









目录
grep搜索
grep 是一个在Linux中用于文本搜索的命令。它的主要功能是在文件中查找包含指定字符串或符合正则表达式模式的行,并将这些行显示在终端上。以下是 grep 命令的一些常见用法和选项:
- 基本用法:
grep pattern file
这将在指定的文件中搜索包含 "pattern" 字符串的行,并将这些行显示在终端上。
-
正则表达式搜索:
grep支持正则表达式,可以使用正则表达式来搜索文本。例如,要查找所有包含 "word1" 或 "word2" 的行,可以使用:
grep 'word1\|word2' file
-
忽略大小写:
- 使用
-i选项可以忽略大小写,使搜索不区分大小写。例如:
grep -i 'pattern' file
-
显示行号:
- 使用
-n选项可以显示匹配行的行号。例如:
grep -n 'pattern' file
-
限制匹配的行数:
- 通过指定
-m后面的数字参数,可以控制grep仅匹配指定数量的行并停止搜索。
grep -m 3 'pattern' file
查找匹配 "pattern" 的前三行,一旦找到三个匹配,它将停止搜索,而不会继续查找文件中的其他匹配行。
-
递归搜索目录:
- 使用
-r选项可以递归搜索指定目录下的所有文件。例如:
grep -r 'pattern' /path/to/directory
-
统计匹配行数:
- 使用
-c选项可以统计匹配模式的行数,而不是显示匹配的行。例如:
grep -c 'pattern' file
-
反向匹配:
- 使用
-v选项可以显示不包含匹配模式的行。例如:
grep -v 'pattern' file
-
使用管道:
grep命令可以与其他命令一起使用,通过管道来处理文本数据。例如,可以使用cat命令查看文件内容并将其传递给grep进行搜索:
cat file.txt | grep 'pattern'
-
显示匹配模式的字符数:
- 使用
-o选项可以仅显示匹配模式的字符,而不是整个匹配行。
grep -o 'pattern' file
-q 选项是 grep 命令的一个安静(quiet)选项,通常用于在脚本中进行文本搜索操作时。当你使用 -q 选项时,grep 不会在终端上显示任何匹配行或输出,而是用于检查文本是否包含匹配模式。
以下脚本检查文件中是否包含 "pattern":
if grep -q 'pattern' file; then
echo "Pattern found in the file."
else
echo "Pattern not found in the file."
fi
静默匹配: 如果你只对匹配与否感兴趣,而不关心匹配的具体行内容,那么使用 -q 选项可以避免不必要的输出。
执行操作基于匹配: 你可以根据匹配结果执行其他操作,例如,如果匹配模式存在,则执行某些命令或处理。
-q 选项通常与脚本编程一起使用,用于自动化文本搜索和处理任务,而不需要显示匹配内容。
-
打印匹配行的上下文:
- 使用 -A 和 -B 选项可以打印匹配行的上下文行。例如,显示匹配行和它前后的两行:
grep -A 2 -B 2 'pattern' file
-
-C
- 选项用于在 grep 命令中指定上下文行的数量,以便显示匹配模式的周围文本行。可以使用 -C 后面跟着一个数字参数,该参数表示要显示的上下文行数。这对于更好地理解匹配行的上下文非常有用。
- 例如,如果想在匹配行的上下文中显示两行文本,可以使用
-C 2选项,如下所示:
grep -C 2 'pattern' file
-
-e -
选项在
grep命令中用于指定要匹配的模式或正则表达式。它通常用于区分多个模式,以便在同一次grep命令中搜索多个模式。你可以使用
-e后面跟着要匹配的模式或正则表达式,如下所示:
grep -e 'pattern1' -e 'pattern2' file
- 这将在文件中同时搜索 "pattern1" 和 "pattern2",并显示包含这些模式的行。
-e选项非常有用,当你需要在同一次搜索中匹配多个不同的模式时。这可以简化命令并减少不必要的重复。-
-w -
选项是
grep命令的一个选项,它用于确保匹配的模式是整个单词,而不是单词的一部分。这对于确保准确匹配整个单词非常有用,而不是包含该单词的子字符串。例如,如果你想查找包含单词 "apple" 的行,而不是包含 "pineapple" 或 "apples" 的行,你可以使用
-w选项:
grep -w 'apple' file
- 这将只匹配包含单词 "apple" 的行,而不会匹配包含 "pineapple" 或 "apples" 的行。
-w选项对于确保精确的单词匹配非常有用,尤其是在处理文本数据时需要区分单词。
-E
选项是 grep 命令的一个扩展正则表达式选项,它允许你使用更强大的正则表达式语法来进行文本搜索。通常,grep 使用基本正则表达式语法,但当你使用 -E 选项时,可以使用扩展正则表达式语法。
扩展正则表达式语法支持更多的元字符和模式匹配选项,包括括号分组、重复次数限制、字符类等。这使得更复杂的模式匹配变得可能。
以下是一些使用 -E 选项的示例:
- 使用括号分组:
grep -E '(apple|banana)' file
这将匹配包含 "apple" 或 "banana" 的行。
- 使用重复次数限制:
grep -E 'a{2,4}' file
这将匹配包含 2 到 4 个连续的 "a" 字符的行。
- 使用字符类:
grep -E '[0-9]{3}-[0-9]{2}-[0-9]{4}' file
这将匹配包含美国社会安全号码的行,其格式为 "###-##-####"。
-E 选项允许你更灵活地定义和匹配模式,特别是在需要更复杂的文本搜索和分析时非常有用。它扩展了 grep 命令的正则表达式功能。
-f
选项是 grep 命令的一个选项,它允许你从一个文件中读取内容列表,然后在指定的文件中搜索这些内容。这对于需要同时搜索多个内容的情况非常有用。
使用 -f 选项时,你需要指定一个包含内容的文件,grep 将会按照文件中内容的顺序逐个匹配这些内容。例如:
grep -f patterns.txt data.txt
上述命令将从 patterns.txt 文件中读取内容,然后在 data.txt 文件中搜索这些内容,显示包含任何模式的行。
patterns.txt 文件的内容可能如下所示:
apple
banana
cherry
这个文件包含了要在 data.txt 文件中搜索的内容列表。
使用 -f 选项的一个主要用途是在需要搜索多个相关内容的情况下,可以将这些内容保存在一个文件中,而不必在命令行中逐个指定它们。这对于处理大量内容或需要定期更新内容列表的情况非常方便。
-r
选项是 grep 命令的一个递归选项,用于在指定目录及其子目录中递归地搜索文件内容。这对于在整个目录结构中查找匹配模式的文件非常有用。不能操作软连接
使用 -r 选项时,你需要指定一个目录作为搜索的起始点,grep 将会递归搜索这个目录及其所有子目录中的文件。例如:
grep -r 'pattern' /path/to/directory
上述命令将从 /path/to/directory 目录开始递归搜索,找到包含 "pattern" 的文件并显示匹配行。
递归搜索非常适合在大型目录结构中查找特定模式的文件,尤其是当你不确定模式所在的确切位置时。你可以使用 -r 选项来搜索整个目录树,而不必手动进入每个子目录进行搜索。
在大多数 grep 版本中,-R 选项与 -r 选项类似,用于递归搜索目录及其子目录中的文件内容。它通常用于 Linux 系统中的 grep 命令。可以处理软连接
grep -R 'pattern' /path/to/directory
与 -r 相似,-R 选项也用于递归搜索指定目录下的文件内容,寻找包含指定模式的行。这对于在整个目录结构中搜索匹配的内容非常有用。
在一些 grep 版本中,-R 可能默认启用,因此使用它与使用 -r 没有明显区别。在另一些版本中,它可能略有不同,但主要目的仍然是递归搜索。
总的来说,-R 选项是 grep 命令的一个变体,用于在目录及其子目录中递归搜索文件内容,查找匹配指定模式的行。
-E 是 grep 命令的一个选项,用于启用扩展正则表达式的匹配模式。扩展正则表达式提供了更丰富的模式匹配功能,包括元字符和语法,使你能够更精确地定义搜索模式。
当你使用 -E 选项时,你可以在搜索模式中使用扩展正则表达式的元字符,例如 +、?、| 等,以及使用括号来创建分组。这允许你编写更复杂和具体的搜索模式。
当你使用 -E 选项时,你可以在搜索模式中使用扩展正则表达式的元字符,例如 +、?、| 等,以及使用括号来创建分组。这允许你编写更复杂和具体的搜索模式。
例如,以下命令使用 -E 选项来搜索包含 "apple" 或 "banana" 的行:
grep -E 'apple|banana' filename
这将匹配包含 "apple" 或 "banana" 的行,而不是仅匹配字面字符串 "apple|banana"。
-E 选项在需要进行高级模式匹配时非常有用,因为它允许你更自由地定义搜索条件。如果你不使用 -E 选项,则 grep 默认使用基本正则表达式,其中某些元字符(如 + 和 |)需要进行转义,而 -E 选项省去了这些转义步骤。
sed文本处理
是一种流编辑器,除非确认操作,否则数据一概不变,在缓冲区的数据,展示结束之后,会被立刻销毁。只有确定写入-i才会保存在硬盘中。在增改功能强大。
sed和grep的区别
sed 和 grep 是两个在 Linux 环境中用于文本处理的常用工具,它们有不同的功能和用途:
grep(Global Regular Expression Print):
-
功能:
grep用于在文本文件中搜索并匹配文本行,然后将匹配的行打印到标准输出。 -
主要用途:查找文本、筛选文件内容、搜索文件中的模式或关键词。
-
示例:
grep 'keyword' filename会在filename文件中查找包含 "keyword" 的行并显示出来。
sed(Stream Editor):
-
功能:
sed用于对文本进行编辑、替换、插入、删除等各种文本处理操作。 -
主要用途:编辑文本、批量替换文本、编辑文本文件内容。
-
示例:
sed 's/old_text/new_text/g' filename会在filename文件中将所有的 "oldtext" 替换为 "newtext"。
关键区别:
-
用途:
grep主要用于文本搜索和筛选,而sed主要用于文本编辑和替换。 -
输出:
grep会输出匹配的行,而sed可以修改文本文件中的内容。 -
语法:
grep使用简单的语法来查找文本,而sed使用更复杂的命令和正则表达式来进行文本编辑。 -
操作对象:
grep操作的对象是整行文本,而sed可以对文本中的特定部分进行编辑,如替换、删除、插入等。
虽然它们有不同的功能,但在实际使用中,经常会看到它们一起使用,以实现更复杂的文本处理任务。例如,可以使用 grep 来筛选出一组文本行,然后使用 sed 来对这些行进行进一步的编辑和处理。
功能
改
修改原文件:-i
sed -i 's/旧文本/新文本/g' 文件名
使用 -i 标志,sed 会直接修改原文件。
替换文本:s
sed 's/旧文本/新文本/g' 文件名
这会在指定文件中查找并替换所有匹配的 "旧文本" 为 "新文本"。如果省略 g 标志,它只会替换每行中的第一个匹配。
全局替换:g
sed 's/旧文本/新文本/g' 文件名
使用 g 标志可以替换每行中的所有匹配。
单字符替换:y
y命令是用于字符替换的命令,它用来将输入文本中的一个字符集映射成另一个字符集。单字符替换。按顺序替换y命令的基本语法如下:
sed 'y/字符集1/字符集2/' file
-
字符集1是要替换的字符集,将其中的字符映射为字符集2中对应位置的字符。 -
file是要处理的文件名。下面是一个简单的示例,将文本中的小写字母映射为大写字母:
echo "hello world" | sed 'y/a-z/A-Z/'
这将输出:
HELLO WORLD
y命令可以用于快速进行字符替换操作,特别是在需要将一个字符集替换为另一个字符集的情况下。
整行替换:c
这会在指定文件中查找并替换所有匹配的 "旧文本" 为 "新文本"。如果省略 g 标志,它只会替换每行中的第一个匹配。
c命令用于替换匹配到的文本行。它的语法如下:
sed 'c\替换后的文本' file
-
替换后的文本是你希望将匹配到的行替换成的新文本。 -
file是要处理的文件名。
c命令将会替换匹配到的整行文本,将其替换为指定的新文本。以下是一个简单的示例,将文件中包含"old text"的行替换为"new text":
sed '/old text/c\new text' input.txt
如果input.txt包含以下内容:
This is some old text.
This line does not contain the old text.
Another line with old text.
运行上述sed命令后,input.txt的内容将变成:
This is some new text.
This line does not contain the old text.
Another line with new text.
注意,c命令只会替换匹配到的行,如果文本中有多个匹配的行,它将分别替换这些行。
批量替换多个规则:-e
sed -e 's/规则1/替换1/g' -e 's/规则2/替换2/g' 文件名
这可以同时应用多个替换规则。
修改字符串位置:分组匹配
sed 修改字符顺序,你可以使用 sed 命令结合正则表达式来重新排列字符。下面是一个示例,假设你有一个文本文件包含一些单词,你想将每个单词中的字母逆序排列:
echo "apple banana cherry date" | sed -r 's/(\w)(\w+)/\2\1/g'
在这个示例中,sed 命令使用正则表达式来匹配每个单词中的第一个字母和其余的字母。(\w) 匹配一个字母,(\w+) 匹配一个或多个字母。然后,通过使用 \2\1,将第一个字母和其余的字母的顺序颠倒。
执行上述命令后,输出将如下所示:
palpe ananab yrrehc etad
增
插入行:i 在选定行的上面插入一行内容
sed '1i 新行内容' 文件名
这会在文件的第一行前插入新行。
追加行:a 在当前行的下面一行插入一行内容
sed '$a 新行内容' 文件名
这会在文件的最后一行后追加新行。
文件追加:r
r 命令用于读取指定文件的内容,并将其插入到 sed 处理的文本流中。r 命令的语法如下:
sed '/pattern/r filename' input.txt
/pattern/是一个正则表达式模式,用于匹配文本中的行。filename是要插入的文件名。
sed 将在匹配到 /pattern/ 的行之后,将 filename 文件的内容插入到文本流中。这在将外部文件内容插入到文本中或根据某些条件动态生成文本时非常有用。
以下是一个示例,假设有一个 data.txt 文件包含如下内容:
This is some data.
Insert file contents here.
More data.
如果我们有一个 insert.txt 文件包含要插入的文本,例如:
This text is inserted from another file.
我们可以使用 sed 的 r 命令将 insert.txt 的内容插入到 data.txt 文件中包含 "Insert file contents here." 的行之后:
sed '/Insert file contents here./r insert.txt' data.txt
执行上述命令后,data.txt 文件的内容将变为:
This is some data.
Insert file contents here.
This text is inserted from another file.
More data.
注意,r 命令是基于行的匹配,所以只会在匹配的行之后插入内容。如果需要在多个地方插入内容,可以多次使用 r 命令。
删
删除行:d
sed '/要删除的文本/d' 文件名
这将删除包含指定文本的行。
sed '/文本1/,/文本2/d' 文件名
删除文本1和文本2
sed '/文本1/!d' 文件名
不删除文本1
sed '/^$/d' 文件名
删除空行
sed -i '/^$/d' 文件名查
打印整个文件:
sed 'p' filename
这将打印文件的每一行,使输出与原文件一样。
打印指定行:
sed -n '5p' filename
这将只打印文件中的第5行。 -n选项取消默认输出。
打印行号范围:
sed -n '2,7p' filename
这将打印文件中的行号2到7的行。
打印匹配某个模式的行:
sed -n '/pattern/p' filename
这将打印包含匹配pattern的行。
打印所有行并将结果保存到新文件:
sed 'p' filename > newfile
这将将文件的内容打印到终端并将其保存到名为newfile的新文件中。
打印奇数行:
sed -n 'n;p' filename
这将打印文件中的奇数行。
打印偶数行:
sed -n 'p;n' filename
这将打印文件中的偶数行。
打印行号
sed -n '=p' 文件名
使用正则表达式:
sed 's/正则表达式/替换文本/g' 文件名
你可以使用正则表达式来匹配和替换文本。
从文件读取 sed 脚本:-f
sed -f scriptfile 文件名
你可以将 sed 脚本存储在一个文件中,然后使用 -f 选项执行。
awk
- awk 是一个强大的文本处理工具,它在 Linux 和其他 Unix-like 系统中广泛使用。
awk主要用于模式扫描和文本/数据提取。
特点
-
字段感知:
awk自动将每一行分割成多个字段,使得对特定列的操作变得非常简单。 -
模式匹配:
awk支持基于模式的处理,可以选择性地对匹配特定模式的行执行操作。 -
内置变量:
awk提供了多个内置变量,如NR(当前行号)、NF(字段数量)、FS(字段分隔符)等,以便于处理数据。 -
编程功能:
awk支持变量、算术运算、条件语句、循环和数组,使其能够执行复杂的文本处理任务。 -
默认分隔符是空格或者tab键,但是多个空格,多个tab键,他会自动压缩成一个。
基本用法
awk 的基本语法如下:
awk 'pattern { action }' input-file
- pattern: 一个可选的条件表达式,如正则表达式或比较表达式。只有当输入行匹配该模式时,后面的动作才会被执行。
- action: 一组在模式匹配时要执行的命令,通常是打印操作,但也可以是任何有效的
awk命令。 - input-file: 要处理的文件名。
-F:
指定输入字段的分隔符。
echo "John:Doe:30" | awk -F: '{print $1}'
输出:
John

-v:为 awk 程序中的变量赋值。
awk -v name=John 'BEGIN {print name}'
输出:
John
-f:
从文件中读取 awk 程序。
假设我们有一个名为 script.awk 的文件,内容如下:
{print $1}
使用以下命令执行该脚本:
echo "apple orange banana" | awk -f script.awk
输出:
apple
-c:
兼容模式。这个选项不常用,因为它主要是为了确保 awk 脚本在不同版本的 awk 之间保持兼容性。
-W:
指定 awk 的行为。例如,使用 POSIX 模式:
echo "apple orange banana" | awk -W posix '{print $1}'
输出:
apple
-o:
将 awk 程序的输出保存到指定的文件中。这个选项在某些 awk 实现中可能不可用。
echo "apple orange banana" | awk -o output.txt '{print $1}'
这会将输出保存到 output.txt 文件中。
打印文件的每一行:
awk '{print}' file.txt
打印特定字段:
打印文件的第一和第三字段:
awk '{print $1, $3}' file.txt
条件打印:
打印第二字段大于 50 的所有行:
awk '$2 > 50' file.txt
模式匹配:
打印包含 "error" 的所有行:
awk '/error/' file.txt
BEGIN 和 END 块:
在处理文件之前和之后执行操作:
awk 'BEGIN {print "Start Processing"} {print} END {print "End Processing"}' file.txt
定义数组
计算和统计:
计算文件中第二字段的总和:
awk '{sum += $2} END {print sum}' file.txt
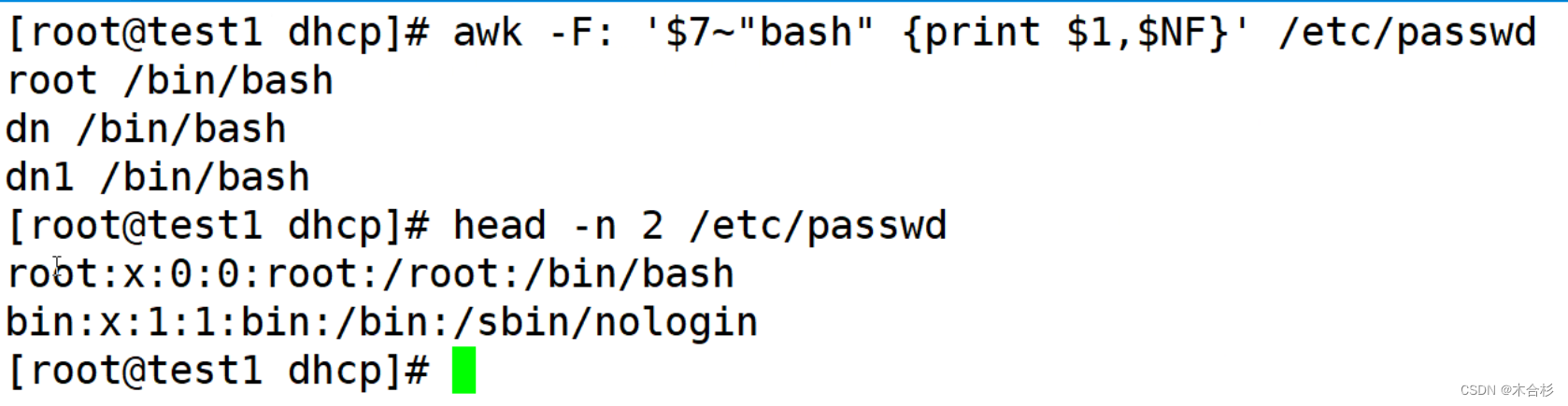
awk精确筛选




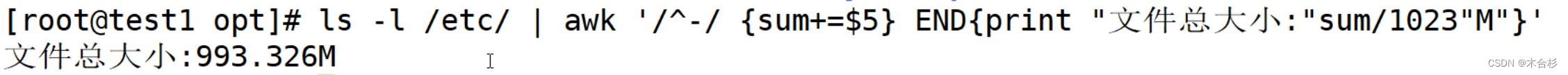 监控cpu
监控cpu

 sort排序
sort排序
Linux中的sort命令用于对文本文件的内容进行排序。它默认按照每行的字母顺序,对文件内容进行排序,但也可以根据需要进行自定义排序。以下是sort命令的一些常见用法和参数:
基本用法:
sort [选项] [文件]
常见选项:
-
-b:忽略每行前面开始出的空格字符。 -
-c:检查文件是否已排序,如果没有排序则输出相应的信息。 -
-d:按照字典顺序(区分大小写)排序。 -
-f:忽略大小写,按照字典顺序排序,默认把大写字母排在前面 -
-i:忽略非打印字符,只对可打印字符排序。 -
-n:按照数值大小排序。 -
-r:逆序排序。 -
-t:指定字段分隔符。 -
-k field1[,field2]:按指定字段排序。
示例:
- 对文件进行默认排序:
sort file.txt
- 忽略大小写进行排序:
sort -f file.txt
- 按照第二列字段进行排序,以逆序输出:
sort -t',' -k2,2 -r file.csv
- 检查文件是否已排序:
sort -c file.txt
5.按行号排序
cat -n file.txt | sort -nr
6.按源文件顺序排序,并输出到一个指定文件
cat -n /etc/passwd | sort -no file.txt
uniq去重
按行进行处理,去除连续重复的行
uniq [OPTION]... [INPUT [OUTPUT]]
uniq [OPTION]... [INPUT [OUTPUT]]
-
OPTION:可选参数,用于指定uniq命令的行为。 -
INPUT:可选参数,指定要处理的输入文件。如果未提供输入文件,则uniq将从标准输入读取数据。 -
OUTPUT:可选参数,指定输出结果的文件。如果未提供输出文件,则uniq将结果输出到标准输出。
常用选项
-
-d:仅显示重复的行。 -
-u:仅显示不重复的行。 -
-c:显示每行重复出现的次数。
下面是一些示例用法:
- 检查文件并删除其中重复的行,并在标准输出中显示不重复的行:
uniq input.txt
- 检查文件并删除其中重复的行,然后将结果输出到另一个文件:
uniq input.txt output.txt
- 显示文件中重复的行和它们出现的次数:
uniq -c input.txt
- 只显示文件中重复的行,不显示不重复的行:
uniq -d input.txt
这些是uniq命令的一些基本用法。根据您的需求,您可以使用不同的选项来处理文本文件中的重复行。
tr 替换删除压缩
tr是一个用于字符转换的命令行工具。它通常用于替换文本中的字符、删除字符或对字符进行转换。
常见用法
-d:删除指定字符集中的字符。
tr -d '0-9' < input.txt > output.txt
这个选项将删除输入文件中的所有数字字符。
-s:压缩字符集中的重复字符。
echo "hello" | tr -s 'l'
这个选项将字符串 "hello" 中的重复字符 'l' 压缩为单个字符。
-c:对字符集取补集。保留未被指定的字符,而将指定字符集以外的字符替换为特定字符
echo "hello" | tr -c 'a-z' '*'
这个选项将输入字符串中的非小写字母字符替换为 '*'。
-t:指定要转换的字符集。
echo "123" | tr -t '123' 'ABC'
这个选项将输入字符串中的 '1' 替换为 'A','2' 替换为 'B','3' 替换为 'C'。
-u:将输出限制为不重复的字符。
echo "hello" | tr -u 'l'
这个选项将输出字符串中的 'l' 重复字符去除,结果为 "helo"。
cut剪切
cut命令是一个用于文本处理的实用程序,通常用于从文本文件中剪切出指定部分并将结果输出到标准输出或另一个文件。cut命令的主要用途是从每行文本中截取指定字段或字符,以便进一步处理或分析数据。
常见用法
-
-b:按字节位置切割。 -
示例:提取文本文件的第 2 到 5 个字节。
cut -b 2-5 input.txt
-
-c:按字符位置切割。 -
示例:提取文本文件的第 2 到 5 个字符。
cut -c 2-5 input.txt
-
-d:指定字段的分隔符。 -
示例:使用逗号作为分隔符,提取逗号分隔的第 2 个字段。
cut -d ',' -f 2 input.txt
-
-f:指定要提取的字段。 -
示例:提取制表符分隔的文本文件的第 3 个字段。
cut -f 3 input.txt
-
--complement:反选,输出未包含指定字段的部分。 -
示例:提取文本文件的第 1 到 3 个字段之外的部分。
cut --complement -f 1-3 input.txt
-
-s:在没有匹配到分隔符的行上不输出任何内容。 -
示例:在逗号分隔的文件中,只提取包含两个字段的行。
cut -d ',' -f 1,2 -s input.txt
如何对文件进行拆分
现有一个日志文件,5G,直接打开速度很慢,有什么办法优化呢?
对文件进行拆分,文件大于2G按大小分,小于按行分
split分割
split命令用于将一个文件分割成多个较小的文件,可以按照不同的标准进行分割,如文件大小、行数或字节数。以下是split命令的基本语法和一些常见选项:
split [选项] [要切割的文件] [输出文件名的前缀]
常见用法
常见选项包括:
-
-b<字节>:指定每个输出文件的大小,单位为字节。您可以使用K(千字节)、M(兆字节)、G(千兆字节)等单位。 -
-C<字节>:与-b选项类似,但它尽量维持每行的完整性,确保不会在行的中间切割。 -
-l<行数>:指定每个输出文件包含的行数。 -
-a<后缀长度>:指定输出文件名的后缀长度,默认为2,通常以字母组合(如aa、ab、ac)的顺序排序。
以下是一些示例用法:
- 将文件分割为固定大小的块(以MB为单位):
split -b 10M largefile.txt output
- 将文件分割为包含100行的部分:
split -l 100 myfile.txt output
- 指定后缀长度为3,并分割文件:
split -a 3 myfile.txt output
paste合并
合并文件的行。它按顺序打印来自每个文件的相应行,每行之间用制表符分隔并并列显示。
以下是一些 paste 命令的常用选项和示例:
基本语法如下:
paste [选项] [文件1名称] [文件2名称]...
常见用法
一些常用选项包括:
-
-d或--delimiters=LIST:允许指定一个定界符的列表,该定界符将用于分隔每个文件中的文本行。 -
-s或--serial:以串联方式合并文件,而不是并联方式。这意味着第一个文件的第一行将与第二个文件的第一行合并,以此类推。 -
-u或--uniq:在合并文件时删除任何重复的行。
示例:
- 合并两个文件并使用制表符分隔它们的行:
paste file1.txt file2.txt
- 合并三个文件并使用逗号作为定界符:
paste -d',' file1.txt file2.txt file3.txt
- 以串联方式合并两个文件:
paste -s file1.txt file2.txt
几个简单示例:
统计当前主机的连接状态: [root@test1 opt]# ss -nat | grep -v 'State'| cut -d " " -f 1 | sort | uniq -c 统计当前主机的连接数: [root@test1 opt]# ss -nt | tr -s " " | cut -d " " -f 4 | sort -n | uniq -c
匹配查找日志时


















 983
983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









