







目录
百度网盘获取pdf版本:
链接:链接
提取码:WHY6
**程序编译的总框架:

简答题
**编译原理的前端和后端分别有哪些阶段组成?
图示:

编译前端:与源语言有关,如词法分析,语法分析,语义分析与中间代码产生,与机器无关的优化,出错管理,符号管理
编译后端:与目标机有关,与目标机有关的优化,目标代码产生
目的:增加可移植性
前端和后端都包含优化过程
编译程序的五个阶段及其作用
- 词法分析:从左到右扫描组成源程序的字符串,并将其转换成单词串
- 语法分析:按照文法的产生式(语言的语法规则),识别输入符号串是否为一个句子(合式程序)
- 语义分析(语法制导翻译)与中间代码生成:分析由语法分析器识别出来的语法成分的语义,语义分析通常以中间代码形式表达操作
- 代码优化:对中间代码进行优化处理,使程序运行能够尽量节省存储空间,更有效地利用机器资源,使得程序的运行速度更快,效率更高
- 目标代码生成:为中间代码中出现的运算对象分配存储单元、寄存器等;将中间代码转换成目标机上的机器指令代码或汇编代码
程序编译的三大模块分类

**解释器和编译器的区别
解释器:把源语言写的源程序作为输入,但不产生目标程序,而是边解释边执行源程序
编译器:把某一种高级语言程序等价地转换成另一种低级语言程序(如汇编语言或机器语言程序)的程序
**文法的形式化定义

推导和规约


补充:多步推导/规约

(规约同理)
**句型、句子和语言的含义
句子一定是句型,但句型不一定是句子
**短语、素短语、直接短语、句柄的含义

参考:
编译原理 —— 短语、直接短语、素短语和句柄_starter_zheng的博客-CSDN博客_直接短语
要知道含义,并且会求

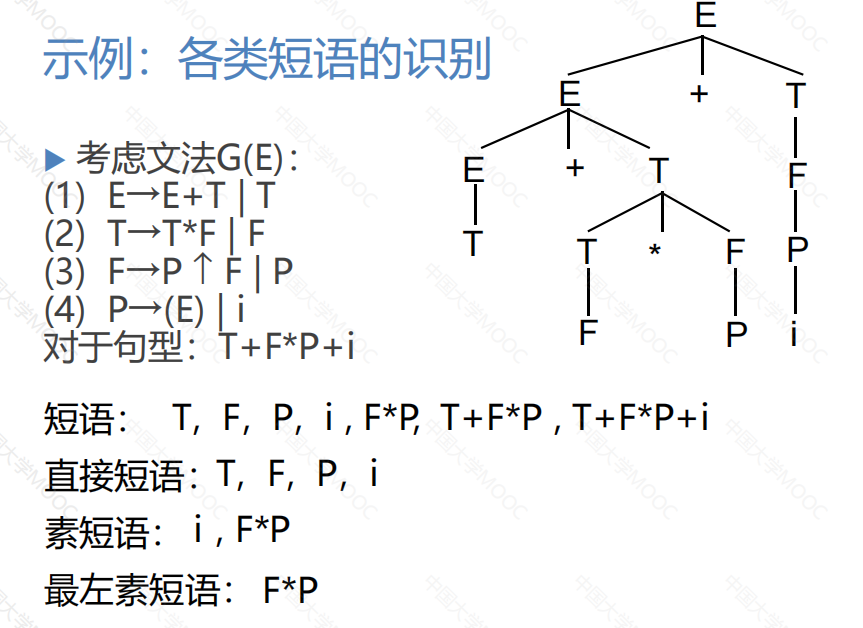
最左推导与最右推导
最左推导:每次推导都施加在句型的最左边的语法变量上。——与最右归约对应
最右推导:每次推导都施加在句型最右边的语法变量上。——与最左归约(规范规约)
示例:
对于文法:
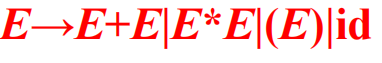
句子id + id * id的推导:
最左推导:
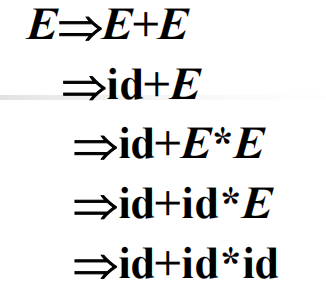
最右推导:
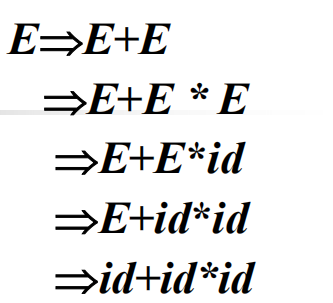
最左规约:
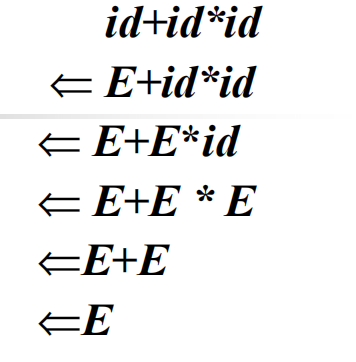
最右规约:
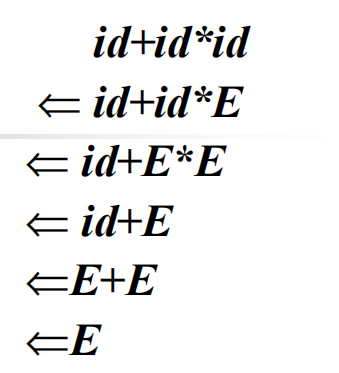
文法的二义性
如果一个文法的句子存在两棵分析树,那么该句子是二义性的。
如果一个文法包含二义性的句子,则称这个文法是二义性的; 否则,该文法是无二义性的
规范规约的含义


字的前缀和活前缀的含义

规范归约过程中,保证分析栈中总是活前缀,就说明分析采取的移进/归约动作是正确的
LR(0)项目的分类

属性和语义规则的定义
属性是与文法符号相关联的语义信息
语义规则是与产生式相关联的语义动作
**综合属性、继承属性和固有属性的含义
综合属性:节点的属性值是通过分析树中该节点或其子节点的属性值计算出来的
继承属性:节点的属性值是由该节点、其兄弟节点或父节点的属性值计算出来的
固有属性:通过词法分析直接得到的属性
**S属性和L属性的定义
S-属性:只含综合属性的语法制导定义称为S-属性定义,S-属性文法适合一遍扫描的自下而上分析
L-属性:一个语法制导定义被称为L-属性定义,当且仅当它的每个属性或者是综合属性,或者是满足如下条件的继承属性:

L-属性文法适合一遍扫描的自上而下分析
S-属性文法一定是L-属性文法
语义规则和翻译模式

图示:

四种参数传递方式
- 传值
- 传地址
- 传值结果
- 传名
举例:

代码优化分类
- 机器相关性:分为机器相关优化(寄存器优化,多处理器优化,特殊指令优化,无用指令消除等)和机器无关优化
- 优化范围:分为局部优化和全局优化
- 优化语言级:分为:针对中间代码和针对机器语言。
**常用的代码优化方法
①公共子表达式删除:用先前的计算结果替换公共子表达式的本次出现
如果表达式E在某次出现之前已经被计算过,并且E中变量的值从那次计算到本次出现之间未被改变过,则E的本次出现称为公共子表达式
②复制传播:

③无用代码删除:无用代码是指计算结果以后不被引用的语句
④代码外提:

⑤强度削弱:用计算较快的运算代替较慢的运算
例如:
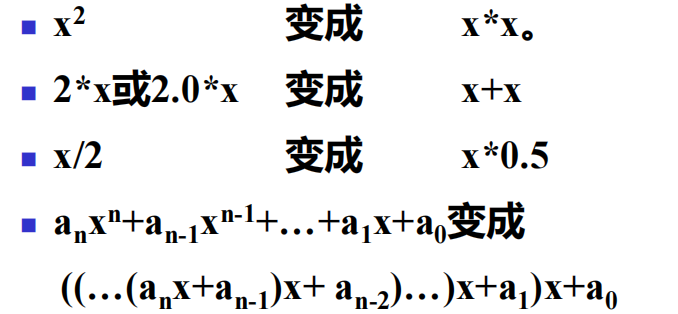
**局部性原理的概念
程序中的大部分运行时间都花费在较少的一部分代码中,而且只是涉及到一小部分数据。时间局部性:如果某个程序访问的内存位置有可能在很短的时间内被再次访问空间局部性:如果被访问过的内存位置的邻近位置有可能在很短的时间内被再次访问
**给出C语言的活动记录格式
过程的每个活动所需要的信息用一块连续的存储区来管理,这块存储区叫做活动记录
非嵌套语言(如C语言)的活动记录格式如下:

sp:指向当前过程的活动记录在栈中的起始位置
top:指向栈顶
形式单元:存储形参
简单变量:存储过程内部定义的变量
旧SP:指的是上一条活动记录的SP的位置
补充:嵌套语言(如PASCAL)的活动记录的基本格式:

代码生成器输出的三种形式
- 绝对机器语言代码
- 可重定位的机器语言代码
- 汇编语言代码
什么是窥孔优化?列出几种窥孔优化的技术
窥孔优化是一种简单有效的局部优化方法,它通过检查目标指令中称为窥孔的短序列,用更小更短的指令序列进行等价代替,以此来提高目标代码的质量
- 冗余指令消除
- 不可达代码消除
- 强度削弱
- 特殊机器指令的使用
另外
符号表的作用

计算题
正则文法和正则表达式之间的转化
1.正则文法——正则表达式:

例题:

2.正则表达式——正则文法

3.正则表达式——状态转换图
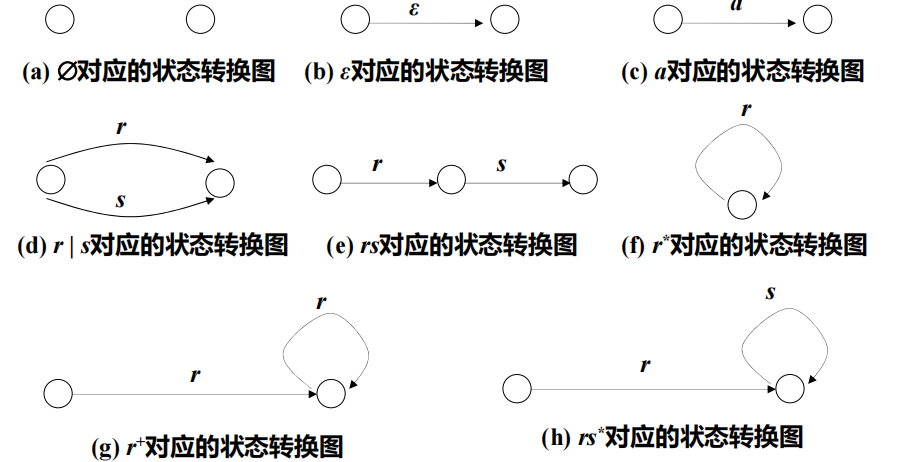
例:
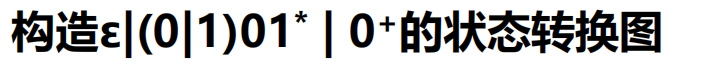
例题:

如何求FIRST集合和FOLLOW集合
FIRST集合

FOLLOW集合:

示例:

判断文法是否是LL(1)文法

LL(1)分析法中分析表的构造和预测分析示例

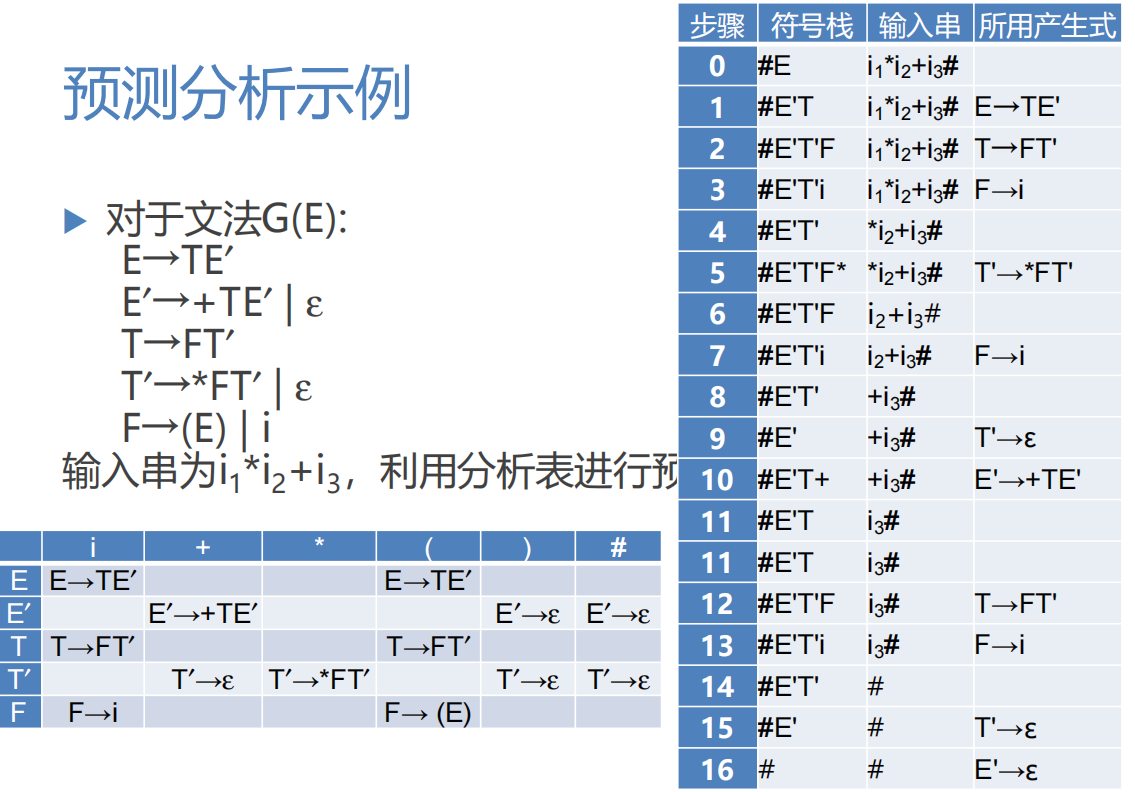
LR(0)分析表和SLR(1)分析表
移进规约冲突:

比较:
逆波兰式

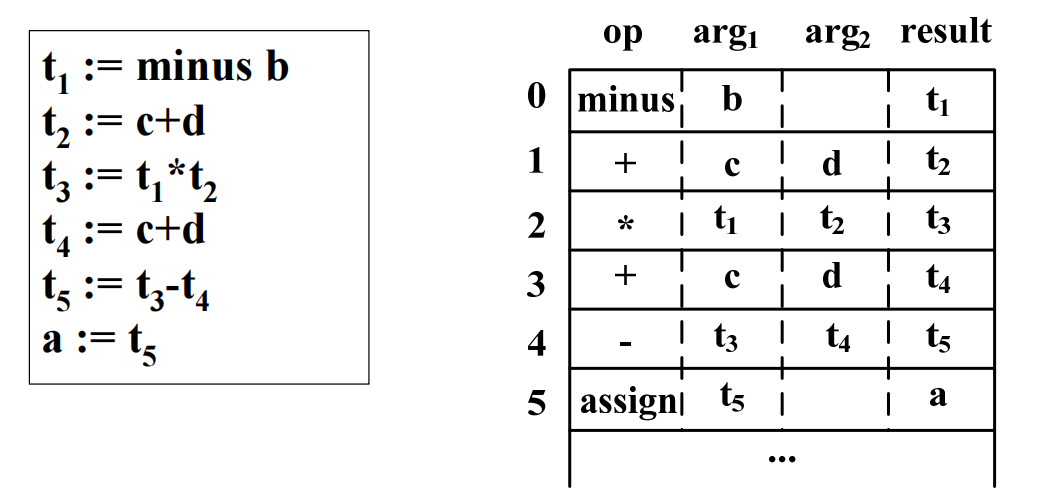
三地址码

四元式:
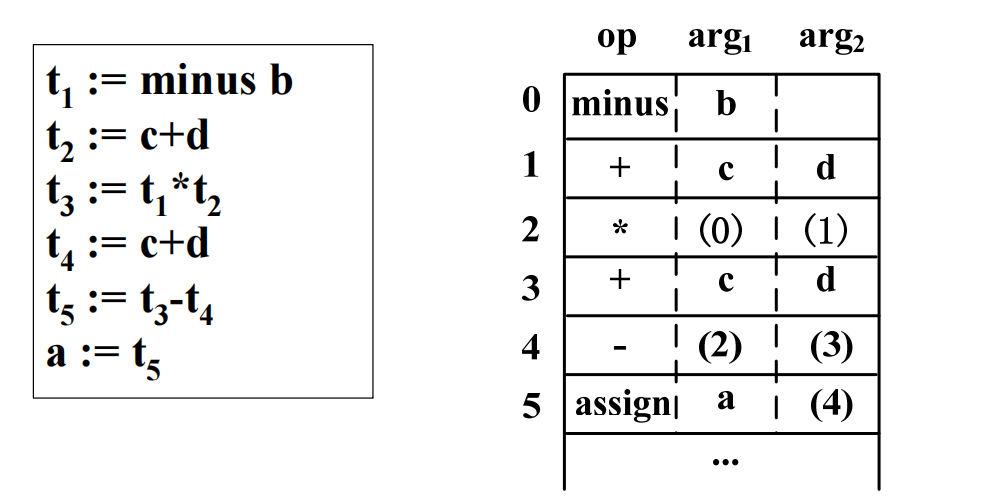
三元式:
抽象语法树(DAG有向无环图)
可以消除公共子表达式,具有公共子表达式的节点具有多个父节点
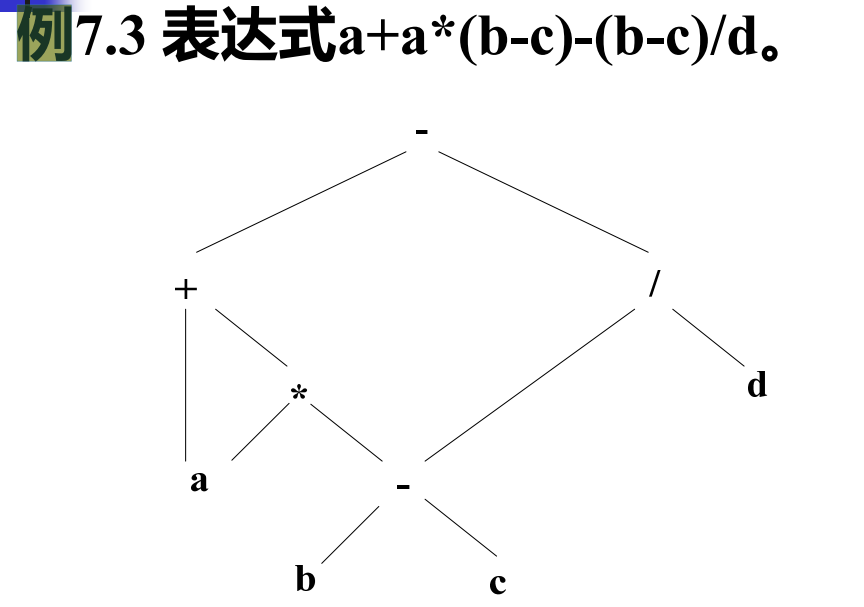
中间代码表示形式示例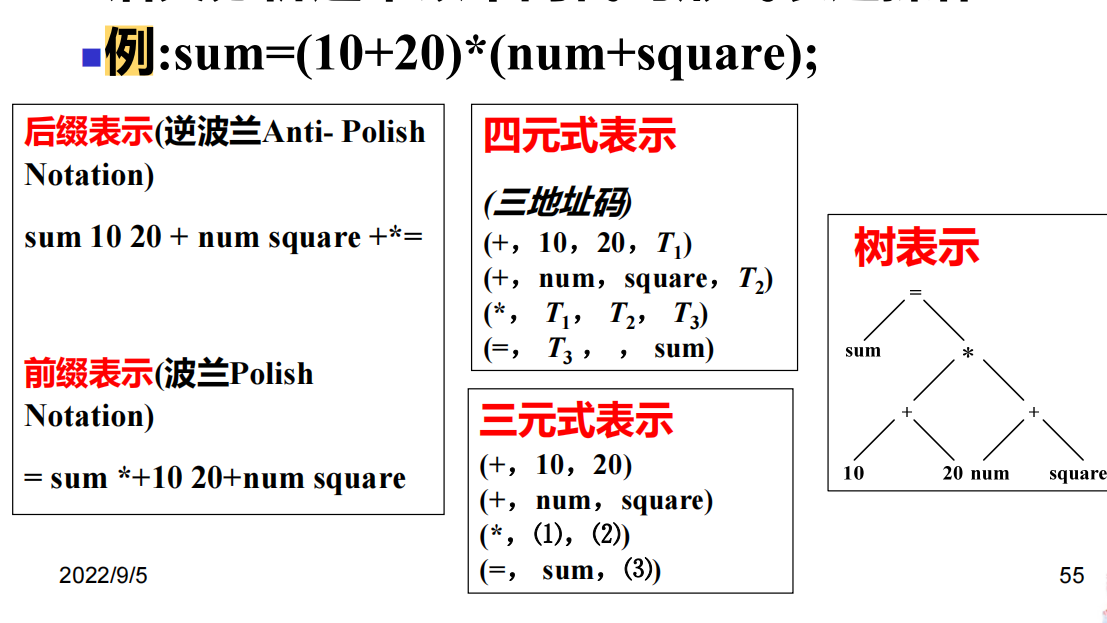
中间代码生成
一遍扫描:通过单遍扫描为布尔表达式和控制流语句生成代码
回填:

用到的函数:
布尔表达式回填式翻译
or:
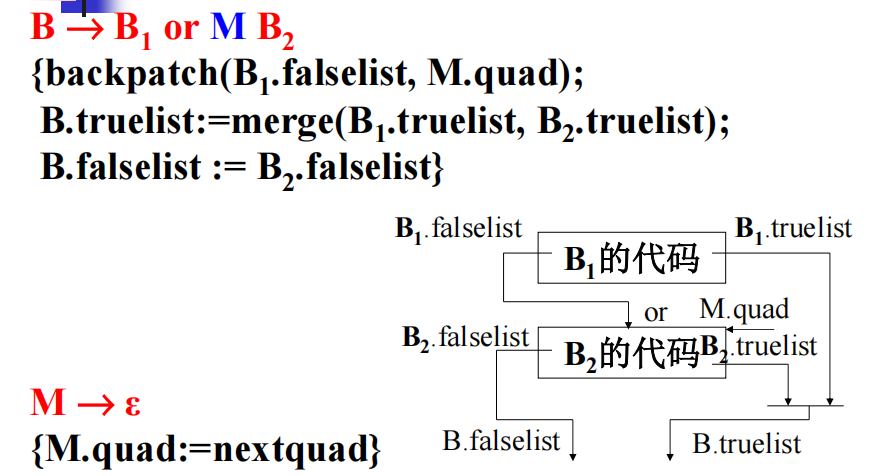
nextquad 指向下一条将要产生的但是没有产生的四元式的地址,初值为1,每当执行一次emit,就自增1
and: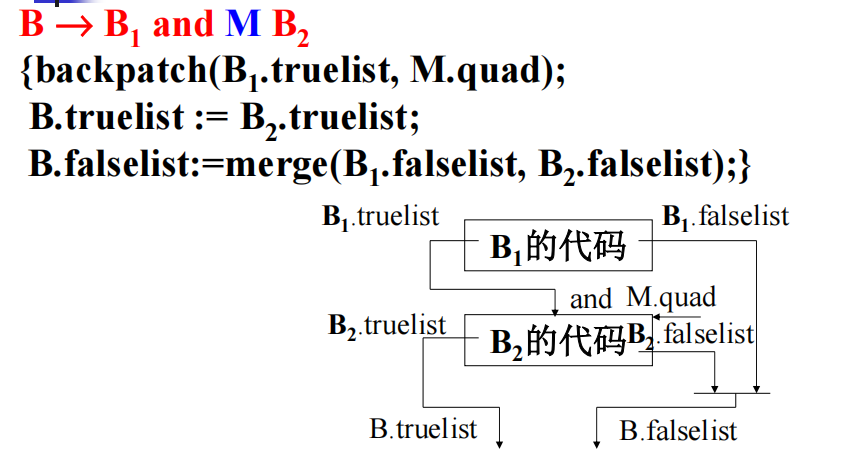
not ()

运算符(<,>)
true false:
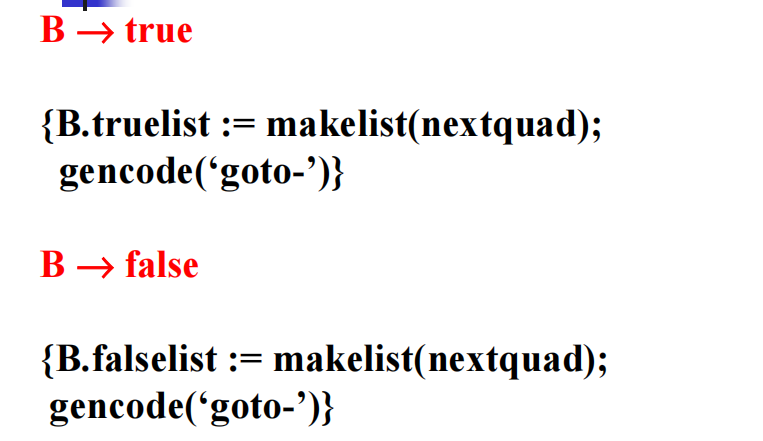
例题:
常见控制结构的回填式翻译
总体:
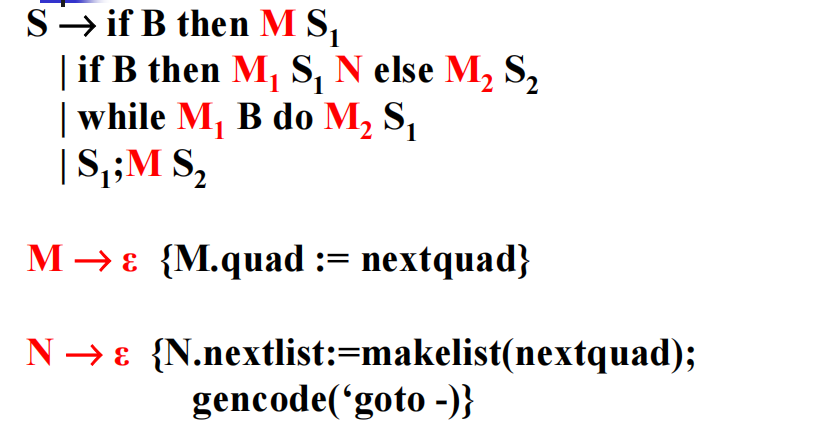
if-then: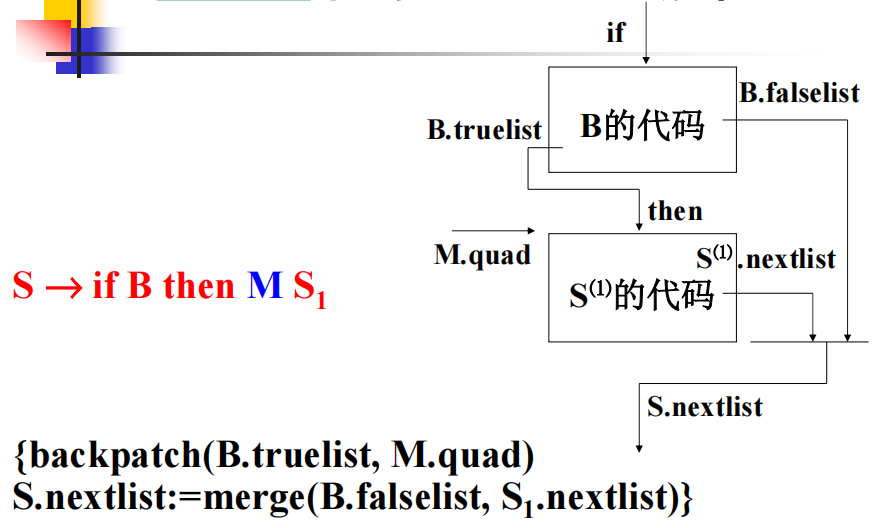
if-then-else

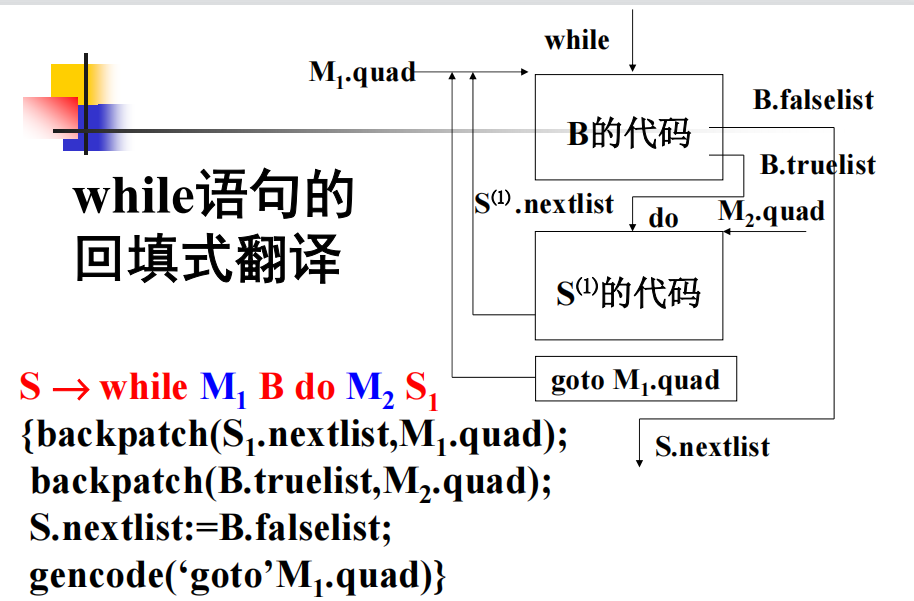
while:
语句序列:
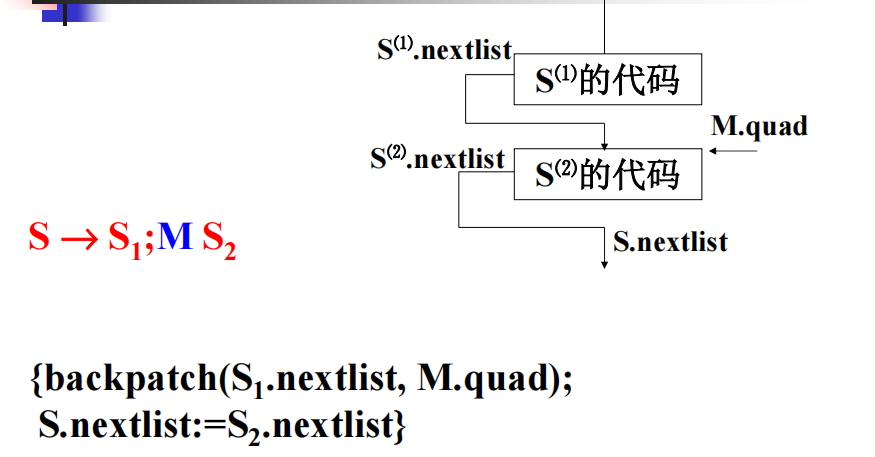
例题: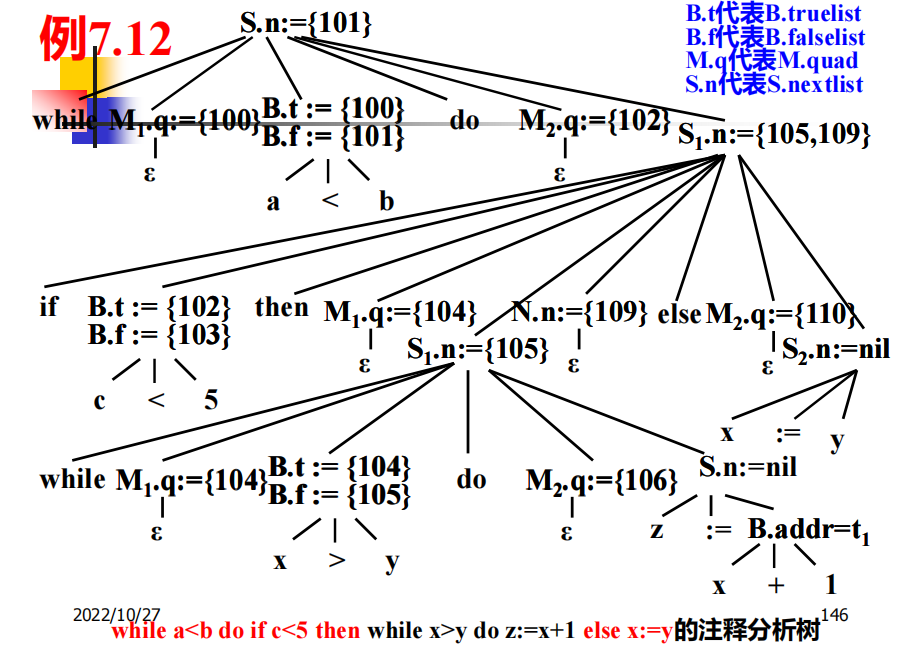
while a<b do:
if c<5 then:
while x>y do:
z := x+1
else
x := y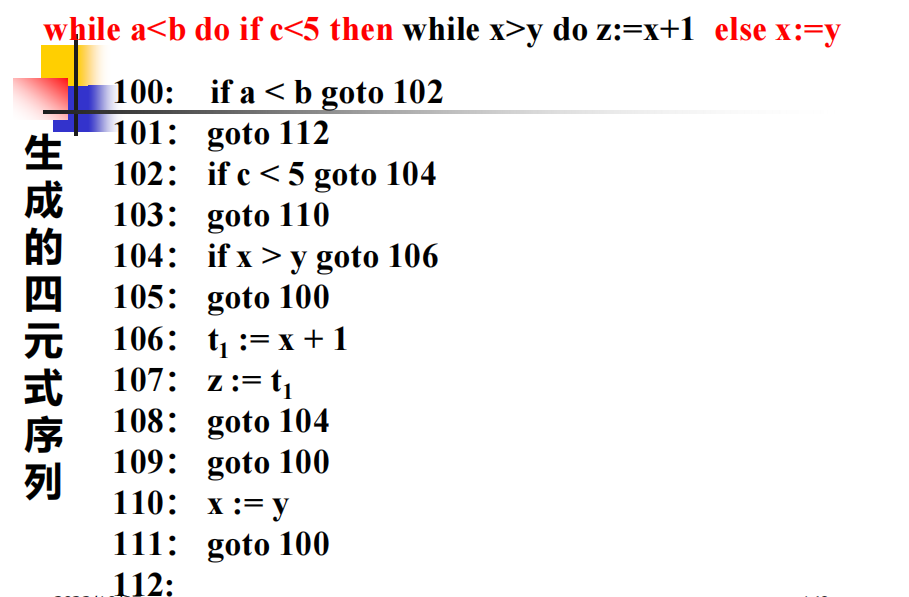
补充
字母表和字符


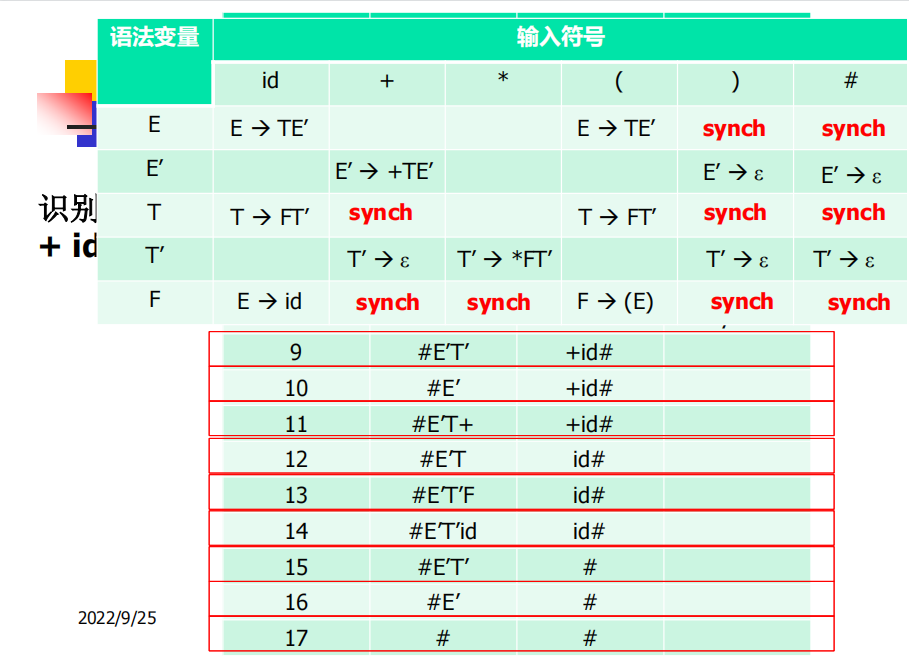
 预测分析中错误的处理
预测分析中错误的处理
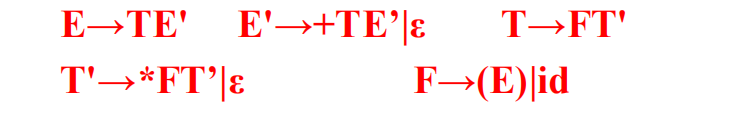



 算符优先文法
算符优先文法
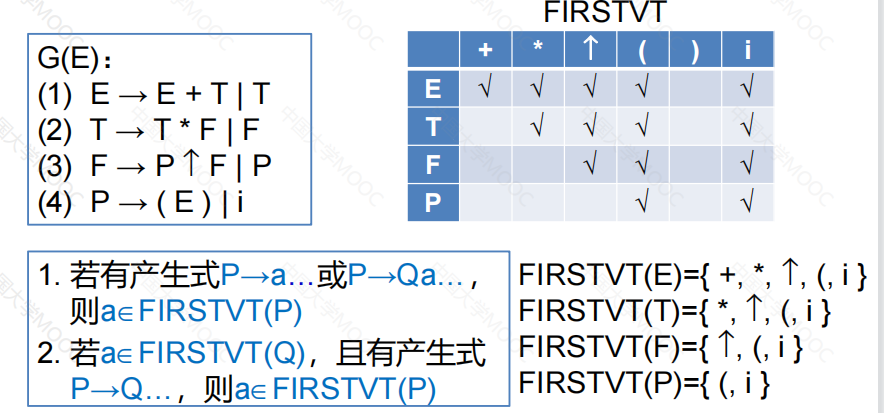
①构造FIRSTVT集合
例:
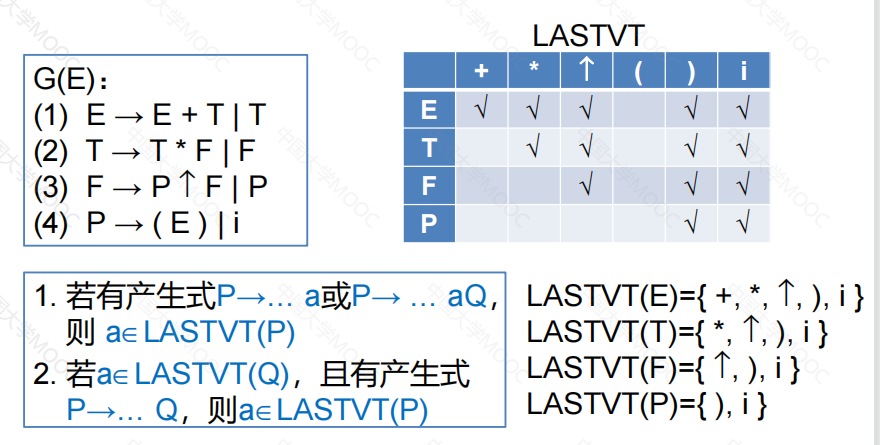
②构造LASTVT集合
例:
③根据FIRSTVT和LASTVT集合构造优先关系表
算法: 例:
例:

简单来说,就是对于一个终结符,其算符优先级小于其右边第一个终结符的FIRSTVT集合中的算符,而其左边第一个终结符的LASTVT集合中的算符的优先级都大于它
在优先关系表中,竖着的一列代表左侧的字符,横着的一行代表右侧的字符
④进行算符优先分析:
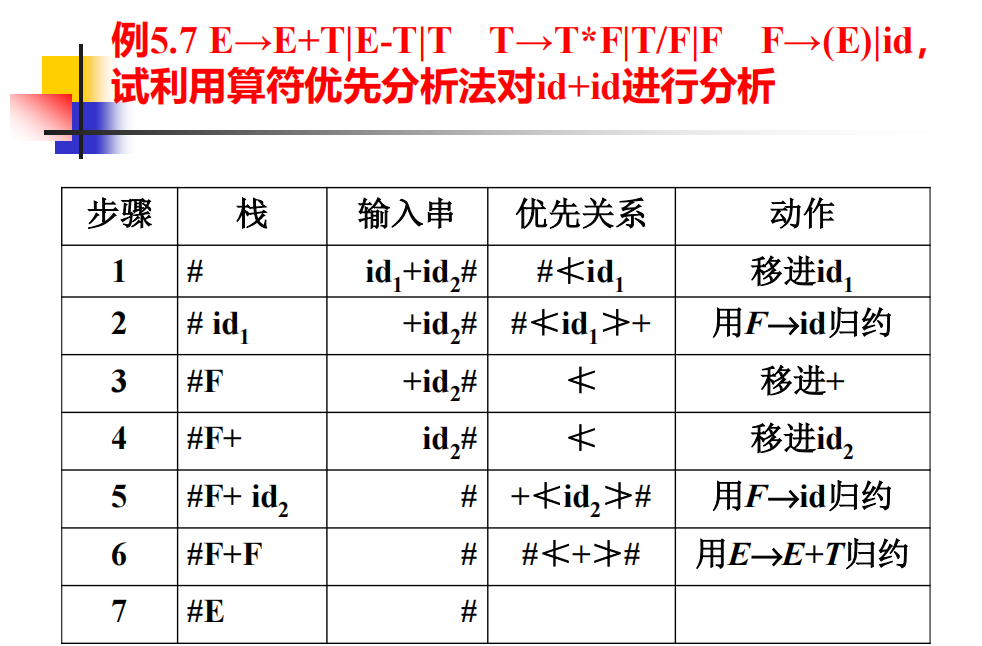
栈中顶部的终结符与输入串的当前符号比较(不用管栈中的非终结符),如果当前符号的优先级高,则将当前符号压入栈中,如果栈顶终结符的优先级高,则对栈中内容进行一次规约,如图所示
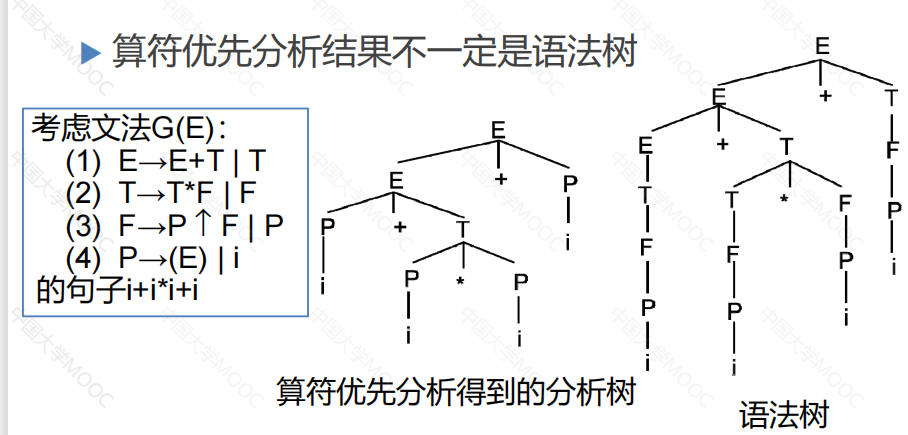
原因是算符优先分析省略了中间过程中单个非终结符到单个非终结符的规约
基于属性文法的处理方法
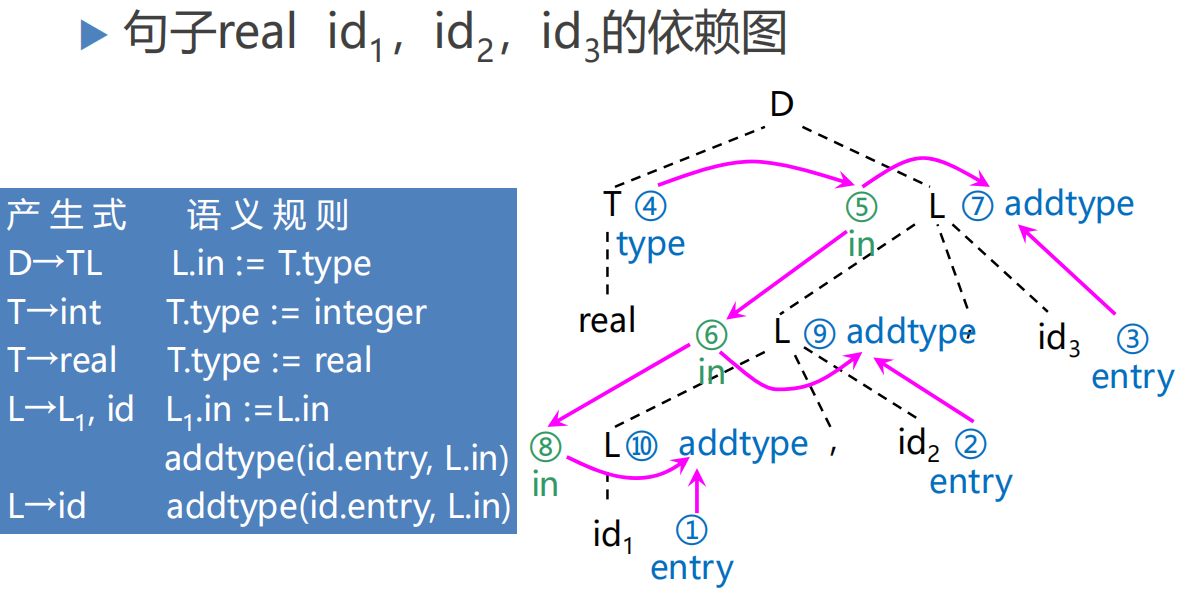
1.依赖图
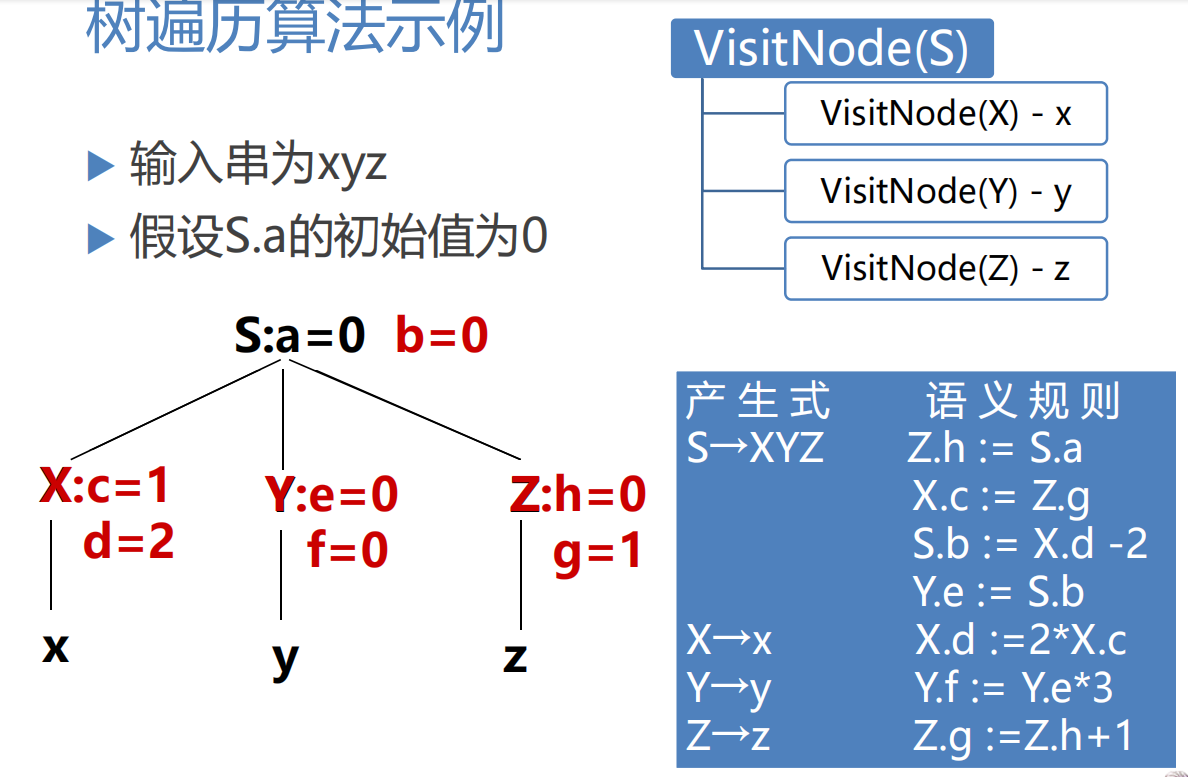
2.树遍历
3.一遍扫描
(建立抽象语法树AST)
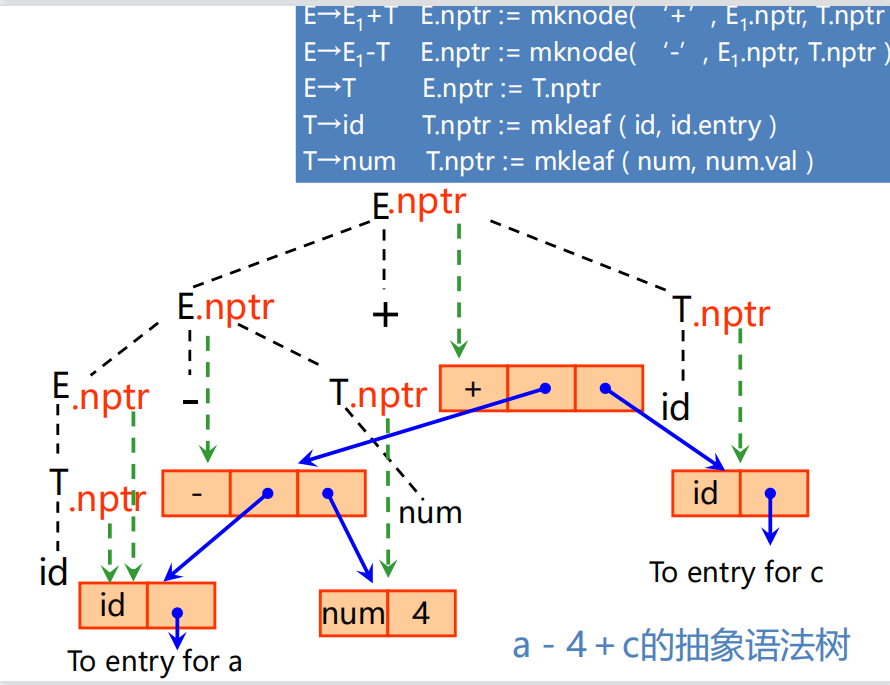

建立翻译模式
翻译模式示例:
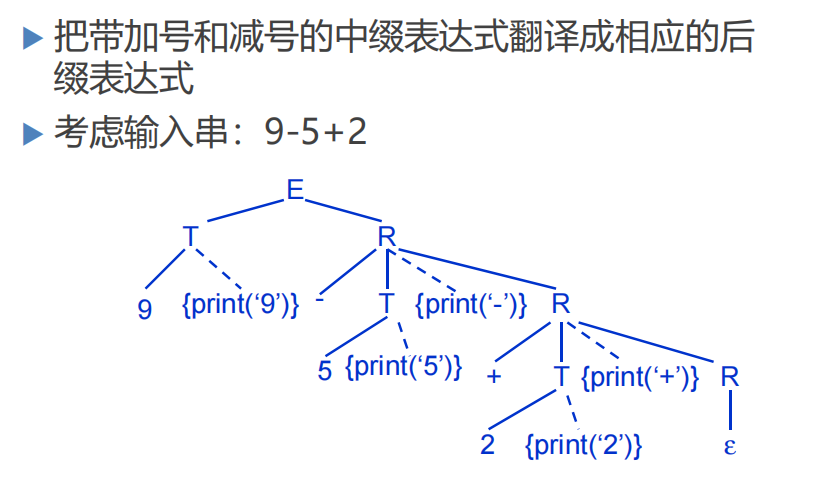
建立翻译模式的方法:
也就是说,不将语义规则插入到产生式中
消除翻译模式中的左递归

示例: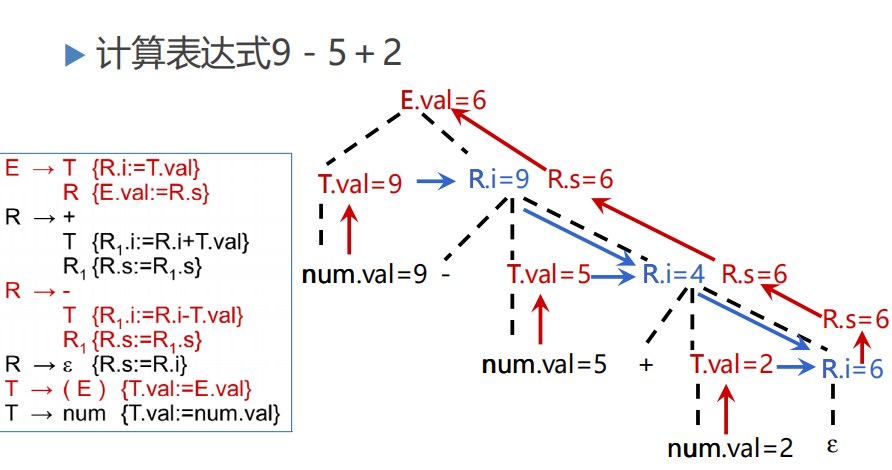 重点在于何处理消除左递归后的翻译模式,
重点在于何处理消除左递归后的翻译模式,
基本方法如下:
原先的文法推导的结果是XY.......Y,引入R来消除左递归,本质上就是用R的迭代来生成若干个Y;
消除左递归后构造抽象语法树:


















 488
488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











