






WAVE-U-NET: A MULTI-SCALE NEURAL NETWORK FOR END-TO-END AUDIO SOURCE SEPARATION
一、Introduction
音频源分离模型通常基于幅度谱,忽略了相位信息,使得分离性能依赖于谱前端的超参数。因此,我们在时域中研究端到端源分离,并且提出了基于U-net结构的wave-U-net 模型,它对特征映射进行重复采样,以计算和组合不同时间尺度的特征。
二、problems:
将混合信号通过短时傅里叶变换(STFT)后,谱图图被分为幅度分量和相位分量,但只有幅度进入参数化模型。同时,分离模型一般不转换声源的相位,通常假定源相等于混合相位,这对重叠部分是不正确的,因此,本文提出分离模型应该学会直接估计包括相位在内的源信号。
三、模型
3.1模型结构
如图,这是本文提出的wave-u-net 架构,它是基于U-net实现的。图中首相将一个混合信号通过L层下采样层,然后经过一个一维卷积后,再经过L层上采样层,最后经过一维卷积层后分成了k个声源的信号。在下采样过程中使用Decimate每隔一个时间步丢弃特征,这使得时间分辨率减半,上采样过程中使用线性插值法在时间方向上以二倍的倍数进行采样。Concat(x)将当前的高级特征与更多的本地特征x连接起来。(M1)

3.2模型改善
3.2.1 Difference output layer(M2)
论文的Baseline通过独立应用K个卷积滤波器,然后对最后一个特征映射进行tanh非线性,为K个源中的每个源输出一个源估计。在论文考虑的分离任务中,混合信号应该其源信号分量的和
![]()
。因此,为了避免不可能的输出,本论文提出差分输出层,即只对前K-1个源信号通过一维卷积和激活函数,而最后一个信号则是混合信号减去前K-1个混合信号的和。
![]()
3.2.2 Prediction with proper input context and resampling(M3)
在通用模型中,输入和特征映射在卷积之前填充了零,这样得到的特征映射的维数不会改变,但是如果没有适当的上下文信息,网络就很难预测序列开头和结尾附近的输出值。因此,本论文没有使用隐式填充的卷积,而是提供比输出预测大小更大的混合输入,以便在正确的音频上下文上计算卷积。
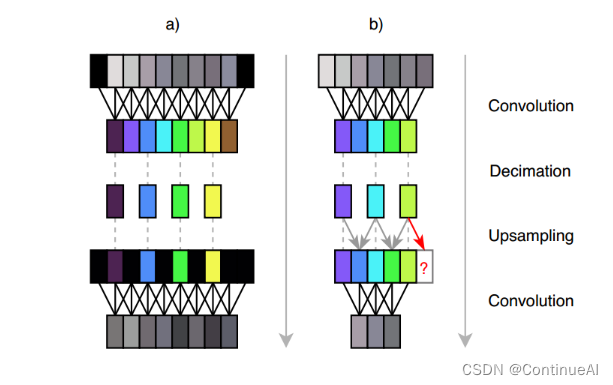
如图,a是普通模型的结构,在卷积前模型会进行零填充,之后在Decimation后使用跨步为2的转置卷积进行上采样,用零填充中间值和边界值,最后再经过一层卷积,这可能会使输出产生高频伪影,而本文提出的模型在上采样时使用线性插值,而不使用零填充,因为输出的特征数是不均匀的,因此上采样过程中不需要推测值。虽然输出更小,但避免了高频伪影。
3.2.3 Stereo channels(M4)
为了适应具有C通道的多通道输入,我们简单地将输入M从Lm × 1改变为Lm × C矩阵。
3.2.4 Learned upsampling for Wave-U-Net(M5)
因为特征空间中两点之间的线性插值本身就是一个有用的点,因此学习上采样可以进一步提高性能。
因此使用该公式进行计算插值特征,其中ft 和ft+1 分别是相邻特征,sigmoid函数σ约束每个w在0到1之内:
四、Result
4.1 Quantitative results
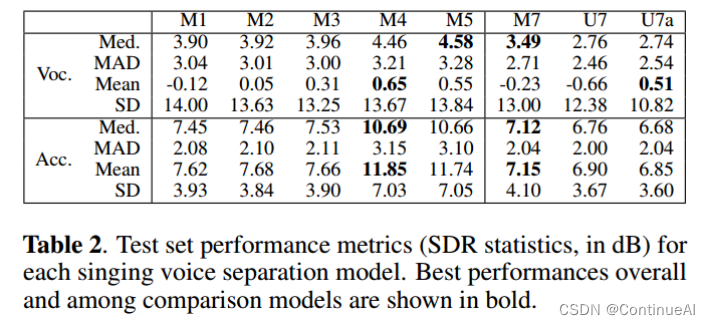
评价指标采用信号失真度(SDR)指标进行评价
如图
1、差异输出层不会显著改变性能,因为M2模型似乎只比M1模型好一点点
2、正如模型M3所示,引入上下文显著提高了性能,这可能是由于在输出边界有更好的预测。
3、在模型M4立体声建模产生改进,特别是为伴奏,在模型四,模型的评价性能达到最高。
4、学习后的上采样(M5)略微提高了中位数,但略微降低了平均声乐SDR
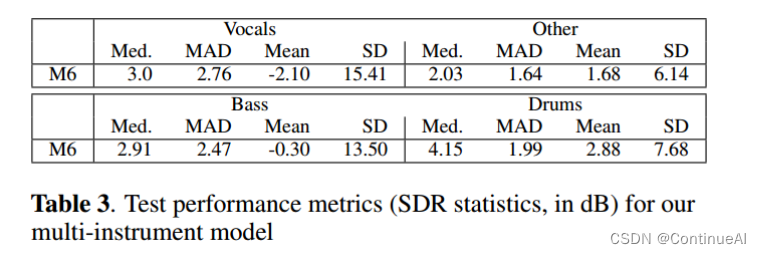
对于多仪器分离,论文实现了稍低但中等的性能。
4.2 Qualitative results and observations
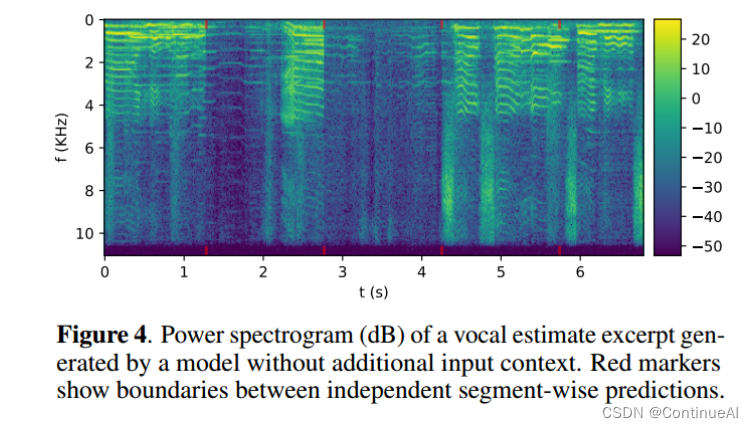
这些模型不仅在这些段边界处存在不一致性,而且当需要来自时间上下文的信息时,在那里执行分离的能力也较差。
五、conclusion
-
论文提出了Wave-U-Net,这是U-Net架构的一维改编,它直接在时域中分离源,并且可以考虑大的时间背景。
-
与之前的工作相比,论文展示了一种为模型提供额外输入上下文的方法,以避免输出窗口边界的工件。
-
论文使用用线性插值替换先前工作中使用的跨行转置卷积用于上采样特征映射,然后通过卷积来避免伪影。

















 4363
4363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









