









pandas是Python的一个非常强大的数据分析库,它提供了高性能易用的数据类型,以及大量能使人们快速地处理数据的函数与方法。pandas的核心数据结构有两种,即一维数组的Series和二维表格型的DataFrame对象,DataFrame对象可以理解为一个由多个Series对象组成的字典,数据分析相关的所有事物都是围绕这两种对象进行的。
具体可以通过
pip install pandas
命令安装pandas扩展库
下面让我们走进pandas的练习吧!
需要注意的是,编写代码之前,首先需要导入相应的库模块,具体导入代码如下所示:
import pandas as pd
import numpy as np
同时,在创建Python脚本或软件包的时候,不要以pandas或numpy命名,否则系统会无法分辨到底要导入哪一个模块而报类似于下面的错误。

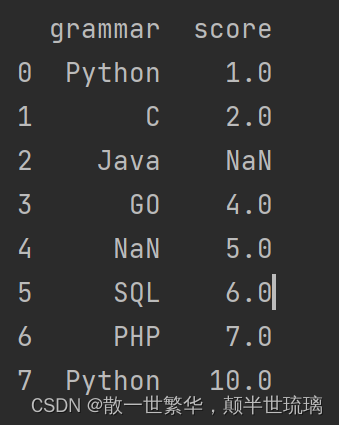
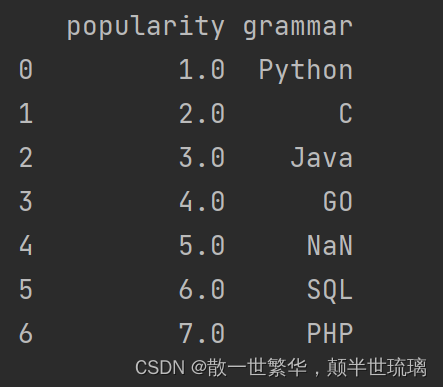
1.将下面的字典创建为DataFrame
data = {'grammar': ['Python', 'C', 'Java', 'GO', np.nan, 'SQL', 'PHP', 'Python'],
'score': [1.0, 2.0, np.nan, 4.0, 5.0, 6.0, 7.0, 10.0]}
df = pd.DataFrame(data)
print(df)
运行打印结果如下所示:
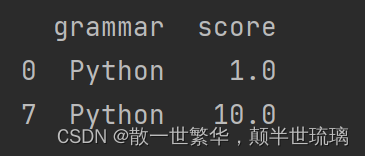
2.提取含有字符串Python的行
result = df[df['grammar'] == 'Python']
print(result)
运行结果如下所示:
3.输出df的所有列名
print(df.columns)
运行结果如下所示:

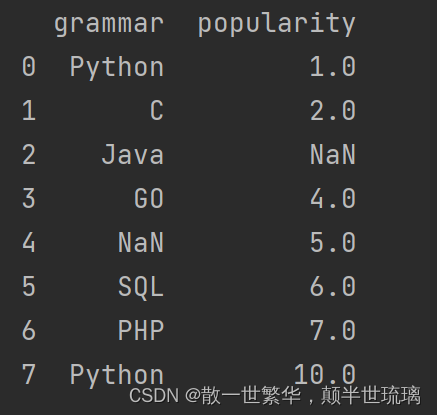
4.修改第二列列名为popularity
# inplace=True 表示在原数据修改
df.rename(columns={'score': 'popularity'}, inplace=True)
print(df)
运行结果如下所示:
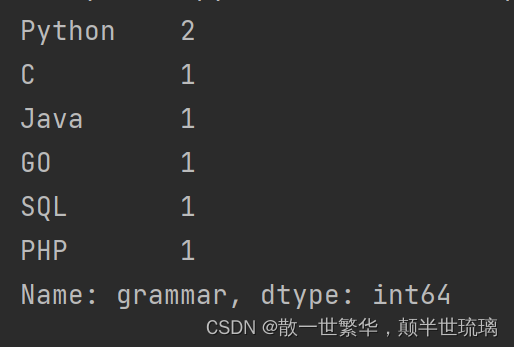
5.统计grammar列中每种编程语言出现的次数
print(df['grammar'].value_counts())
运行结果如下所示:
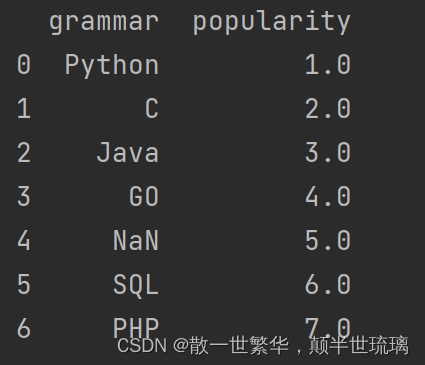
6.将空值用插值的方式填充
df['popularity'] = df['popularity'].fillna(df['popularity'].interpolate())
print(df)
运行结果如下所示:
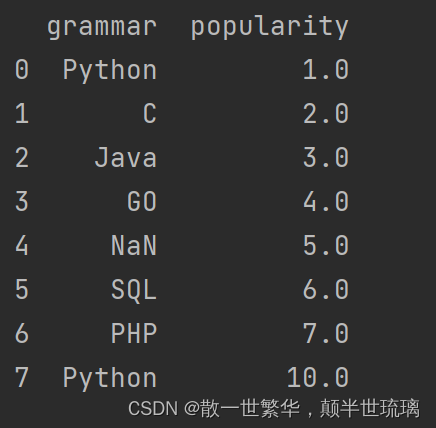
7.提取popularity列中值大于3的行
result = df[df['popularity'] > 3]
print(result)
运行结果如下所示:
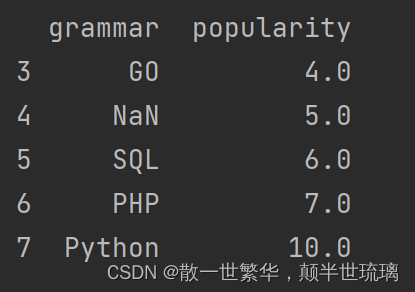
8.按照grammar列进行去除重复值
print(df.drop_duplicates('grammar', keep='first'))
注意,这里并未修改原数据,这里只是将删除重复grammar的DataFrame对象返回并输出。具体输出效果如下所示:
9.计算popularity列的平均值
print(df['popularity'].mean())
# 输出结果为 4.75
10.将grammar列转化为List
print(df['grammar'].tolist())
运行转换效果如下所示:

11将DataFrame保存为Excel
df.to_excel('test.xlsx')
运行结束后可以看见在Python文件的同级目录出现了一个test.xlsx文件。
12.查看数据行列数
print(df.shape)
# 输出为(8,2)
13.提取popularity列值大于3小于7的行
print(df[(df['popularity'] > 3) & (df['popularity'] < 7)])
运行结果如下所示:

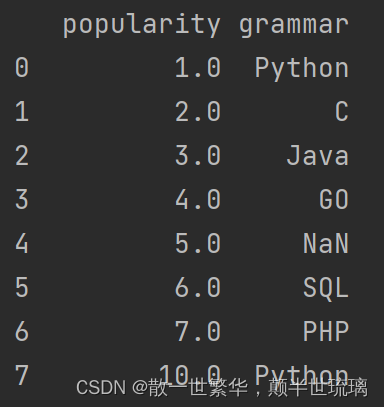
14.交换两列位置
cols = df.columns[[1,0]]
df = df[cols]
print(df)
运行结果如下所示:
15.提取popularity列最大值所在的行
print(df[df['popularity'] == df['popularity'].max()])
运行效果如下所示:
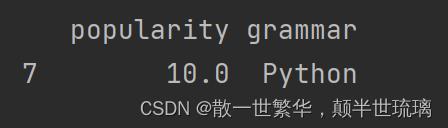
16.查看最后5行数据
print(df.tail())
运行效果如下所示:
查看开始5行的函数是head(),有兴趣的小伙伴可以尝试一下。
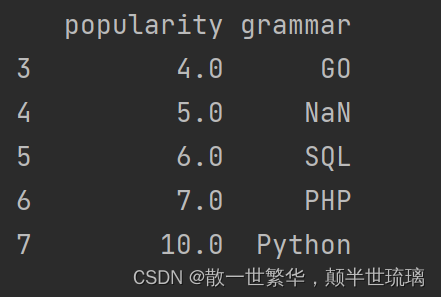
17.删除最后一行数据
#df.drop([len(df)-1],inplace=True)
#print(df)
df.drop(index=(len(df)-1),inplace=True)
print(df)
运行结果如下所示:
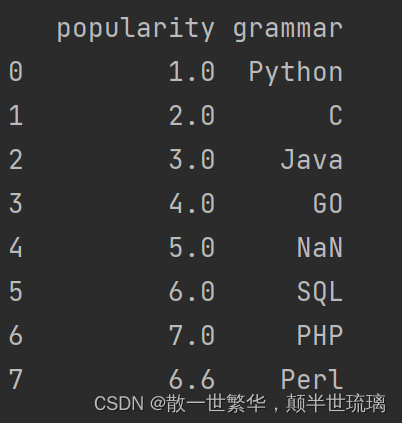
18.添加一行数据[‘Perl’,6.6]
row = {'grammar': 'Perl','popularity': 6.6}
df = df.append(row,ignore_index=True)
print(df)
运行结果如下所示:
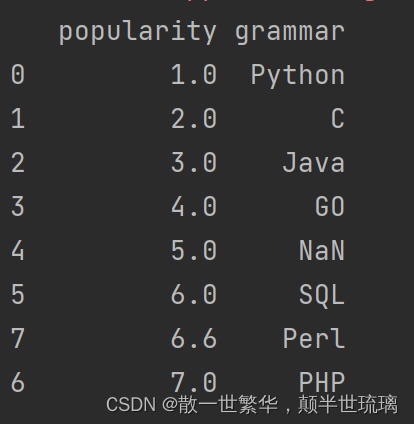
19.对数据按照"popularity"列值大小进行排序
df.sort_values('popularity', inplace=True, ascending=True)
print(df)
运行结果如下所示:
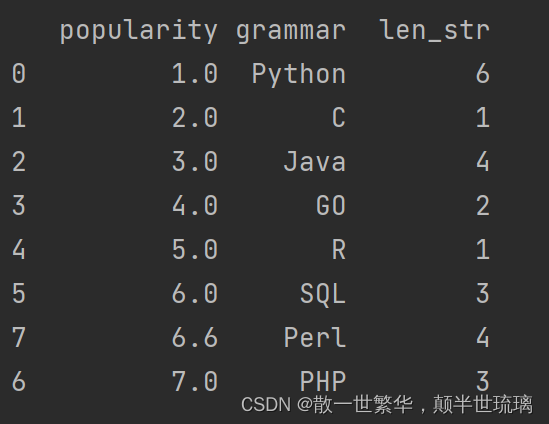
20.统计grammar列每个字符串的长度
df['grammar']=df['grammar'].fillna('R')
df['len_str']=df['grammar'].map(lambda x:len(x))
print(df)
运行结果如下所示:

















 9924
9924











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











