 空洞卷积:原理、实现与应用——深度学习中的创新解决方案,
空洞卷积:原理、实现与应用——深度学习中的创新解决方案,





目录
1. 引言与背景
随着深度学习技术的飞速发展,卷积神经网络(Convolutional Neural Networks, CNNs)已成为处理图像、语音等复杂数据的关键工具。然而,在面对诸如语义分割、目标检测等任务时,传统的卷积操作往往受限于有限的感受野和对空间分辨率的损失。为应对这些挑战,空洞卷积(Atrous Convolution),又称扩张卷积或带孔卷积,作为一种创新的卷积机制应运而生。本文旨在全面介绍空洞卷积的理论基础、算法原理、实现方法,以及其在实际应用中的优缺点,并通过具体案例和与其他算法的对比,展现其在机器学习领域的价值与潜力。
2. 空洞卷积定理
空洞卷积的核心思想是通过引入“空洞”(dilation)参数,调整卷积核中元素之间的间距,从而在不增加参数数量的前提下有效扩大感受野,同时保持输出特征图的空间分辨率。其数学表述如下:
对于一个输入信号 I 和空洞卷积核 K,其空洞率为 d(通常为整数),空洞卷积的计算公式为:
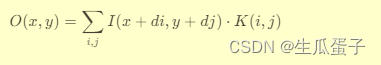
其中,(x,y) 是输出特征图上的位置,(i,j) 是卷积核内的位置。空洞率 d 的引入,使得卷积核在遍历输入时以固定步长进行跳跃式采样,有效地增大了感受野,同时避免了池化层或下采样带来的分辨率损失。
3. 算法原理
空洞卷积的工作原理可以概括为以下三点:
(1)扩大感受野:通过设置非零的空洞率,卷积核能够在不增加大小的情况下覆盖更广的输入区域,有助于捕捉到更大尺度的特征,这对于识别大范围依赖关系的任务(如语义分割)至关重要。
(2)保持空间分辨率:传统卷积在增加感受野的同时会降低输出特征图的分辨率,而空洞卷积通过跳过某些像素进行卷积,保持了原始输入的空间信息,有利于精确边界定位和细节保留。
(3)参数效率:空洞卷积并未增加额外的参数量,仅通过改变卷积核的采样方式提升了模型的表达能力,这在资源有限的场景下具有显著优势。
4. 算法实现
在主流深度学习框架(如 TensorFlow、PyTorch)中,空洞卷积已作为内置模块提供。用户只需指定常规卷积层的 dilation 参数即可启用空洞卷积。
当然可以。以下是一个使用 Python 和 PyTorch 实现空
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









