







第1章 Python概述
(1)下面不属于Python特性的是( ) B
A. 解释型 B. 静态 C. 动态 D. 面向对象
(2)下列关于注释的说法正确的是( ) A
A. 单行注释只能使用#号创建
B. 多行注释只能使用#号创建
C. 使用引号创建注释时,须保证前后引号数目相同,类型不必一致
D. 注释的主要目的在于使代码美观
(3)下列关于运算符的说法正确的是( ) D
A. 算术运算符包括加、减、乘、除4种
B. 运算符“=”和运算符“==”是等效的
C. 逻辑表达式x or y,若x为False,则返回x
D. 指数运算符的优先级最高
(4)下列关于if语句的说法正确的是( ) C
A. 一个完整的if语句必须包含if、elif和else,否则无法执行
B. 在if语句的单行形式中,必须将布尔表达式放在最前端
C. 理论上,elif可以实现无限个条件分支
D. if语句的嵌套次数可以尽可能多,并无不良影响
(5)下列关于循环语句的说法正确的是( ) D
A. for语句是一种当型循环
B. while 语句是一种直到型循环
C. 使用while 语句创建了无限循环时,一定是因为顶端布尔表达式只包含常数
D. for语句和while语句都支持嵌套,并且可以相互嵌套
6)下列关于循环控制语句的说法正确的是( ) D
A. break 语句的作用是终止整个程序
B. continue 语句的作用是终止整层循环
C. pass 语句的作用是终止一层循环中的某一次循环
D. break和continue 语句采用不同方式终止循环,pass 语句仅仅是一个占位符
(7)下列关于def语句与lambda语句的说法错误的是( ) D
A. def语句允许传入多个参数、输出多个返回值
B. 无返回值的def语句也可能输出信息
C. lambda 语句只能是单行的形式
D. lambda 语句不支持嵌人结构体
(8)下列关于数据和数据分析的说法正确的是( )B
A. 数据就是数据库中的表格
B. 文字、声音、图像这些都是数据
C. 数据分析不可能预测未来几天的天气变化
D. 数据分析的数据只能是结构化的
(9)下列关于数据分析流程的说法错误的是( )C
A. 需求分析是数据分析最重要的一部分
B. 数据预处理是能够建模的前提
C. 分析与建模时只能够使用数值型数据
D. 模型评价能够评价模型的优劣
(10)下列关于分析与建模流程的说法错误的是( )D
A. 传统的统计对比分析不属于分析与建模流程
B. 分析与建模的模型选择要根据需求确定
C. 分析与建模时可以选择多个模型,同时分析
D. 分析与建模工作是数据分析的核心
(11)下列关于模型评价与优化的说法正确的是( )B
A. 模型构建完成就可以使用
B. 模型评价的目的是为了确认模型的有效性
C. 模型评价结果良好,模型一定可用,不需要重构
D. 所有的模型评价方法相同
(12)下列不属于数据分析应用场景的是( )D
A. 产品销量分析 B. 码头货物吞吐量预测
C. 计算机硬盘使用寿命预测 D. 某人一生的命运预测
(13)下列不属于Python 优势的是( )C
A. 语法简洁,程序开发速度快
B. 拥有大量的第三方库,能够调用C、C++、Java语言
C. 程序的运行速度在所有计算机语言中最快
D. 开源免费
(14)下列关于数据和数据分析的说法正确的是( )B
A. 数据就是数据库中的表格
B. 文字、声音和图像都是数据
C. 数据分析只能是对过去发生事情的描述和分析
D. 数据分析的数据只能是结构化的
(15)下列分析方法属于狭义数据分析的是( )C
A. 智能推荐 B. 关联规则 C. 交叉分析 D. 文本分类
(16)下列关于数据分析流程的说法错误的是( )D
A. 需分析是数据分析最重要的一部分
B. 数据预处理是能够建模的前提
C. 模型评估能评价模型的优劣
D. 声音和图像无法用数据分析
(17)下列关于数据分析工具的说法正确的是( )D
A. MATLAB是最适合开发网络应用的语言
B. R语言主要应用于工程计算、控制设计
C. MATLAB拥有大量的第三方库,而且开源
D. Python拥有大量的第三方库,能调用C、Java等其他程序语言
(18)Python不支持的数据类型有( )A
A. char B. int C. float D. list
(19)以下( )是不合法的表达式。B
A. x in range(6) B. 3=a C. e>5 and 4==f D. (x-6)>5
(20)若k为整数,下列while循环执行的次数为( 10 )
K=1000
while k>1:
print(k)
k=int(k/2)
(21)下列代码,(D )会输出1、2、3三个数字。
A. for i in range(3):
print(i)
B. alist=[1,2,3]
for i in alist: i从0开始的
print(i+1)
C. i=1
while i<3:
print(i)
i+=1
D. for i in range(3):
print(i+1)
(22)以下叙述正确的是( B )
A. continue 语句的作用是结束整个循环的执行
B. 只能在循环体内使用break语句
C. 在循环体内使用 break 语句和 continue 语句作用相同
D. 从多层循环嵌套中退出时,只能使用goto语句
第二章 Numpy的数值计算
(1)【多选】NumPy提供的两种基本对象是(B,C )
A. array B. ndarray C. ufunc D. matrix
(2)不列不属于ndarray的属性的是( D )
A. ndim B. shape C. size D. add
(3)创建一个3x3的ndarray,下列代码错误的是(C )
A. np.arange(0,9).reshape(3,3)
B. np.eye(3)
C. np.random.random([3,3,3])
D. np.mat("1 23;456;789")
(4)以下函数中不具备排序功能的是( D )
A. sort B. argsort C. lexsort D. extract
(5)以下最能体现ufunc特点的是( C )
A. 其又称通用函数(Universal Functions)
B. 对ndarray中的每一个元素进行逐一操作
C. 对整个ndarray 进行操作
D. ndarray中的元素是相同类型的
(6)下列属于NumPy提供的基本对象的是(A )
A. ndarray B. list C. matrix D. tuple
(7)下列不能创建数组的函数是( D )
A. linspace B. zeros C. ones D. twos
(8)改变数组的操作是( A )
A. 切片 B. 索引 C. 转置 D. 堆叠
(9)不列不属于数组的常用统计函数的是( A )
A. split(分割字符串) B. sum C. mean D. std
第三章 Matplotlib绘图
(1)下列函数不是控制坐标轴属性的是( D )
A. xlabel B. xlim C. xticks D. xkcd
(2)下列描述有误的是( B )
A. 基本流程:创建画布,绘制图形,保存展示图形
B. 必须先保存图形才能展示图形
C. 添加图例必须在绘制图形之后
D. 创建子图时,默认会根据画布的大小平均分配
(3)在不使用辅助库的情况下,Matplotlib不能绘制的图形是( C )
A. 箱线图 B. 折线图 C. 3D图 D. 条形图
(4)按以下步骤绘图,会出现错误的是( A )
A. 创建画布→添加图例→绘制图形→展示图形
B. 创建画布→绘制图形→展示图形→保存图形
C. 创建画布→修改图形元素→绘制图形→展示图形
D. 绘制图形→添加图例→保存图形→展示图形
(5)下列不属于rc参数的是(C )
A. axes.titlesize B. axes.linewidth C. boxplot D. axes.facecolor
(6)以下关于绘图标准流程说法错误的是(B )
A. 绘制最简单的图形可以不用创建画布
B. 添加图例可以在绘制图形之前
C. 添加x轴、y轴的标签可以在绘制图形之前
D. 修改x轴标签、y轴标签和绘制图形没有先后
(7)下列参数中调整后显示中文的是( C )
A. lines.linestyle B. lines.linewidth
C. font.sans-serif D. axes.unicode_minus
(8)下列代码中绘制散点图的是( A )
A. plt.scatter(x,y) B. plt.plot(x,y)
C. plt.legend(‘upper left’) D. plt.xlabel(’散点图’)
(9)下列字符串表示 plot 线条颜色、点的形状和类型为红色五角星点短虚线的是( D )
A. ‘bs-’ B. ‘go-.’ C.’ r+-.‘ D. ‘r*:’
(10)下列说法正确的是( C )
A. 散点图不能在子图中绘制
B. 散点图的x轴刻度必须为数值
C. 折线图可以用作查看特征间的趋势关系
D. 箱线图可以用来查看特征间的相关关系
(11)下列关于绘图标准流程说法错误的是( B )
A. 绘制最简单的图形可以不用创建画布
B. 添加图例可以在绘制图形之前
C. 添加x轴、y轴的标签可以在绘制图形之前
D. 修改x轴、y轴标签和绘制图形没有先后
(12)下列代码中绘制散点图的是( B )
A. plt.plot(x,y) B. plt.scatter(x,y)
C. plt. legend(‘bottom’) D. plt.label(’散点图’)
(13)下列代码中给图表添加标签的是( D )
A. plt. plot(x,y) B. plt.xlabel(‘text’)
C. plt.ylabel(‘text’) D. plt.text(x,y,’text’)
(14)绘制水平条形图的函数是( C)
A. plot() B. pie() C. barh() D. bar()
第四章 pandas数据处理
(1) pandas的常用类不包括( C )
A. Series B. DataFrame C. Panel D. Index
(2)Series能够接收的数据类型不包括( C )
A. dict B. list C. array D. set
(3)关于Series索引方式错误的是( D )
A. s[0:2] B. s[2] C. s[s>2] D. s[s=2]
(4)删除 DataFrame数据的方法不包括( D )
A. drop B. pop C. del D. remove
(5)关于iloc的说法不正确的是( D )
A. 既可以行索引,又可以列索引
B. 不能使用标签索引
C. 当传入的行索引位置或列索引位置为区间时,其为前闭后开区间
D. 可以接收Series
(6)merge函数用于主键合并,下列说法错误的是( D )
A. on参数用于指定主键
B. sort参数为True时将对合并的数据进行排序
C. suftixes 参数用于对重叠列加尾缀
D. join 参数表示表连接的方式
(7)关于pandas库的文本操作,下列说法错误的是( B )
A. replace方法用于替换字符串
B. slice方法不是通过截取字符实现文本索操作的
C. upper方法可将Series 各元素转换为大写
D. 存在一些特殊的方法是Python原生 str类型所没有的
(8)关于时间相关类,下列说法错误的是( D )
A. Timestamp是存放某个时间点的类
B. Period是存放某个时间段的类
C. Timestamp数据可以使用标准的时间str转换得来
D. 两个数值上相同的Period和Timestamp所代表的意义相同
(9)下列关于pandas数据读/写说法错误的是( A )
A. read_csv能偶够读取所有文本文档的数据
B. read_sql能够读取数据库的数据
C. to_csv 函数能够将结构化数据写入.csv文件
D. to_excel函数能够将结构化数据写入 Excel 文件
(10)下列loc、iloc、ix属性的用法正确的是( D )
A. df.loc[‘列名’, ’索引名’]; df.iloc[‘索引位置’, ’列位置’]; df.ix[‘索引位置’, ’列名’]
B. df.loc[’索引名’, ‘列名’]; df.iloc[‘索引位置’, ‘列名’]; df.ix[‘索引位置’, ’列名’]
C. df.loc[’索引名’, ‘列名’]; df.iloc[‘索引位置’, ‘列名’]; df.ix[‘索引名’, ’列位置’]
D. df.loc[’索引名’, ‘列名’]; df.iloc[‘索引位置’, ’列位置’]; df.ix[‘索引位置’, ’列位置’]
(11)下列关于groupby方法说法正确的是( C )
A. groupby能够实现分组聚合
B. groupby方法的结果能够直接查看
C. groupby是pandas提供的一个用来分组的方法
D. groupby方法是pandas提供的一个用来聚合的方法
(12)下列关于apply方法说法正确的是( D )
A. apply方法是对DataFrame每一个元素应用某个函数的
B. apply方法能够实现所有 aggregate方法的功能
C. apply方法和map方法都能够进行聚合操作
D. apply方法只能够对行列进行操作
(13)下列关于分组聚合的说法错误的是( C )
A. pandas提供的分组和聚合函数分别只有一个
B. pandas分组聚合能够实现组内标准化
C. pandas 聚合时能够使用agg、apply、transform方法
D. pandas分组函数只有一个 groupby
(14)使用pivot_table函数制作透视表用下列( A )参数设置行分组键。
A. index B. raw C. values D. data
(15)使用其本身可以达到数据透视功能的函数是( D )
A. groupby B. transform C. crosstab D. pivot_table
(16)以下关于缺失值检测的说法中正确的是( B )
A. null和notnull可以对缺失值进行处理
B. dropna()方法既可以删除观测记录,也可以删除特征
C. fillna()方法中用来替换缺失值的值只能是数据框
D. pandas 库中的 interpolate 模块包含了多种插值方法
(17)以下关于drop_duplicates()函数的说法中错误的是( B )
A. 仅对DataFrame和Series类型的数据有效
B. 仅支持单一特征的数据去重
C. 数据重复时默认保留第一个数据
D. 该函数不会改变原始数据排列
(18)数据质量包含的要素有( D )
A. 准确性、完整性 B. 一致性、可解释性
C. 时效性、可信性 D. 以上所有要素
(19)以下关于数据分析预处理的过程描述正确的是( C )
A. 数据清洗包含了数据标准化、数据合并和缺失值处理
B. 数据合并按照合并轴方向主要分为左连接、右连接、内连接和外连接
C. 数据分析的预处理过程主要包括数据清洗、数据合并、数据标准化和数据转换,它们之间存在交叉,没有严格的先后关系
D. 数据标准化的主要对象是类别型的特征
(20)有一份数据,需要查看数据的类型,并将部分数据做强制类型转换,以及对数值数据做基本的描述性分析。下列的步骤和方法正确的是( A )
A. dtypes查看类型,astype转换类别,describe描述性统计
B. astype查看类型,dtypes转换类别,describe 描述性统计
C. describe查看类型,astype转换类别,dtypes描述性统计
D. dtypes 查看类型,describe转换类别,astype 描述性统计
(21)下列关于concat函数、append方法、merge函数和join方法的说法正确的是( D )
A. concat是最常用的主键合并的函数,能够实现内连接和外连接
B. append方法只能用来做纵向堆叠,适用于所有纵向堆叠情况
C. merge是最常用的主键合并的函数,但不能够实现左连接和右连接
D. join是常用的主键合并方法之一,但不能够实现左连接和右连接
(22)下列与标准化方法有关的说法中错误的是( A )
A. 离差标准化简单易懂,对最大值和最小值敏感度不高
B. 标准差标准化是最常用的标准化方法,又名零一均值标准化、
C. 小数定标标准化实质上就是将数据按照一定的比例缩小
D. 多个特征的数据的K-Means聚类不需要对数据进行标准化
(23)关于标准差标准化,下列说法中错误的是( B )
A. 经过该方法处理后的数据均值为0,标准差为1
B. 可能会改变数据的分布情况
C. Python中可自定义该方法实现函数:
def StandardScaler(data):
data=(data-data.mean())/data.std()
return data
D. 计算公式为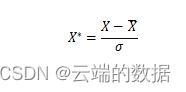
(24)以下关于pandas数据预处理说法正确的是( D )
A. pandas 没有做哑变量的函数
B. 在不导人其他库的情况下,仅仅使用pandas就可实现聚类分析离散化
C. pandas可以实现所有的数据预处理操作
D. cut函数默认情况下做的是等宽法离散化
(25)关于数据库数据的读写,下列说法正确的有( B )
A. read_sql_table 可以使用SQL语句读写数据库数据
B. pandas 除了read_sql之外,没有其他数据库读写函数
C. 使用read_sql函数读取数据库数据时不需要使用数据库连接
D. read_sql既可以使用SQL语句读取数据库数据,又可以直接读取数据库表
(26)【多选】关于pandas数据读写,下列说法正确的有( A,B,c,D )
A. read_excel能够读取扩展名为.xls的文件
B. read_sql能够读取数据库的数据
C. to_csv方法能够将 DataFrame写出到csv中
D. to_sql方法能够将 DataFame写出到数据库中
(27)【多选】对数值型数据应用describe方法返回的特征不包括( A,B )
A. 中位数 B. 标准差 C. 数目 D. 方差
(28)关于agg方法,下列说法错误的是( )
A. 返回标量值和数组
B. 可接收NumPy函数
C. 可对分组的不同列指定作用的函数
D. 可同时接收多个函数
(29)【多选】关于groupby方法,下列说法正确的是( B,C )
A. groupby 能够实现分组聚合
B. groupby方法返回的结果能够直接查看
C. groupby是pandas提供的一个用来分组的方法
D. groupby方法是pandas提供的一个用来聚合的方法
(30)使用pivot_table函数制作透视表时,要用下列( D )参数设置行分组键。A. data B. values C. columns D. index
(31)【多选】关于缺失值,下列说法中正确的是( CD )
A. isnull方法可用于计算缺失值数量
B. dropna方法既可以删除观测记录,又可以删除特征
C. fillna方法可用于替换缺失值
D. pandas库中的 interpolate 模块包含了多种插值方法
(32)关于 drop_duplicates函数,下列说法中错误的是( B )
A. 对DataFrame的数据有效
B. 仅支持单一特征的数据去重
C. 数据有重复时默认保留第一个数据
D. 该函数不会改变原始数据排列
第五章 网络爬虫基础
(1)下列不属于网页组织形式的是( B )
A. HTML B. XML C. CSS D. ASP
(2)下列不属于HTML元素的是( C )
A. body B. div C. amp D. span
(3)下列关于HTML的说法错误的是( C )
A. HTML可以接受空元素 B. HTML不能没有结束标签
C. HTML可以没有结束标签 D. HTML对标签大小写不敏感
(4)下列关于XML的说法错误的是( D )
A. XML文档必须有根元素 B. XML不能没有结束标签
C. XML属性值需添加引号 D. XML对标签大小写不敏感
(5)下列不属于HTTP工作过程的是( D )
A. 建立连接 B. 浏览器请求 C. 服务器应答 D. 浏览器关闭















 2232
2232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









