







实验6 数据挖掘分类入门实验
1. 实验数据
该数据集包含1439条训练数据,存放于“data-train.csv”文件;另有160条未知标签的测试数据,保存在“data-test.csv”文件中。
训练集数据共含与某种酒品质相关的11个(匿名)特征属性(f1~f11)和1个目标属性(target),具体字段如下: #data-train.csv
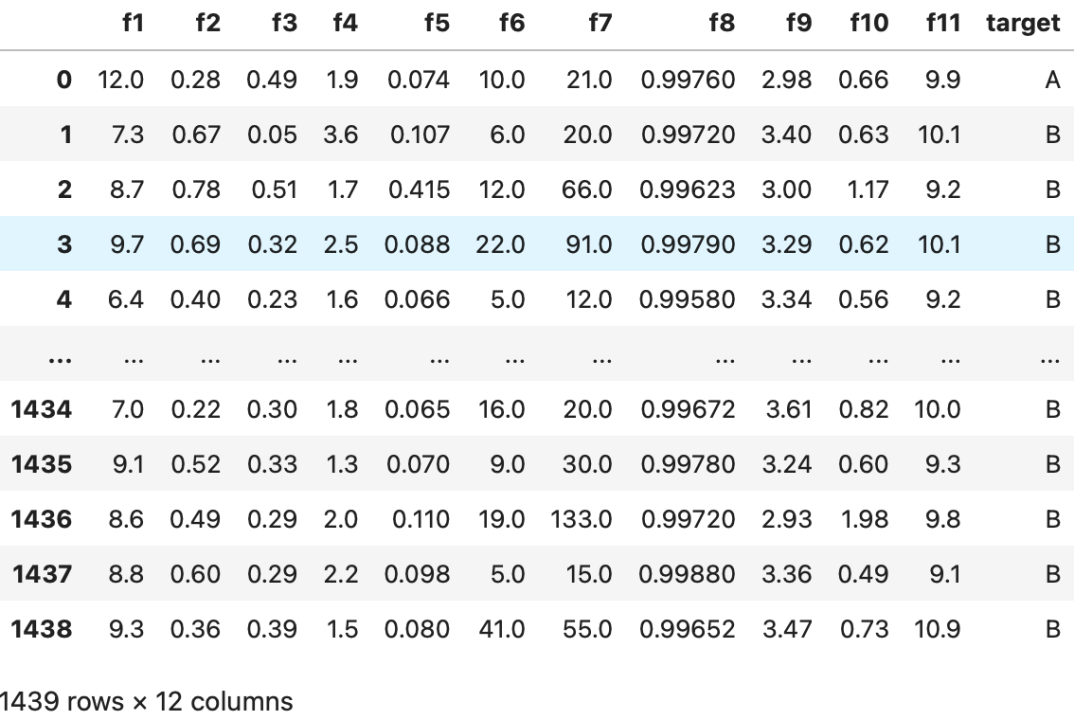
测试数据的具体字段如下: #data-test.csv
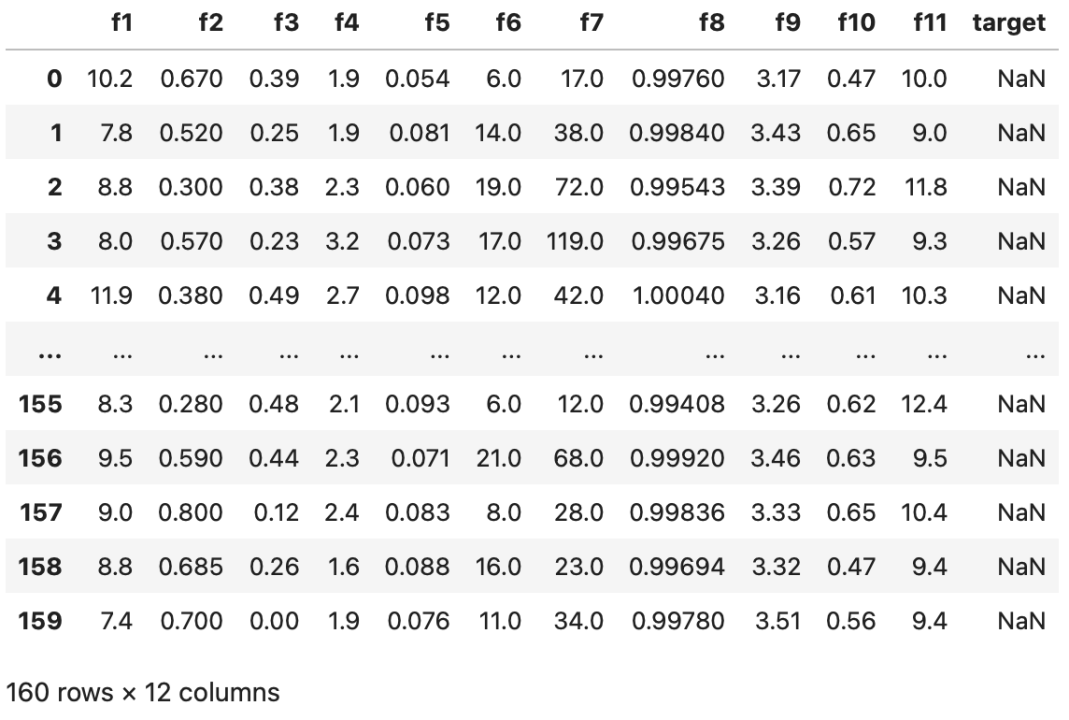
其中目标属性,即target字段未知,待建模预测。
2. 实验目的
本次实验的目的是利用机器学习分类算法,基于训练集构建分类器模型,进而预测测试集中全体样本的分类结果,即测试样本的target 值:A、B 、C(品质:A 优于 B,B优于C)。
3. 实验要求
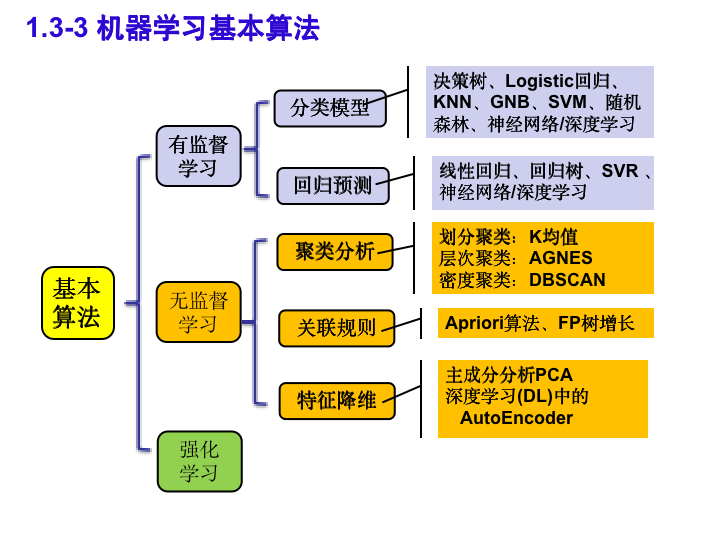
(1) 具体的机器学习算法不限,以预测效果最佳为目标。#感觉和鸢尾花差不多 可以用DT
(2) 将预测结果保存在名为“predictions.txt”的文本文件中,内容为160行, 每一行只有A 或者B或者C,代表你的算法对测试数据的预测结果。预测数据顺序须与测试集“data-test.csv”中的样本顺序保持一致。
(3) 将结果文件“predictions.txt”以附件形式提交至学习通。
另外请注意:只需提交结果文件,无需提交本次实验报告文件。
(4) 本次实验成绩评定采用竞赛机制,即计算每位同学预测结果的micro F1 score,然后由高到低进行排序评定相应的实验成绩。
分析:
#data-train.csv
分类任务的目标是将输入数据分配到具有不同属性的一组预定义类别中。
本次的任务是一个分类任务,其基本内容是学习11个匿名属性与target的关系,并且利用匿名属性预测测试集的标签。本任务和西瓜书中的“色泽青绿、响声清脆”任务很像,还有鸢尾花数据。
赛题基本过程:读取train.csv,留出测试集和验证集,构建模型学习属性和标签之前的关系,在验证集上计算F1 Score,调整模型,对test.csv应用模型、逐个输出标签、存储结果,提交predictions.txt
![]()
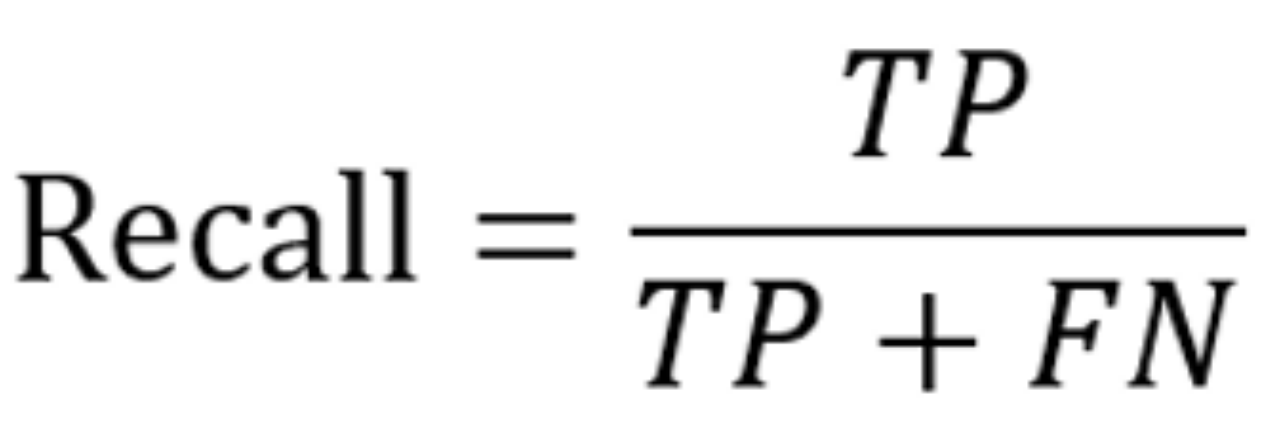
![]()
分类任务的思路:
① 读取数据,看看有没有Nan这些脏数据,有的话需要处理一下
② 针对标签进行清洗,利用person相关系数/Aprior频繁项集,剔除不显著的属性
此外可以利用聚类分析(K-means)、特征降维等方法找出具有显著性的属性
③ 构建分类器。可能的思路包括:
(1)基于贝叶斯定理的分类:先验概率的计算
(2)基于决策树(ID3 Cart C4.5)的分类,以及随机森林:信息纯度的指标选取
(3)Logistic回归:虽然叫回归实际上可以做分类任务
(4)KNN(K近邻):基于Len欧氏距离、Mht距离、Cheby切比雪夫等距离的计算
(5)神经网络的构建。因为数据量不太够可以试试小样本和元学习,深度学习可能要再研究
(6)集成/迁移/模型融合。先把上面的都测一遍,再选出几个比较好的模型一起用。
④ F1 Score计算。可以参考同类赛题看看模型的训练效果怎么样。
使用的模型 :(还没写,放个)
// `\其他人能做得到吗?/`相关赛题收集:
基础类:
零基础入门数据挖掘 - 二手车交易价格预测_学习赛_天池大赛-阿里云天池
零基础入门数据挖掘-心跳信号分类预测_学习赛_天池大赛-阿里云天池
零基础入门NLP - 新闻文本分类_学习赛_天池大赛-阿里云天池
中文NLP地址要素解析_学习赛_赛题与数据_天池大赛-阿里云天池
零基础入门推荐系统 - 新闻推荐_学习赛_天池大赛-阿里云天池
AI安全类:
WEBSHELL文本检测学习赛_学习赛_天池大赛-阿里云天池
【长期赛】安全AI挑战者计划第一期 - 人脸识别对抗_学习赛_天池大赛-阿里云天池
【长期赛】安全AI挑战者计划第二期 - ImageNet图像分类对抗攻击_学习赛_天池大赛-阿里云天池
【长期赛】安全AI挑战者计划第三期 - 文本分类对抗攻击_学习赛_天池大赛-阿里云天池
【长期赛】安全AI挑战者计划第五期:伪造图像的对抗攻击_学习赛_天池大赛-阿里云天池
学术类:
零基础入门数据分析-学术前沿趋势分析_学习赛_天池大赛-阿里云天池
Chinese Scientific Literature Dataset 中文科学文献数据集(CSL)_数据集-阿里云天池
金融类:
Historical Income Tax Rates & Brackets | Kaggle
【教学赛】金融数据分析赛题1:银行客户认购产品预测_学习赛_天池大赛-阿里云天池
【教学赛】金融数据分析赛题2:保险反欺诈预测_学习赛_天池大赛-阿里云天池
【教学赛】金融数据分析赛题3:证券数据可视化分析_学习赛_天池大赛-阿里云天池
零基础入门金融风控-贷款违约预测_学习赛_天池大赛-阿里云天池
数据挖掘 :
【教学赛】数据分析达人赛1:用户情感可视化分析_学习赛_天池大赛-阿里云天池
【教学赛】数据分析达人赛2:产品关联分析_学习赛_天池大赛-阿里云天池
【教学赛】数据分析达人赛3:汽车产品聚类分析_学习赛_天池大赛-阿里云天池
司法类:Search | Kaggle
California Crime and Law Enforcement | Kaggle
Law School Admissions Bar Passage | Kaggle
Police deaths in USA from 1791 to 2022 | Kaggle
Hong Kong - National Security Law 2020 | Kaggle
US Supreme Court Cases, 1946-2016 | Kaggle
Global Terrorism Database | Kaggle
Indian Prison Statistics | Kaggle
电子合同管理系统_电子签章软件_智能合同审查-小包公法律AI平台
SPSSAU_相关|回归分析_因子|方差分析_SPSS下载-在线SPSS分析软件
Stopword Lists for 19 Languages 19种语言的停用词列表_数据集-阿里云天池
Crimes Committed in France 法国犯下的罪行_数据集-阿里云天池
https://www.kaggle.com/datasets/fbi-us/california-crime
# LAIC2022——小样本多任务学习 README.md
针对本次任务,我们会提供包含案件情节描述的陈述文本,选手需要识别出文本中的关键信息实体,并按照规定格式返回结果。
数据需要doccano.py文件经过转换才能用于训练。
## 1. 案件要素
案件要素中包含8个二分类子任务,子任务数据格式为json格式,字典包含字段为:
- ``id``:文本id。
- ``data``:文本内容,文书中事实描述部分。
- ``label``:是否是当前案件要素,是/否。
- ``task``:任务类型,CLS。
## 2. 刑档 CLS
## 3. 命名实体识别 NER。
在模型评测阶段,你需要将所有的代码压缩为一个必须为 `zip`的文件进行提交,该 `zip`文件将通过**内部** `main.py`文件将包含的程序包含在内作为运行的。在评测阶段会使用如下命令来运行你的程序:
```python
python main.py \
--test_file "default" \
--output_file "default" \
```
## 评测脚本 在 `evaluation` 文件夹中提供了评分的代码和提交文件样例,以供参考
## 模型 `baseline`目录。
## 动态模型运行环境 参考baseline文件夹下的requirements.txt















 1030
1030











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









