






1 引言
1.1 问题
现有的方法难以对实体之间的复杂关系进行建模,这严重阻碍了它们有效地完成知识图谱的能力。
1.2 目的
本研究使模型在建模几何关系时捕获更多有用的信息来对头、尾实体进行预测,从而提高嵌入性能。
1.3 技术
①提出了一种新的分层多头关注网络嵌入框架RiQ-KGC,该框架集成了知识图三元组的不同粒度上下文信息,并对实体之间的四元数旋转关系进行了建模。
②提出了一种关系实例化方法,以减轻表达实体之间复杂关系的困难。利用Transformer对关系进行集成,获得多跳邻居信息,使一个关系可以根据不同的实体嵌入到不同的嵌入中。
1.4 本文结合的信息
RiQ-KGC对实体和关系之间的几何信息进行建模和提取,利用实体几何变换和多跳邻域信息来支持模型学习。
1.5 相关概念
①欧拉角和万向锁
欧拉角中的描述物体运动的方向的方式 :偏航-俯仰-滚转(yaw-pitch-roll),等价于围绕ZYX轴进行旋转。
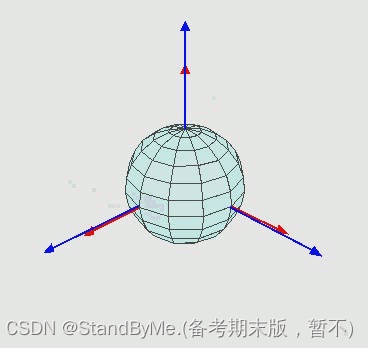
如图,每次旋转有新的ZYX轴,绕着新的轴旋转。但是这种表示方式会遇到万向锁(Gimbal lock)问题。
万向锁问题:如果第二次旋转的角度为90°,则有两个轴会重叠。损失了一个自由度,比如
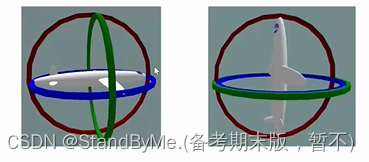
像这样绿色和蓝色重叠在一起,你绕蓝色或者绿色旋转,将会是同样的旋转。
参考:空间几何-欧拉角、四元数、重投影误差_四元数投影角-CSDN博客
②四元数空间
四元数空间是一种数学上的概念,它是四元数集合的几何表示。四元数是由爱尔兰数学家威廉·罗文·哈密顿于1843年发明的,作为一种扩展复数的概念,但引入了额外的维度和更复杂的代数结构。
在四元数空间中,每一个四元数都可以表示为一个形如 𝑎+𝑏𝑖+𝑐𝑗+𝑑𝑘的数,其中 𝑎,𝑏,𝑐,𝑑是实数,而 𝑖,𝑗,𝑘是四元数的基本单位,它们满足特定的乘法规则:

这些规则意味着四元数乘法是不 交换的,也就是说,两个四元数的乘积依赖于它们的顺序。
四元数空间可以视为一个四维实数向量空间,其中每个四元数对应于四维空间中的一个点,或者说是四维向量。四元数的加法遵循向量加法的规则,而四元数的乘法则涉及到了更复杂的代数运算。
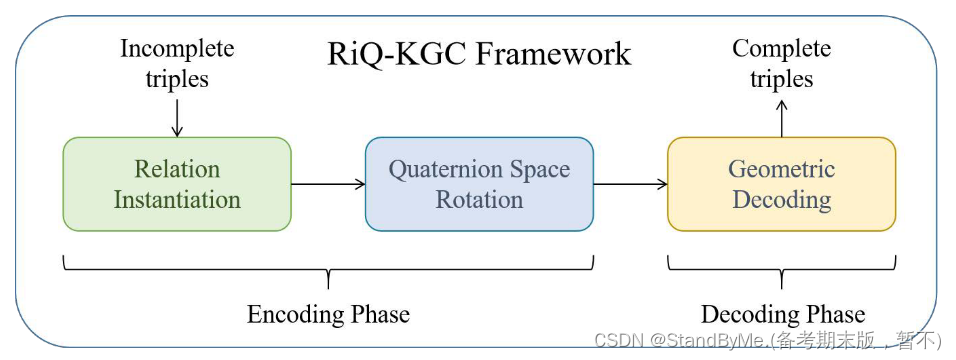
2 RiQ-KGC模型
2.1 链接预测的四元数
RiQ-KGC由关系实例化、四元数空间旋转和几何解码三个功能模块组成。关系实例化模块用于对关系进行本地化,并使它们成为特定于实体的表示形式。四元数空间旋转模块通过实例化的关系在四元数空间中旋转实体以获得几何信息。几何解码模块对以上两个模块得到的信息进行分析。它的输出将与四元数空间中的每个实体的相似性进行比较,得分最高的实体被认为是这个三元组的目标结果。

链接预测任务被统一为(e_s, e_r, e_t),其中 e_s可以是三元组中的头实体或尾实体。
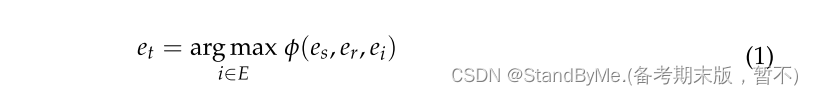

四元数Q由一个标量q0和一组向量Q = (q1, q2, q3)组成,可以表示为Q = q0 + Q = q0 + q1i + q2j + q3k,其中i、j、k分别表示x、y、z轴上的单位向量。𝑖,𝑗,𝑘满足四元数要求,因此四元数可以表示为四元数(q0, q1, q2, q3)。在RiQ-KGC中,实体嵌入e_s = (e_s0, e_s1, e_s2, e_s3)和关系嵌入e_r = (e_r0, e_r1, e_r2, e_r3)由四部分组成。每个部分的维数为d/4,而实体和关系的嵌入仍然使用d维向量表示。
源实体可以通过使用Hamilton积(四元数乘法)的关系进行旋转:
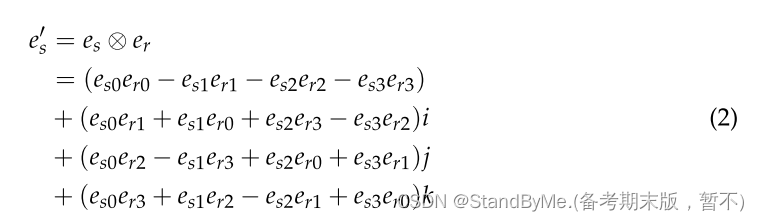
对于公式(1)中结果向量e_' s与目标实体et之间的相似性作为评分函数来评估三元组的有效性:
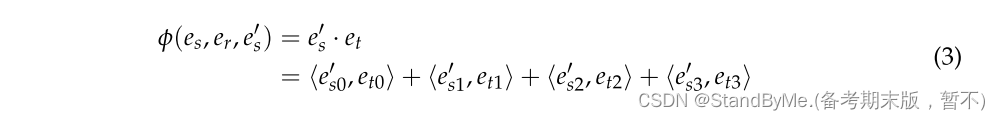
目标是确保每个包含分数的真正的三元组都尽可能高,而不是旨在使每个三元组都获得最高分。
2.2 关系实例化
2.2.1 问题解读
例如,WN18RR数据集包含40,943个实体实例和93,003个三元组,而只给出了11个关系。因此,每个实体只有11个几何变换,尽管邻居的数量可能要高得多。将关系实例化到相应的实体中,可以缓解实体中m-1的问题以及实体之间复杂关系的问题。我们将在两种不同的情况下演示关系实例化方法的有效性。
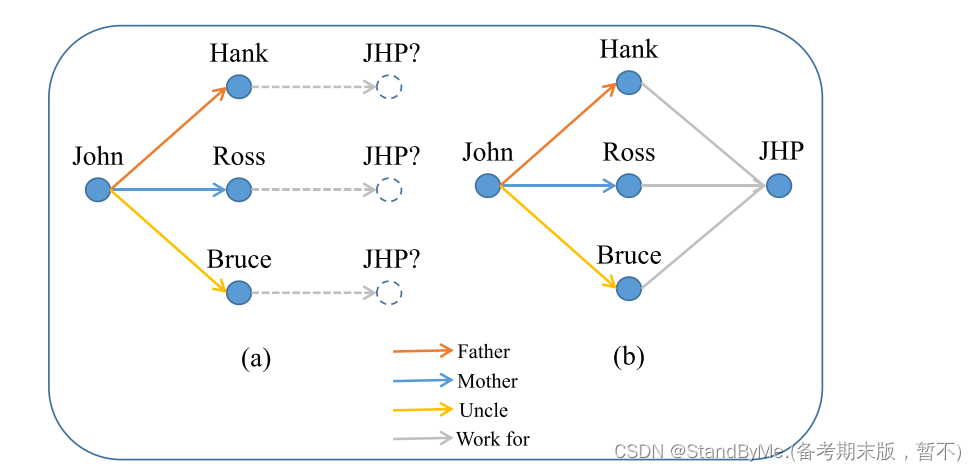
情况1:假设Hank、 Ross、 Bruce分别是约翰的父亲、母亲、叔叔,他们三人都是约翰·霍普金斯医院(JHP)的医生。我们可以使用关系旋转图来表示它们之间的关系,如下图a所示。父亲、母亲、叔叔的关系不同,相应的嵌入位置也不同。然而,work_for关系迫使JHP同时处于三个潜在的嵌入位置,这是不可能的。从下图b可以看出,在关系实例化后,work_for关系可以表示不同的旋转,从而可以准确地表示JHP的嵌入位置。这说明了关系实例化如何缓解m对1的问题。关系实例化的过程可以看作是“反向聚类”的一种形式,它可以防止相似的实体由于m-to-1关系而嵌入在距离很近的地方。该方法提高了模型对最难负样本的区分和准确分类能力。
情况2:如下图a所示,当John长大后成为JHP的一名医生,Hank不仅是他的父亲,也是他的同事。然而,由于父亲和同事是由两个不同的关系表示的,对应于不同的旋转,如果同时给Hank分配两个可能的嵌入位置,就会发生错误。解决这个问题的一个潜在方法是让两个关系表示相同的旋转,这可以唯一地定位Hank,尽管在物理世界中不是等价的。下图b说明了如何使用两个关系来使用不同的旋转来表示从John到Hank的旋转,而在关系实例化后应用关系时不会影响其他实体。这种方法使我们能够唯一地定位Hank,并解决了同时有两个可能嵌入位置的问题。
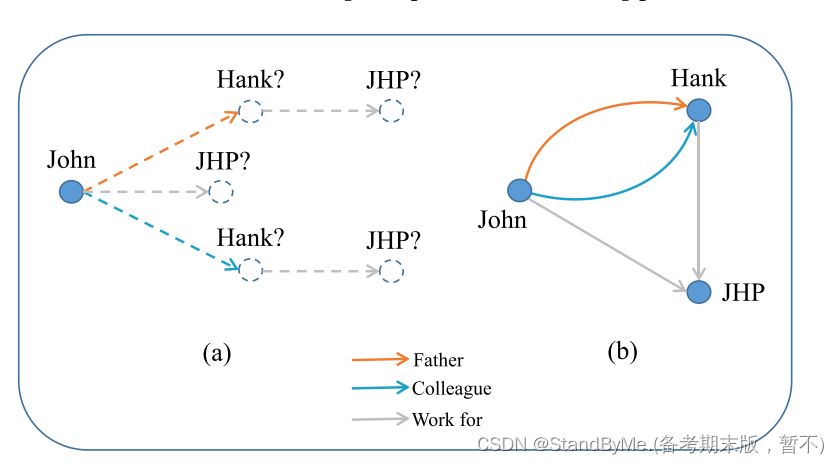
实体之间复杂关系的表示。子图(a)显示了复杂关系的不准确表达,而子图(b)通过关系实例化方法改善了这种情况。不同颜色的箭头表示实体之间不同的旋转,实线表示已确定的旋转过程,虚线表示不确定的旋转过程。
2.2.2 实例化模块的具体构造
分层的Transformer结构,使关系能够完全集成给定实体邻居中包含的环境信息。我们的目标是确保关系可以在不同的环境背景下有不同的旋转。

在关系实例化中,选择相当数量的第二跳、第三跳和第四跳邻居(由e_sec、e_ther和e_for表示),以提供源实体的上下文信息。跳数较小的邻居(如1跳和2跳邻居)与源实体的关系更密切。它们可以直接反映源实体的相关信息。另一方面,跳数较大的邻居,如3跳和4跳邻居,可以通过大致反映源实体所在的场景来提供额外的信息。
值得注意的是,没有使用这些相邻三元组的关系,因为关系集R的大小明显小于我们将选择的相邻三元组的数量。因此,这些关系对源实体的特征表示没有贡献。
如何在多头注意力Transformer网络中生成和使用CLS′0和CLS′1这两个上下文向量:

- 上下文向量的获取:首先通过平均实体表示来获得上下文向量,这些向量包含了实体间的相关信息。
- 输入到多头Transformer:将这些上下文向量与其他输入(源实体、关系和标志向量)一起输入到Transformer中,这样可以在计算过程中保留和处理更多的上下文信息。
- 生成CLS′0 和CLS′1:Transformer的输出是两个新的关系组件CLS′0 和CLS′1,它们代表了关系的不同实例化结果。
- 多头Transformer的作用:多头Transformer通过多个注意力头和前馈网络来处理输入,并通过残差连接和归一化操作来增强模型的稳定性和性能。
2.2.3 四元数空间旋转
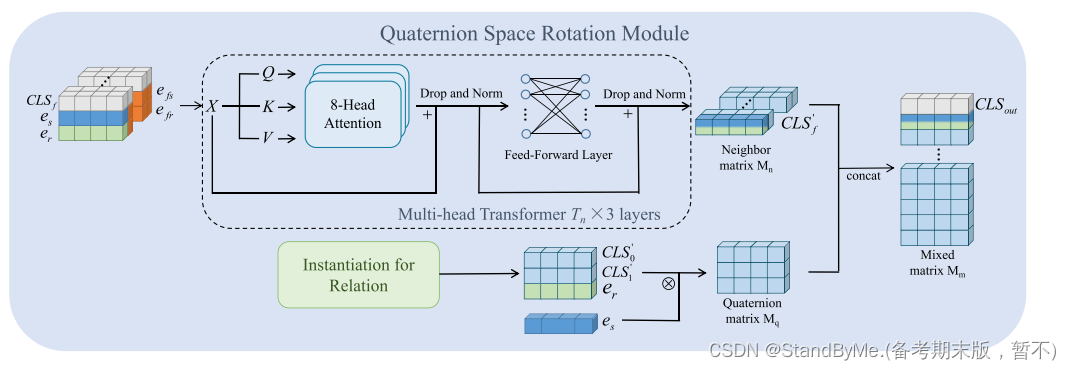
粗粒度邻居信息:
将输出CLS_ ' 0和CLS_ ' 1与er组合以获得关系实例化矩阵。我们对这个矩阵中的三个向量中的每一个执行了es的Hamilton积,导致源实体从三个不同的角度进行四元数旋转,并产生一个四元数矩阵Mq:

得到源实体e_s的多跳邻居信息Mq,捕获粗粒度的上下文情况。
细粒度邻居信息:
从源实体的第一跳邻居中获取细粒度的邻居信息。
①CLS_n 和 CLS_f 是预定义的标志向量,通常在模型初始化时被定义为固定的向量。CLS_n 主要用于指示当前的上下文层次,而 CLS_f 用于指示与第一跳邻居相关的上下文信息。这些向量可以是随机初始化的或是通过某种方式预训练得到的。
②
-
e_s:源实体的表示。
-
e_r:关系的表示。
-
e_{fs}:第一跳邻居实体的表示。
-
e_{fr}:第一跳邻居关系的表示。
- CLSn 和 CLSfCLS_fCLSf 是输入标志向量,它们与 e_s、e_r、e_{fs} 和 e_{fr}一起输入到多头Transformer T_n中。
- 多头Transformer T_n处理这些输入后,生成新的上下文表示CLS'_f。
- 这些输出标志向量 CLSf′CLS'_fCLSf′ 经过连接后,形成邻居矩阵 MnM_nMn,该矩阵包含了整合后的上下文信息。
公式如下:
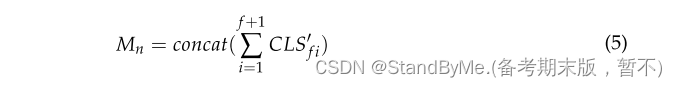
f为第一跳邻居的个数。为了保证源实体信息不被过多的邻居信息淹没,将T_n中的e_s以一定概率替换或屏蔽为随机实体,鼓励模型稍后恢复源实体。
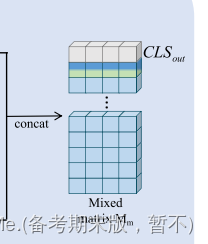
为了整合和统一这些不同层次的上下文信息,将第一跳邻居信息与 M_q连接起来。在Mm的第一行插入一个标志向量CLSout,随后在几何解码中使用它来解析目标实体的表示。,把Mn和Mq结合得到一个混合矩阵:
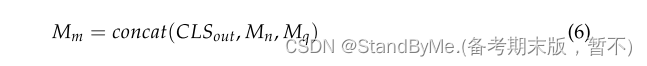
2.2.4 几何解码
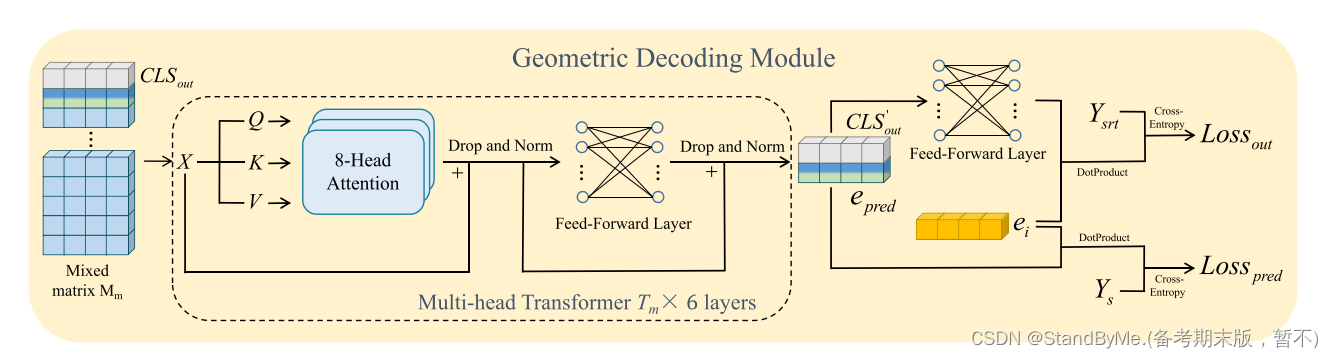 Mm由多头变压器Tm进行解码处理。结果输出的前两行CLS_' out和e_pred分别用于解析目标实体的表示和实体缩减的程度。
Mm由多头变压器Tm进行解码处理。结果输出的前两行CLS_' out和e_pred分别用于解析目标实体的表示和实体缩减的程度。
最后,将cls_‘out输入到线性前馈网络中

e_o代表目标实体。随后,我们通过点积计算与每个i∈E的相似度为

当三元组的尾部实体对应于ei时,可以将其视为置信水平。这三组的分数越高,该实体越有可能是目标实体,因此被适当地预测。
损失函数: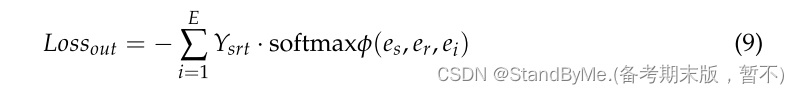
为了避免在解码过程中过分强调邻居信息而忽略源实体信息。
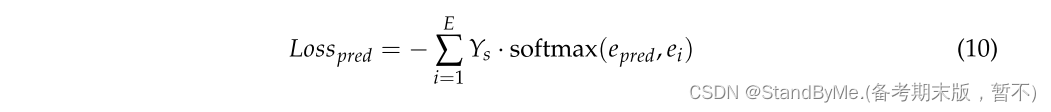
公式 (10) 定义了预测损失 Loss_pred,用于衡量 e_pred与源实体e_s的相似度,目标是最大化源实体的相似度,最小化其他实体的相似度。
r_s是一个二元标签,表示实体i是否为源实体。如果i是源实体,则r_s为 1,否则为0。
总损失函数:
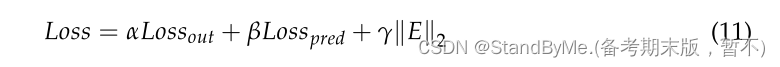
此外,应用实体正则化来防止过度拟合和一般化实体的嵌入位置。















 1694
1694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









