







机器学习概述
机器学习简介
什么是机器学习?
机器学习是一种从数据当中发现复杂规律,并且利用规律对未来时刻、未知状况进行预测和判定的方法,是当下被认为最有可能实现人工智能的方法。
机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。
举例说明:
- 已有的数据(经验)
- 某种模型(迟到的规律)
- 利用此模型预测未来(是否迟到)
- 机器学习界“数据为王”思想
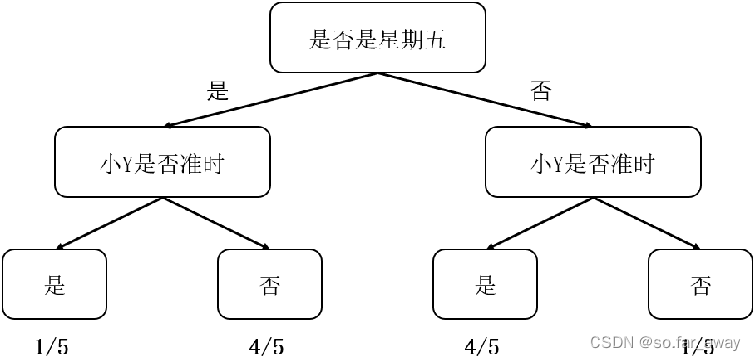
引例:小Y不是一个守时的人,最常见的表现是他经常迟到。小A与他相约3点钟在某地见面,在出门的那一刻小A突然想到一个问题:我现在出发合适吗?我会不会又到了地点后,还要花上30分钟去等他?
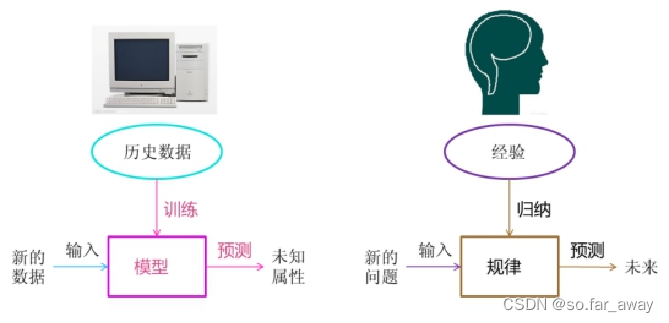
机器学习与人脑学习比较
- 电脑:
训练数据 建立模型 预测未知属性- 人脑:
总结经验 发现规律 预测未来
交叉学科
- 模式识别
- 计算机视觉
- 数据挖掘
- 语音识别
- 统计学习
- 自然语言处理
关系:
- 模式识别=机器学习
- 数据挖掘=机器学习+数据库
- 统计学习近似等于机器学习
- 计算机视觉=图像处理+机器学习
- 语音识别=语音处理+机器学习
- 自然语言处理=文本处理+机器学习
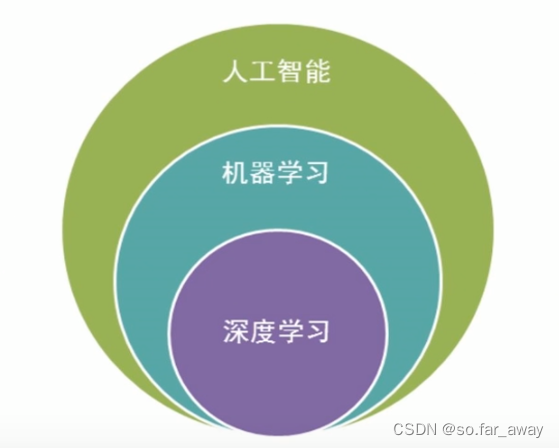
机器学习、人工智能与深度学习
人工智能是机器学习的父亲,机器学习的子类是深度学习:
深度学习是机器学习中神经网络算法的延伸,只不过应用的比较广
深度学习在计算机视觉和自然语言处理中更厉害一些
基本的机器学习术语
- 数据集(Dataset):数据是进行机器学习的基础,所有数据的集合称为数据集。
- 样本(Sample):数据集中每条记录是关于一个事件或对象的描述,称为样本。
- 属性(Attribute)或特征(Feature):每个样本在某方面的表现或性质。
- 特征向量(Feature Vector):每个样本的特征对应的特征空间中的一个坐标向量。
- 学习(Learning)或者训练(Training):从数据中学得模型的过程,这个过程通过执行某个学习算法来完成。
- 训练数据(Training Data):训练过程中使用的数据。
- 训练样本(Traing Sample):训练数据的每个样本。
- 训练集:训练样本组成的集合。
- 标记(Label):训练数据中可能会出现训练结果的信息。
- 测试(Test):学习到模型后,使用其进行预测的过程。
- 泛化能力(Generalization):学习到的模型适用于新样本的能力。机器学习的目标是使得学习到的模型能很好得适用于新样本,而不是仅仅在训练样本上适用。
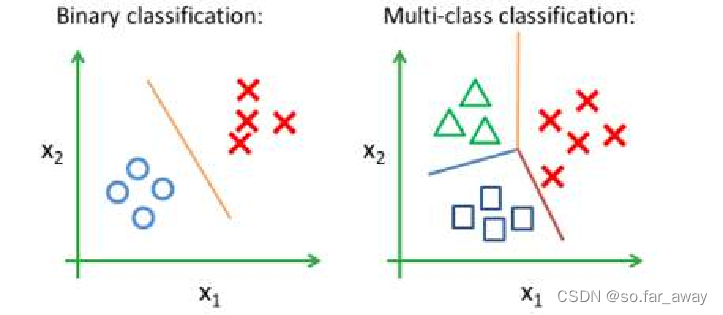
- 分类(Classfication):使用计算机学习出的模型进行预测得到的是离散值。
①二分类:只设计两个类别的分类任务,其中一个类为正类(Positive Class),另一个类为负类(Negative Class),如是猫、不是猫两类。
②多分类:涉及多个类别的分类任务。
- 回归(Regression):使用计算机学习出的模型进行预测得到的是连续值。
- 分类与回归的区别:
①输出不同:
1)分类问题输出的是物体所属的类别,回归问题输出的是物体的值。
2)分类问题输出的值是定性的,回归问题输出的值是定量的。
②目的不同:
1)分类的目的是为了寻找决策边界。
2)回归的目的是为了找到最优拟合。
③结果不同:
1)分类的结果没有逼近,对就是对,错就是错。
2)回归是对真实值的一种逼近预测。
机器学习的工作流程
数据采集
几种方式介绍:
- 爬虫:这种通常在个人项目、公司资源不足以提供数据、原始数据不足需要扩展数据情况下使用较多,比如根据时间获取天气数据,一般都是通过爬虫爬来的。
- API:现在有很多公开的数据集,一些组织也提供开放的API接口来获取相关数据,比如OpenDota提供Dota2相关数据,好处是通常数据更加规范。
- 数据库:这种算是最常见,也最理想的状态,通过公司自身的数据库保存数据,更加可控,也更加自由灵活。
数据处理
- 数据清洗:更多是针对类似爬虫这种方式获取的数据,这种数据通常没有一个非常固定规范的格式,数据非常不稳定,因此需要进行前期的清洗工作。
- 数据预处理:缺失值处理、重复值处理、数据类型的转换、字符串数据的规整。
- 数据归一化/标准化:数据归一化(Normalization)是指将原始数据按照一定比例缩放到[0,1]范围内,使得不同属性之间具有可比性;数据标准化(Standardization)是指将原始数据转换为均值为0,标准差为1的分布形式,以消除不同属性之间的量纲影响,并使得数据更易于比较和分析。
特征工程
特征工程指的是把原始数据转变为模型的训练数据的过程,它的目的就是获取更好的训练数据特征。
特征工程在机器学习中占有非常重要的作用,一般认为括特征构建、特征提取、特征选择三个部分。
构建模型
①建立训练数据集和测试数据集,通常80%为训练数据集。
②选择机器学习算法
- 导入算法
逻辑回归(logisic regression)
随机森林(Random Forests Model)
支持向量机(Support Vector Machines)
K-nearest neighbors
Gaussian Naive Bayes
数据降维:PCA,Isomap
数据分类:SVC,K-Means
线性回归:LinearRegression- 创建模型
- 训练模型
③模型调优
选择合适的算法对模型进行训练。
④模型融合
一般来讲,任何一个模型在预测上都无法达到一个很好的结果,这是因为通常来说单个模型无法拟合所有数据,及不具备对所有未知数据的泛化能力,因此需要对多个模型进行融合。
模型评估
针对分类、排序、回归、序列预测等不同类型的机器学习问题,评估指标的选择也有所不同。
知道每种评估指标的精确定义、有针对性地选择合适的评估指标、根据评估指标的反馈进行模型调整,这些都是模型评估阶段的关键问题。
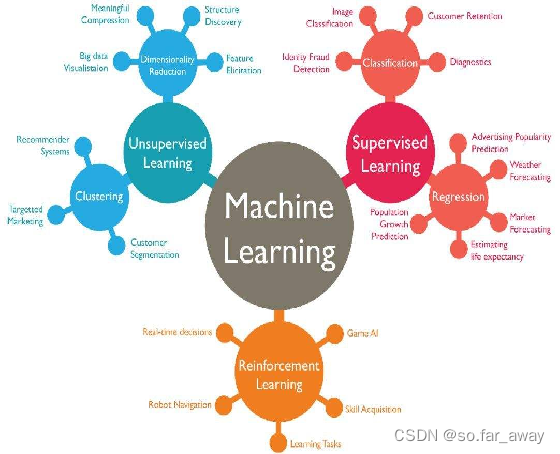
知识框架
机器学习的分类
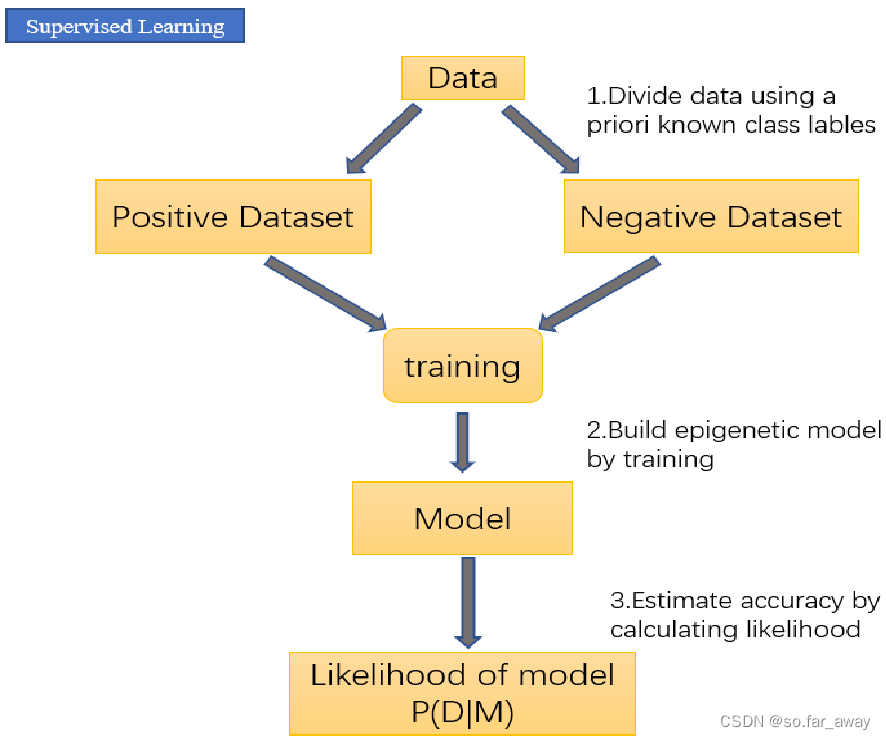
监督学习
- 在建立预测模型的过程中将预测结果与训练数据的实际结果进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率。
其训练集要求包括输入和输出,也可以说是特征和目标。训练集的目标通常是由人标注的。
典型例子:分类和回归任务、决策树、贝叶斯模型、支持向量机、深度学习。
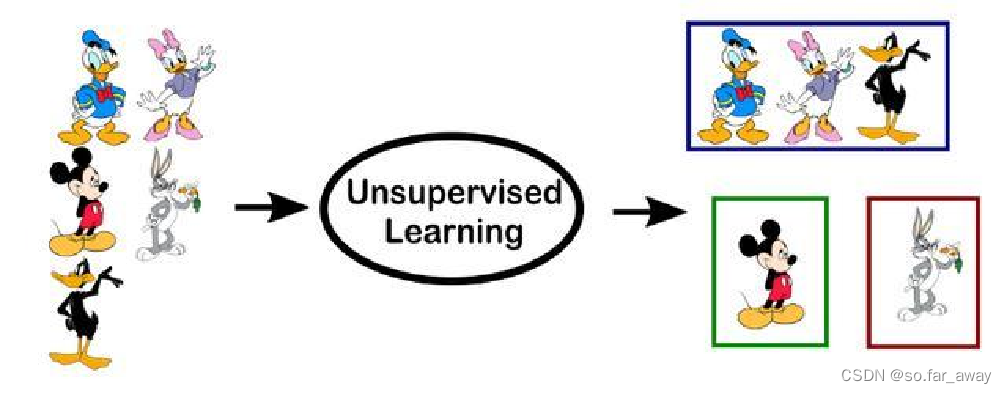
无监督学习
- 数据并不被特别标识,计算机自行学习分析数据内部的规律、特征等,进而得出一定的结果(如内部结构、主要成分等)。
- 典型例子:聚类算法。
半监督学习
- 半监督学习介于监督学习和非监督学习之间,输入数据部分被标识,部分没有被标识,没标识数据的数量常常远远大于有标识数据数量。
- 这种学习模型可以用来进行预测,但是模型首先需要学习数据的内在结构以便合理的组织数据来进行预测。
强化学习
- 基于与环境的交互进行学习。通过尝试来发现各个动作产生的结果,对各个动作产生的结果进行反馈(奖励或惩罚)。在这种学习模式下,输入数据直接反馈到模型,模型必须作出调整。
机器学习常用算法
回归分析
- 回归分析是一种研究自变量和因变量之间关系的预测模型,用于分析当自变量发生变化时因变量的变化值。
- 要求自变量相互独立。
分类算法
- 分类就是通过分析训练集中的数据,为每个类别做出准确的描述或建立分析模型或挖掘出分类规则,然后用这个分类规则对其它数据对象进行分类。
- 决策树、支持向量机、神经网络、朴素贝叶斯、Bayes网络、k-最近邻等是几种常用的分类方法。
神经网络
- 传统的神经网络为BP神经网络,基本网络结构为输入层、隐藏层和输出层,节点代表神经元,边代表权重值,对输入值按照权重和偏置计算后将结果传给下一层,通过不断的训练修正权重和偏置。递归神经网络(RNN)、卷积神经网络(CNN)都在神经网络在深度学习上的变种。
- 神经网络的训练主要包括前向传输和反向传输。
- 神经网络的结果准确性与训练集的样本数量和分类质量有关。
- 神经网络是基于历史数据构建的分析模型,新数据产生时需要动态优化网络的结构和参数。
深度学习
- 深度学习是通过构建多个隐藏层和大量数据来学习特征,从而提升分类或预测的准确性。
- 与神经网络相比,层数更多,而且有逐层训练机制避免梯度扩散。
- 深度学习包括了:
卷积神经网络(CNN)
深度神经网络(DNN)
循环神经网络(RNN)
对抗神经网络(GAN)- 深度学习中训练集、开发集、测试集的样本比例一般为6:2:2。
- 常见的权重更新方式包括SGD和Momentum。
聚类算法
- 聚类分析是把一个给定的数据对象(样本)集合分成不同的簇(组)。
- 聚类就是把整个数据集分成不同的组,并使组与组之间的差距尽可能大,组内数据的差异尽可能小。
- K-means是一种常用的聚类算法,用户指定聚类的类别数K,随机地选择K个对象作为K个初始聚类中心。对剩余的每个对象,分别计算与初始聚类中心的距离,根据距离划分到不同的簇。然后重新计算每个簇的平均值,求出新的聚类中心,再重新聚类。这个过程不断重复,直到收敛(相邻两次计算的聚类中心相同)。
关联分析(好像没怎么听说过)
- 关联分析通过对数据集中某些属性同时出现的规律和模式来发现其中的属性间的关联、相关、因果等关系,典型应用是购物篮分析。
- 关联分析包括Apriori算法和FP-Growth算法。
- Apriori算法的基本思想是先找出所有的频繁项集,然后由频繁项集产生强关联规则,这些规则必须满足最小支持度和最小置信度。算法要多次扫描样本集,需要由候选频繁项集生成频繁项集。
- FP-Growth算法是基于FP树生成频繁项集的,算法只扫描两次数据集,且不使用候选项集,直接按照支持度构造出一个频繁模式树,用这棵树生成关联规则。
- 关联分析已经在客户购物行为分析、电子推荐、产品质量检测、文档主题分析等得到了广泛应用。
















 3869
3869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











