






1.启动Hadoop
可以看博主之前写过的启动方式~链接已经发出来了。
2.先创建一个新的文件来写下单词
vi [文件名]
我这里取得名字是hello1
![]()
这里进入文件后,按 i 进入输入模式,写下所需的单词,然后按esc然后输入:wq退出该文件
3.可以查看自己写进去的单词
cat [文件名]
![]()
这我随便打的文件名和拼音~
4.使用 put 操作将“hello1”文件上传到 HDFS 的根目录
hadoop fs -put hello1 /hello1
5.进入Hadoop中mapreduce文件夹下(路径输自己存放Hadoop的路径)
cd hadoop-2.7.1/share/hadoop/mapreduce/
![]()
因为我这里是把我的Hadoop(2.7.1版本)存放在module目录下的
6.使用 jar 操作运行 Hadoop 中自带的 jar 进行单词计数(注意自己的Hadoop的版本)
hadoop jar hadoop-mapreduce-examples-2.7.1.jar wordcount /hello1 /out1
![]()
注意后面的out1,如果你之前使用过out1作为计数结果文件,那么这里就不能使用了,就需要重新取名,不然会报错的
例如这个样就是报错,这里提示out文件已经存在了(之前我采用了out文件作为计数文件)

解决方法:
1.换一个文件去存放计数结果,这是最简单的,也就是不要命名out了,换成out1、out2...或者其他的都可以
2.删除out文件
hadoop fs -rm -r /out

这个时候你就可以用out文件作为你存放计数结果的文件了
如果该步骤是正确的,那么会出现以下的说明

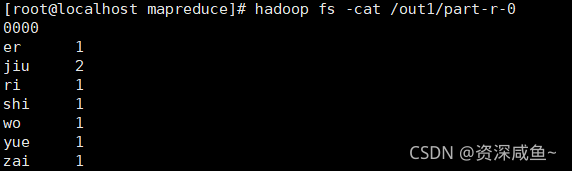
8.使用 cat 查看统计结果
hadoop fs -cat /out1/part-r-00000
进入网页查看文件,端口:50070

到这就结束了!
值得注意的是,有些地方是命令,需要空格,不然就会报错哦~















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









