






分库分表方式:垂直分表、垂直分库、水平分库和水平分表
垂直分表:可以把一个宽表的字段按访问频次、是否是大字段的原则拆分为多个表,这样既能使业务清晰,还能提升部分性能。拆分后,尽量从业务角度避免联查,否则性能方面将得不偿失【同一库中将单张表按照字段拆分成若干表,拆分后表的记录行数不变】。
垂直分库:可以把多个表按业务耦合松紧归类,分别存放在不同的库,这些库可以分布在不同服务器,从而使访问压力被多服务器负载,大大提升性能,同时能提高整体架构的业务清晰度,不同的业务库可根据自身情况定制优化方案。但是它需要解决跨库带来的所有复杂问题。 【根据业务将表分组形成不同的库,这些库又可以部署到不同的数据库中-专库专用】
水平分表:可以把一个表的数据(按数据行)分到多个同一个数据库的多张表中,每个表只有这个表的部分数据,这样做能小幅提升性能,它仅仅作为水平分库的一个补充优化。【同一数据库中将大表拆分成若干小表,每张表的结构一致,但保存的数据不同】
水平分库:可以把表的数据(按数据行)分 到多个不同的库,每个库只有这个表的部分数据,这些库可以分布在不同服务器,从而使访问压力被多服务器负载,大大提升性能。它不仅需要解决跨库带来的所有复杂问题,还要解决数据路由的问题(数据路由问题后边介绍)。
最佳实践:
一般来说,在系统设计阶段就应该根据业务耦合松紧来确定垂直分库,垂直分表方案。当然在数据量及访问压力不是特别大的情况,首先考虑缓存、读写分离、索引技术等方案。若数据量极大,且持续增长,再考虑水平分库水平分表方案。
总之,基于开发和维护成本比考虑,非必须,不要对数据库做分库分表处理!
Sharding-JDBC执行原理
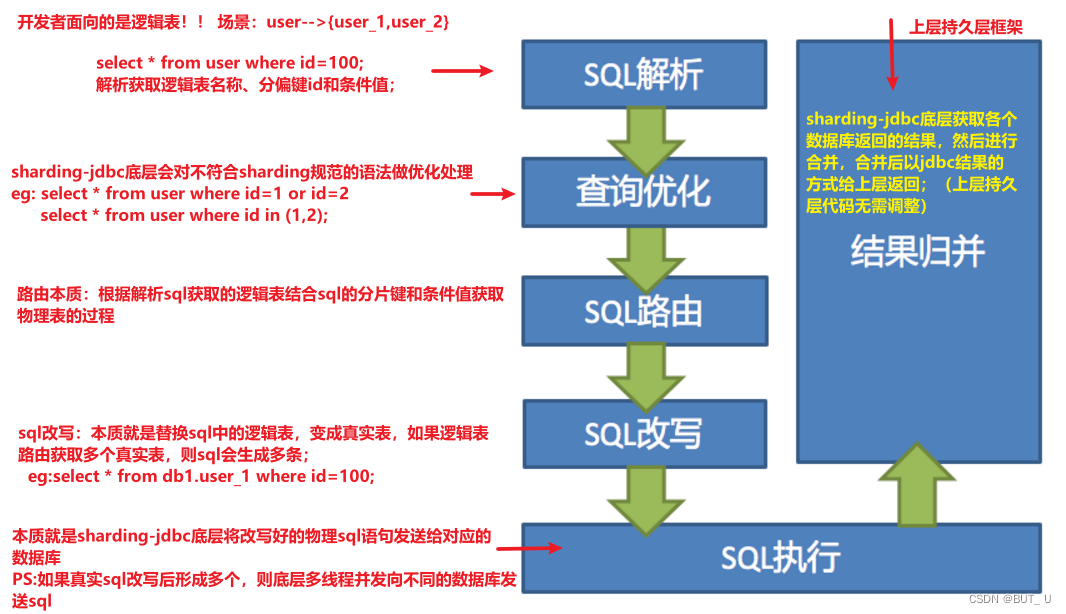
sharding-jdbc分片方式介绍
inline模式
-
使用最简单,开发成本比较低;
-
只能使用单个字段作为分片键;
-
基于行表达式定义分片规则;
通过groovy表达式来表示分库分表的策略; db0 ├── t_order0 └── t_order1 db1 ├── t_order0 └── t_order1 表达式:db${0..1}.t_order${0..1} t_order${orderId % 2}standard标准分片模式
-
用户可通过代码自定义复杂的分片策略;
-
同样只能使用单个字段作为分片键;
Standard模式实现分库分表
















 645
645











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









