







 本文介绍了几个在线的免费资源平台,包括盐神阁提供知乎小说阅读,ilovepdf进行文档格式转换,备胎书屋供小说下载,短视频去水印工具,体育直播网站,视频分享服务以及AI搜索引擎天工AI搜索和漫画网站Justamoment。
本文介绍了几个在线的免费资源平台,包括盐神阁提供知乎小说阅读,ilovepdf进行文档格式转换,备胎书屋供小说下载,短视频去水印工具,体育直播网站,视频分享服务以及AI搜索引擎天工AI搜索和漫画网站Justamoment。
一、盐神阁
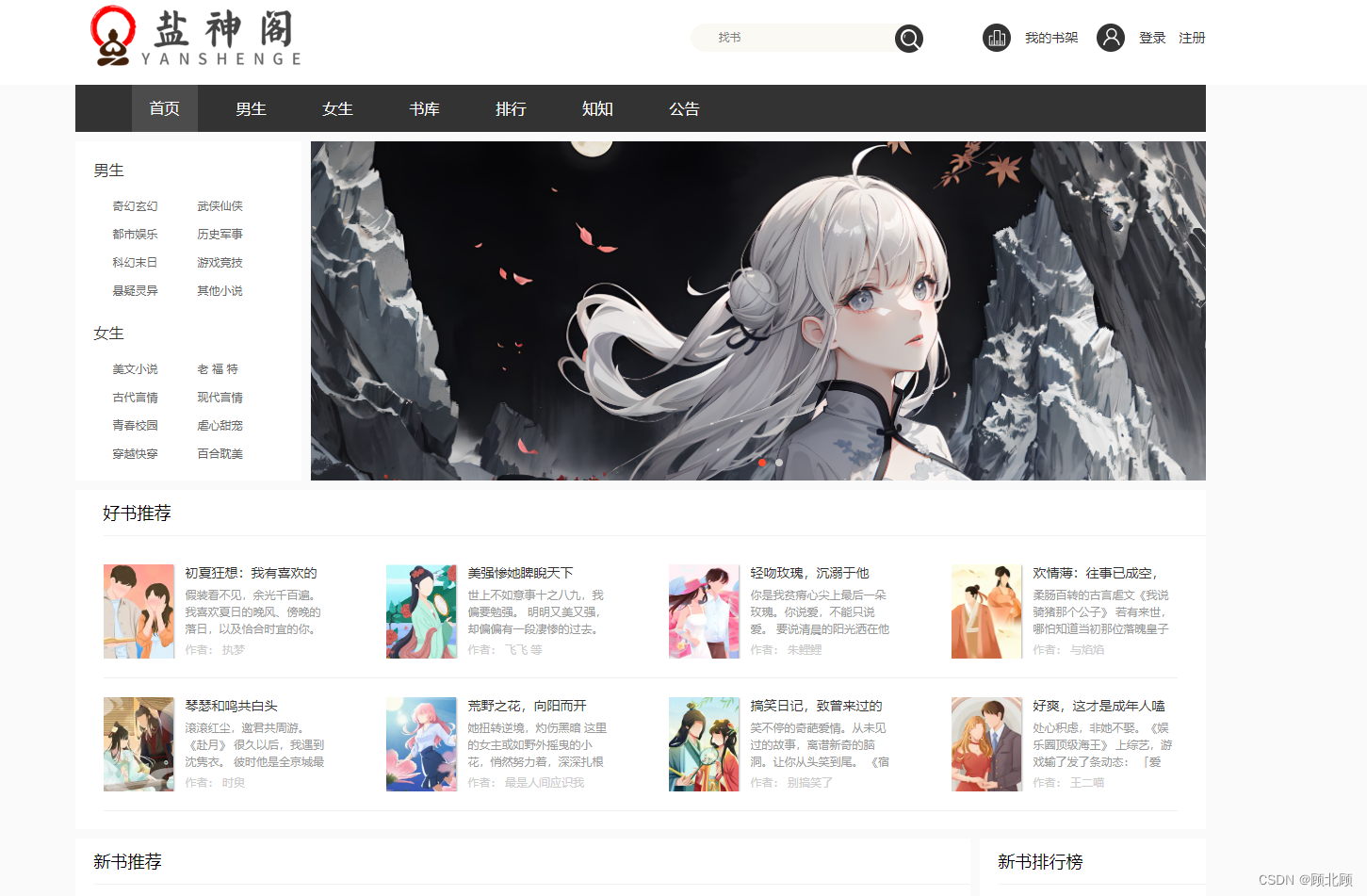
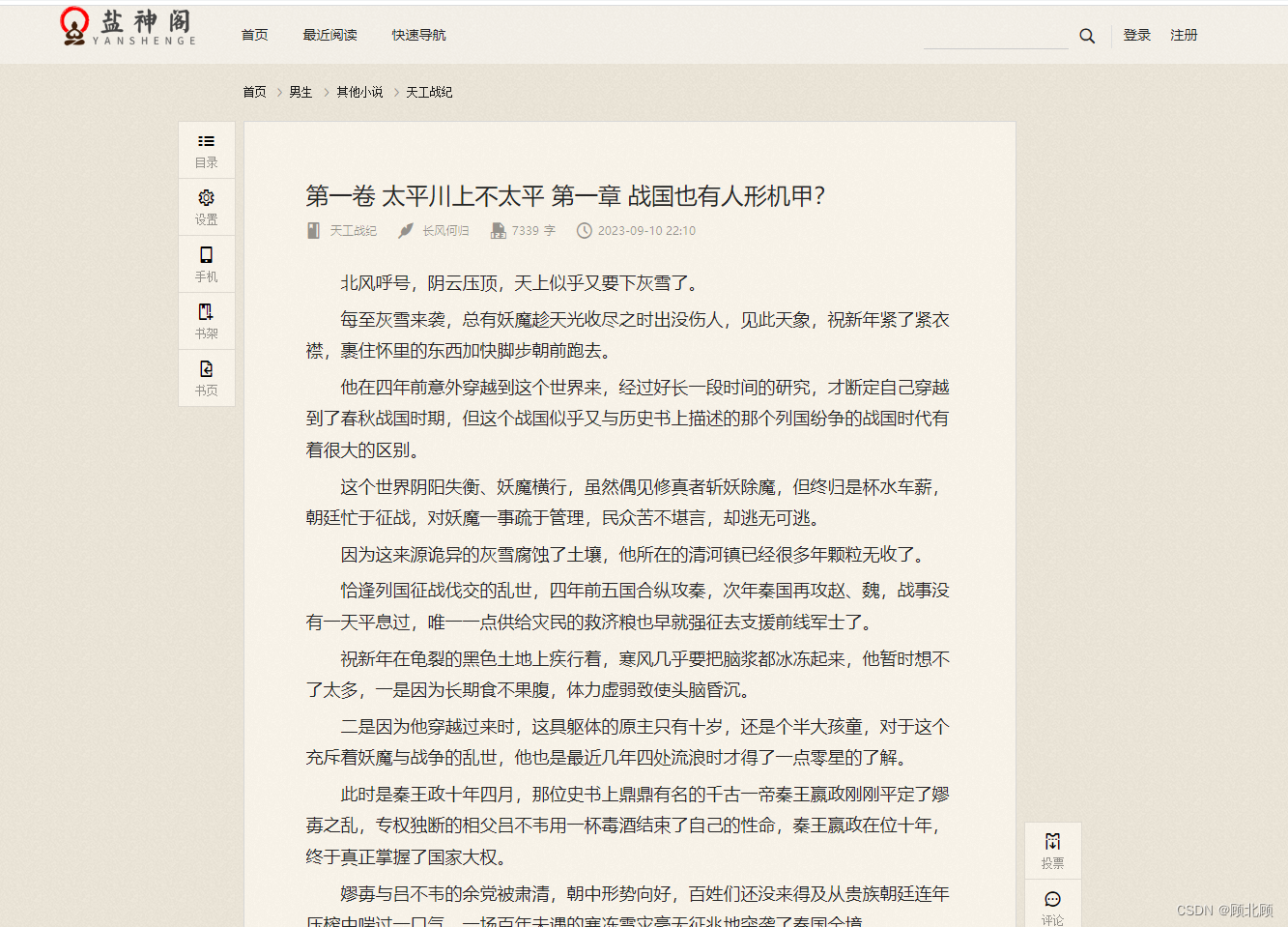
盐神阁知乎小说免费阅读网,知乎搬运工,我不是盐神
盐神阁是一个免费的知乎盐选文章搬运分享的网站(主要是小说),网站界面也非常好看干净,在线阅读知乎盐选文章也非常舒适,资源非常丰富,网站还提供免费文求文的服务,不用注册登录即可在线阅读
二、ilovepdf
iLovePDF | Online PDF tools for PDF lovers
这是一个完全免费的文章格式转换网站、可将PDF转为Word、Expcel、ppt、PDF压缩、拆分、以及其他类型格式的文章转换为PDF,可满足日常多数文档格式转换需求

三、备胎书屋
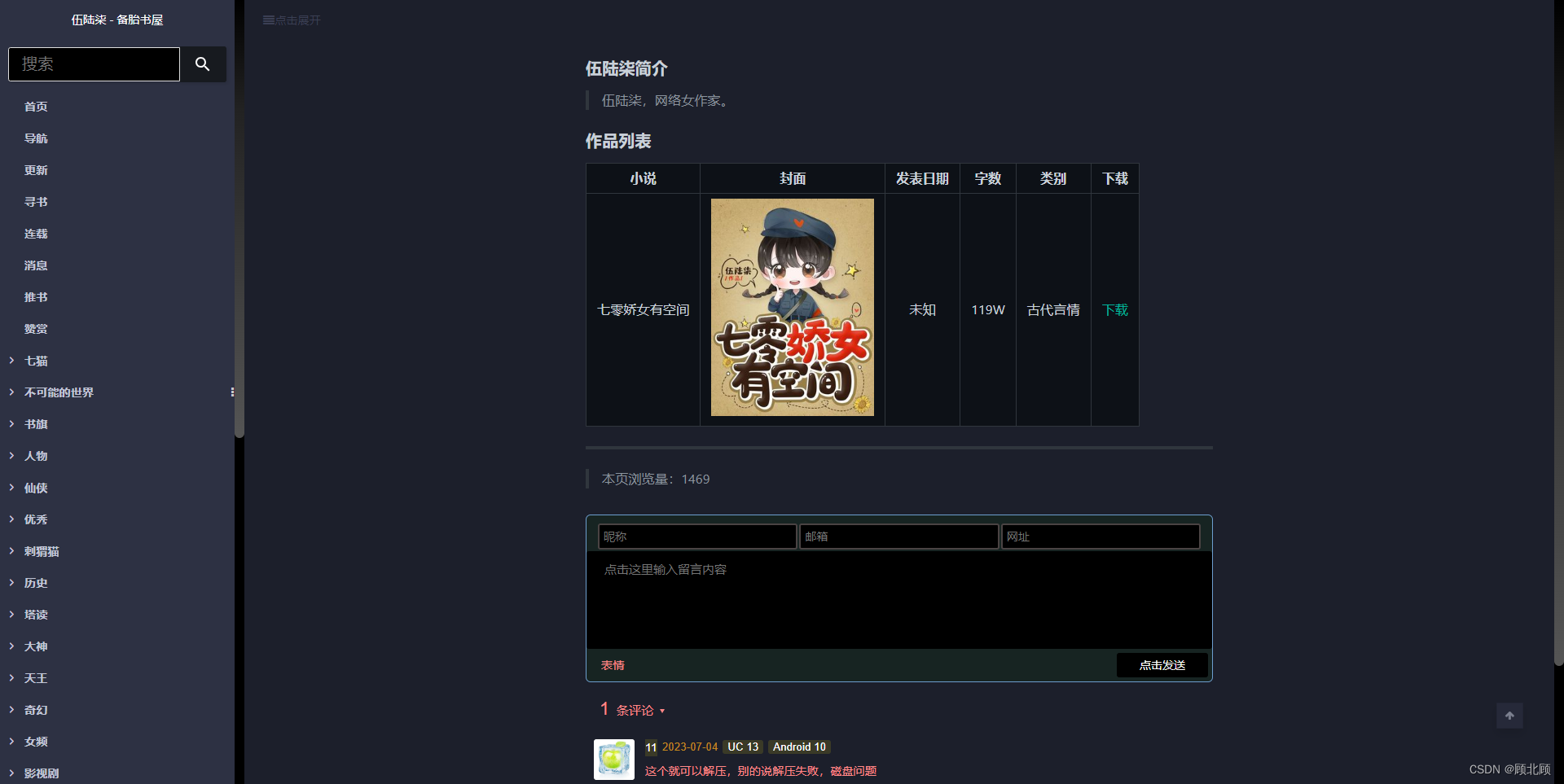
你好 - 备胎书屋
这个网站的资源很丰富,涵盖了全网最火的小说。网站不支持在线阅读,可免费下载阅读。推荐用微信阅读导入阅读

四、短视频/图集在线去水印解析
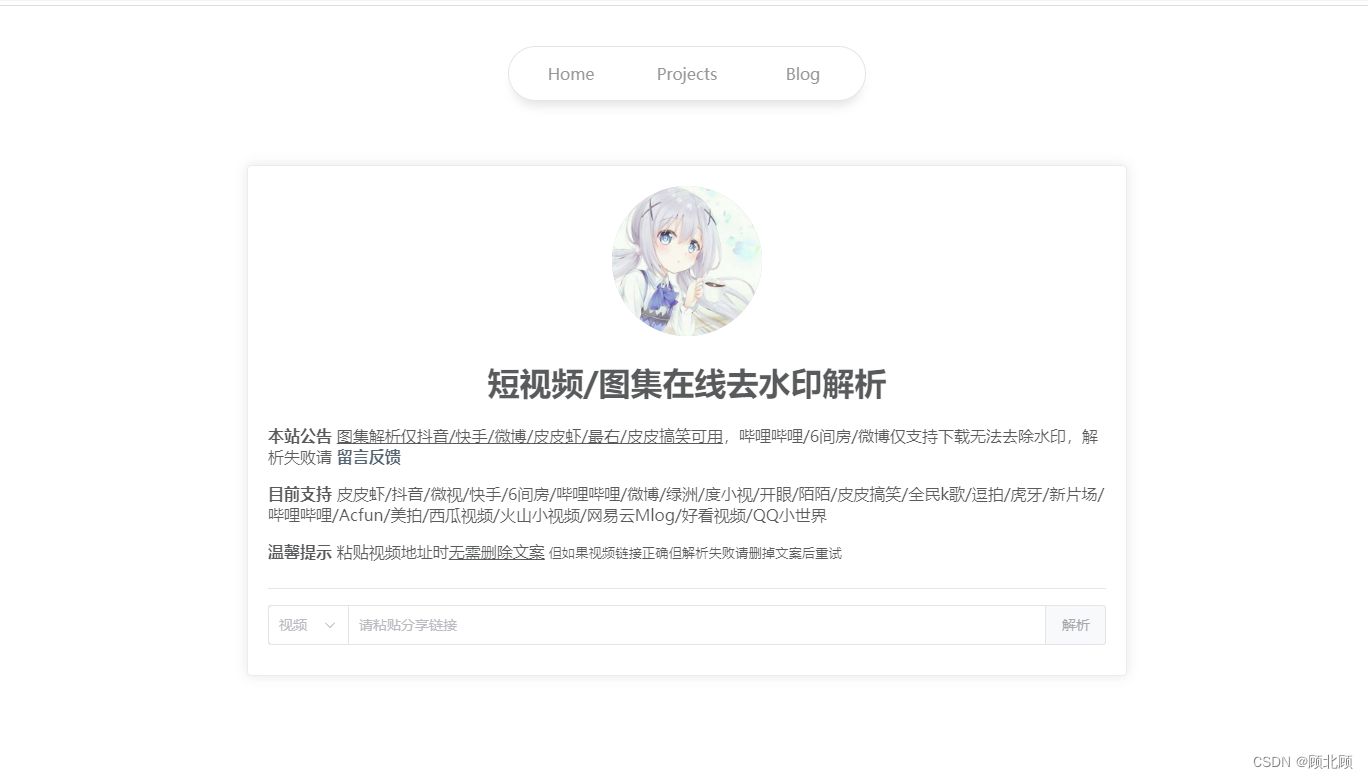
I Am I の 实验室
改网站可以去水印解析下载短视频网站视频。目前支持解析的平台有抖音/皮皮虾/火山/微视/微博/绿洲等平台
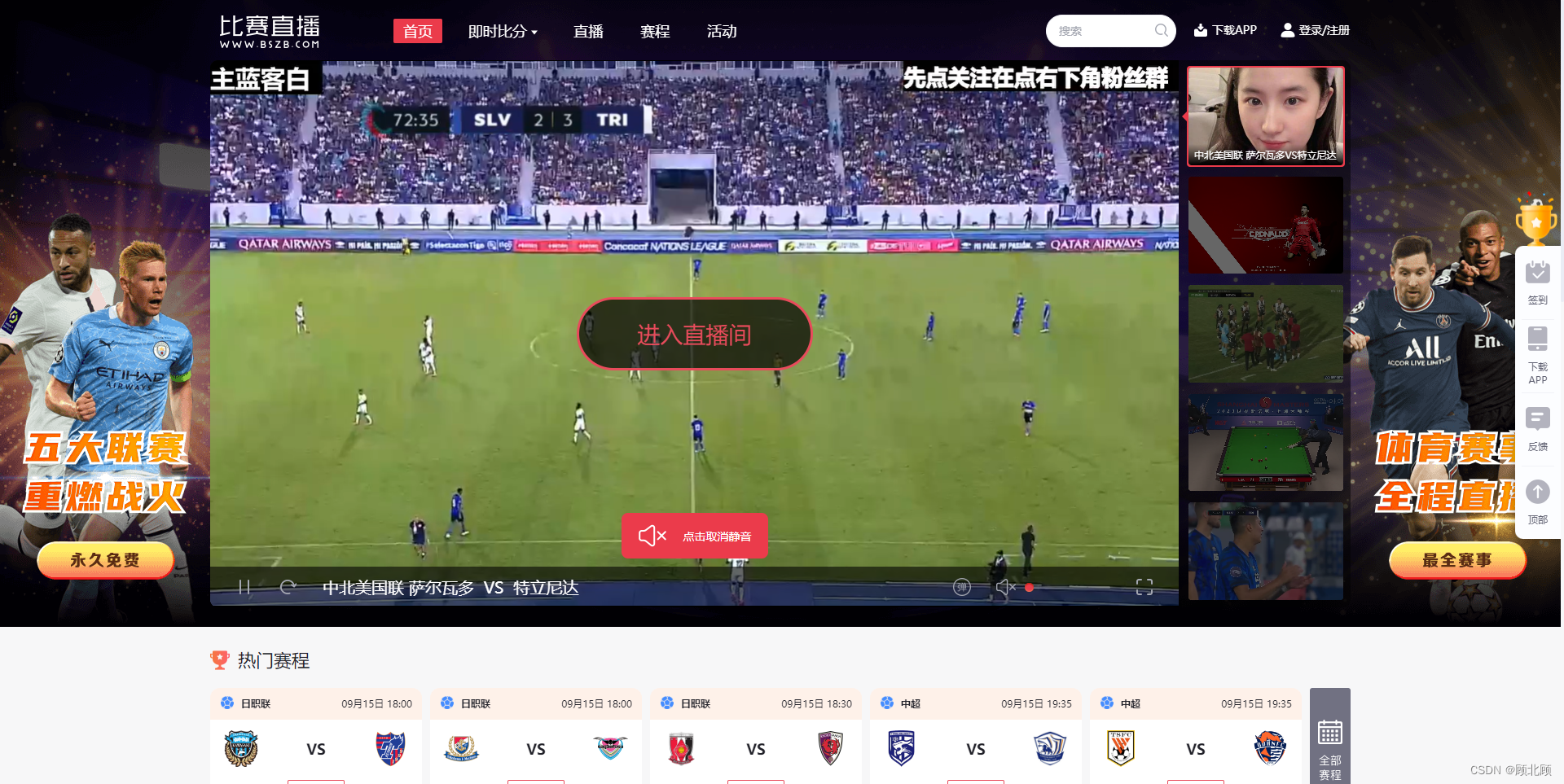
五、比赛直播
比赛直播-欧洲杯直播_世界杯直播_五大联赛直播_NBA直播_电竞直播,足球篮球全量数据
一个完全免费的体育赛事直播网站,不喜欢网站的还有安卓与苹果软件,高清流畅,还支持投屏到电视,体验还不错,直播广告不可信
六、视频网站分享
HDmoli - 高品质在线影视
好用的视频网站分享,可免费看奈飞视频。纸钞屋,海贼王真人版等
海贼王 真人版在线观看 - HDmoli


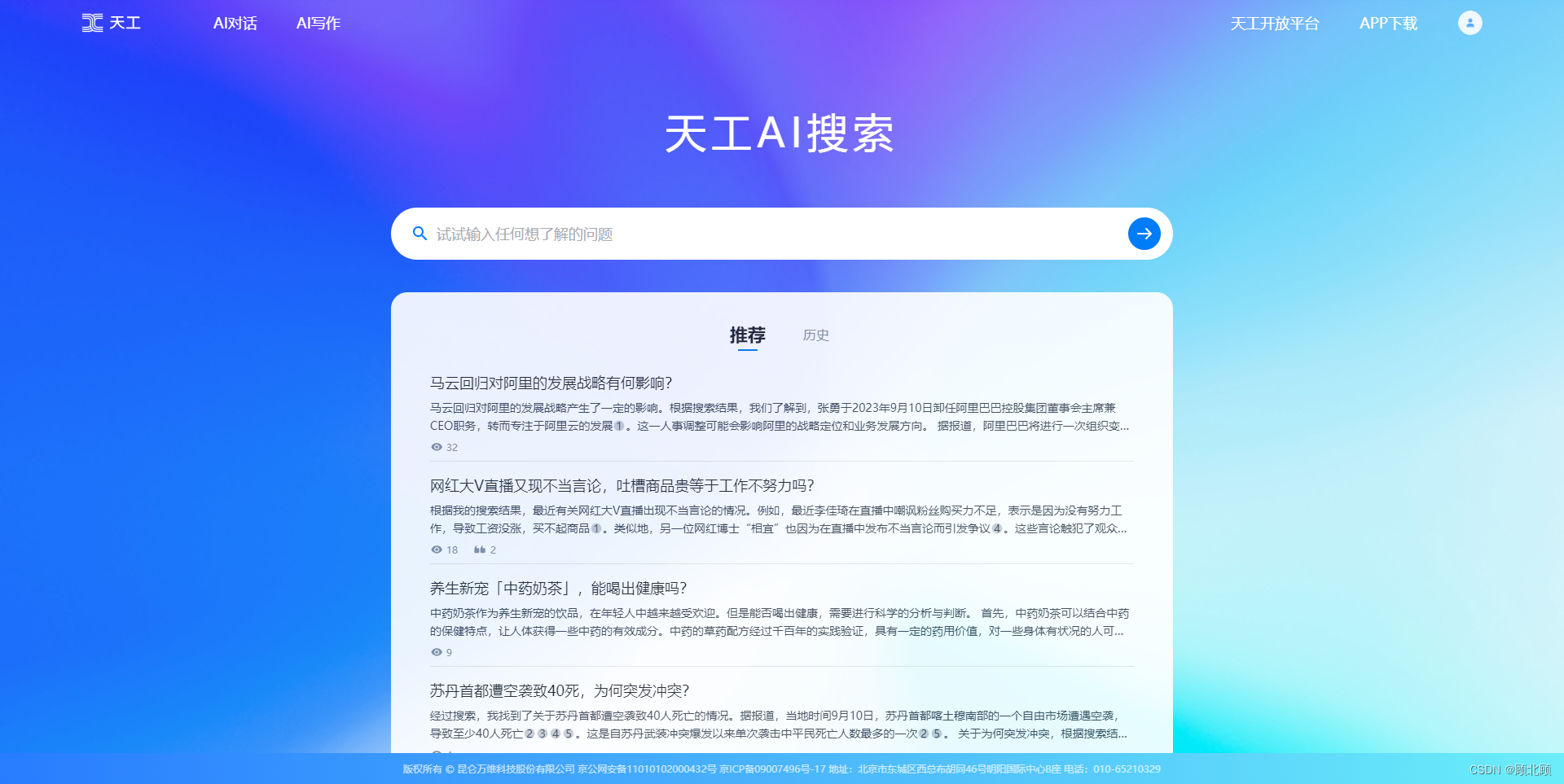
七、天工AI搜索
天工AI搜索 — 知识从这里开始
天工AI搜素是由昆仑万维开发的一种生成式搜索引擎,是国内首款融入大语言模型的AI搜索产品,简单来说,相比百度,他会总结搜索结果,给你提炼后的答案。
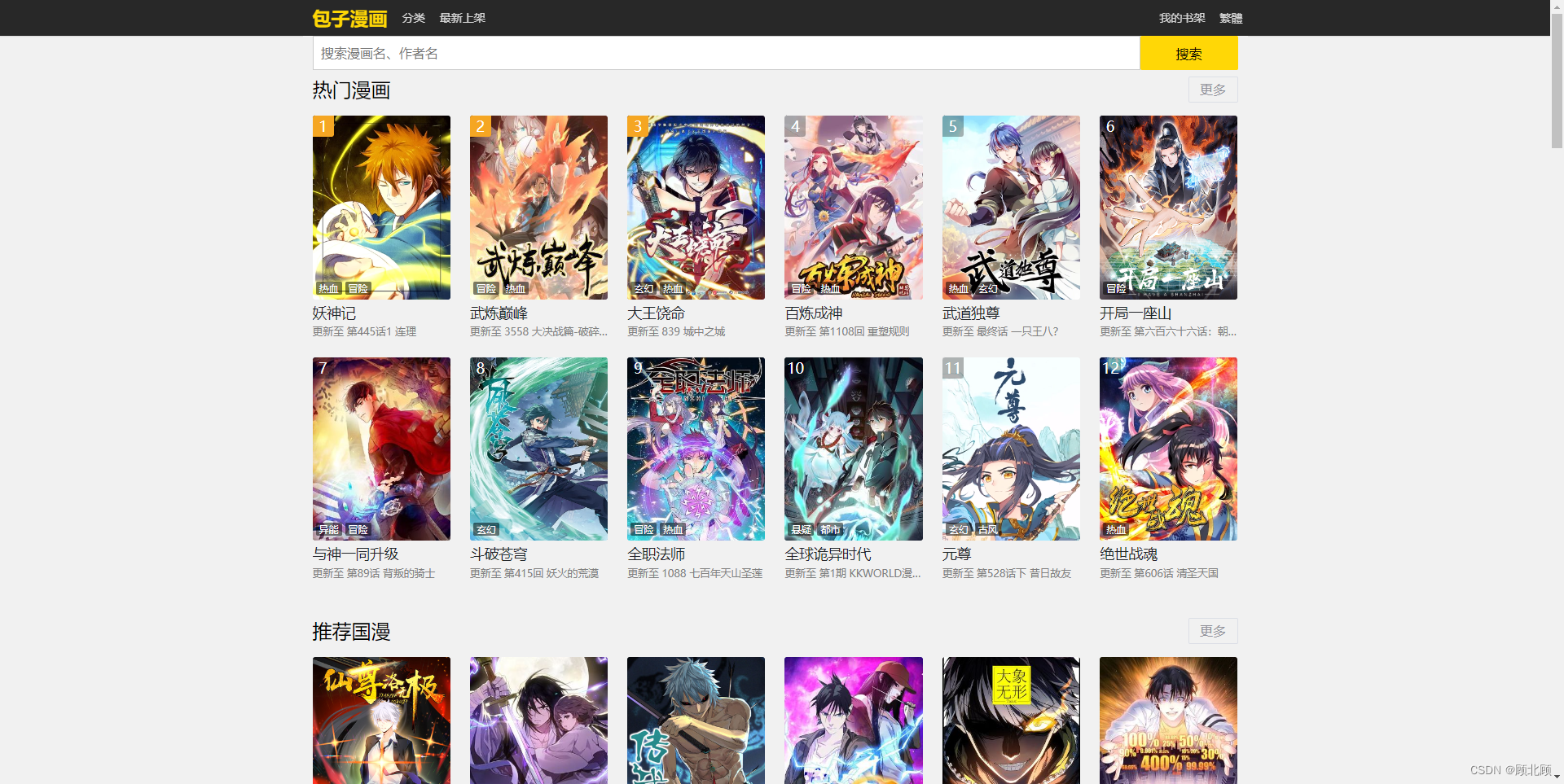
八、漫画网站
Just a moment…
整合了国内的许多漫画,更新速度也还可以



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









