







vector
vector, 变长数组,倍增的思想
size() 返回元素个数
empty() 返回是否为空
clear() 清空
front()/back()
push_back()/pop_back()
begin()/end()
[]
支持比较运算,按字典序
c++自带两个vector之间的比较,依次比较两个vector的元素,首次出现不同的元素时,元素大的数组判断为大
vector<int> a = { 0,1,2,3 };
vector<int> b = { 0,1,3 };
bool int_comp = a >= b;
if (int_comp) {
cout << "a>=b" << endl;
} else {
cout << "a<b" << endl;
}//输出a<b
sort排序时写法
sort(v.begin(), v.end());//而不是sort(v, v + n);
遍历
for(int i = 0; i < v.size(); i ++ ) { }
for(auto it = v.begin(); it != v.end(); it ++) { }
查找
if(find(v.begin(), v.end(), nu) != v.end()) cout << “find” << endl;
else cout << “not find” << endl;
map
第一个元素为键,第二个元素为值
插入可以用insert,也可以直接通过 【】来插入
map<string, int> ma;
for(int i = 1; i <= 3; i ++ )
{
string str;
cin >> str;
ma[str] ++;//ma.insert(make_pair(str, i));
}
for(auto it = ma.begin(); it != ma.end(); it ++ )
cout << it->first << ' ' << it->second << endl;
删除可以用erase(x)
x可以为键,或者为迭代器
unordered_map
unordered_map 容器,直译过来就是"无序 map 容器"的意思。所谓“无序”,指的是 unordered_map 容器不会像 map 容器那样对存储的数据进行排序,但仍然不会重复。换句话说,unordered_map 容器和 map 容器仅有一点不同,即 map 容器中存储的数据是有序的,而 unordered_map 容器中是无序的。
优先队列priority_queue
priority_queue<int, vector<int>, less<int>> q; // 最大堆 从大到小排序,降序
priority_queue<int, vector<int>, greater<int>> q; // 最小堆 从小到大排序,升序
priority_queue q;默认从大到小排序
q.size();//返回q里元素个数
q.empty();//返回q是否为空,空则返回1,否则返回0
q.push(k);//在q的末尾插入k
q.pop();//删掉q的第一个元素
q.top();//返回q的第一个元素
巧妙用法:当数据规模很大时,大根堆可以保存前n1个最小值,因为是从小到大排序,当q.size() > n1是可以直接pop(),pop()出去的数据一定不是前n1个最小值。
同理,用大根堆(从小到大排序)可以算出前n2个最大值。
对于自定义类型,必须重载operator<
#include <iostream>
#include <queue>
using namespace std;
struct Node{
int x, y;
Node(int a=0, int b=0):
x(a),y(b){}
bool operator< (const Node& b)const {
if(x != b.x) return x > b.x;
else return y > b.y;
}
};
//bool operator<(Node a, Node b){//返回true时,说明a的优先级低于b
// //x值较大的Node优先级低(x小的Node排在队前)
// //x相等时,y大的优先级低(y小的Node排在队前)
// if( a.x== b.x ) return a.y> b.y;
// return a.x> b.x;
//}
int main(){
priority_queue<Node> q;
for( int i= 0; i< 10; ++i )
q.push( Node( rand(), rand() ) );
while( !q.empty() ){
cout << q.top().x << ' ' << q.top().y << endl;
q.pop();
}
return 0;
}
也可以这样写
#include <iostream>
#include <queue>
using namespace std;
struct Node{
int x, y;
Node( int a= 0, int b= 0 ):
x(a), y(b) {}
};
struct cmp{
bool operator() ( Node a, Node b ){//默认是less函数
//返回true时,a的优先级低于b的优先级(a排在b的后面)
if( a.x== b.x ) return a.y> b.y;
return a.x> b.x; }
};
int main(){
priority_queue<Node, vector<Node>, cmp> q;
for( int i= 0; i< 10; ++i )
q.push( Node( rand(), rand() ) );
while( !q.empty() ){
cout << q.top().x << ' ' << q.top().y << endl;
q.pop();
}
return 0;
}
set
在set中每个元素的值都唯一,而且系统能根据元素的值自动进行排序(整数默认从小到大排序,字符串按字母序排序)。应该注意的是set中数元素的值不能直接被改变
set中的删除操作是不进行任何的错误检查的,比如定位器的是否合法等等,所以用的时候自己一定要注意。
begin() ,返回set容器的第一个元素
end() ,返回set容器的最后一个元素
clear() ,删除set容器中的所有的元素
empty() ,判断set容器是否为空
max_size() ,返回set容器可能包含的元素最大个数
size() ,返回当前set容器中的元素个数
rbegin ,返回的值和end()相同
rend() ,返回的值和rbegin()相同
find(),返回给定值值得定位器,如果没找到则返回end()。
count() 用来查找set中某个某个键值出现的次数。这个函数在set并不是很实用,
因为一个键值在set只可能出现0或1次,这样就变成了判断某一键值是否在set出现过了。
insert(key_value); 将key_value插入到set中
erase(iterator) ,删除定位器iterator指向的值
lower_bound(key_value) ,返回第一个大于等于key_value的定位器
upper_bound(key_value),返回最后一个大于等于key_value的定位器
L2-014 列车调度 (25 分)
火车站的列车调度铁轨的结构如下图所示。
两端分别是一条入口(Entrance)轨道和一条出口(Exit)轨道,它们之间有N条平行的轨道。每趟列车从入口可以选择任意一条轨道进入,最后从出口离开。在图中有9趟列车,在入口处按照{8,4,2,5,3,9,1,6,7}的顺序排队等待进入。如果要求它们必须按序号递减的顺序从出口离开,则至少需要多少条平行铁轨用于调度?
输入格式:
输入第一行给出一个整数N (2 ≤ N ≤10
5
),下一行给出从1到N的整数序号的一个重排列。数字间以空格分隔。
输出格式:
在一行中输出可以将输入的列车按序号递减的顺序调离所需要的最少的铁轨条数。
#include <iostream>
#include <cstdio>
#include <cstring>
#include <algorithm>
#include <set>
using namespace std;
set<int> se;
int main()
{
int n;
cin >> n;
for(int i = 0; i < n; i ++ )
{
int nu;
cin >> nu;
auto it = se.lower_bound(nu);
if(it != se.end())
{
se.erase(it);
}
se.insert(nu);
}
cout << se.size();
return 0;
}
unordered_set
定义于头文件<unordered_set>,内部插入的元素无序,且插入删除查找元素的时间复杂度未常量。
memcpy(a, b, sizeof b)复制数组
next_permutation
对数组进行全排列,对直接对数组进行改变,返回bool类型,成功返回true
头文件 < algorithm >
next_permutation(数组头地址,数组尾地址)
next_permutation函数将按字母表顺序生成给定序列的下一个较大的排列,直到整个序列为降序为止。
prev_permutation函数与之相反,是生成给定序列的上一个较小的排列。
算法流程
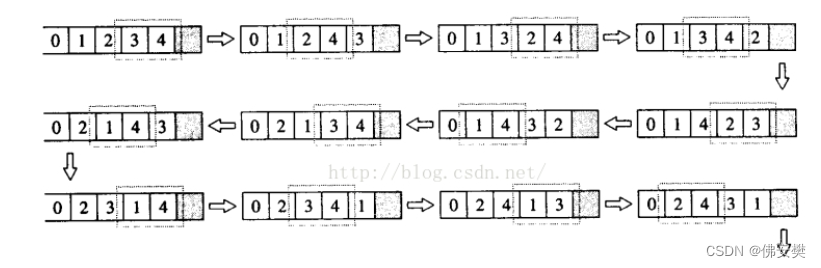
例如1,2,3,4会有24种全排列的情况 next_permutation(a, a + 4)
如果数组初始化为2,3,1 next_permutation(a, a + 3)
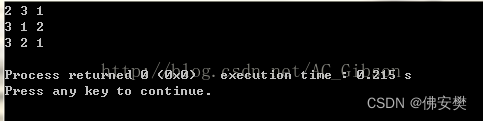
完整全排列如下
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
int main() {
vector<char> chars = {'a', 'b', 'c'};
do {
cout << chars[0] << chars[1] << chars[2] << endl;
} while (next_permutation(chars.begin(), chars.end()));
return 0;
}















 2168
2168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









