






1 引言
1.1 本研究针对的问题
①在真实的知识图谱中,不同的关系往往表现出明显的长尾分布,即许多关系只有少量的实体对。②现有方法一般通过学习实体和关系的表示来完善知识图谱,但忽略了三元组实体对之间邻域关系的相似性对知识图完善的影响(例如,在知识图谱中,如果实体A和B经常出现在类似的上下文中,比如它们都有共同的邻居实体和关系类型,那么A和B之间的关系可能也是相似的)。
1.2 本研究给出的解决方案
提出了一种隐式关系注意力网络来解决这一局限性,挖掘实体对邻居关系的相似度信息。
具体的:
①提出了一种异质实体和关系编码器来挖掘一跳邻居信息,并通过注意机制和卷积来增强实体和关系的表示。
②提出了一种隐式关系感知编码器来挖掘三元组实体对的邻居关系相似信息,并得到三元组动态关系表示。(实体A可能通过关系R1与实体C相连,实体B可能通过关系R2与实体D相连。如果我们发现实体C和实体D在某些方面是相似的,或者关系R1和R2在某种意义上是等价的,那么这可能暗示着实体A和实体B之间也存在某种关系或相似性。)
③提出了一种自适应关系融合网络,该网络融合了实体对的三元组动态关系表示和相邻关系相似度的原始信息,增强了查询集对参考集的关系表示;从而提高了少样本知识图补全的精度。
1.3 相关概念
①参考集
虽然在某些文献中可能被称为验证集或测试集,但在元学习和少样本学习的上下文中,它通常指的是一个较大的数据集,包含所有可能的类别样本,用于调整模型参数或选择最佳模型。它可以帮助确定模型在面对所有潜在类别时的表现,而不仅仅是支持集和查询集中出现的那些类别。在实际应用中,参考集可能不会被明确划分,而是根据实验设计需要动态地从完整数据集中抽取出来用作验证或测试。
②异构实体
异构实体指的是图中的节点和边代表不同类型的对象和关系。例如,节点可以表示人、公司、地点等,边可以表示“雇佣”、“位于”等关系。
③GELU激活函数



④Hadmard积

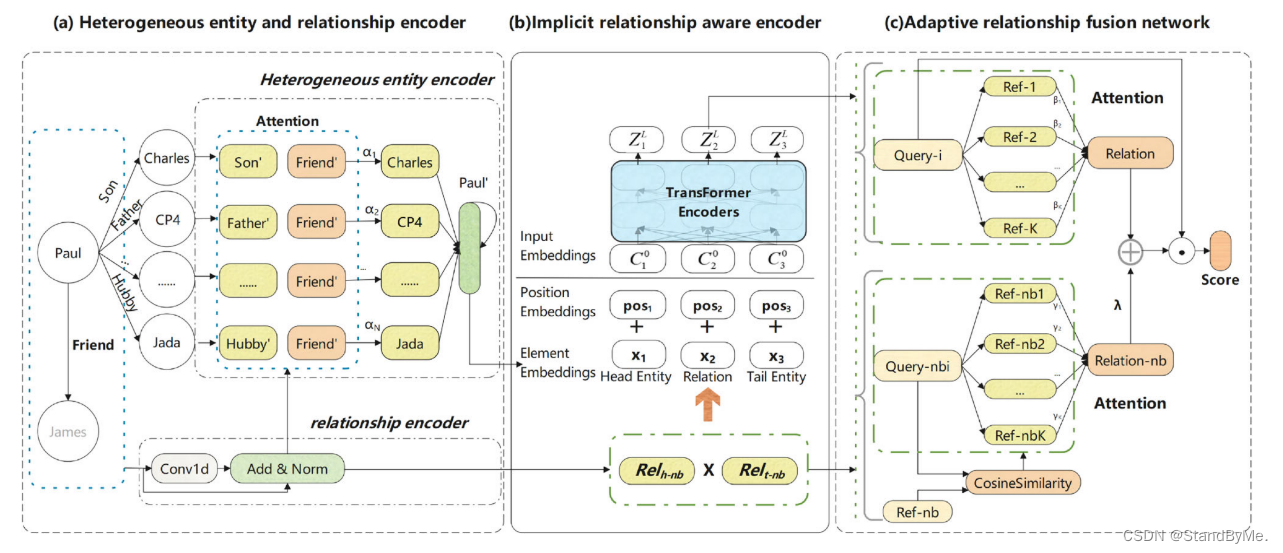
2 隐式关系注意网络
利用实体对的邻域关系在三元组中的相似性信息→增强查询集到参考集的关系表示,从而提高了知识图谱补全的准确性。
目标是利用有限数量的可用参考三元组(h,r,?)来完成尾实体的补全。以下是变量说明:
2.1 异构实体和关系编码器
在关系编码器部分中,提取有关实体与其邻居的关系的信息。以实体Paul为例,我们对Paul与其邻居之间的关系进行卷积,包括任务关系“Friend”,以获取关系信息。

但是在少样本场景中,通过TransE获得的嵌入可能会受到任务关系表示不足的影响,并且在捕获实体与其相邻实体之间的关系信息时可能会出现类似的问题。为了解决这些问题,我们使用一维卷积函数进行特征提取。
关系嵌入可以表示为:
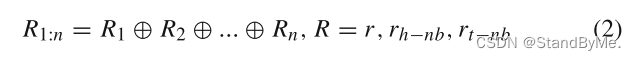
⊕表示连接操作,n表示实体的邻居数量,r表示当前任务关系,r_h−nb表示头部实体与其邻居之间的关系,r_t−nb表示尾部实体与其邻居之间的关系,r展开为与r_h−nb具有相同的维度。
换句话说,公式 (2) 中的 R1:n是包含多个关系嵌入的集合,它们通过拼接操作组合在一起,最终用于进行卷积操作,以提取更多的特征信息。

新特征Rel_i是由关系R_i生成的:

连接Rel_i以获得REL:
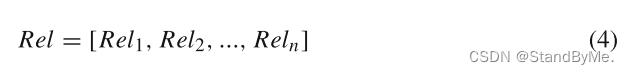
为了缓解消失梯度问题,在关系R和新的关系特征REL上应用剩余连接和归一化操作:
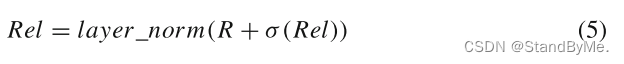
σ(.)使用GELU函数来增强模型的泛化能力。
通过关系编码器分别获得Rel_r、Rel_h−nb和Rel_t−nb。以头部实体为例。在异质邻居编码器中,由于不同的邻居关系和任务关系之间的相似度不同,需要为不同的邻居关系赋予不同的权重,以说明它们之间的差异。所以定义了一个度量函数ψ(·),它通过将嵌入Rel_r的任务关系乘以嵌入头实体的邻居关系Rel_h−nb来计算其相关性分数。
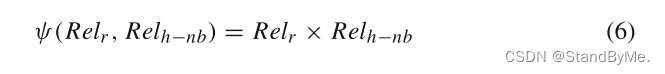
其中Rel_r和Rel_h−nb可以通过(5)获得,Rel_h−nb表示头实体的邻居关系的增强嵌入。基于它们在实体中的角色,将不同的权重α_nb分配给头实体的每个邻居e_nb,从而产生邻居感知嵌入: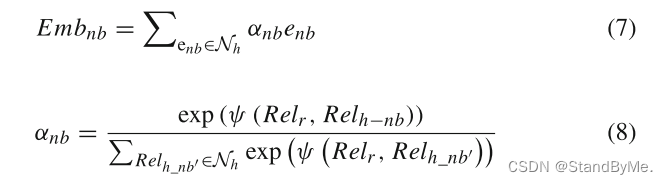
ψ(Rel_r,Rel_h−nb)的值将更大,表明与头实体对应的相邻实体在该任务关系中扮演更重要的角色。我们得到了增强头部实体的增强嵌入:
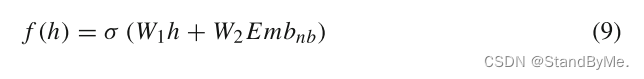
2.2 隐式关系感知编码器
目的:增强实体对的嵌入。
原因:认为在头实体的邻居和尾实体的邻居之间存在相关性。
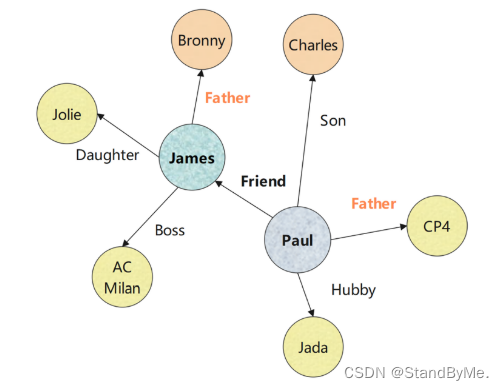
方案:使用Hadamard乘积来计算头部实体邻居关系向量和尾部实体邻居关系向量之间的相似度,并将其作为关系输入:

将三元组以以下的形式作为transformer的输入:X ={x_1, x_2, x_3},分别对应(h, r, t)。
对于每一个输入表示为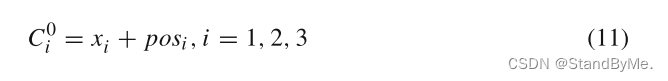
其中x_i表示嵌入向量,pos_i表示位置编码。得到位置编码后的嵌入向量后,送入L层变压器块进行编码:
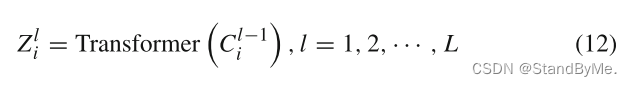
其中Z_l i为Ci在第L层后的隐藏状态。变压器编码器采用多头注意力,丰富了特征子空间,可以捕获更多样化的特征信息。
将最终隐藏状态z_L2作为三元组动态关系表示(后面增前后将称为一般关系表示)。这种表示捕获每个实体之间的语义信息,为当前任务中的不同实体提取细粒度语义。
2.3 自适应关系融合网络
针对的问题:①对于任务关系下的实体对,需要评估当前实体对相对于当前任务的重要性。
②隐式关系感知编码后,可能会有邻居相似关系信息的丢失。
所以,有必要通过加权求和的方法,加入一些邻居相似关系信息来提高模型的精度(如模型图中(C)所示)。
公式(13)在少样本场景下,利用动态关系表示和邻居关系相似度来计算查询集和参考集之间的关系相似度。
当
此时度量函数用于表示查询集和参考集之间三元组动态关系表示的相关性。Q_r′ 和 S_r′可以通过公式 (12) 获得。
当
度量函数表示查询集和参考集中邻居关系相似度的相关性。Q_nb 和 S_nb 可以通过公式 (10) 获得。
为了进一步增强查询集和参考集之间邻居关系相似度的相关性,使用余弦相似度来计算。
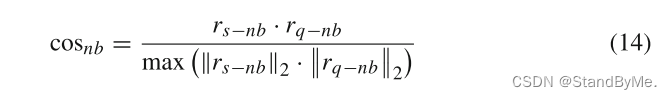
其中r_s−nb表示参考集S_nb中邻居关系的相似度,r_q−nb表示查询集Q_nb中邻居关系的相似度。
然后利用注意机制生成不同关系表征和相邻关系相似表征:

当η=1,得到与查询实体对相适应的一般关系表示。
当η=cos_nb
获取与查询实体对的邻居关系的相似度相适应的一般邻居关系关联表示。
融合不同查询实体对的一般关系表示和一般邻居关系表示,将查询集的关系表示增强为参考集,得到融合的关系表示:
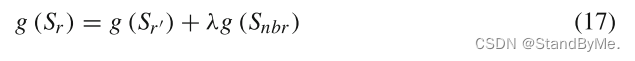
其中λ是一个可学习的参数。0≤λ≤1根据邻居信息的分散度进行调整。邻居信息越分散,λ的值越大;邻居信息越聚集,λ的值越小。
解释:
关于λ,涉及如何处理局部结构和全局信息。在图神经网络(Graph Neural Networks, GNNs)或类似的方法中,节点的表示不仅依赖于其自身的特征,还依赖于其邻居节点的特征。参数λ控制着一个节点的表示受其直接邻居影响的程度。
-
当邻居信息非常聚合(即相似或紧密相关)时,意味着局部信息已经足够丰富和一致,可能不需要过多地考虑全局信息。因此,λ的值会较小,使得节点的表示更多地依赖于其自身和其直接邻居的信息,而不是更远的邻居或整个图的信息。
-
相反,当邻居信息很分散(即不相似或变化较大)时,这意味着仅依靠局部信息可能不足以捕获节点的真实特性。在这种情况下,增加λ的值可以使得节点的表示更多地考虑全局信息,即更远的邻居或整个图的信息,从而有助于弥补局部信息的不足。
通过这种方式,λ作为调节参数,帮助模型在局部和全局信息之间找到平衡,以优化节点的表示学习过程。这尤其在处理具有复杂结构的图数据时非常重要,例如社交网络、化学分子结构等。
度量查询集和参考集的相似度:

φ(·)值越大,相似性越高,查询为真的可能性就越大。
从任务中选择正样本和负样本三元组,分别形成正查询集合和负查询集合,修改正三元组的尾部实体,确保负三元组一定不是正确的。损失函数:
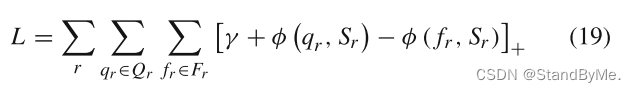
通过最小化L,目标是最大化正查询集q_r和参考集之间的相似度分数,同时最小化负查询f_r集和参考集之间的相似度分数。
















 1950
1950











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









