






 博客介绍了全卷积时域音频分离网络(convt - tasnet)的模型架构,包含编码器、分离和解码器三个处理阶段,先将混合波形转换为中间特征表示,再估计掩码,最后重建源波形。还提及了相关代码,如TCN和Conv - TasNet。
博客介绍了全卷积时域音频分离网络(convt - tasnet)的模型架构,包含编码器、分离和解码器三个处理阶段,先将混合波形转换为中间特征表示,再估计掩码,最后重建源波形。还提及了相关代码,如TCN和Conv - TasNet。
一、模型架构
全卷积时域音频分离网络(convt - tasnet)包括三个处理阶段,如(A)所示:编码器、分离和解码器。首先,使用编码器模块将混合波形的短段转换为其在中间特征空间中的相应表示。然后使用这种表示来估计每个时间步长的每个源的乘法函数(掩码)。然后通过使用解码器模块转换掩码编码器特征来重建源波形。
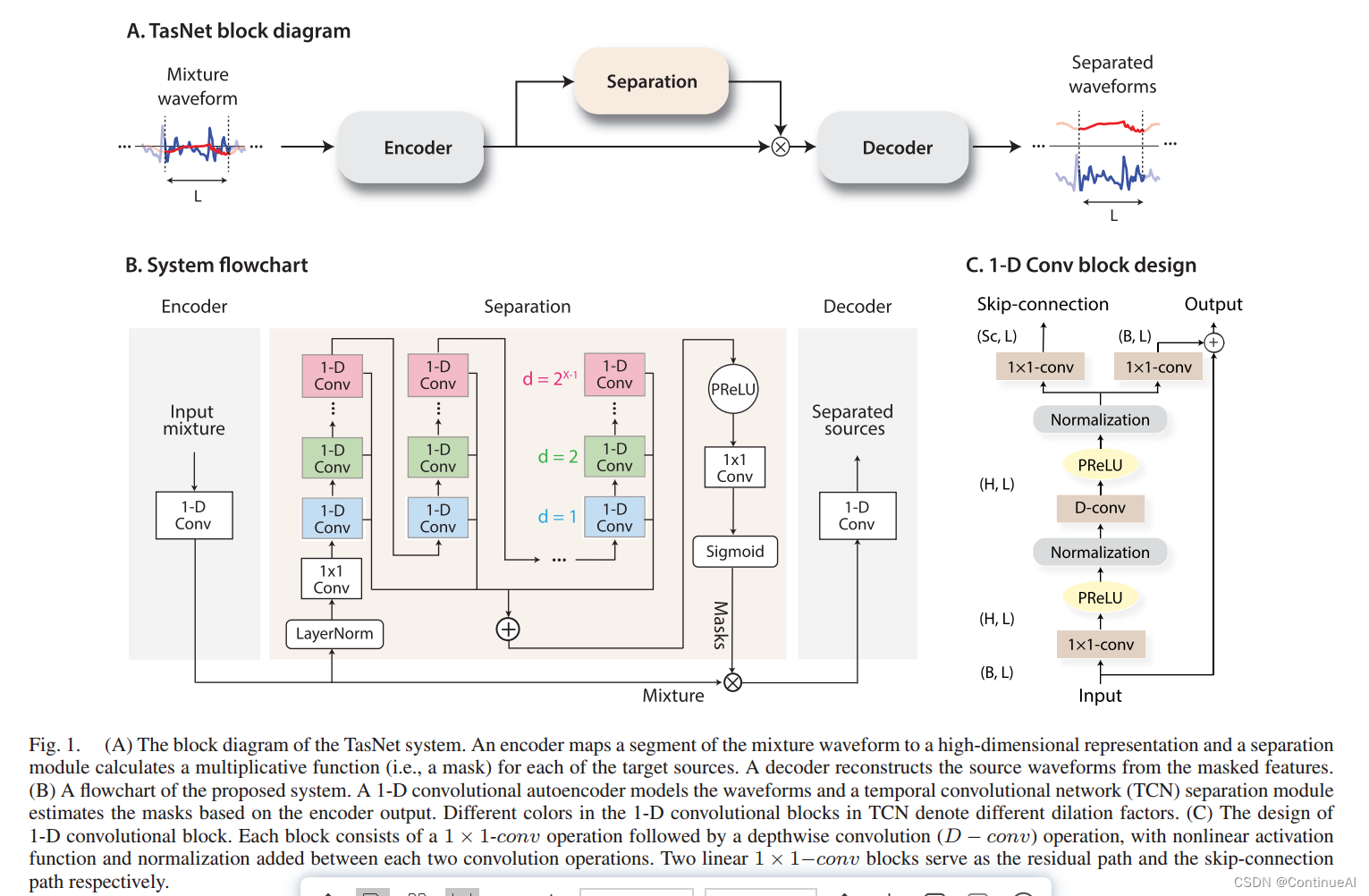
二、代码
1、TCN
import numpy as np
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
class cLN(nn.Module):
def __init__(self, dimension, eps = 1e-8, trainable=True):
super(cLN, self).__init__()
self.eps = eps
if trainable:
self.gain = nn.Parameter(torch.ones(1, dimension, 1))
self.bias = nn.Parameter(torch.zeros(1, dimension, 1))
else:
self.gain = Variable(torch.ones(1, dimension, 1), requires_grad=False)
self.bias = Variable(torch.zeros(1, dimension, 1), requires_grad=False)
def forward(self, input):
# input size: (Batch, Freq, Time)
# cumulative mean for each time step
batch_size = input.size(0)
channel = input.size(1)
time_step = input.size(2)
step_sum = input.sum(1) # B, T
step_pow_sum = input.pow(2).sum(1) # B, T
cum_sum = torch.cumsum(step_sum, dim=1) # B, T
cum_pow_sum = torch.cumsum(step_pow_sum, dim=1) # B, T
entry_cnt = np.arange(channel, channel*(time_step+1), channel)
entry_cnt = torch.from_numpy(entry_cnt).type(input.type())
entry_cnt = entry_cnt.view(1, -1).expand_as(cum_sum)
cum_mean = cum_sum / entry_cnt # B, T
cum_var = (cum_pow_sum - 2*cum_mean*cum_sum) / entry_cnt + cum_mean.pow(2) # B, T
cum_std = (cum_var + self.eps).sqrt() # B, T
cum_mean = cum_mean.unsqueeze(1)
cum_std = cum_std.unsqueeze(1)
x = (input - cum_mean.expand_as(input)) / cum_std.expand_as(input)
return x * self.gain.expand_as(x).type(x.type()) + self.bias.expand_as(x).type(x.type())
def repackage_hidden(h):
"""
Wraps hidden states in new Variables, to detach them from their history.
"""
if type(h) == Variable:
return Variable(h.data)
else:
return tuple(repackage_hidden(v) for v in h)
class MultiRNN(nn.Module):
"""
Container module for multiple stacked RNN layers.
args:
rnn_type: string, select from 'RNN', 'LSTM' and 'GRU'.
input_size: int, dimension of the input feature. The input should have shape
(batch, seq_len, input_size).
hidden_size: int, dimension of the hidden state. The corresponding output should
have shape (batch, seq_len, hidden_size).
num_layers: int, number of stacked RNN layers. Default is 1.
bidirectional: bool, whether the RNN layers are bidirectional. Default is False.
"""
def __init__(self, rnn_type, input_size, hidden_size, dropout=0, num_layers=1, bidirectional=False):
super(MultiRNN, self).__init__()
self.rnn = getattr(nn, rnn_type)(input_size, hidden_size, num_layers, dropout=dropout,
batch_first=True, bidirectional=bidirectional)
self.rnn_type = rnn_type
self.hidden_size = hidden_size
self.num_layers = num_layers
self.num_direction = int(bidirectional) + 1
def forward(self, input):
hidden = self.init_hidden(input.size(0))
self.rnn.flatten_parameters()
return self.rnn(input, hidden)
def init_hidden(self, batch_size):
weight = next(self.parameters()).data
if self.rnn_type == 'LSTM':
return (Variable(weight.new(self.num_layers*self.num_direction, batch_size, self.hidden_size).zero_()),
Variable(weight.new(self.num_layers*self.num_direction, batch_size, self.hidden_size).zero_()))
else:
return Variable(weight.new(self.num_layers*self.num_direction, batch_size, self.hidden_size).zero_())
class FCLayer(nn.Module):
"""
Container module for a fully-connected layer.
args:
input_size: int, dimension of the input feature. The input should have shape
(batch, input_size).
hidden_size: int, dimension of the output. The corresponding output should
have shape (batch, hidden_size).
nonlinearity: string, the nonlinearity applied to the transformation. Default is None.
"""
def __init__(self, input_size, hidden_size, bias=True, nonlinearity=None):
super(FCLayer, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.bias = bias
self.FC = nn.Linear(self.input_size, self.hidden_size, bias=bias)
if nonlinearity:
self.nonlinearity = getattr(F, nonlinearity)
else:
self.nonlinearity = None
self.init_hidden()
def forward(self, input):
if self.nonlinearity is not None:
return self.nonlinearity(self.FC(input))
else:
return self.FC(input)
def init_hidden(self):
initrange = 1. / np.sqrt(self.input_size * self.hidden_size)
self.FC.weight.data.uniform_(-initrange, initrange)
if self.bias:
self.FC.bias.data.fill_(0)
# 1 × 1 convD 模块
class DepthConv1d(nn.Module):
def __init__(self, input_channel, hidden_channel, kernel, padding, dilation=1, skip=True, causal=False):
super(DepthConv1d, self).__init__()
self.causal = causal
self.skip = skip
self.conv1d = nn.Conv1d(input_channel, hidden_channel, 1)
if self.causal:
self.padding = (kernel - 1) * dilation
else:
self.padding = padding
self.dconv1d = nn.Conv1d(hidden_channel, hidden_channel, kernel, dilation=dilation,
groups=hidden_channel,
padding=self.padding)
self.res_out = nn.Conv1d(hidden_channel, input_channel, 1)
self.nonlinearity1 = nn.PReLU()
self.nonlinearity2 = nn.PReLU()
if self.causal:
self.reg1 = cLN(hidden_channel, eps=1e-08)
self.reg2 = cLN(hidden_channel, eps=1e-08)
else:
self.reg1 = nn.GroupNorm(1, hidden_channel, eps=1e-08)
self.reg2 = nn.GroupNorm(1, hidden_channel, eps=1e-08)
if self.skip:
self.skip_out = nn.Conv1d(hidden_channel, input_channel, 1)
def forward(self, input):
output = self.reg1(self.nonlinearity1(self.conv1d(input)))
if self.causal:
output = self.reg2(self.nonlinearity2(self.dconv1d(output)[:,:,:-self.padding]))
else:
output = self.reg2(self.nonlinearity2(self.dconv1d(output)))
residual = self.res_out(output)
if self.skip:
skip = self.skip_out(output)
return residual, skip
else:
return residual
class TCN(nn.Module):
def __init__(self, input_dim, output_dim, BN_dim, hidden_dim,
layer, stack, kernel=3, skip=True,
causal=False, dilated=True):
super(TCN, self).__init__()
# input is a sequence of features of shape (B, N, L)
# normalization
if not causal:
self.LN = nn.GroupNorm(1, input_dim, eps=1e-8)
else:
self.LN = cLN(input_dim, eps=1e-8)
self.BN = nn.Conv1d(input_dim, BN_dim, 1)
# TCN for feature extraction
self.receptive_field = 0
self.dilated = dilated
self.TCN = nn.ModuleList([])
for s in range(stack):
for i in range(layer):
if self.dilated:
self.TCN.append(DepthConv1d(BN_dim, hidden_dim, kernel, dilation=2**i, padding=2**i, skip=skip, causal=causal))
else:
self.TCN.append(DepthConv1d(BN_dim, hidden_dim, kernel, dilation=1, padding=1, skip=skip, causal=causal))
if i == 0 and s == 0:
self.receptive_field += kernel
else:
if self.dilated:
self.receptive_field += (kernel - 1) * 2**i
else:
self.receptive_field += (kernel - 1)
#print("Receptive field: {:3d} frames.".format(self.receptive_field))
# output layer
self.output = nn.Sequential(nn.PReLU(),
nn.Conv1d(BN_dim, output_dim, 1)
)
self.skip = skip
def forward(self, input):
# input shape: (B, N, L)
# normalization
output = self.BN(self.LN(input))
# pass to TCN
if self.skip:
skip_connection = 0.
for i in range(len(self.TCN)):
residual, skip = self.TCN[i](output)
output = output + residual
skip_connection = skip_connection + skip
else:
for i in range(len(self.TCN)):
residual = self.TCN[i](output)
output = output + residual
# output layer
if self.skip:
output = self.output(skip_connection)
else:
output = self.output(output)
return output2、Conv-TasNet
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
# Conv-TasNet
class TasNet(nn.Module):
def __init__(self, enc_dim=512, feature_dim=128, sr=16000, win=2, layer=8, stack=3,
kernel=3, num_spk=2, causal=False):
super(TasNet, self).__init__()
# hyper parameters
self.num_spk = num_spk
self.enc_dim = enc_dim
self.feature_dim = feature_dim
self.win = int(sr*win/1000)
self.stride = self.win // 2
self.layer = layer
self.stack = stack
self.kernel = kernel
self.causal = causal
# input encoder
self.encoder = nn.Conv1d(1, self.enc_dim, self.win, bias=False, stride=self.stride)
# TCN separator
self.TCN = TCN(self.enc_dim, self.enc_dim*self.num_spk, self.feature_dim, self.feature_dim*4,
self.layer, self.stack, self.kernel, causal=self.causal)
self.receptive_field = self.TCN.receptive_field
# output decoder
self.decoder = nn.ConvTranspose1d(self.enc_dim, 1, self.win, bias=False, stride=self.stride)
def pad_signal(self, input):
# input is the waveforms: (B, T) or (B, 1, T)
# reshape and padding
if input.dim() not in [2, 3]:
raise RuntimeError("Input can only be 2 or 3 dimensional.")
if input.dim() == 2:
input = input.unsqueeze(1)
batch_size = input.size(0)
nsample = input.size(2)
rest = self.win - (self.stride + nsample % self.win) % self.win
if rest > 0:
pad = Variable(torch.zeros(batch_size, 1, rest)).type(input.type())
input = torch.cat([input, pad], 2)
pad_aux = Variable(torch.zeros(batch_size, 1, self.stride)).type(input.type())
input = torch.cat([pad_aux, input, pad_aux], 2)
return input, rest
def forward(self, input):
# padding
output, rest = self.pad_signal(input)
batch_size = output.size(0)
# waveform encoder
enc_output = self.encoder(output) # B, N, L
# generate masks
masks = torch.sigmoid(self.TCN(enc_output)).view(batch_size, self.num_spk, self.enc_dim, -1) # B, C, N, L
masked_output = enc_output.unsqueeze(1) * masks # B, C, N, L
# waveform decoder
output = self.decoder(masked_output.view(batch_size*self.num_spk, self.enc_dim, -1)) # B*C, 1, L
output = output[:,:,self.stride:-(rest+self.stride)].contiguous() # B*C, 1, L
output = output.view(batch_size, self.num_spk, -1) # B, C, T
return output
def test_conv_tasnet():
x = torch.rand(2, 32000)
nnet = TasNet()
x = nnet(x)
s1 = x[0]
print(s1.shape)
for name,param in nnet.named_parameters():
print(name,param.shape)
if __name__ == "__main__":
test_conv_tasnet()
















 2349
2349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









