






以Pytorch为例
混合精度训练
Pytorch自动混合精度(AMP)训练
Pytorch自动混合精度(AMP)介绍与使用
1. 理论基础
pytorch从1.6版本开始,已经内置了torch.cuda.amp,采用自动混合精度训练就不需要加载第三方NVIDIA的apex库了。AMP (automatic mixed-precision training)
PyTorch提供了一种自动混合精度(AMP)训练技术,可以在保持模型准确性的同时,提高训练速度和减少显存消耗。AMP利用了浮点数的精度,将训练过程中的某些操作转换为半精度浮点数(FP16),从而减少了显存占用和计算时间。
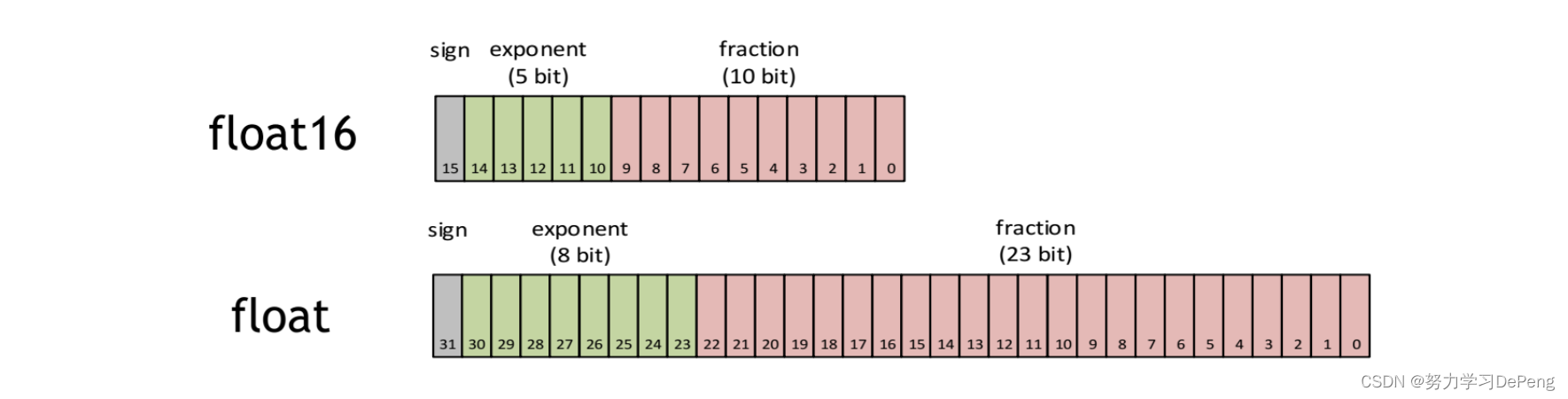
与单精度float(32bit,4个字节)相比,半进度float16仅有16bit,2个字节组成。天然的存储空间是float的一半。 其中,float16的组成分为了三个部分:最高位表示符号位,sign 位表示正负,有5位表示exponent位, exponent 位表示指数,有10位表示fraction位, fraction 位表示的是分数。
torch.FloatTensor(32bit floating point)
torch.DoubleTensor(64bit floating point)
torch.HalfTensor(16bit floating piont1)
torch.BFloat16Tensor(16bit floating piont2)
torch.ByteTensor(8bit integer(unsigned)
torch.CharTensor(8bit integer(signed))
torch.ShortTensor(16bit integer(signed))
torch.IntTensor(32bit integer(signed))
torch.LongTensor(64bit integer(signed))
torch.BoolTensor(Boolean)
默认Tensor是32bit floating point,这就是32位浮点型精度的tensor。
AMP(自动混合精度)的关键词有两个:自动,混合精度。这是由PyTorch 1.6的torch.cuda.amp模块带来的:
自动:Tensor的dtype类型会自动变化,框架按需自动调整tensor的dtype,当然有些地方还需手动干预。
混合精度:采用不止一种精度的Tensor,torch.FloatTensor和torch.HalfTensor
pytorch1.6的新包:torch.cuda.amp,torch.cuda.amp 的名字意味着这个功能只能在cuda上使用,是NVIDIA开发人员贡献到pytorch里的。只有支持tensor core的CUDA硬件才能享受到AMP带来的优势(比如2080ti显卡)。
Tensor core是一种矩阵乘累加的计算单元,每个tensor core时针执行64个浮点混合精度操作(FP16矩阵相乘和FP32累加)。英伟达宣称使用Tensor Core进行矩阵运算可以轻易的提速,同时降低一半的显存访问和存储。
要使用PyTorch AMP训练,可以使用torch.cuda.amp模块中的**autocast()和GradScaler()**函数。autocast()函数会将使用该函数包装的代码块中的浮点数操作转换为FP16,而GradScaler()函数则会自动缩放梯度,以避免在FP16计算中的梯度下降步骤中的下溢问题。
2. 使用AMP的优势
AMP其实就是Float32与Float16的混合,那为什么不单独使用Float32或Float16,而是两种类型混合呢?
原因是:在某些情况下Float32有优势,而在另外一些情况下Float16有优势。而相比于之前的默认的torch.FloatTensor,torch.HalfTensor的劣势不可忽视。
这里先介绍下FP16(torch.HalfTensor)的优劣势:
优势:
1、减少显存占用:现在模型越来越大,当你使用 Bert 这一类的预训练模型时,往往模型及模型计算就占去显存的大半,当想要使用更大的 Batch Size 的时候会显得捉襟见肘。由于 FP16 的内存占用只有 FP32 的一半,自然地就可以帮助训练过程节省一半的显存空间,可以增加batchsize了。
2、加快训练和推断的计算:与普通的空间时间 Trade-off 的加速方法不同,FP16 除了能节约内存,还能同时节省模型的训练时间。在大部分的测试中,基于 FP16 的加速方法能够给模型训练能带来多一倍的加速体验。
3、张量核心的普及(NVIDIA Tensor Core),低精度计算是未来深度学习的一个重要趋势。
劣势:
溢出错误:数值范围小(更容易Overflow / Underflow)、舍入误差(Rounding Error,导致一些微小的梯度信息达不到16bit精度的最低分辨率,从而丢失)。
解决问题的方法:混合精度训练+动态损失放大
(1)混合精度训练
在某些模型中,fp16矩阵乘法的过程中,需要利用 fp32 来进行矩阵乘法中间的累加(accumulated),然后再将 fp32 的值转化为 fp16 进行存储。
换句不太严谨的话来说,也就是在内存中用FP16做储存和乘法从而加速计算,而用FP32做累加避免舍入误差。混合精度训练的策略有效地缓解了舍入误差的问题。
### torch.HalfTensor 操作
__matmul__
addbmm
addmm
addmv
addr
baddbmm
bmm
chain_matmul
conv1d
conv2d
conv3d
conv_transpose1d
conv_transpose2d
conv_transpose3d
linear
matmul
mm
mv
prelu
FP32 权重备份
(2)动态损失放大(Loss scaling)
混合精度训练,还是存在无法收敛的情况,原因是激活梯度的值太小,造成了下溢出(Underflow)。
Loss Scale 主要是为了解决 fp16 underflow 的问题。刚才提到,训练到了后期,梯度(特别是激活函数平滑段的梯度)会特别小,如果用 fp16 来表示,则这些梯度都会变成0(舍入误差),因此导致fp16 表示容易产生 underflow 现象。
为了解决梯度过小的问题,论文中对计算出来的loss值进行scale,由于链式法则的存在,loss上的scale会作用,同时也会作用在梯度上。这样比起对每个梯度进行scale更加划算。 scaled 过后的梯度,就会平移到 fp16 有效的展示范围内。
这样,scaled-gradient 就可以一直使用 fp16 进行存储了。只有在进行更新的时候,才会将 scaled-gradient 转化为 fp32,同时将scale抹去。论文指出, scale 并非对于所有网络而言都是必须的。而scale的取值为也会特别大,论文给出在 8 - 32k 之间皆可。
Pytorch可以通过使用torch.cuda.amp.GradScaler,通过放大loss的值来防止梯度的underflow(只在BP时传递梯度信息使用,真正更新权重时还是要把放大的梯度再unscale回去)
损失放大的思路是:
反向传播前,将损失变化手动增大2^k倍,因此反向传播时得到的中间变量(激活函数梯度)则不会溢出;
反向传播后,将权重梯度缩小2^k倍,恢复正常值。
3. 使用方法
下面是一个使用AMP训练模型的例子:
import torch
from torch.cuda.amp import autocast, GradScaler
# 定义模型和优化器
model = ...
optimizer = ...
# 定义GradScaler
scaler = GradScaler()
for epoch in range(num_epochs):
for input_data, labels in train_loader:
optimizer.zero_grad()
# 开启自动混合精度
with autocast():
outputs = model(input_data)
loss = loss_function(outputs, labels)
# 反向传播和梯度缩放
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
在这个例子中,我们使用autocast()包装了模型的前向传播和损失计算代码,以实现半精度浮点数计算。在反向传播之前,我们使用scaler.scale(loss)将损失缩放,并在反向传播之后使用scaler.step(optimizer)进行梯度更新。最后,我们使用scaler.update()更新缩放器。
值得注意的是,自动混合精度不适用于所有模型。在一些情况下,使用FP16可能会导致数值不稳定,从而影响模型准确性。此外,如果模型具有较小的计算开销,则使用FP16的性能提升可能不明显。因此,需要根据具体情况权衡利弊,并根据需要进行调整。
分布式训练
PyTorch支持多种分布式训练方式,包括数据并行、模型并行和跨机器分布式训练。以下是一些常见的PyTorch分布式训练方式:
- 数据并行:将数据划分为多个子批次,每个子批次在不同的GPU上运行,各自计算梯度并将结果发送到主GPU上进行平均,最终更新模型参数。这种方式适用于单机多卡的情况,可以有效利用GPU的计算资源。
- 模型并行:将模型划分为多个部分,不同的部分在不同的GPU上运行,各自计算梯度并将结果发送到主GPU上进行平均,最终更新模型参数。这种方式适用于模型较大,单个GPU无法容纳整个模型的情况。
- 跨机器分布式训练:将数据和模型分布在不同的机器上,通过MPI(Message Passing Interface)或RPC(Remote Procedure Call)进行通信和同步,各自计算梯度并将结果发送到主节点进行平均,最终更新模型参数。这种方式适用于大规模分布式集群的情况。
PyTorch是非常流行的深度学习框架,它在主流框架中对于灵活性和易用性的平衡最好。Pytorch有两种方法可以在多个GPU上切分模型和数据:nn.DataParallel和nn.distributedataparallel。DataParallel更易于使用(只需简单包装单GPU模型)。然而,由于它使用一个进程来计算模型权重,然后在每个批处理期间将分发到每个GPU,因此通信很快成为一个瓶颈,GPU利用率通常很低。而且,nn.DataParallel要求所有的GPU都在同一个节点上(不支持分布式),而且不能使用Apex进行混合精度训练。nn.DataParallel和nn.parallel.DistributedDataParallel的主要差异可以总结为以下几点(译者注):
- DistributedDataParallel支持模型并行,而DataParallel并不支持,这意味如果模型太大单卡显存不足时只能使用前者;
- DataParallel是单进程多线程的,只用于单机情况,而DistributedDataParallel是多进程的,适用于单机和多机情况,真正实现分布式训练;
- DistributedDataParallel的训练更高效,因为每个进程都是独立的Python解释器,避免GIL问题,而且通信成本低其训练速度更快,基本上DataParallel已经被弃用;
- 必须要说明的是DistributedDataParallel中每个进程都有独立的优化器,执行自己的更新过程,但是梯度通过通信传递到每个进程,所有执行的内容是相同的;
使用PyTorch进行分布式训练需要以下步骤:
- 初始化分布式环境:使用PyTorch提供的**torch.distributed.init_process_group()**函数初始化分布式环境,并指定分布式训练的参数,如进程数、通信方式、主机地址等。
- 定义模型:定义PyTorch模型,并使用torch.nn.parallel.DistributedDataParallel将模型分布到不同的GPU或机器上。
- 定义数据读取器:使用PyTorch提供的torch.utils.data.distributed.DistributedSampler对数据进行分布式采样,确保每个进程读取不同的数据。
# 1. 导入torch.utils.data.distributed.DistributedSampler
from torch.utils.data.distributed import DistributedSampler
# 2. 初始化,dataset是需要采样的数据集,num_replicas是总的进程数,rank是当前进程的编号,shuffle表示是否对数据进行随机打乱,seed是随机种子。
sampler = DistributedSampler(dataset, num_replicas=None, rank=None, shuffle=True, seed=0)
# 3. 这将在数据加载器中使用DistributedSampler来对数据进行分布式采样。注意,需要将sampler作为参数传递给数据加载器,并将num_workers设置为0或大于1,以避免进程之间的数据重复读取。
data_loader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, sampler=sampler, num_workers=num_workers, pin_memory=True)
需要注意的是,使用DistributedSampler时,数据集的大小应该被进程数整除,否则可能会导致最后一些进程无法读取到完整的数据。此外,由于在分布式训练中可能会存在一些进程无法访问某些数据集,因此建议使用较大的batch_size来减少数据集的访问次数,从而提高训练效率。
- 定义优化器和损失函数:定义PyTorch优化器和损失函数,与单机训练方式相同。
- 训练模型:在每个epoch中,使用分布式数据读取器读取分布式采样的数据,将数据传输到分布式模型中,计算梯度并进行参数更新。每个进程都需要进行同步,确保模型参数一致。
- 释放分布式环境:在分布式训练结束后,使用**torch.distributed.destroy_process_group()**函数释放分布式环境。
torch.distributed.launch使用方法
【pytorch记录】pytorch的分布式 torch.distributed.launch 命令在做什么呢
我们在训练分布式时候,会使用到 torch.distributed.launch
可以通过命令,来打印该模块提供的可选参数 python -m torch.distributed.launch --help
usage: launch.py [-h] [–nnodes NNODES] [–node_rank NODE_RANK]
[–nproc_per_node NPROC_PER_NODE] [–master_addr MASTER_ADDR] [–master_port MASTER_PORT]
[–use_env] [-m] [–no_python] [–logdir LOGDIR]
training_script …
torch.ditributed.launch参数解析(终端运行命令的参数):
nnodes:节点的数量,通常一个节点对应一个主机,方便记忆,直接表述为主机
node_rank:节点的序号,从0开始
nproc_per_node:一个节点中显卡的数量
-master_addr:master节点的ip地址,也就是0号主机的IP地址,该参数是为了让 其他节点 知道0号节点的位,来将自己训练的参数传送过去处理
-master_port:master节点的port号,在不同的节点上master_addr和master_port的设置是一样的,用来进行通信
torch.ditributed.launch相关环境变量解析(代码中os.environ中的参数):
WORLD_SIZE:os.environ[“WORLD_SIZE”]所有进程的数量
LOCAL_RANK:os.environ[“LOCAL_RANK”]每张显卡在自己主机中的序号,从0开始
RANK:os.environ[“RANK”]进程的序号,一般是1个gpu对应一个进程
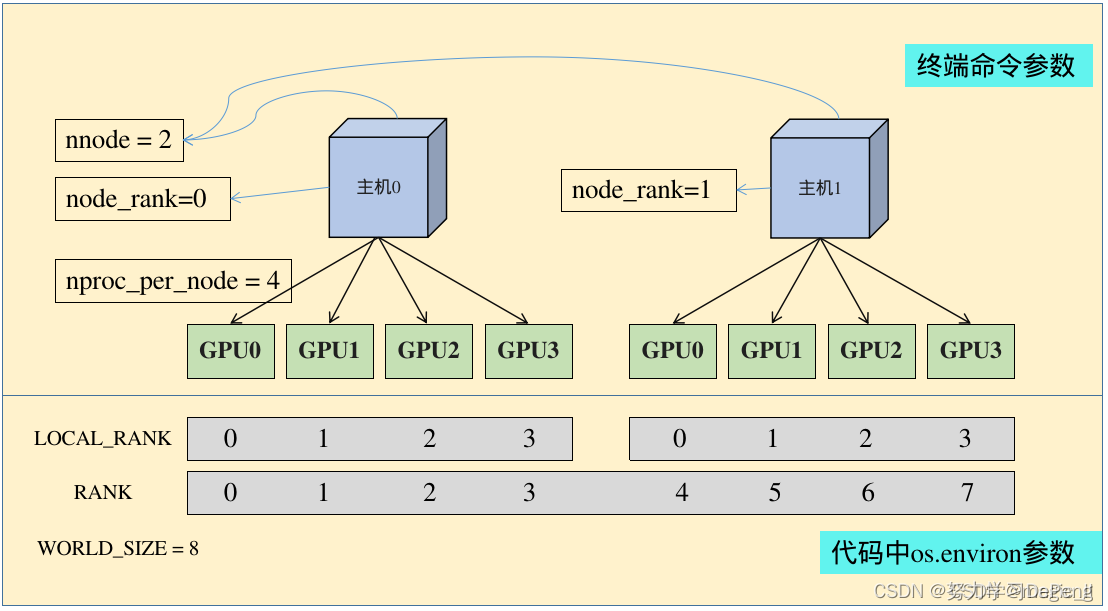
1. 多机多卡的分布式
在0号机器上调用
python -m torch.distributed.launch --nproc_per_node 4 --nnodes 2 --node_rank 0 --master_addr='172.18.39.122' --master_port='29500' train.py
在1号机器上调用
python -m torch.distributed.launch --nproc_per_node 4 --nnodes 2 --node_rank 1 --master_addr='172.18.39.122' --master_port='29500' train.py
注意:
命令中的【–master_addr=‘172.18.39.122’】指的是0号机器的IP,在0号机器上运行的命令中【node_rank】必须为0
只有当【nnodes】个机器全部运行,代码才会进行分布式的训练操作,否则一直处于等待状态
2. 单机多卡的分布式
单机多卡 训练
只需要说明 想要使用GPU的[编号]、[数量]即可。由于不需要不同机器之间的通信,就少了其余4个参数的设定
export CUDA_VISIBLE_DEVICES=0,1
python -m torch.distributed.launch --nproc_per_node=2 train.py
















 2186
2186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











