







文章目录
anaconda安装
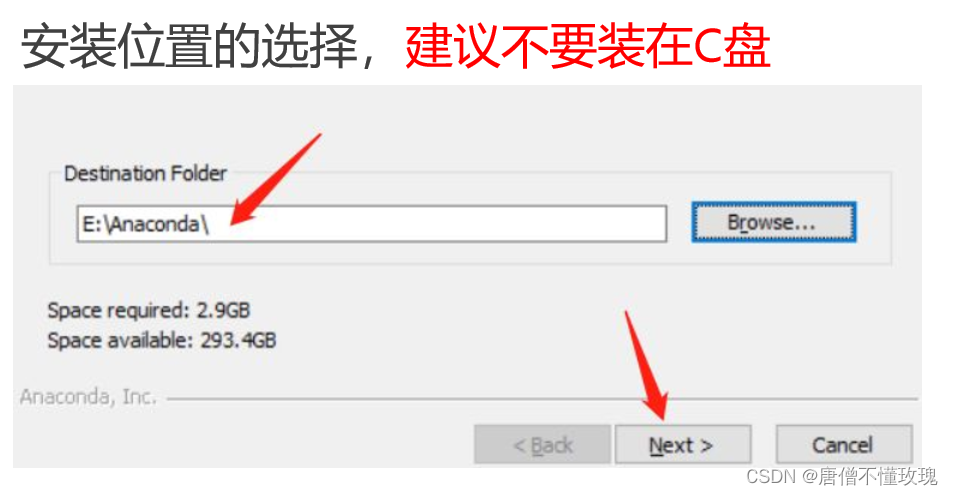
下载anaconda之前需要把python卸载
可以找到
卸载和安装的步骤一样,双击
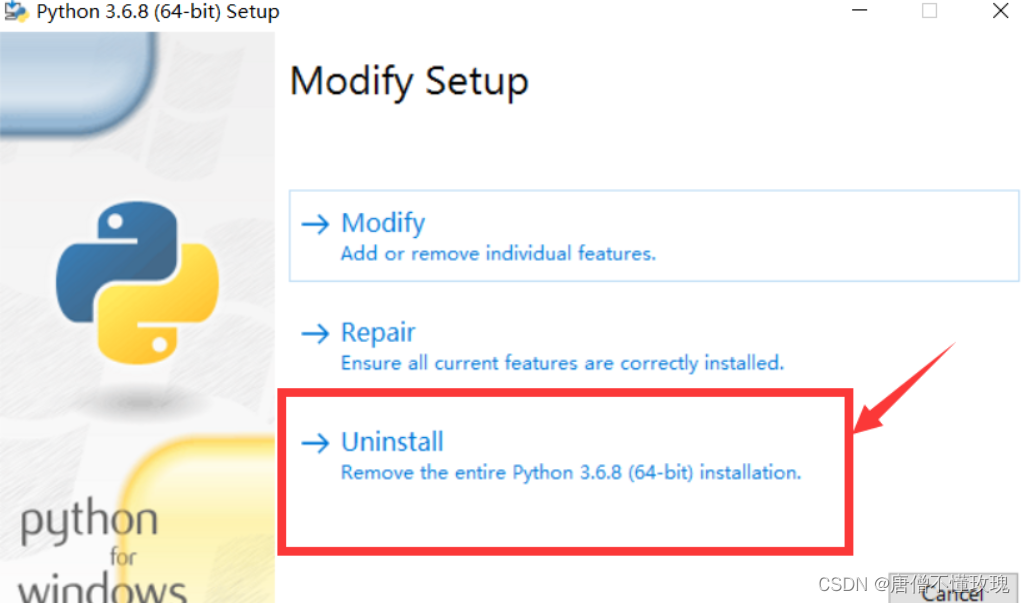
如果你找不到,可以去官网下载安装的python对应的版本,
如果不知道安装的python版本是什么可以在,win+r输入cmd回车,执行
python --version
然后去官网下载相应的包,进行卸载
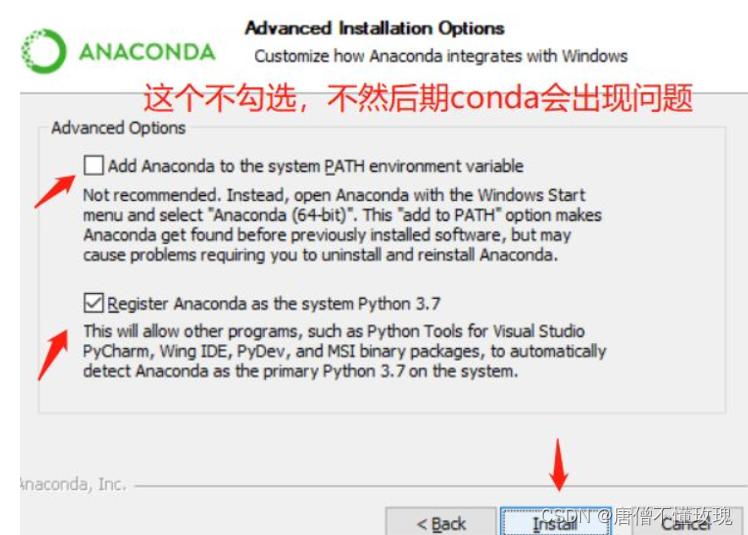
不要打勾
安装完成后,最重要一步,环境变量设置
此电脑——属性——高级系统设置——环境变量——path——编辑——新建
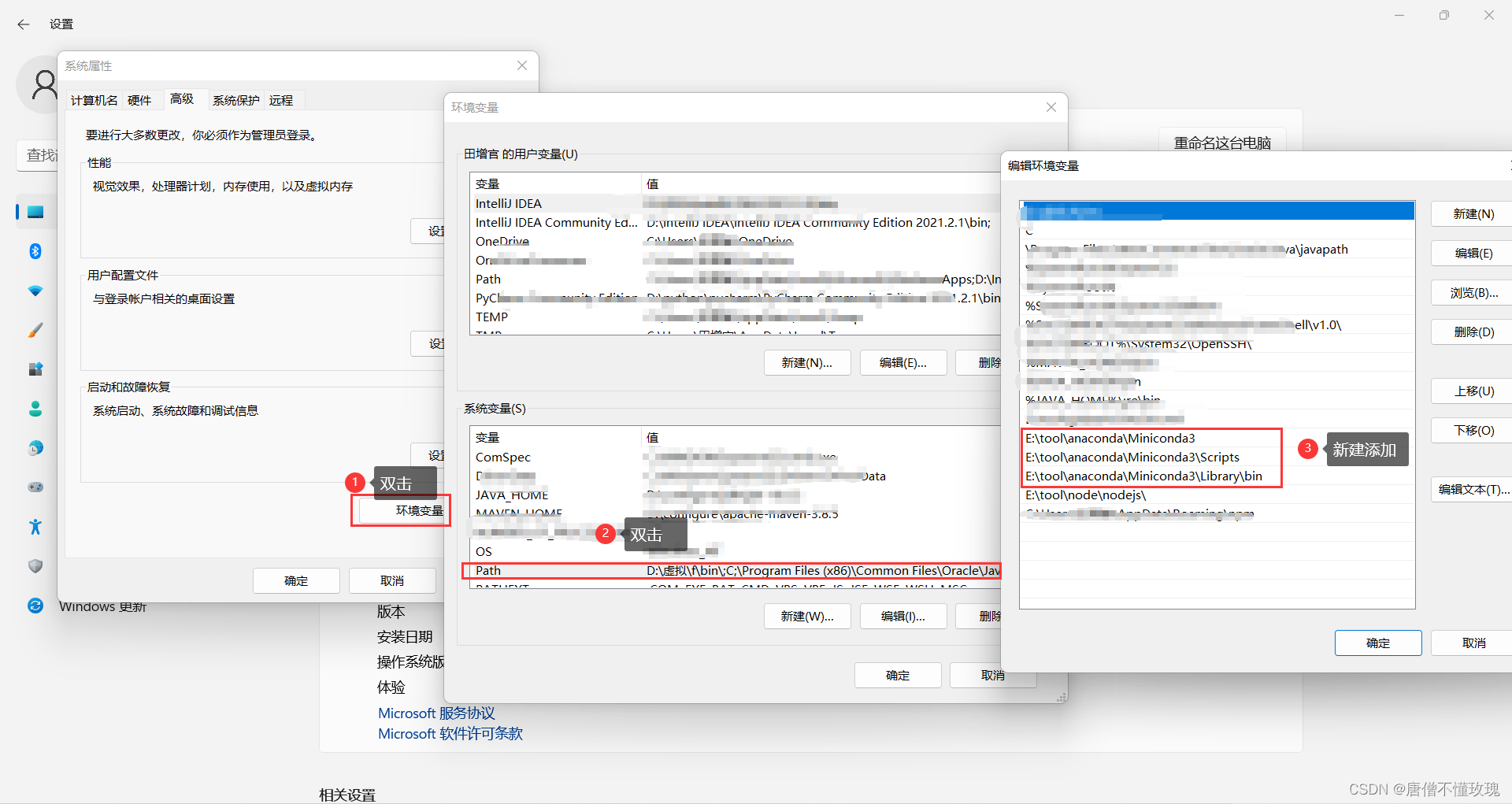
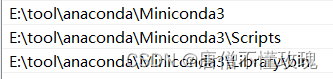
绿色为自己的目录,不要照抄
E:\tool\anaconda\Miniconda3(Python需要)
E:\tool\anaconda\Miniconda3\Scripts(conda自带脚本)
E:\tool\anaconda\Miniconda3\Library\bin(jupyter notebook动态库)
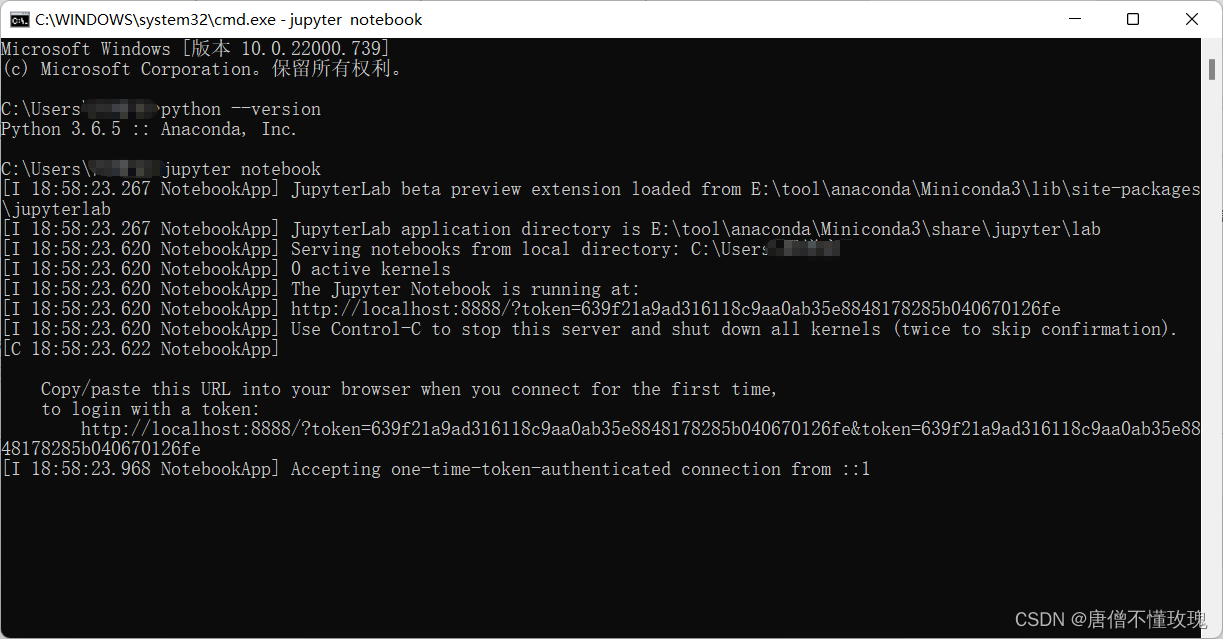
执行两个命令
python --version
jupyter notebook
numpy基础
导入bao
import numpy as np
两个一维数组相加
原生python实现代码
def python_sum(n):
'''
原生python实现2个数组的加法
'''
# 使用列表生成式创建1到N的平方
a = [i**2 for i in range(n)]
# 使用列表生成式创建1到N的立方
b = [i**3 for i in range(n)]
# 新创建新列表
ab_sum = []
# 循环a的索引
for i in range(n):
# 将a中的对应元素与b中对应的元素相加
ab_sum.append(a[i]+b[i])
return ab_sum
#################################
# 调用实现函数
python_sum(10)
################################
[0, 2, 12, 36, 80, 150, 252, 392, 576, 810]
numpy 实现代码
def numpy_sum(n):
'''
numpy实现2个数组的加法
'''
a = np.arange(n) ** 2
b = np.arange(n) ** 3
print(a)
print(b)
return a + b
##############################
# 调用numpy实现函数
numpy_sum(10)
#############################
[ 0 1 4 9 16 25 36 49 64 81]
[ 0 1 8 27 64 125 216 343 512 729]
array([ 0, 2, 12, 36, 80, 150, 252, 392, 576, 810], dtype=int32)
创建ndarray对象
通过 NumPy 的内置函数 array() 可以创建 ndarray 对象,其语法格式如下:
numpy.array(object, dtype = None, copy = True, order = None,subok=False,ndmin = 0)
参数说明
| 序号 | 参数 | 描述说明 |
|---|---|---|
| 1 | object | 表示一个数组序列。 |
| 2 | dtype | 可选参数,通过它可以更改数组的数据类型。 |
| 3 | copy | 可选参数,表示数组能否被复制,默认是 True。 |
| 4 | ndmin | 用于指定数组的维度。 |
| 5 | subok | 可选参数,类型为bool值,默认False。为True,使用object的内部数据类型;False:使用object数组的数据类型。 |
array()函数,括号内可以是列表、元祖、数组、迭代对象,生成器等
np.array([1,2,3,4,5])
#输出: array([1, 2, 3, 4, 5])
# 迭代对象
np.array(range(10))
# 生成器
np.array([i**2 for i in range(10)])
# 列表中元素类型不相同
np.array([1,1.5,3,4.5,'5'])
#输出: array(['1', '1.5', '3', '4.5', '5'], dtype='<U32')
#浮点型
ar2 = np.array([1,2,3.14,4,5])
输出: array([1. , 2. , 3.14, 4. , 5. ])
ndmin 用于指定数组的维度
a = np.array([1,2,3])
print(a)
a = np.array([1,2,3], ndmin=2)
a
输出:[1 2 3]
array([[[1, 2, 3]]])
数组复制的几种方案
#定义个数组
a = np.array([2,4,3,1])
# 在定义b时,如果想复制a的几种方案:
1.使用np.array()
b = np.array(a)
print('b = np.array(a):',id(b),id(a))
#输出
b = np.array(a): 2066731363744 2066731901216
2.使用数组的copy()方法
c = a.copy()
print('c = a.copy():',id(c),id(a))
#输出
c = a.copy(): 2066732267520 2066731901216
直接使用=号复制
直接使用=号,会使2个变量指向相同的内存地址,修改d也会相应的修改a
d = a
print('d = a:',id(d),id(a))
#输出
d = a: 2066731901216 2066731901216
arange()生成区间数组
根据 start 与 stop 指定的范围以及 step 设定的步长,生成一个 ndarray。
numpy.arange(start, stop, step, dtype)
参数说明
| 序号 | 参数 | 描述说明 |
|---|---|---|
| 1 | start | 起始值,默认为0 |
| 2 | stop | 终止值(不包含) |
| 3 | step | 步长,默认为1 |
| 4 | dtype | 返回ndarray的数据类型,如果没有提供,则会使用输入数据的类型。 |
整型
np.arange(10)
# np.array(range(10))
#输出
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
浮点型
# 可以使用浮点型数值
np.arange(3.1)
#输出
array([0., 1., 2., 3.])
指定类型
# 返回浮点型的,也可以指定类型
x = np.arange(5, dtype = float)
x
#输出
array([0., 1., 2., 3., 4.])
指定开始位置和步长
# 起始10 ,终止值20 步长2
np.arange(10,20,2)
#输出
array([10, 12, 14, 16, 18])
指定参数
ar3 = np.arange(20,step=3)
print(ar3)
#输出
[ 0 3 6 9 12 15 18]
float 不精确影响numpy.arange
linspace() 创建等差数列
返回在间隔[开始,停止]上计算的num个均匀间隔的样本。数组是一个等差数列构成
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
参数说明
| 序号 | 参数 | 描述说明 |
|---|---|---|
| 1 | start | 必填项,序列的起始值, |
| 2 | stop | 必填项,序列的终止值,如果endpoint为true,该值包含于数列中 |
| 3 | num | 要生成的等步长的样本数量,默认为50 |
| 4 | endpoint | 该值为 true 时,数列中包含stop值,反之不包含,默认是True。 |
| 5 | retstep | 如果为 True 时,生成的数组中会显示间距,反之不显示。 |
| 6 | dtype | ndarray 的数据类型 |
# 以下实例用到三个参数,设置起始点为 1 ,终止点为 10,数列个数为 10。
a = np.linspace(1,10,10)
a
#输出
array([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.])
a = np.linspace(1,10,endpoint=False)
a
#输出 默认均分50等份
array([1. , 1.18, 1.36, 1.54, 1.72, 1.9 , 2.08, 2.26, 2.44, 2.62, 2.8 ,
2.98, 3.16, 3.34, 3.52, 3.7 , 3.88, 4.06, 4.24, 4.42, 4.6 , 4.78,
4.96, 5.14, 5.32, 5.5 , 5.68, 5.86, 6.04, 6.22, 6.4 , 6.58, 6.76,
6.94, 7.12, 7.3 , 7.48, 7.66, 7.84, 8.02, 8.2 , 8.38, 8.56, 8.74,
8.92, 9.1 , 9.28, 9.46, 9.64, 9.82])
# 一下实例用到三个参数,设置起始位置为2.0,终点为3,0 数列个数为5
ar1 = np.linspace(2.0, 3.0, num=5)
ar1
#输出
array([2. , 2.25, 2.5 , 2.75, 3. ])
#设置retstep显示计算后的步长
ar1 = np.linspace(2.0,3.0,num=5, retstep=True)
print(ar1)
#输出
(array([2. , 2.25, 2.5 , 2.75, 3. ]), 0.25)
logspace()等比数列
返回在间隔[开始,停止]上计算的num个均匀间隔的样本。数组是一个等比数列构成
np.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)
参数说明
| 序号 | 参数 | 描述说明 |
|---|---|---|
| 1 | start | 必填项,序列的起始值, |
| 2 | stop | 必填项,序列的终止值,如果endpoint为true,该值包含于数列中 |
| 3 | num | 要生成的等步长的样本数量,默认为50 |
| 4 | endpoint | 该值为 true 时,数列中包含stop值,反之不包含,默认是True。 |
| 5 | base | 对数 log 的底数 |
| 6 | dtype | ndarray 的数据类型 |
整数
a = np.logspace(0,9,10,base=2)
a
#输出
array([ 1., 2., 4., 8., 16., 32., 64., 128., 256., 512.])
np.logspace(A,B,C,base=D)
- A: 生成数组的起始值为D的A次方
- B:生成数组的结束值为D的B次方
- C:总共生成C个数
- D:指数型数组的底数为D,当省略base=D时,默认底数为10
浮点数
# 取得1到2之间10个常用对数
np.logspace(1.0,2.0,num=10)
NumPy 数组属性
NumPy 的数组中比较重要 ndarray 对象属性有:
| 属性 | 说明 |
|---|---|
| ndarray.ndim | 秩,即轴的数量或维度的数量 |
| ndarray.shape | 数组的维度,对于矩阵,n 行 m 列 |
| ndarray.size | 数组元素的总个数,相当于 .shape 中 n*m 的值 |
| ndarray.dtype | ndarray 对象的元素类型 |
| ndarray.itemsize | ndarray 对象中每个元素的大小,以字节为单位 |
调整维度 reshape
返回调整维度后的副本,而不改变原 ndarray。
reshape 调整维度
a = np.array([1,2,3,4,5, 6])
print('一维数组a:',a.shape)
# 使用a数组,创建一个新的数组b,并向形状修改为2行3列
b = a.reshape((2,3))
print('b的形状:',b.shape)
print('b:', b)
#输出
一维数组a: (6,)
b的形状: (2, 3)
b: [[1 2 3]
[4 5 6]]
调整维度 resize
numpy.resize(a, new_shape) 如果新数组大于原始数组,则新数组将填充a的重复副本。
请注意,此行为与a.resize(new_shape)不同,后者用零而不是重复的a填充。
# a 为2行2列
a=np.array([
[0,1],
[2,3]
])
# 一a为原数组创建2行3列的新数组
b_2_3 = np.resize(a,(2,10))
b_2_3
#输出
array([[0, 1, 2, 3, 0, 1, 2, 3, 0, 1],
[2, 3, 0, 1, 2, 3, 0, 1, 2, 3]])
ndarray.ndim
返回数组的维度(秩):轴的数量,或者维度的数量,是一个标量,一维数组的秩为 1,二维数组的秩为 2
a = np.array([1,2,3,4,5, 6])
b = a.reshape((2,3))
c = np.array([
[
[1, 2, 3],
[4, 5, 6]
],
[
[11, 22, 33],
[44, 55, 66]
]
])
print('a的ndim:',a.ndim)
print('b的ndim:', b.ndim)
print('c的ndim:', c.ndim)
#输出
a的ndim: 1
b的ndim: 2
c的ndim: 3
ndarray.size
数组元素的总个数,相当于 .shape 中 n*m 的值
a = np.array([1,2,3,4,5,6])
print('[1,2,3,4,5,6]的size:', a.size)
a = np.array([[1,2,3],[4,5,6]])
print('[[1,2,3],[4,5,6]]的size:', a.size)
#输出
[1,2,3,4,5,6]的size: 6
[[1,2,3],[4,5,6]]的size: 6
ndarray.dtype
ndarray 对象的元素类型
a = np.array([1,2,3,4,5,6])
print(a.dtype)
b = np.array([1.1,2,3,4,5,6])
print(b.dtype)
#输出
int32
float64
方法astype()
numpy数据类型转换,调用astype返回数据类型修改后的数据,但是源数据的类型不会变
a=np.array([1.1, 1.2])
print('a数据类型:',a.dtype) #
print('astype修改数据类型:',a.astype('float32').dtype)
print('原数据类型未改变',a.dtype)
# 正确操作
a = a.astype('float32')
print('修改类型后再次操作,类型改变:',a.dtype)
#输出
a数据类型: float64
astype修改数据类型: float32
原数据类型未改变 float64
修改类型后再次操作,类型改变: float32
ndarray.itemsize
以字节的形式返回数组中每一个元素的大小。
例如,一个元素类型为 float64 的数组 itemsize 属性值为 8(float64 占用 64 个 bits,每个字节长度为 8,所以 64/8,占用 8 个字节)
a = np.array([1.1,2.2,3.3])
print('dtype:',a.dtype,' itemsize:',a.itemsize)
b = np.array([1,2,3,4,5])
print('dtype:',b.dtype,' itemsize:',b.itemsize)
#输出
dtype: float64 itemsize: 8
dtype: int32 itemsize: 4
数据类型
| 名称 | 描述 | 名称 | 描述 |
|---|---|---|---|
| bool_ | 布尔型数据类型(True 或者 False) | float_ | float64 类型的简写 |
| int_ | 默认的整数类型(类似于 C 语言中的 long,int32 或 int64) | float16/32/64 | 半精度浮点数:1 个符号位,5 个指数位,10个尾数位 单精度浮点数:1 个符号位,8 个指数位,23个尾数位 双精度浮点数,包括:1 个符号位,11 个指数位,52个尾数位 |
| intc | 和 C 语言的 int 类型一样,一般是 int32 或 int 64 | complex_ | 复数类型,与 complex128 类型相同 |
| intp | 用于索引的整数类型(类似于 C 的 ssize_t,通常为 int32 或 int64) | complex64/128 | 复数,表示双 32 位浮点数(实数部分和虚数部分) 复数,表示双 64 位浮点数(实数部分和虚数部分) |
| int8/16/32/64 | 代表与1字节相同的8位整数 代表与2字节相同的16位整数 代表与4字节相同的32位整数 代表与8字节相同的64位整数 | str_ | 表示字符串类型 |
| uint8/16/32/64 | 代表1字节(8位)无符号整数 代表与2字节相同的16位整数 代表与4字节相同的32位整数 代表与8字节相同的64位整数 | string_ | 表示字节串类型,也就是bytes类型 |
# 将数组中的类型存储为浮点型
a = np.array([1,2,3,4],dtype=np.float64)
a
#输出
array([1., 2., 3., 4.])
# 将数组中的类型存储为布尔类型
a = np.array([0,1,2,3,4],dtype=np.bool_)
print(a)
a = np.array([0,1,2,3,4],dtype=np.float_)
print(a)
#输出
[False True True True True]
[0. 1. 2. 3. 4.]
# str_和string_区别
str1 = np.array([1,2,3,4,5,6],dtype=np.str_)
string1 = np.array([1,2,3,4,5,6],dtype=np.string_)
str2 = np.array(['我们',2,3,4,5,6],dtype=np.str_)
print(str1,str1.dtype)
print(string1,string1.dtype)
print(str2,str2.dtype)
#输出
['1' '2' '3' '4' '5' '6'] <U1
[b'1' b'2' b'3' b'4' b'5' b'6'] |S1
['我们' '2' '3' '4' '5' '6'] <U2
定义结构化数据
使用数据类型标识码
| 字符 | 对应类型 | 字符 | 对应类型 | 字符 | 对应类型 | 字符 | 对应类型 |
|---|---|---|---|---|---|---|---|
| b | 代表布尔型 | i | 带符号整型 | u | 无符号整型 | f | 浮点型 |
| c | 复数浮点型 | m | 时间间隔(timedelta) | M | datatime(日期时间) | O | Python对象 |
| S,a | 字节串(S)与字符串(a) | U | Unicode | V | 原始数据(void) |
还可以将两个字符作为参数传给数据类型的构造函数。此时,第一个字符表示数据类型,
第二个字符表示该类型在内存中占用的字节数(2、4、8分别代表精度为16、32、64位的
浮点数):
import numpy as np
teacher = np.dtype([('name',np.str_,2), ('age', 'i1'), ('salary', 'f4')])
#输出结构化数据teacher
print(teacher)
#将其应用于ndarray对象
b = np.array([('wl', 32, 8357.50),('lh', 28, 7856.80)], dtype = teacher)
print(b)
print(b['name'])
#输出
[('name', '<U2'), ('age', 'i1'), ('salary', '<f4')]
[('wl', 32, 8357.5) ('lh', 28, 7856.8)]
['wl' 'lh']
切片和索引
ndarray对象的内容可以通过索引或切片来访问和修改,与 Python 中 list 的切片操作一样。
ndarray 数组可以基于 0 - n 的下标进行索引
区别在于:数组切片是原始数组视图(这就意味着,如果做任何修改,原始都会跟着更改)。
这也意味着,如果不想更改原始数组,我们需要进行显式的复制,从而得到它的副本(.copy())。
冒号分隔切片参数 [start:stop:step]
一维切片
ar1 = np.arange(10)
# 从索引 2 开始到索引 7 停止,间隔为 2
ar2 = ar1[2:7:2]
print(ar2)
print(ar1)
#输出
[2 4 6]
[0 1 2 3 4 5 6 7 8 9]
冒号 : 的解释:如果只放置一个参数,
- 如 [2],将返回与该索引相对应的单个元素。
- 如果为 [2:],表示从该索引开始以后的所有项都将被提取。
- 如果使用了两个参数,如 [2:7],那么则提取两个索引(不包括停止索引)之间的项。
ar3 = np.arange(1,20,2)
#array([ 1, 3, 5, 7, 9, 11, 13, 15, 17, 19])
print(ar3[:-2])
#[ 1 3 5 7 9 11 13 15]
ar3[::-1]
#array([19, 17, 15, 13, 11, 9, 7, 5, 3, 1])
为什么切片和区间会忽略最后一个元素
计算机科学家edsger w.dijkstra(艾兹格·W·迪科斯彻),delattr这一风格的解释应该是比较好的:
- 当只有最后一个位置信息时,我们可以快速看出切片和区间里有几个元素:range(3)和my_list[:3]
- 当起始位置信息都可见时,我们可以快速计算出切片和区间的长度,用有一个数减去第一个下表(stop-start)即可
- 这样做也让我们可以利用任意一个下标把序列分割成不重叠的两部分,只要写成my_list[:x]和my_list[x:]就可以了。
二维切片
ar4_5 = np.arange(20).reshape(4,5)
print(ar4_5)
#输出
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]]
# 切片为下一维度的一个元素,所以是一维数组
ar4_5[2]
#输出
array([10, 11, 12, 13, 14])
# 二次索引取得,一维数组中的元素
print(ar4_5[2][2])
#输出
12
ar4_5[2:]
#array([[10, 11, 12, 13, 14],
# [15, 16, 17, 18, 19]])
s = ar4_5[:][0]
#[0 1 2 3 4]
注意:切片还可以使用省略号“…”,如果在行位置使用省略号,那么返回值将包含所有行元素,反之,则包含所有列元素。
需要取得第二列数据
ar4_5[...,1]
# array([ 1, 6, 11, 16])
返回第二列后的所有项
ar4_5[...,1:]
array([[ 1, 2, 3, 4],
[ 6, 7, 8, 9],
[11, 12, 13, 14],
[16, 17, 18, 19]])
返回2行3列数据
print(ar4_5[1,2]) # 对应(1,2) 的元素
print(ar4_5[1:,2:])
7
[[ 7 8 9]
[12 13 14]
[17 18 19]]
索引的高级操作
在 NumPy 中还可以使用高级索引方式,比如整数数组索引、布尔索引,以下将对两种种索引方式做详细介绍。















 3696
3696











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









