







最近刚刚完成了服务器流量收集这一块儿的代码,就顺便整理一下思路什么的吧。
首先就是流量包的抓取和解析。因为我们使用的是python语言,而python中的关于数据包抓取的模块是scapy,而不是scrapy,这个是爬虫里面需要用到的模块。当然,不仅仅是scapy,还有文件夹操作的os模块和实行多线程的threading模块。
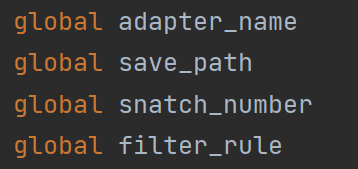
首先就是对网卡/网络适配器,过滤规则(我们这里采用的是BPF规则去对协议进行过滤),抓包数量以及保存路径的定义,将其设为全局变量:
接着就是对数据包的操作,先创建或者说是查找数据包保存路径,利用os模块和其中的mkdir函数去进行操作。
然后便是利用scapy模块中的sniff(嗅探/流量监控)函数去进行数据包的抓取,sniff函数的一些参数如下:

因为我们要用到的是多线程的抓取,所以需要用到threading模块,而threading模块儿的具体详解我也不详细阐述了在这里面,附加一个链接,在CSDN中也算是高阅读量的解释吧:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2628
2628
07-27
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









