






概念
来源
ClickHouse背后的研发团队是俄罗斯的Yandex公司。Yandex是一家俄罗斯的搜索引擎公司,类似于我国的百度,Yandex于2011年在纳斯达克上市。
架构演变

特点
Clickhouse使用的是列式存储
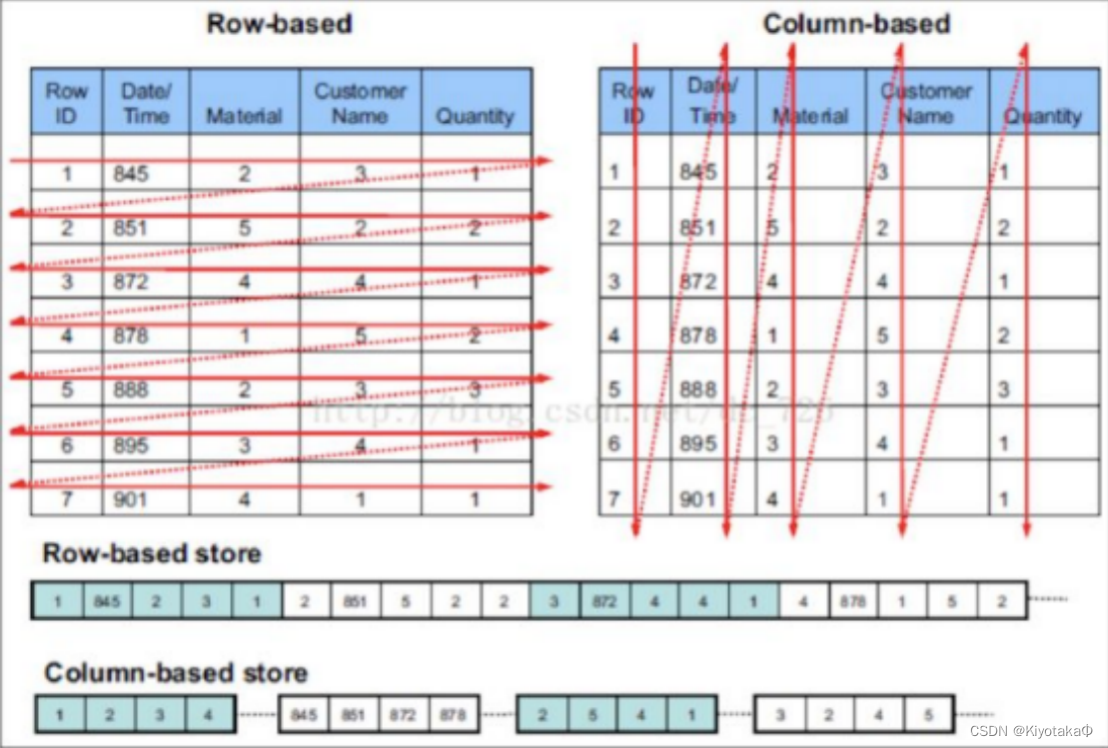
图中第二个使用的列式存储在提取某一部分的全部数据时,可以直接连续的提出,不需要像行式存储要遍历整个数据库,在数据分析时就非常方便
优点
- 在某些场景例如需要读大量行但是少数几个列,所有行的数据都存储在一个block中,不参与计算的列在IO时也要全部读出,读取操作被严重放大,而列式存储只需读出参与行即可
- 同一列中的数据属于同一类型,压缩效果显著
- 更高的压缩比意味着更小的data size
- 自由的压缩算法选择,可以选用不同算法
- 高压缩比,能存储更多数据
原理
列式存储
上文已经详细介绍
顺序存储
- ClickHouse支持在建表时,指定将数据按照某些列进行order by。
- 排序后,保证了相同sort key的数据在磁盘上连续存储,且有序摆放。在进行等值、范围查询时,where条件命中的数据都紧密存储在一个或若干个连续的Block中,而不是分散的存储在任意多个Block, 大幅减少需要IO的block数量。
- 另外,连续IO也能够充分内存缓存,相同内存可以缓存更多有效数据量。
索引
主键索引
clickhouse支持主键索引,将每一列按照index granularity(默认8219行)进行划分,每一个index granularity的开头第一行成为一个mark行,主键索引该mark行对应的primary key的值。
primary key采用二分法查找,避免了全表扫描从而加速查询。
稀疏索引
ClickHouse支持对任意列创建任意数量的稀疏索引,他本质上是对一个完整的index granularity进行统计信息,不会记录具体每一行在文件中的位置。
数据分片
clickhouse支持单机也支持分布式集群模式,在分布式集群模式下clickhouse会把数据分为多个分片,并且分布到不同节点上。
- random随机分片:数据会被随机分配到集群的某个节点上
- constant固定分片:写入数据会分法到固定的一个节点上
- column value分片:按照某一列的值进行hash分片
- 自定义表达式分片:指定合法表达式,根据表达式计算后进行hash分片
数据分片可以充分利用集群的优势,快速返回搜索结果
数据分片是通过分布式表实现的,集群的每个节点都可以称为shard(分片)
分布式表
分布式表也是在clickhouse中建立的一个表,但是这个表不存储数据,只作为一层代理,在集群中进行分发、写入、查询、路由等操作
创建分布式表的时候,需要指定分片规则,将数据写入到不同分片
- rand():随机写入
- userid:根据userid的余数划分
- intHash64(userid) 按照userid的hash值进行划分
PARTITION BY
ClickHouse支持PARTITION BY子句,在建表时可以指定按照任意合法表达式进行数据分区操作,比如通过toYYYYMM()将数据按月进行分区、toMonday()将数据按照最近一周的周一进行分区、对Enum类型的列直接每种取值作为一个分区等。
在partition key上进行分区裁剪,可以有效地跳过无用的数据文件,缩小查询范围,只查询必要的数据。
数据TTL
TTL(time to live):表示数据存在的时间
出于成本和效率考虑,有的项目只会保留几个月的数据,通过TTL使clickhouse能够管理数据生命周期
ClickHouse支持几种不同粒度的TTL:
- 列级别TTL:当一列中的部分数据过期,会被替换为默认值;全列的数据都过期,会删除该列
- 表级别TTL:当某一行过期后,会删除该行
表引擎
介绍
与mysql类似,表引擎决定其特征,clickhouse不同引擎之间区别很大,分为六类20多种
- MergeTree系列引擎
- 外部存储类型
- 文件类型
- 内存类型
- 接口类型
- 其它类型
其中MergeTree系列引擎性能强大、使用场景广,也只有MergeTree系列引擎才支持主键索引、数据分区、数据副本和数据采样这些特性
MergeTree
建表方式
SQL
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
[PARTITION BY expr]
[ORDER BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]- PARTITION BY:分区键,不声明分区键,则会默认生成一个名为all的分区
- ORDER BY:必填,排序键,默认情况下主键与排序键相同
- PRIMARY KEY:会根据主键字段生成一级索引,用于加速查询,可不声明,默认是ORDER BY定义的字段
- SAMPLE BY:抽样表达式,声明数据以何种标准进行采样,如果使用此配置,必须在主键的配置中也声明同样的表达式。 例如:ORDER BY (CounterID,intHash32(UserID)) SAMPLE BY intHash32(UserID)
- SETTINGS
• index_granularity:索引粒度,默认8192,也就每隔8192行才生成一条索引
• enable_mixed_granularity_parts:是否开启自适应索引间隔功能,默认开启
• index_granularity_bytes:每一批次写入的数据量大小,默认10M(10*1024*1024)
例:
SQL语句
CREATE TABLE test.part_v1
(
`ID` String,
`URL` String,
`age` UInt8 DEFAULT 0,
`EventTime` Date
)
ENGINE = MergeTree()
PARTITION BY toYYYYMMDD(EventTime)
ORDER BY ID
SETTINGS index_granularity = 8192抽样查询
SELECT avg(CountID) FROM hits_v1 SAMPLE 0.1;文件类型
.bin文件
.bin是实际存储数据的文件,每列一个.bin文件
checksums.txt
校验文件,二进制文件,保存了余下各类文件(primary.idx、count.txt等)的size大小和size哈希值,用于快速校验文件的完整性和正确性
columns.txt
列信息文件,明文存储格式,保存本数据分区下的列字段信息
count.txt
计数文件,使用明文存储,记录当前数据分区目录下数据的总行数
primary.idx
一级索引文件,二进制文件,用于存放稀疏索引,有助于系统提高查询速度
列.bin
数据文件,默认使用LZ4压缩格式存储,存放某一列数据,MergeTree采用列式存储,所以每一个列字段都拥有独立的.bin数据文件,并以列字段名称命名
列.mrk2
列字段标记文件,二进制文件,存储.bin文件中数据的偏移量信息
partition.data与minmax_[cloume].idx
两者都是索引文件,二进制文件,前者存储当前分区下分区表达式最终生成的值,即分区字段值
后者用于存储当前分区字段对应的原始数值的最大和最小值
Clickhouse单机版
安装
安装前准备
1.打开文件数限制
vim /etc/security/limits.conf 文件末尾加入这四行
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072编辑第二个文件
vim /etc/security/limits.d/20-nproc.conf文件末尾加入这四行
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072重启服务器后验证
ulimit -n
ulimit -a2.取消SELINUX
vim /etc/selinux/config修改文件中的selinux
注:ARM架构最好不要使用disable,可能出现问题
SELINUX=permissive3.关闭防火墙
systemctl status firewalld.service
systemctl stop firewalld.service
systemctl disable firewalld.service4.安装依赖
yum install -y libtool
yum install -y *unixODBC*本体安装
更新软件仓库
sudo yum install -y yum-utils
sudo yum-config-manager --add-repo https://packages.clickhouse.com/rpm/stable/下载三个组件
yum install clickhouse-common-static-22.6.3.35 -y --nogpgcheck
yum install clickhouse-client-22.6.3.35 -y --nogpgcheck
yum install clickhouse-server-22.6.3.35 -y --nogpgcheck启动服务
方式1:服务器启动方式
systemctl start clickhouse-server方式2:前台启动
cd /var/lib/
chown -R root:root clickhouse
clickhouse-server --config-file=/etc/clickhouse-server/config.xml方式3:后台启动(输出到日志中)
cd /var/lib/
chown -R root:root clickhouse
clickhouse-server --config-file=/etc/clickhouse-server/config.xml 1>~/logs/clickhouse_std.log 2>~/logs/clickhouse_err.log &启动成功后检查一下
ps -aux | grep clickhouse
netstat -nltp | grep clickhouse如果报权限错误,修改安装目录的权限,默认使用 clickhouse 用户
cd /var/lib/
chown -R root:root clickhouseroot用户启动:把/var/lib/clickhouse 改成:root:root
clickhouse用户启动:运行chmod -u /bin/bash clickhouse后再切换到clickhouse用户使用
启动客户端
clickhouse-client
#或
clickhouse-client --host=localhost --port=9000 -m进入后输入指令show databases试一下
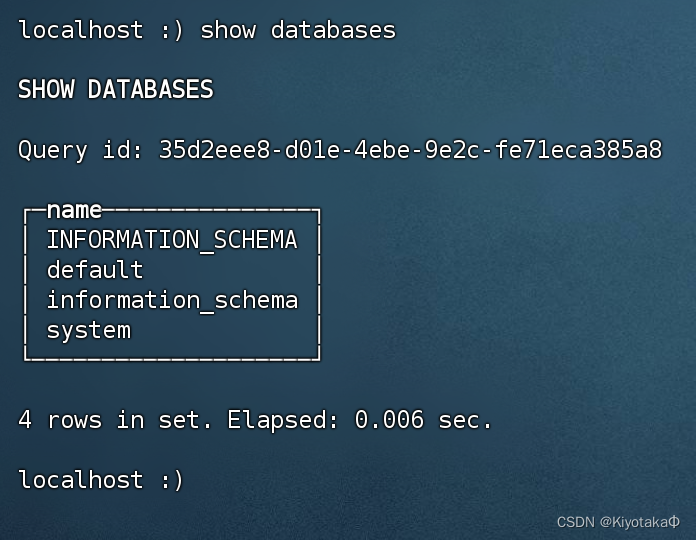
基本使用
创建库
create database test切换库
use test创建表
CREATE TABLE t_stu
(
`id` UInt8,
`name` String,
`age` UInt8,
`birthday` Date
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(birthday)
PRIMARY KEY id
ORDER BY id注:文件类型、引擎类型等都必须区分大小写
查看表
show tables插入数据
insert into t_stu
(id,age,name,birthday)
values
(1001,20,'张三','2000-01-01'),
(1002,22,'李四','2000-01-03'),
(1003,26,'王五','2000-01-02'),
(1004,28,'赵六','2000-01-06');
进入文件夹查看文件结构
cd /var/lib/clickhouse/data
ll test/t_stu/
文件名称结构
分区名称构成 = 分区ID _ 最小数据块 _ 编号最大数据块编号 _ 合并层级
200001 _ 1 _ 1 _ 0
数据合并
在ClickHouse中,MergeTree表支持数据合并操作,当表的分区达到一定数量或者手动触发合并操作时,ClickHouse会自动执行数据合并。如果你想要手动触发合并,可以使用OPTIMIZE查询。这里是一个示例:
OPTIMIZE TABLE database_name.table_name FINAL;基于zookeeper的clickhouse
在clickhouse23版本以前clickhouse没有自己的分布式协调服务,只能借助zookeeper实现集群
zookeeper
起源
最早起源于雅虎研究院的一个研究小组,目的在于解决很多大型系统基本都需要依赖一个类似的系统来进行分布式协调,于是雅虎的开发人员就试图开发一个通用的无单点问题的分布式协调框架
作用
zookeeper是一个集中的服务,用于维护配置信息、命名(服务注册和发现)、提供分布式同步以及提供组服务
应用场景
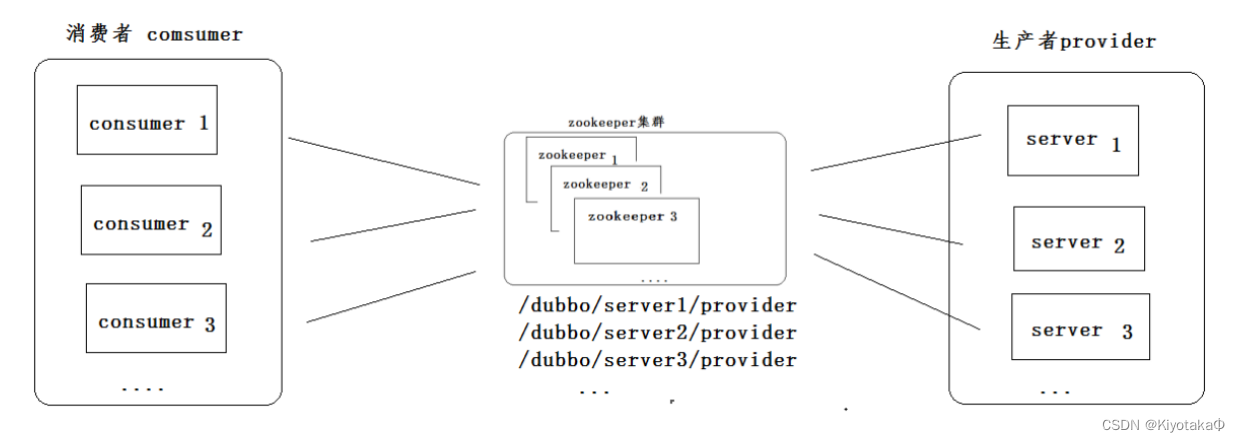
注册中心
通过使用命名服务,客户端应用能够根据指定名字来获取资源的实体、服务地址和提供者的信息等
- /provider:存放服务地址
- /consumer:存放消费地址
- /conf:存放配置信息限制
consumer通过监听provider节点的内容修改实现动态读取地址,只需要在provider中存放多个地址然后程序中通过代码实现随机调用即可
搭建clickhouse集群
安装zookeeper
1.配置java环境
将java1.8安装包存入/opt文件夹
运行本地安装
yum -y loaclinstall /opt/java1.8查看java安装是否成功
java -version2.解压文件
将安装包传入服务器,解压压缩包
tar -xvf zookeeper-3.4.13.tar.gz -C /usr/修改文件夹名称
mv /usr/zookeeper-3.4.13 usr/zookeeper
3.配置环境变量
vim /etc/profile在文件中添加这两行
export ZK_HOME=/usr/zookeeper #要与安装目录相同
export PATH=$PATH:$ZK_HOME/bin让文件生效
source /etc/profile4.使能配置文件
cp /usr/zookeeper/conf/zoo_sample.cfg /usr/zookeeper/conf/zoo.cfg这个zoo_sample.cfg是zk官方给的配置文件样例,只需要将名字修改为zoo.cfg就能生效
5.启动测试
此时zookeeper已经配置完成,启动试试
zkServer.sh start #启动
#连接
zkCli.sh
zkCli.sh -server 172.16.12.148:2181 检查服务是否正常
jps #java检测运行服务脚本
安装clickhouse集群
按照单机版安装好ck
ck文件配置
1.添加config.d中的节点
vim /etc/clickhouse-server/config.d/metrika.xml注:这个metrika.xml文件名字不是固定的,起什么名字都可以
编辑文件内容
<?xml version="1.0"?>
<yandex>
<!-- 添加集群相关配置 -->
<remote_servers>
<!-- 2个分片1个副本 -->
<test_cluster_shards>
<shard>
<!-- 是否只将数据写入其中一个副本,默认为false,表示写入所有副本,
在复制表的情况下可能会导致重复和不一致,所以这里要改为true,
clickhouse分布式表只管写入一个副本,其余同步表的事情交给复制表和zookeeper来进行 -->
<internal_replication>true</internal_replication>
<replica>
<host>172.16.12.148</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>172.16.12.149</host>
<port>9000</port>
</replica>
</shard>
</test_cluster_shards>
</remote_servers>
<!-- 复制标识的配置,也称为宏配置,这里唯一标识一个副本名称,
每个实例配置都是唯一的 -->
<macros>
<!-- 当前节点在在集群中的分片编号,需要在集群中唯一,3个节点分别为01,02,03 -->
<shard>01</shard>
<!-- 副本的唯一标识,需要在单个分片的多个副本中唯一,3个节点分别为cdh01,cdh02,cdh03 -->
<replica>ck148</replica>
</macros>
<zookeeper-servers>
<node index="1">
<host>172.16.12.148</host>
<port>2181</port>
</node>
</zookeeper-servers>
</yandex>2.配置/etc/clickhouse-server/config.xml
先删除config.xml中的<remote_servers>节点相关的配置
注:删除的remote的内容其实就是我们创建的metrika.xml的内容,只是分出来方便另外配置
可以看到从这里开始

这里结束

删除
:688,825d修改这行删掉注释,打开监听端口
<listen_host>0.0.0.0</listen_host>在文件底下添加这些内容
<zookeeper incl="zookeeper-servers" optional="true" />
<remote_servers incl="remote_servers" optional="true" />
<macros incl="macros" optional="true"/>
<include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from>
注:在</clickhouse>之前
至此主服务器的ck配置完成
在ck启动前,先启动zk,避免注册不上zk
配置第二台clickhouse
为了快速配置,我们直接远程复制我们编辑过的文件
scp config.xml 172.16.12.149:/etc/clickhouse-server/
scp metrika.xml 172.16.12.149:/etc/clickhouse-server/config.d/编辑metrika.xml文件
编辑macros部分即可
<macros>
<shard>02</shard>
<replica>ck149</replica>
</macros>启动服务
systemctl start clickhouse.server进入主机(装有zookeeper的服务器)
zkCli.sh通过命令ls /可以看到自动注册了clickhouse组
接下来就玩转一下集群吧
Clickhouse建库
基础语句
连接客户端
clickhouse-client --host=localhost --port=9000 -m创建数据库
CREATE DATABASE IF NOT EXISTS test01 ON CLUSTER test_cluster_shards;- 创建名称为test01的数据库。
- 如果指定了 ON CLUSTER cluster 子句,那么在指定集群 cluster 的所有服务器上创建test01 数据库
- ClickHouse 默认使用 Atomic 数据库引擎,即有默认值 ENGINE = Atomic
查看创建的数据库
show databases;
show create database test01;
#更详细的数据库列表信息
select * FROM system.databases;创建本地物理表
格式
CREATE TABLE [IF NOT EXISTS] [db.]table_name ON CLUSTER cluster
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = engine_name()
[PARTITION BY expr]
[ORDER BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...];项目描述
- db:指定数据库名称,如果当前语句没有包含‘db’,则默认使用当前选择的数据库为‘db’。
- cluster:指定集群名称,目前固定为default。ON CLUSTER 将在每一个节点上都创建一个本地表。
- type:该列数据类型,例如 UInt32。
- DEFAULT:该列缺省值。如果INSERT中不包含指定的列,那么将通过表达式计算它的默认值并填充它。
- MATERIALIZED:物化列表达式,表示该列不能被INSERT,是被计算出来的; 在INSERT语句中,不需要写入该列;在SELECT *查询语句结果集不包含该列。
- ALIAS :别名列。这样的列不会存储在表中。 它的值不能够通过INSERT写入,同时使用SELECT查询星号时,这些列也不会被用来替换星号。 但是它们可以用于SELECT中,在这种情况下,在查询分析中别名将被替换。
- 物化列与别名列的区别: 物化列是会保存数据,查询的时候不需要计算,而别名列不会保存数据,查询的时候需要计算,查询时候返回表达式的计算结果
以下选项与表引擎相关,只有MergeTree系列表引擎支持:
- PARTITION BY:指定分区键。通常按照日期分区,也可以用其他字段或字段表达式。
- ORDER BY:指定 排序键。可以是一组列的元组或任意的表达式。
- PRIMARY KEY: 指定主键,默认情况下主键跟排序键相同。因此,大部分情况下不需要再专门指定一个 PRIMARY KEY 子句。
- SAMPLE BY :抽样表达式,如果要用抽样表达式,主键中必须包含这个表达式。
- SETTINGS:影响 性能的额外参数。
- GRANULARITY :索引粒度参数。
示例
CREATE TABLE test01.table_001_local ON CLUSTER 'test_cluster_shards' (
ts DateTime,
tvid Int32,
area Int32,
count Int32
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/test01/table_001_local/{shard}', '{replica}')
PARTITION BY toYYYYMMDD(ts)
ORDER BY (ts,tvid,area);创建分布式表
作用:用于分发数据
格式
CREATE TABLE [db.]table_name ON CLUSTER default
AS db.local_table_name
ENGINE = Distributed(<cluster>, <database>, <shard table> [, sharding_key])- db:数据库名。
- local_table_name:对应的已经创建的本地表表名。
- shard table:同上,对应的已经创建的本地表表名。
- sharding_key:分片表达式。可以是一个字段,例如user_id(integer类型),通过对余数值进行取余分片;也可以是一个表达式,例如rand(),通过rand()函数返回值/shards总权重分片;为了分片更均匀,可以加上hash函数,如intHash64(user_id)
示例
CREATE TABLE test01.table_001 ON CLUSTER 'test_cluster_shards'
AS test01.table_001_local
ENGINE = Distributed(test_cluster_shards,test01,table_001_local,tvid);插入数据
insert into test01.table_001 values('2021-02-25 12:12:17',6,11010,100);
insert into test01.table_001 values('2021-02-25 12:12:17',7,11010,100); 在两台服务器上分别查询
可以看到查询到的数据是一样的
但是查询本地表时只看到本表的数据只有一条,这是由于分布式表分配算法
基于clickhouse-keeper的clickhouse
clickhouse23版本后clickhouse自带clickhousekeeper,代替zookeeper
安装clickhouse
按照之前搭建单机版过程相同,区别在于安装时的版本不同
yum install clickhouse-common-static-24.3.2.23 -y --nogpgcheck
yum install clickhouse-client-24.3.2.23 -y --nogpgcheck
yum install clickhouse-server-24.3.2.23 -y --nogpgcheck编辑hosts文件
vim /etc/hosts添加内容
192.168.48.201 ck201
192.168.48.202 ck202进入clickhouse-keeper文件夹
vim /etc/clickhouse-keeper/keeper-config.xml配置keeper文件
<listen_host>0.0.0.0</listen_host>
<keeper_server>
<tcp_port>9181</tcp_port>
<server_id>1</server_id>
<raft_configuration>
<server>
<id>1</id>
<hostname>ck201</hostname>
<port>9234</port>
</server>
<server>
<id>2</id>
<hostname>ck202</hostname>
<port>9234</port>
</server>
</raft_configuration>
</keeper_server>创建clickhouse-keeper路径
mkdir /var/lib/clickhouse-keeper修改路径权限
chown -R clickhouse:clickhouse /var/lib/clickhouse-keeper/启动keeper
systemctl start clickhouse-keeper检测keeper是否启动
yum install -y nc
echo ruok | nc localhost 9181; echo imok配置clickhouse-server
创建xml文件
vim /etc/clickhouse-server/config.d/clickhouse-keeper.xml编辑内容
<clickhouse>
<remote_servers>
<cluster_2S_1R>
<shard>
<replica>
<host>ck201</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<host>ck202</host>
<port>9000</port>
</replica>
</shard>
</cluster_2S_1R>
</remote_servers>
<zookeeper>
<node>
<host>ck201</host>
<port>9181</port>
</node>
<node>
<host>ck202</host>
<port>9181</port>
</node>
</zookeeper>
</clickhouse>修改config.xml文件
vim /etc/clickhouse-server/config.xml跟单机版一样,删掉remote-server部分,解开部分代码注释
<listen_host>0.0.0.0</listen_host>
<interserver_listen_host>::</interserver_listen_host>添加include_from配置
<include_from>/etc/clickhouse-server/config.d/clickhouse-keeper.xml</include_from>重启服务
systemctl restart clickhouse-server至此,基于clickhousekeeper的clickhouse配置完成















 1706
1706

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









