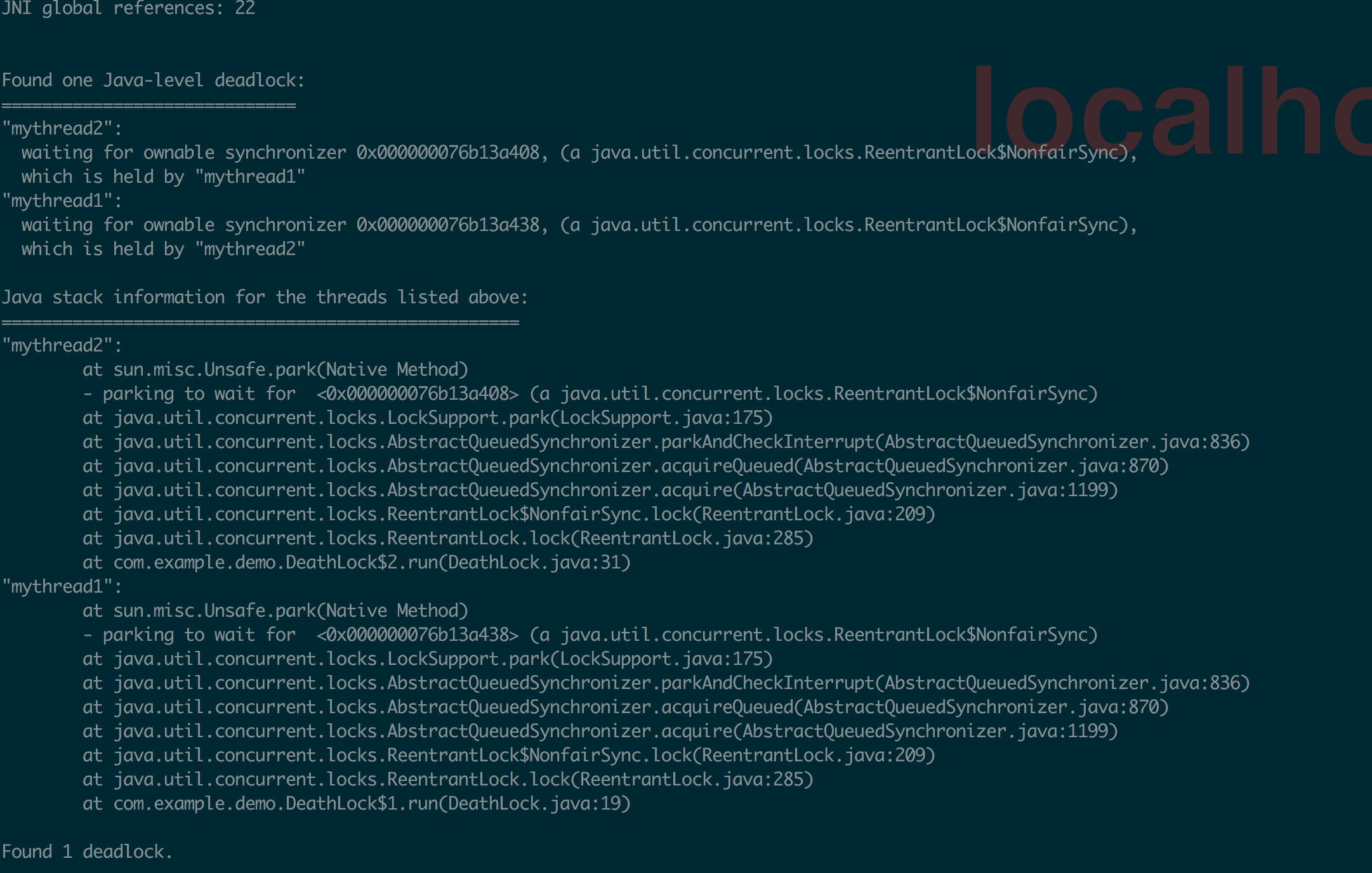
7. jconsole:Java监视与管理控制台
Jconsole:Java Monitoring and Management Console,Java 5引⼊,⼀个内置 Java 性能分析器, 可以从命令
⾏或在 GUI shell 中运⾏。
您可以轻松地使⽤ JConsole来监控 Java 应⽤程序性能和跟踪 Java 中的代码。
如何启动JConsole
如果是从命令⾏启动,使 JDK 在 PATH 上,运⾏ jconsole 即可。
如果从 GUI shell 启动,找到 JDK 安装路径,打开 bin ⽂件夹,双击 jconsole 。
当分析⼯具弹出时(取决于正在运⾏的 Java 版本以及正在运⾏的 Java 程序数量),可能会出现⼀ 个对话框,要
求输⼊⼀个进程的 URL 来连接,也可能列出许多不同的本地 Java 进程(有时包含 JConsole 进程本身)来连
接。如下图所示:想分析那个程序就双击那个进程。
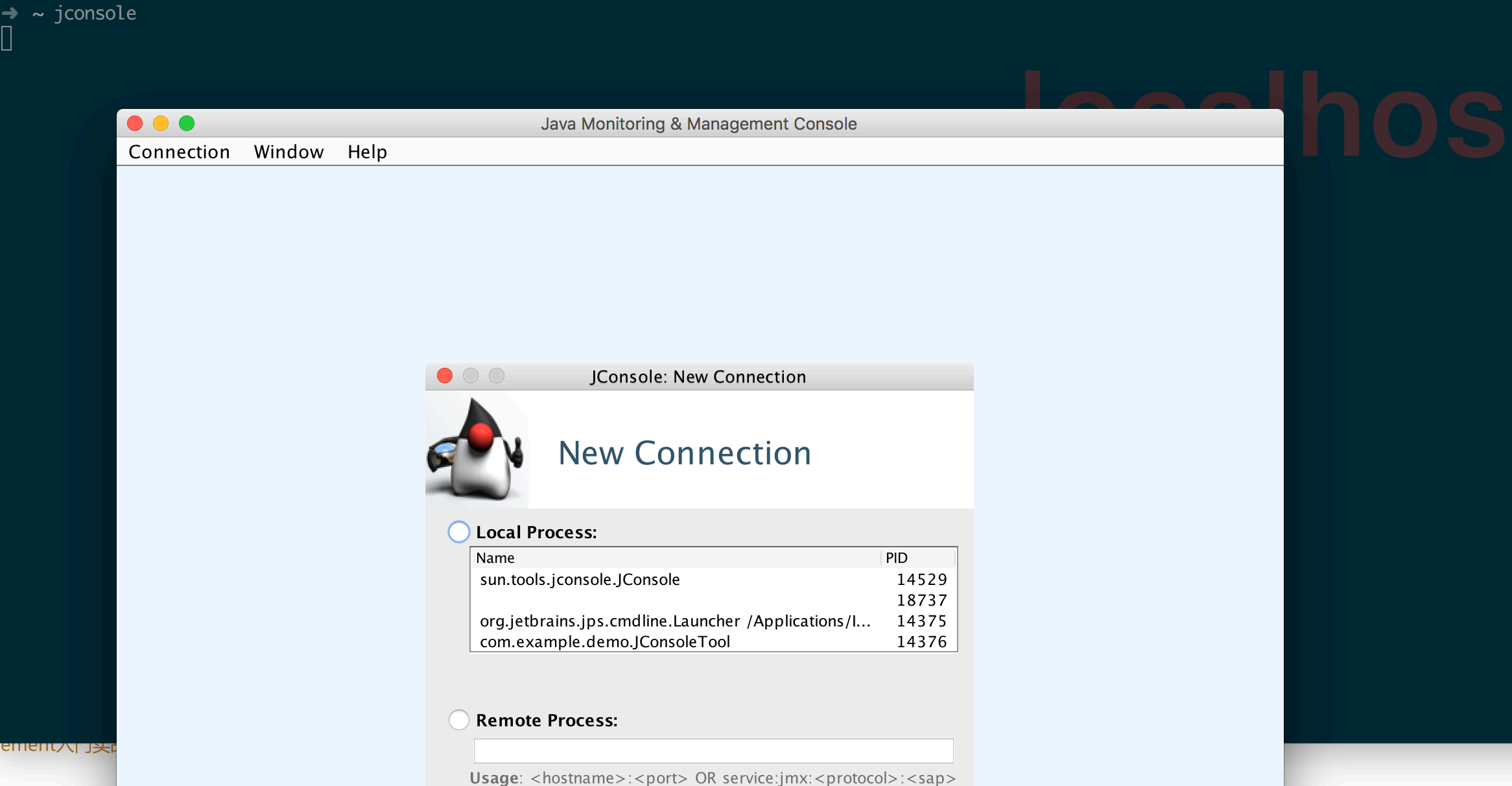
如何设置JAVA程序运⾏时可以被JConsolse连接分析
本地程序(相对于开启JConsole的计算机),⽆需设置任何参数就可以被本地开启的JConsole连接
(Java SE 6开始⽆需设置,之前还是需要设置运⾏时参数 -Dcom.sun.management.jmxremote )
JConsole如何连接远程机器的JAVA程序
jconsole 192.168.0.1:8999也可以在已经打开的JConsole界⾯操作 连接->新建连接->选择远程进程->输⼊远程主机IP和端⼝号- >
点击“连接”,如下图:
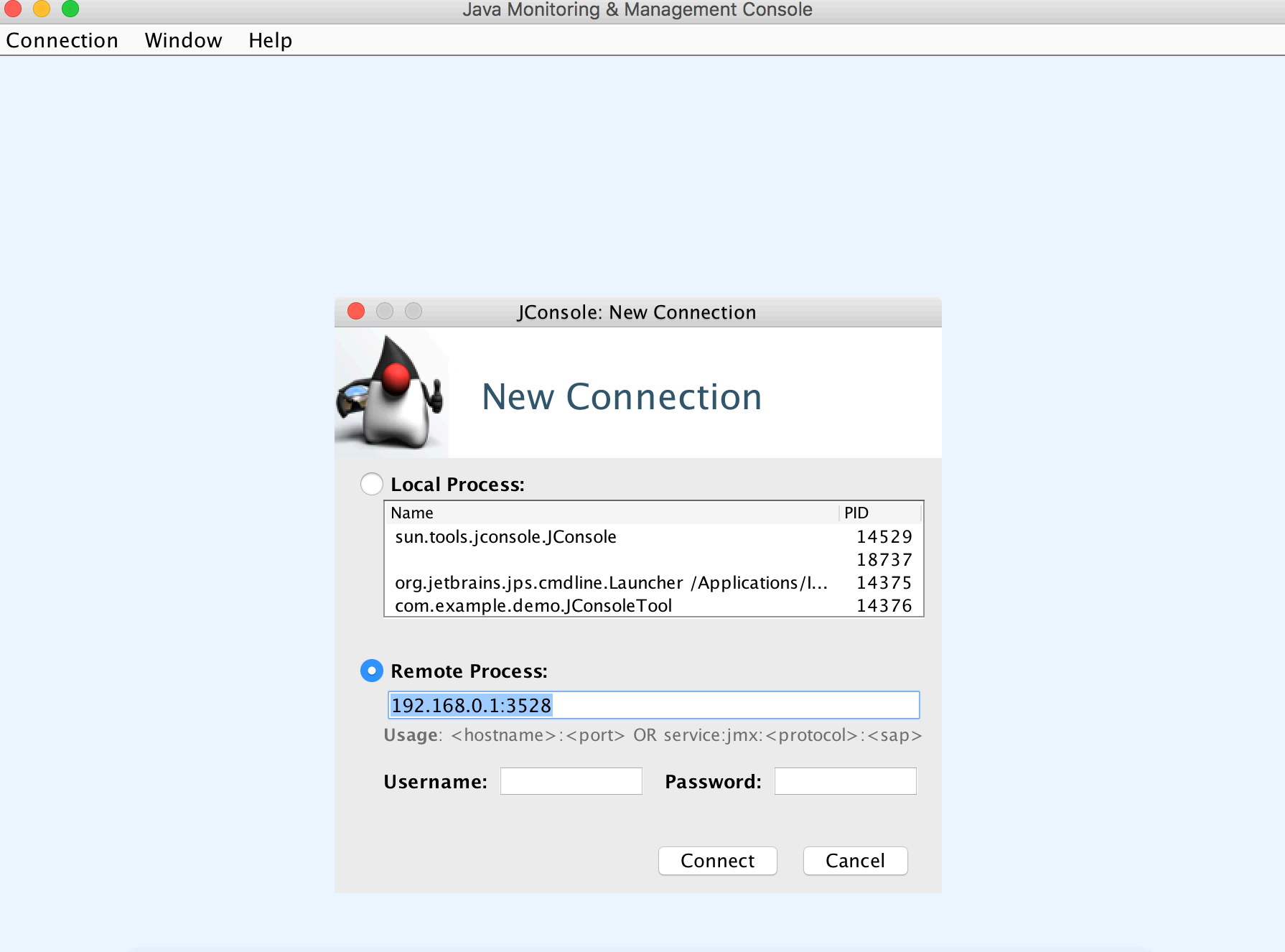
示例一
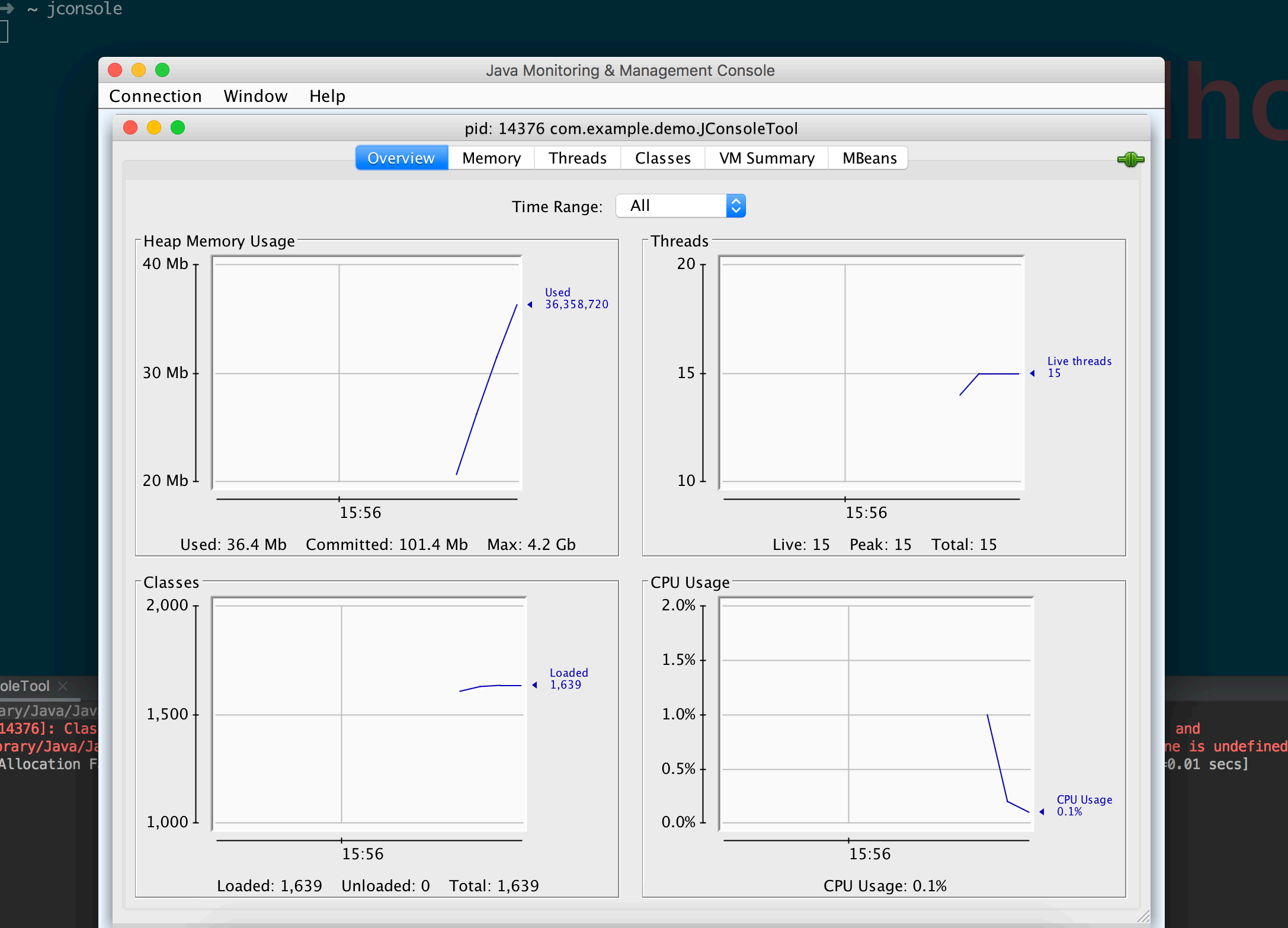
进⼊视图后包括这六个标签:
Overview: Displays overview information about the Java VM and monitored values. Memory: 显示内存使
⽤信息
Threads: 显示线程使⽤信息
Classes: 显示类装载信息
VM Summary:显示java VM信息
MBeans: 显示 MBeans.
上图描述有我们需要的信息,同时点击右键可以保存数据到CSV⽂件。
内存页签相对于可视化的jstat 命令,⽤于监视受收集器管理的虚拟机内存。
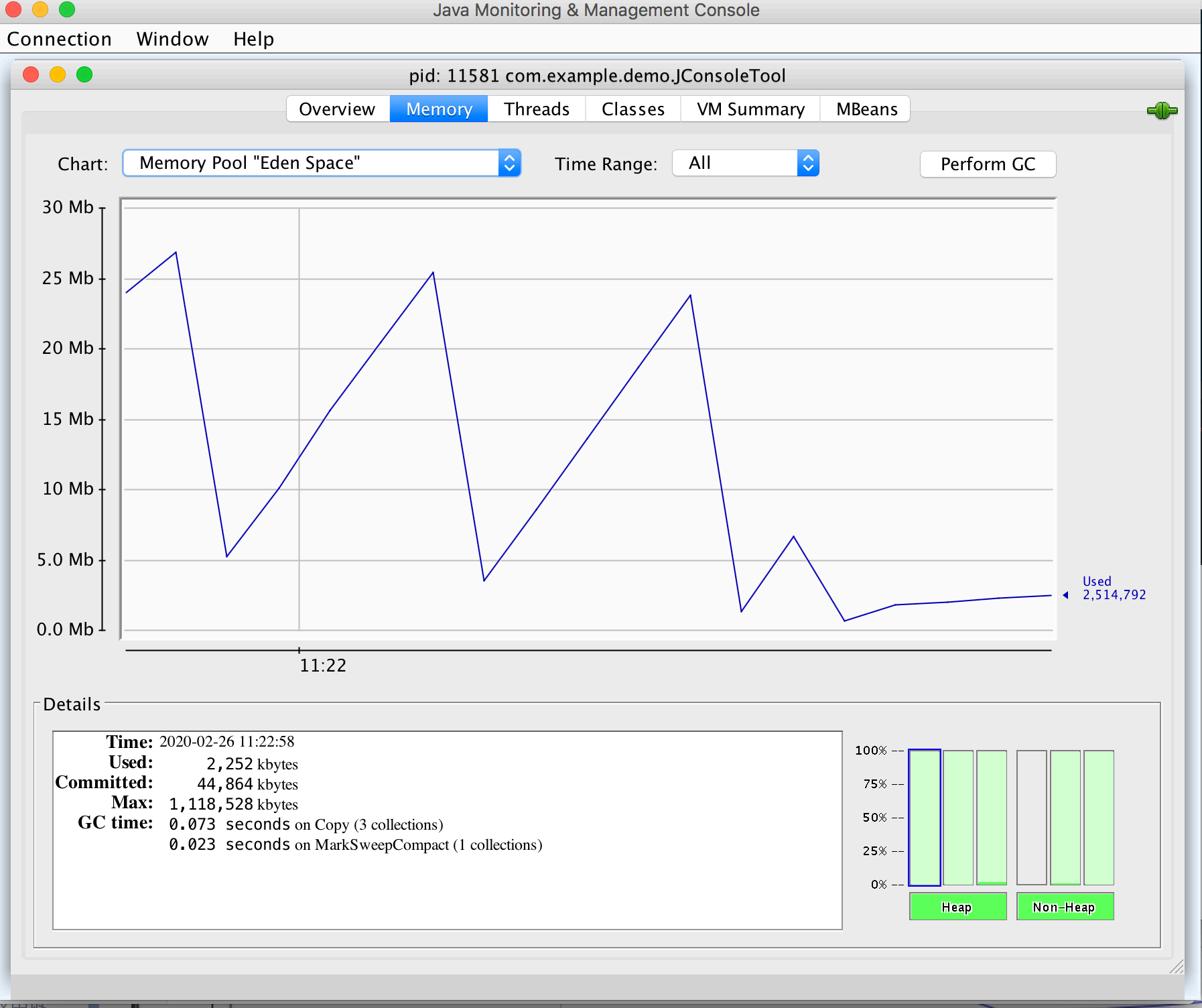
下⾯三个⽅法分别等待控制台输⼊、死循环演示、线程锁等待演示
package com.wclass.example;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
/**
* 线程死锁验证
*/
public class JConsoleThreadLock {
/**
* 等待控制台输⼊
* @throws IOException
*/
public static void waitRerouceConnection () throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
br.readLine();
}
/**
* 线程死循环演示
*/
public static void createBusyThread() {
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
while (true);
}
}, "testBusyThread");
thread.start();
}
/**
* 线程锁等待演示
*/
public static void createLockThread(final Object lock) {
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
synchronized (lock) {
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}, "testLockThread");
thread.start();
}
public static void main(String[] args) throws IOException {
createBusyThread();
}
}8. hprof:堆内存使用统计工具
hprof:Heap/CPU Profiling Tool 能够展现CPU使用率,统计堆内存使拥情况
J2SE中提供了⼀个简单的命令⾏⼯具来对java程序的cpu和heap进⾏ profiling,叫做HPROF。
HPROF实际上是JVM中的⼀个native的库,它会在JVM启动的时候通过命令⾏参数来动态加载,并成为 JVM进
程的⼀部分。
若要在java进程启动的时候使⽤HPROF,⽤户可以通过各种命令⾏参数类型来使⽤
HPROF对java进程的heap或者 (和)cpu进⾏profiling的功能。
HPROF产⽣的profiling数据可以是⼆ 进制的,也可以是⽂本格式的。
这些⽇志可以⽤来跟踪和分析 java进程的性能问题和瓶颈,解决内存使 ⽤上不优的地⽅或者程序实现上的不优之
处。
⼆进制格式的⽇志还可以被JVM中的HAT⼯具来进⾏浏览 和分析,⽤ 以观察java进程的heap中各种类型和数据的
情况。
在J2SE 5.0以后的版本中,HPROF已经被 并⼊到⼀个叫做Java Virtual Machine Tool Interface(JVM TI)中。
语法格式如下
java -agentlib:hprof[=options] ToBeProfiledClass
java -Xrunprof[:options] ToBeProfiledClass
javac -J-agentlib:hprof[=options] ToBeProfiledClass完整的命令选项如下:
Option Name and Value Description Default
--------------------- ----------- -------
heap=dump|sites|all heap profiling all
cpu=samples|times|old CPU usage off
monitor=y|n monitor contention n
format=a|b text(txt) or binary output a
file=<file> write data to file java.hprof[.txt]
net=<host>:<port> send data over a socket off
depth=<size> stack trace depth 4
interval=<ms> sample interval in ms 10
cutoff=<value> output cutoff point 0.0001
lineno=y|n line number in traces? y
thread=y|n thread in traces? n
doe=y|n dump on exit? y
msa=y|n Solaris micro state accounting n
force=y|n force output to <file> y
verbose=y|n print messages about dumps y来⼏个官⽅指南上的实例
CPU Usage Sampling Profiling(cpu=samples)的例⼦:
java -agentlib:hprof=cpu=samples,interval=20,depth=3 Hello上⾯每隔20毫秒采样CPU消耗信息,堆栈深度为3,⽣成的profile⽂件名称是java.hprof.txt,在当前 ⽬录。
CPU Usage Times Profiling(cpu=times)的例⼦,它相对于CPU Usage Sampling Profile能够获得更 加细粒度的CPU消耗信息,
能够细到每个⽅法调⽤的开始和结束,它的实现使⽤了字节码注⼊技术 (BCI):
javac -J-agentlib:hprof=cpu=times Hello.javaHeap Allocation Profiling(heap=sites)的例⼦:
javac -J-agentlib:hprof=heap=sites Hello.javaHeap Dump(heap=dump)的例⼦,它⽐上⾯的Heap Allocation Profiling能⽣成更详细的Heap Dump信息:
javac -J-agentlib:hprof=heap=dump Hello.java虽然在JVM启动参数中加⼊-Xrunprof:heap=sites参数可以⽣成CPU/Heap Profile⽂件,
但对JVM性 能影响非常⼤,不建议在线上服务器环境使⽤。
示例一:统计方法耗时
package com.wclass.example;
public class HprofTest {
public void slowMethod(){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void slowerMethod(){
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void fastMethod(){
try {
Thread.yield();
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args){
HprofTest test = new HprofTest();
test.fastMethod();
test.slowMethod();
test.slowerMethod();
}
}➜ classes java -agentlib:hprof=cpu=times,interval=10
com.wclass.example.HprofTest
Dumping CPU usage by timing methods ... done.⽣成 java.hprof.txt ⽂件
➜ classes vim java.hprof.txt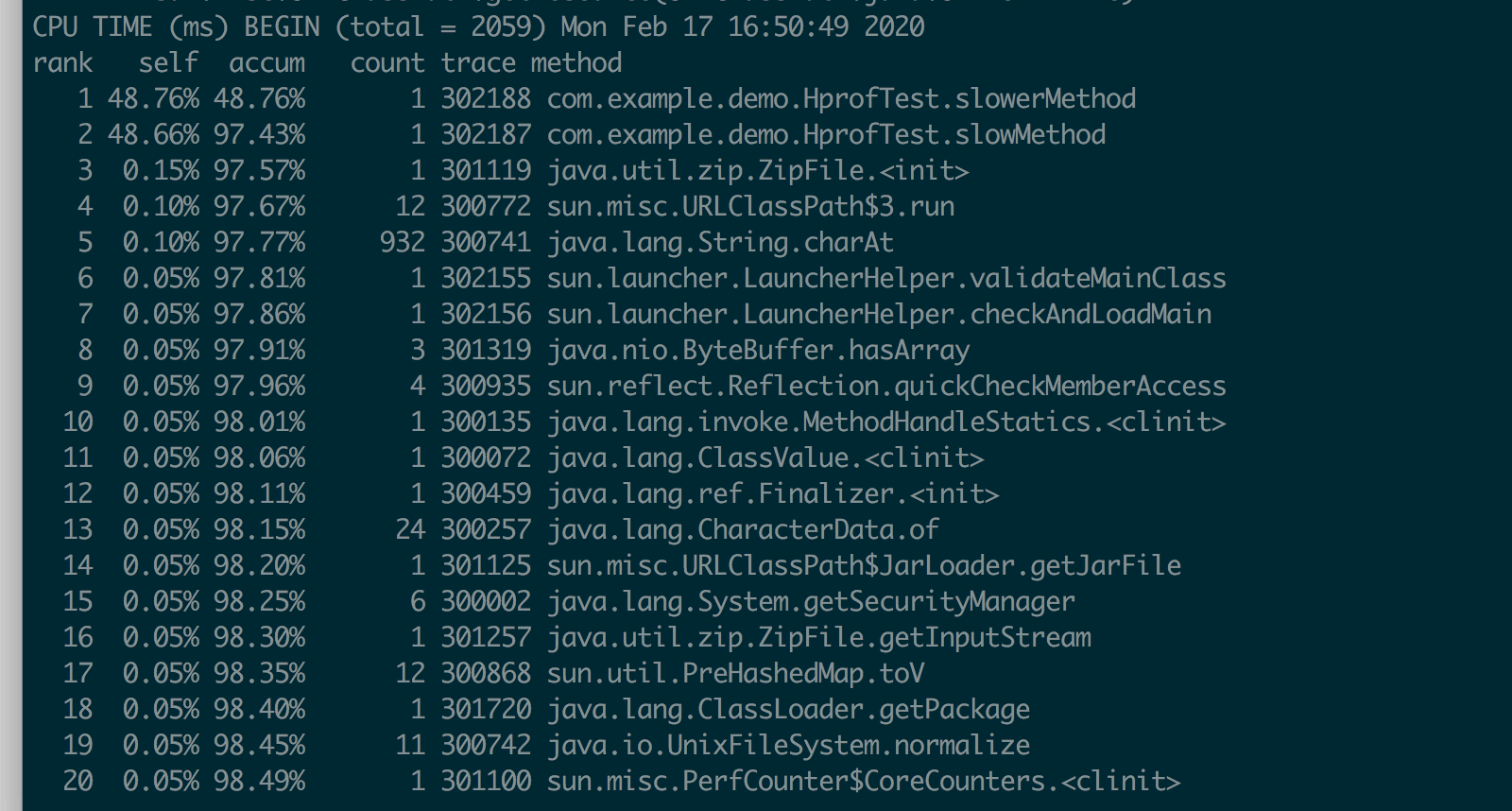
示例二:生成跟踪点类所占内存百分比
➜ classes java -agentlib:hprof=heap=sites com.wclass.example.HprofTest
Dumping allocation sites ... done.⽣成 java.hprof.txt⽂件
二、Linux
1. top:Linux进程监控工具
Linux中的top命令显示系统上正在运⾏的进程。它是系统管理员最重要的⼯具之⼀。
被⼴泛⽤于监 视服务器的负载。
在本篇中,我们会探索top命令的细节。top命令是⼀个交互命令。在运⾏top的时候 还可以运⾏很多命令。
(译注:不同发⾏版的top命令在各种细节有不同,如果发现不同时,请读你的帮助⼿册和命令内的帮 助。)
top的使⽤⽅式 top [-d number] | top [-bnp]
使用方式
显示进程信息
# top显示完整命令
# top -c以批处理模式显示程序信息
# top -b以累积模式显示程序信息
# top -S设置信息更新次数
top -n 2
//表示更新两次后终⽌更新显示设置信息更新时间
# top -d 3
//表示更新周期为3秒显示指定的进程信息
# top -p 139
//显示进程号为139的进程信息,CPU、内存占⽤率等显示更新⼗次后退出
top -n 10使⽤者将不能利⽤交谈式指令来对⾏程下命令
top -s示例⼀
Top命令输出,默认运⾏时,top命令会显示如下输出:
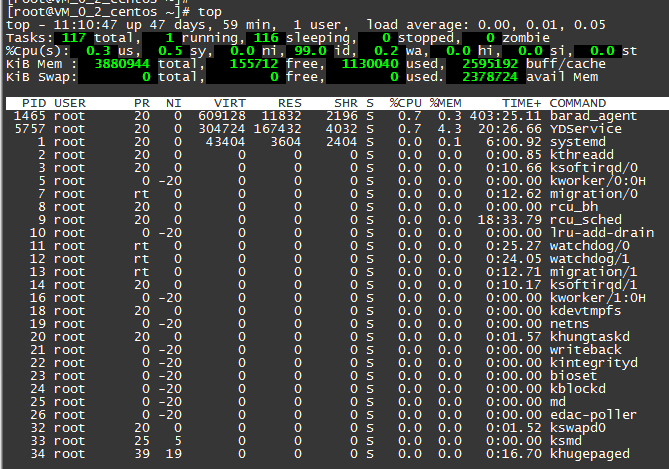
前⼏⾏⽔平显示了不同系统参数的概括,接下来是进程和它们在列中的属性。
(1)系统运⾏时间和平均负载:
![]()
top命令的顶部显示与uptime命令相似的输出。
这些字段显示:
- 当前时间
- 系统已运⾏的时间
- 当前登录⽤户的数量
- 相应最近5、10和15分钟内的平均负载
可以使⽤’l’命令切换uptime的显示。
(2)任务:
![]()
第⼆⾏显示的是任务或者进程的总结。进程可以处于不同的状态。
这⾥显示了全部进程的数量。除 此之外,还有正在运⾏、睡眠、停⽌、僵⼫进程的数量
(僵⼫是⼀种进程的状态)。
这些进程概括信息 可以⽤’t’切换显示。
(3)CPU 状态
![]()
下⼀⾏显示的是CPU状态。 这⾥显示了不同模式下的所占CPU时间的百分⽐。这些不同的CPU时间 表示:
- us, user: 运⾏(未调整优先级的) ⽤户进程的CPU时间
- sy,system: 运⾏内核进程的CPU时间
- ni,niced:运⾏已调整优先级的⽤户进程的CPU时间
- wa,IO wait: ⽤于等待IO完成的CPU时间
- hi:处理硬件中断的CPU时间
- si: 处理软件中断的CPU时间
- st:这个虚拟机被hypervisor偷去的CPU时间(译注:如果当前处于⼀个hypervisor下的vm,实 际上hypervisor也是要消耗⼀部分CPU处理时间的)。
可以使⽤’t’命令切换显示。
(4)内存使⽤

接下来两⾏显示内存使⽤率,有点像’free’命令。第⼀⾏是物理内存使⽤,第⼆⾏是虚拟内存使⽤(交换空间)。
物理内存显示如下:全部可⽤内存、已使⽤内存、空闲内存、缓冲内存。
相似地:交换部分显示的 是:全部、已使⽤、空闲和缓冲交换空间。
内存显示可以⽤’m’命令切换。
(5)字段/列
在横向列出的系统属性和状态下⾯,是以列显示的进程。不同的列代表下⾯要解释的不同属性。
默认上,top显示这些关于进程的属性:
PID 进程ID,进程的唯⼀标识符
USER 进程所有者的实际⽤户名。
PR 进程的调度优先级。这个字段的⼀些值是’rt’。这意味这这些进程运⾏在实时态。
NI 进程的nice值(优先级)。越⼩的值意味着越⾼的优先级。
VIRT 进程使⽤的虚拟内存。
RES 驻留内存⼤⼩。驻留内存是任务使⽤的⾮交换物理内存⼤⼩。
SHR 是进程使⽤的共享内存。
S 这个是进程的状态。它有以下不同的值: D – 不可中断的睡眠态。
R – 运⾏态
S – 睡眠态
T – 被跟踪或已停⽌
Z – 僵⼫态
%CPU ⾃从上⼀次更新时到现在任务所使⽤的CPU时间百分⽐。
%MEM 进程使⽤的可⽤物理内存百分⽐。
TIME+ 任务启动后到现在所使⽤的全部CPU时间,精确到百分之⼀秒。
COMMAND 运⾏进程所使⽤的命令。
还有许多在默认情况下不会显示的输出,它们可以显示进程的⻚错误、有效组和组ID和其他更多的信 息。
2. vmstat:虚拟内存统计工具
vmstat是Virtual Meomory Statistics(虚拟内存统计)的缩写,可对操作系统的虚拟内存、进 程、CPU活动进
⾏监控。
是对系统的整体情况进⾏统计,不⾜之处是⽆法对某个进程进⾏深⼊分析。
怎 样通过vmstat来发现系统中的瓶颈呢?
在回答这个问题前,还是让我们回顾⼀下Linux中关于虚拟内存 相关内容。
物理内存和虚拟内存区别
我们知道,直接从物理内存读写数据要⽐从硬盘读写数据要快的多,
因此,我们希望所有数据的读 取和写⼊都在内存完成,⽽内存是有限的,这样就引出了物理内存与虚拟内存的概
念。
物理内存就是系统硬件提供的内存⼤⼩,是真正的内存,相对于物理内存,在linux下还有⼀个虚拟 内存的概念,
虚拟内存就是为了满⾜物理内存的不⾜⽽提出的策略,它是利⽤磁盘空间虚拟出的⼀块逻 辑内存,⽤作虚拟内存的磁盘空间被称为交
换空间(Swap Space)。
用法
vmstat [-a] [-n] [-S unit] [delay [ count]]
vmstat [-s] [-n] [-S unit]
vmstat [-m] [-n] [delay [ count]]
vmstat [-d] [-n] [delay [ count]]
vmstat [-p disk partition] [-n] [delay [ count]]
vmstat [-f]
vmstat [-V]
-a:显示活跃和⾮活跃内存
-f:显示从系统启动⾄今的fork数量 。
-m:显示slabinfo -n:只在开始时显示⼀次各字段名称。
-s:显示内存相关统计信息及多种系统活动数量。
delay:刷新时间间隔。如果不指定,只显示⼀条结果。
count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为⽆穷。
-d:显示磁盘相关统计信息。
-p:显示指定磁盘分区统计信息
-S:使⽤指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节 (byte)。
默认单位为K(1024 bytes)
-V:显示vmstat版本信息。
示例一
每3秒输出⼀条结果
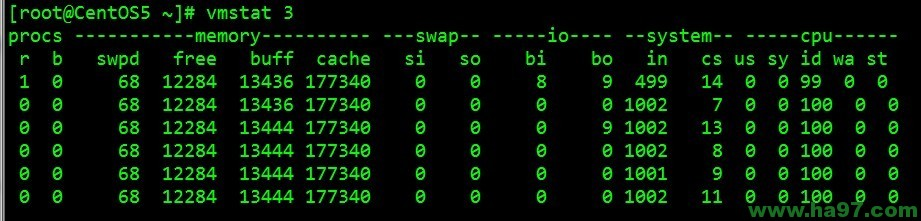
字段说明:
Procs(进程)
r: 运⾏队列中进程数量,这个值也可以判断是否需要增加CPU。(⻓期⼤于1)
b: 等待IO的进程数量
Memory(内存)
swpd: 使⽤虚拟内存⼤⼩
注意:如果swpd的值不为0,但是SI,SO的值⻓期为0,这种情况不会影响系统性能。
free: 空闲物理内存⼤⼩
buff: ⽤作缓冲的内存⼤⼩
cache: ⽤作缓存的内存⼤⼩
注意:如果cache的值⼤的时候,说明cache处的⽂件数多,如果频繁访问到的⽂件都能被cache处,那 么磁盘的读IO bi会⾮常⼩。
Swap
si: 每秒从交换区写到内存的⼤⼩,由磁盘调⼊内存
so: 每秒写⼊交换区的内存⼤⼩,由内存调⼊磁盘
注意:内存够⽤的时候,这2个值都是0,如果这2个值⻓期⼤于0时,系统性能会受到影响,磁盘IO和
CPU资源都会被消耗。有些朋友看到空闲内存(free)很少的或接近于0时,就认为内存不够⽤了,不能 光看这⼀
点,还要结合si和so,如果free很少,但是si和so也很少(⼤多时候是0),那么不⽤担⼼,系 统性能这时不会受
到影响的。
IO(现在的Linux版本块的⼤⼩为1kb)
bi: 每秒读取的块数
bo: 每秒写⼊的块数
注意:随机磁盘读写的时候,这2个值越⼤(如超出1024k),能看到CPU在IO等待的值也会越⼤。
系统
in: 每秒中断数,包括时钟中断。
cs: 每秒上下⽂切换数。
注意:上⾯2个值越⼤,会看到由内核消耗的CPU时间会越⼤。
CPU(以百分⽐表示)
us: ⽤户进程执⾏时间百分⽐(user time)
注意: us的值⽐较⾼时,说明⽤户进程消耗的CPU时间多,但是如果⻓期超50%的使⽤,
那么我们就该 考虑优化程序算法或者进⾏加速。
sy: 内核系统进程执⾏时间百分⽐(system time)
注意:sy的值⾼时,说明系统内核消耗的CPU资源多,这并不是良性表现,我们应该检查原因。
wa: IO等待时间百分⽐
注意:wa的值⾼时,说明IO等待⽐较严重,这可能由于磁盘⼤量作随机访问造成,也有可能磁盘出现 瓶颈(块操作)。
备注:
如果r经常⼤于4,id经常少于40,表示cpu的负荷很重。
如果bi,bo⻓期不等于0,表示内存不⾜。
如果disk经常不等于0,且在b中的队列⼤于3,表示io性能不好。
Linux在具有⾼稳定性、可靠性的同时,具有很好的可伸缩性和扩展性,能够针对不同的应⽤和硬件环 境调整,优
化出满⾜当前应⽤需要的最佳性能。
因此企业在维护Linux系统、进⾏系统调优时,了解系 统性能分析⼯具是⾄关重要的。
示例二
显示活跃和⾮活跃内存
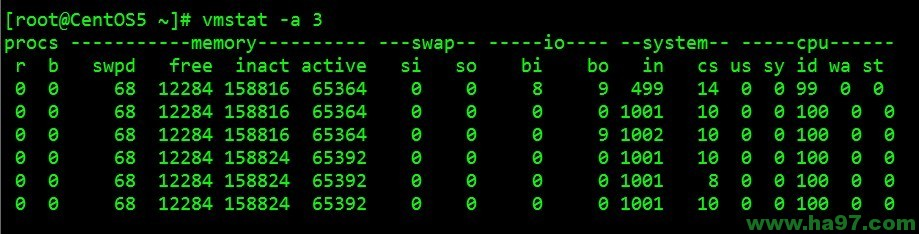
使⽤-a选项显示活跃和⾮活跃内存时,所显示的内容除增加inact和active外,其他显示内容与例⼦1相 同。
字段说明:
Memory(内存)
inact: ⾮活跃内存⼤⼩(当使⽤-a选项时显示)
active: 活跃的内存⼤⼩(当使⽤-a选项时显示)
示例三
显示从系统启动⾄今的fork数量
vmstat -f 【 linux下创建进程的系统调⽤是fork】
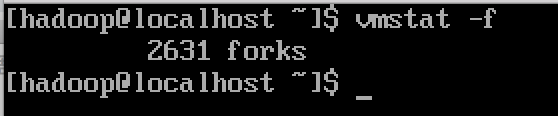
说明:信息是从/proc/stat中的processes字段⾥取得的
示例四
查看详细信息
vmstat -s 【显示内存相关统计信息及多种系统活动数量】
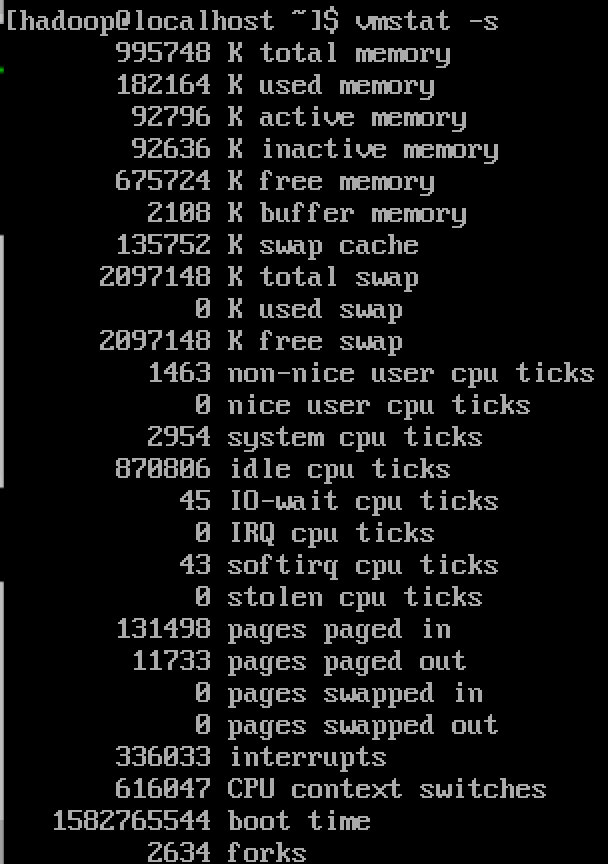
说明:这些vvmstat的分别来⾃于/proc/meminfo,/proc/stat和/proc/vmstat
示例五
vmstat -d 【查看磁盘的读写】

说明:这些信息主要来⾃于/proc/diskstats.
示例六
查看/dev/sda1磁盘的读/写
vmstat -p /dev/sda1 【显示指定磁盘分区统计信息】

说明:这些信息主要来⾃于/proc/diskstats. reads:来⾃于这个分区的读的次数。
read sectors:来⾃于这个分区的读扇区的次数。
writes:来⾃于这个分区的写的次数。
requested writes:来⾃于这个分区的写请求次数。
3. iostat:输⼊/输出统计工具
iostat:I/O statistics(输⼊/输出统计)的缩写,iostat⼯具将对系统的磁盘操作活动进⾏监视。
它 的特点是汇报磁盘活动统计情况,同时也会汇报出CPU使⽤情况。
iostat也有⼀个弱点,就是它不能对 某个进程进⾏深⼊分析,仅对系统的整体情况进⾏分析。
iostat 安装
# iostat属于sysstat软件包。可以直接安装。
yum install sysstat示例⼀
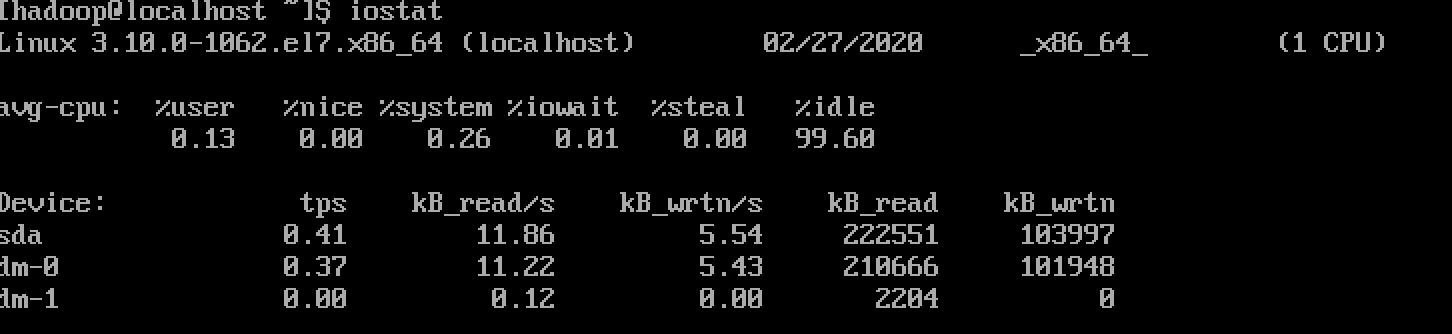
单独执⾏iostat,显示的结果为从系统开机到当前执⾏时刻的统计信息。
以上输出中,包含三部分:
| 选项 | 说明 |
| 第⼀⾏ | 最上⾯指示系统版本、主机名和当前⽇期 |
| avg-cpu | 总体cpu使⽤情况统计信息,对于多核cpu,这⾥为所有cpu的平均值 |
| Device | 各磁盘设备的IO统计信息 |
avg-cpu中各列参数含义如下:
| 选项 | 说明 |
| %user | CPU在⽤户态执⾏进程的时间百分⽐。 |
| %nice | CPU在⽤户态模式下,⽤于nice操作,所占⽤CPU总时间的百分⽐ |
| %system | CPU处在内核态执⾏进程的时间百分⽐ |
| %iowait | CPU⽤于等待I/O操作占⽤CPU总时间的百分⽐ |
| %steal | 管理程序(hypervisor)为另⼀个虚拟进程提供服务⽽等待虚拟CPU的百分⽐ |
| %idle | CPU空闲时间百分⽐ |
- 若 %iowait 的值过⾼,表示硬盘存在I/O瓶颈
- 若 %idle 的值⾼但系统响应慢时,有可能是CPU等待分配内存,此时应加⼤内存容量
- 若 %idle 的值持续低于1,则系统的CPU处理能⼒相对较低,表明系统中最需要解决的资源是 CPU
Device中各列参数含义如下:
| 选项 | 说明 |
| Device | 设备名称 |
| tps | 每秒向磁盘设备请求数据的次数,包括读、写请求,为rtps与wtps的和。出于效率考虑,每⼀次IO下发后并不是⽴即处理请求,⽽是将请求合并(merge),这⾥tps指请求合并后的请求计数。 |
| kB_read/s | 每秒从设备(drive expressed)读取的数据量; |
| kB_wrtn/s | 每秒向设备(drive expressed)写⼊的数据量; |
| kB_read | 读取的总数据量; |
| kB_wrtn | 写⼊的总数量数据量; |
我们可以使⽤-c选项单独显示avg-cpu部分的结果,使⽤-d选项单独显示Device部分的信息。
定时显示所有信息
# 【每隔2秒刷新显示,且显示3次】
iostat 2 3显示指定磁盘信息
iostat -d /dev/sda显示tty和Cpu信息
iostat -t以M为单位显示所有信息
iostat -m查看设备使用率(%util)、响应时间(await)
# 【-d 显示磁盘使⽤情况,-x 显示详细信息】
iostat -d -x -k 1 1示例⼆
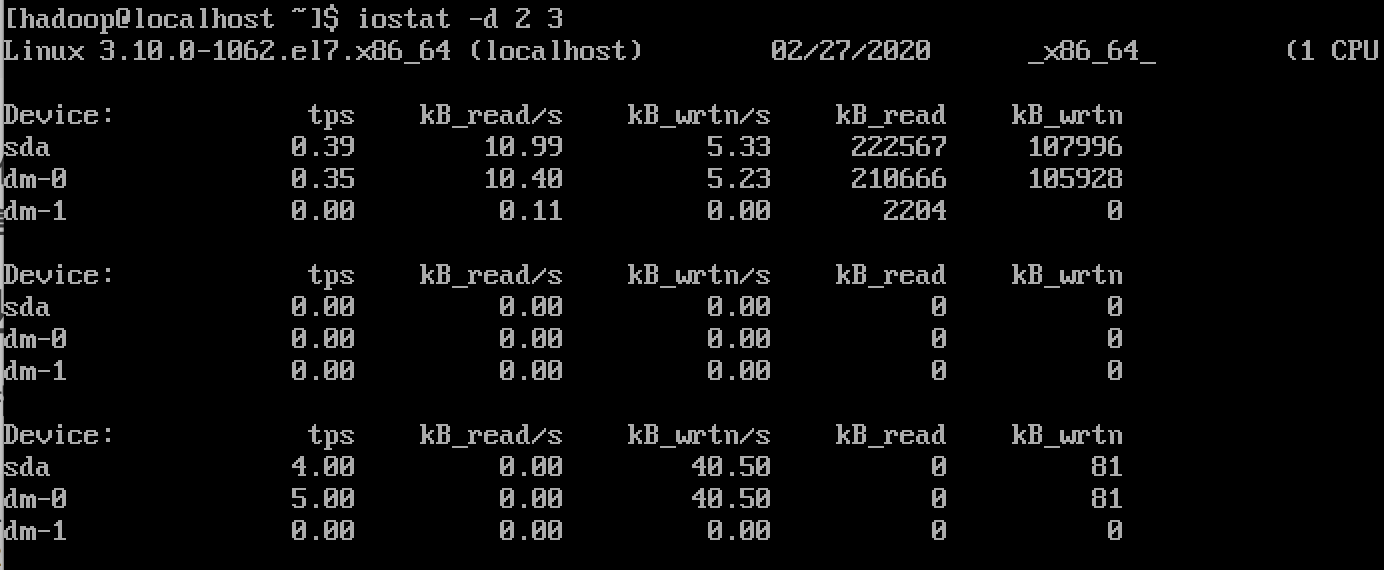
以上命令输出Device的信息,采样时间为2秒,采样3次,若不指定采样次数,则iostat会⼀直输出采样 信息,直
到按”ctrl+c”退出命令。
注意,第1次采样信息与单独执⾏iostat的效果⼀样,为从系统开机到 当前执⾏时刻的统计信息。
示例三
以kB为单位显示读写信息(-k选项)/以mB为单位显示读写信息(-m选项)
我们可以使⽤-k选项,指定iostat的部分输出结果以kB为单位,⽽不是以扇区数为单位:
iostat -d -k
以上输出中,kB_read/s、kB_wrtn/s、kB_read和kB_wrtn的值均以kB为单位,
相⽐以扇区数为单位, 这⾥的值为原值的⼀半(1kB=512bytes*2)
示例四
为显示更详细的io设备统计信息,我们可以使⽤-x选项,在分析io瓶颈时,⼀般都会开启-x选项:

以上各列的含义如下:
| 选项 | 说明 |
| rrqm/s | 每秒对该设备的读请求被合并次数,⽂件系统会对读取同块(block)的请求进⾏合并 |
| wrqm/s | 每秒对该设备的写请求被合并次数 |
| r/s | 每秒完成的读次数 |
| w/s | 每秒完成的写次数 |
| rkB/s | 每秒读数据量(kB为单位) |
| wkB/s | 每秒写数据量(kB为单位) |
| avgrq-sz | 平均每次IO操作的数据量(扇区数为单位) |
| avgqu-sz | 平均等待处理的IO请求队列⻓度 |
| await | 平均每次IO请求等待时间(包括等待时间和处理时间,毫秒为单位) |
| svctm | 平均每次IO请求的处理时间(毫秒为单位) |
| %util | 采⽤周期内⽤于IO操作的时间⽐率,即IO队列⾮空的时间⽐率 |
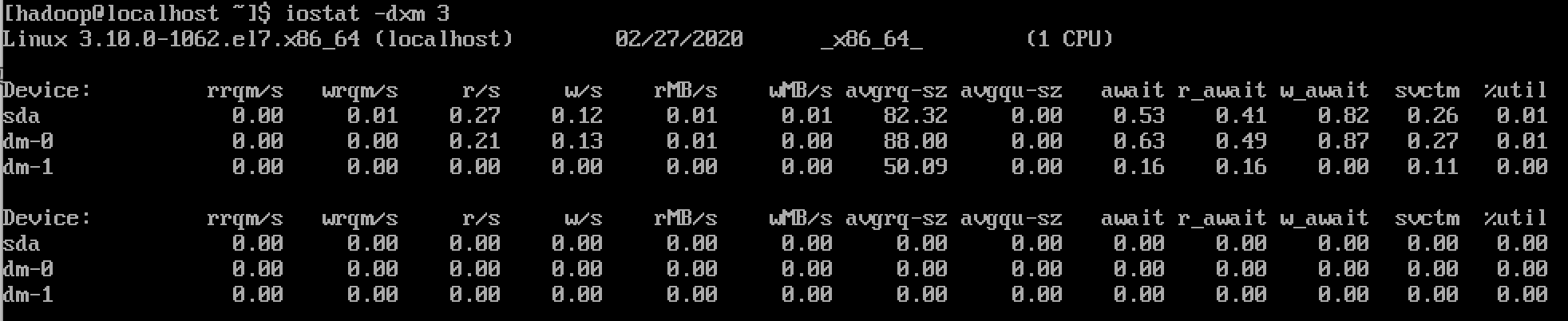
示例五
实际查看时,⼀般结合着多个选项查看: 如 iostat -dxm 3
4. pidstat:进程监控工具
pidstat是sysstat⼯具的⼀个命令,⽤于监控全部或指定进程的cpu、内存、线程、设备IO等系统资源
的占⽤情况。
pidstat⾸次运⾏时显示⾃系统启动开始的各项统计信息,
之后运⾏pidstat将显示⾃上 次运⾏该命令以后的统计信息。
⽤户可以通过指定统计的次数和时间来获得所需的统计信息。
pidstat 安装
pidstat 是sysstat软件套件的⼀部分,sysstat包含很多监控linux系统状态的⼯具,它能够从⼤多数linux发⾏版的
软件源中获得。
- 在Debian/Ubuntu系统中可以使⽤下⾯的命令来安装: apt-get install sysstat
- CentOS/Fedora/RHEL版本的linux中则使⽤下⾯的命令yum install sysstat
用法
pidstat [ 选项 ] [ <时间间隔> ] [ <次数> ] 
常用的参数:
- -u:默认的参数,显示各个进程的cpu使⽤统计
- -r:显示各个进程的内存使⽤统计
- -d:显示各个进程的IO使⽤情况
- -p:指定进程号
- -w:显示每个进程的上下⽂切换情况
- -t:显示选择任务的线程的统计信息外的额外信息
- -T { TASK | CHILD | ALL }这个选项指定了pidstat监控的。TASK表示报告独⽴的task,CHILD关键字表示报告进程下所有线 程统计信息。ALL表示报告独⽴的task和task下⾯的所有线程。 注意:task和⼦线程的全局的统计信息和pidstat选项⽆关。这些统计信息不会对应到当前的统计 间隔,这些统计信息只有在⼦线程kill或者完成的时候才会被收集。
- -V:版本号
- -h:在⼀⾏上显示了所有活动,这样其他程序可以容易解析。
- -I:在SMP环境,表示任务的CPU使⽤率/内核数量
- -l:显示命令名和所有参数
示例一
查看所有进程的 CPU 使⽤情况( -u -p ALL)
pidstat
pidstat -u -p ALLpidstat 和 pidstat -u -p ALL 是等效的。
pidstat 默认显示了所有进程的cpu使⽤率。
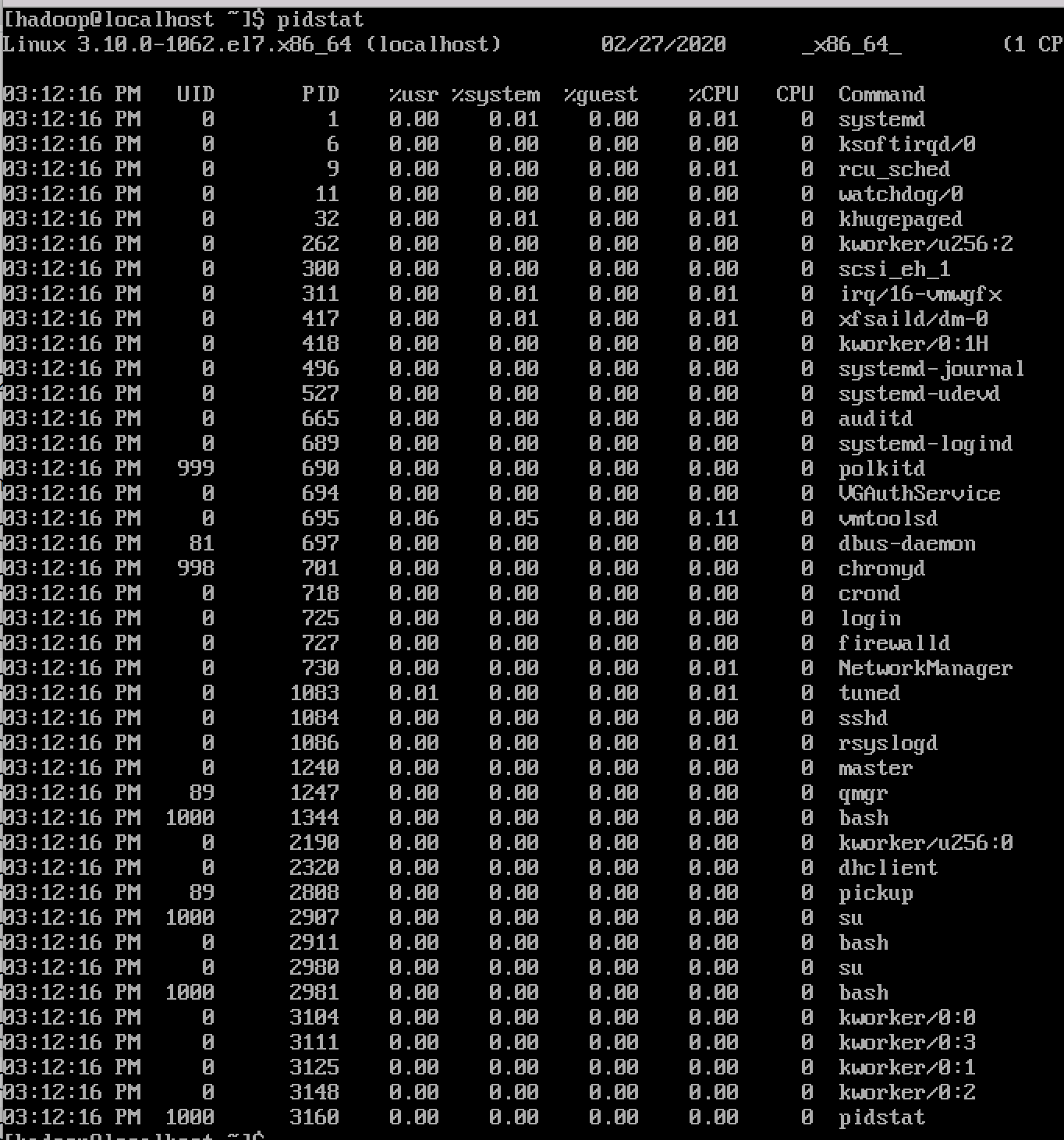
详细说明
- PID:进程ID %usr:进程在⽤户空间占⽤cpu的百分⽐
- %system:进程在内核空间占⽤cpu的百分⽐
- %guest:进程在虚拟机占⽤cpu的百分⽐
- %CPU:进程占⽤cpu的百分⽐
- CPU:处理进程的cpu编号
- Command:当前进程对应的命令
示例⼆
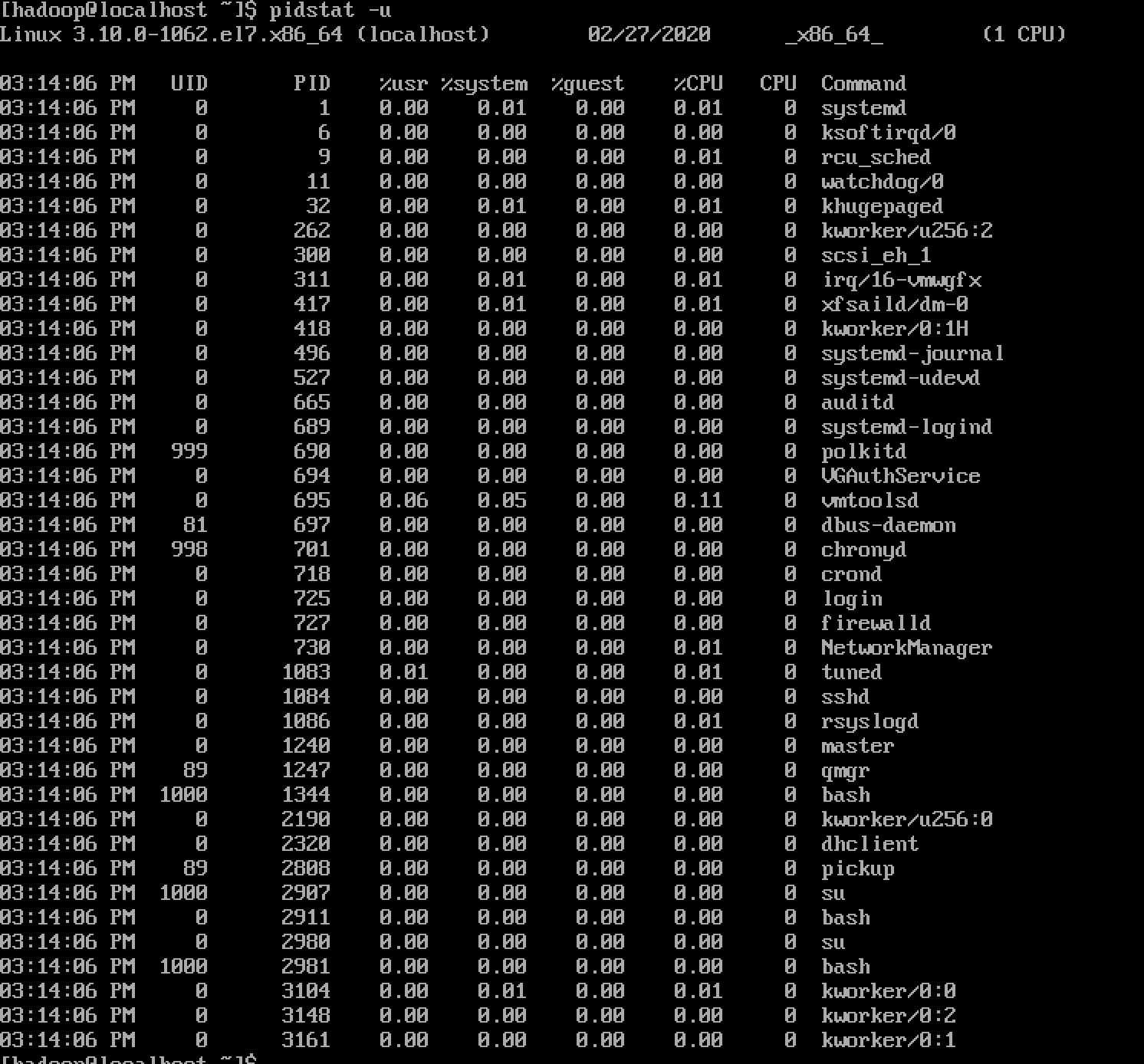
cpu使⽤情况统计(-u)
pidstat -u使⽤-u选项,pidstat将显示各活动进程的cpu使⽤统计,执⾏”pidstat -u”与单独执⾏”pidstat”的效果⼀ 样。
示例三
内存使⽤情况统计(-r)
pidstat -r使⽤-r选项,pidstat将显示各活动进程的内存使⽤统计:
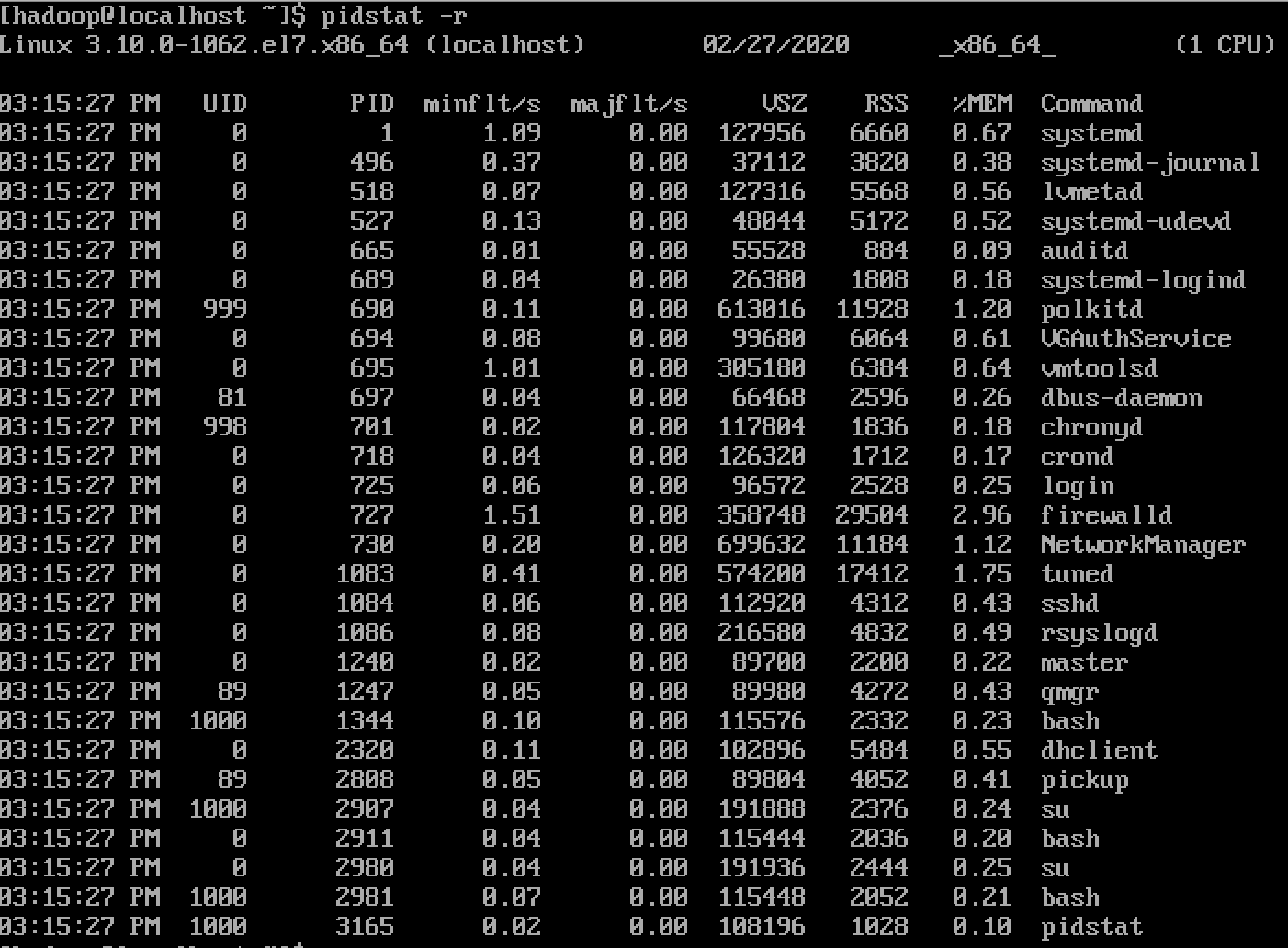
PID:进程标识符
Minflt/s:任务每秒发⽣的次要错误,不需要从磁盘中加载⻚
Majflt/s:任务每秒发⽣的主要错误,需要从磁盘中加载⻚
VSZ:虚拟地址⼤⼩,虚拟内存的使⽤KB RSS:常驻集合⼤⼩,⾮交换区五⾥内存使⽤KB Command:task命令
名
示例四
显示各个进程的IO使⽤情况(-d)
pidstat -d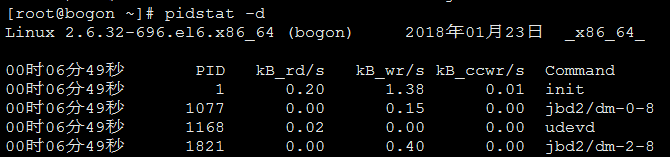
报告IO统计显示以下信息:
- PID:进程id kB_rd/s:每秒从磁盘读取的KB
- pidstat -d
- kB_wr/s:每秒写⼊磁盘
- KB kB_ccwr/s:任务取消的写⼊磁盘的KB。当任务截断脏的pagecache的时候会发⽣。
- COMMAND:task的命令名
示例五
显示每个进程的上下⽂切换情况(-w)

- PID:进程id Cswch/s:每秒主动任务上下⽂切换数量
- Nvcswch/s:每秒被动任务上下⽂切换数量
- Command:命令名
示例六
显示选择任务的线程的统计信息外的额外信息 (-t)

- TGID:主线程的表示
- TID:线程id %usr:进程在⽤户空间占⽤cpu的百分⽐
- %system:进程在内核空间占⽤cpu的百分⽐
- %guest:进程在虚拟机占⽤cpu的百分⽐
- %CPU:进程占⽤cpu的百分⽐
- CPU:处理进程的cpu编号
- Command:当前进程对应的命令
示例七
pidstat -T TASK
pidstat -T CHILD
pidstat -T ALLTASK表示报告独⽴的task。
CHILD关键字表示报告进程下所有线程统计信息。
ALL表示报告独⽴的task和task下⾯的所有线程。
注意:task和⼦线程的全局的统计信息和pidstat选项⽆关。
这些统计信息不会对应到当前的统计间隔, 这些统计信息只有在⼦线程kill或者完成的时候才会被收集。

- PID:进程id Usr-ms:任务和⼦线程在⽤户级别使⽤的毫秒数。
- System-ms:任务和⼦线程在系统级别使⽤的毫秒数。
- Guest-ms:任务和⼦线程在虚拟机(running a virtual processor)使⽤的毫秒数。
- Command:命令名
三、第三方
1. VisualVM:多合-故障处理工具
开发⼤型 Java 应⽤程序的过程中难免遇到内存泄露、性能瓶颈等问题,⽐如⽂件、⽹络、数据库 的连接未
释放,未优化的算法等。
随着应⽤程序的持续运⾏,可能会造成整个系统运⾏效率下降,严重 的则会造成系统崩溃。为了找出程序中
隐藏的这些问题,在项⽬开发后期往往会使⽤性能分析⼯具来对 应⽤程序的性能进⾏分析和优化。
VisualVM 是⼀款免费的性能分析⼯具。它通过 jvmstat、JMX、SA(Serviceability Agent)以及 Attach
API 等多种⽅式从程序运⾏时获得实时数据,从⽽进⾏动态的性能分析。同时,它能⾃动选择更 快更轻量级的技
术尽量减少性能分析对应⽤程序造成的影响,提⾼性能分析的精度。
性能分析的主要方式
(1)监视:
监视是⼀种⽤来查看应⽤程序运⾏时⾏为的⼀般⽅法。
通常会有多个视图(View)分别 实时地显示 CPU 使⽤情况、内存使⽤情况、线程状态以及其他⼀些有⽤的信
息,以便⽤户能很快地发 现问题的关键所在。
(2)转储:
性能分析⼯具从内存中获得当前状态数据并存储到⽂件⽤于静态的性能分析。
Java 程序 是通过在启动 Java 程序时添加适当的条件参数来触发转储操作的。
它包括以下三种:
- 系统转储:JVM ⽣成的本地系统的转储,⼜称作核⼼转储。⼀般的,系统转储数据量⼤,需要平台 相关的⼯具去分析,如 Windows 上的 windbg 和 Linux 上的 gdb。
- java 转储:JVM 内部⽣成的格式化后的数据,包括线程信息,类的加载信息以及堆的统计数据。 通常也⽤于检测死锁。 堆转储:JVM 将所有对象的堆内容存储到⽂件。
- 3)快照:应⽤程序启动后,性能分析⼯具开始收集各种运⾏时数据,其中⼀些数据直接显示在监 视视图中,⽽另外⼤部分数据被保存在内部,直到⽤户要求获取快照,基于这些保存的数据的统计 信息才被显示出来。快照包含了应⽤程序在⼀段时间内的执⾏信息,通常有 CPU 快照和内存快照两种类型。
- CPU 快照:主要包含了应⽤程序中函数的调⽤关系及运⾏时间,这些信息通常可以在 CPU 快照视 图中进⾏查看。内存快照:主要包含了内存的分配和使⽤情况、载⼊的所有类、存在的对象信息及对象间的引⽤关 系等。这些信息通常可以在内存快照视图中进⾏查看。
4)性能分析:性能分析是通过收集程序运⾏时的执⾏数据来帮助开发⼈员定位程序需要被优化的 部分,从⽽提⾼
程序的运⾏速度或是内存使⽤效率,主要有以下三个⽅⾯:
- CPU 性能分析:CPU 性能分析的主要⽬的是统计函数的调⽤情况及执⾏时间,或者更简单的情况 就是统计应⽤程序的 CPU 使⽤情况。通常有 CPU 监视和 CPU 快照两种⽅式来显示 CPU 性能分析 结果。
- 内存性能分析:内存性能分析的主要⽬的是通过统计内存使⽤情况检测可能存在的内存泄露问题及 确定优化内存使⽤的⽅向。通常有内存监视和内存快照两种⽅式来显示内存性能分析结果。
- 线程性能分析:线程性能分析主要⽤于在多线程应⽤程序中确定内存的问题所在。⼀般包括线程的 状态变化情况,死锁情况和某个线程在线程⽣命期内状态的分布情况等
1.1. VisualVM 安装
VisualVM 是⼀个性能分析⼯具,⾃从 JDK 6 Update 7 以后已经作为 Oracle JDK 的⼀部分,位于 JDK 根⽬录
的 bin ⽂件夹下。VisualVM ⾃身要在 JDK6 以上的版本上运⾏,但是它能够监控 JDK1.4 以 上版本的应⽤程序。
1)JDK8 如下图:
![]()
2)官⽹安装:
VisualVM 项⽬的官⽅⽹站(https://visualvm.github.io/)⽬前提供英⽂版本和多语⾔⽀持版本下载。 多语⾔版本
主要⽀持英语、⽇语以及中⽂三种语⾔。
如果下载安装多语⾔版本的 VisualVM,安装程序 会依据操作系统的当前语⾔环境去安装相应 VisualVM 的语⾔
版本。
最新 VisualVM 版本主要⽀持的操 作系统包括:
Microsoft Windows (7, Vista, XP, Server)、Linux、Sun Solaris、Mac OS X、HP-UX 11i。
本⽂以 Microsoft Windows XP 为安装环境并⽀持中⽂。
- 从 VisualVM 项⽬的官⽅⽹站上下载 VisualVM 安装程序。
- 将 VisualVM 安装程序解压缩到本地系统。
- 导航⾄ VisualVM 安装⽬录的 bin ⽬录,然后启动 jvisualvm.exe
1.2. 安装VisualVM 上的插件
VisualVM 插件中⼼提供很多插件以供安装向 VisualVM 添加功能。可以通过 VisualVM 应⽤程序安 装,或者从
VisualVM 插件中⼼⼿动下载插件,然后离线安装。https://visualvm.github.io/pluginscenters.html,
另外,⽤户还可以通过下载插件分发⽂件 (.nbm ⽂件 ) 安装第三⽅插件为 VisualVM 添加功 能。
从 VisualVM 插件中⼼安装插件安装步骤 :
- 从主菜单中选择“⼯具”>“插件”。
- 在“可⽤插件”标签中,选中该插件的“安装”复选框。
- 单击“安装”。 逐步完成插件安装程序。
如下图: VisualVM 插件管理器
根据 .nbm ⽂件安装第三⽅插件安装步骤 :
- 从主菜单中选择“⼯具”>“插件”。
- 在“已下载”标签中,点击"添加插件"按钮,选择已下载的插件分发⽂件 (.nbm) 并打开。
- 选中打开的插件分发⽂件,并单击"安装"按钮,逐步完成插件安装程序。
package com.wclass.example;
/**
-Xms10m -Xmx10m
*/
public class HeapDemo {
public static void main(String[] args) {
System.out.println("======start=========");
try {
Thread.sleep(1000000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("========end=========");
}
}package com.wclass.example;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
/*
-Xmx600m -Xms600m -XX:+PrintGCDetails
*/
public class HeapInstanceTest {
byte[] buffer = new byte[new Random().nextInt(1024*200)];
public static void main(String[] args) {
List<HeapInstanceTest> list = new ArrayList<HeapInstanceTest>();
while (true){
list.add(new HeapInstanceTest());
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}package com.wclass.example;
import org.springframework.cglib.proxy.Enhancer;
import org.springframework.cglib.proxy.MethodInterceptor;
import org.springframework.cglib.proxy.MethodProxy;
import java.lang.reflect.Method;
/**
* -XX:MetaspaceSize=10m -XX:MaxMetaspaceSize=10m
*/
public class JavaMethodAreaOOM {
public static void main(String[] args) {
while (true){
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(OOMObject.class);
enhancer.setUseCache(false);
enhancer.setCallback(new MethodInterceptor() {
@Override
public Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy)
throws Throwable {
return methodProxy.invoke(o,args);
}
});
enhancer.create();
try {
Thread.sleep(100L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
static class OOMObject{
}
}1.3. 内存分析
VisualVM 通过检测 JVM 中加载的类和对象信息等帮助
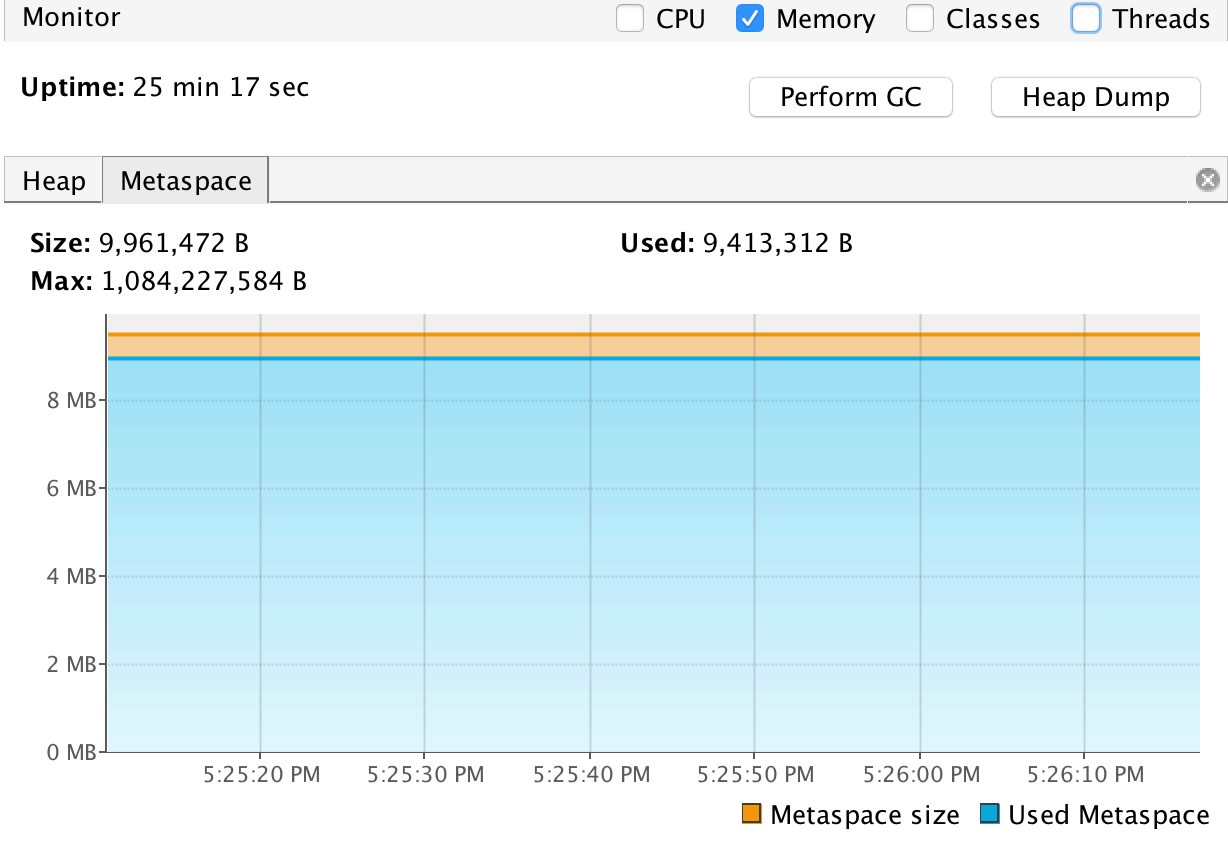
我们分析内存使⽤情况,我们可以通过 VisualVM 的监视标签和 Profiler 标签对应⽤程序进⾏内存 分析。
在监视标签内,我们可以看到实时的应⽤程序内存堆以及永久保留区域的使⽤情况。
内存堆使用情况
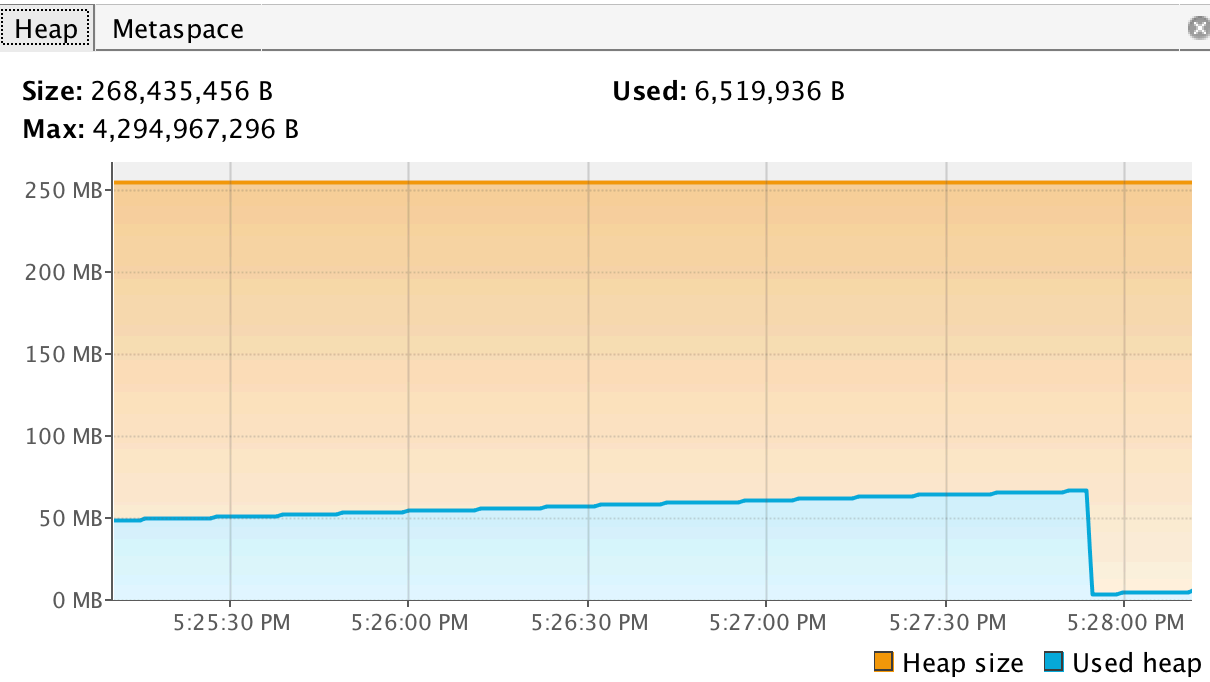
元空间使用情况
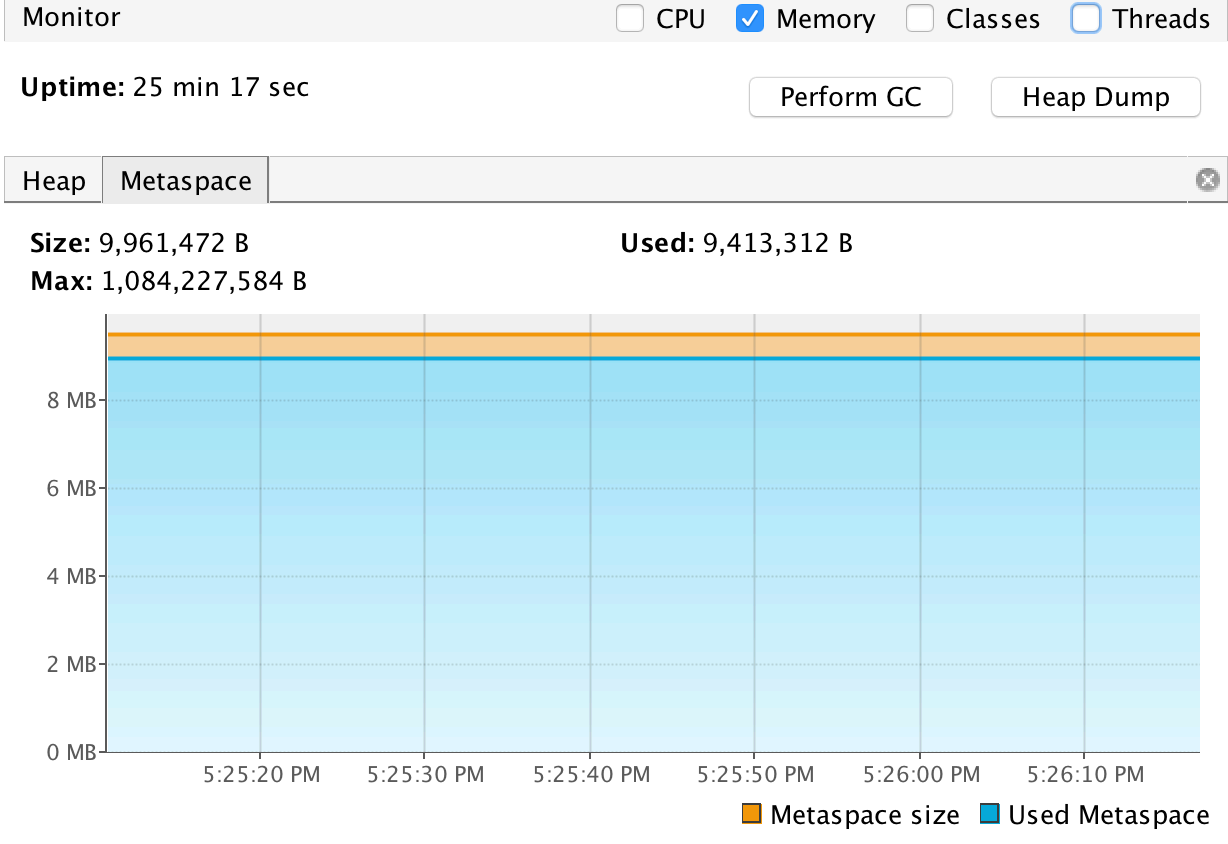
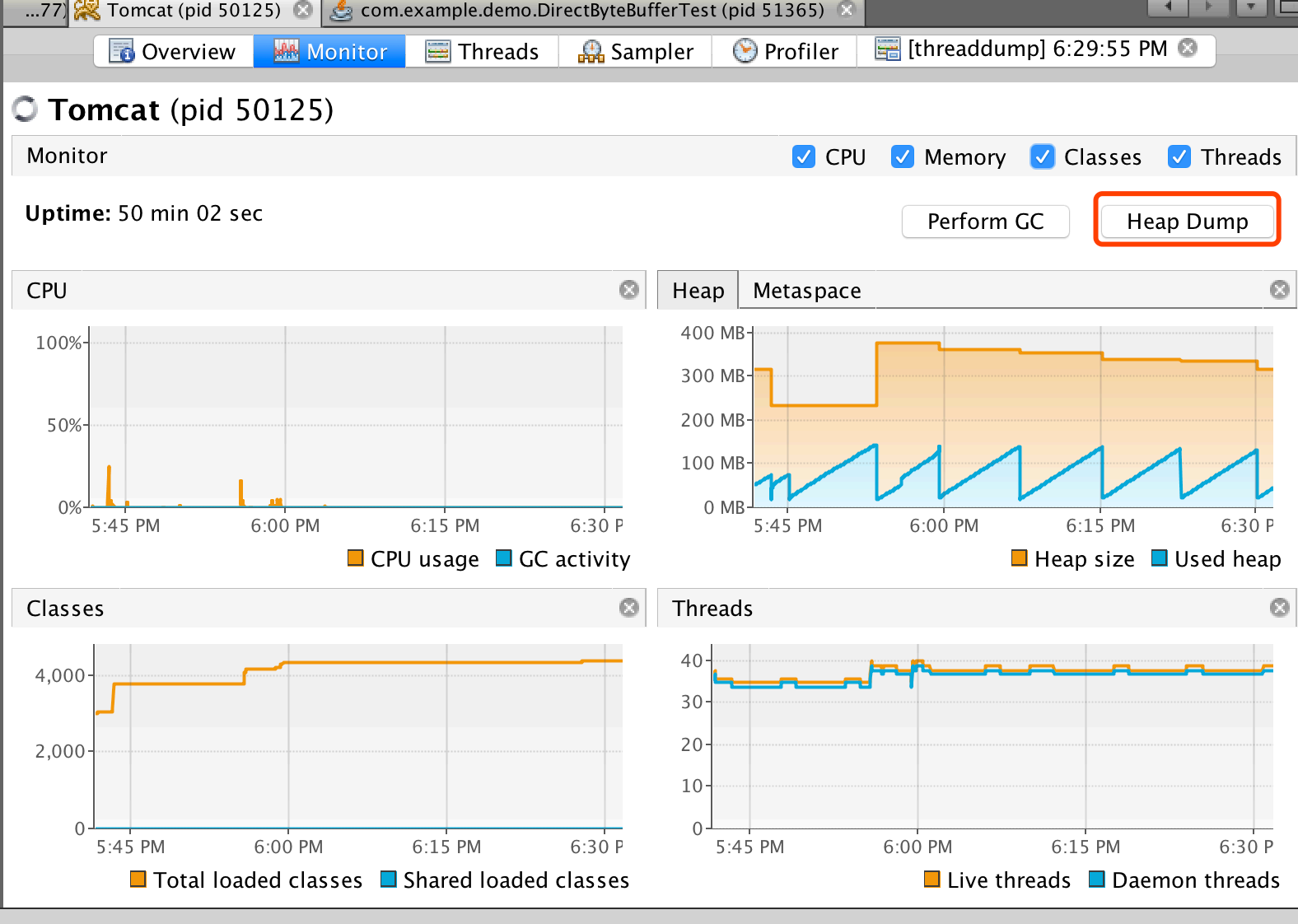
此外,我们也可以通过 Applications 窗⼝右击应⽤程序节点来启⽤“在出现 OOME 时⽣成堆 Dump”功能,
当应⽤程序出现 OutOfMemory 例外时,VisualVM 将⾃动⽣成⼀个堆转储。 开启“在出现 OOME 时⽣成堆”功能
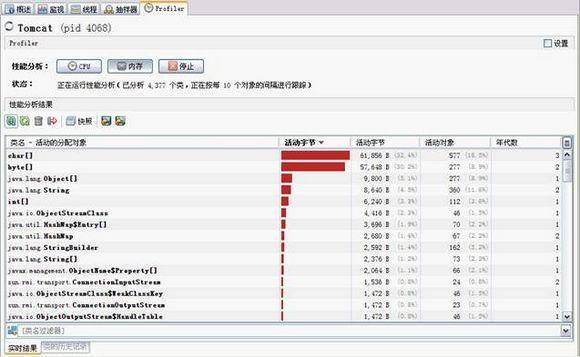
在 Profiler 标签,点击“内存”按钮将启动⼀个内存分析会话,等 VisualVM 收集和统计完相关性能 数据信息,
将会显示在性能分析结果。
通过内存性能分析结果,我们可以查看哪些对象占⽤了较多的内 存,存活的时间⽐较⻓等,以便做进⼀步的优
化。
此外,我们可以通过性能分析结果下⽅的类名过滤器对分析结果进⾏过滤。
内存分析结果:
1.4. CPU分析
VisualVM 能够监控应⽤程序在⼀段时间的 CPU 的使⽤情况,显示 CPU 的使⽤率、⽅法的执⾏效 率和频率等相
关数据帮助我们发现应⽤程序的性能瓶颈。我们可以通过 VisualVM 的监视标签和 Profiler 标签对应⽤程序进⾏
CPU 性能分析。
在监视标签内,我们可以查看 CPU 的使⽤率以及垃圾回收活动对性能的影响。过⾼的 CPU 使⽤率 可能是由于我
们的项⽬中存在低效的代码,可以通过 Profiler 标签的 CPU 性能分析功能进⾏详细的分 析。
如果垃圾回收活动过于频繁,占⽤了较⾼的 CPU 资源,可能是由内存不⾜或者是新⽣代和⽼⽣代 分配不合理导致
的等。
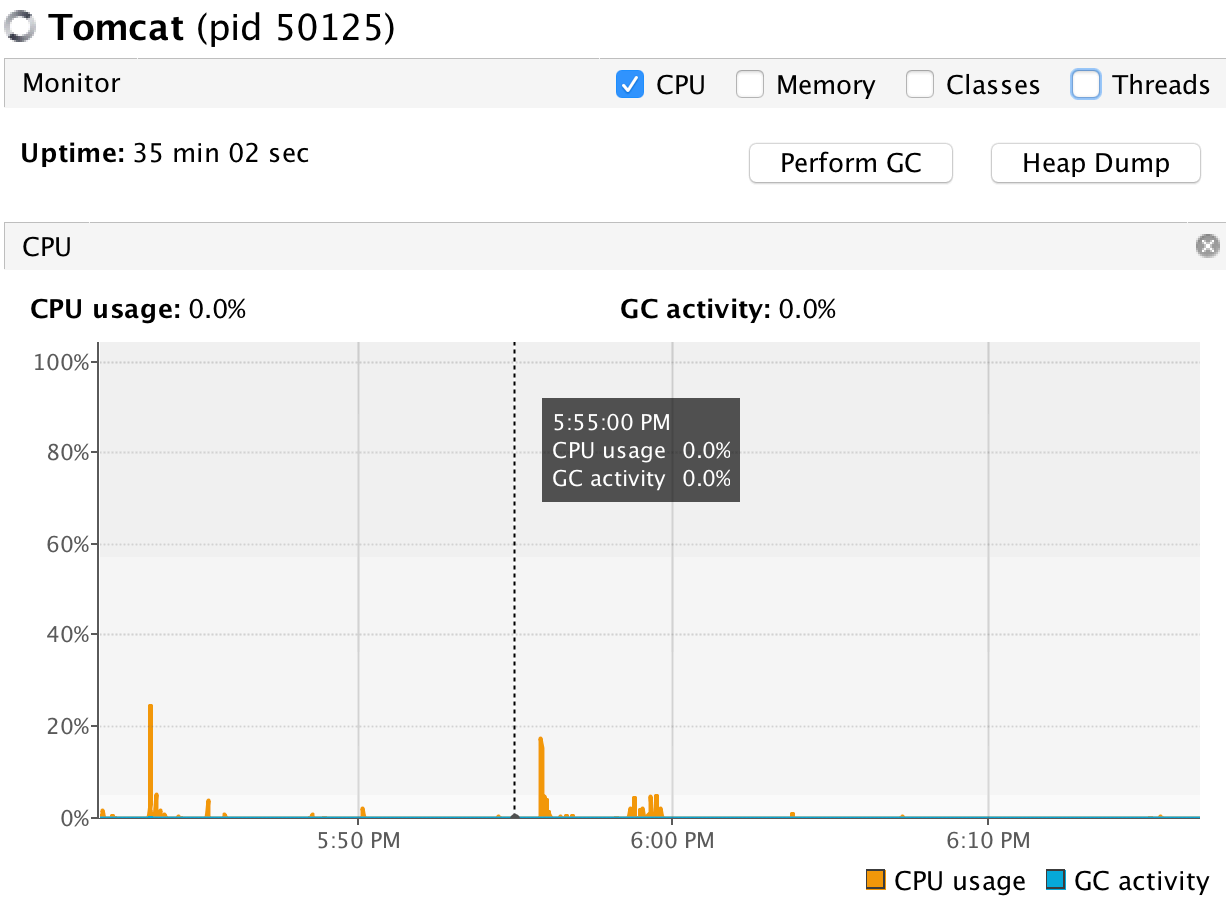
在 Profiler 标签,点击“CPU”按钮启动⼀个 CPU 性能分析会话 ,VisualVM 会检测应⽤程序所有的被 调⽤
的⽅法。当进⼊⼀个⽅法时,线程会发出⼀个“method entry”的事件,当退出⽅法时同样会发出⼀
个“method exit”的事件,这些事件都包含了时间戳。然后 VisualVM 会把每个被调⽤⽅法的总的执⾏时 间和
调⽤的次数按照运⾏时⻓展示出来。
此外,我们也可以通过性能分析结果下⽅的⽅法名过滤器对分析结果进⾏过滤。
CPU 性能分析结果
1.5. 线程分析
Java 语⾔能够很好的实现多线程应⽤程序。当我们对⼀个多线程应⽤程序进⾏调试或者开发后期做 性能调优的时
候,往往需要了解当前程序中所有线程的运⾏状态,是否有死锁、热锁等情况的发⽣,从 ⽽分析系统可能存在的
问题。
在 VisualVM 的监视标签内,我们可以查看当前应⽤程序中所有活动线程和守护线程的数量等实时 信息。
package com.wclass.example;
import java.util.concurrent.Executor;
import java.util.concurrent.Executors;
public class JStackCase {
public static Executor executor = Executors.newFixedThreadPool(3);
public static Object lock = new Object();
public static void main(String[] args) {
StackTask task1 = new StackTask();
StackTask task2 = new StackTask();
executor.execute(task1);
executor.execute(task2);
}
static class StackTask implements Runnable{
public void run(){
synchronized (lock){
cal();
}
}
public void cal(){
int i=0;
while(true){
i++;
}
}
}
}public class DeathLock {
private static Lock lock1 = new ReentrantLock();
private static Lock lock2 = new ReentrantLock();
public static void deathLock() {
Thread t1 = new Thread() {
@Override
public void run() {
try {
lock1.lock();
TimeUnit.SECONDS.sleep(1);
lock2.lock();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
Thread t2 = new Thread() {
@Override
public void run() {
try {
lock2.lock();
TimeUnit.SECONDS.sleep(1);
lock1.lock();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
t1.setName("mythread1");
t2.setName("mythread2");
t1.start();
t2.start();
}
public static void main(String[] args) {
deathLock();
}
}活跃线程情况
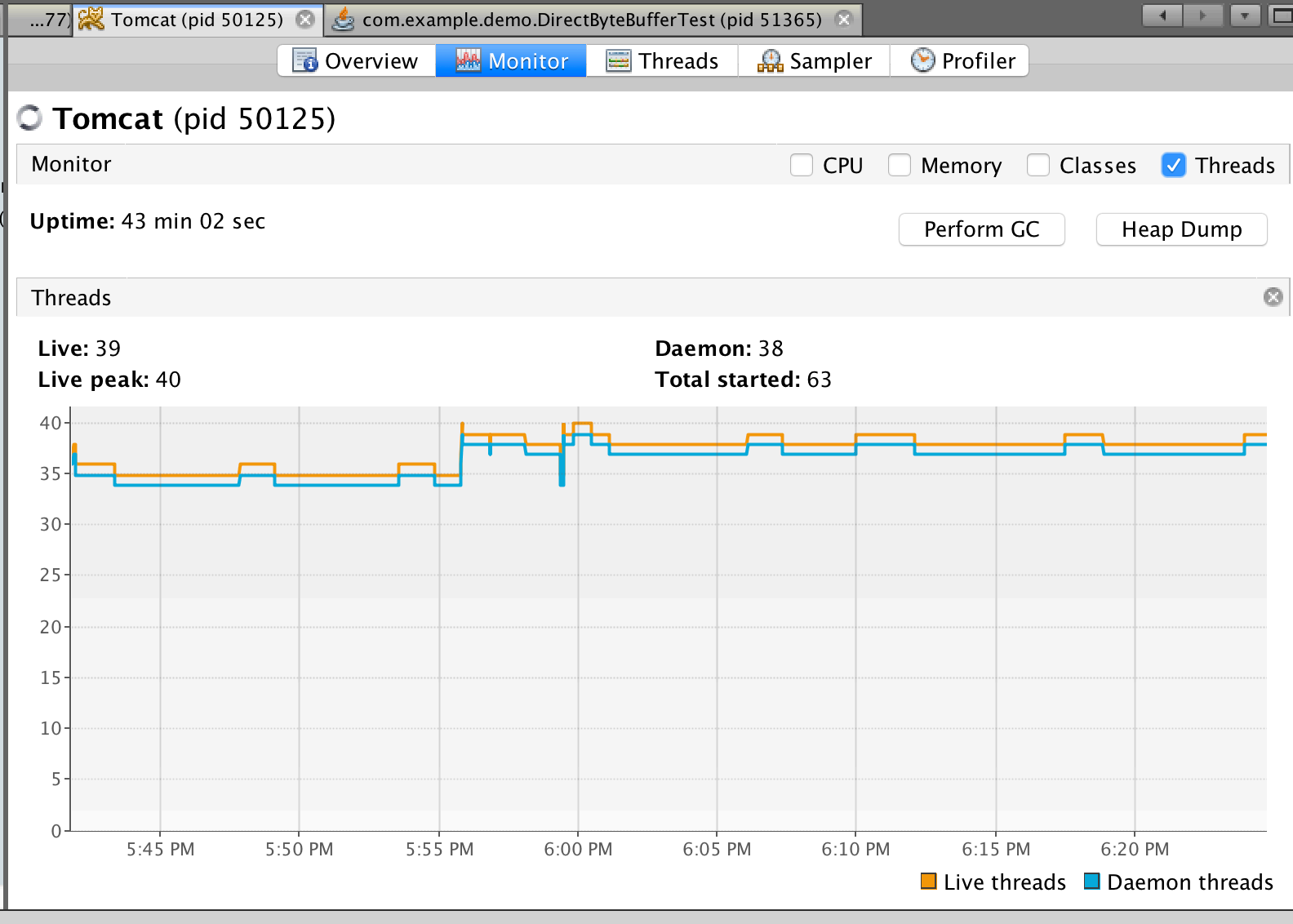
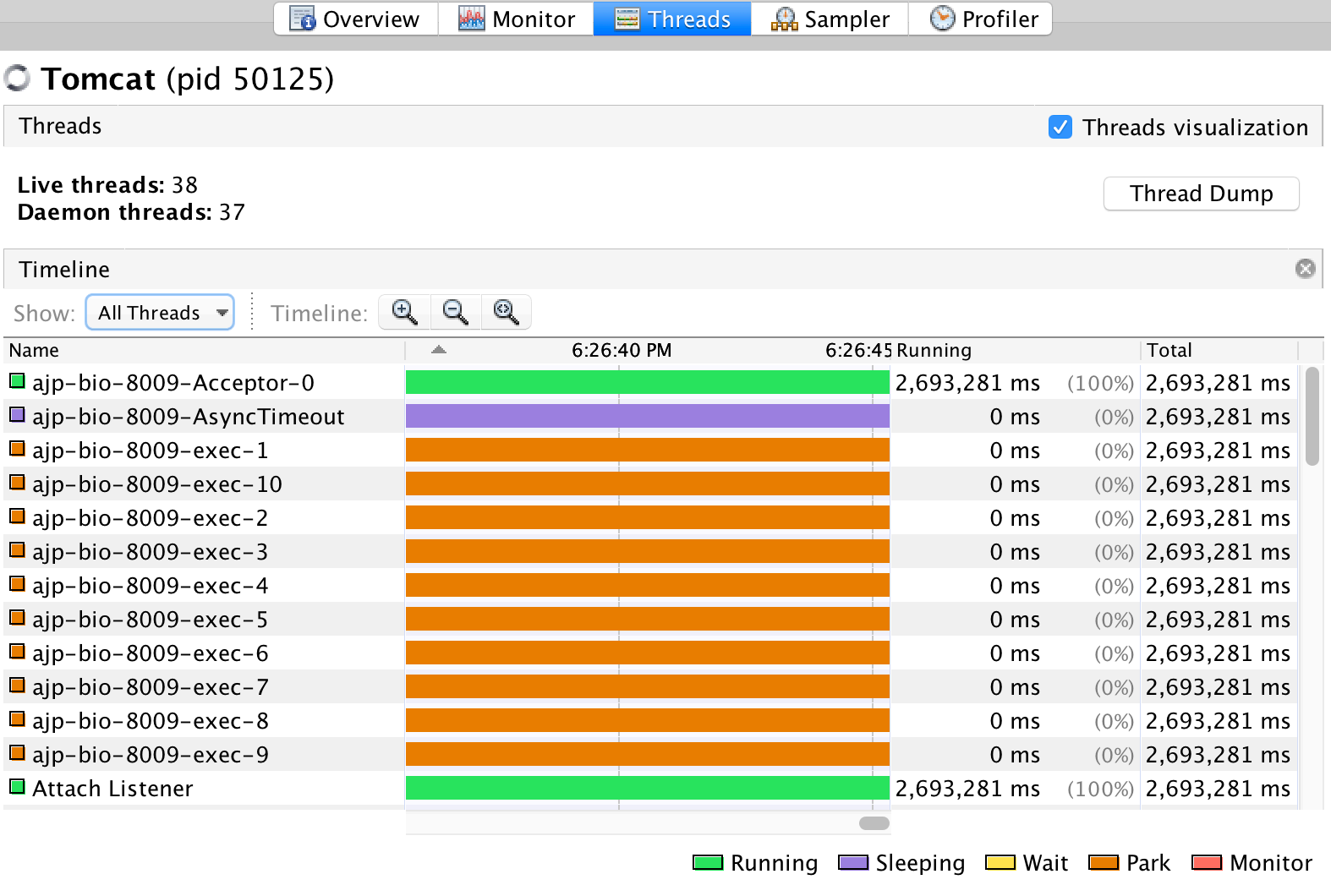
VisualVM 的线程标签提供了三种视图,默认会以时间线的⽅式展现。另外两种视图分别是表视图 和详细信息视图
时间线视图上⽅的⼯具栏提供了缩⼩,放⼤和⾃适应三个按钮,以及⼀个下拉框,我们可以选择将 所有线程、活动线程或者完成的线
程显示在视图中。
线程时间线视图
1.6. 快照功能
我们可以使⽤ VisualVM 的快照功能⽣成任意个性能分析快照并保存到本地来辅助我们进⾏性能 分析。
快照为捕获应⽤程序性能分析数据提供了⼀个很便捷的⽅式因为快照⼀旦⽣成可以在任何时候离线打开和查
看,也可以相互传阅。
VisualVM 提供了两种类型的快照:
- 1、Profiler 快照:当有⼀个性能分析会话(内存或者 CPU)正在进⾏时,我们可以通过性能分析结果 ⼯具栏的“快照”按钮⽣成 Profiler 快照捕获当时的性能分析数据。
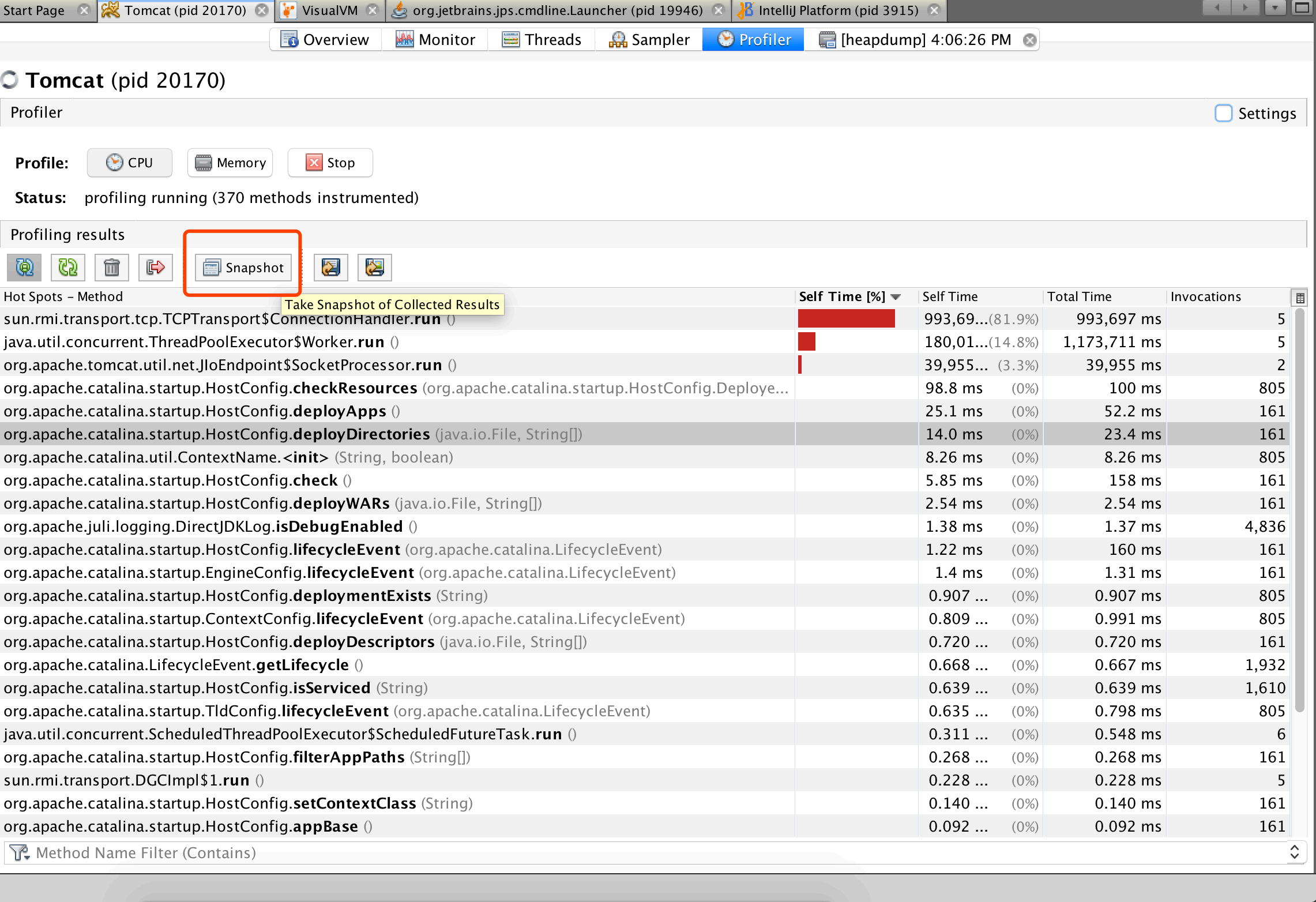
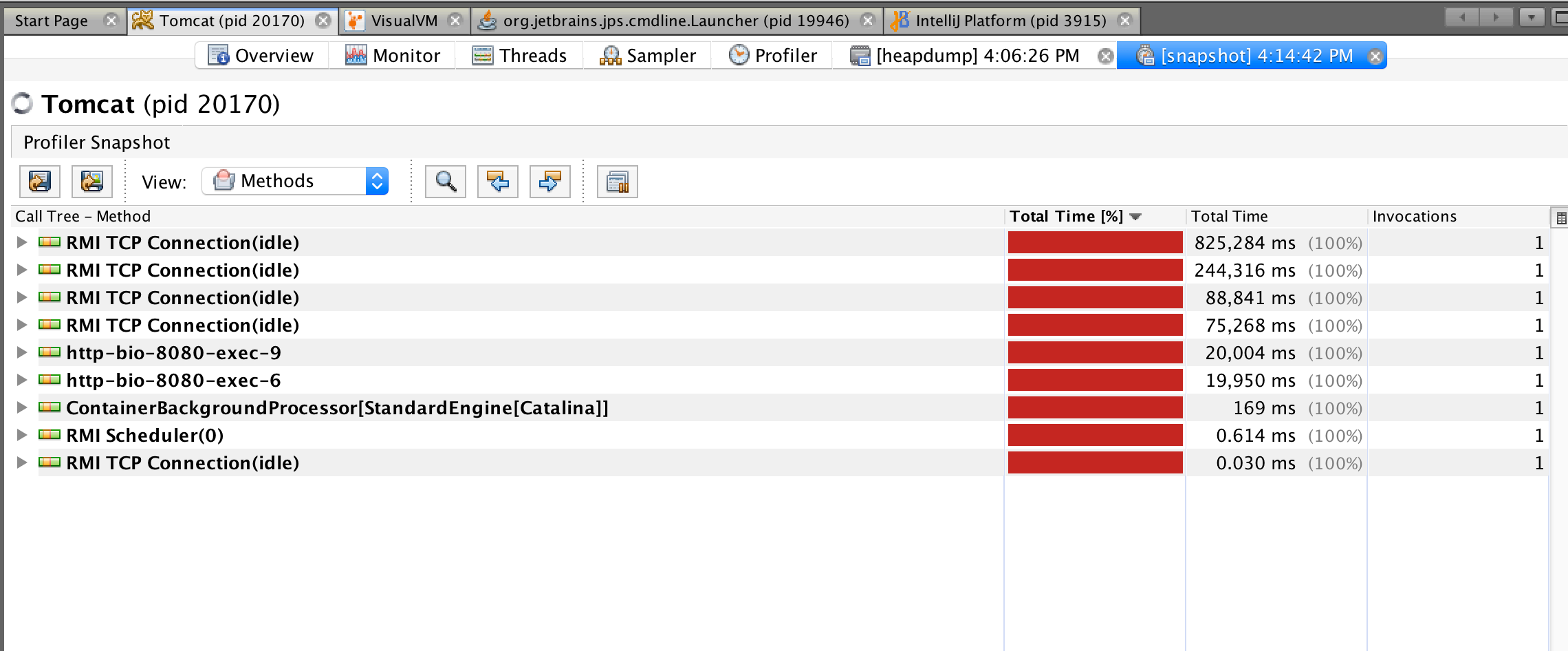
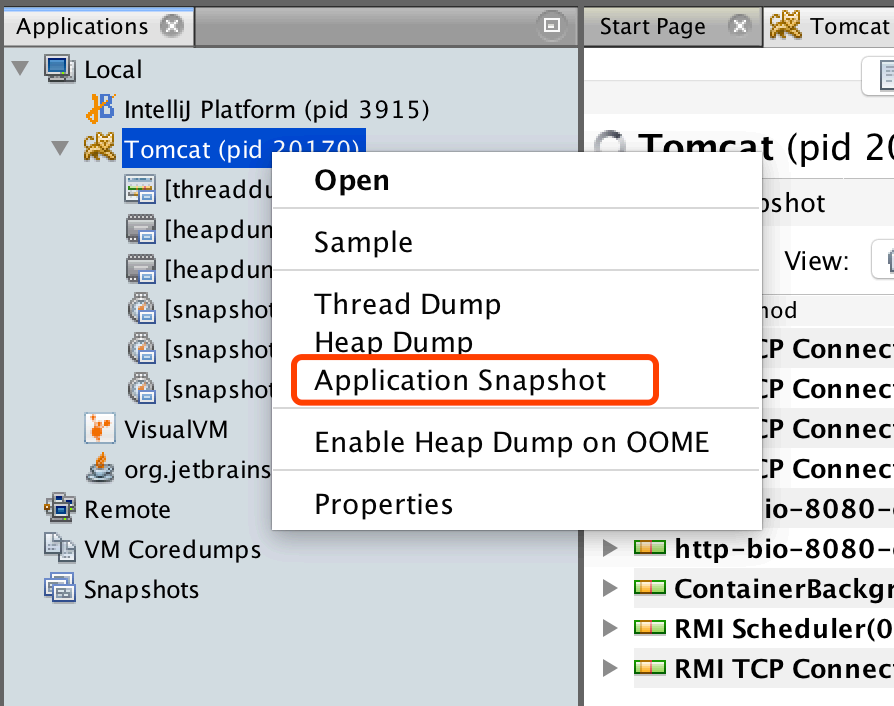
- 2、应⽤程序快照:我们可以右键点击左侧 Applications 窗⼝中应⽤程序节点,选择“应⽤程序快照”为 ⽣成⼀个应⽤程序快照。应⽤程序快照会收集某⼀时刻的堆转储,线程转储和 Profiler 快照,同时也会 捕获 JVM 的⼀些基本信息。
1.7. 转储功能
线程转储的⽣成与分析
VisualVM 能够对正在运⾏的本地应⽤程序⽣成线程转储,把活动线程的堆栈踪迹打印出来,
线程标签及线程转储功能
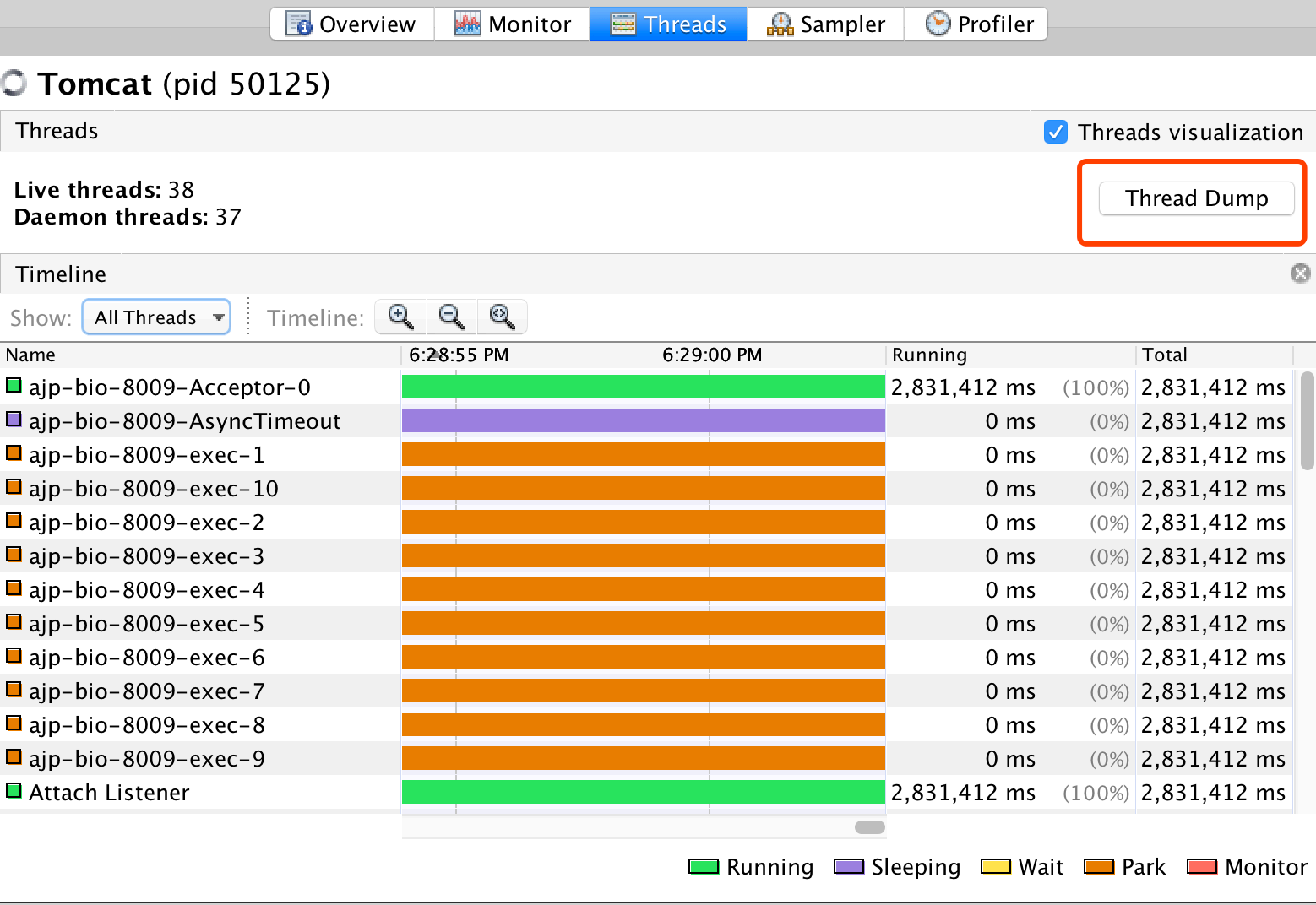
当 VisualVM 统计完应⽤程序内线程的相关数据,会把这些信息显示新的线程转储标签。
线程转储结果
堆转储的生成与分析
VisualVM 能够⽣成堆转储,统计某⼀特定时刻 JVM 中的对象信息,帮助我们分析对象的引⽤关 系、是否有内存
泄漏情况的发⽣等。
监视标签及堆转储功能
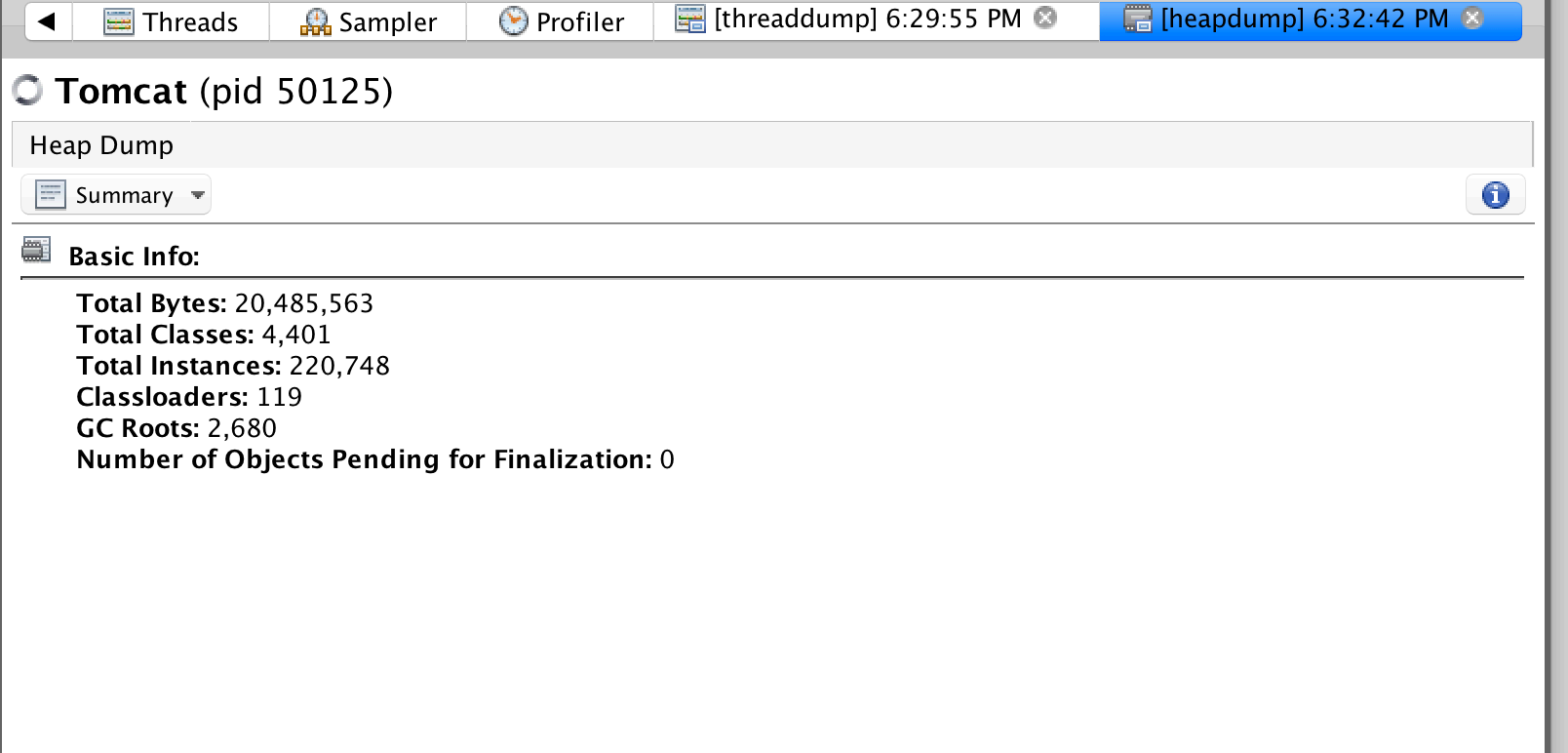
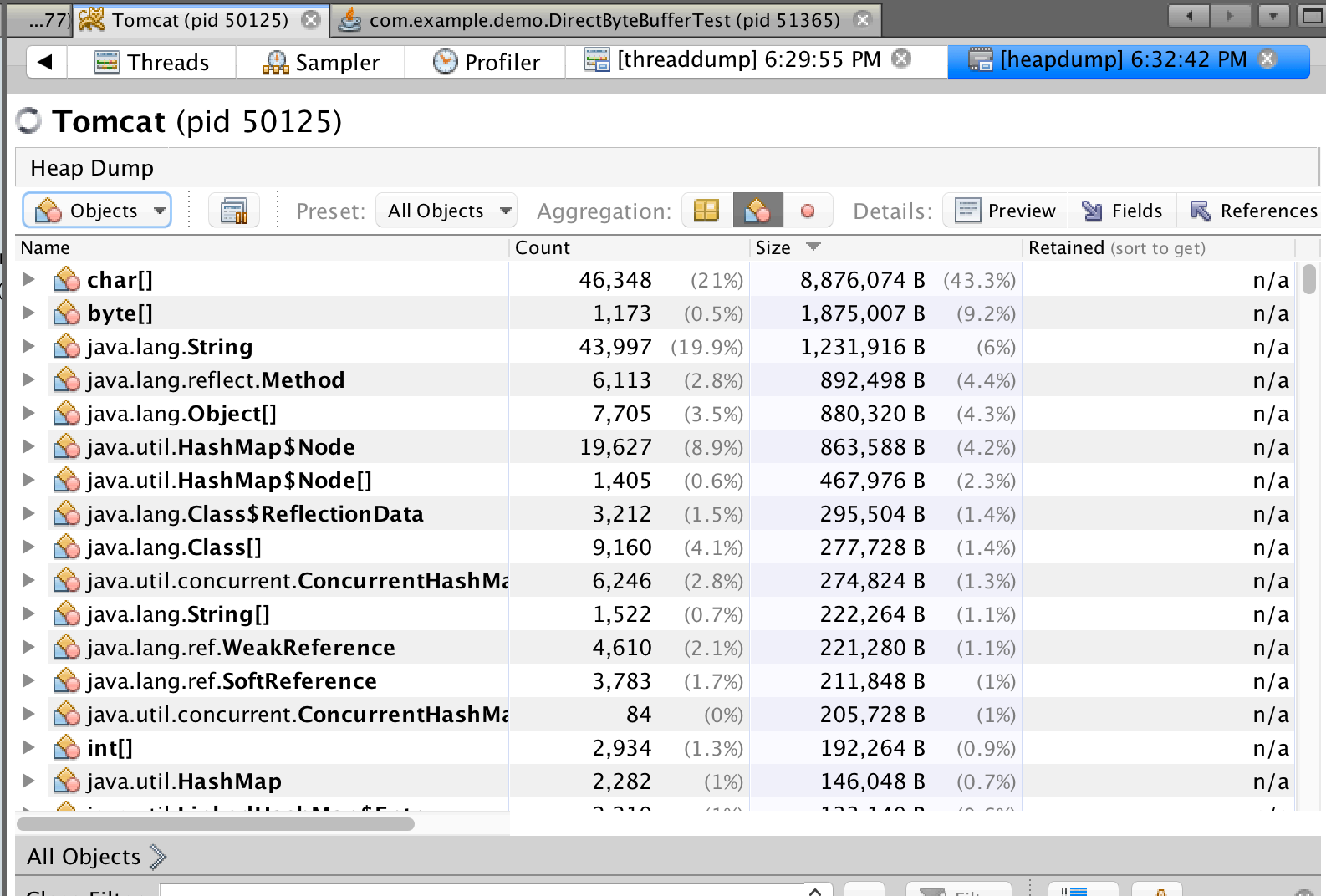
当 VisualVM 统计完堆内对象数据后,会把堆转储信息显示在新的堆转储标签内,我们可以看到摘 要、类、
实例数等信息以及通过 OQL 控制台执⾏查询语句功能。
堆转储的摘要包括转储的⽂件⼤⼩、路径等基本信息,运⾏的系统环境信息,也可以显示所有的线 程信息。
堆转储的摘要视图
通过实例数视图可以获得每个实例内部各成员变量的值以及该实例被引⽤的位置。⾸先需要在类视 图选择需
要查看实例的类。
实例数视图
线程转储和堆转储均可以另存成⽂件,以便进⾏离线分析。
转储⽂件的导出
1.8. 知识小结
本节⾸先简要列举了⼀些性能分析相关的背景知识。
然后介绍了 VisualVM 的下载和安装。
最后从 内存性能、CPU 性能、线程分析、快照功能以及转储功能五个⽅⾯展开,进⼀步说明了如何使⽤
VisualVM 进⾏性能分析。
2. MAT:内存分析⼯具
2.1. 介绍
MAT是⼀个强⼤的内存分析⼯具,可以快捷、有效地帮助我们找到内存泄露,减少内存消耗分析⼯ 具。
MAT是Memory Analyzer tool的缩写,是⼀种快速,功能丰富的Java堆分析⼯具,能帮助你查找内存泄漏和减少
内存消耗。
很多情况下,我们需要处理测试提供的hprof⽂件,分析内存相关问题,那么MAT也绝对是不⼆之选。
使⽤MAT,可以轻松实现以下功能:
- 找到最⼤的对象,因为MAT提供显示合理的累积⼤⼩(retained size)
- 探索对象图,包括inbound和outbound引⽤,即引⽤此对象的和此对象引出的
- 查找⽆法回收的对象,可以计算从垃圾收集器根到相关对象的路径
- 找到内存浪费,⽐如冗余的String对象,空集合对象。
2.2. 安装
MAT安装有两种⽅式,⼀种是以eclipse插件⽅式安装,⼀种是独⽴安装。
在MAT的官⽅⽂档中有相 应的安装⽂件下载,下载地址为:Not Found
- 若使⽤eclipse插件安装,help -> install new soft点击ADD,在弹出框中添加插件地址:http://download.eclipse.org/mat/1.9.0/update-site/,也可以直接在下载⻚⾯下载离线插件包,以离线⽅ 式安装。
- 独⽴安装,选择如下的版本,进⾏安装。

2.3. MAT相关概念说明
1 内存泄漏与内存溢出
- 内存泄露(memory leak):程序在申请内存后,⽆法释放已申请的内存空间,对象已经没⽤了(不被 任何程序逻辑所需要),还存在被根元素引⽤的情况,⽆法通过垃圾收集器进⾏⾃动回收,需要通 过找出泄漏的代码位置和原因,才好确定解决⽅案;
- 内存溢出(out of memory):程序在申请内存时,没有⾜够的内存空间供其使⽤, 内存中的对象都还 存活着,JVM的堆分配空间不⾜,需要检查堆设置⼤⼩(-Xmx与-Xms),代码是否存在对象⽣命 周期太⻓、持有状态时间过⻓的情况。memory leak会最终会导致out of memory! 内存泄露是指⽆⽤对象(不再使⽤的对象)持续占 有内存或⽆⽤对象的内存得不到及时释放,从⽽造成的内存空间的浪费称为内存泄露。内存泄露有 时不严重且不易察觉,这样开发者就不知道存在内存泄露,但有时也会很严重,会提示你Out of memory。
2 引用(强引用,软引用,弱引用,虚引用)
从JDK 1.2版本开始,对象的引⽤被划分为 4 种级别,从⽽使程序能更加灵活地控制对象的⽣命周 期。
这4种级别由⾼到低依次为:强引⽤、软引⽤、弱引⽤和虚引⽤。
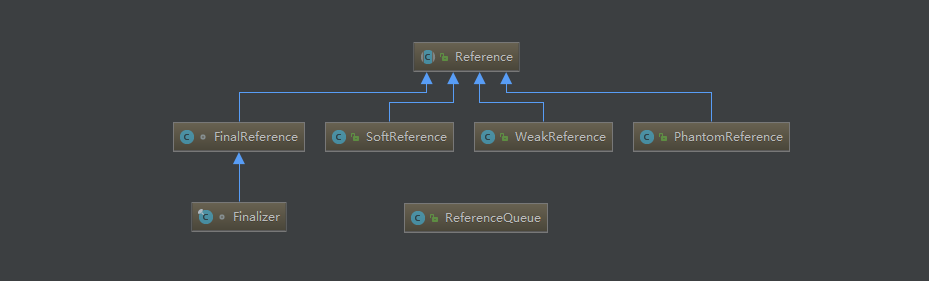
- Strong Ref(强引用):强可达性的引⽤,对象保存在内存中,只有去掉强可达,对象才被回收,通常 我们编写的代码都是Strong Ref。
- Soft Ref(软引用):对应软可达性,只要有⾜够的内存,就⼀直保持对象,直到发现内存吃紧且没有Strong Ref时才回收对象。⼀般可⽤来实现缓存,通过java.lang.ref.SoftReference类实现。
- Weak Ref(弱引用):⽐Soft Ref更弱,当发现不存在Strong Ref时,⽴刻回收对象⽽不必等到内存吃 紧的时候。通过java.lang.ref.WeakReference和java.util.WeakHashMap类实现。
- Phantom Ref(虚引用):根本不会在内存中保持任何对象,你只能使⽤Phantom Ref本身。⼀般⽤于 在进⼊finalize()⽅法后进⾏特殊的清理过程,通过 java.lang.ref.PhantomReference实现。
java中4种引⽤的级别和强度由⾼到低依次为:强引⽤ -> 软引⽤ -> 弱引⽤ -> 虚引⽤
通过表格来说明⼀下,如下:
| 引⽤类型 | 被垃圾回收时间 | ⽤途 | ⽣存时间 |
| 强引⽤ | 从来不会 | 对象的⼀般状态 | JVM停⽌运⾏时终⽌ |
| 软引⽤ | 当内存不⾜时 | 对象缓存 | 内存不⾜时终⽌ |
| 弱引⽤ | 正常垃圾回收时 | 对象缓存 | 垃圾回收后终⽌ |
| 虚引⽤ | 正常垃圾回收时 | 跟踪对象的垃圾回收 | 垃圾回收后终⽌ |
3 shallow heap及retained heap
- shallow heap:对象本身占⽤内存的⼤⼩,也就是对象头加成员变量(不是成员变量的值)的总 和,如⼀个引⽤占⽤32或64bit,⼀个integer占4bytes,Long占8bytes等。如简单的⼀个类⾥⾯ 只有⼀个成员变量int i,那么这个类的shallo size是12字节,因为对象头是12B,成员变量int是4字节。常规对象(⾮数组)的Shallow size有其成员变量的数量和类型决定,数组的shallow size有数组元素的类型(对象类型、基本类型)和数组⻓度决定。
-
- 对象的头部(对象的GC信息,hash值,类定义引⽤等)
- 对象的成员变量: 包括基本数据类型和引⽤。 如成员变量是⼀个引⽤, 引⽤了其他对象,被引 ⽤的对象内存另外计算。
//header 12B
public class Person {
public int age; //4B
public String name; //8B
public double height; //8B
......
}shallow heap的⼤⼩是32B = 12+4+8+8
- retained heap:如果⼀个对象被释放掉,那会因为该对象的释放⽽减少引⽤进⽽被释放的所有的 对象(包括被递归释放的)所占⽤的heap⼤⼩,即对象X被垃圾回收器回收后能被GC从内存中移 除的所有对象之和。相对于shallow heap,Retained heap可以更精确的反映⼀个对象实际占⽤的 ⼤⼩(若该对象释放,retained heap都可以被释放)。
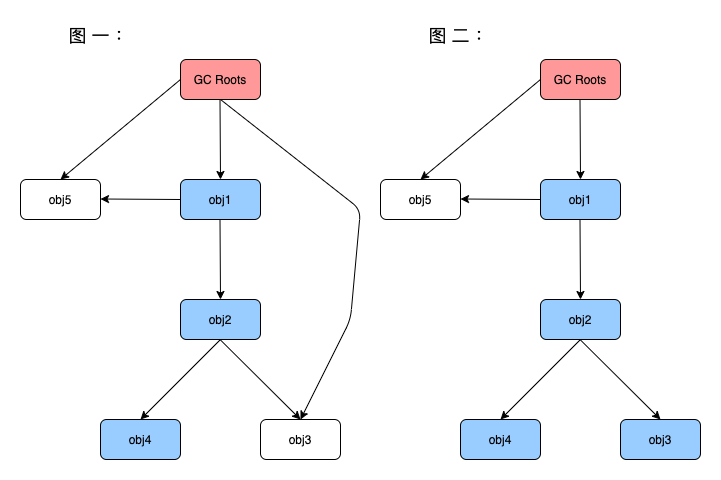
因此obj1的retained heap的⼤⼩在图⼀中指的是:Obj1+ Obj2+Obj4; 在图⼆中指的是:Obj1+ Obj2+ Obj3+ Obj4;
4 outgoing references与incoming references
- outgoing references :表示该对象的出节点(被该对象引⽤的对象)
- incoming references :表示该对象的⼊节点(引⽤到该对象的对象)
public class A {
private C c1 = C.getInstance();
}
public class B {
private C c2 = C.getInstance();
}
public class C {
private static C myC = new C();
public static C getInstance() {
return myC;
}
private D d1 = new D();
private E e1 = new E();
}
public class D {
}
public class E {
}
public class SimpleExample {
public static void main (String argsp[]) throws Exception {
A a = new A();
B b = new B();
}
}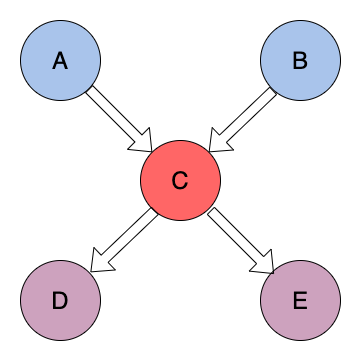
拥有对象 C 的引⽤的所有对象都称为 Incoming references。在此示例中,对象 C 的“Incoming
references”是对象 A、对象 B 和 C 的类对象 。
对象 C 引用的所有对象都称为 Outgoing References。在此示例中,对象 C 的“outgoing
references”是对象 D、对象 E 和 C 的类对
5 Dominator Tree
MAT提供了⼀个称为⽀配树(Dominator Tree)的对象图。⽀配树体现了对象实例间的⽀配关 系。
Dominator Tree 中,显示的是 dump 中占⽤ Retained Heap 最多的⼤对象。
Dominator Tree 体现了对象实例之间的⽀配关系 。 在对象引⽤图中,如果所有指向对象 B 的路径 都必须经过对象 A ,那么就认为对
象 A ⽀配着对象 B。 如果对象 A 是离对象 B 最近的⽀配对象,那么 对象 A 就是对象 B 的直接⽀配者 。 如果对象 A ⽀配着对象 B ,那么
对象 A 的直接⽀配者也⽀配着对象 B。
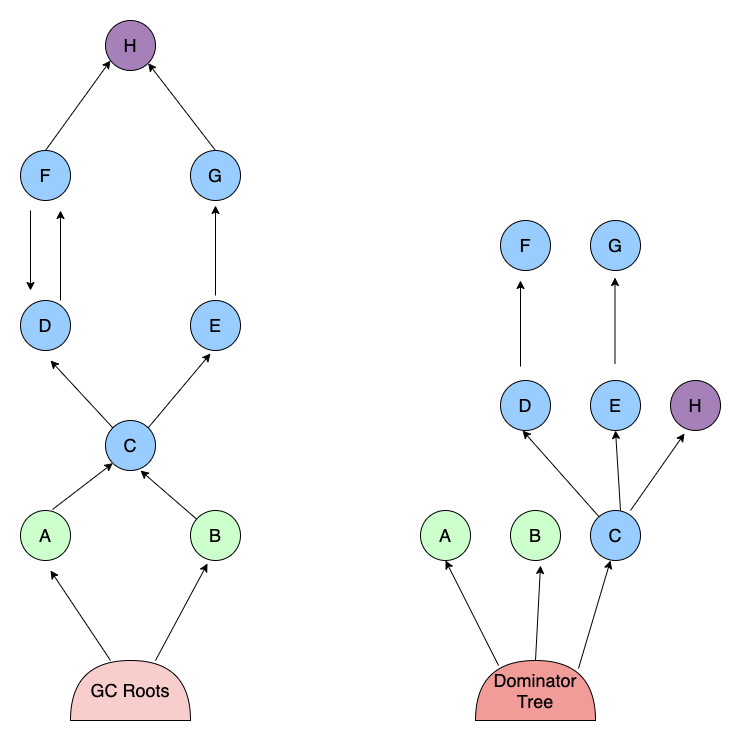
左图表示对象之间的引⽤关系,右图表示左图所对应的⽀配树关系 。 对象 A 和 B 由 GC Roots 直接⽀ 配。
因为在到对象 C 的路径中,即可以经过 A ,也可以经过 B ,所以对象 C 的直接⽀配者也是 GC Roots 。
因此⽀配树关系图中的第⼀层是直连 A、B、C。 对象 F 与对象 D 相互引⽤,因为到对象 F 的 所有路径必然经过
对象 D ,所以,对象 D 是对象 F 的直接⽀配者 。
⽽到对象 D 的所有路径中,必然经 过对象 C ,即使是从对象 F 到对象 D 的引⽤,从根节点出发,也是经过对
象 C 的,所以,对象 D 的直 接⽀配者为对象 C。 同理,对象 E ⽀配对象 G。 到达对象 H 的路径,即可以通过
对象 D ,也可以通 过对象 E ,因此对象 D 和 E 都不能直接⽀配对象 H ,⽽经过对象 C 既可以到达 D 也可以到
达 E ,因此 对象 C 为对象 H 的直接⽀配者 。
Dominator Tree 就是通过以上的逻辑判断,把对象之间的引⽤关系转换为对应的⽀配树关系的。
6 Garbage Collection Roots(GC root)
在执⾏GC时,是通过对象可达性来判断是否回收对象的,⼀个对象是否可达,也就是看这个对象 的引⽤连是否和
GC Root相连。
⼀个GC root指的是可以从堆外部访问的对象,有以下原因可以使⼀个对 象成为GC root对象。
- System Class: 通过bootstrap/system类加载器加载的类,如rt.jar中的java.util.* JNI Local: JNI⽅法中的变量或者⽅法形参
- JNI Global:JNI⽅法中的全局变量
- Thread Block:线程⾥⾯的变量,⼀个活着的线程⾥⾯的对象肯定不能被回收
- Thread:处于激活状态的线程
- Busy Monitor:调⽤了wait()、notify()⽅法,或者是同步对象,例如调⽤synchronized(Object) 或者进⼊⼀synchronized⽅法后的当前对象
- Java Local:本地变量,例如⽅法的输⼊参数或者是⽅法内部创建的仍在线程堆栈⾥⾯的对象
- Native Stack:Java ⽅法中的变量或者⽅法形参. Finalizable:等待运⾏finalizer的对象
- Unfinalized:有finalize⽅法,但未进⾏finalized,且不在finalizer队列的对象。
- Unreachable:通过其它root都不可达的对象,MAT会把它标记为root以便于分析回收。
- Java Stack Frame:java栈帧
2.4. MAT工具使用
1 OOM异常
package com.wclass.example;
import java.util.ArrayList;
import java.util.List;
/**
* -Xmx10m -Xms10m -XX:+HeapDumpOnOutOfMemoryError -
* XX:HeapDumpPath=/Users/hadoop/Desktop
*/
public class OOMTest {
public static void main(String[] args) {
List<Person> users=new ArrayList<Person>();
while(true) {
users.add(new Person(24,"www.kkb.com",1.76));
}
}
}
class Person{
public int age;
public String name;
public double height;
public Person(int age,String name,double height) {
this.age = age;
this.name = name;
this.height = height;
}
}2 生成hprof⽂件
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/Users/hadoopjava.lang.OutOfMemoryError: Java heap space
Dumping heap to /Users/hadoop/Desktop/java_pid7563.hprof ...
Heap dump file created [13895131 bytes in 0.105 secs]
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:3210)
at java.util.Arrays.copyOf(Arrays.java:3181)
at java.util.ArrayList.grow(ArrayList.java:261)
at java.util.ArrayList.ensureExplicitCapacity(ArrayList.java:235)
at java.util.ArrayList.ensureCapacityInternal(ArrayList.java:227)
at java.util.ArrayList.add(ArrayList.java:458)
at com.wclass.example.OOMTest.main(OOMTest.java:19)3 打开dump⽂件
注:在原始堆转储⽂件的⽬录下, MAT 已经将报告的内容压缩打包到⼀个zip⽂件,命名
为“java_pid*_Leak_Suspects.zip”,整个报告是⼀个HTML格式的⽂件,可以⽤浏览器直接打开查看, 可以⽅
便进⾏报告分发、分享。
分析Actions, 它包含了4个部分:
| 视图 | 含义 |
| Histogram | 列举内存中对象存在的个数和⼤⼩ |
| Dominator Tree | 该视图会以占⽤总内存的百分⽐来列举所有实例对象,注意这个地⽅是对象⽽不 是类了,这个视图是⽤来发现⼤内存对象的 |
| Top Consumers | 该视图会显示可能的内存泄漏点 |
| Duplicate Classes | 该视图显示重复的类等信息 |
点击他们能得到不同的视图,下⾯来⼀⼀介绍:
histogram视图
点击Overview⻚⾯Actions区域内的“Histogram视图”或点击⼯具栏的“histogram”按钮,可以显示 直⽅图
列表,它以Class类的维度展示每个Class类的实例存在的个数、 占⽤的Shallow heap 和 Retained内存⼤小,可
以分别排序显示
对于java的对象,其成员基本都是引⽤。真正的内存都在堆上,看起来是⼀堆原⽣的byte[], char[], int[],
因此如果只看对象本身的内存,数量都很⼩,⽽多数情况下,在Histogram视图看到实例对象数 量⽐较多的类都
是⼀些基础类型(通常都排在前⾯),如char[]、String、byte[],所以仅从这些是⽆法 判断出具体导致内存泄露
的类或者⽅法的。可以直接看到com.wclass.example.Person对象的数量很多, 有时不容易看出来的,可以使⽤
⼯具栏中的group result by 可以以super class,class loader等排序。
通常,如果Histogram视图展示的数量多的实例对象不是基础类型,⽽是⽤户⾃定义的类或者有嫌 疑的类,
就要重点关注查看。想进⼀步分析的,可以右键,选择使⽤List objects 或 Merge Shortest Paths to GC roots
等功能继续钻取数据。其中list objects分别有outgoing references及incoming references,可以找出由这个对
象出去的引⽤及通过哪些引⽤到这个对象的。Merge Shortest Paths to GC roots可以排除掉所有不是强引⽤
的,找到这个对象的到GC root的引⽤路径。最终⽬的就是找到占 ⽤内存最⼤对象和⽆法回收的对象,计算从垃
圾收集器根到相关对象的路径,从⽽根据这个对象路径去 检查代码,找出问题所在。
Dominator Tree视图
点击Overview⻚⾯Actions区域内的“Dominator Tree视图”或点击⼯具栏的“open Dominator
Tree”按钮,可以进⼊ Dominator Tree视图。该视图以实例对象的维度展示当前堆内存中Retained Heap占⽤
最⼤的对象,以及依赖这些对象存活的对象的树状结构。
视图展示了实例对象名、Shallow Heap⼤⼩、Retained Heap⼤⼩、以及当前对象的Retained Heap在整
个堆中的占⽐。该图是树状结构的,当上⼀级的对象被回收,那么,它引⽤的⼦对象都会被 回收,这也是
Dominator的意义,当⽗节点的回收会导致⼦节点也被回收。通过此视图,可以很⽅便的 找出占⽤Retained
Heap内存最多的⼏个对象,并表示出某些objects的是因为哪些objects的原因⽽存活。本示例中,可以看出是由
于Object[] s引⽤的数组存储过量的com.wclass.example.Person对象。
线程视图查看线程栈运⾏情况
点击⼯具栏的“⻮轮”按钮,可以打开Thread Overview视图,可以查看线程的栈帧信息,包括线程对 象/
线程栈信息、线程名、Shallow Heap、Retained Heap、类加载器、是否Daemon线程等信息。结 合内存Dump
分析,看到线程栈帧中的本地变量,在左下⽅的对象属性区域还能看到本地变量的属性 值。
2 查看GC Roots
package com.wclass.example;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.Scanner;
public class GCRootsTest {
public static void main(String[] args) {
List<Object> numList = new ArrayList<>();
Date birth = new Date();
for(int i=0;i<100;i++){
numList.add(String.valueOf(i));
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("数据添加完毕,请下⼀步操作:");
new Scanner(System.in).next();
numList = null;
birth = null;
System.out.println("numList、birth已置空,请下⼀步操作:");
new Scanner(System.in).next();
System.out.println("结束");
}
}2.5. 知识小结
对于java应⽤的内存分析,需要对java应⽤的内存进⾏dump操作,⽣成内存快照后,使⽤MAT进 ⾏分析,
找出⼤对象,找到内存泄漏或溢出的地⽅,从⽽分析代码,解决问题。
本节对MAT的使⽤场 景,基本概念,安装、使⽤进⾏了详细介绍,⼤家可以⾃⼰具体实践⼀下。
3. GCViewer:开源的GC日志分析⼯具
GCViewer是⼀款开源的GC日志分析⼯具。
项⽬的 GitHub 主⻚对各个指标提供了完整的描述信息 需要安装jdk才能使⽤。
https://github.com/chewiebug/GCViewer
下载https://github.com/chewiebug/GCViewer/releases,
借助GCViewer⽇志分析⼯具,可以⾮常直观地分析出待调优点。可从以下⼏⽅⾯来分析:
Memory,分析Totalheap、Tenuredheap、Youngheap内存占⽤率及其他指标,理论上内存占⽤ 率越⼩越好;
Pause,分析Gc pause、Fullgc pause、Total pause三个⼤项中各指标,理论上GC次数越少越好,GC时⻓越短越
好;
3.1. GC日志
- some support for OpenJDK 9 / 10 unified logging format -Xlog:gc:, the following configurations will work
-
- -Xlog:gc:file="path-to-file" (uses defaults)
- -Xlog:gc=info:file="path-to-file":tags,uptime,level (minimum configuration needed)
- -Xlog:gc*=trace:file="path-to-file":tags,time,uptime,level (maximum configuration supported, additional tags ok, but ignored; additional decorations will break parsing)
- Oracle JDK 1.8 -Xloggc: [-XX:+PrintGCDetails] [-XX:+PrintGCDateStamps]
- Sun / Oracle JDK 1.7 with option -Xloggc: [-XX:+PrintGCDetails] [-XX:+PrintGCDateStamps]
用法
java -jar gcviewer-1.36.jar gc.log
# 或
java -jar gcviewer-1.36.jar gc.log summary.csv chart.png//-XX:+UseConcMarkSweepGC -Xms200M -Xmx200M -Xmn32m -XX:SurvivorRatio=8 -XX:+PrintGCDetails -verbose:gc -Xloggc:/Users/hadoop/Desktop/gc.log
package com.wclass.example;
import java.util.ArrayList;
import java.util.List;
public class SimulateFullGc {
public static void main(String[] args) throws InterruptedException {
List<Object> l = new ArrayList<Object>();
for (int i =0; i< 100;i++) {
l.add(new byte[1024*1024 ]);
if (i % 10 ==0) {
Thread.sleep(5000);
System.gc();
}
}
}
}
顶部的⿊⾊线都代表Full GC,也可以理解为Major GC,是根据⽇志中的CMS GC统计的;
底部灰⾊ 线代表的是Minor GC。
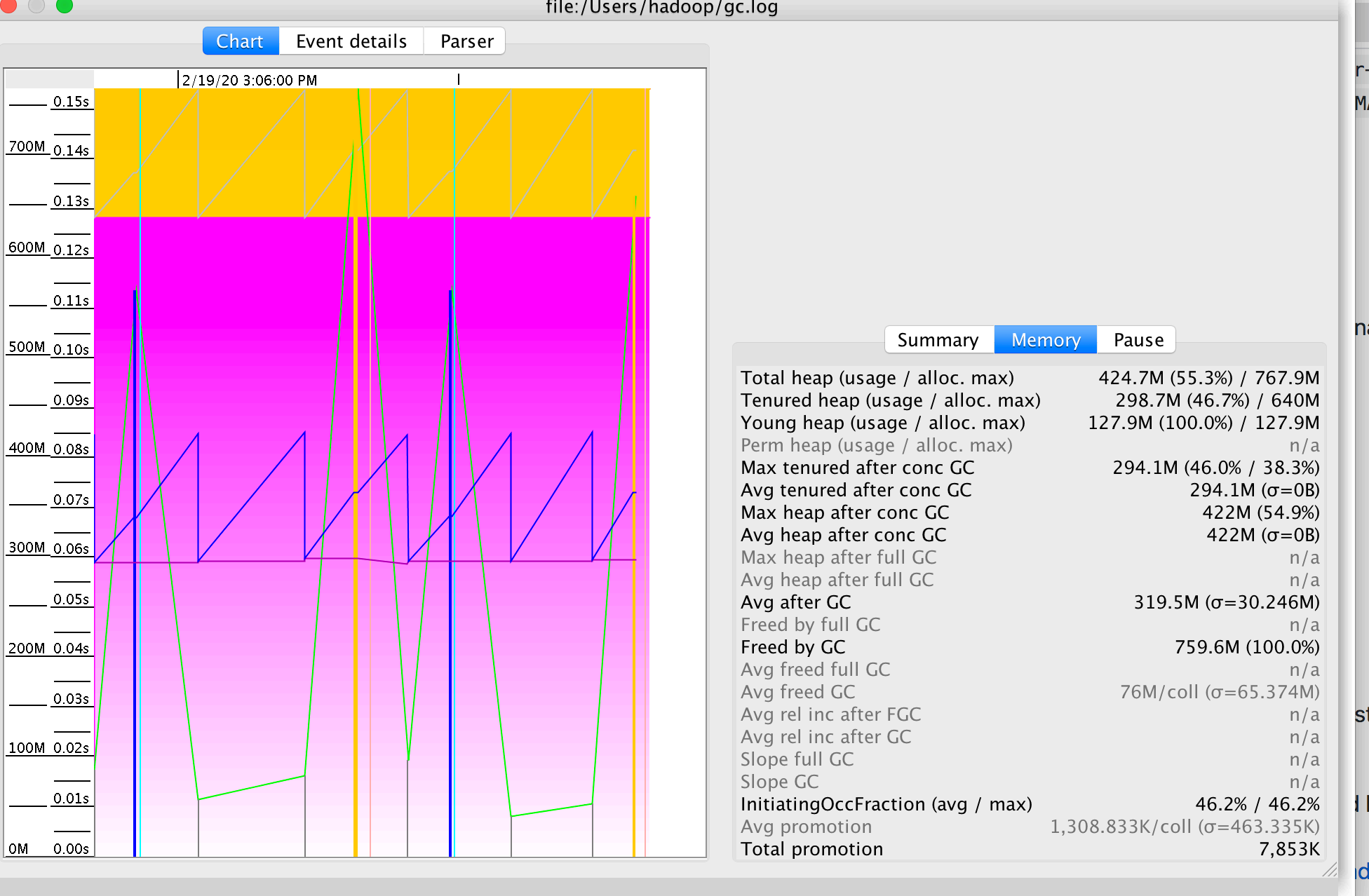
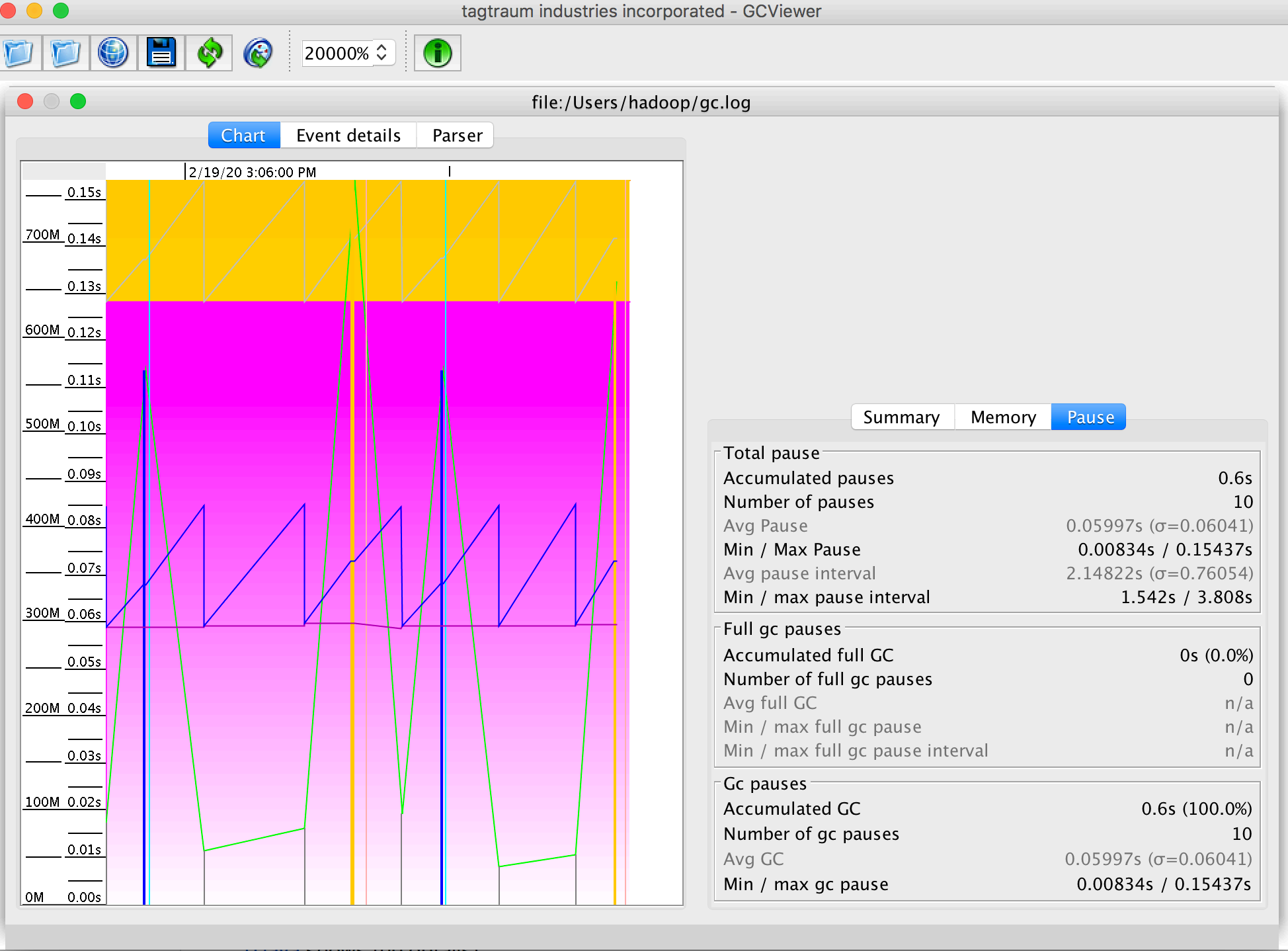
3.2. 结果分析
- Chart
- Summary
- Memory
- Pause
4. Arthas:Java诊断⼯具
Arthas是Alibaba开源的Java诊断⼯具,深受开发者喜爱。⽤户⽂档:https://alibaba.github.io/art has/
当你遇到以下类似问题⽽束⼿⽆策时,Arthas可以帮助你解决:
- 这个类从哪个 jar 包加载的?为什么会报各种类相关的 Exception?
- 我改的代码为什么没有执⾏到?难道是我没 commit?分⽀搞错了?
- 遇到问题⽆法在线上 debug,难道只能通过加⽇志再重新发布吗?
- 线上遇到某个⽤户的数据处理有问题,但线上同样⽆法 debug,线下⽆法重现!
- 是否有⼀个全局视⻆来查看系统的运⾏状况?
- 有什么办法可以监控到JVM的实时运⾏状态?
- 怎么快速定位应⽤的热点,⽣成⽕焰图?
Arthas⽀持JDK 6+,⽀持Linux/Mac/Winodws,采⽤命令⾏交互模式,
同时提供丰富的 Tab ⾃ 动补全功能,进⼀步⽅便进⾏问题的定位和诊断。
4.1. 安装
下载 arthas-boot.jar ,然后⽤ java -jar 的⽅式启动:
curl -O https://alibaba.github.io/arthas/arthas-boot.jar
java -jar arthas-boot.jar打印帮助信息:
java -jar arthas-boot.jar -h启动arthas
java -jar arthas-boot.jar4.2. arthas-demo示例
选择应⽤java进程:
$ $ java -jar arthas-boot.jar
* [1]: 35542
[2]: 71560 arthas-demo.jarDemo进程是第2个,则输⼊2,再输⼊ 回⻋/enter 。Arthas会attach到⽬标进程上,并输出⽇志:
[INFO] Try to attach process 71560
[INFO] Attach process 71560 success.
[INFO] arthas-client connect 127.0.0.1 3658
,---. ,------. ,--------.,--. ,--. ,---. ,---.
/ O \ | .--. ''--. .--'| '--' | / O \ ' .-'
| .-. || '--'.' | | | .--. || .-. |`. `-.
| | | || |\ \ | | | | | || | | |.-' |
`--' `--'`--' '--' `--' `--' `--'`--' `--'`-----'
wiki: https://alibaba.github.io/arthas
version: 3.0.5.20181127201536
pid: 71560
time: 2018-11-28 19:16:24
$查看dashboard
输⼊dashboard,按 回⻋/enter ,会展示当前进程的信息,按 ctrl+c 可以中断执⾏。
通过thread命令来获取到arthas-demo进程的Main Class
thread 1 会打印线程ID 1的栈,通常是main函数的线程。
$ thread 1 | grep 'main('
at demo.MathGame.main(MathGame.java:17)通过jad来反编译Main Class
$ jad demo.MathGame
ClassLoader:
+-sun.misc.Launcher$AppClassLoader@3d4eac69
+-sun.misc.Launcher$ExtClassLoader@66350f69
Location:
/tmp/arthas-demo.jar
/*
* Decompiled with CFR 0_132.
*/
package demo;
import java.io.PrintStream;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Random;
import java.util.concurrent.TimeUnit;
public class MathGame {
private static Random random = new Random();
private int illegalArgumentCount = 0;
public static void main(String[] args) throws InterruptedException {
MathGame game = new MathGame();
do {
game.run();
TimeUnit.SECONDS.sleep(1L);
} while (true);
}
public void run() throws InterruptedException {
try {
int number = random.nextInt();
List<Integer> primeFactors = this.primeFactors(number);
MathGame.print(number, primeFactors);
} catch (Exception e) {
System.out.println(String.format("illegalArgumentCount:%3d, ", this.illegalArgumentCount) +
e.getMessage());
}
}
public static void print(int number, List<Integer> primeFactors) {
StringBuffer sb = new StringBuffer("" + number + "=");
Iterator<Integer> iterator = primeFactors.iterator();
while (iterator.hasNext()) {
int factor = iterator.next();
sb.append(factor).append('*');
}
if (sb.charAt(sb.length() - 1) == '*') {
sb.deleteCharAt(sb.length() - 1);
}
System.out.println(sb);
}
public List<Integer> primeFactors(int number) {
if (number < 2) {
++this.illegalArgumentCount;
throw new IllegalArgumentException("number is: " + number + ", need >= 2");
}
ArrayList<Integer> result = new ArrayList<Integer>();
int i = 2;
while (i <= number) {
if (number % i == 0) {
result.add(i);
number /= i;
i = 2;
continue;
}
++i;
}
return result;
}
}
Affect(row-cnt:1) cost in 970 ms.watch
通过watch命令来查看 demo.MathGame#primeFactors 函数的返回值:
$ watch demo.MathGame primeFactors returnObj
Press Ctrl+C to abort.
Affect(class-cnt:1 , method-cnt:1) cost in 107 ms.
ts=2018-11-28 19:22:30; [cost=1.715367ms] result=null
ts=2018-11-28 19:22:31; [cost=0.185203ms] result=null
ts=2018-11-28 19:22:32; [cost=19.012416ms] result=@ArrayList[
@Integer[5],
@Integer[47],
@Integer[2675531],
]
ts=2018-11-28 19:22:33; [cost=0.311395ms] result=@ArrayList[
@Integer[2],
@Integer[5],
@Integer[317],
@Integer[503],
@Integer[887],
]
ts=2018-11-28 19:22:34; [cost=10.136007ms] result=@ArrayList[
@Integer[2],
@Integer[2],
@Integer[3],
@Integer[3],
@Integer[31],
@Integer[717593],
]
ts=2018-11-28 19:22:35; [cost=29.969732ms] result=@ArrayList[
@Integer[5],
@Integer[29],
@Integer[7651739],
]4.3. CPU示例
package com.wclass.example;
import java.util.HashSet;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* <p>
* ArthasDemo
*/
public class ArthasDemo {
private static HashSet hashSet = new HashSet();
/** 线程池,⼤⼩1*/
private static ExecutorService executorService = Executors.newFixedThreadPool(1);
public static void main(String[] args) {
// 模拟 CPU 过⾼,这⾥注释掉了,测试时可以打开
cpu();
// 模拟线程阻塞
thread();
// 模拟线程死锁
deadThread();
// 不断的向 hashSet 集合增加数据
addHashSetThread();
}
/**
* 不断的向 hashSet 集合添加数据
*/
public static void addHashSetThread() {
// 初始化常量
new Thread(() -> {
int count = 0;
while (true) {
try {
hashSet.add("count" + count);
Thread.sleep(10000);
count++;
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
public static void cpu() {
cpuHigh();
cpuNormal();
}
/**
* 极度消耗CPU的线程
*/
private static void cpuHigh() {
Thread thread = new Thread(() -> {
while (true) {
System.out.println("cpu start 100");
}
});
// 添加到线程
executorService.submit(thread);
}
/**
* 普通消耗CPU的线程
*/
private static void cpuNormal() {
for (int i = 0; i < 10; i++) {
new Thread(() -> {
while (true) {
System.out.println("cpu start");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
}
/**
* 模拟线程阻塞,向已经满了的线程池提交线程
*/
private static void thread() {
Thread thread = new Thread(() -> {
while (true) {
System.out.println("thread start");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
// 添加到线程
executorService.submit(thread);
}
/**
* 死锁
*/
private static void deadThread() {
/** 创建资源 */
Object resourceA = new Object();
Object resourceB = new Object();
// 创建线程
Thread threadA = new Thread(() -> {
synchronized (resourceA) {
System.out.println(Thread.currentThread() + " get ResourceA");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "waiting get resourceB");
synchronized (resourceB) {
System.out.println(Thread.currentThread() + " get resourceB");
}
}
});
Thread threadB = new Thread(() -> {
synchronized (resourceB) {
System.out.println(Thread.currentThread() + " get ResourceB");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "waiting get resourceA");
synchronized (resourceA) {
System.out.println(Thread.currentThread() + " get resourceA");
}
}
});
threadA.start();
threadB.start();
}
}使⽤ dashboard 命令可以概览程序的 线程、内存、GC、运⾏环境信息。
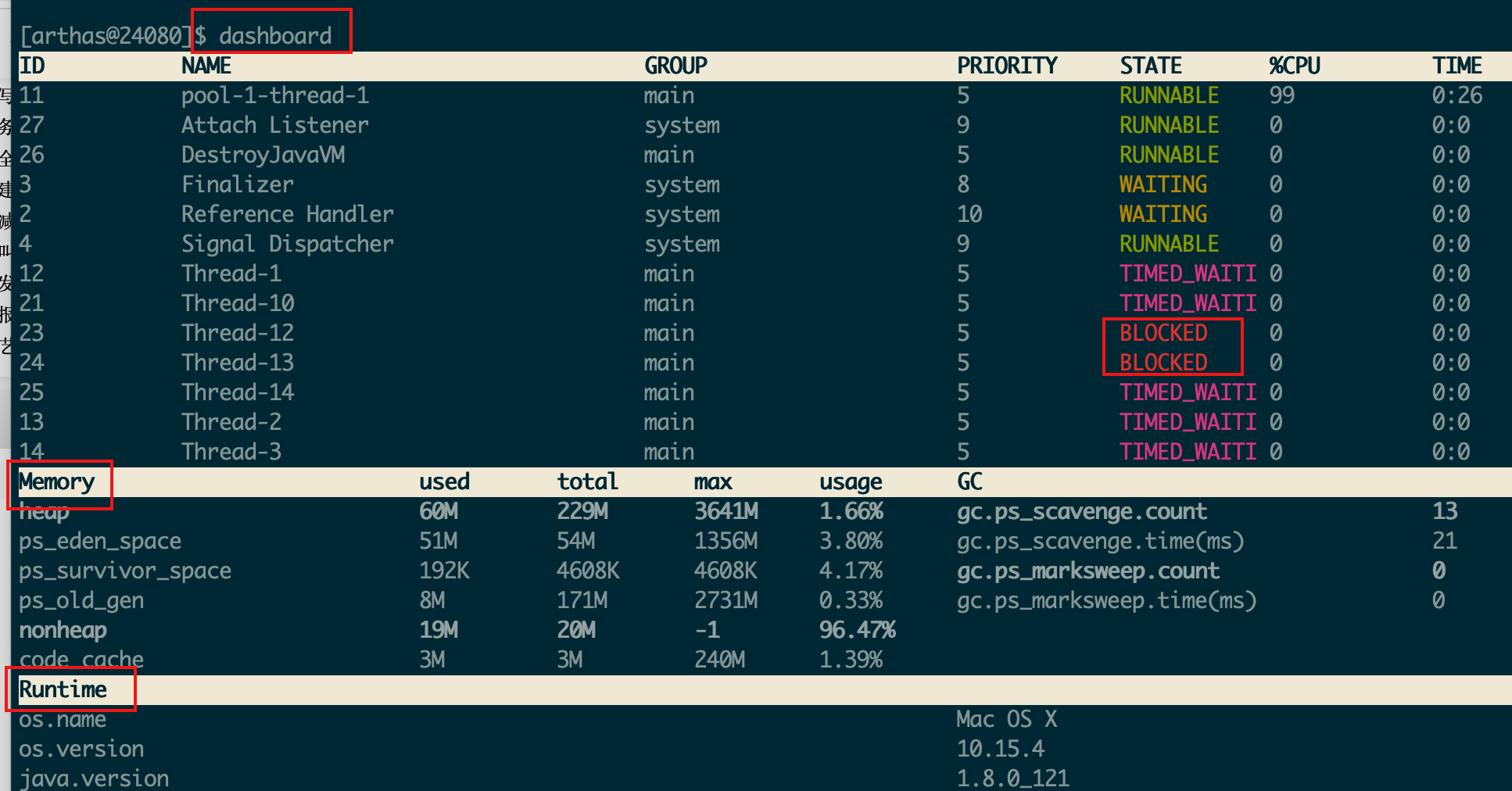
使⽤ thread 查看所有线程信息,同时会列出每个线程的 CPU 使⽤率,可以看到图⾥ ID 为11 的线程 CPU 使⽤99%。

使⽤命令 thread 11 查看 CPU 消耗较⾼的 11 号线程信息,可以看到 CPU 使⽤较⾼的⽅法和⾏数
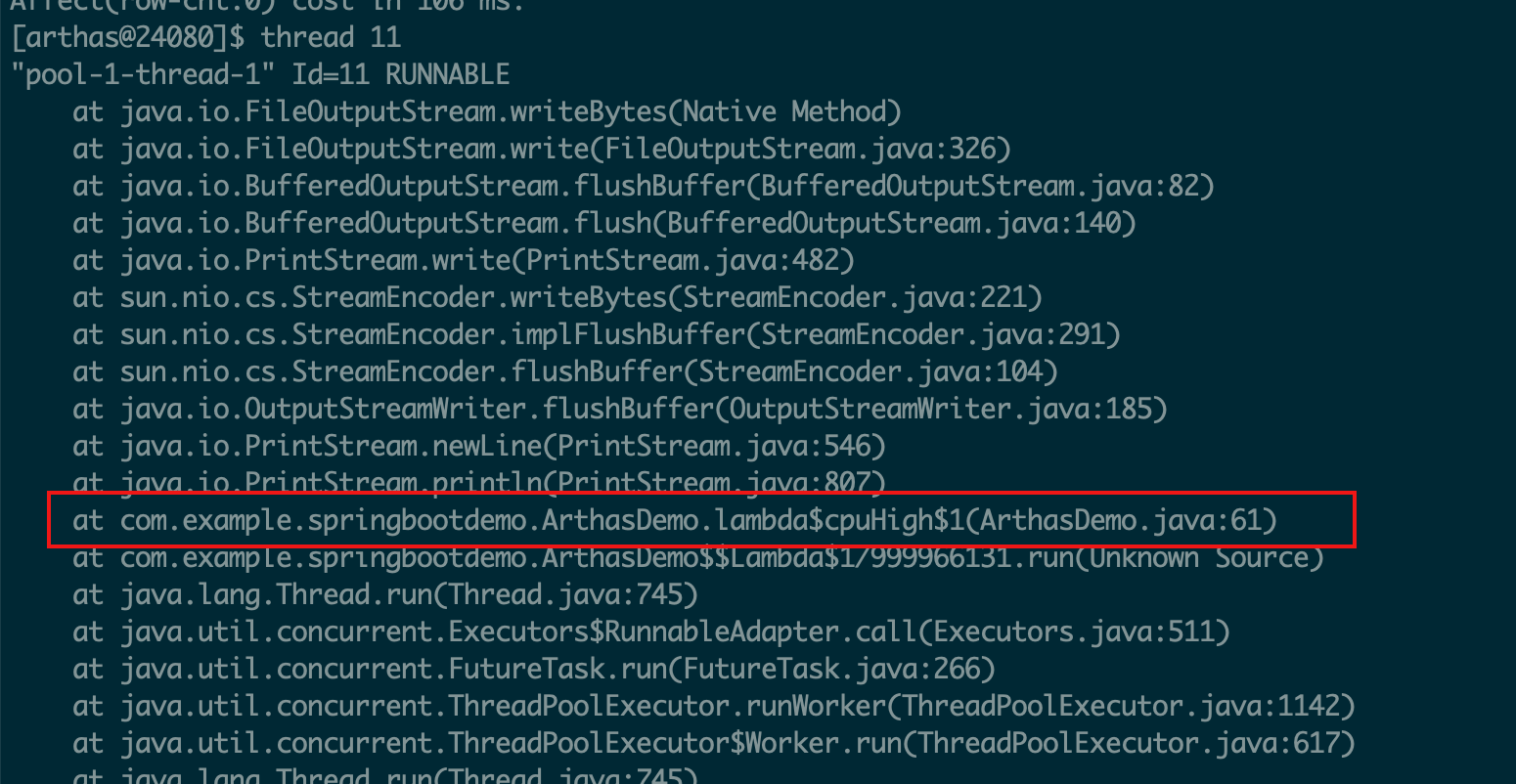
上⾯是先通过观察总体的线程信息,然后查看具体的线程运⾏情况。如果只是为了寻找 CPU 使⽤较⾼ 的线程,可
以直接使⽤命令 thread -n [显示的线程个数] ,就可以排列出 CPU 使⽤率 Top N 的线程。
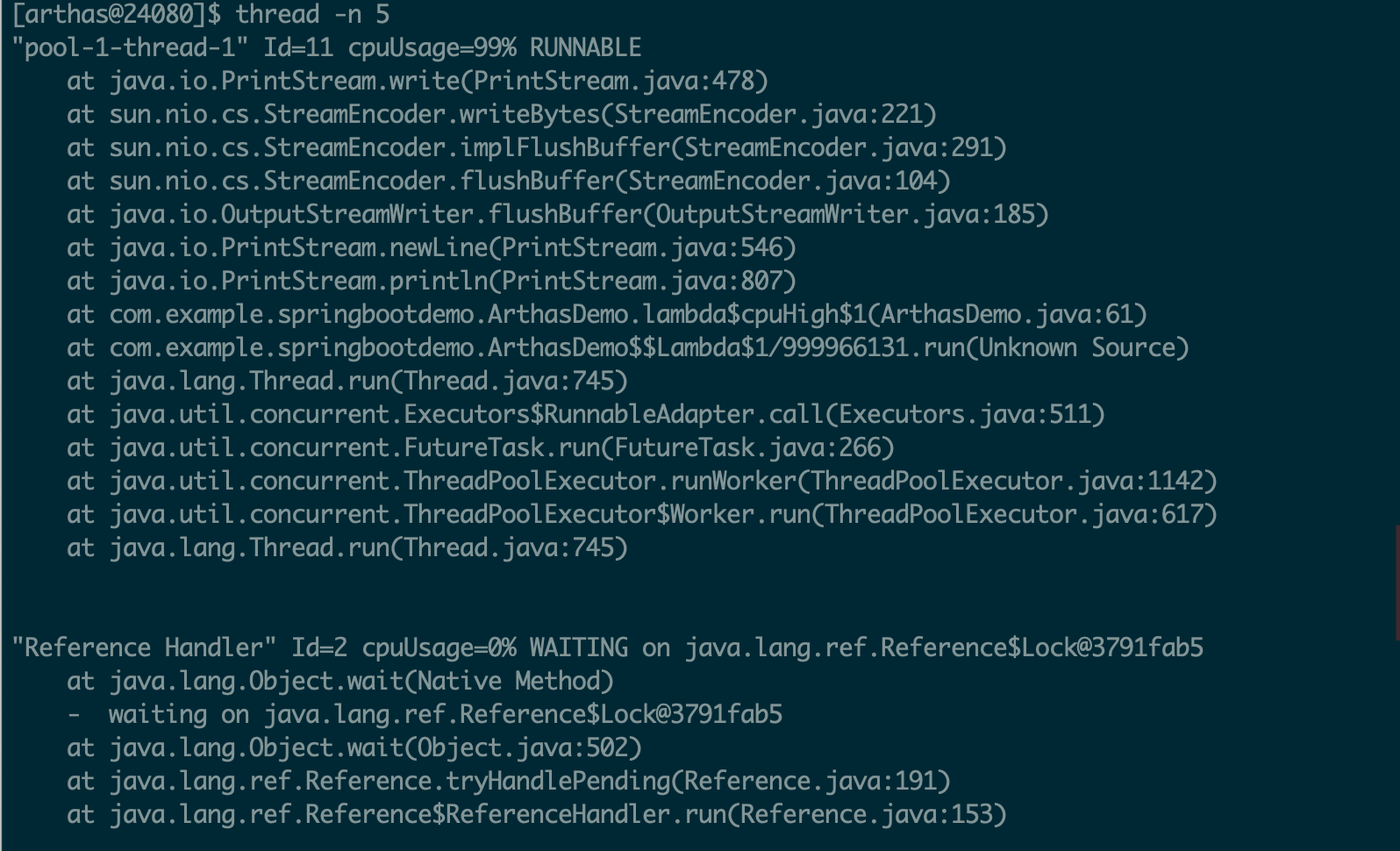
上⾯的模拟代码⾥,定义了线程池⼤⼩为1 的线程池,然后在 cpuHigh ⽅法⾥提交了⼀个线程,
在 thread ⽅法再次提交了⼀个线程,后⾯的这个线程因为线程池已满,会阻塞下来。
使⽤ thread | grep pool 命令查看线程池⾥线程信息。

deadThread ⽅法实现了⼀个死锁,使⽤ thread -b 命令查看直接定位到死锁信息。
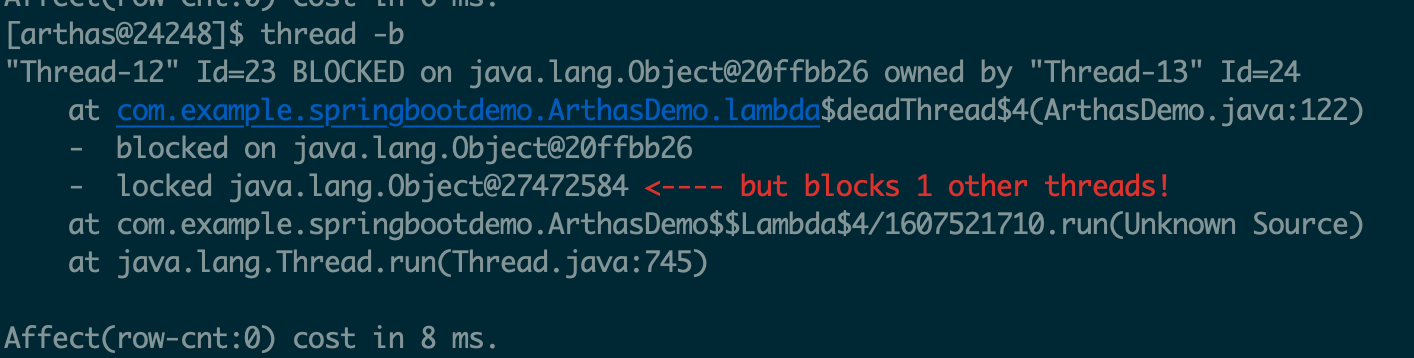
假设这是⼀个线上环境,当怀疑当前运⾏的代码不是⾃⼰想要的代码时,
可以直接反编译出代码,也可 以选择性的查看类的字段或⽅法信息。
如果怀疑不是⾃⼰的代码,可以使⽤ jad 命令直接反编译 class。
查看静态变量 hashSet 信息,查看静态变量 hashSet ⼤⼩,甚⾄可以进⾏操作。
[arthas@24811]$ ognl '@com.example.springbootdemo.ArthasDemo@hashSet'
@HashSet[
@String[count1],
@String[count2],
@String[count0],
@String[count5],
@String[count6],
@String[count3],
@String[count4],
@String[count9],
@String[count7],
@String[count8],
]
[arthas@24811]$ ognl '@com.example.springbootdemo.ArthasDemo@hashSet.size()'
@Integer[18]
[arthas@24811]$ ognl
'@com.example.springbootdemo.ArthasDemo@hashSet.add("kkb")'
@Boolean[true]
[arthas@24811]$ ognl '@com.example.springbootdemo.ArthasDemo@hashSet' | grep
kkb
@String[kkb],4.4. 耗时示例
使⽤ trace 命令可以跟踪统计⽅法耗时
package com.example.springbootdemo.controller;
import com.example.springbootdemo.service.UserServiceImpl;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.HashMap;
@RestController
@Slf4j
public class UserController {
@Autowired
private UserServiceImpl userService;
@GetMapping(value = "/user")
public HashMap<String, Object> getUser(Integer uid) throws Exception {
// 模拟⽤户查询
userService.get(uid);
HashMap<String, Object> hashMap = new HashMap<>();
hashMap.put("uid", uid);
hashMap.put("name", "name" + uid);
return hashMap;
}
}package com.example.springbootdemo.service;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
@Service
@Slf4j
public class UserServiceImpl {
public void get(Integer uid) throws Exception {
check(uid);
service(uid);
redis(uid);
mysql(uid);
}
public void service(Integer uid) throws Exception {
int count = 0;
for (int i = 0; i < 10; i++) {
count += i;
}
log.info("service end {}", count);
}
public void redis(Integer uid) throws Exception {
int count = 0;
for (int i = 0; i < 10000; i++) {
count += i;
}
log.info("redis end {}", count);
}
public void mysql(Integer uid) throws Exception {
long count = 0;
for (int i = 0; i < 10000000; i++) {
count += i;
}
log.info("mysql end {}", count);
}
public boolean check(Integer uid) throws Exception {
if (uid == null || uid < 0) {
log.error("uid不正确,uid:{}", uid);
throw new Exception("uid不正确");
}
return true;
}
}运⾏ Springboot 之后,使⽤ trace 命令开始检测耗时情况。

继续跟踪耗时⾼的⽅法,然后再次访问。
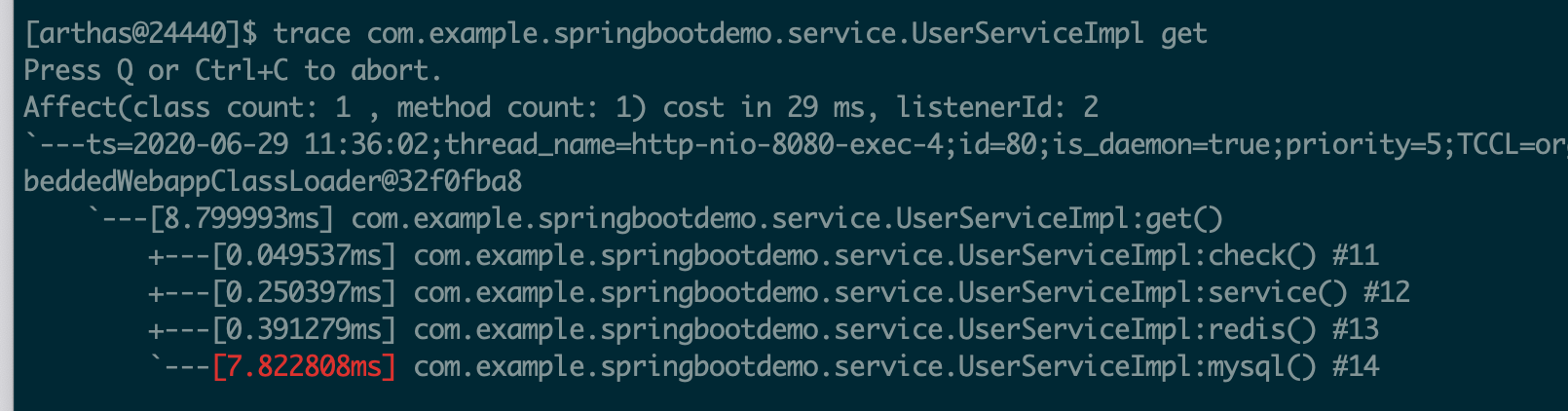
使⽤ monitor 命令监控统计⽅法的执⾏情况。
monitor -c 5 com.example.springbootdemo.service.UserServiceImpl get
4.5. 其他命令
退出
如果只是退出当前的连接,可以⽤ quit 或者 exit 命令。Attach到⽬标进程上的arthas还会继续运⾏, 端⼝会保
持开放,下次连接时可以直接连接上。 如果想完全退出arthas,可以执⾏ stop 命令。
基础命令
help——查看命令帮助信息
cat——打印⽂件内容,和linux⾥的cat命令类似
} monitor -c 5 com.example.springbootdemo.service.UserServiceImpl get
grep——匹配查找,和linux⾥的grep命令类似
tee——复制标准输⼊到标准输出和指定的⽂件,和linux⾥的tee命令类似
pwd——返回当前的⼯作⽬录,和linux命令类似
cls——清空当前屏幕区域
session——查看当前会话的信息
reset——重置增强类,将被 Arthas 增强过的类全部还原,Arthas 服务端关闭时会重置所有增强 过的类
version——输出当前⽬标 Java 进程所加载的 Arthas 版本号
history——打印命令历史
quit——退出当前 Arthas 客户端,其他 Arthas 客户端不受影响
stop——关闭 Arthas 服务端,所有 Arthas 客户端全部退出
keymap——Arthas快捷键列表及⾃定义快捷键
jvm相关
dashboard——当前系统的实时数据⾯板
thread——查看当前 JVM 的线程堆栈信息
jvm——查看当前 JVM 的信息
sysprop——查看和修改JVM的系统属性
sysenv——查看JVM的环境变量
vmoption——查看和修改JVM⾥诊断相关的option
logger——查看和修改logger
getstatic——查看类的静态属性
ognl——执⾏ognl表达式
mbean——查看 Mbean 的信息
heapdump——dump java heap, 类似jmap命令的heap dump功能
class/classloader相关
sc——查看JVM已加载的类信息
sm——查看已加载类的⽅法信息
jad——反编译指定已加载类的源码
mc——内存编绎器,内存编绎 .java ⽂件为 .class ⽂件
redefine——加载外部的 .class ⽂件,redefine到JVM⾥
dump——dump 已加载类的 byte code 到特定⽬录
classloader——查看classloader的继承树,urls,类加载信息,使⽤classloader去getResource
monitor/watch/trace相关
请注意,这些命令,都通过字节码增强技术来实现的,会在指定类的⽅法中插⼊⼀些切⾯来实现 数据统计和观测,因此在线上、预发使⽤时,请尽量明确需要观测的类、⽅法以及条件,诊断结 束要执⾏ stop 或将增强过的类执⾏ reset 命令。
monitor——⽅法执⾏监控
watch——⽅法执⾏数据观测
trace——⽅法内部调⽤路径,并输出⽅法路径上的每个节点上耗时
stack——输出当前⽅法被调⽤的调⽤路径
tt——⽅法执⾏数据的时空隧道,记录下指定⽅法每次调⽤的⼊参和返回信息,并能对这些不同的 时间下调⽤进⾏观测
profiler/⽕焰图
profiler–使⽤async-profiler对应⽤采样,⽣成⽕焰图
options
options——查看或设置Arthas全局开关
管道
Arthas⽀持使⽤管道对上述命令的结果进⾏进⼀步的处理,如 sm java.lang.String * | grep 'index'
grep——搜索满⾜条件的 结果
plaintext——将 命令的结果去除ANSI颜⾊
wc——按⾏统计输出结果
后台异步任务
当线上出现偶发的问题,⽐如需要watch某个条件,⽽这个条件⼀天可能才会出现⼀次时,异步后台任 务就派上⽤场了,详情请参考这⾥
使⽤ > 将结果重写向到⽇志⽂件,使⽤ & 指定命令是后台运⾏,session断开不影响任务执⾏(⽣ 命周期默认为1天)
jobs——列出所有job kill——强制终⽌任务
fg——将暂停的任务拉到前台执⾏
bg——将暂停的任务放到后台执⾏
⽤户数据回报
在 3.1.4 版本后,增加了⽤户数据回报功能,⽅便统⼀做安全或者历史数据统计。 在启动时,指定 stat-url ,就会回报执⾏的每⼀⾏命令,⽐如: ./as.sh --stat-url 'http://192.168.10.11:8080/api/stat'
在tunnel server⾥有⼀个示例的回报代码,⽤户可以⾃⼰在服务器上实现
其他特性
异步命令⽀持 执⾏结果存⽇志 批处理的⽀持
ognl表达式的⽤法说明
5. GChisto:GC 日志离线分析⼯具
5.1. 简介
⼀款分析 GC 日志的离线分析⼯具, GChisto 以表格和图形化的⽅式展示 GC 次数、 持续时间 等, 提⾼了分析
GC ⽇志的效率。
不过这个⼯具似乎没怎么维护了, 存在不少 bug, 使⽤过程发现识别不了 JDK 1.7 GC ⽇志的 Young GC, 还
有⼀些 NullPointer 错误。
整体来说, 只能观察某些参数
源码地址:https://github.com/jewes/gchisto
How to build gchisto
mvn clean installHow to run it
java -jar gchisto-\<version>.jar5.2. 应用
(1)导⼊成功, 切到 GC Pause Stats 选项卡, 可以⼤致看下 GC 的次数、 GC 的时间、 GC 的开 销、 最⼤
GC 时间和最⼩ GC 时间等
垃圾收集的开销(Overhead)表示垃圾收集的调优程度。 ⼀般情况, 并发垃圾收集的开销应该 ⼩于
10%, 也有可能达到 1% ~ 3%。
(2)切到 GC Pause Distribution 选项卡, 可以查看 GC 停顿的详细分布, x 轴表示垃圾收集停顿 时间, y 轴
表示是停顿次数。
(3)切换到 GC Timeline 选项卡, 可以显示整个时间线上的垃圾收集, 以便于按时间去查找应⽤⽇ 志
(tomcat ⽇志等), 去了解峰值时系统发⽣了什么。
IBM HeapAnalyzer:Java堆泄漏图形工具
IBM HeapAnalyzer是⽤于发现可能的Java堆泄漏的图形⼯具。
下载
Download: https://public.dhe.ibm.com/software/websphere/appserv/support/tools/HeapAnalyzer/ha457.jar
//-Xmx10m -Xms10m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/Users/hadoop/Desktop
package com.wclass.example;
import java.util.ArrayList;
import java.util.List;
public class TestIBM {
public static void main(String[] args) {
List<User> list=new ArrayList<>();
int i=1;
while (true){
User u = new User();
u.setAge(i);
u.setName("name is "+i);
i++;
list.add(u);
}
}
}
class User {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}启动
java -Xmx2g -jar ha457.jar
dump⽂件打开后
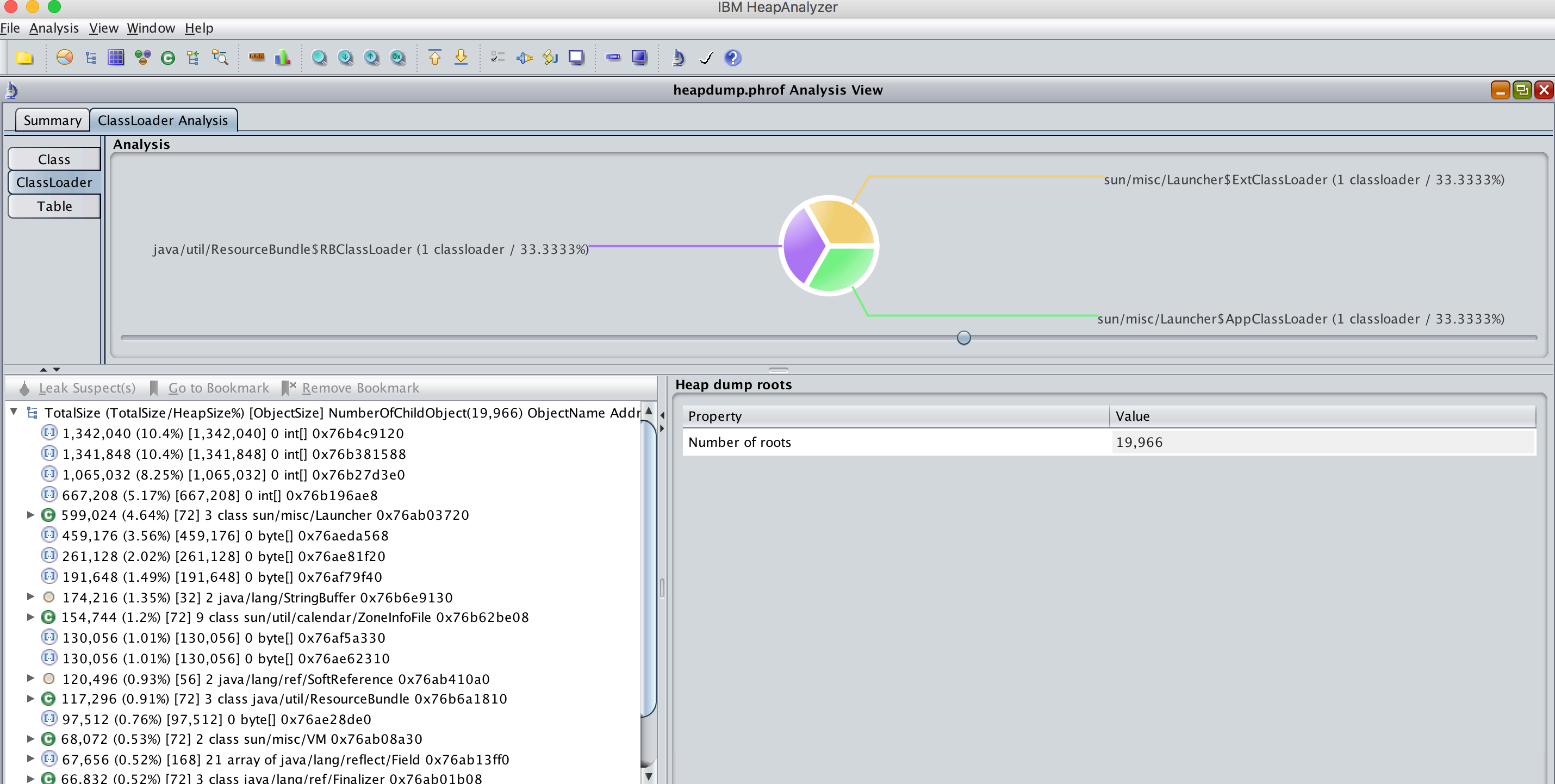
根据官⽅⽂档的说法,如果服务器存在内存泄漏的可能,那么会出现上图红框所示的“Reference Tree”界
⾯。 也就是说,如果你打开dump⽂件后,没有找到这个界⾯,说明你的jvm是正常的。
Reference Tree中列出的是当前堆中占⽐最⼤的对象信息,另外也可以通过菜单栏中的“Tree view”选项
查看所有对象的的详细信息
如果你的⽂件打开后出现“Reference Tree”界⾯,在其中选择占⽐最⼤⼀项,⼀层层点开,最后就 会看到你熟悉的类了
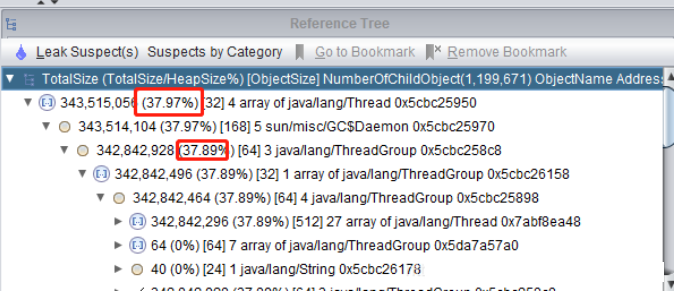
-------------------------------------------
讲解三:实践篇(二)
一、前置启动程序
事先启动一个web应用程序,用jps查看其进程id,接着用各种jdk自带命令优化应用
二、Jmap
此命令可以用来查看内存信息,实例个数以及占用内存大小
jmap -histo 14660 #查看历史生成的实例
jmap -histo:live 14660 #查看当前存活的实例,执行过程中可能会触发一次full gc打开log.txt,文件内容如下:
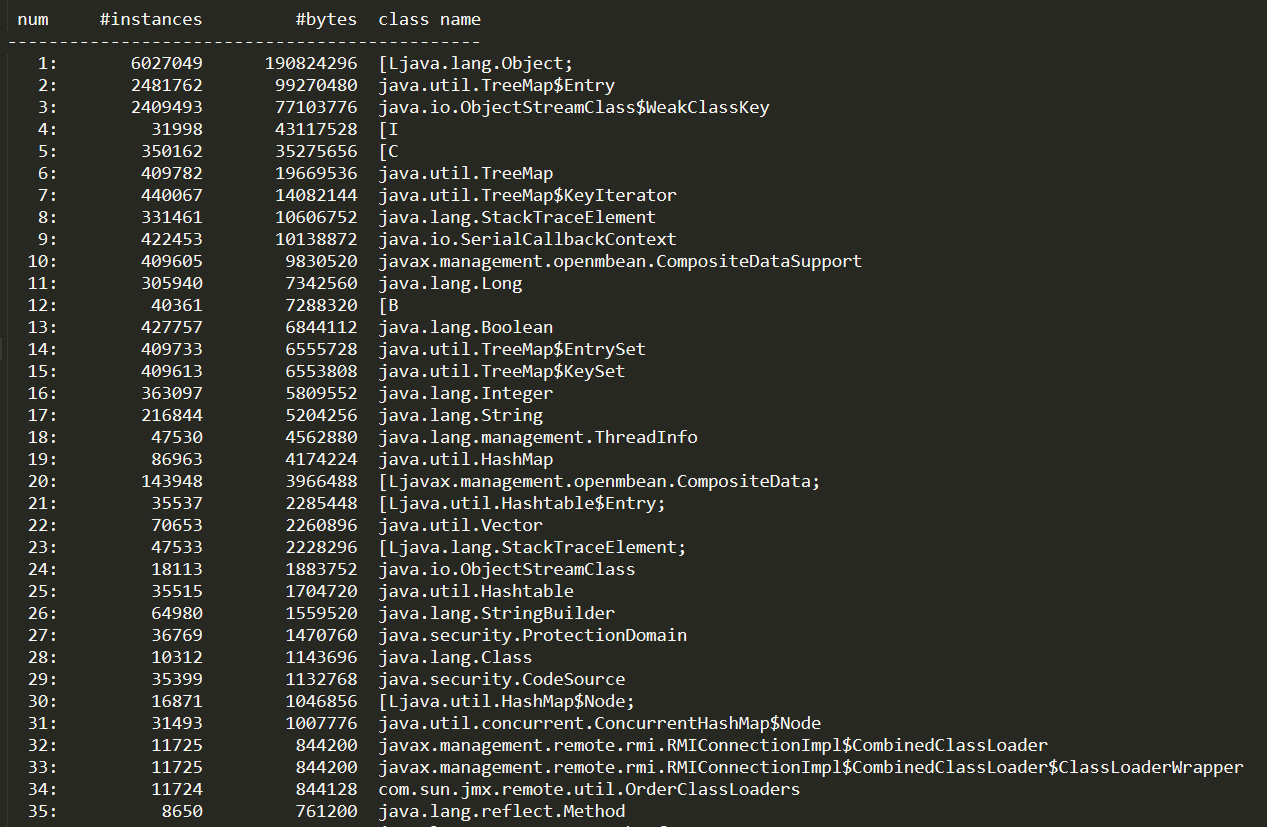
- num:序号
- instances:实例数量
- bytes:占用空间大小
- class name:类名称,[C is a char[],[S is a short[],[I is a int[],[B is a byte[],[[I is a int[][]
堆信息
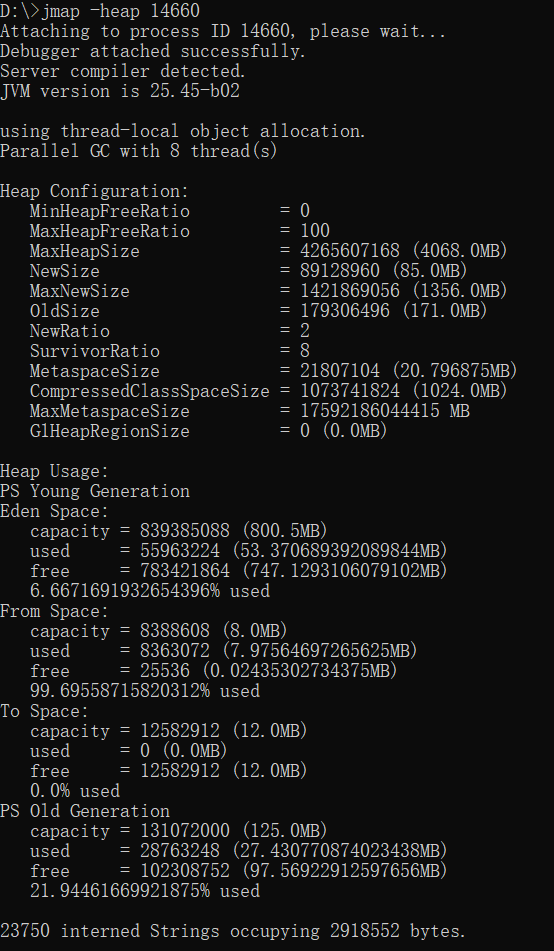
堆内存dump
jmap -dump:format=b,file=eureka.hprof 14660
也可以设置内存溢出自动导出dump文件(内存很大的时候,可能会导不出来)
- -XX:+HeapDumpOnOutOfMemoryError
- -XX:HeapDumpPath=./ (路径)
示例代码:
public class OOMTest {
public static List<Object> list = new ArrayList<>();
// JVM设置
// -Xms10M -Xmx10M -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=D:\jvm.dump
public static void main(String[] args) {
List<Object> list = new ArrayList<>();
int i = 0;
int j = 0;
while (true) {
list.add(new User(i++, UUID.randomUUID().toString()));
new User(j--, UUID.randomUUID().toString());
}
}
}可以用jvisualvm命令工具导入该dump文件分析
三、Jstack
用jstack加进程id查找死锁,见如下示例
public class DeadLockTest {
private static Object lock1 = new Object();
private static Object lock2 = new Object();
public static void main(String[] args) {
new Thread(() -> {
synchronized (lock1) {
try {
System.out.println("thread1 begin");
Thread.sleep(5000);
} catch (InterruptedException e) {
}
synchronized (lock2) {
System.out.println("thread1 end");
}
}
}).start();
new Thread(() -> {
synchronized (lock2) {
try {
System.out.println("thread2 begin");
Thread.sleep(5000);
} catch (InterruptedException e) {
}
synchronized (lock1) {
System.out.println("thread2 end");
}
}
}).start();
System.out.println("main thread end");
}
}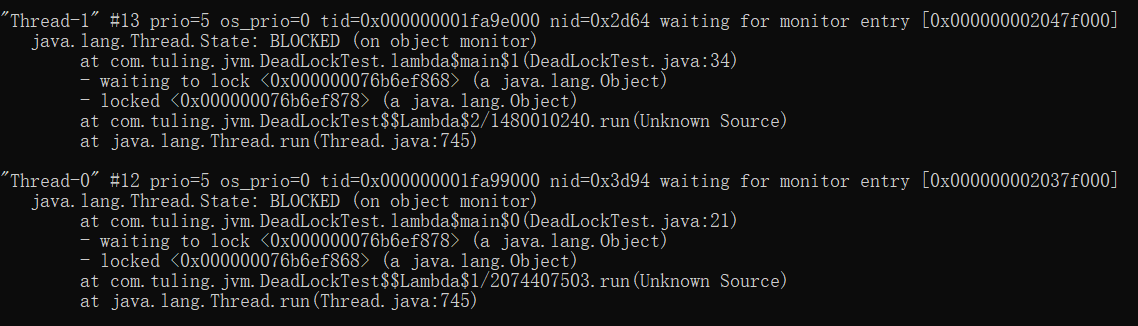
"Thread-1" 线程名
prio=5 优先级=5
tid=0x000000001fa9e000 线程id
nid=0x2d64 线程对应的本地线程标识nid
java.lang.Thread.State: BLOCKED 线程状态
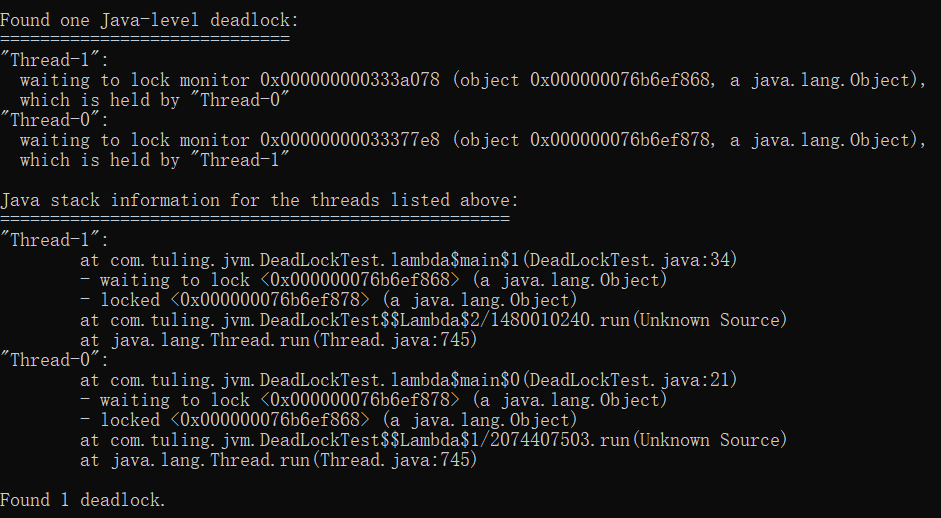
还可以用jvisualvm自动检测死锁
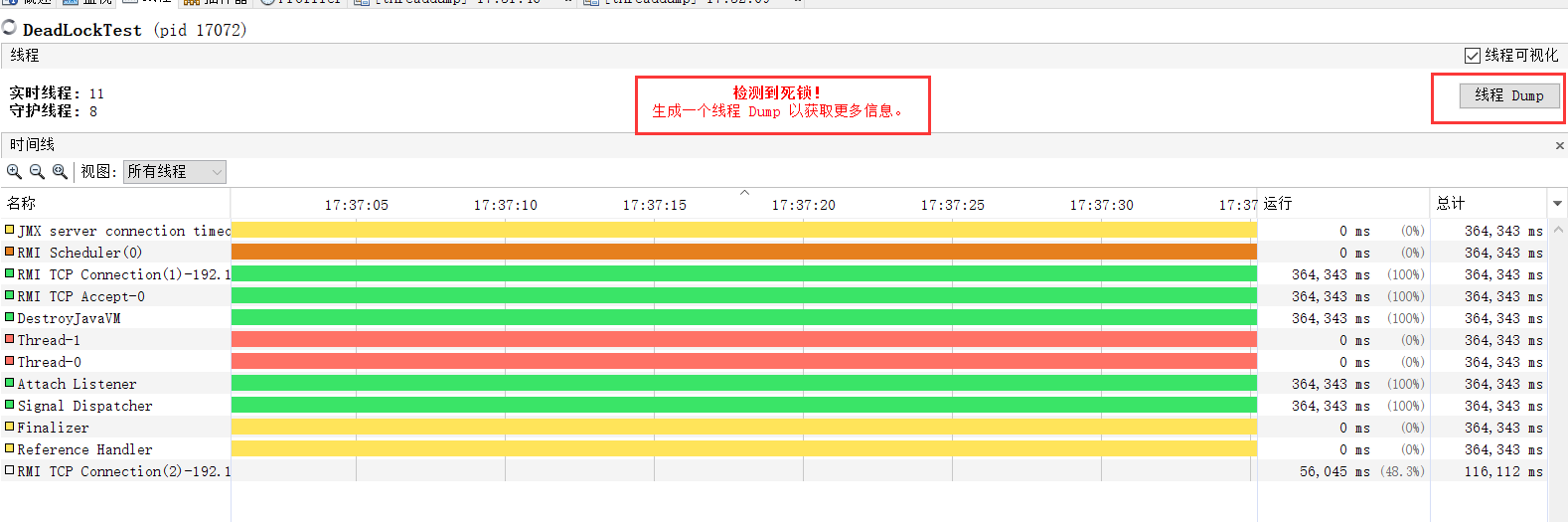
远程连接jvisualvm
启动普通的jar程序JMX端口配置:
java -Dcom.sun.management.jmxremote.port=8888 -Djava.rmi.server.hostname=192.168.65.60 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -jar microservice-eureka-server.jarPS:
-Dcom.sun.management.jmxremote.port 为远程机器的JMX端口
-Djava.rmi.server.hostname 为远程机器IP
tomcat的JMX配置:在catalina.sh文件里的最后一个JAVA_OPTS的赋值语句下一行增加如下配置行
JAVA_OPTS="$JAVA_OPTS -Dcom.sun.management.jmxremote.port=8888 -Djava.rmi.server.hostname=192.168.50.60 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false"连接时确认下端口是否通畅,可以临时关闭下防火墙
systemctl stop firewalld #临时关闭防火墙jstack找出占用cpu最高的线程堆栈信息
package com.tuling.jvm;
/**
* 运行此代码,cpu会飙高
*/
public class Math {
public static final int initData = 666;
public static User user = new User();
public int compute() { //一个方法对应一块栈帧内存区域
int a = 1;
int b = 2;
int c = (a + b) * 10;
return c;
}
public static void main(String[] args) {
Math math = new Math();
while (true){
math.compute();
}
}
}1,使用命令top -p ,显示你的java进程的内存情况,pid是你的java进程号,比如19663
2,按H,获取每个线程的内存情况
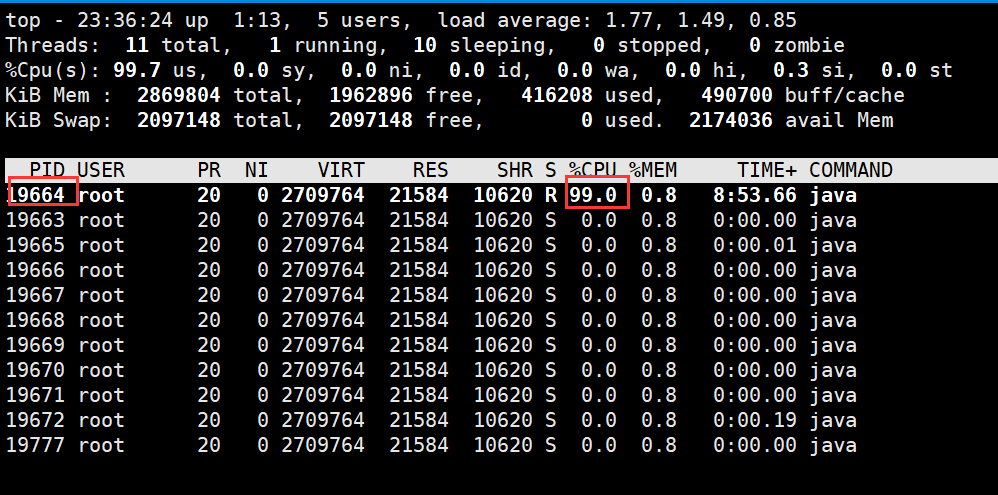
3,找到内存和cpu占用最高的线程tid,比如19664
4,转为十六进制得到 0x4cd0,此为线程id的十六进制表示
5,执行 jstack 19663|grep -A 10 4cd0,得到线程堆栈信息中 4cd0 这个线程所在行的后面10行,
从堆栈中可以发现导致cpu飙高的调用方法
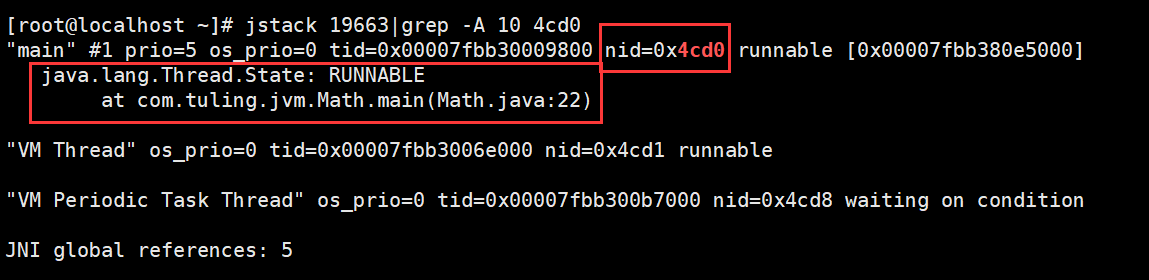
6,查看对应的堆栈信息找出可能存在问题的代码
四、Jinfo
查看正在运行的Java应用程序的扩展参数
查看jvm的参数

查看java系统参数
五、Jstat
jstat命令可以查看堆内存各部分的使用量,以及加载类的数量。命令的格式如下:
jstat [-命令选项] [vmid] [间隔时间(毫秒)] [查询次数]
注意:使用的jdk版本是jdk8
垃圾回收统计
jstat -gc pid 最常用,可以评估程序内存使用及GC压力整体情况

- S0C:第一个幸存区的大小,单位KB
- S1C:第二个幸存区的大小
- S0U:第一个幸存区的使用大小
- S1U:第二个幸存区的使用大小
- EC:伊甸园区的大小
- EU:伊甸园区的使用大小
- OC:老年代大小
- OU:老年代使用大小
- MC:方法区大小(元空间)
- MU:方法区使用大小
- CCSC:压缩类空间大小
- CCSU:压缩类空间使用大小
- YGC:年轻代垃圾回收次数
- YGCT:年轻代垃圾回收消耗时间,单位s
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间,单位s
- GCT:垃圾回收消耗总时间,单位s
堆内存统计

- NGCMN:新生代最小容量
- NGCMX:新生代最大容量
- NGC:当前新生代容量
- S0C:第一个幸存区大小
- S1C:第二个幸存区的大小
- EC:伊甸园区的大小
- OGCMN:老年代最小容量
- OGCMX:老年代最大容量
- OGC:当前老年代大小
- OC:当前老年代大小
- MCMN:最小元数据容量
- MCMX:最大元数据容量
- MC:当前元数据空间大小
- CCSMN:最小压缩类空间大小
- CCSMX:最大压缩类空间大小
- CCSC:当前压缩类空间大小
- YGC:年轻代gc次数
- FGC:老年代GC次数
新生代垃圾回收统计

- S0C:第一个幸存区的大小
- S1C:第二个幸存区的大小
- S0U:第一个幸存区的使用大小
- S1U:第二个幸存区的使用大小
- TT:对象在新生代存活的次数
- MTT:对象在新生代存活的最大次数
- DSS:期望的幸存区大小
- EC:伊甸园区的大小
- EU:伊甸园区的使用大小
- YGC:年轻代垃圾回收次数
- YGCT:年轻代垃圾回收消耗时间
新生代内存统计

- NGCMN:新生代最小容量
- NGCMX:新生代最大容量
- NGC:当前新生代容量
- S0CMX:最大幸存1区大小
- S0C:当前幸存1区大小
- S1CMX:最大幸存2区大小
- S1C:当前幸存2区大小
- ECMX:最大伊甸园区大小
- EC:当前伊甸园区大小
- YGC:年轻代垃圾回收次数
- FGC:老年代回收次数
老年代垃圾回收统计

- MC:方法区大小
- MU:方法区使用大小
- CCSC:压缩类空间大小
- CCSU:压缩类空间使用大小
- OC:老年代大小
- OU:老年代使用大小
- YGC:年轻代垃圾回收次数
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间
- GCT:垃圾回收消耗总时间
老年代内存统计

- OGCMN:老年代最小容量
- OGCMX:老年代最大容量
- OGC:当前老年代大小
- OC:老年代大小
- YGC:年轻代垃圾回收次数
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间
- GCT:垃圾回收消耗总时间
元数据空间统计

- MCMN:最小元数据容量
- MCMX:最大元数据容量
- MC:当前元数据空间大小
- CCSMN:最小压缩类空间大小
- CCSMX:最大压缩类空间大小
- CCSC:当前压缩类空间大小
- YGC:年轻代垃圾回收次数
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间
- GCT:垃圾回收消耗总时间

- S0:幸存1区当前使用比例
- S1:幸存2区当前使用比例
- E:伊甸园区使用比例
- O:老年代使用比例
- M:元数据区使用比例
- CCS:压缩使用比例
- YGC:年轻代垃圾回收次数
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间
- GCT:垃圾回收消耗总时间
JVM运行情况预估
用 jstat gc -pid 命令可以计算出如下一些关键数据,有了这些数据就可以采用之前介绍过的优化思路,先给自己的系统设置一些初始性的
JVM参数,比如堆内存大小,年轻代大小,Eden和Survivor的比例,老年代的大小,大对象的阈值,大龄对象进入老年代的阈值等。
年轻代对象增长的速率
可以执行命令 jstat -gc pid 1000 10 (每隔1秒执行1次命令,共执行10次),通过观察EU(eden区的使用)来估算每秒eden大概新增多少对
象,如果系统负载不高,可以把频率1秒换成1分钟,甚至10分钟来观察整体情况。注意,一般系统可能有高峰期和日常期,所以需要在
不同的时间分别估算不同情况下对象增长速率。
Young GC的触发频率和每次耗时
知道年轻代对象增长速率我们就能推根据eden区的大小推算出Young GC大概多久触发一次,Young GC的平均耗时可以通过 YGCT/YGC
公式算出,根据结果我们大概就能知道系统大概多久会因为Young GC的执行而卡顿多久。
每次Young GC后有多少对象存活和进入老年代
这个因为之前已经大概知道Young GC的频率,假设是每5分钟一次,那么可以执行命令 jstat -gc pid 300000 10 ,观察每次结果eden,
survivor和老年代使用的变化情况,在每次gc后eden区使用一般会大幅减少,survivor和老年代都有可能增长,这些增长的对象就是每次
Young GC后存活的对象,同时还可以看出每次Young GC后进去老年代大概多少对象,从而可以推算出老年代对象增长速率。
Full GC的触发频率和每次耗时
知道了老年代对象的增长速率就可以推算出Full GC的触发频率了,Full GC的每次耗时可以用公式 FGCT/FGC 计算得出。
优化思路其实简单来说就是尽量让每次Young GC后的存活对象小于Survivor区域的50%,都留存在年轻代里。尽量别让对象进入老年
代。尽量减少Full GC的频率,避免频繁Full GC对JVM性能的影响。
系统频繁Full GC导致系统卡顿是怎么回事
- 机器配置:2核4G
- JVM内存大小:2G
- 系统运行时间:7天
- 期间发生的Full GC次数和耗时:500多次,200多秒
- 期间发生的Young GC次数和耗时:1万多次,500多秒
大致算下来每天会发生70多次Full GC,平均每小时3次,每次Full GC在400毫秒左右;
每天会发生1000多次Young GC,每分钟会发生1次,每次Young GC在50毫秒左右。
JVM参数设置如下:
-Xms1536M -Xmx1536M -Xmn512M -Xss256K -XX:SurvivorRatio=6 -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly 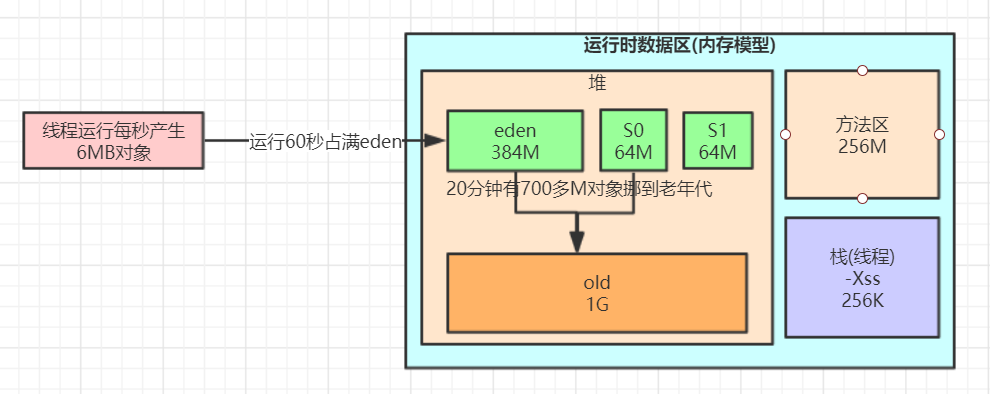
大家可以结合对象挪动到老年代那些规则推理下我们这个程序可能存在的一些问题
经过分析感觉可能会由于对象动态年龄判断机制导致full gc较为频繁
为了给大家看效果,我模拟了一个示例程序(见课程对应工程代码:jvm-full-gc),打印了jstat的结果如下:
jstat -gc 13456 2000 10000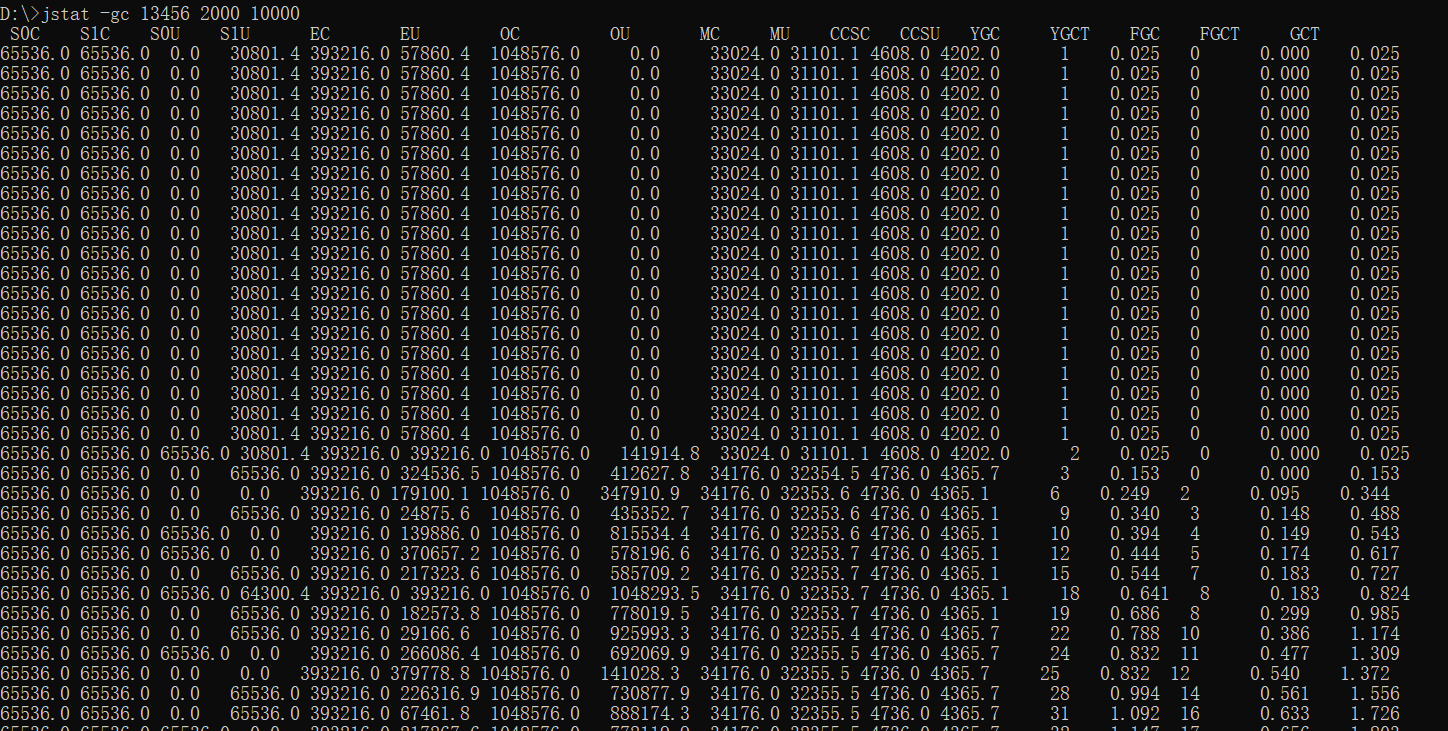
对于对象动态年龄判断机制导致的full gc较为频繁可以先试着优化下JVM参数,把年轻代适当调大点:
-Xms1536M -Xmx1536M -Xmn1024M -Xss256K -XX:SurvivorRatio=6 -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=92 -XX:+UseCMSInitiatingOccupancyOnly 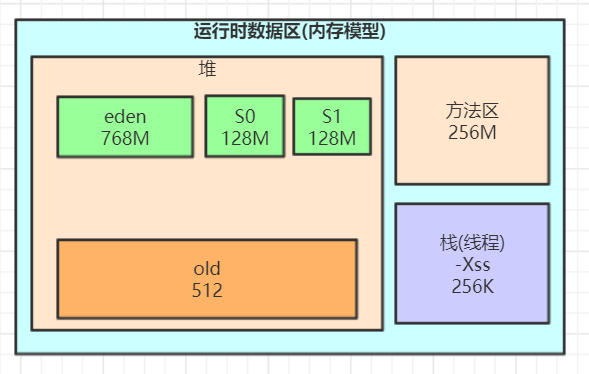
优化完发现没什么变化,full gc的次数比minor gc的次数还多了
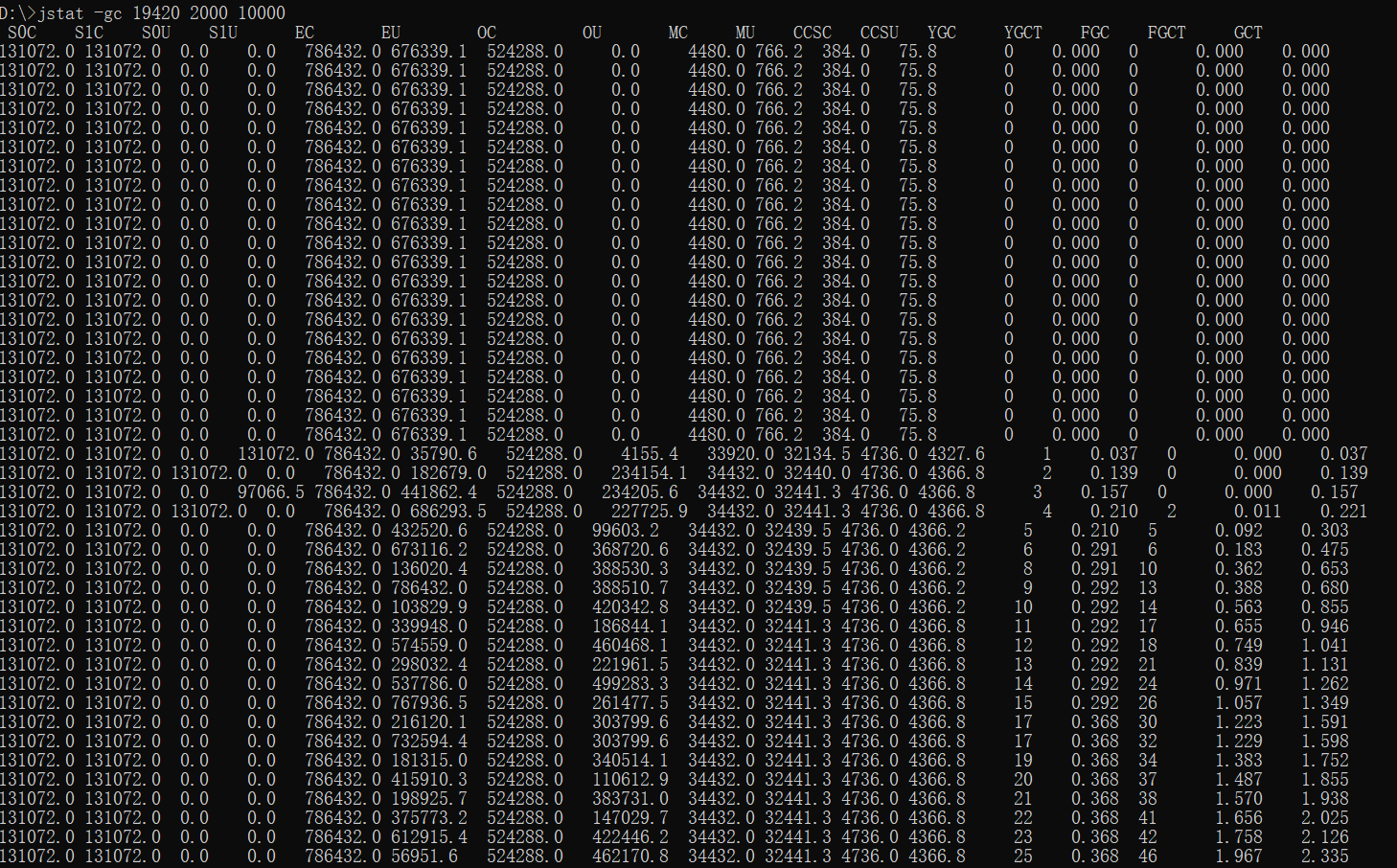
我们可以推测下full gc比minor gc还多的原因有哪些?
1、元空间不够导致的多余full gc
2、显示调用System.gc()造成多余的full gc,这种一般线上尽量通过-XX:+DisableExplicitGC参数禁用,
如果加上了这个JVM启动参数,那么代码中调用System.gc()没有任何效果
3、老年代空间分配担保机制
最快速度分析完这些我们推测的原因以及优化后,我们发现young gc和full gc依然很频繁了,
而且看到有大量的对象频繁的被挪动到老年代,这种情况我们可以借助jmap命令大概看下是什么对象
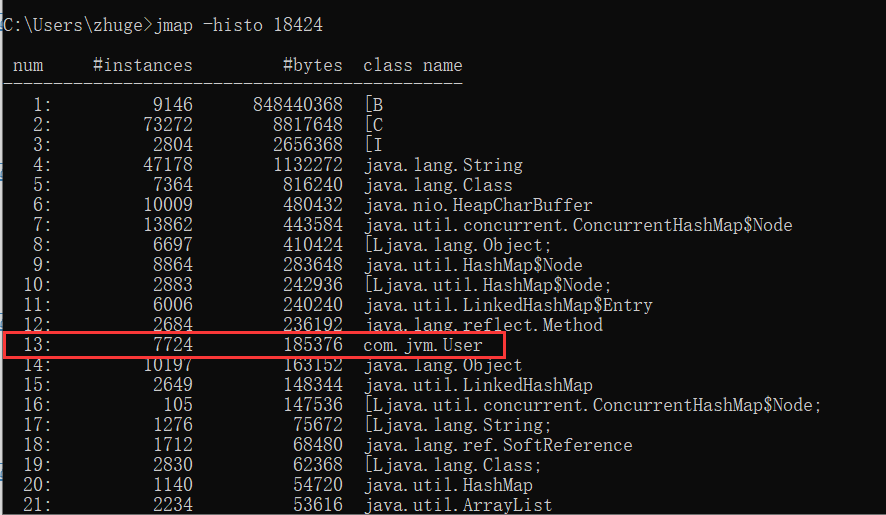
查到了有大量User对象产生,这个可能是问题所在,但不确定,还必须找到对应的代码确认,如何去找对应的代码了?
1、代码里全文搜索生成User对象的地方(适合只有少数几处地方的情况)
2、如果生成User对象的地方太多,无法定位具体代码,我们可以同时分析下占用cpu较高的线程,一般有大量对象不断产生,
对应的方法代码肯定会被频繁调用,占用的cpu必然较高
可以用上面讲过的jstack或jvisualvm来定位cpu使用较高的代码,最终定位到的代码如下:
import java.util.ArrayList;
@RestController
public class IndexController {
@RequestMapping("/user/process")
public String processUserData() throws InterruptedException {
ArrayList<User> users = queryUsers();
for (User user: users) {
//TODO 业务处理
System.out.println("user:" + user.toString());
}
return "end";
}
/**
* 模拟批量查询用户场景
* @return
*/
private ArrayList<User> queryUsers() {
ArrayList<User> users = new ArrayList<>();
for (int i = 0; i < 5000; i++) {
users.add(new User(i,"zhuge"));
}
return users;
}
}同时,java的代码也是需要优化的,一次查询出500M的对象出来,明显不合适,
要根据之前说的各种原则尽量优化到合适的值,尽量消除这种朝生夕死的对象导致的full gc
内存泄露到底是怎么回事
再给大家讲一种情况,一般电商架构可能会使用多级缓存架构,就是redis加上JVM级缓存,大多数同学可能为了
图方便对于JVM级缓存就简单使用一个hashmap,于是不断往里面放缓存数据,但是很少考虑这个map的容量问
题,结果这个缓存map越来越大,一直占用着老年代的很多空间,时间长了就会导致full gc非常频繁,这就是一
种内存泄漏,对于一些老旧数据没有及时清理导致一直占用着宝贵的内存资源,时间长了除了导致full gc,还有可
能导致OOM。
这种情况完全可以考虑采用一些成熟的JVM级缓存框架来解决,比如ehcache等自带一些LRU数据淘汰算法的框架
来作为JVM级的缓存。


















 692
692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











