






机器学习实验二--拓展
前言
实验二前半部分连接 传送门
一、根据信息熵处理数据
之前采用暴力划分的方式显然是不合理的,容易受到极端值的影响导致部分区间数据过少或者偏多.
重新观察数据图发现,数据的属性有很强的线性关系,类别的标签分别为1,2,3,0等奖四种,凭借直觉就可以感觉出,应该要把属性分四类,可以很好的有效降低信息熵,

依然使用该函数进行计算数据的熵
#计算给定数据的熵
def calcEnt(data):
num=len(data)#获取数据的行数
labels={}
#遍历数据的所有行
for featVec in data:
#为所有可能分类创建字典
currentLabel=featVec[-1]
if currentLabel not in labels.keys():#如果字典中不存在该键则创建并初始化为0
labels[currentLabel]=0
labels[currentLabel]+=1#统计每个类别
Ent=0.0
for key in labels:
prob=float(labels[key])/num
Ent-=prob*log2(prob)
return Ent
两个函数,作用分别是取data[axis]小于等于value数据集的值,和大于的值,分别返回retDataSet_font,retDataSet_back
#按照给定区间划分数据集
def splitDataSet_bydata_font(dataSet,axis,value):# 待划分的数据集 划分数据集的特征 比较的特征值
retDataSet_font=[]
if isinstance(dataSet,list) ==False:
dataSet=dataSet.tolist()
for featVec in dataSet:#遍历每一行
if featVec[axis] <=value:
reducedFeatVec=featVec[:axis]
reducedFeatVec.extend(featVec[axis:])#放列表中的元素
retDataSet_font.append(reducedFeatVec)#把整个列表放入
return retDataSet_font
#按照给定特征区间划分数据集
def splitDataSet_bydata_back(dataSet,axis,value):# 待划分的数据集 划分数据集的特征 比较的特征值
retDataSet_back=[]
if isinstance(dataSet,list) ==False:
dataSet=dataSet.tolist()
for featVec in dataSet:#遍历每一行
if featVec[axis] >value:
reducedFeatVec=featVec[:axis]
reducedFeatVec.extend(featVec[axis:])#放列表中的元素
retDataSet_back.append(reducedFeatVec)#把整个列表放入
return retDataSet_back
创建树的代码和判断最优值函数都要修改:
def createTree(dataSet,labels):
#类别完全相同则停止划分
classList=[example[-1] for example in dataSet]
if classList.count(classList[0])==len(classList):
print("发生了类别完全相同",classList[0])
return classList[0]
#遍历完所有特征时返回出现次数最多的类别
if len(dataSet[0])==1:
return majorityCnt(classList)
bestFeat,bestData=chooseBestData(dataSet)
bestFeatLabel=labels[bestFeat]
myTree={bestFeatLabel:{}}
#分支的多少和循环次数有关
listJudge=["<="+str(bestData),">="+str(bestData)]
subLabels=labels[:] #复制一份
print(bestFeat,bestData)
newDataSet_font=splitDataSet_bydata_font(dataSet,bestFeat,bestData)
newDataSet_back=splitDataSet_bydata_back(dataSet,bestFeat,bestData)
print(newDataSet_font)
if(newDataSet_font!=[] and bestFeat!=-1):
myTree[bestFeatLabel][listJudge[0]]=createTree(newDataSet_font,subLabels)
if(newDataSet_back!=[] and bestFeat!=-1):
myTree[bestFeatLabel][listJudge[1]]=createTree(newDataSet_back,subLabels)
return myTree
def chooseBestData(dataset):
num=len(dataset[0])-1
baseEnt=calcEnt(dataset)
print("初始信息熵",baseEnt)
bestGain=0.0
bestFeature=-1
bestdata=0
for i in range(num):#0 1 2
#创建唯一的分类标签列表
featlist=[example[i] for example in dataset]#对每行数据取i列放入featlist
for value in featlist:
newEnt=0.0
#计算每种划分方式的信息熵
subDataSet_font=splitDataSet_bydata_font(dataset,i,value)
subDataSet_back=splitDataSet_bydata_back(dataset,i,value)
prob_font=len(subDataSet_font)/float(len(dataset))
prob_back=len(subDataSet_back)/float(len(dataset))
newEnt=prob_font*calcEnt(subDataSet_font)+prob_back*calcEnt(subDataSet_back)
inforGain=baseEnt-newEnt
#计算最好的信息熵
if (inforGain>bestGain):
print("当前信息熵增益为:",inforGain,"i为",i,"data为:",value)
bestGain=inforGain
bestFeature=i
bestdata=value
return bestFeature,bestdata
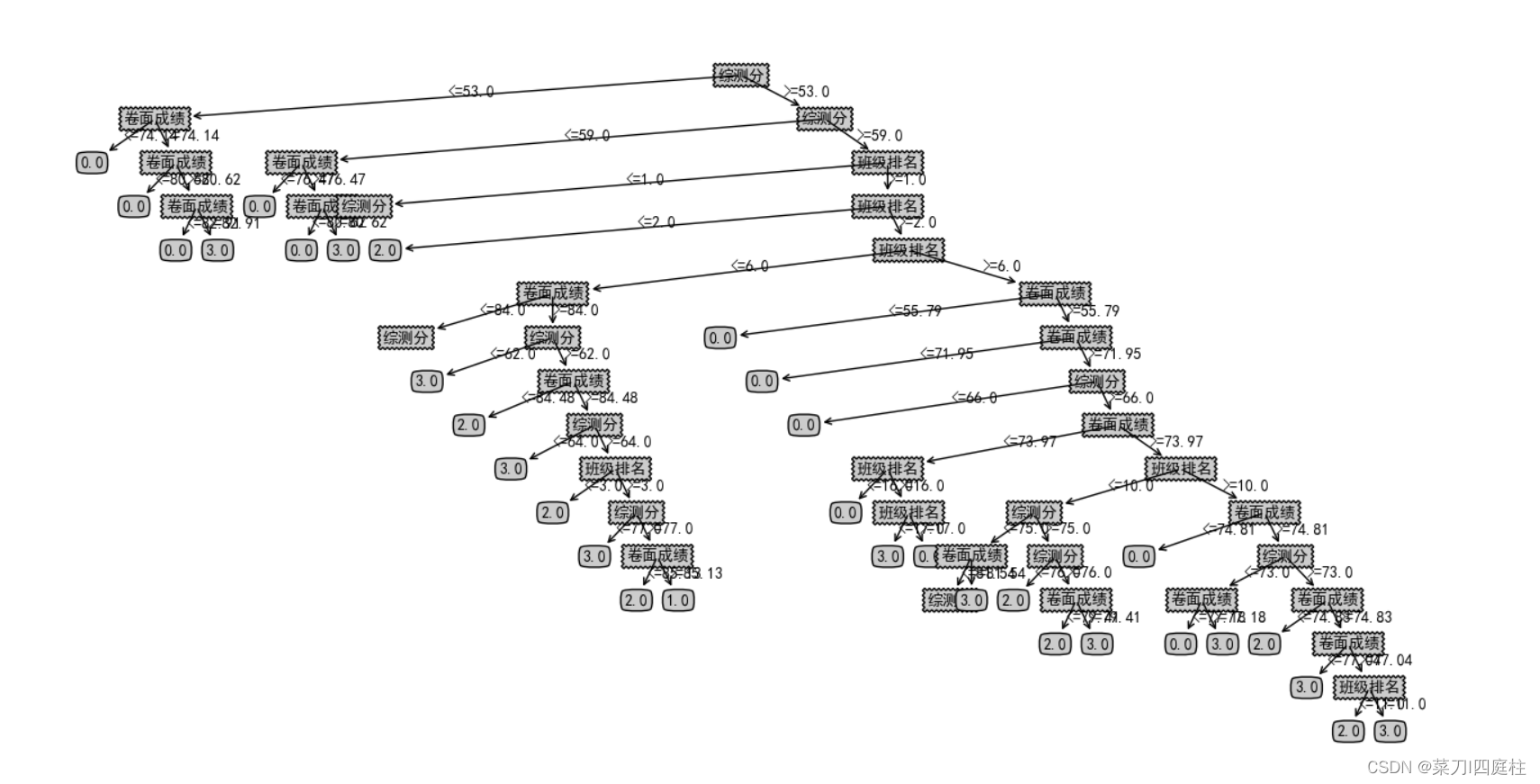
测试代码生成的树,可以看到这是一棵过拟合的树,且深度过深,原因在于停止创建树的条件完全依赖于
1.数据集类别完全相同
2.没有数据了,甚至不产生叶子节点
如何解决?接下来就要进行剪枝了
二、剪枝的学问
预剪枝:自顶至下,从根节点开始,核心思想是在树中结点进行扩展之前,先计算当前的划分是否能带来模型泛化能力的提升,如果可以则会展开,否则不展开。
预剪枝的方法:
1.限定决策树的深度
2.设定一个阈值(当信息增益熵达到设定阈值时才继续生成树)
3.设置某个指标,比较节点划分前后的泛化能力
后剪枝:是在已经生成的决策树上进行剪枝,自下至上,从叶子节点开始,如果某个节点剪枝后泛化能力更高,则进行剪枝,否则不剪枝。
1.预剪枝
1.1限定决策树的深度:
将createTree()新增一个传入的参数 depth,每次递归子树时将其减1
#数据集 标签 限定树的深度
def createTree(dataSet,labels,depth):
classList=[example[-1] for example in dataSet]
#达到指定深度停止划分
if depth==0:
return majorityCnt(classList)
#类别完全相同则停止划分
if classList.count(classList[0])==len(classList):
return classList[0]
#遍历完所有特征时返回出现次数最多的类别
if len(dataSet[0])==1:
return majorityCnt(classList)
bestFeat,bestData=chooseBestData(dataSet)
bestFeatLabel=labels[bestFeat]
myTree={bestFeatLabel:{}}
#分支的多少和循环次数有关
listJudge=["<="+str(bestData),">"+str(bestData)]
subLabels=labels[:] #复制一份
print(bestFeat,bestData)
newDataSet_font=splitDataSet_bydata_font(dataSet,bestFeat,bestData)
newDataSet_back=splitDataSet_bydata_back(dataSet,bestFeat,bestData)
print(newDataSet_font)
if(newDataSet_font!=[] and bestFeat!=-1):
newDepth=depth-1
myTree[bestFeatLabel][listJudge[0]]=createTree(newDataSet_font,subLabels,newDepth)
if(newDataSet_back!=[] and bestFeat!=-1):
newDepth=depth-1
myTree[bestFeatLabel][listJudge[1]]=createTree(newDataSet_back,subLabels,newDepth)
return myTree
if __name__=='__main__':
labels=['卷面成绩','班级排名','综测分']
mydata=createData('./ch1/grade.txt')
mytree=createTree(mydata,labels,5)
print(mytree)
createPlot(mytree)
以下为初始化设置树的深度为5的树,已经比较好的结果,但是还是存在问题:
问题:没有类别为1的奖学金类
出现的原因:达到树的最大深度,进行多数票决时,该类别数据量依然少于其他类别
解决办法:适当增加初始树的深度

增加树的深度到6,可以看到类别1出现了

1.2 设定阈值
这里设置阈值为0.7,及信息增益要大于0.7,否则不生成子树
if __name__=='__main__':
labels=['卷面成绩','班级排名','综测分']
mydata=createData('./ch1/grade.txt')
threshold=0.7
mytree=createTree(mydata,labels,6)
print(mytree)
createPlot(mytree)
修改的部分:
1.chooseBestData()函数增加一个返回值

2.createTree增加修改如下代码

依然存在的问题:
1.阈值是超参数,需要手动设置
2.没有班级排名?有循环判断过,看来真的无关紧要。。

1.3 设置某个指标,比较节点划分前后的泛化能力
测试集上的误差率:测试集中错误分类的实例占比:
误差率越高,代表泛化能力越弱,误差率越低,代表泛化能力越强
通过比较误前后差率来决定要不要剪枝
预剪枝使得很多分支没有展开,这不仅降低了过拟合的风险,还显著减少了决策树的训练时间开销和测试时间。但是,有些分支虽当前不能提升泛化性。甚至可能导致泛化性暂时降低,但在其基础上进行后续划分却有可能导致显著提高,因此预剪枝的这种贪心本质,给决策树带来了欠拟合的风险。
1.4 对决策树进行预测
设置一个测试集:

def getPredict(myTree,mylist):
firstStr=list(myTree.keys())[0]
num1=mylist[labels_dic[firstStr]]
secondDict=myTree[firstStr]
num2=getStringNum(list(secondDict.keys())[0])
k=-1
for key in secondDict.keys():
k=(k+1)%2
if type(secondDict[key]).__name__=='dict':#float类型
if(num1<=num2):
return getPredict(secondDict[list(secondDict.keys())[0]],mylist)
elif(num1>num2):
return getPredict(secondDict[list(secondDict.keys())[1]],mylist)
break
else:
if(num1<=num2 and k==0):#小于满足打印出来
return secondDict[key]
elif(num1>num2 and k==1):#大于满足打印出来
return secondDict[key]
else:
continue
def getStringNum(test):
if test[0]=='<':
return float(test[2:])
else:
return float(test[1:])
测试对奖学金的预测:
testdata=createData('./ch1/test.txt')
for mylist in testdata:
predict=getPredict(mytree,mylist)
print("预测的奖学金等级为",predict,"正确标签为:",mylist[-1])

总结
1.出现的问题及解决的办法
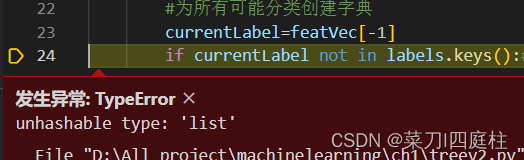
1.1 unhashable type:‘list’
原因:传入的列表为空
解决办法:在递归传入列表时判断列表是否为空
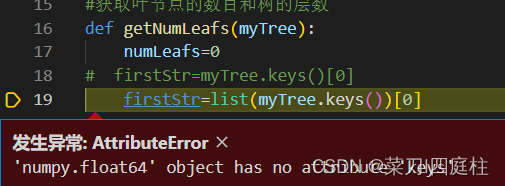
1.2 ‘numpy.float64’ object has no attribute ‘keys’
原因:之前设置的阈值太高,第一个节点都生成不了
解决办法:调高阈值
2.实验总结
1.设置决策树的深度能够有效达到预剪枝的效果
2.设置阈值的方法中,由于阈值的认为设置,可能导致节点无法生成,在不同数据集上表示可能不相同
3.由于我所有数据都为连续型数据,且和时间有关(两个学期的),不同时间的相似相邻数据可能会使准确率降低
参考文献
http://t.csdn.cn/RBWuB















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









