






提出了 AlpaServe,一个用于多个大型深度学习模型的预测服务的系统。 AlpaServe的关键创新是将模型并行性集成到多模型服务中。 由于模型并行性固有的开销,这种并行性传统上是保守应用的——仅用于模型根本不适合单个 GPU 或在所需 SLO 内执行的情况。
问题:大模型无法通过单个设备处理,对于请求的爆发会导致处理延迟增加
优化指标:GPU利用率,SLO attainment(百分比用户在一定延迟内的请求能完成),latency
并行的优点:设备的统计复用,提升GPU利用率,应对高并发,
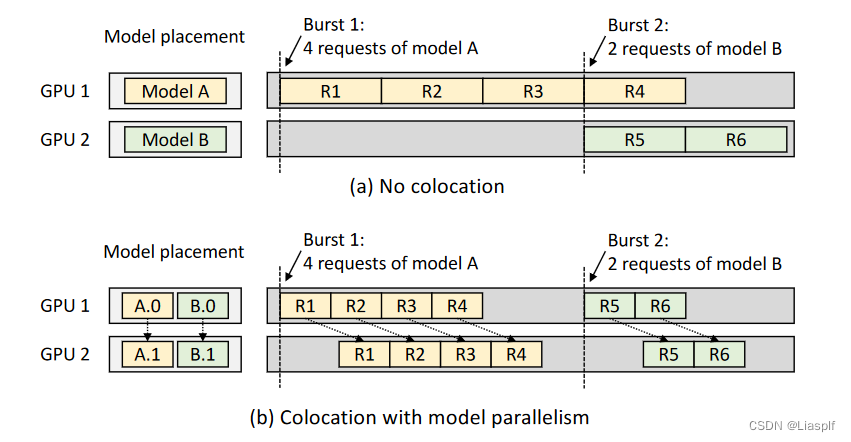
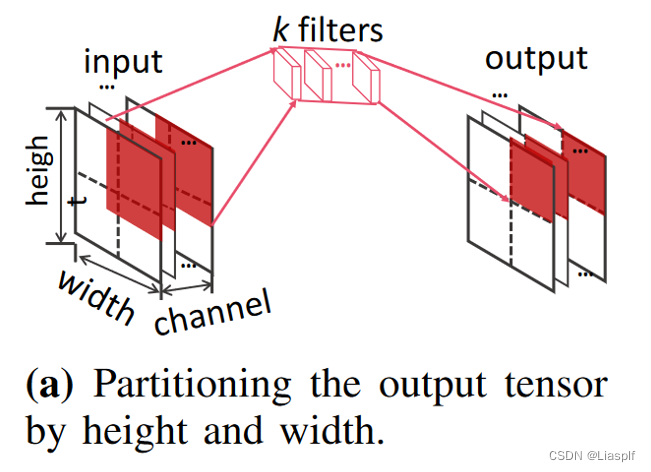
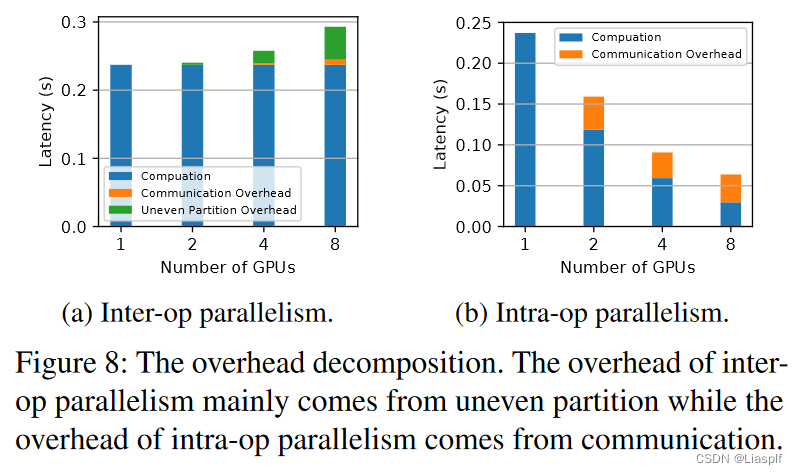
Fig1:假设四个请求同时到来,这里面四个请求指示代指大量请求同时到达,实际上四个请求同时到达当然可以通过批处理的来完成,但是实际情况可能一次性有四千个请求,四万个请求,此时也就无法批处理,因为同时激活这些请求数据会导致大量的内存被占用,这也是为什么批处理不是越大越好的原因之一。
Fig1(b)的防止策略采用的是模型拆分,算子间的并行操作,由A.0先处理一部分任务,然后传输中间结果给A.1,这里会导致后续提到的通信开销(表明的意思是不是拆分的越细,越能提升CPU利用以及效率),拆分后,GPU1能够更快的空闲出来处理下一个任务,由此达到提升任务处理速度以及GPU利用率
Fig2:将一个tensor分成多个块给每个设备进行并行计算,需要考虑输入的拆分以及结果的合并,这一块也同样存在通信开销,两种并行策略是互不冲突的可以同时使用的,但是要考虑资源数量是否支持,并且Fig2的并行可以降低单个输入的延迟,因为算子间并行最终还是要考虑数据依赖性,而算子内并行无需考虑数据依赖性
Fig8:算子间并行,由于它存在多个阶段(阶段数=切分数-1),不同阶段之间由于数据依赖需要通信,通信延迟不固定,即不平衡,取决于最慢的那个延迟,会导致一个不平衡分区延迟,而算子内并行则没有这方面问题,因为它的通信只有在最终合并结果时,相对来说没有算子间并行通信那么频繁
但是算子内并行需要通信的数据量更大,导致它的通信开销延迟更大(结果显示是这样,但是按道理应该是算子间并行通信开销大,这里有问题)
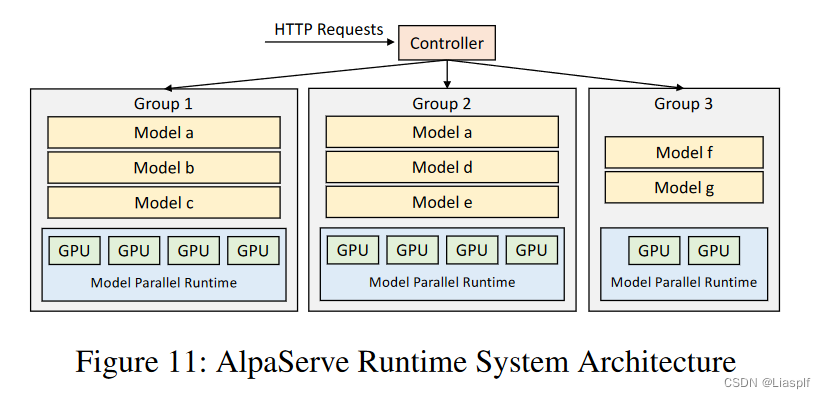
Fig11 导出有效的模型并行推理策略,以减少模型并行的开销。(找到一种分区策略,最大限度地减少算子间并行性的阶段不平衡);根据请求达到模式来决定模型并行化防止策略,以此来达到最大化SLO attainment
1.并行配置和权衡:不同的并行配置会涉及到延迟(latency)和吞吐量(throughput)之间的
权衡。不同的配置可能适用于不同的模型和任务,因此需要尝试多种可能的配置。
2.自动并行编译器: AlpaServe首先运行一个自动并行编译器,该编译器会在各种约束条件下生成一系列可能的配置列表。这些配置可以涵盖模型的操作内并行性和操作间并行性,以满足不同需求。
·模型和集群: AlpaServe面对一组模型(models)和一个固定的计算集群(cluster)。·集群分区: AlpaServe将计算集群分为多个设备组(groups of devices)。每个设备组使用共享的模型并行配置来为一组模型提供服务。不同设备组可以持有相同模型的副本。
·请求分派:针对某个模型的请求被分派到包含请求的模型副本的设备组中。这意味着如果有多个副本,请求将被分派到包含请求模型副本的设备组。
·放置(Placement)︰将特定的集群分组、模型选择和并行配置称为放置。放置是一种策略,决定了哪些设备组服务哪些模型以及如何进行并行计算配置。
·目标: AlpaServe的目标是找到一个放置策略,以最大程度地实现服务水平协议(SLO)的达成。换句话说,它旨在确保在给定的模型和集群条件下,服务的性能和可用性达到最佳状态。
设计了一个两级放置算法:给定一个集群分组分区和每个组的共享模型并行配置,算法1使用一个模拟器引导的贪婪算法来决定每个组选择哪些模型。然后,算法2枚举各种潜在的集群分区和并行配置,并比较来自算法1的SLO达成,以确定最佳的放置策略。
这两个算法合作以找到最佳的放置策略。算法1负责为每个设备组选择模型,而算法2负责确定如何分配设备和模型,以实现最佳的SLO达成。这个两级放置算法允许系统更好地适应不同的情况和要求,以最大程度地提高性能和可用性。
Fig15 批处理不会带来性能改善的原因大致是因为批处理最终还是将tensor整合在一起,而系统又会根据贪婪测试后选择最佳的并行策略,以此来控制每个设备处理的数据量,批处理量大,算子内并行通道可能就相对增多,算子间并行通道相对减少,使得控制每个设备的计算量尽量稳定















 806
806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









