







MySQL中的分组函数(多行函数):
sum()求和
avg()求平均值
这两个只适用于数值型的变量(括号里面放的东西要具有实际的数值意义)
参考举例代码如下:
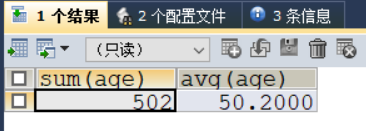
SELECT SUM(age),AVG(age) # avg(name)就是没有意义的
FROM t_emp;
以上代码编译结果如下:
----------------------------------------(分割线)---------------------------------------
max()求最大值
min()求最小值
这两个只适用于数值型、字符串型、日期型的变量
参考举例代码如下:
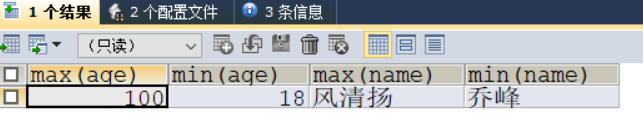
SELECT MAX(age),MIN(age),MAX(NAME),MIN(NAME)
FROM t_emp;
备注:这里的MAX(NAME),MIN(NAME)是按照name在表中的排列顺序的前后来返回的。
以上代码编译结果如下:
----------------------------------------(分割线)---------------------------------------
count()求个数
返回所选字段在表格里的总个数(只能计算非空数值的个数,字段里的null对象会被忽略)
参考举例代码如下:
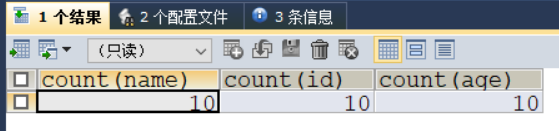
SELECT COUNT(NAME),COUNT(id),COUNT(age)
FROM t_emp;
以上代码编译结果如下:
备注:
(1).实际计算中,我们可以认为 avg = sum/count 说明在计算平均值和求总和的时候,也会忽略null对象。
如果计算时需要把空对象也计算在内的话,可以采用COUNT(IFNULL()),举例如下:
如果需要计算公司的平均奖金率,可以使用以下公式:
SELECT SUM(commission_pct)/COUNT(IFNULL(commission_pct,0))
FROM DUAL;
(2).在使用COUNT()的时候,有时候需要进行全局统计,这个时候就需要避免null对象被忽略的情况,可以采用COUNT(*)
参考代码如下:
SELECT COUNT(employee_id),COUNT(*),COUNT(1),COUNT(2)
FROM emlpoyees;
备注:这里COUNT(*),COUNT(1),COUNT(2)都是等效的,我们一般用COUNT(*)
----------------------------------------(分割线)---------------------------------------
group by...通过…进行分组
注意:查询的字段包含组函数和非组涵数,非组函数的字段(分组的依据)一定要声明在group by中,即指明要按照这些非组函数的字段声明
反之,声明在group by中的非组函数(分组的依据),不一定要声明在select中。
举例:
计算各个部门的最高工资
参考代码如下:
SELECT MAX(salary)
FROM employees
GROUP BY department_id;
(++++++++++++++++++++++分割线++++++++++++++++++++)
计算各个工种的最高工资
参考代码如下:
SELECT MAX(salary)
FROM employees
GROUP BY job_id;
(++++++++++++++++++++++分割线++++++++++++++++++++)
查询不同部门、不同工种的员工的平均工资和最高工资
参考代码如下:
SELECT employee_id,job_id,MAX(salary),AVG(salary)
FROM employees
GROUP BY department_id,job_id;
或者
SELECT job_id,employee_id,MAX(salary),AVG(salary)
FROM employees
GROUP BY job_id,department_id;
(++++++++++++++++++++++分割线++++++++++++++++++++)
关于前面提到的,非组函数的字段(分组的依据)一定要声明在group by中,即指明要按照这些非组函数的字段声明反之,声明在group by 中的非组函数(分组的依据),不一定要声明在select中。我们可靠以下的示范:
错误示范:
SELECT job_id,employee_id,MAX(salary),AVG(salary)
FROM employees
GROUP BY job_id;
正确示范:
SELECT MAX(salary),AVG(salary)
FROM employees
GROUP BY job_id,department_id;
----------------------------------------(分割线)---------------------------------------
having和where功能很相似,只不过比where的使用条件更宽泛,
包含分组函数的过程条件必须声明在having中,而不包含分组函数的过滤条件建议声明在where中(因为where的执行效率更高)
注意:如果在过滤条件中出现了分组函数,则需要使用having替换where
举例:
实现查询,部门最高工资比10000高的部门
SELECT department_id,MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary) > 10000;
注意:要将having声明在group by 后面
以下是错误示范:
SELECT department_id,MAX(salary)
FROM employees
HAVING MAX(salary) > 10000 #having声明在group by 后面
GROUP BY department_id;
SELECT department_id,MAX(salary)
FROM employees
WHERE MAX(salary) > 10000 # where不能用来过滤具有分组函数的条件
GROUP BY department_id;
(++++++++++++++++++++++分割线++++++++++++++++++++)
举例:
查询10,20,30三个部门中,最高工资比10000高的部门
推荐的写法:
SELECT departemt_id,MAX(salary)
FROM emlpoyees
WHERE department_id IN(10,20,30)
GROUP BY department_id
HAVING MAX(salary) > 10000;
不太推荐的写法(也可以运行)(但是效率较低,反应慢一些)
SELECT departemt_id,MAX(salary)
FROM emlpoyees
GROUP BY department_id
HAVING MAX(salary) > 10000
AND department_id IN(10,20,30);














 9852
9852











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









