






 本文探讨了在神经网络模型服务中,如何在面对动态随机工作负载和短延迟约束下,通过SHEPHERD系统优化扩展性、吞吐量和资源利用率。SHEPHERD通过聚合请求流、抢占机制和ILP模型来管理资源,确保在不可预测的工作负载下提供稳定的服务性能。
本文探讨了在神经网络模型服务中,如何在面对动态随机工作负载和短延迟约束下,通过SHEPHERD系统优化扩展性、吞吐量和资源利用率。SHEPHERD通过聚合请求流、抢占机制和ILP模型来管理资源,确保在不可预测的工作负载下提供稳定的服务性能。
问题:神经网络模型充斥在各类web服务应用中,而有大量的网络请求涌向模型,因为模型请求数具有动态随机性,而服务于模型的硬件资源有限,故承载模型的服务系统需要进行拓展,保证高吞吐量以及高资源利用率
优化指标:扩展性,吞吐量,资源利用率
限制因素:短延迟约束(一般在10-500ms),无法预测的工作负载,
扩展性与资源利用率的权衡差
传统方法优缺点:
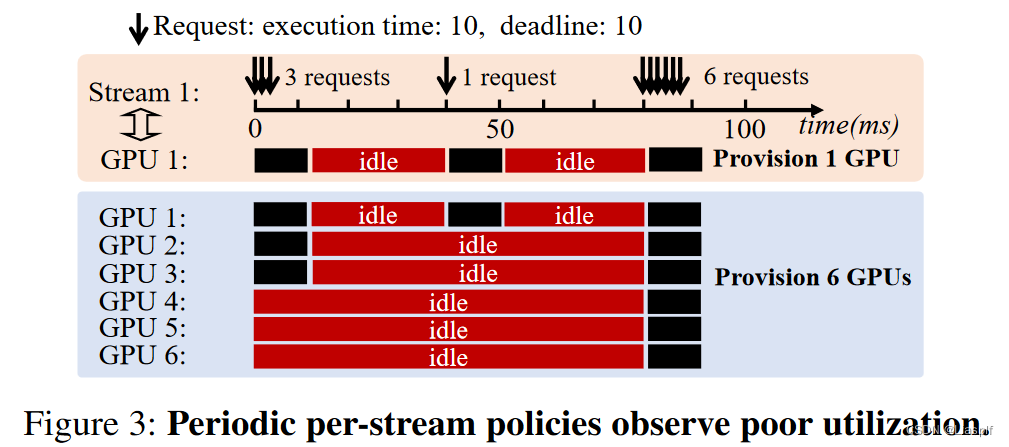
- 定期给每个流配置:定期配置具有扩展性较好的优势,但是对于突发的请求,使得系统每次都需要过度配置资源,这会导致资源利用率低下
- 在线全局配置策略:它能够通过在线调度算法实现高资源利用率,但是随着系统规模扩张,流数量增多以及资源池的扩张,系统资源分配复杂度急剧上升,扩展性较差
吞吐量无法保证
现有方法都无法在无法预测的工作负载情况下,对系统吞吐量做出保证(具备一个最低吞吐量标准);吞吐量的保证需要了解未来请求的到达模式;在没有使用抢占策略的情况下无法达到最优策略
问题关键点:短期的工作负载难以预测
如何在不可预测的工作负载条件下,设计一个具备扩展性、高资源利用率、有高吞吐量保证的模型服务系统
扩展性与高资源利用率通过聚合请求流来完成
高吞吐量保证通过抢占机制来实现
将具有相同延迟的SLO和目标模型的请求组成一个请求流进行处理
文章内容:构建了SHEPHERD系统,满足上述三个优化指标;在planning阶段,通过聚合请求流到组提升请求的可预测率来实现高资源利用率以及扩展性;在serving阶段,通过在线调度算法的抢占机制以及批处理机制来保证高吞吐量。
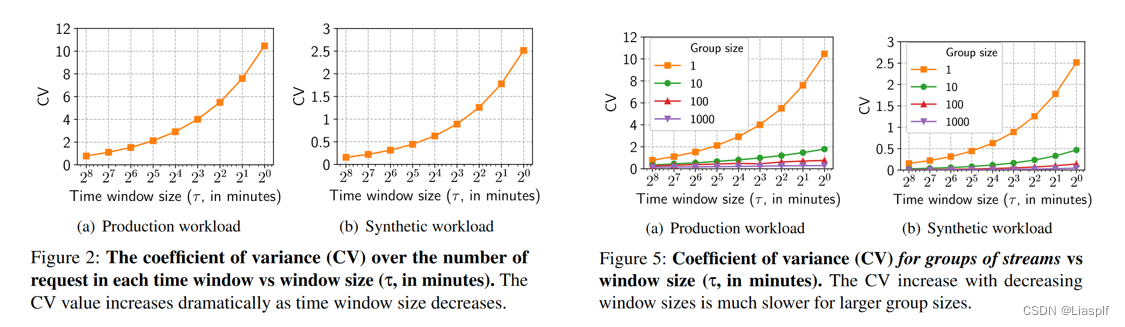
聚合请求流的原因
- Fig2的实验是按照请求流在一定的时间窗口内所发出的请求数,使用方差系数(标准差与 rt,s 平均值的比率)来量化每个流中的不可预测性
- Fig5将请求流聚类成组进行预测,组规模越大,相对来说组内请求总数越稳定,将请求流随机分配给一个组
- 这激发除了一个组多路复用,GPU集群资源划分到组,组内不同模型,模型有多个流,每个流的请求数量不一致,此时可以对资源进行统计复用,这解决了资源利用率以及扩展性的问题(因为成千上万个流与大量GPU资源调度难以处理,成组后限制了组内规模,具有一定的扩展性,资源也可以进行复用)
- 在单个请求流无法预测的时间段,可以选择将请求相同模型的流聚集到同一个组,并且通过实验测试可知,这个组在一定时间段内的请求数量是稳定的,并且随着时间段的缩小,请求数量的方差均处于一个较小且稳定的范围内
- 根据这一特性,在固定时间窗口内,模型组的请求数量可预测,可据此对模型所需资源进行扩展,高请求率的组划分更多的相应资源以保证资源高利用率。
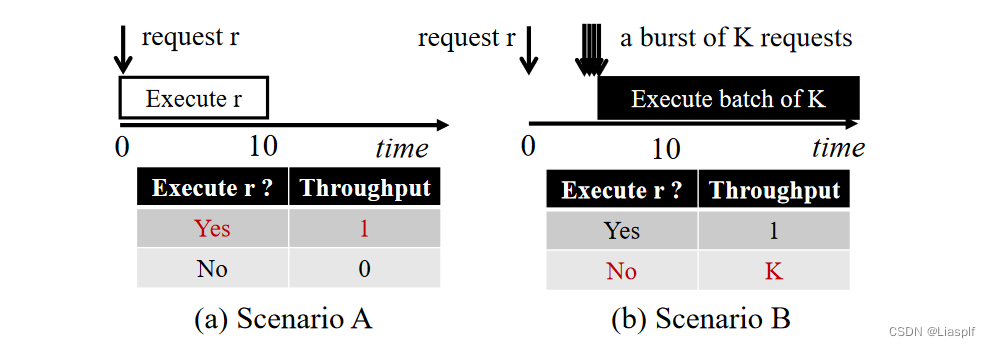
抢占原因
当单个请求到达时,系统会选择处理先到的请求,此时若已无空闲资源,并且有K个请求到达,那么K个请求只能等待其他请求的完成,待到其他请求结束推理,K个请求可能已经超出最大请求完成延迟了,至此导致系统吞吐量降低
这种抢占的思想在SLO比较紧张的时候,带来的吞吐量收益非常明显
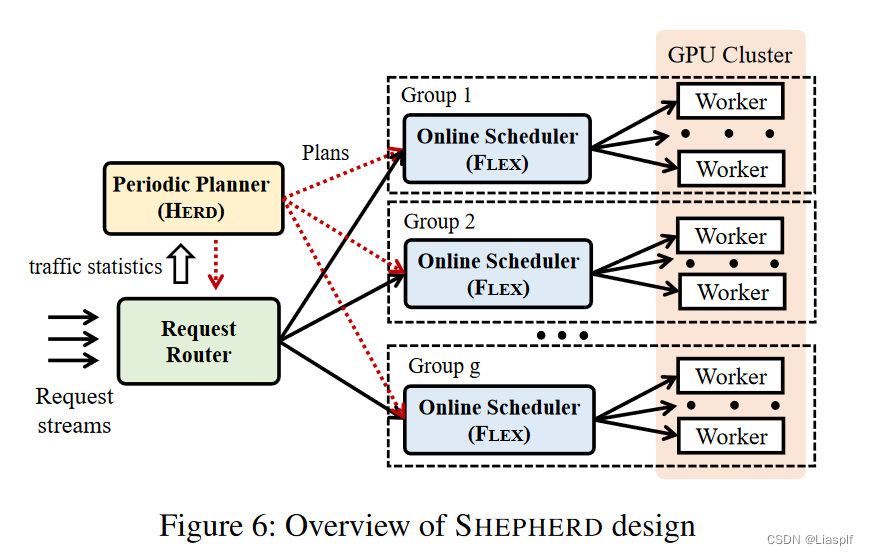
架构图:
定期规划组件利用长期的负载统计数据将整个GPU集群划分为多个服务组,并确定如何将查询他们的模型和请求流映射到这些组,以优化资源利用率和系统可扩展性
Planner(HERD):执行定期计划,通知每个GPU Worker它属于哪个服务组以及它必须服务的模型,他还为每个组配备了一个组级调度程序,组级调度程序的总数可以根据系统所服务的模型数量以及它们之间的总负载进行扩展
Request router:该请求路由根据目标模型将客户端推理请求转发到组级调度程序,并收集到达模式的统计信息,用于HERD进行计算组级映射
Scheduler(FLEX):执行在线调度算法FLEX,用于将推理请求发送给服务于对应模型的GPU worker
Multiple GPU workers:执行推理任务
Planning阶段
- 将模型和GPU工作线程随机分配在一个服务组内也能够实现良好的工作负载可预测性,但实现高利用率和保证吞吐量需要考虑许多额外的因素,然后将这些约束因素表述为一个整数线性规划,特别是将α,β相似的模型放在同一个服务组时后续的FLEX阶段由更好的吞吐量保证(用于跨模型抢占),HERD 还在其 ILP 中纳入了模型亲和力(α、β 值之间的相似性度量),并且限制了模型亲和力K值不超过某个数
- Ti是一个流在单个GPU上能够执行的最大吞吐量,每个流的平均负载ratei需要ni个GPU来支持
- ni=ratei/Ti,即ni是平均负载下需要消耗ni个GPU来维持运行
- bt(i) = 一个流所属分组的GPU数量/ni = 该组集中所有资源能处理流的最大请求负载数量,即为容忍度。对于容忍度当然是越高越好,因为更能应对突发的请求流
- 这个阶段会根据ILP划分好群组,组内GPU资源,模型,请求流分配;并且ILP求解出最优分配策略只需要几秒钟,而请求流中请求总数在较长一段时间内是稳定的
Serving 阶段(由λ决定K,即λ约等于3.03时,系统吞吐量最差为12.62K倍,后续有8页推导)
- FLEX保证吞吐量最多比完全了解未来请求到达模式的离线算法差12.62K倍,K是模型亲和力参数,如果服务组中所有模型具有相同的αβ,则参数为1,如果模型差异较大,则K增大
- 实现的方法两个关键点是利用抢占实际来实现优先级,修正错误调度;以及掌握批处理与延迟之间的关系,便于估算请求的DDL
- 在线调度专注于单个服务组中跨模型跨GPU的推理请求调度,一个请求流中的请求具有相同的SLO,请求是成批进行处理BB代表所有可能的批处理集合,B是批处理集合,每个批都有到达时间,DDL,请求模型,调度策略就是决定批处理集合中的某个批是否应当处理以达到最大化吞吐量
- Batch generation算法是生成GPU n上所有模型中最大的批处理请求,FLEX有两大事件会触发代码执行,一个是GPU上某个批处理结束,需要选择新的最大批进行处理;第二个就是有新请求到达,需要更新每个GPU上的批,在符合抢占条件的情况下,被强占的批找到最近的退出点重新入队,抢占批执行处理。















 767
767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









