







ELK日志管理系统的搭建
环境准备
Linux安装Elasticsearch
使用的 Elasticsearch的版本是7.6.2。Elasticsearch7.x要求 Linux内核必须是4+版本以上。
在linux操作系统中,查看内核的版本的命令是
uname -a

我使用的是Linux的CentOS8 内核版本是4.18满足要求
为Elasticserach提供完善的系统配置
Elasticsearch.在 Linux中安装部署的时候,需要系统为其提供若干系统配置。如:应用可启动的线程数、应用可以在系统中划分的虚拟内存、应用可以最多创建多少文件等。
1.1修改限制信息
vim /etc/security/limits.conf
是修改系统中允许应用最多创建多少文件等的限制权限。Linux默认来说,一般限制应用最多创建的文件是65535个。但是Elasticsearch至少需要65536 的文件创建权限。
修改后的内容为
* soft nofile 65536
* hard nofile 65536
*代表任意用户,soft表示内存中虚拟文件(软文件),hard表示落地到磁盘的具体文件(硬文件), nofile,表示权限,65536表示个数。
1.2修改线程开启限制
在centOS7+版本中编辑配置文件是:
vim /etc/security/limits.conf
是修改系统中允许用户启动的进程开启多少个线程。默认的 Linux限制root用户开启的进程可以开启任意数量的线程,其他用户开启的进程可以开启1024个线程。必须修改限制数为4096+。因为Elasticseanch.至少需要4096的线程池预备。Elasticsearch,在5.x版本之后,强制要求在linux.,中不能使用root用户启动Elasticsearch进程。所以必须使用其他用户启动Elasticsearch,进程才可以。
* soft nproc 4096
root soft nproc unlimited
*任何用户nproc创建线程数量4096
注意:Linux 低版本内核为线程分配的内存是128K。4.x版本的内核分配的内存更大.如果虚拟机的内存是1G,最多只能开启3000+个线程数。至少为虚拟机分配1.5G以上的内存,保险起见建议2G以上.
1.3修改系统控制权限
CentoS8中的配置文件为:
vim /etc/sysctl.d/99-sysctl.conf
系统控制文件是管理系统中的各种资源控制的配置文件。Elasticsearch.,需要开辟一个65536字节以上空间的虚拟内存。Linux默认不允许任何用户和应用直接开辟虚拟内存。
新增内容为:
vm.max_map_count=655360
使用命令 : sysctl -p 让系统控制权限配置生效。
CentOS Docker 安装
手动安装
较旧的 Docker 版本称为 docker 或 docker-engine 。如果已安装这些程序,请卸载它们以及相关的依赖项。
$ sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
使用 Docker 仓库进行安装
在新主机上首次安装 Docker Engine-Community 之前,需要设置 Docker 仓库。之后,您可以从仓库安装和更新 Docker。
设置仓库
安装所需的软件包。yum-utils 提供了 yum-config-manager ,并且 device mapper 存储驱动程序需要 device-mapper-persistent-data 和 lvm2
$ sudo yum install -y yum-utils \
device-mapper-persistent-data \
lvm2
使用官方源地址(比较慢)
$ sudo yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
可以选用国内的一些源地址
阿里云
$ sudo yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
清华大学源
$ sudo yum-config-manager \
--add-repo \
https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/centos/docker-ce.repo
安装 Docker Engine-Community
安装最新版本的 Docker Engine-Community 和 containerd
$ sudo yum install docker-ce docker-ce-cli containerd.io docker-compose-plugin
要安装特定版本的 Docker Engine-Community,请在存储库中列出可用版本,然后选择并安装:
1、列出并排序您存储库中可用的版本。此示例按版本号(从高到低)对结果进行排序。
$ yum list docker-ce --showduplicates | sort -r
docker-ce.x86_64 3:18.09.1-3.el7 docker-ce-stable
docker-ce.x86_64 3:18.09.0-3.el7 docker-ce-stable
docker-ce.x86_64 18.06.1.ce-3.el7 docker-ce-stable
docker-ce.x86_64 18.06.0.ce-3.el7 docker-ce-stable
2、通过其完整的软件包名称安装特定版本,该软件包名称是软件包名称(docker-ce)加上版本字符串(第二列),从第一个冒号(:)一直到第一个连字符,并用连字符(-)分隔。例如:docker-ce-18.09.1。
$ sudo yum install docker-ce-<VERSION_STRING> docker-ce-cli-<VERSION_STRING> containerd.io
启动 Docker
$ sudo systemctl start docker
查看docker版本
$ sudo docker -v

通过运行 hello-world 镜像来验证是否正确安装了 Docker Engine-Community 。
$ sudo docker run hello-world
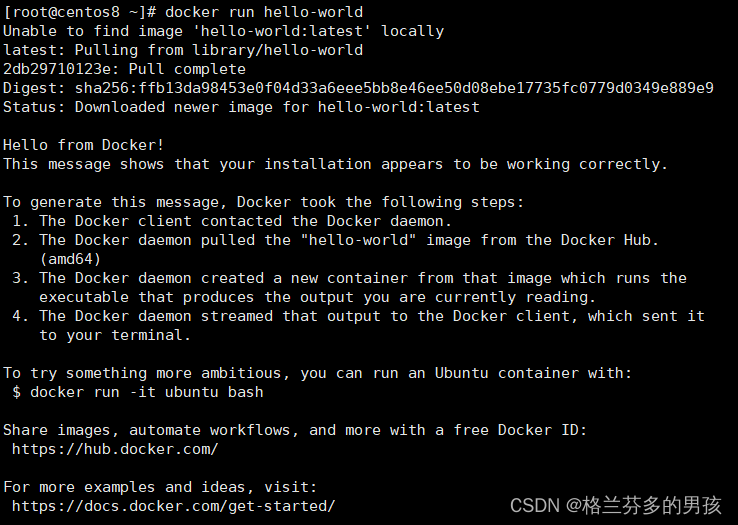
设置 docker 开机自启
$ sudo systemctl enable docker
卸载 docker
删除安装包:
yum remove docker-ce
删除镜像、容器、配置文件等内容:
rm -rf /var/lib/docker
Docker安装Elasticsearch
开启docker软件。
systemctl start docker
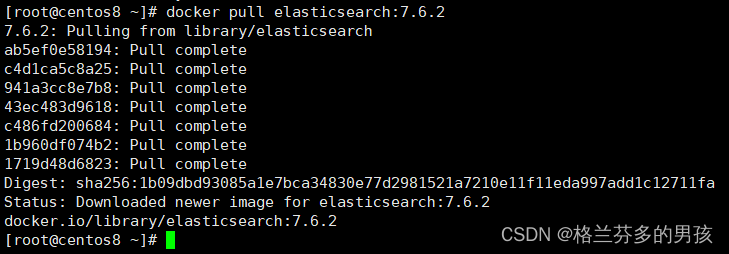
拉取Elasticsearch镜像
docker pull elasticsearch:7.6.2
在docker hub 官网中搜索自己需要安装的东西 找到需要的版本复制即可

镜像拉取完成
创建并启动容器
–name名字为es
-d后台启动
-p端口号。9200restful 访问端口,9300为java 代码访问端口
discovery.type=single-node集群模式:单机版
docker run --name=es -d -p 9200:9200 -p 9300:9300 --restart=always -e "discovery.type=single-node" elasticsearch:7.6.2

重启docker 检查是否开机自启 发现已经成功启动es

查看es日志
docker logs -f es
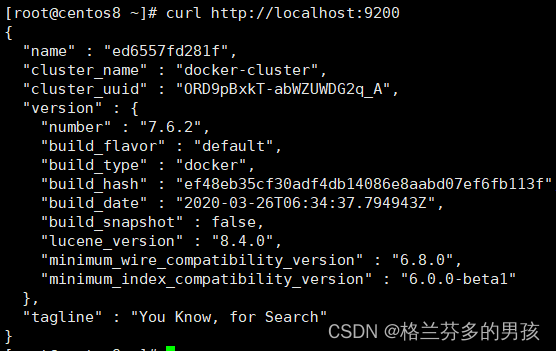
测试是否成功启动
curl http://localhost:9200
Docker安装Kibana
kibana 版本必领和ES 的版本对应
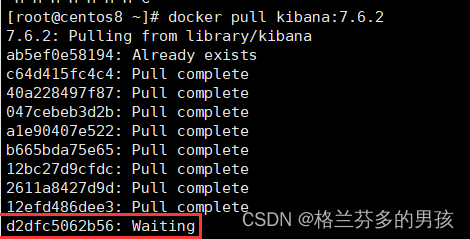
拉取镜像
docker pull kibana:7.6.2
出现一直wait时可以选择换个wifi或者热点
新建并且启动容器
–link es:es中第一个es是容器名,第二个es 是容器别名。设置link后才能让容器互通。
docker run -it -d --name kibana --restart=always --link es:es -p 5601:5601 kibana:7.6.2
修改Kibana参数
docker exec -it kibana /bin/bash # 进入到容器的内部
cd config
vi kibana.yml
将虚拟机的ip地址替换原本的主机地址
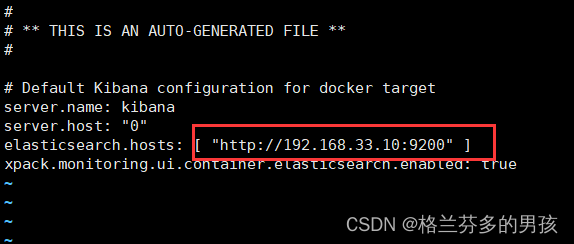
保存退出后重启kibana
docker restart kibanna
之后在浏览器中输入 虚拟机ip地址+:5601 就可以进入了
效果对比 减少了输入


Docker安装中文分词器
进入容器
docker exec -it es /bin/bash
安装IK
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.6.2/elasticsearch-analysis-ik-7.6.2.zip
安装完成后退出并且重启es

利用kibana测试

分词结果如下
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "一个",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "一",
"start_offset" : 2,
"end_offset" : 3,
"type" : "TYPE_CNUM",
"position" : 3
},
{
"token" : "个",
"start_offset" : 3,
"end_offset" : 4,
"type" : "COUNT",
"position" : 4
},
{
"token" : "年轻",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "小老师",
"start_offset" : 6,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "老师",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 7
}
]
}
自定义分词器
主要分为以下几步:
1.进入 docker 找到主词典 main.dic 的位置(直接打开会乱码,需要将其拷贝出docker 再修改)
2.使用 pwd 指令查询其具体位置
/usr/share/elasticsearch/config/analysis-ik
3. 退出docker
4. 新建文件夹 将 main.dic 文件拷贝下来
5. 修改 main.dic 即加入自己需要的词条
6. 将其拷贝回 docker 即 /usr/share/elasticsearch/config/analysis-ik
拷贝指令如下
docker cp /usr/local/es/extra_main.dic es:/usr/share/elasticsearch/config/analysis-ik
后面的路基指的是背拷贝到的位置
mian.dic 的位置

pwd 指令 查看当前具体文件夹位置

测试

分词结果

Docker安装Logstash
拉取镜像
docker pull
启动容器
docker run -it -p 4560:4560 --restart=always --name logstash -d logstash:7.6.2
配置logstash
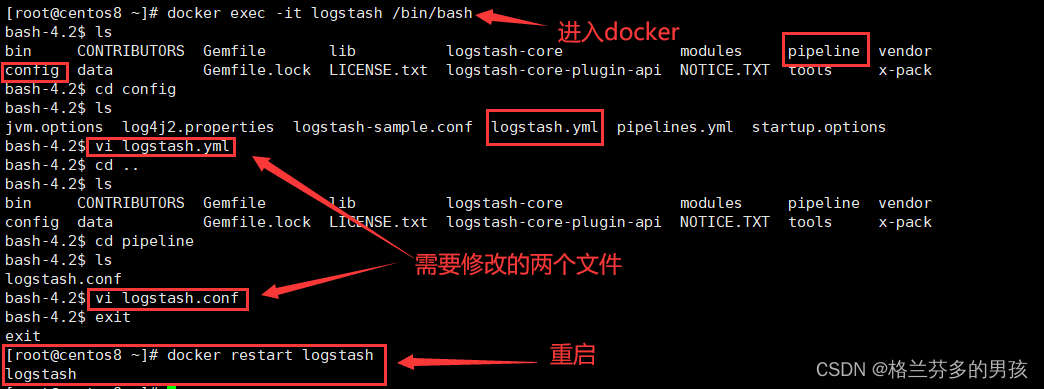
logstsh.yml文件
http.host: "0.0.0.0"
xpack.monitoring.elasticsearch.hosts: [ "http://192.168.33.10:9200" ]
logstash.conf文件
input {
tcp {
mode => "server"
port => 4560
}
}
filter{
}
output {
elasticsearch {
action => "index"
hosts => "192.168.33.10:9200"
index => "test_log"
}
}
Elasticsearch
查询 mapping 关系
get index_test4/_mappings
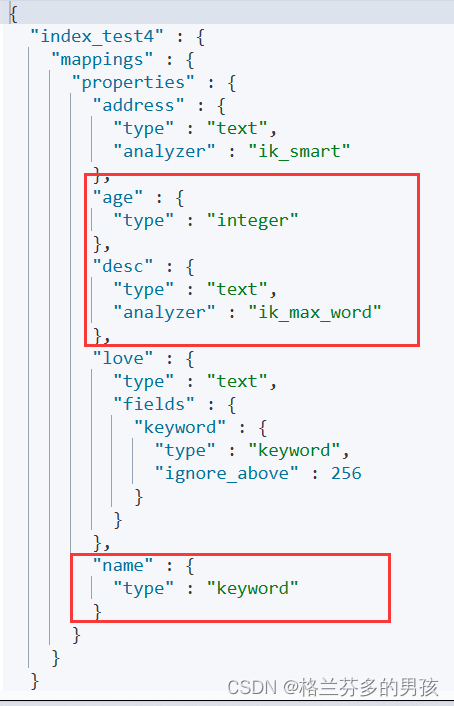
添加新字段mapping
put index_test4/_mapping
{
"properties":{
"address":{
"type":"text",
"analyzer":"ik_smart"
}
}
}
Kibana基础语法
GET _search
{
"query": {
"match_all": {}
}
}
get _cat/indices?v
get _cat/shards?v
put index_test
put index_test2
{
"settings":{
"number_of_shards":2,
"number_of_replicas":2
}
}
put index_test2/_settings
{
"number_of_replicas":1
}
delete index_test2
#新增document put方法
put index_test3/_doc/1
{
"name":"why123",
"age":12
}
get index_test3/_search
#强制新增
put index_test3/_create/2
{
"name":"why1233",
"age":123
}
#新增document post 方法
post index_test3/_doc
{
"name":"why66",
"age":18
}
#根据主键去查询
get index_test3/_doc/2
#批量查询
get index_test3/_mget
{
"docs":[
{
"_id":1
},
{
"_id":2
}
]
}
#更新Document
post index_test3/_update/2
{
"doc":{
"name":"why"
}
}
#删除Document
delete index_test3/_doc/1
#bulk批量增删改
post _bulk
{"create":{"_index":"index_test3","_id":5}}
{"name":"name-value","age":123}
{"index":{"_index":"index_test3","_id":6}}
{"name":"啦啦啦阿联","age":12345}
{"update":{"_index":"index_test3","_id":6}}
{"doc":{"age":90}}
{"delete":{"_index":"index_test3","_id":6}}
get index_test3/_search
# 分词器
## 默认分词器standard
get _analyze
{
"text":"I am a teacher",
"analyzer":"standard"
}
## 安装完ik中文分词器
get _analyze
{
"text":"我是一个年轻小老师",
"analyzer":"ik_max_word"
}
## 自定义分词器 王怀于
get _analyze
{
"text":"我是一个年轻小老师,名字叫王怀于",
"analyzer":"ik_max_word"
}
get index_test3/_mappings
# 自定义 mapping 关系
put index_test4
{
"mappings":{
"properties":{
"name":{
"type":"keyword"
},
"age":{
"type":"integer"
},
"desc":{
"type":"text",
"analyzer":"ik_max_word"
}
}
}
}
get index_test4/_mappings
# 添加新字段mapping
put index_test4/_mapping
{
"properties":{
"address":{
"type":"text",
"analyzer":"ik_smart"
}
}
}
put index_test4/_doc/1
{
"name":"张三",
"age":20,
"desc":"我是中国人",
"address":"浙江杭州"
}
get index_test4/_analyze
{
"field":"address",
"text":"浙江杭州"
}
put index_test4/_doc/2
{
"name":"李四",
"age":18,
"desc":"我是上海人",
"address":"浙江杭州",
"love":"sleep"
}
## 测试数据的导入
put test_search
{
"mappings":{
"properties":{
"dname":{
"type":"text",
"analyzer":"standard"
},
"ename":{
"type":"text",
"analyzer":"standard"
},
"eage":{
"type":"long"
},
"hiredate":{
"type":"date"
},
"gender":{
"type":"keyword"
}
}
}
}
## 批量
post test_search/_bulk
{"index":{}}
{"dname":"Sales Department","ename":"张三","eage":20,"hiredate":"2019-01-01","gender":"男性"}
{"index":{}}
{"dname":"Sales Department","ename":"李四","eage":21,"hiredate":"2019-02-01","gender":"男性"}
{"index":{}}
{"dname":"Development Department","ename":"王五","eage":23,"hiredate":"2019-03-01","gender":"男性"}
{"index":{}}
{"dname":"Development Department","ename":"赵六","eage":20,"hiredate":"2018-01-01","gender":"男性"}
{"index":{}}
{"dname":"Development Department","ename":"韩梅梅","eage":24,"hiredate":"2019-05-01","gender":"女性"}
{"index":{}}
{"dname":"Development Department","ename":"钱虹","eage":29,"hiredate":"2018-03-01","gender":"女性"}
get test_search/_search
{
"query":{
"match_all": {}
}
}
get test_search/_search
{
"query":{
"match": {
"ename": "张三"
}
}
}
get _cat/indices?v
get index_item/_mappings
get index_item/_search
# 分页查询
get test_log/_search
{
"from": 0,
"size": 20
}
Elasticsearch 中的 Mapping 问题
强调:
- 1.类型必须记住。
-
- text 和 keyword 区别。
-
- mapping 一定生效不允许修改。所以创建索引时直接指定 mapping 关系。
Mapping在Elasticsearch.中是非常重要的一个概念。决定了一个index中的field 使用什么数据格式存储,使用什么分词器解析,是否有子字段等。
自定义 mapping 关系
# 自定义 mapping 关系
put index_test4
{
"mappings":{
"properties":{
"name":{
"type":"keyword"
},
"age":{
"type":"integer"
},
"desc":{
"type":"text",
"analyzer":"ik_max_word"
}
}
}
}
java 连接 Elasticsearch
1.添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
2.application.properties中配置连接
spring.elasticsearch.rest.uris=http://192.168.33.10:9200
3.编写实体类
/**
* 自定义mapping关系是通过实体类进行控制的。
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
//定义类和索引的关系
@Document(indexName = "index_item",shards = 1,replicas = 1)
public class Item {
/*
在spring data es 中要求所有属性都必须要有对应注解,否则自动映射
*/
@Id
//在实体类中,可以起名id或者_id都可以映射上
private String id;
@Field(name = "title",type = FieldType.Text,analyzer = "ik_max_word")
private String title;
@Field(name = "price",type = FieldType.Long)
private Long price;
@Field(name = "catName",type = FieldType.Keyword)
private String catName;
}
4.测试
@SpringBootTest
class SpringdataesApplicationTests {
@Autowired
private ElasticsearchRestTemplate elasticsearchRestTemplate;
@Test
void contextLoads() {
// 调用代码实现映射关系
// spring data 4.x 操作索引都是通过 IndexOperations 进行操作
IndexOperations indexOperations = elasticsearchRestTemplate.indexOps(Item.class);
if (!indexOperations.exists()) {
//创建索引,所有配置为默认值,没有mapping关系
boolean result1 = indexOperations.create();
System.out.println(result1);
//自定义mapping
// 根据类中注解产生mapping
Document document = indexOperations.createMapping(Item.class);
boolean result2 = indexOperations.putMapping(document);
System.out.println(result2);
}
}
/**
* 删除索引
*/
@Test
void deleteIndex() {
IndexOperations indexOperations = elasticsearchRestTemplate.indexOps(Item.class);
indexOperations.delete();
}
/**
* 文档的增删改查
*/
/**
* 新增
*/
@Test
void save() {
Item item = new Item();
item.setCatName("手机");
item.setPrice(1999L);
item.setTitle("性价比手机");
item.setId("1");
Item result = elasticsearchRestTemplate.save(item);
System.out.println(result);
}
/**
* \
* 批量新增
*/
@Test
void saveM() {
Item item1 = new Item(null, "华为手机", 2999l, "手机");
Item item2 = new Item(null, "小米手机", 2999l, "手机");
Iterable<Item> items = elasticsearchRestTemplate.save(item1, item2);
Iterator<Item> iterator = items.iterator();
while ((iterator.hasNext())) {
System.out.println(iterator.next());
}
}
@Test
void saveM2() {
Item item1 = new Item(null, "联想电脑", 7999l, "电脑");
Item item2 = new Item(null, "小米电脑", 4999l, "电脑");
List<Item> list = new ArrayList<>();
list.add(item1);
list.add(item2);
Iterable<Item> items = elasticsearchRestTemplate.save(list);
Iterator<Item> iterator = items.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
/**
* 删除
*/
@Test
void delete() {
String id = elasticsearchRestTemplate.delete("Q5IzLYcBwwnrdP0y83gc", Item.class);
System.out.println(id);
}
@Test
void delete2() {
Item item = new Item();
item.setId("RJIzLYcBwwnrdP0y83gc");
//参数是对象时只考虑id,其他有没有 和 对不对 都不影响删除
String delete = elasticsearchRestTemplate.delete(item);
System.out.println(delete);
}
/**
* 修改操作 即 新增操作 全量替换
*/
@Test
void save2() {
Item item = new Item();
item.setCatName("手机");
item.setPrice(1999L);
item.setTitle("性价比手机");
item.setId("1");
Item result = elasticsearchRestTemplate.save(item);
System.out.println(result);
}
/**
* 查询操作
*/
@Test
//根据主键查询
void search() {
Item item = elasticsearchRestTemplate.get("SJI6LYcBwwnrdP0y0nia", Item.class);
System.out.println(item);
}
@Test
// 模糊查询
void search2() {
Query query = new NativeSearchQuery(QueryBuilders.queryStringQuery("手机"));
SearchHits<Item> search = elasticsearchRestTemplate.search(query, Item.class);
List<SearchHit<Item>> searchHits = search.getSearchHits();
for (SearchHit<Item> searchHit : searchHits) {
System.out.println(searchHit.getContent());
}
}
@Test
// 查询全部
void search3() {
Query query = new NativeSearchQuery(QueryBuilders.matchAllQuery());
SearchHits<Item> search = elasticsearchRestTemplate.search(query, Item.class);
List<SearchHit<Item>> searchHits = search.getSearchHits();
for (SearchHit<Item> searchHit : searchHits) {
System.out.println(searchHit.getContent());
}
}
@Test
// 条件查询
void search4() {
Query query = new NativeSearchQuery(QueryBuilders.matchQuery("title", "电脑"));
SearchHits<Item> search = elasticsearchRestTemplate.search(query, Item.class);
List<SearchHit<Item>> searchHits = search.getSearchHits();
for (SearchHit<Item> searchHit : searchHits) {
System.out.println(searchHit.getContent());
}
}
@Test
//短语查询
void search5() {
Query query = new NativeSearchQuery(QueryBuilders.matchPhraseQuery("title", "电脑"));
SearchHits<Item> search = elasticsearchRestTemplate.search(query, Item.class);
List<SearchHit<Item>> searchHits = search.getSearchHits();
for (SearchHit<Item> searchHit : searchHits) {
System.out.println(searchHit.getContent());
}
}
@Test
//rang查询
void search6() {
Query query = new NativeSearchQuery(QueryBuilders.rangeQuery("price").gt(2000).lt(5000));
SearchHits<Item> search = elasticsearchRestTemplate.search(query, Item.class);
List<SearchHit<Item>> searchHits = search.getSearchHits();
for (SearchHit<Item> searchHit : searchHits) {
System.out.println(searchHit.getContent());
}
}
/**
* 排序和分页
*/
@Test
void sortPage() {
Query query = new NativeSearchQuery(QueryBuilders.matchAllQuery());
//排序
query.addSort(Sort.by(Sort.Direction.DESC, "price"));
//分页
query.setPageable(PageRequest.of(1, 2));
SearchHits<Item> search = elasticsearchRestTemplate.search(query, Item.class);
List<SearchHit<Item>> searchHits = search.getSearchHits();
for (SearchHit<Item> searchHit : searchHits) {
System.out.println(searchHit.getContent());
}
}
/**
* 高亮查询
*/
@Test
void h1() {
Query query = new NativeSearchQuery(QueryBuilders.matchQuery("title","手机"));
HighlightBuilder builder = new HighlightBuilder();
builder.preTags("<span style='color:red;'>");
builder.postTags("/<span>");
builder.field("title");
HighlightQuery highlightQuery = new HighlightQuery(builder);
query.setHighlightQuery(highlightQuery);
SearchHits<Item> search = elasticsearchRestTemplate.search(query, Item.class);
// 第二个hits
List<SearchHit<Item>> searchHits = search.getSearchHits();
for (SearchHit<Item> searchHit : searchHits) {
Item item = searchHit.getContent();
System.out.println("非高亮数据" + item);
List<String> list = searchHit.getHighlightField("title");
//有高亮数据
if (list != null && list.size() > 0) {
item.setTitle(list.get(0));
}
System.out.println("添加高亮字段后的数据" + item);
}
}
}
java项目输出日志到logstash
1.添加依赖
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>6.3</version>
</dependency>
2.配置logback.xml
<?xml version="1.0" encoding="UTF-8"?>
<!--该日志将日志级别不同的log信息保存到不同的文件中 -->
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<springProperty scope="context" name="springAppName" source="spring.application.name"/>
<!-- <!–在日志工程中输出的位置–>-->
<!-- <property name="logback.logdir" value="C:\\logs"/>-->
<!-- <property name="logback.appname" value="logfile"/>-->
<property name="LOG_FILE" value="${BUILD_FOLDER:-build}/${springAppName}" />
<!-- 控制台的日志输出样式 -->
<property name="CONSOLE_LOG_PATTERN"
value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}}"/>
<!-- 控制台输出 -->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFO</level>
</filter>
<!-- 日志输出编码 -->
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- <!– 输出到文件-前期暂时保留 –>-->
<!-- <appender name="fileLog" class="ch.qos.logback.core.rolling.RollingFileAppender">-->
<!-- <File>${logback.logdir}/${logback.appname}.log</File>-->
<!-- <!–滚动策略,按照时间滚动 TimeBasedRollingPolicy–>-->
<!-- <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">-->
<!-- <!–文件路径,定义了日志的切分方式——把每一天的日志归档到一个文件中,以防止日志填满整个磁盘空间–>-->
<!-- <FileNamePattern>${logback.logdir}/${logback.appname}.%d{yyyy-MM-dd}.log</FileNamePattern>-->
<!-- <!–只保留最近90天的日志–>-->
<!-- <maxHistory>90</maxHistory>-->
<!-- <!–用来指定日志文件的上限大小,那么到了这个值,就会删除旧的日志–>-->
<!-- <!–<totalSizeCap>1GB</totalSizeCap>–>-->
<!-- </rollingPolicy>-->
<!-- <!–日志输出编码格式化–>-->
<!-- <encoder>-->
<!-- <charset>UTF-8</charset>-->
<!-- <pattern>%d [%thread] %-5level %logger{36} %line - %msg%n</pattern>-->
<!-- </encoder>-->
<!-- </appender>-->
<!-- 为logstash输出的JSON格式的Appender -->
<!-- <appender name="logstash" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>192.168.130.33:9250</destination>
日志输出编码
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<pattern>
<pattern>
{
"severity": "%level",
"service": "${springAppName:-}",
"trace": "%X{X-B3-TraceId:-}",
"span": "%X{X-B3-SpanId:-}",
"exportable": "%X{X-Span-Export:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message",
"stack_trace": "%exception{5}"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender> -->
<appender name="logstash" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>192.168.33.10:4560</destination>
<encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"/>
</appender>
<!--指定最基础的日志输出级别-->
<root level="INFO">
<!--appender将会添加到这个loger-->
<appender-ref ref="console"/>
<!-- <appender-ref ref="fileLog"/>-->
<appender-ref ref="logstash"/>
</root>
</configuration>
3.运行项目
在kibana客户端查询结果

搭建日志系统
1.引入依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
2.application.yaml配置连接Elasticsearch
spring:
elasticsearch:
rest:
uris: http://192.168.33.10:9200
3.创建实体类
@Data
@Document(indexName = "test_log",shards = 1,replicas = 1)
public class LogPojo {
@Id
private String id;
@Field(name = "port",type = FieldType.Integer)
private Integer port;
@Field(name = "message",type = FieldType.Text)
private String message;
@Field(name = "@version",type = FieldType.Keyword)
private String version;
//默认不能转换时间,必须设置format
@Field(name = "@timestamp",type = FieldType.Date,format = DateFormat.date_time)
private Date timestamp;
@Field(name = "host",type = FieldType.Keyword)
private String host;
private MessagePojo mp;
}
@Data
public class MessagePojo {
@JsonProperty("@timestamp")
private Date timestamp;
@JsonProperty("@version")
private String version;
private String message;
private String logger_name;
private String thread_name;
private String level;
private Long level_value;
}
4.编写 service 层
public interface LogService {
List<LogPojo> selectPage(Integer page,Integer rows);
}
@Service
public class LogServiceImpl implements LogService {
@Autowired
ElasticsearchRestTemplate elasticsearchRestTemplate;
@SneakyThrows
@Override
public List<LogPojo> selectPage(Integer page, Integer rows) {
//小于当前15分钟的时间对象
Calendar calendar = Calendar.getInstance();
calendar.add(Calendar.MINUTE,-15);
//查询最近15分钟内的日志
Query query = new NativeSearchQuery(QueryBuilders.rangeQuery("@timestamp").gte(calendar.getTime()));
query.setPageable(PageRequest.of(page-1,rows));
SearchHits<LogPojo> search = elasticsearchRestTemplate.search(query, LogPojo.class);
List<LogPojo> list = new ArrayList<>();
for(SearchHit<LogPojo> searchHit : search.getSearchHits()){
LogPojo logPojo = searchHit.getContent();
//把String message 转换成 MessagePojo类型的属性。
//使用Jackson
ObjectMapper objectMapper = new ObjectMapper();
MessagePojo messagePojo = objectMapper.readValue(logPojo.getMessage(), MessagePojo.class);
logPojo.setMp(messagePojo);
System.out.println(logPojo.getMp().getMessage());
list.add(logPojo);
}
return list;
}
}
5.编写 controller 层
@RestController
public class LogController {
@Autowired
private LogService logService;
@RequestMapping("/")
public List<LogPojo> show(Integer page, Integer rows) {
return logService.selectPage(page, rows);
}
}
6.测试
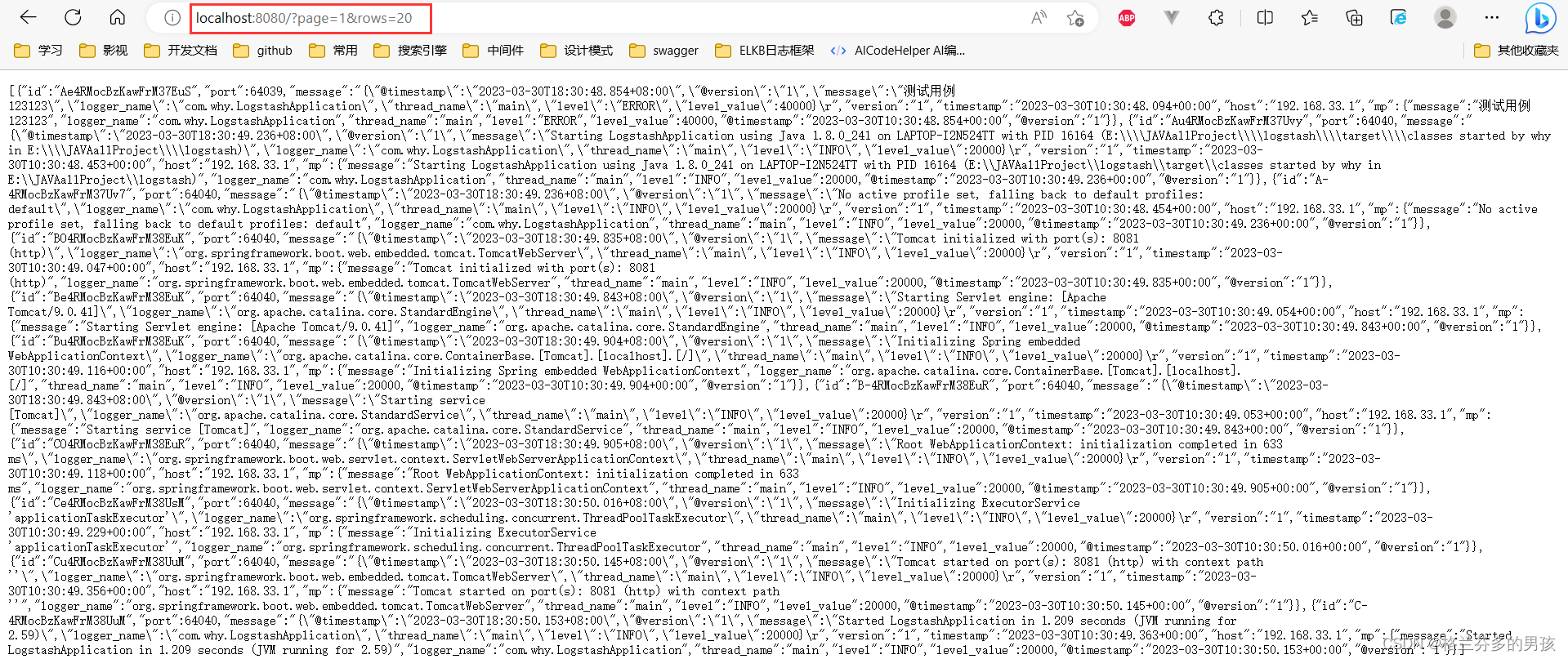
首先利用java项目输出日志到logstash部分写的demo想kibana中写入日志
然后输入网址http://localhost:8080/?page=1&rows=20 得到结果,成功获取java项目的日志















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









