







文章目录
一、文献简明(zero)
领域:NLP、大模型与生成式AI
标题:[2020] ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators(ELECTRA:将文本编码器预训练为鉴别器而非生成器)
作者:Clark et al.贡献:提出了ELECTRA模型,通过替换检测任务进行预训练,提高了模型的效率和性能。
链接:https://arxiv.org/pdf/2003.10555
二、快速预览(first)
1、标题分析
1. 标题的核心内容
标题的核心是“ELECTRA”,这是一个特定的模型名称,表明该研究介绍了一种名为ELECTRA的模型架构。ELECTRA是“Efficiently Learning an Encoder that Classifies Token Replacements Accurately”的缩写,意为“高效学习能够准确分类标记替换的编码器”。这表明该模型的主要目标是通过一种高效的方式对文本编码器进行预训练,使其能够准确区分文本中的标记是否被正确替换。
2. 预训练的背景与意义
“Pre-training Text Encoders”表明该研究聚焦于文本编码器的预训练过程。预训练是自然语言处理(NLP)领域的一个重要技术,通过在大规模无监督数据上进行预训练,模型可以学习到语言的通用特征,从而在后续的下游任务中表现出色。这种预训练方式能够显著提高模型的性能和泛化能力,是近年来NLP领域取得突破性进展的关键因素之一。
3. 鉴别器与生成器的对比
“as Discriminators Rather Than Generators”是标题的关键部分,它明确指出了ELECTRA模型的设计理念与传统预训练模型(如BERT)的不同。传统的预训练模型(如BERT)通常采用生成器的方式,通过预测被掩盖的标记来学习语言模型。而ELECTRA则采用了鉴别器的方式,即训练一个模型来判断文本中的标记是否被正确替换。这种设计的优势在于能够更高效地利用训练数据,减少计算资源的消耗,同时提高模型的性能。
4. 研究的创新性与价值
通过将文本编码器预训练为鉴别器而非生成器,ELECTRA在预训练模型的设计上提出了新的思路。这种创新不仅提高了模型的效率,还为NLP领域的发展提供了新的方向。ELECTRA模型的提出,表明在预训练模型的设计中,除了传统的生成器方式外,还可以通过其他方式(如鉴别器)来实现高效的预训练。这对于推动自然语言处理技术的发展具有重要意义。
5. 总结
标题“ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators”简洁明了地概括了该研究的核心内容和创新点。它不仅介绍了ELECTRA模型的名称和功能,还通过对比“鉴别器”和“生成器”的方式,突出了该模型的设计理念和优势。这一标题为读者提供了清晰的研究方向和重点,有助于快速理解该研究的价值和意义。
2、作者介绍

-
Kevin Clark
- 机构:斯坦福大学(Stanford University)
- 电子邮件:kevclark@cs.stanford.edu
- 备注:Kevin Clark是斯坦福大学的研究人员,专注于计算机科学领域。
-
Minh-Thang Luong
- 机构:Google Brain
- 电子邮件:thangluong@google.com
- 备注:Minh-Thang Luong是Google Brain团队的成员,Google Brain是Google的一个研究项目,专注于人工智能和机器学习。
-
Quoc V. Le
- 机构:Google Brain
- 电子邮件:qvl@google.com
- 备注:Quoc V. Le同样隶属于Google Brain,参与人工智能和机器学习的研究。
-
Christopher D. Manning
- 机构:斯坦福大学 & CIFAR Fellow
- 电子邮件:manning@cs.stanford.edu
- 备注:Christopher D. Manning是斯坦福大学的教授,同时也是CIFAR(加拿大高级研究所)的研究员,他在自然语言处理和人工智能领域有着重要的贡献。
这些作者可能共同参与了某项研究或项目,他们的合作可能涉及到自然语言处理、机器学习或人工智能的其他领域。
3、引用数
……
4、摘要分析

(1)翻译
掩码语言建模(MLM)预训练方法,如BERT,通过将一些标记替换为[MASK]来破坏输入,然后训练一个模型来重建原始标记。虽然它们在转移到下游自然语言处理(NLP)任务时能产生良好的结果,但通常需要大量的计算才能有效。作为替代方案,我们提出了一种更高效的样本预训练任务,称为替换标记检测。我们的方法不是掩盖输入,而是通过从小生成器网络中采样可能的替代项来替换一些标记。然后,我们不是训练一个模型来预测被破坏标记的原始身份,而是训练一个判别模型来预测每个标记在被破坏的输入中是否被生成器样本替换。通过彻底的实验表明,这种新的预训练任务比MLM更有效,因为任务是在所有输入标记上定义的,而不仅仅是被掩盖的小子集。结果表明,我们的方法学习到的上下文表示在相同的模型大小、数据和计算条件下,显著优于BERT学习到的。对于小模型来说,收益尤其显著;例如,我们在一台GPU上训练一个模型4天,其在GLUE自然语言理解基准测试中的表现超过了GPT(使用了30倍更多的计算)。我们的方法在大规模上同样有效,在使用相同计算量时,其性能与RoBERTa和XLNet相当,而在使用1/4计算量时则优于它们。
(2)分析
- 语言风格
- 学术性:摘要使用了专业的术语和结构,如“掩码语言建模(MLM)”、“自然语言处理(NLP)”、“上下文表示”等,体现了学术研究的严谨性。
- 客观性:摘要中对方法的描述和实验结果的陈述都保持了客观性,没有使用夸张或主观的表述。
- 结构
- 引言:首先介绍了现有方法(BERT)的局限性,即需要大量计算资源。
- 方法介绍:接着介绍了新提出的方法(替换标记检测),并详细说明了其与现有方法的不同之处。
- 实验结果:然后展示了实验结果,证明了新方法的有效性和优越性。
- 结论:最后总结了新方法在不同规模下的表现,强调了其在计算效率上的优势。
- 关键术语
- MLM(Masked Language Modeling):掩码语言建模,一种预训练语言模型的方法。
- NLP(Natural Language Processing):自然语言处理,研究如何使计算机能够理解和处理人类语言。
- GLUE(General Language Understanding Evaluation):通用语言理解评估,一个用于评估自然语言处理模型性能的基准测试。
- 翻译要点
- 准确性:翻译时需要准确传达原文的意思,特别是专业术语的翻译。
- 流畅性:翻译后的句子需要流畅自然,符合中文的表达习惯。
- 简洁性:在保持原文意思的基础上,尽量简化表述,避免冗长。
- 翻译后的效果
- 清晰性:翻译后的摘要清晰地传达了原文的意思,使读者能够快速理解研究的核心内容和结论。
- 专业性:使用了专业术语,符合学术研究的表达习惯。
- 对比性:通过对比新方法和现有方法的优缺点,突出了新方法的创新性和优势。
5、总结分析

(1)翻译
我们提出了一种名为替换标记检测的新自监督任务,用于语言表示学习。关键思想是训练一个文本编码器,以区分由小型生成网络产生的高质量负样本和输入标记。与掩码语言建模相比,我们的预训练目标在计算上更高效,并在下游任务上取得更好的性能。即使使用相对较少的计算资源,它也能表现良好,我们希望这将使研究人员和实践者更容易开发和应用预训练文本编码器,特别是那些计算资源较少的人。我们还希望未来的NLP预训练工作不仅考虑绝对性能,还考虑效率,并遵循我们在报告计算使用情况和参数数量以及评估指标方面的努力。
(2)分析
- 语言风格
- 学术性:结论部分使用了专业的术语和结构,如“自监督任务”、“文本编码器”、“下游任务”等,体现了学术研究的严谨性。
- 客观性:结论中对方法的描述和实验结果的陈述都保持了客观性,没有使用夸张或主观的表述。
- 结构
- 方法总结:首先总结了提出的新方法(替换标记检测)的核心思想和优势。
- 比较优势:接着将新方法与现有方法(掩码语言建模)进行比较,强调其在计算效率和性能上的优势。
- 实际应用:然后讨论了新方法在实际应用中的潜力,特别是对于计算资源有限的研究人员和实践者。
- 未来展望:最后提出了对未来研究的期望,希望未来的工作能够同时考虑效率和性能。
- 关键术语
- 自监督任务:一种不需要外部标注数据,通过利用数据本身的结构信息进行学习的任务。
- 文本编码器:一种将文本转换为数值表示的模型组件,通常用于下游任务。
- 下游任务:指在预训练模型的基础上进行的特定任务,如文本分类、情感分析等。
6、部分图表
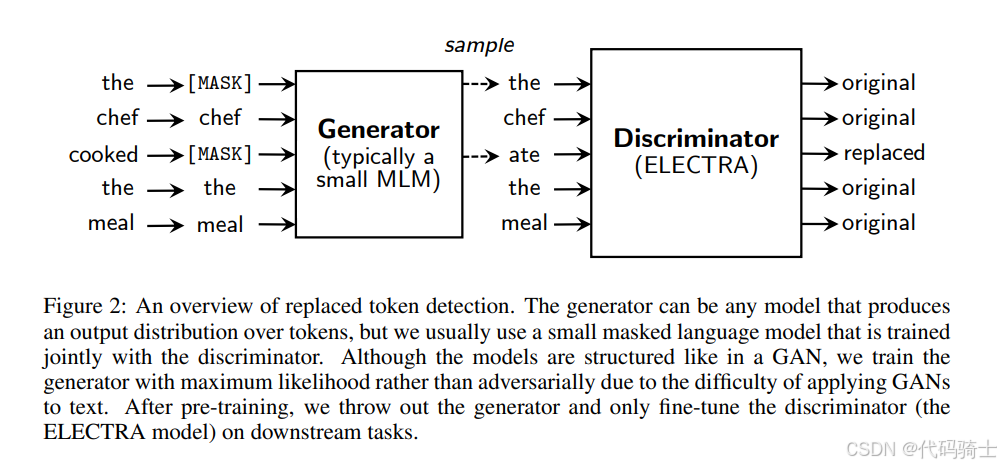
图表展示了替换标记检测(Replaced Token Detection)的概述,这是ELECTRA模型预训练的核心机制。该图表分为两个主要部分:生成器(Generator)和鉴别器(Discriminator)。
生成器(Generator)
- 功能:生成器负责生成可能的标记替换。通常,这可以通过一个小型的掩码语言模型(MLM)来实现。
- 过程:
- 输入句子中的某些标记被替换为[MASK]。
- 生成器尝试预测这些[MASK]标记的可能替代项。
- 在图中,“the"被替换为"ate”,“cooked"被替换为"meal”。
鉴别器(Discriminator,ELECTRA)
- 功能:鉴别器的任务是区分输入中的标记是原始的还是被替换的。
- 过程:
- 鉴别器接收来自生成器的输出。
- 它预测每个标记是“original”(原始的)还是“replaced”(被替换的)。
- 在图中,鉴别器需要判断“the”、“chef”、“ate”、“the”和“meal”这些标记的原始状态。
训练过程
- 生成器训练:生成器使用最大似然估计进行训练,而不是对抗性训练,因为将生成对抗网络(GAN)应用于文本存在困难。
- 鉴别器训练:鉴别器通过预测每个标记是否被替换来进行训练。
预训练后的处理
- 丢弃生成器:在预训练完成后,生成器被丢弃,只保留鉴别器(即ELECTRA模型)。
- 微调鉴别器:鉴别器在下游任务上进行微调,以适应特定的应用场景。
图表说明
- 图2:提供了替换标记检测的概览。生成器可以是任何产生标记输出分布的模型,但通常使用与鉴别器一起训练的小型掩码语言模型。尽管模型结构类似于GAN,但由于将GAN应用于文本的困难,我们使用最大似然而不是对抗性训练生成器。预训练后,我们丢弃生成器,仅在下游任务上微调鉴别器(ELECTRA模型)。
这个图表和说明清晰地展示了ELECTRA模型如何通过替换标记检测来进行预训练,以及这种方法如何提高计算效率和下游任务的性能。
7、引言分析
(1)翻译
当前最先进的语言表示学习方法可以被视为学习去噪自编码器。这些方法选择未标记输入序列的一小部分(通常为15%),掩盖这些标记的身份,然后训练网络以恢复原始输入。虽然这些掩码语言建模(MLM)方法由于学习双向表示而比传统语言模型预训练更有效,但它们会产生大量的计算成本,因为网络每次只从15%的标记中学习。
作为替代方案,我们提出了一种称为替换标记检测的预训练任务,其中模型学习区分真实输入标记和合理但合成生成的替换标记。我们的方法不是掩盖输入,而是通过从一个小的掩码语言模型中采样可能的替代项来破坏输入。然后,我们预训练网络作为判别器,预测每个标记是否为原始或替换。与MLM训练网络作为生成器预测被破坏标记的原始身份不同,我们的方法的一个关键优势是模型从所有输入标记中学习,而不仅仅是被掩盖的子集,使其在计算上更有效。
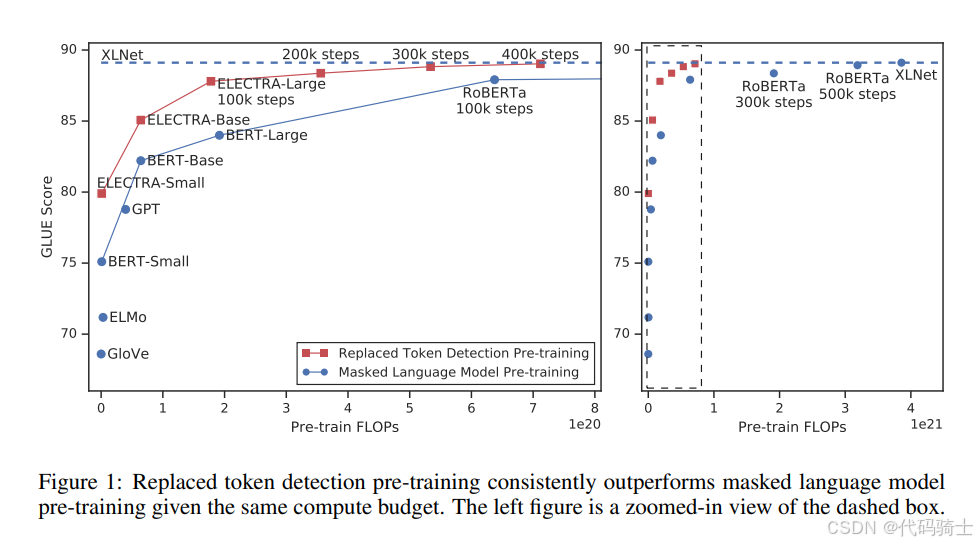
图1:替换标记检测预训练在相同的计算预算下始终优于掩码语言模型预训练。左图是虚线框的放大视图。
我们的方法类似于训练GAN的判别器。我们的方法不是对抗性的,因为生成被破坏标记的生成器是使用最大似然训练的,这是由于将GAN应用于文本的困难(Caccia et al., 2018)。
我们的方法称为ELECTRA,代表“高效学习分类标记替换的编码器”。在之前的工作中,我们应用它来预训练Transformer文本编码器,这些编码器可以在下游任务中微调。通过一系列实验,我们展示了从所有输入位置学习使ELECTRA比BERT训练得更快。我们还展示了ELECTRA在完全训练时在下游任务上实现更高的准确性。
大多数当前的预训练方法需要大量的计算才能有效,这引发了对其成本和可访问性的担忧。由于预训练具有更多的计算几乎总是导致更好的下游准确性,我们认为预训练方法的一个重要考虑因素应该是计算效率以及绝对的下游性能。从这个角度来看,我们训练了各种大小的ELECTRA模型,并评估了它们的下游性能与计算需求。特别是,我们在GLUE自然语言理解基准和SQuAD问答基准上进行了实验。ELECTRA在给定相同的模型大小、数据和计算的情况下,显著优于基于MLM的方法,如BERT和XLNet。例如,我们在1个GPU上训练4天构建了一个ELECTRA-Small模型。ELECTRA-Small在GLUE上比BERT模型高出5分,甚至超过了更大的GPT模型(Radford et al., 2018)。我们的方法在大规模上也有效,我们训练了一个ELECTRA-Large模型,其性能与RoBERTa和XLNet相当,尽管参数更少,并且使用了1/4的计算量进行训练。训练ELECTRA-Large进一步在GLUE上取得了更好的结果,甚至超过了ALBERT(Lan et al., 2019)在SQuAD 2.0上的表现。总的来说,我们的结果表明,区分真实数据和具有挑战性的负样本的判别任务比现有的生成方法在语言表示学习中更计算高效和参数高效。
(2)分析
- 语言风格
- 学术性:文本使用了专业的术语和结构,如“掩码语言建模(MLM)”、“生成对抗网络(GAN)”、“判别器”等,体现了学术研究的严谨性。
- 客观性:文本中对方法的描述和实验结果的陈述都保持了客观性,没有使用夸张或主观的表述。
- 结构
- 引言:首先介绍了现有方法(BERT)的局限性,即需要大量计算资源。
- 方法介绍:接着介绍了新提出的方法(替换标记检测),并详细说明了其与现有方法的不同之处。
- 实验结果:然后展示了实验结果,证明了新方法的有效性和优越性。
- 结论:最后总结了新方法在不同规模下的表现,强调了其在计算效率上的优势。
- 关键术语
- MLM(Masked Language Modeling):掩码语言建模,一种预训练语言模型的方法。
- GAN(Generative Adversarial Network):生成对抗网络,一种通过生成器和判别器进行对抗训练的模型。
- GLUE(General Language Understanding Evaluation):通用语言理解评估,一个用于评估自然语言处理模型性能的基准测试。
- SQuAD(Stanford Question Answering Dataset):斯坦福问答数据集,一个用于评估问答系统性能的数据集。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











