







简介
ist 列表是简单的字符串列表,按照插入顺序排序,可以从头部或尾部向 List 列表添加元素。
列表的最大长度为 2^32 - 1,也即每个列表支持超过 40 亿个元素。
/*
* 双端链表结构
*/
typedef struct list {
// 表头节点
listNode *head;
// 表尾节点
listNode *tail;
// 节点值复制函数
void *(*dup)(void *ptr);
// 节点值释放函数
void (*free)(void *ptr);
// 节点值对比函数
int (*match)(void *ptr, void *key);
// 链表所包含的节点数量
unsigned long len; //最大为2^32 - 1
} list;
内部实现
List 类型的底层数据结构是由双向链表或压缩列表实现的:
- 如果列表的元素个数小于 512 个(默认值,可由 list-max-ziplist-entries 配置),列表每个元素的值都小于 64 字节(默认值,可由 list-max-ziplist-value 配置),Redis 会使用压缩列表作为 List 类型的底层数据结构;
- 如果列表的元素不满足上面的条件,Redis 会使用双向链表作为 List 类型的底层数据结构;
/* The function pushes an element to the specified list object 'subject',
* at head or tail position as specified by 'where'.
*
* 将给定元素添加到列表的表头或表尾。
*
* 参数 where 决定了新元素添加的位置:
*
* - REDIS_HEAD 将新元素添加到表头
*
* - REDIS_TAIL 将新元素添加到表尾
*
* There is no need for the caller to increment the refcount of 'value' as
* the function takes care of it if needed.
*
* 调用者无须担心 value 的引用计数,因为这个函数会负责这方面的工作。
*/
void listTypePush(robj *subject, robj *value, int where) {
/* Check if we need to convert the ziplist */
// 是否需要转换编码?
listTypeTryConversion(subject,value); //值超过64字节压缩链表会转化为双端链表
if (subject->encoding == REDIS_ENCODING_ZIPLIST &&
ziplistLen(subject->ptr) >= server.list_max_ziplist_entries)
listTypeConvert(subject,REDIS_ENCODING_LINKEDLIST); //压缩链表长度超过512会双端链表
// ZIPLIST
if (subject->encoding == REDIS_ENCODING_ZIPLIST) {
int pos = (where == REDIS_HEAD) ? ZIPLIST_HEAD : ZIPLIST_TAIL;
// 取出对象的值,因为 ZIPLIST 只能保存字符串或整数
value = getDecodedObject(value);
subject->ptr = ziplistPush(subject->ptr,value->ptr,sdslen(value->ptr),pos);
decrRefCount(value);
// 双端链表
} else if (subject->encoding == REDIS_ENCODING_LINKEDLIST) {
if (where == REDIS_HEAD) {
listAddNodeHead(subject->ptr,value);
} else {
listAddNodeTail(subject->ptr,value);
}
incrRefCount(value);
// 未知编码
} else {
redisPanic("Unknown list encoding");
}
}
压缩链表
ziplist 是一个特殊双向链表,不像普通的双向链表使用前后指针关联在一起,它是存储在连续内存上的。
unsigned char *ziplistNew(void) {
// ZIPLIST_HEADER_SIZE 是 ziplist 表头的大小
// 1 字节是表末端 ZIP_END 的大小
unsigned int bytes = ZIPLIST_HEADER_SIZE+1;
// 为表头和表末端分配空间
unsigned char *zl = zmalloc(bytes);
// 初始化表属性
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0;
// 设置表末端
zl[bytes-1] = ZIP_END;
return zl;
}

每个字段的含义如下
- zlbytes: 32 位无符号整型,记录 ziplist 整个结构体的占用空间大小。当然了也包括 zlbytes 本身。这个结构有个很大的用处,就是当需要修改 ziplist 时候不需要遍历即可知道其本身的大小。 这个 SDS 中记录字符串的长度有相似之处。
- zltail: 32 位无符号整型, 记录整个 ziplist 中最后一个 entry 的偏移量。所以在尾部进行操作时候不需要先遍历一次。
- zllen: 16 位无符号整型, 记录 entry 的数量, 所以只能表示 2^16。但是 Redis 作了特殊的处理:当实体数超过 2^16 ,该值被固定为 2^16 - 1。 所以这种时候要知道所有实体的数量就必须要遍历整个结构了。
- entry: 真正存数据的结构。
- zlend: 8 位无符号整型, 固定为 255 (0xFF)。为 ziplist 的结束标识。
zipentry 节点
每个 entry 都包含两条信息的元数据为前缀:
第一元数据用来存储前一个 entry 的长度,以便能够从后向前遍历列表。
第二元数据是表示 entry 的编码形式。 用来表示 entry 类型,整数或字符串,在字符串的情况下,它还表示字符串有效的长度。
/*
* 保存 ziplist 节点信息的结构
*/
typedef struct zlentry {
// prevrawlen :前置节点的长度
// prevrawlensize :编码 prevrawlen 所需的字节大小
unsigned int prevrawlensize, prevrawlen;
// len :当前节点值的长度
// lensize :编码 len 所需的字节大小
unsigned int lensize, len;
// 当前节点 header 的大小
// 等于 prevrawlensize + lensize
unsigned int headersize;
// 当前节点值所使用的编码类型
unsigned char encoding;
// 指向当前节点的指针
unsigned char *p;
} zlentry;
/*
空白 ziplist 示例图
area |<---- ziplist header ---->|<-- end -->|
size 4 bytes 4 bytes 2 bytes 1 byte
+---------+--------+-------+-----------+
component | zlbytes | zltail | zllen | zlend |
| | | | |
value | 1011 | 1010 | 0 | 1111 1111 |
+---------+--------+-------+-----------+
^
|
ZIPLIST_ENTRY_HEAD
&
address ZIPLIST_ENTRY_TAIL
&
ZIPLIST_ENTRY_END
非空 ziplist 示例图
area |<---- ziplist header ---->|<----------- entries ------------->|<-end->|
size 4 bytes 4 bytes 2 bytes ? ? ? ? 1 byte
+---------+--------+-------+--------+--------+--------+--------+-------+
component | zlbytes | zltail | zllen | entry1 | entry2 | ... | entryN | zlend |
+---------+--------+-------+--------+--------+--------+--------+-------+
^ ^ ^
address | | |
ZIPLIST_ENTRY_HEAD | ZIPLIST_ENTRY_END
|
ZIPLIST_ENTRY_TAIL
*/

连锁更新
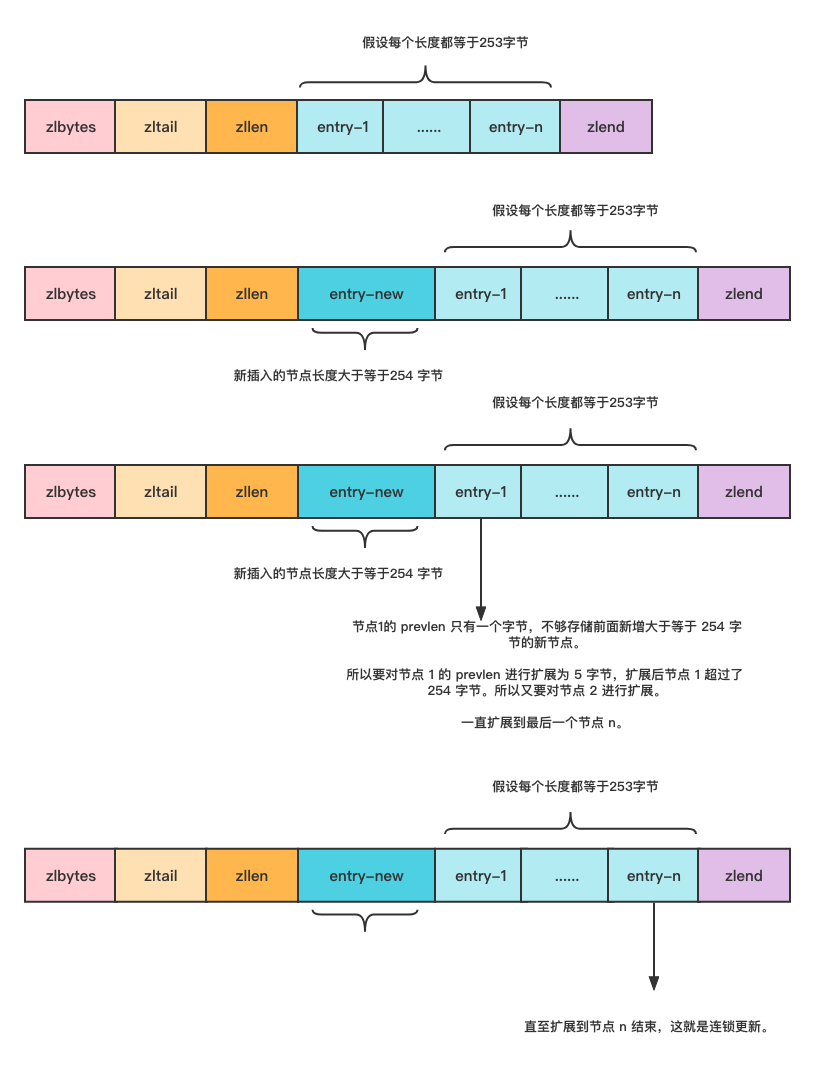
连锁更新是 ziplist 一个比较大的缺点。
ziplist 在更新或者新增时候,如空间不够则需要对整个列表进行重新分配。当新插入的元素较大时,可能会导致后续元素的 prevlen 占用空间都发生变化,从而引起「连锁更新」问题,导致每个元素的空间都要重新分配,造成访问压缩列表性能的下降。
ziplist 节点的 prevlen 属性会根据前一个节点的长度进行不同的空间大小分配:
- 如果前一个节点的长度小于 254 字节,那么 prevlen 属性需要用 1 字节的空间来保存这个长度值。
- 如果前一个节点的长度大于等于 254 字节,那么 prevlen 属性需要用 5 字节的空间来保存这个长度值。
假设有这样的一个 ziplist,每个节点都是等于 253 字节的。新增了一个大于等于 254 字节的新节点,由于之前的节点 prevlen 长度是 1 个字节。
为了要记录新增节点的长度所以需要对节点 1 进行扩展,由于节点 1 本身就是 253 字节,再加上扩展为 5 字节的 pervlen 则长度超过了 254 字节,这时候下一个节点又要进行扩展了。这样会导致整个ziplist全部更新。
总结
- ziplist 为了节省内存,采用了紧凑的连续存储。所以在修改操作下并不能像一般的链表那么容易,需要重新分配新的内存,然后复制到新的空间。
- ziplist 是一个双向链表,可以在时间复杂度为 O(1) 从下头部、尾部进行 pop 或 push。
- 新增或更新元素可能会出现连锁更新现象。
- 不能保存过多的元素,否则查询效率就会降低。
双端链表
/*
* 双端链表节点
*/
typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 节点的值
void *value;
} listNode;
/*
* 双端链表迭代器
*/
typedef struct listIter {
// 当前迭代到的节点
listNode *next;
// 迭代的方向
int direction;
} listIter;
/*
* 双端链表结构
*/
typedef struct list {
// 表头节点
listNode *head;
// 表尾节点
listNode *tail;
// 节点值复制函数
void *(*dup)(void *ptr);
// 节点值释放函数
void (*free)(void *ptr);
// 节点值对比函数
int (*match)(void *ptr, void *key);
// 链表所包含的节点数量
unsigned long len;
} list;
- 由于是双向链表,具有前后节点的指针引用,所以对获取这两个节点的时间复杂度为O(1)。
- 通过链表长度len属性,获取长度的时间复杂度为O(1) 。
- 由于节点值是一个指针,所以value可以指定任何类型。
- 头节点的前指针和尾结点的后指针都为NULL,是无环的
- 每个节点只有一个value,导致内存利用率过低
快速链表
高版本的list实现是quicklist

实际上quicklist就是双端列表+压缩列表
- 第一 双向链表能在头尾在 O(1)下找到一个元素,若是在中部查找则平均复杂度也只是O(N),N 是 entry 的个数。
- 第二 ziplist 使用了紧凑布局和可变编码方式大大降低了内存的使用。这就是 quicklis 作为 List 首选的实现方案。
但是若是 quicklistNode 中 ziplist 的 entry 的个数设置的不恰当,那 quicklist 的性能也会大幅降低。比如下面的极端情况:
- list-max-ziplist-size 设置为 1 。这时候 quicklist 性能上就退化和普通双向链表一样。在内存使用上就不能体验到 ziplist 的优势。
- list-max-ziplist-size 设置为所有元素的个数,甚至所有的元素都存储在一个节点中,ziplist 的缺点就会被无限放大放大。ziplist 需要一段连续的内存,且修改时候会发生内存的复制。
所以在实际使用中,要根据数据特点设置一个比较合理的值。
















 1447
1447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









