







在大部分程序员写代码或者教其他人写代码时,只要其他人函数参数用pass by value,而非pass by reference时,都会嗤之以鼻,觉得这是没有实力的表现。有部分人知道不能全用pass by reference,因为有时候会导致安全问题。但是基本没人知道其实在某种情况下pass by value性能不仅不低,而且会比pass by reference 性能高。
1.性能角度
如果函数内,将接收的参数拿去拷贝一份,再把副本拿去做处理, 那么性能更高的方法是直接在函数的接收参数用pass by value。 因为编译器这时候可能生成更高效的代码。
例如下面这份代码
void printString(std::string& s)
{
std::string cur = s;
cur += "dd";
}
void printHighString(std::string s)
{
s += "dd";
}
static void BM_demo1(benchmark::State& state) {
std::string ss("hello world");
for (auto _ : state)
printString(ss);
}
BENCHMARK(BM_demo1)->Iterations(1000000); //用于注册测试函数
static void BM_demo2(benchmark::State& state) {
std::string ss("hello world");
for (auto _ : state)
printHighString(ss);
}
BENCHMARK(BM_demo2)->Iterations(1000000); //用于注册测试函数
// Register the function as a benchmark
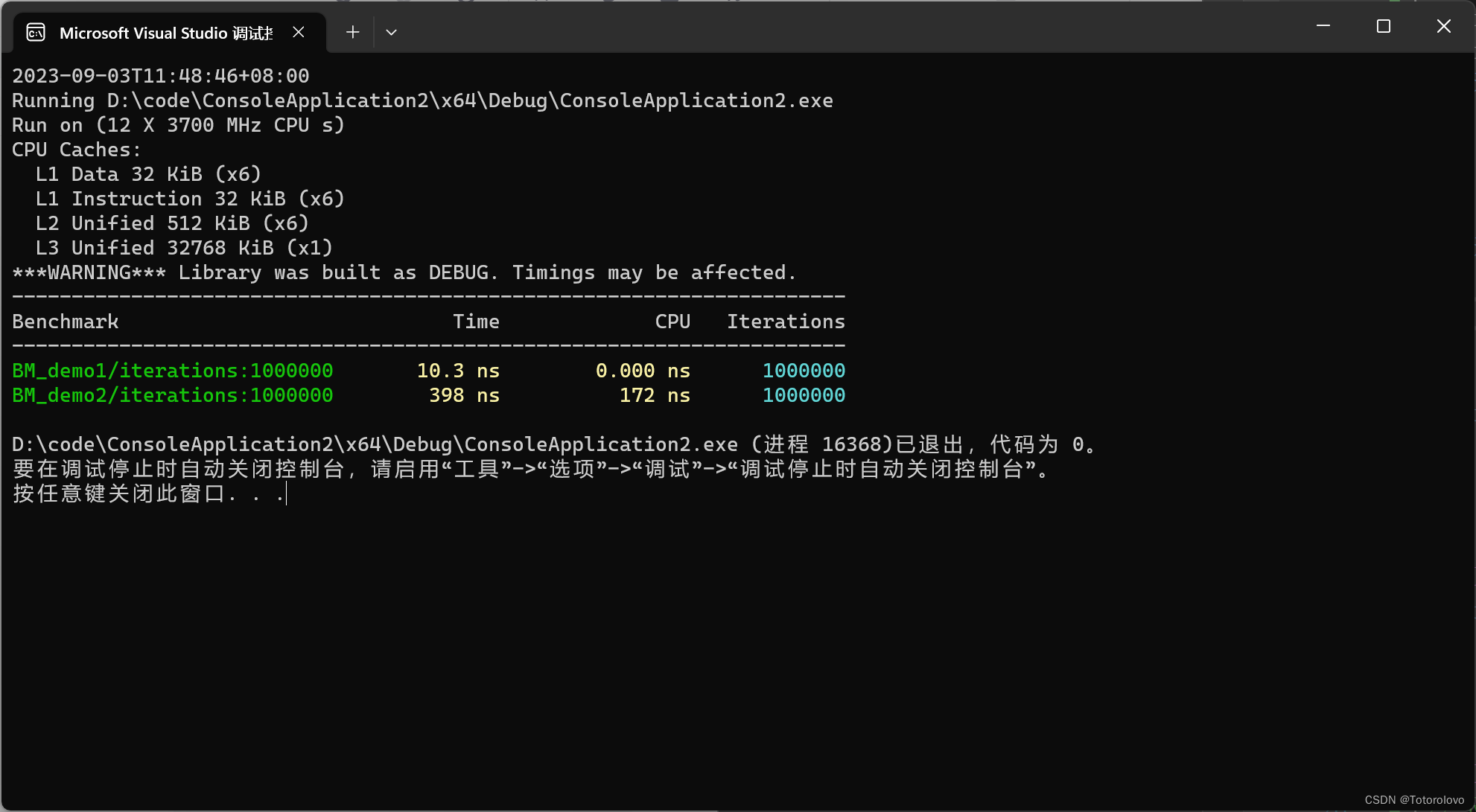
BENCHMARK_MAIN(); //程序入口可以看到printString函数用pass by reference,printHighString函数用pass by value,按照一般人理解,这里肯定printString性能高啊!,光觉得谁性能高是没用的,所有我这里采用google-benchmark来得到结果。

可以看到printHighString函数的运行时间,不仅不慢,甚至还比printString函数更快。
为什么会有这种违反直觉的结果呢?这是由于他们忽略了一个最重要的问题,printString函数里面将引用传递的参数拿来拷贝了一份,再将副本拿去操作。而printHighString函数pass by value方式传参,编译器可以优化。
如果我们将printString函数中的拷贝副本操作取消,得到以下结果
这里确实就符合了大家对pass by reference 和pass by value 性能差距的固有认知。















 807
807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









