







正则表达式,又称规则表达式,(Regular Expression,在代码中常简写为regex、regexp或RE),是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符"),是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串,通常被用来检索、替换那些符合某个模式(规则)的文本。
1.正则表达式的作用
很多时候我们学习了正则表达式,但是却不知道它的作用,不知道学了正则表达式到底可以做什么?以至于学了忘,然后忘记了又继续学,做了很多无用功。今天,我就带大家来感受一下正则表达式的强大魅力吧!
现在假设你使用爬虫代码爬取了市场职位信息,具体内容如下所示:
Python3 高级开发工程师 上海互教教育科技有限公司上海-浦东新区2万/月02-18满员
测试开发工程师(C++/python) 上海墨鹍数码科技有限公司上海-浦东新区2.5万/每月02-18未满员
Python3 开发工程师 上海德拓信息技术股份有限公司上海-徐汇区1.3万/每月02-18剩余11人
测试开发工程师(Python) 赫里普(上海)信息科技有限公司上海-浦东新区1.1万/每月02-18剩余5人
Python高级开发工程师 上海行动教育科技股份有限公司上海-闵行区2.8万/月02-18剩余255人
python开发工程师 上海优似腾软件开发有限公司上海-浦东新区2.5万/每月02-18满员
现在,我们的需求是,我们要写一段程序,要从这些爬取到的文本中抓取所有职位的薪资,具体输出如下所示:
2
2.5
1.3
1.1
2.8
2.5
很明显,则要求是对字符串进行处理,如果使用我们的Python基础来实现,具体代码如下所示:
content = '''
Python3 高级开发工程师 上海互教教育科技有限公司上海-浦东新区2万/月02-18满员
测试开发工程师(C++/python) 上海墨鹍数码科技有限公司上海-浦东新区2.5万/每月02-18未满员
Python3 开发工程师 上海德拓信息技术股份有限公司上海-徐汇区1.3万/每月02-18剩余11人
测试开发工程师(Python) 赫里普(上海)信息科技有限公司上海-浦东新区1.1万/每月02-18剩余5人
Python高级开发工程师 上海行动教育科技股份有限公司上海-闵行区2.8万/月02-18剩余255人
python开发工程师 上海优似腾软件开发有限公司上海-浦东新区2.5万/每月02-18满员
'''
# 将文本按行存储到列表中
lines = content.splitlines()
for line in lines:
# 查找万/元的位置索引
pos2 = line.find('万/月')
if pos2 < 0:
#查找万/每月的位置索引
pos2 = line.find('万/每月')
if pos2 < 0:
continue
# 找到数字开始的位置pos1
idx = pos2-1
while line[idx].isdigit() or line[idx] == '.':
idx = idx-1
pos1 = idx + 1
print(line[pos1:pos2])
上述是我们使用Python基础,通过一段比较复杂的逻辑实现的提取并输出职位的薪资的程序。但是我想告诉你,如果使用正则表达式,程序代码的规模将大大减少,这里先展示一些如何使用正则来完成该需求,具体正则表达式的代码如下所示:
content = '''
Python3 高级开发工程师 上海互教教育科技有限公司上海-浦东新区2万/月02-18满员
测试开发工程师(C++/python) 上海墨鹍数码科技有限公司上海-浦东新区2.5万/每月02-18未满员
Python3 开发工程师 上海德拓信息技术股份有限公司上海-徐汇区1.3万/每月02-18剩余11人
测试开发工程师(Python) 赫里普(上海)信息科技有限公司上海-浦东新区1.1万/每月02-18剩余5人
Python高级开发工程师 上海行动教育科技股份有限公司上海-闵行区2.8万/月02-18剩余255人
python开发工程师 上海优似腾软件开发有限公司上海-浦东新区2.5万/每月02-18满员
'''
import re
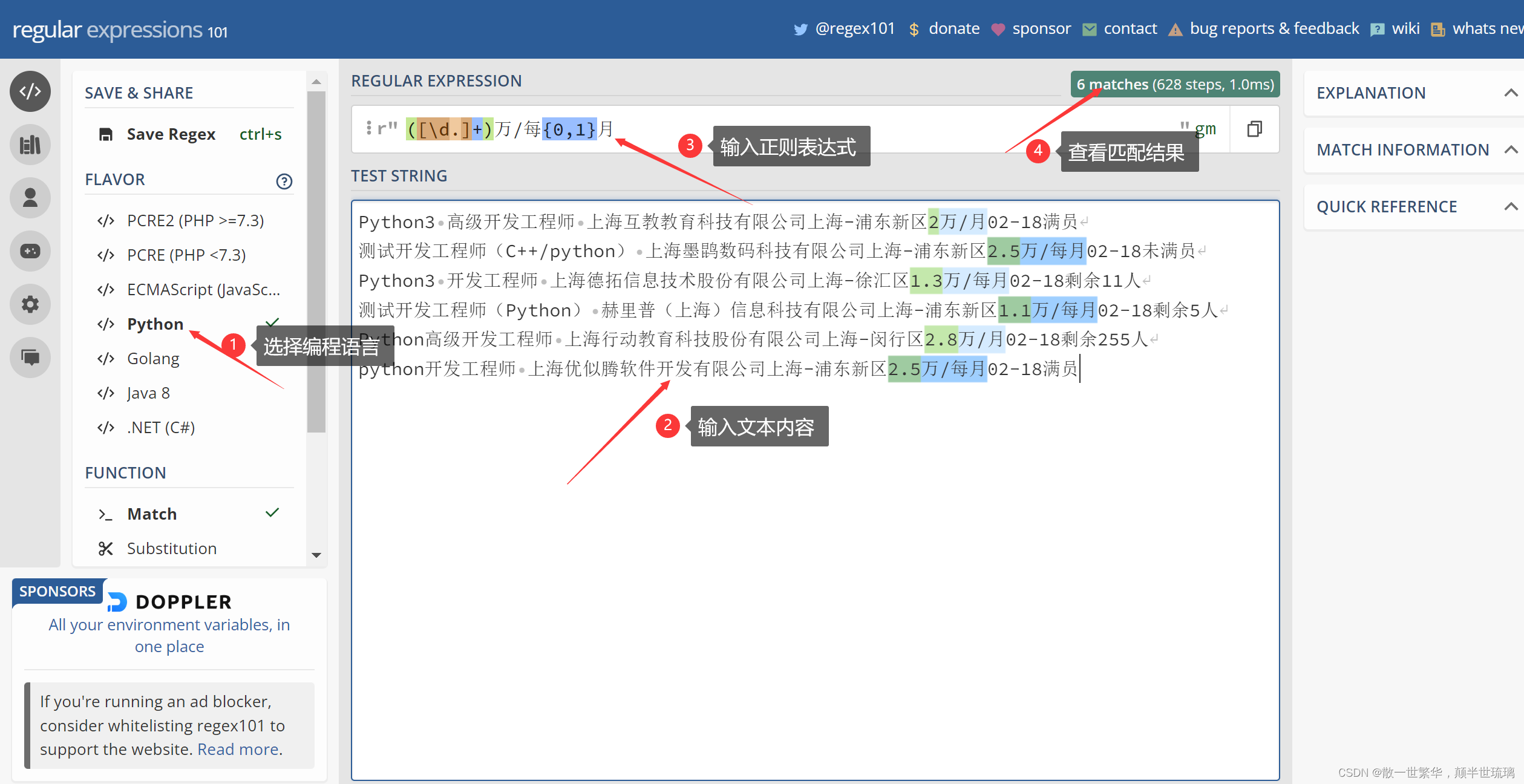
for one in re.findall(r'([\d.]+)万/每{0,1}月', content):
print(one)
怎么样?是不是代码量大大减少,有没有勾起你学习正则表达式的欲望呢?下面就让我们真正走进正则表达式的语法世界吧!对了,这里还向大家推荐一个验证正则表达式的优质外国网站国外正则表达式验证网站,在之后的学习过程中,每当我们编写完成一个正则表达式,不要急着运行程序,先把正则表达式在该网站进行验证,查看匹配结果,如果没问题然后在运行程序,它可以帮助我们排错和进一步提高我们编码的效率。
2.正则表达式的语法
正则表达式是一种文本模式,它包括普通字符与特殊字符,普通字符包括普通的中英文字符,例如python,中国之类的,而特殊字符包括. * + ? \ [ ] ^ $ { } | ( ),下面我带大家来分别介绍一下它各自的含义,具体如下表所示:
| 表达式 | 描述 |
|---|---|
| . | 匹配任何单个字符,除了换行符’/n’ |
| * | 匹配前面的子表达式任意次,包括0次 |
| + | 表示匹配前面的子表达式一次或多次,不包括0次 |
| {m,n} | 表示匹配前面的子表达式至少m次,最多n次 |
| \ | 表示转义字符 |
| [] | 匹配几个字符之一 |
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的结尾 |
| () | 将匹配到的字符串进行组选择 |
| ? | 匹配前面的子表达式0次或1次,相当于{0,1} |
下面对特殊字符的具体用法做进一步分解释,具体如下所示:
. 表示要匹配除了换行符之外的任何单个字符
比如,现在需要从下面的文本中,选出所有的颜色并输出
苹果是绿色的
橙子是橙色的
香蕉是黄色的
乌鸦是黑色的
很明显,我们可以直接将正则表达式写成
.色
然后去对应的国外验证网站验证正则表达式的正确性,如下图所示:
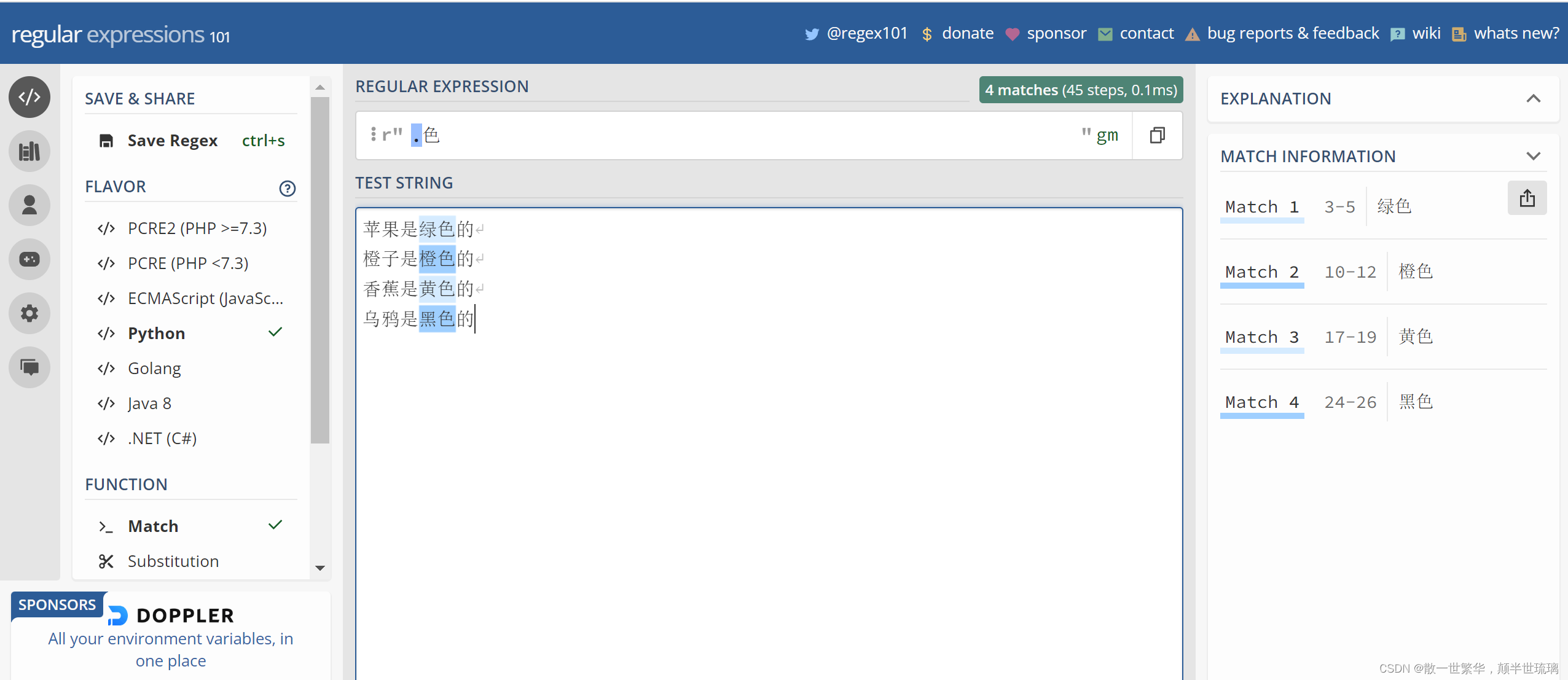
从上图可以看出有4个匹配结果,那么我们的python代码该如何编写呢?具体如下所示:
import re
content = '''
苹果是绿色的
橙子是橙色的
香蕉是黄色的
乌鸦是黑色的
'''
p = re.compile(r'.色')
for one in p.findall(content):
print(one)
# 运行结果如下所示
# 绿色
# 橙色
# 黄色
# 黑色
这里简单说一下,使用正则表达式前需要导包
import re
而compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,通过Pattern对象可以使用各种正则表达式对象的API方法。
*表示匹配前面的子表达式任意次
比如,你要从下面的文本中,选择每行逗号后面的字符串内容,包括逗号本身。
苹果,是绿色的
橙子,是橙色的
香蕉,是黄色的
乌鸦,是黑色的
猴子,
这样,根据特殊字符*的含义,我们可以很容易写出正则表达式为
,.*
将对应的文本内容与正则表达式带入对应的正则表达式验证网站验证其正确性,具体如下所示:
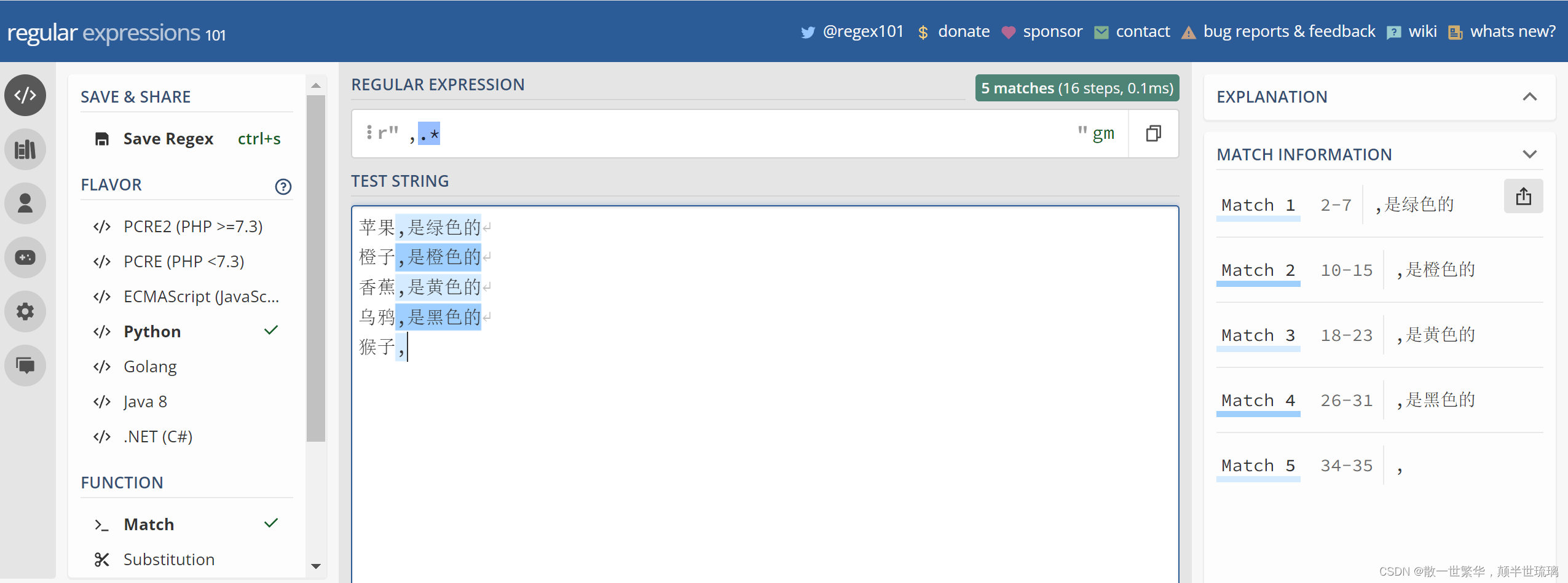
完成对应需求的python代码如下所示:
content = '''苹果,是绿色的
橙子,是橙色的
香蕉,是黄色的
乌鸦,是黑色的
猴子,'''
import re
p = re.compile(r',.*')
for one in p.findall(content):
print(one)
+表示匹配前面的子表达式一次或多次
特殊字符+与*特别类似,区别就是 +不能匹配前面的子表达式匹配0次。
比如,还是上面的例子,你要从文本中,选择每行逗号后面的字符串内容,包括逗号本身。
但是,添加一个条件, 如果逗号后面 没有内容,就不要选择了。
比如,下面的文本中,最后一行逗号后面 没有内容,就不要选择了。
苹果,是绿色的
橙子,是橙色的
香蕉,是黄色的
乌鸦,是黑色的
猴子,
面对这样的要求,我们就可以把正则表达式改为
,.+
去网站验证一下,结果如下所示:
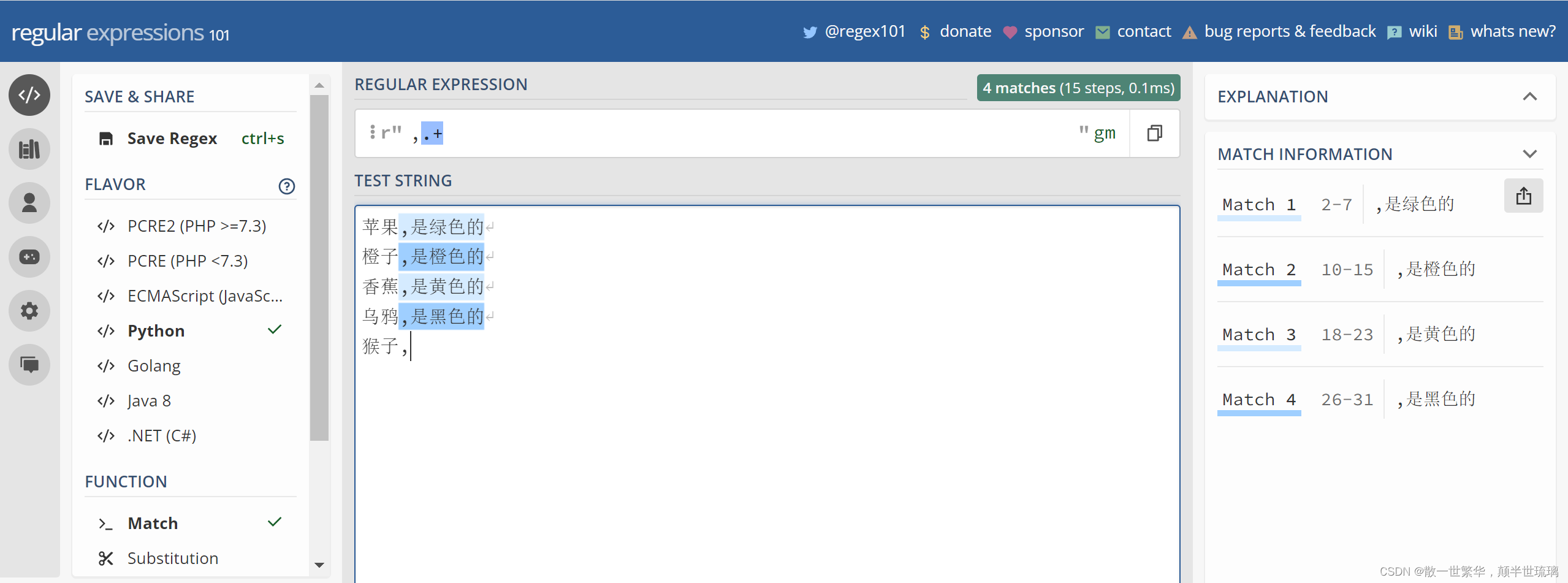
需要注意的是:在最后一行,猴子逗号后面没有其它字符了,而+表示至少匹配1次, 所以最后一行没有子串选中。
花括号-匹配指定次数
花括号表示 前面的字符匹配 指定的次数 。
比如 ,下面的文本
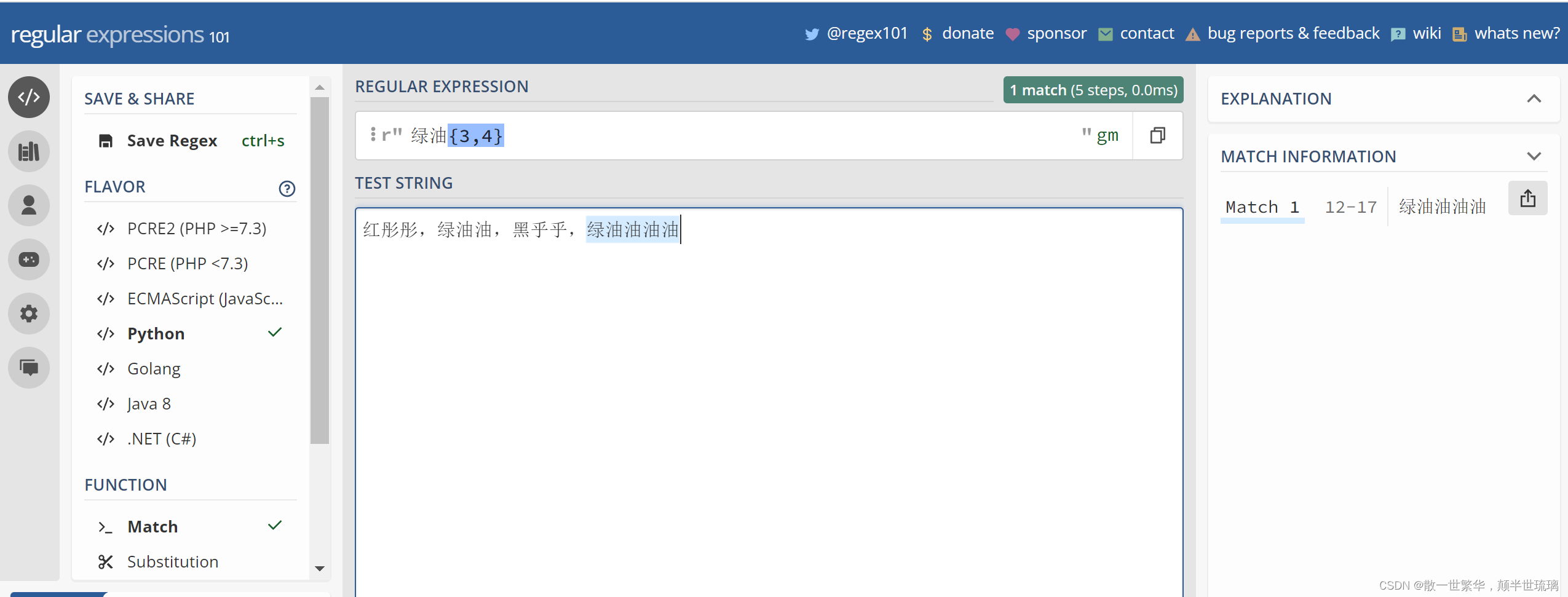
红彤彤,绿油油,黑乎乎,绿油油油油
表达式 油{3} 就表示匹配 连续的油字3次
表达式 油{3,4} 就表示匹配 连续的油字至少3次,至多 4 次
如果使用正则表达式
绿油{3,4}
类似于这样匹配指定次数的文本,生活中比较普遍的应用就是从一段文本中提取出长度固定的内容,例如电话号码,身份证号码等信息。
贪婪模式与非贪婪模式
这里先不直接给出贪婪模式与非贪婪模式的定义,而是给出二者的区别!
假设现在我们有一个需求,要从一段文本中中提取出标签,具体的文本如下所示:
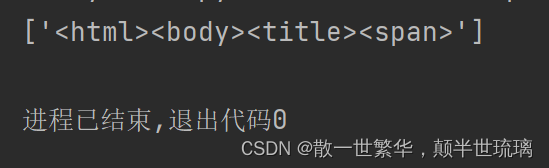
source = '<html><body><title><span>'
而我们的目的是想得到一个这样的列表,具体如下所示:
['<html>','<body>','<title>','<span>']
面对此需求,我们根据前面所学习的知识,很快我们就能给出相应的正则表达式为
<.*>
但是事情真的会与我们预期的一致吗?下面就让我们来测试一下。测试的Python代码如下所示:
import re
source = '<html><body><title><span>'
p = re.compile(r'<.*>')
print(p.findall(source))
按照上面的程序,运行结果却是
那么到底怎么回事呢? 原来在正则表达式中, 像*和+这样的特殊字符都是贪婪地,使用他们时,会尽可能多的匹配内容,所以, <.*> 中的 星号(表示任意次数的重复),一直匹配到了 字符串最后的 里面的>。所以才会出现上述现象,要解决这个问题,就需要使用非贪婪模式,也就是在*后面加上 ? ,变成这样 <.*?>
知道问题的根源后,我们对症下药,改变正则表达式为
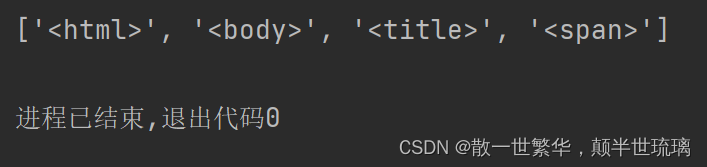
<.*?>
改变对应的程序为:
import re
source = '<html><body><title><span>'
p = re.compile(r'<.*?>')
print(p.findall(source))
则运行结果如下所示:
元字符的转义
\在我们正则表达式中起重要作用!
例如,假设我们要从下面的文本中,提取出.前面的全部内容(包括文本与数字),具体文本如下所示:
黄金帅水果的单价是101.77元/斤
红颜草莓20.8元/斤
西瓜1.1元/斤
黄桃10.6元每斤
按照前面所学的知识,我们很容易想到的正则表达式为
.*.
细心的你一定会发现问题所在。因为点是一个 元字符,直接出现在正则表达式中,表示匹配任意的单个字符, 不能表示 . 这个字符本身的意思了。怎么办呢?如果我们要搜索的内容本身就包含元字符,就可以使用 反斜杠进行转义。
这里我们就应用使用这样的表达式:
.*\.
因为代码类似,这里就不展示了,读者可以自行将前面代码中的正则表达式与文本内容替换即可查看效果!
\更重要的应用就是,如果\后面接一些字符,表示匹配 某种类型 的一个字符。
比如:
\d 匹配0-9之间任意一个数字字符,等价于表达式 [0-9]
\D 匹配任意一个不是0-9之间的数字字符,等价于表达式 [^0-9]
\s 匹配任意一个空白字符,包括 空格、tab、换行符等,等价于表达式 [\t\n\r\f\v]
\S 匹配任意一个非空白字符,等价于表达式 [^ \t\n\r\f\v]
\w 匹配任意一个文字字符,包括大小写字母、数字、下划线,等价于表达式 [a-zA-Z0-9_]
\W 匹配任意一个非文字字符,等价于表达式 [^a-zA-Z0-9_]
方括号表示匹配几个字符之一
方括号表示要匹配指定的几个字符之一 。
比如:
[abc] 可以匹配 a, b, 或者 c 里面的任意一个字符。等价于 [a-c] 。[a-c] 中间的 - 表示一个范围从a 到 c。
如果你想匹配所有的小写字母,可以使用 [a-z],所有的大写字母就是[A-Z]。
一些元字符在方括号内失去了魔法,变得和普通字符一样了。比如
[akm.] 匹配 a k m . 里面任意一个字符
这里 . 在括号里面不在表示 匹配任意字符了,而就是表示匹配 . 这个字符
如果在方括号中使用 ^ , 表示 非 方括号里面的字符集合。
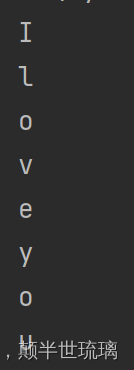
假设我们要从当前的文本中选出非数字并打印输出,具体的文本如下所示:
I5lov2e0you
从该文本中提取出所有的非数字并输出,代码如下所示:
import re
content = 'I5lov2e0you'
p = re.compile(r'[^\d]')
for one in p.findall(content):
print(one)
运行效果如下所示:
起始位置和单行、多行模式
^ 表示匹配文本的开头位置。
正则表达式可以设定 单行模式 和 多行模式
如果是 单行模式 ,^表示匹配 整个文本 的开头位置。
如果是 多行模式 ,^表示匹配 文本每行 的开头位置。
$ 表示匹配文本的结尾位置。
如果是 单行模式 ,$表示匹配 整个文本 的结尾位置。
如果是 多行模式 ,$表示匹配 文本每行 的结尾位置。
我们在Python代码中可以设置compile 的第二个参数 re.M ,指明了使用多行模式,
这里由于很好理解,就不带大家看具体的案例了,有兴趣的小伙伴可以自己测试一下。
括号-组选择
很多时候我们通过正则表达式提取到的是一个整体字符串,而我们还要在整体字符串中再一次截取有效的部分,这个时候就需要用到()来进行组选择了。
组就是把正则表达式匹配的内容里面其中的某些部分 标记为某个组。
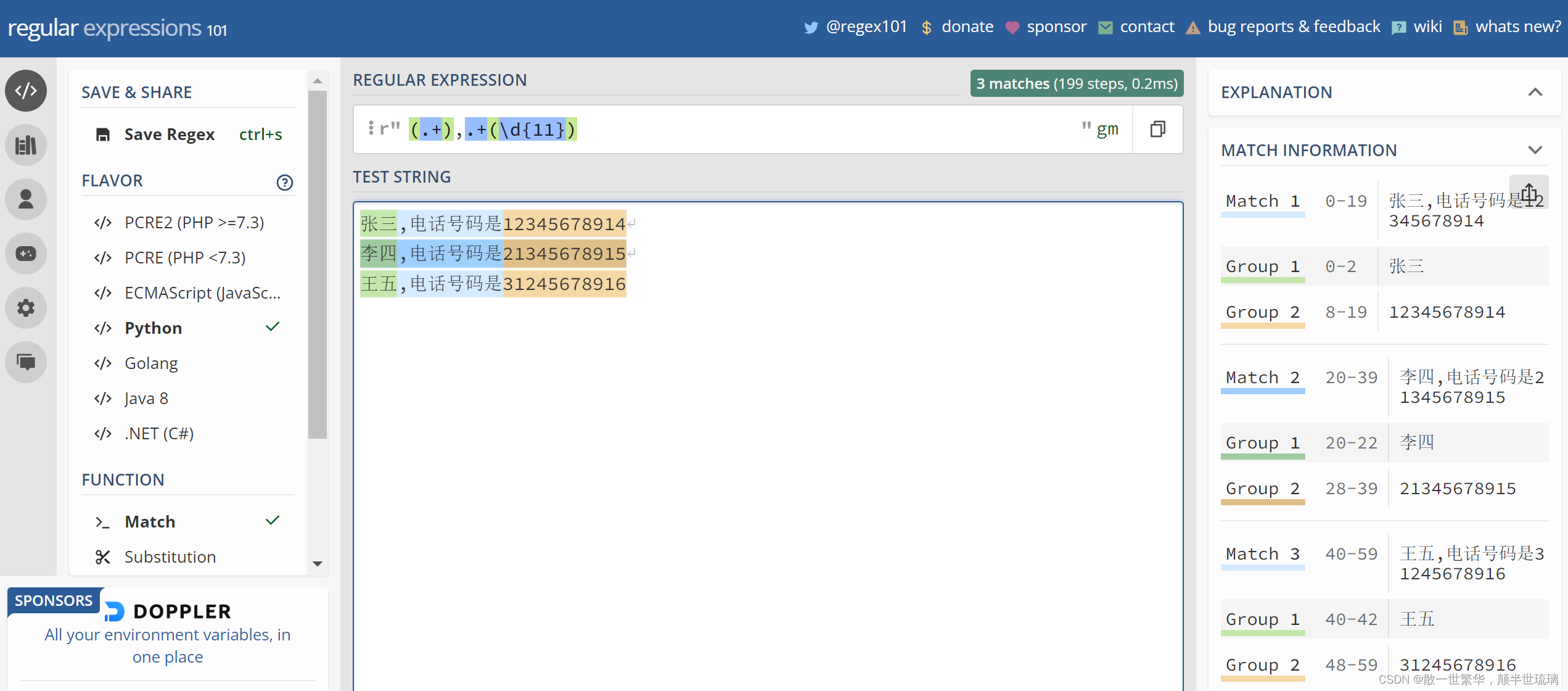
例如,我们需要从下面的文本中提取出人名和对应的电话号码,内容如下所示:
张三,电话号码是12345678914
李四,电话号码是21345678915
王五,电话号码是31245678916
假设我们只能写出下面的正则表达式
.+,.+\d{11}
很明显,如果这样写,同时设置为多行模式,则每一行的数据都是全部匹配,但是我们只需要人名和电话号码,这个时候在我们所需要的匹配内容上面加上()即可取出对应的内容,具体的正则表达式如下所示:
(.+),.+\(d{11})

















 6868
6868











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











