






目录
为什么我要写这篇文章呢?因为前几天一直在网上找数据解析相关的帖子,但是一直没有找到我想要的,都不是特别详细,因此我才想要写下这篇文章。像JSON、XML这些在开发中还是很常用的,可以说是必须掌握,所以我也是为了如果今后我忘记了这方面相关的知识点,还可以回来看看,另外也是希望能给学习编程的网友带来帮助。
XML
什么是XML
X(extensible:可扩展的)
M(markup:标记)
L(language:语言)
把上面每个单词翻译过来就是可扩展的标记语言,学过HTML的一定知道HTML就是超文本标记语言,它主要的目的就是制作网页。将信息显示在网页上,而XML的宗旨在于传输信息。下面是XML的主要作用:
- 存储数据:IO流和数据库也能存储数据,但是IO流读写数据的速率较低,而数据库所占用的空间很大,比如说一些单机游戏就不适合用数据库,这时候就能体现出XML的优越性。
- 传输数据:将数据写在XML文件中,通过网络传输给其他PC或者传输给后台或者前台。
- 做配置文件:目前这是XML最重要的一个用处。
XML的特点
- 平台无关性:和Java一样,都具有跨平台的特点,即同一个XML文件在Windows、Linux等平台上都是可以的。
- 具有自我描述性。
- 90%以上的语言都是支持XML的,有的语言不支持是因为这些语言发布的时候,XML还没有发布。
XML的语法规则
- XML文件必须有且仅有一个根元素。
- XML元素(标签)必须匹配有对应的结束标签,且必须是正确的嵌套关系。
- XML元素对大小写敏感。
- XML元素的属性必须加引号(单引号双引号都可以)。
在HTML中,所有的标签都是官方定义好的,比如说<br>、<a>...,我们只需要拿来用就行,不允许我们自定义一个标签,但是在XML中,我们是可以自定义标签的,想叫啥就叫啥。下面是一个正确的XML文件的格式:
<students>
<student name="张三" age="20">
<id>111</id>
<sex>男</sex>
</student>
<student name="李四" age="21">
<id>222</id>
<sex>女</sex>
</student>
<student name="王五" age="22">
<id>333</id>
<sex>男</sex>
</student>
</students>
CDATA区
什么是CDATA区呢?其实它起到一个转义的功能,在Java等编程语言中,如果想要一个特殊字符体现出它本身的含义,例如下面这句代码:我们想输出"a"。
String str = ""a"";
这句代码在程序中就会报错,原因是默认第一个左引号和第二个左引号匹配,这样匹配之后就不符合Java语法规范,所以报错。因此得用/进行转义。以下是正确的写法。
String str = "\"a\"";
那么XML语言中的转义是\吗,其实不是的,XML语言中要实现转义就需要用到CDATA区,如下面XML语句:
<div>10<5</div>
上面这句代码也会报错,因为系统默认会把10<5中的小于号看做是左尖括号,导致语法错误而报错。正确的格式如下:
<div><![CDATA[10<5]]>
解析XML文件
DOM方式解析
要求解析器将整个XML文件全部加载到内存中,生成一个Document对象。
优点:
元素和元素之间保留结构和关系,可以针对元素进行增删改查操作。
缺点:
如果XML文件太大,可能会导致内存溢出。但是这个缺点可能一辈子都遇不到,因为一般的文件都不是很大,用DOM方式来解析都是可以的。
SAX方式解析
是一种快速高效的解析方式。它强行扫描,它是逐行扫描的,边扫描边解析,并且以时间驱动的方式来进行具体的解析,每解析一行都会触发一个事件。
优点:
不会出现内存溢出的问题,可以处理大文件。
缺点:
只能读,不能写。
解析器就是根据不同的解析方式提供具体的实现,为了方便开发人员来解析XML文件,设计者们提供了一些方便操作的类库。比如dom4j:比较简单的XML解析的类库,又比如Jsoup:功能强大的DOM方式解析的类库,尤其对HTML的解析更加方便。
dom4j工具
dom4j是现在比较流行的一种解析工具,里面提供了解析XML文件的jar包。在使用dom4j解析之前,首先要去官方网站下载它的jar包,下面是详细的下载过程。
下载dom4j的jar包
dom4j网址:https://dom4j.github.io/
或者直接在浏览器搜索dom4j官网。
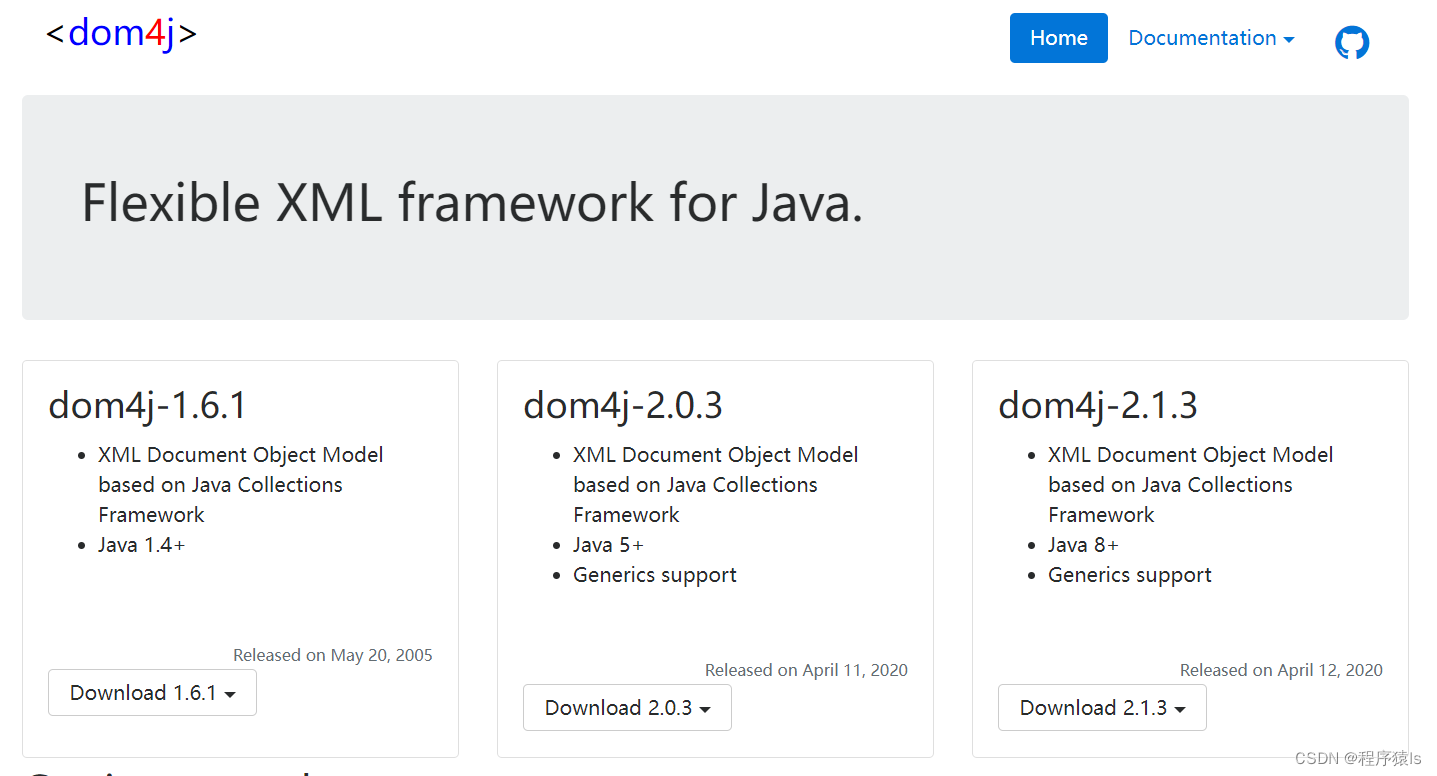
在官网的首页可以看到dom4j的三个版本,我们选择dom4j-2.1.3版本,因为这个是支持Java8及之后的语法。
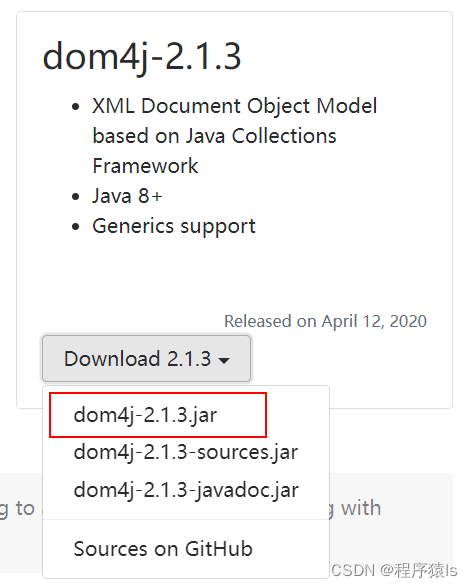
点击这个jar包进行下载。下载好了可能会出现以下提示:

这个时候不用担心,直接点击保留就OK。
导入下载好的jar包
这里有两种导入jar包的方式(针对IDEA),第一种方式是点击File文件选择Project Structure...。
选择Libraries,点击+号,然后就在你本地文件中找到刚刚下载好的jar包。
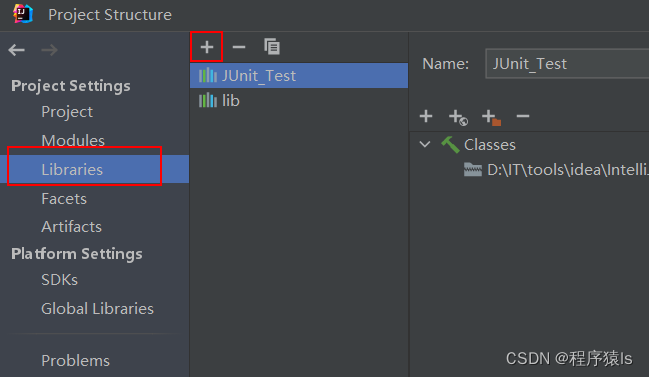
点击OK。
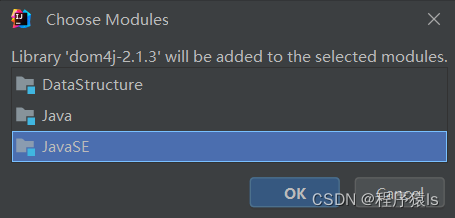
到这里就导入成功了。这个时候你就可以使用dom4j工具对XML文件进行解析了。但是这种导入的方式有一个缺点:如果你要把你这整个项目发送给别人,你下载的jar包存储的路径和别人的jar包路径肯定是不一样的,这样的话别人在他电脑上进行解析就会出错。因此我们引出第二种导入方式。其步骤如下:
- 在项目中创建一个包,习惯上我们将这个包命名为lib。
- 复制刚刚下载好的jar包。
- 将复制的jar包粘贴到创建的lib包下。
- 鼠标右键点击lib包,选择Add as Library...。
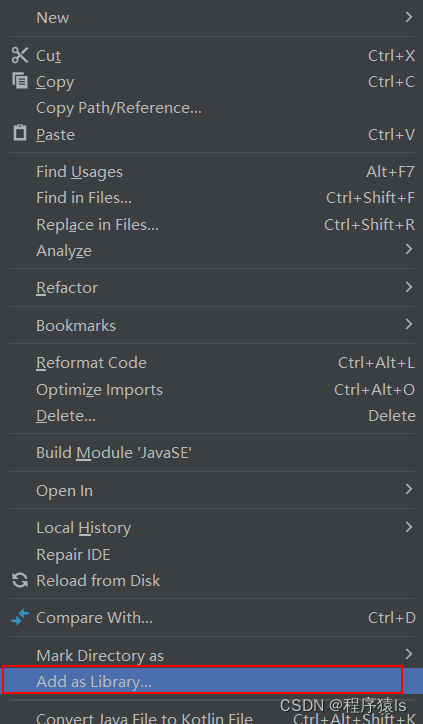
最后Level选择Project Library,最后点击OK即可。

利用dom4j解析XML文件
现在我们就可以使用dom4j工具对XML文件进行解析了。下面我们就正式的来使用dom4j来解析XML文件了。
第一步:创建解析器对象。
第二步:使用解析器对象读取XML文件生成Document对象。
第三步:根据Document对象获取XML文件的元素(标签)信息。(一般都是先获取到根标签)
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.junit.jupiter.api.Test;
import java.util.List;
public class Test01 {
@Test
public void Test() { //这里的Test只是一个方法名,和上面注解中的Test不一样
SAXReader saxReader = new SAXReader(); //创建一个解析器对象
try {
//read()方法有DocumentException异常
//使用解析器对象读取XML文件生成Document对象
Document document = saxReader.read(Test01.class.getClassLoader().getResource("数据解析\\students.xml"));
Element rootElement = document.getRootElement(); //获取根标签
System.out.println(rootElement.getName()); //获取根标签的名字
List<Element> elements = rootElement.elements(); //获取根标签下所有的子标签并存入List集合中
for(Element element : elements) { //遍历所有的子标签并获取子标签的名字
System.out.println(" 根标签下的子标签的名字: " + element.getName()); //获取子标签的名字
System.out.println(" 子标签上的属性: " + element.attributeValue("name")); //获取标签上的属性,注意这里如果属性名不存在则返回null
System.out.println(" 子标签上的属性: " + element.attributeValue("age"));
//如果子标签下还有子标签,直接套娃就行
List<Element> elements1 = element.elements(); //获取根标签的子标签下的子标签
for(Element element1 : elements1) {
System.out.println(" 该标签的名字为: " + element1.getName());
System.out.println(" 该子标签的文本信息: " + element1.getText());
}
}
/*
上面我们是一次性获取全部子标签,那么我们如何获取指定子标签呢?
使用element(String s)方法: s为指定的标签名。
如果子标签中有不止一个指定的标签名时,默认为第一个。
如下面的实例中根标签下有三个student标签,默认为第一个。
*/
System.out.println("--------------------------------------------------");
Element student = rootElement.element("student");
String id = student.elementText("id"); //获取该学生对象的id标签中的文本
System.out.println("第一个student对象的id是: " + id);
}catch(DocumentException e) {
e.printStackTrace();
}
}
}运行结果展示:
students
根标签下的子标签的名字: student
子标签上的属性: 张三
子标签上的属性: 20
该标签的名字为: id
该子标签的文本信息: 111
该标签的名字为: sex
该子标签的文本信息: 男
根标签下的子标签的名字: student
子标签上的属性: 李四
子标签上的属性: 21
该标签的名字为: id
该子标签的文本信息: 222
该标签的名字为: sex
该子标签的文本信息: 女
根标签下的子标签的名字: student
子标签上的属性: 王五
子标签上的属性: 22
该标签的名字为: id
该子标签的文本信息: 333
该标签的名字为: sex
该子标签的文本信息: 男
--------------------------------------------------
第一个student对象的id是: 111
如何创建XML文件
和创建普通文件的步骤一样,唯一不一样的就是需要在文件名后面加后缀名.xml,表示这是一个XML文件。然后里面的编写具体的XML语句。但是我们如何利用dom4j来创建一个XML文件呢?其实dom4j的官网上有具体的步骤。
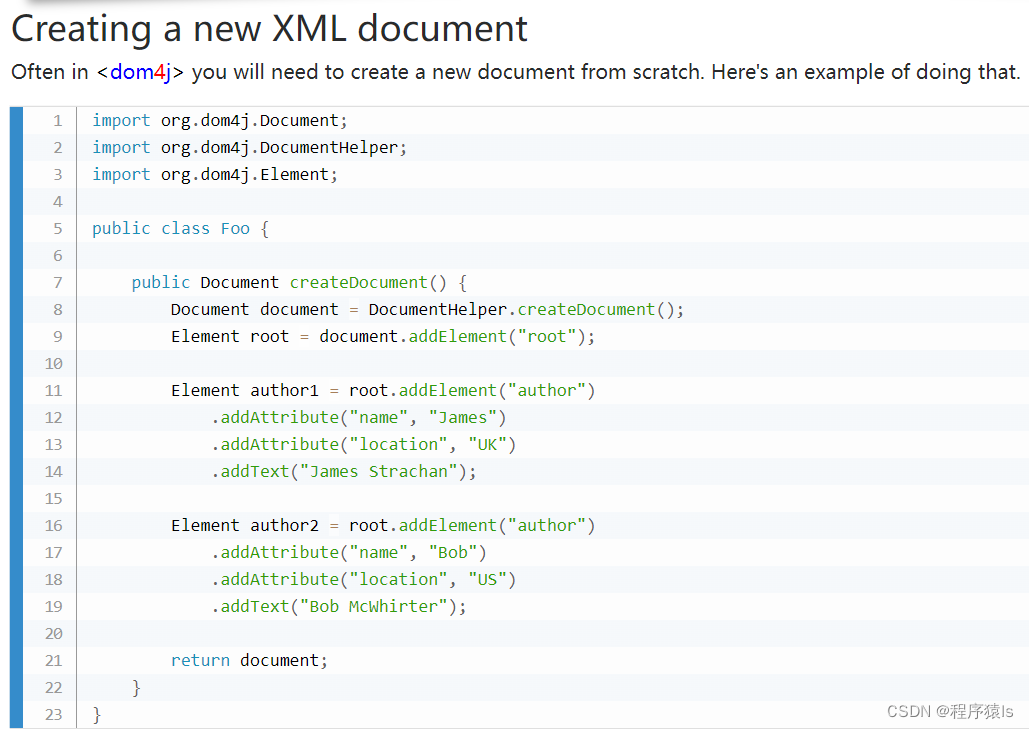
那我们就直接跟着官网给的代码来写呗!
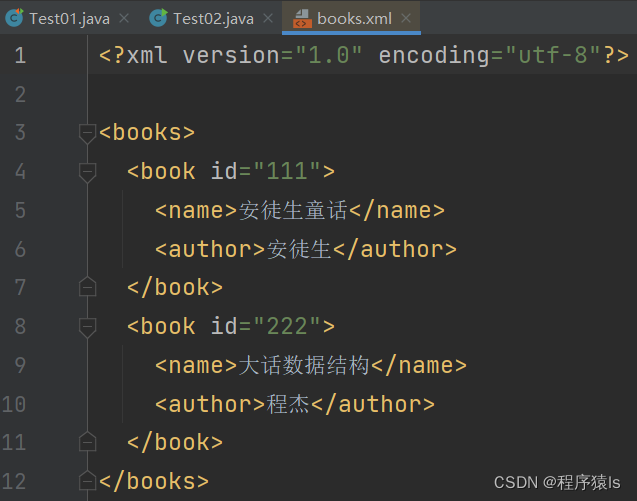
写的XML文件内容如下:
<books>
<book id="111">
<name>安徒生童话</name>
<author>安徒生</author>
</book>
<book id=""222>
<name>大话数据结构</name>
<author>程杰</author>
</book>
</books>
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.XMLWriter;
import java.io.FileOutputStream;
import java.io.IOException;
public class Test02 {
public static void main(String[] args) {
test();
}
public static void test() {
Document document = DocumentHelper.createDocument(); //创建一个XML文件对象
Element rootElement = document.addElement("books"); //添加根标签
Element book1 = rootElement.addElement("book"); //添加根标签的子标签(第一本书)
Element field1 = book1.addAttribute("id", "111"); //添加跟标签的子标签的属性
Element name1 = book1.addElement("name"); //添加根标签的子标签的子标签
Element author1 = book1.addElement("author"); //添加根标签的子标签的子标签
Element text1 = name1.addText("安徒生童话"); //添加书名
Element text2 = author1.addText("安徒生"); //添加书的作者
Element book2 = rootElement.addElement("book"); //添加第二本书
Element field2 = book2.addAttribute("id", "222");
Element name2 = book2.addElement("name");
Element author2 = book2.addElement("author");
Element text3 = name2.addText("大话数据结构");
Element text4 = author2.addText("程杰");
OutputFormat format = OutputFormat.createPrettyPrint(); //创建XML文件格式化对象,为了美化XML文件
format.setEncoding("utf-8"); //设置字符集为utf-8
FileOutputStream fos = null; //创建输出流
XMLWriter writer = null; //创建输出流对象,专门写XML文件的输出流
try {
fos = new FileOutputStream("books.xml");
writer = new XMLWriter(fos,format);
writer.write(document);
}catch(IOException e) {
e.printStackTrace();
}finally {
if(fos != null) {
try {
fos.close();
}catch(IOException e) {
e.printStackTrace();
}
}
if(writer != null) {
try {
writer.close();
}catch(IOException e) {
e.printStackTrace();
}
}
}
}
}运行 结果展示:
在dom4j的官网中将一个XML文件写到磁盘上是用的一下方式。

但是这种方式没有格式化,写出的XML文件在一行显示,看起来不方便。因此我换了一种写出的方式。
Jsoup工具
除了dom4j工具解析XML之外,Jsoup也是一种比较常用的解析工具,Jsoup不仅可以解析XML文件,还可以用来解析HTML文件。和dom4j一样,在使用它之前还是要导入Jsoup的jar包,具体怎么导入请参考dom4j的jar包导入的方式。下面我们利用它来解析上面我们刚创建的books.xml文件。
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
public class Test03 {
public static void main(String[] args) {
test();
}
public static void test() {
Document document = null;
try {
document = Jsoup.parse(new File("books.xml"), "utf-8");
Element book1 = document.getElementById("111");
if(book1 != null) { //book1可能为空,这里要避免空指针异常
System.out.println(book1.attributes());
Elements name = book1.getElementsByTag("name"); //注意这里返回值类型是Elements,可能返回值有多个
System.out.println("返回元素的个数为: " + name.size());
System.out.println(name.get(0)); //因为books.xml文件中每个book里面只有一个name标签,所以这里只有一个元素
name = document.getElementsByTag("book"); //有两本书,因此此时返回值有两个
System.out.println("返回元素的个数为: " + name.size());
System.out.println("第一本书的名字叫: " + name.get(0).getElementsByTag("name").text());
System.out.println("第二本书的名字叫: " + name.get(1).getElementsByTag("name").text());
}
}catch(IOException e) {
e.printStackTrace();
}
}
}结果展示:
id="111"
返回元素的个数为: 1
<name>
安徒生童话
</name>
返回元素的个数为: 2
第一本书的名字叫: 安徒生童话
第二本书的名字叫: 大话数据结构
JSON
为什么要用JSON
上面XML格式的文件其实有一个弊端,比如拿上面创建的books.xml文件来说,假如我们要把这个文件进行网络传输,我们会发现里面的有效数据还没有标签多,也就是说我们只需要里面的数据,并不想要这些标签,但是又不得不连带着标签一起传输,这就使得传输的效率降低。因此就有了JSON。JSON是一种更轻量级的数据交换格式。
JSON的语法格式
- 由一对中括号包裹。
- 里面的数据以键值对的形式存在。
- 键值对中的键必须是String类型,值的类型随意。
- 每组数据之间使用逗号隔开,最后一组数据后面没有逗号。
下面是一个正确的JSON示例。
{"name" : "张三","age" : 20,"sex" : "男",
"name" : "李四","age" : 18,"sex" : "女"}
JSON数组对象
顾名思义,JSON数组对象就是把每一个JSON作为一个对象构成一个数组,这个数组里面的每一个元素都是一个JSON对象。如我们将上面的示例改写成JSON数组对象的形式。
[{"name" : "张三","age" : 20,"sex" : "男"},
{"name" : "李四","age" : 18,"sex" : "女"}
]
bejson工具
这是一个检测一个文件是否符合JSON格式的小工具,对于我们的开发很有帮助。例如我们将上面的JSON数组对象粘贴上去检测看是否满足JSON格式。
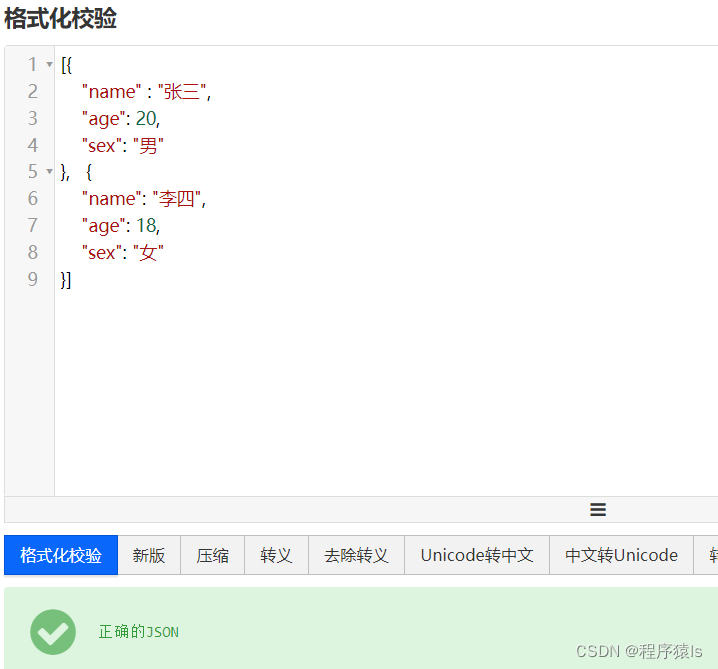
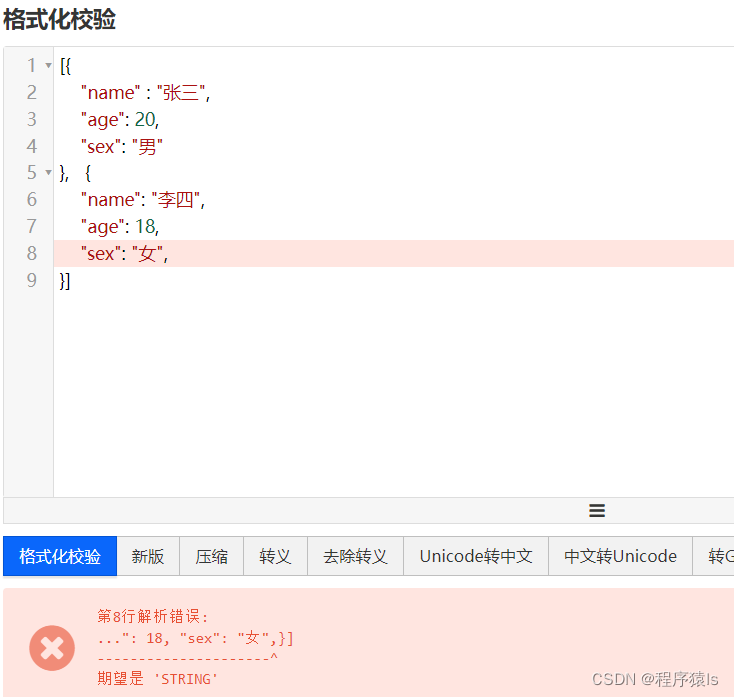
可以看到格式化校验后它会自动帮我们格式化,使它更加美观和规整。另外,它还能帮我们检查语法错误,如下:我给“女”后面再添加一个逗号,它就会检测出来具体是哪出错了,并给我们相应的提示。
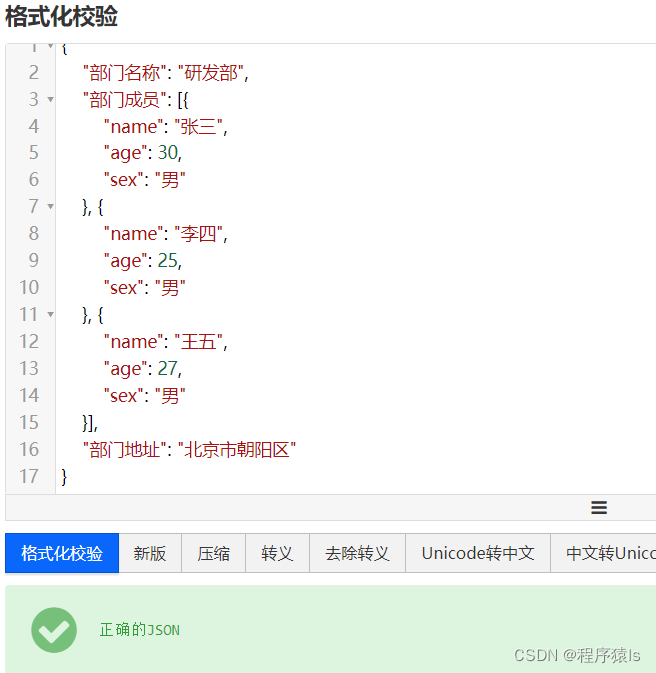
JSON嵌套
JSON里面也是可以套JSON的。如下示例。
{"部门名称" : "研发部",
"部门成员" : [{"name" : "张三","age" : 30,"sex" : "男"},
{"name" : "李四","age" : 25,"sex" : "男"},
{"name" : "王五","age" : 27,"sex" : "男"}
],
"部门地址" : "北京市朝阳区"
}
JSON的解析
fastjson工具
官网:https://github.com/alibaba/fastjson
fastjson是阿里巴巴研发的一个解析JSON的小工具,它最大的优势就是速度快,效率高,但是它解析的时候有很多bug,现在fastjson已经到了2版本了,但我用的是fastjson1.2.79版本。因为2版本还需要导入一些maven的配置,比较麻烦。
和上面的dom4j一样,在使用fastjosn之前得先导入它的jar包。具体导入过程和dom4j一样。下面就来正式的使用fastjson来解析JSON。
Java对象转换成JSON串
这是一个将数据从后台到前端的过程。
//实体类
public class Emp {
private String name;
private int age;
private String sex;
public Emp() {
}
public Emp(String name,int age,String sex) {
this.name = name;
this.age = age;
this.sex = sex;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
@Override
public String toString() {
final StringBuffer sb = new StringBuffer("Emp{");
sb.append("name='").append(name).append('\'');
sb.append(", age=").append(age);
sb.append(", sex='").append(sex).append('\'');
sb.append('}');
return sb.toString();
}
}import com.alibaba.fastjson.JSON;
import java.util.ArrayList;
public class JSONTest02 {
public static void main(String[] args) {
Emp emp1 = new Emp("张三",25,"男");
String s = JSON.toJSONString(emp1); //将一个JavaBean对象转换成一个JSON串
/*要注意这里的JavaBean对象是一种特殊的Java对象,JavaBean类中必须私有化属性,
向外提供无参构造器、set()方法和get()方法,不然转换的结果为{}。
*/
System.out.println(s);
Emp emp2 = new Emp("李四",28,"女");
Emp[] arr = {emp1,emp2};
String s1 = JSON.toJSONString(arr); //将一个数组对象转换成一个JSON串
System.out.println(s1);
ArrayList<Emp> list = new ArrayList<>();
list.add(emp1);
list.add(emp2);
String s2 = JSON.toJSONString(list); //将一个List集合转换成一个JSON串,结果和s1一样,因为集合也可以看成是数组
System.out.println(s2);
}
}结果展示:
{"age":25,"name":"张三","sex":"男"}
[{"age":25,"name":"张三","sex":"男"},{"age":28,"name":"李四","sex":"女"}]
[{"age":25,"name":"张三","sex":"男"},{"age":28,"name":"李四","sex":"女"}]
这个结果我们仔细一看它的键的顺序并不是按照我们声明的顺序来的,它默认是按照字典序排的 ,那么我们怎么指定它转换成JSON串之后键的顺序呢?阿里巴巴在fastjson中提供了一个注解——JSONField,这个注解专门作用在JavaBean类中的属性上,它里面有一个ordinal属性来指定排序规则。
//实体类
import com.alibaba.fastjson.annotation.JSONField;
public class Emp {
@JSONField(ordinal = 1)
private String name;
@JSONField(ordinal = 2)
private int age;
@JSONField(ordinal = 3)
private String sex;
public Emp() {
}
public Emp(String name,int age,String sex) {
this.name = name;
this.age = age;
this.sex = sex;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
@Override
public String toString() {
final StringBuffer sb = new StringBuffer("Emp{");
sb.append("name='").append(name).append('\'');
sb.append(", age=").append(age);
sb.append(", sex='").append(sex).append('\'');
sb.append('}');
return sb.toString();
}
}结果展示:
{"name":"张三","age":25,"sex":"男"}
[{"name":"张三","age":25,"sex":"男"},{"name":"李四","age":28,"sex":"女"}]
[{"name":"张三","age":25,"sex":"男"},{"name":"李四","age":28,"sex":"女"}]
另外,这个注解还有以下两个属性:
- name:主要的作用是转换成JSON串时候将对象的属性名修改为指定的名称,因为有时候后台的属性名可能会很长,这样很占用空间,因此我们最好给它改的简洁一点。
- serialize:实现选取JavaBean类中的属性进行序列化。因为有时候我们并不需要将全部属性都进行序列化。这个属性一般不和ordinal属性结合使用,因为serialize修饰的属性都不进行序列化了,自然就不用排序了。
//实体类
import com.alibaba.fastjson.annotation.JSONField;
public class Emp {
@JSONField(ordinal = 1)
private String name;
@JSONField(ordinal = 2)
private int age;
@JSONField(serialize = false)
private String sex;
public Emp() {
}
public Emp(String name,int age,String sex) {
this.name = name;
this.age = age;
this.sex = sex;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
@Override
public String toString() {
final StringBuffer sb = new StringBuffer("Emp{");
sb.append("name='").append(name).append('\'');
sb.append(", age=").append(age);
sb.append(", sex='").append(sex).append('\'');
sb.append('}');
return sb.toString();
}
}结果展示:
{"name":"张三","age":25}
[{"name":"张三","age":25},{"name":"李四","age":28}]
[{"name":"张三","age":25},{"name":"李四","age":28}]
上面转换的JSON串都不直观,甚至看不出来是一个JSON串,如果想要对它进行格式化转换,只需要在转换的方法,即toJSONString()方法中添加一个true即可,这个参数表示格式化转换。
JSON串转换成Java对象
这是从前端到后台的过程。
import com.alibaba.fastjson.JSON;
import java.util.List;
public class JSONTest03 {
public static void main(String[] args) {
test();
}
public static void test() {
String jsonStr = "{\"name\": \"张三\",\"age\" : 20,\"sex\" : \"男\"," +
"\"name\" : \"李四\",\"age\" : 18,\"sex\" : \"女\"}";
Emp emp = JSON.parseObject(jsonStr,Emp.class); //由于是解析成一个Java对象,所以必须指明这个Java对象是什么类型
System.out.println(emp);
//当JSON串是一个数组的时候,此时使用parseObject()方法就不合适了,
//因为此时会转换出多个Java对象,用一个Java对象来接收也不合适了。
jsonStr = "[{\"name\": \"张三\",\"age\" : 20,\"sex\" : \"男\"}," +
"{\"name\" : \"李四\",\"age\" : 18,\"sex\" : \"女\"}]";
List<Emp> list = JSON.parseArray(jsonStr,Emp.class);
System.out.println(list);
}
}需要注意的是在JSON转Java对象时,这个测试文件,即JSONTest03文件的路径中不能出现中文,不然会出现格式化异常。
上面我们是拿到JSON串的全部信息,但是有时候我们只想拿到JSON串键值对里面的某个具体的值。
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
public class JSONTest04 {
public static void main(String[] args) {
test();
}
public static void test() {
String jsonStr = "{\"部门名称\" : \"研发部\"," +
"\"部门成员\" : [{\"name\" : \"张三\",\"age\" : 30,\"sex\" : \"男\"}," +
"{\"name\" : \"李四\",\"age\" : 25,\"sex\" : \"男\"}," +
"{\"name\" : \"王五\",\"age\" : 27,\"sex\" : \"男\"}" +
"]," +
"\"部门地址\" : \"北京市朝阳区\"" +
"}";
JSONObject jsonObject = JSON.parseObject(jsonStr); //将JSON串转换成一个Java对象
System.out.println(jsonObject);
String name = jsonObject.getString("部门名称"); //从这个Java对象中获取部门名称
System.out.println(name);
JSONArray empList = jsonObject.getJSONArray("部门成员"); //从这个Java对象中获取部门成员列表,由于有多个成员,所以得用getJSONArray()方法
System.out.println(empList);
for(int i = 0;i < empList.size();i++) {
JSONObject emp = empList.getJSONObject(i); //每一个成员又是一个JSON对象,因此要将其先转换成一个Java对象
System.out.println(emp.getString("name"));
System.out.println(emp.getInteger("age"));
System.out.println(emp.get("sex"));
System.out.println("-----------------");
}
}
}结果展示:
{"部门成员":[{"sex":"男","name":"张三","age":30},{"sex":"男","name":"李四","age":25},{"sex":"男","name":"王五","age":27}],"部门地址":"北京市朝阳区","部门名称":"研发部"}
研发部
[{"sex":"男","name":"张三","age":30},{"sex":"男","name":"李四","age":25},{"sex":"男","name":"王五","age":27}]
张三
30
男
-----------------
李四
25
男
-----------------
王五
27
男
-----------------
XML与JSON的异同
相同点:它们都可以作为一种数据交换的格式。
区别:XML是重量级的,JSON是轻量级的,XML再传输过程中比较占用宽带,JSON占用的宽带少,易于压缩。XML和JSON都用在项目交互下,但是XML多用于做配置文件,JSON多用于数据交互。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











