







python网络爬虫与信息提取
Requests库的安装
requests库是python爬取网页的第三方库。特点是简单而且简洁。
安装requests库之后在pycharm集成编译器中进行测试,查看百度网页的状态码:
import requests
r = requests.get(url="http://www.baidu.com")
print(r.status_code) #查看状态码
#200

Requests库的get方法
r=requests.get(url) 构造一个向服务器请求资源的Request对象,返回一个包含服务器资源的Response对象。Response对象包含从服务器返回的所有资源。完整参数如下:

Request对象和Response对象是两个最重要的对象。其中Response对象是最重要的对象,包含了爬虫得到的网页中的全部内容。
Response对象常用属性:


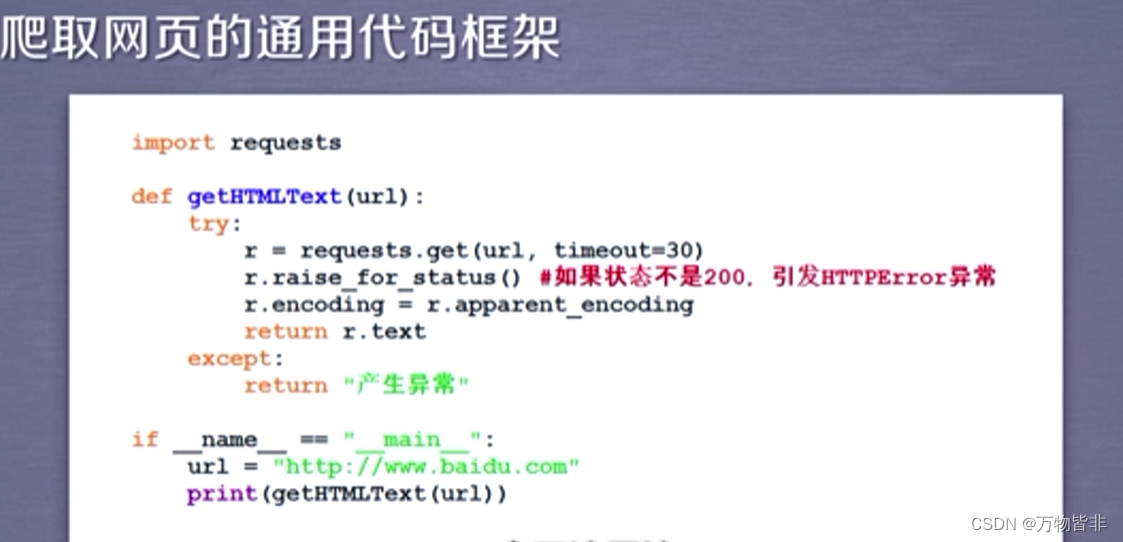
爬取网页的常用框架
http协议以及Requests方法
HTTP协议
超文本传输协议,是一种基于请求与响应的无状态的应用层协议。
请求与响应:用户发起请求,服务器做出相应
无状态:第一次请求和第二次请求无关联
http协议采用URL作为定位网络资源的标识。
格式: http://host[:post][path]
http对资源的操作(对应requests):

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









