







WAF:Web应用防护系统(也称为:网站应用级入侵防御系统。英文:Web Application Firewall,简称: WAF)。利用国际上公认的一种说法:Web应用防火墙是通过执行一系列针对HTTP/HTTPS的安全策略来专门为Web应用提供保护的一款产品。
与传统防火墙 /IPS 设备相比较,WAF最显著的技术差异性体现在:
(1)对HTTP有本质的理解(即:能完整地解析HTTP,包括报文头部、参数及载荷。)
(2)提供应用层规则(即:具备可以检测到变形攻击的能力)
(3)提供正向安全模型(白名单)(即:只允许已知有效的输入通过,这一点增强了web的防护能力)
(4)提供会话防护机制(即:防护基于会话的攻击类型,如cookie篡改及会话劫持攻击。)
WAF支持完全代理方式,作为 Web 客户端和服务器端的中间人,它避免 Web服务器直接暴露在互联网上,监控 HTTP/HTTPS 双向流量,对其中的恶意内容(包括攻击请求以及网页内容中被植入的恶意代码)进行在线清洗。所以,它可以应用于以下场景:
(1)网页篡改在线防护(它可以按照网页篡改事件发生的时序,提供事中防护以及事后补偿的在线防护解决方案。)
(2)网页挂马在线防护(即当用户请求访问某一个页面时,WAF会对服务器侧响应的网页内容进行在线检测,判断是否被植入恶意代码,并对恶意代码进行自动过滤。)
(3)敏感信息泄露防护(WAF 可以识别并更正 Web 应用错误的业务流程,识别并防护敏感数据泄露,满足合规与审计要求。)
(4)WEB 应用交付(因为WAF同时提供SSL加速及卸载、Web caching及压缩等功能。)
以上种种便是WAF的简单介绍与其相较于传统防火墙的优点。
而WAF种类从产品形态上来划分主要分为三大类:硬件设备类、基于云的 WAF与软件产品类。
我们就简单说一下云WAF的简单实现思路:
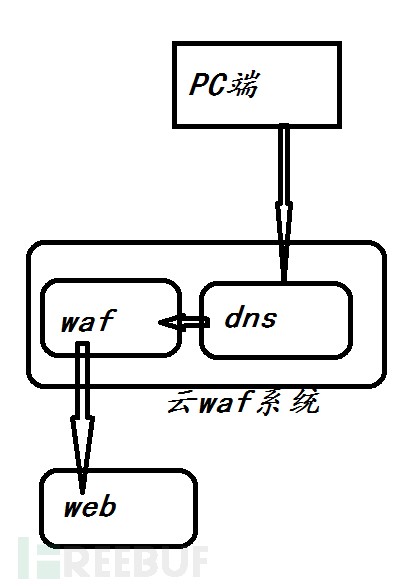
我们通过openresty的lua拓展便可以将用户的DNS解析到我们的WAF服务器里,再通过WAF反向代理将流量代理到真正的web服务器上面,这时用户无法直接访问到web服务器,便可以使web服务器处于保护状态。而我们的WAF则可以在这个过程中检测URL是恶意还是正常的,并进行反馈,如果检测出来URL是恶意的,这时候便回馈给用户并发出警告,而如果是安全URL,便可以放其通行,并准备进行下次检测。

















01-17
 1908
1908
1908
05-15
1170
1170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









