







第7部分,视觉实验
8 Speech Experiments
我们进行了实验来研究将语音功能集成到Llama 3中的组合方法,类似于我们用于视觉识别的方法。在输入端,一个编码器,连同一个适配器,被并入处理语音信号。在Llama 3中,我们利用系统提示符(文本)来实现不同的语音理解操作模式。如果没有提供系统提示,则该模型作为通用的语音对话模型,可以以与纯文本版本Llama 3一致的方式有效地响应用户的语音。引入对话历史作为提示前缀,提升多轮对话体验。我们还试验了能够使用Llama 3进行自动语音识别(ASR)和自动语音翻译(AST)的系统提示。Llama 3的语音接口支持多达34种语言它还允许文本和语音的交错输入,使该模型能够解决高级音频理解任务。
我们还实验了一种语音生成方法,其中我们实现了一个流式文本到语音(TTS)系统,该系统在语言模型解码期间实时生成语音波形。我们基于专有的TTS系统为Llama 3设计了语音生成器,并且没有对语音生成的语言模型进行微调。相反,我们专注于通过在推理时利用Llama 3嵌入来提高语音合成延迟、准确性和自然性。语音接口如图28和29所示。

 8.1 Data
8.1 Data
8.1.1 Speech Understanding
训练数据可以分为两类。预训练数据包含大量未标记语音,用于自监督方式初始化语音编码器。所述监督微调数据包括语音识别、语音翻译和语音对话数据;当与大型语言模型集成时,这些数据用于解锁特定的能力。
预训练的数据。为了预训练语音编码器,我们策划了一个包含大量语言的大约1500万小时语音记录的数据集。我们使用语音活动检测(VAD)模型过滤音频数据,并选择VAD阈值大于0.7的音频样本进行预训练。在语音预训练数据中,我们也注重保证PII的不存在。我们使用Presidio Analyzer来识别此类PII。
语音识别和翻译数据。我们的ASR训练数据包含23万小时的人工转录语音记录,涵盖34种语言。我们的AST训练数据包含两个方向的90K小时的翻译:从33种语言到英语和从英语到33种语言。该数据包含使用NLLB工具包生成的监督数据和合成数据(NLLB Team et al, 2022)。合成AST数据的使用使我们能够提高低资源语言的模型质量。我们数据中的语音片段的最长长度为60秒。
口语对话数据。为了调整语音适配器,我们合成了响应通过要求语言模型响应这些提示的转录(Fathullah et al, 2024)。我们使用具有60K小时语音的ASR数据集的子集以这种方式生成合成数据。此外,我们通过运行Voicebox TTS系统(Le et al, 2024)对用于微调Llama 3的数据子集生成了25K小时的合成数据。我们使用了几种启发式方法来选择与语音分布匹配的微调数据子集。这些启发式方法包括关注结构简单且没有非文本符号的相对较短的提示。
8.1.2 Speech Generation
语音生成数据集主要包括文本归一化模型和韵律模型的训练数据集。两个训练数据都增加了Llama 3嵌入的额外输入功能,以提供上下文信息。
文本规范化数据。我们的TN训练数据集包括55K个样本,涵盖了广泛的符号类(例如,数字、日期、时间),需要非平凡的规范化。每个样本都是一对书面形式文本和相应的规范化口语形式文本,并推断出执行规范化的手工TN规则序列。
韵律模型数据。PM训练数据包括从50k小时的TTS数据集中提取的语言和韵律特征,这些数据集是由专业配音演员在工作室设置中录制的配对文本和音频。
Llama 3嵌入。将Llama 3嵌入作为第16解码器层的输出。我们专门与Llama 3 8b模型一起工作,并提取给定文本的嵌入(例如,TN的书面形式输入文本或PM的音频记录),就好像它们是由Llama 3模型与空用户提示生成的一样。在给定的示例中,Llama 3 tokens序列中的每个块都明确地与TN或PM的本机输入序列中的相应块对齐,即,TN特定的文本tokens(由unicode类别划分)或电话率特征。这允许训练TN和PM模块与Llama 3 tokens和嵌入的流输入。
8.2 Model Architecture
8.2.1 Speech Understanding
在输入端,语音模块由两个连续的模块组成:语音编码器和适配器。语音模块的输出直接作为标记表示输入语言模型,从而支持语音和文本标记之间的直接交互。此外,我们还合并了两个新的特殊标记来封装语音表示序列。语音模块与视觉模块有很大的不同(见第7节),视觉模块通过跨注意层向语言模型提供多模态信息。相比之下,语音模块生成的嵌入可以与文本标记无缝集成,从而使语音接口能够利用Llama 3语言模型的所有功能。
语音编码器。我们的语音编码器是一个具有1B个参数的Conformer (Gulati等人,2020)模型。模型的输入包括80维mel-spectrogram特征,首先通过stride-4堆叠层进行处理,然后进行线性投影,将帧长度减少到40 ms。生成的特征由具有24个Conformer层的编码器处理。每个Conformer层的潜在维数为1536,由两个维数为4096的Macron-net风格前馈网络、一个核大小为7的卷积模块和一个具有24个注意头的transformer模块(Su et al, 2024)组成。
语音适配器。语音适配器包含约100M个参数。它由一个卷积层、一个transformer层和一个线性层组成。卷积层的核大小为3,步长为2,其目的是将语音帧长度减少到80ms。这允许模型为语言模型提供更粗粒度的特性。Transformer层的潜在维数为3072,前馈网络的维数为4096,该网络通过卷积下采样进一步处理语音信息。最后,线性层映射输出维数以匹配语言模型嵌入层的维数。
8.2.2 Speech Generation
我们在语音生成的两个关键组件中使用Llama 3 8b嵌入:文本规范化和韵律建模。TN模块通过上下文将书面文本转换为口语形式来确保语义正确性。PM模块通过使用这些嵌入预测韵律特征来增强自然度和表达性。它们共同实现了准确和自然的语音生成。
文本规范化。作为生成语音语义正确性的决定因素,文本规范化(TN)模块进行上下文感知的转换,从书面形式的文本转换为相应的口语形式,最终由下游组件进行语言化。例如,根据语义上下文,书面形式的文本123被读取为基数(123)或逐个拼写(123)。TN系统由一个基于流式lstm的序列标记模型组成,该模型预测用于转换输入文本的手工TN规则的序列(Kang et al, 2024)。该神经模型还采用了Llama 3嵌入,通过交叉关注来利用其中编码的上下文信息,实现最小的文本标记前瞻性和流输入/输出。
韵律建模。为了增强合成语音的自然度和表达性,我们集成了一个仅基于transformer的解码器韵律模型(PM) (Radford等人,2021),该模型将Llama 3嵌入作为额外输入。这种集成利用了Llama 3的语言能力,以tokens率利用其文本输出和中间嵌入(Devlin等人,2018;Dong等人,2019;拉斐尔等人,2020;Guo et al ., 2023)来增强对韵律特征的预测,从而减少模型所需的前瞻性。
PM集成了几个输入组件来生成全面的韵律预测:从上面详细介绍的文本规范化前端派生的语言特征、标记和嵌入。PM预测三个关键的韵律特征:每个电话的日志持续时间,日志F0(基频)平均值,以及整个电话持续时间的日志功率平均值。该模型由一个单向transformer和六个注意头组成。每个块包括交叉注意层和双重全连接层,隐藏维数为864。PM的一个显著特征是它的双重交叉注意机制,其中一层专门用于语言输入,另一层用于羊驼嵌入。这种设置有效地管理不同的输入速率,而不需要显式对齐。
8.3 Training Recipe
8.3.1 Speech Understanding
语音模块的训练分为两个阶段。第一阶段,语音预训练,利用未标记的数据来训练语音编码器,该编码器在语言和声学条件下表现出强大的泛化能力。在第二阶段,监督微调,适配器和预训练编码器与语言模型集成,并在LLM保持冻结的情况下与语言模型联合训练。这使模型能够响应语音输入。这个阶段使用与语音理解能力相对应的标记数据。
多语言ASR和AST建模通常会导致语言混淆/干扰,从而导致性能下降。缓解这种情况的一种流行方法是在源端和目标端合并语言标识(LID)信息。这可以在预先确定的方向集中提高性能,但它确实具有潜在的一般性损失。例如,如果翻译系统期望源端和目标端都有LID,那么模型就不太可能在训练中没有看到的方向上显示出良好的零射击性能。所以我们的挑战是设计一个系统,在一定程度上允许LID信息,但保持模型足够通用,这样我们就可以让模型在看不见的方向上进行语音翻译。为了解决这个问题,我们设计了系统提示符,它只包含要发出的文本的LID(目标端)。在这些提示中没有语音输入(源端)的LID信息,这也可能允许它处理代码切换语音。对于ASR,我们使用如下系统提示:在{language}:中跟我重复,其中{language}来自34种语言(英语、法语等)中的一种。对于语音翻译,系统提示为:将以下句子翻译成{language}:。这种设计已被证明在提示语言模型以所需语言进行响应方面是有效的。我们在训练和推理过程中使用了相同的系统提示。
语音预训练。我们使用自监督BEST-RQ算法(Chiu et al, 2022)对语音编码器进行预训练。我们以2.5%的概率对输入的梅尔光谱图应用32帧长度的掩模。如果语音超过60秒,我们执行6K帧的随机裁剪,对应于60秒的语音。我们通过堆叠4个连续帧来量化梅尔谱图特征,将320维向量投影到16维空间,并在8,192个向量的码本中执行关于余弦相似性度量的最近邻搜索。为了稳定预训练,我们使用了16种不同的密码本。投影矩阵和码本随机初始化,在整个模型训练过程中不更新。出于效率原因,多软最大损耗仅用于屏蔽帧。编码器训练了500K步,全局批处理大小为2048个话语。
监督微调。在监督微调阶段,将预先训练好的语音编码器和随机初始化的适配器与Llama 3进一步联合优化。在此过程中,语言模型保持不变。训练数据是ASR、AST和口语对话数据的混合。Llama 3 8b的语音模型被训练为650K次更新,使用全局批处理大小为512个话语,初始学习率为10^−4。Llama 3 70b的语音模型被训练了60万次更新,使用768个话语的全局批处理大小和4 × 10^−5的初始学习率。
8.3.2 Speech Generation
为了支持实时处理,韵律模型采用了一种前瞻机制,该机制考虑了固定数量的未来speech和可变数量的未来tokens。这确保了在处理传入文本时保持一致的前瞻性,这对于低延迟语音合成应用程序至关重要。
训练。我们开发了一种利用因果掩蔽的动态对齐策略,以促进语音合成的流化。该策略结合了一种针对固定数量的未来电话和可变数量的未来tokens的前瞻性机制,与文本规范化过程中的分块过程保持一致(第8.1.2节)。对于每个电话,tokens前瞻包括由块大小定义的tokens的最大数量,从而导致Llama嵌入的可变前瞻,但对于音素的固定前瞻。
Llama 3嵌入来自Llama 3 8b模型,在韵律模型的训练期间保持冻结。输入电话率功能包括语言和说话者/风格可控元素。模型训练的批处理大小为1024个语音,每个语音的最大长度为500个电话。我们使用AdamW优化器使用9 × 10^−4的学习率,训练超过100万个更新,并按照余弦时间表对前3000个更新进行学习率预热。
推理。在推理过程中,采用相同的前瞻机制和因果掩蔽策略,保证了训练和实时处理的一致性。PM以流方式处理传入的文本,逐个电话更新输入的电话率特性,逐个块更新输入的令牌率特性。只有当该块的第一个电话是当前的时候,新的块输入才会更新,保持对齐和前瞻性,就像在训练期间一样。
对于韵律目标预测,我们采用了延迟模式方法(Kharitonov等人,2021),这增强了模型捕获和再现远程韵律依赖关系的能力。这种方法有助于合成语音的自然性和表现力,确保低延迟和高质量的输出。
8.4 Speech Understanding Results
我们在三个任务上评估了我们为Llama 3设计的语音接口的语音理解能力:(1)自动语音识别,(2)语音翻译,(3)语音问答。我们将Llama 3的语音接口性能与三种最先进的语音理解模型进行了比较:Whisper (Radford等人,2023)、SeamlessM4T (Barrault等人,2023)和Gemini.19。在所有评估中,我们使用贪婪搜索来进行Llama 3 tokens预测。
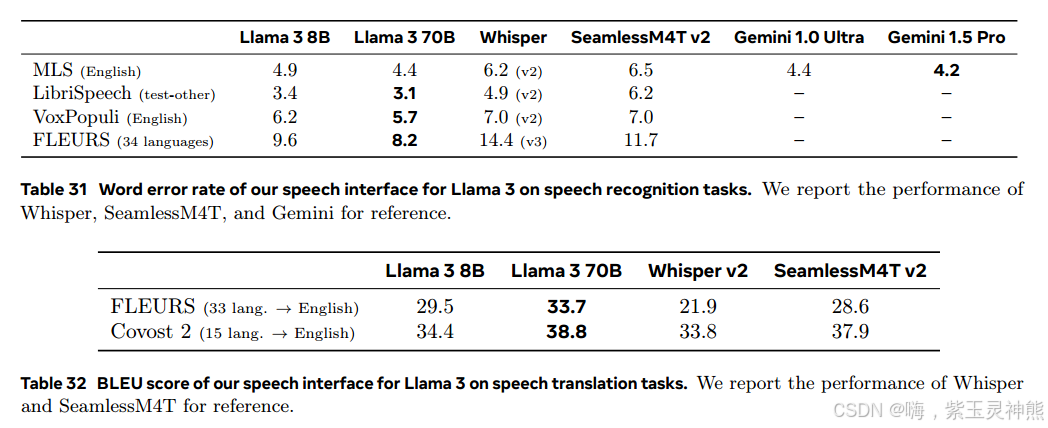
语音识别。我们在Multilingual librisspeech (MLS)的英语数据集上评估ASR的性能;Pratap等人(2020))、librisspeech (Panayotov等人,2015)、VoxPopuli (Wang等人,2021a)和多语言FLEURS数据集的一个子集(Conneau等人,2023)。在评估中,使用Whisper文本规范化器对解码结果进行后处理,以确保与其他模型报告的结果相一致。在所有基准测试中,我们测量了Llama 3的语音界面的单词错误率在这些基准的标准测试集上,除了中文、日语、韩语和泰语,其中报告了字符错误率。
表31显示了ASR评估的结果。它展示了Llama 3(以及更普遍的多模态基础模型)在语音识别任务上的强大性能:我们的模型在所有基准测试中都优于为语音量身定制的模型,如Whisper20和SeamlessM4T。在MLS英语中,Llama 3的表现与Gemini相似。
语音翻译。我们还在语音翻译任务中评估了我们的模型,其中模型被要求将非英语语音翻译成英语文本。我们在这些评估中使用了FLEURS和Covost 2 (Wang et al ., 2021b)数据集,测量了翻译英语的BLEU分数。表32给出了这些实验的结果我们的模型在语音翻译中的表现突出了多模态基础模型在语音翻译等任务中的优势。
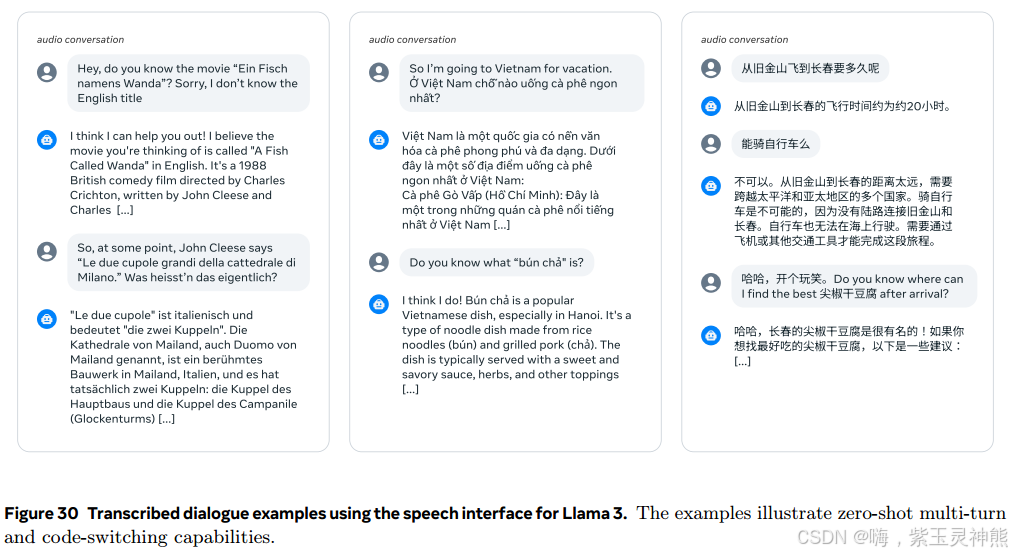
口语问答。Llama 3的语音界面显示出卓越的问答能力。该模型可以毫不费力地理解代码转换语音,而无需事先接触此类数据。值得注意的是,尽管该模型只训练了单回合对话,但它能够参与扩展的、连贯的多回合对话会话。图30展示了几个突出显示这些多语言和多回合功能的示例。
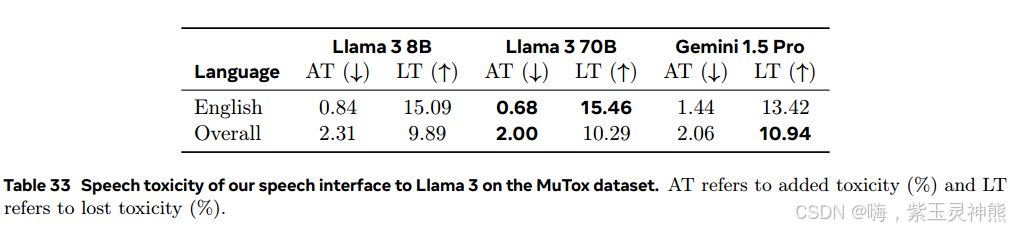
安全。我们在MuTox (costa - juss<s:1>等人,2023)上评估了我们的语音模型的安全性,MuTox是一个基于多语言音频的数据集,包含英语和西班牙语的20,000个语音,以及其他19种语言的4,000个语音,每个语音都附有毒性标签。将音频作为输入传递给模型,并在清除一些特殊字符后评估输出的毒性。我们应用MuTox分类器(costa - juss<s:1>等人,2023),并将结果与Gemini 1.5 Pro进行比较。我们评估添加毒性的百分比(AT),当输入提示是安全的,输出是有毒的,以及失去毒性的百分比(LT),当输入提示是有毒的,而答案是安全的。表33显示了英语的结果以及我们在22上评估的所有21种语言的平均值添加毒性的百分比非常低:我们的语言模型对英语的添加毒性百分比最低,不到1%。它去除的毒性远远大于增加的毒性。
8.5 Speech Generation Results
对于语音生成,我们专注于评估使用Llama 3嵌入的标记智能输入流模型的质量,用于文本规范化和韵律建模任务。评估的重点是与没有将Llama 3嵌入作为额外输入的模型进行比较。
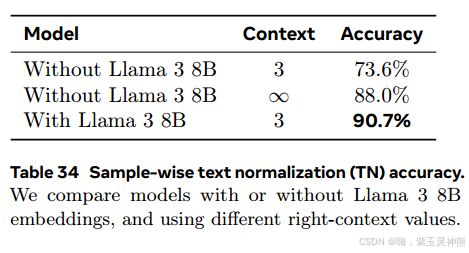
文本规范化。为了测量Llama 3嵌入的效果,我们尝试改变模型使用的正确上下文的数量。我们使用3个TN标记的正确上下文(由unicode类别划分)训练模型。将此模型与不使用Llama 3嵌入的模型(使用3个token的右上下文或完整的双向上下文)进行比较。如预期的那样,表34显示了在没有Llama 3嵌入的情况下,使用完全正确的上下文可以提高模型的性能。然而,包含Llama 3嵌入的模型优于所有其他模型,因此可以在不依赖于输入中的长上下文的情况下实现tokens输入/输出流。
韵律建模。为了评估我们的韵律模型(PM)在Llama 3 8b上的性能,我们进行了两组人类评估,比较了嵌入Llama 3和未嵌入Llama 3的模型。评分者听了不同型号的样品,并表明了他们的偏好。为了生成最终的语音波形,我们使用基于内部变压器的声学模型(Wu et al ., 2021)来预测频谱特征,并使用WaveRNN神经声码器(Kalchbrenner et al ., 2018)来生成最终的语音波形。
首先,我们直接与没有Llama 3嵌入的流基线模型进行比较。在第二个测试中,将Llama 3 8b PM与没有Llama 3嵌入的非流基线模型进行比较。如表35所示,与流基准相比,Llama 3 8b PM在60%的时间内是首选的,并且63.6%的时间与非流基线相比,表明感知质量有显着改善。Llama 3 8b PM的主要优势是它的tokens流式传输能力(第8.2.2节),它在推理期间保持低延迟。这减少了模型的前瞻要求,与非流基线相比,实现了更快的响应和实时语音合成。综上所述,Llama 3 8b韵律模型始终优于基线模型,证明了其在增强合成语音的自然度和表达性方面的有效性。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









