







字体示例1

字体示例2
字体示例3

生成的过程中,问题还是挺多的,比如文字不存在,就会生产出来全白色的图片,这需要删掉!
还有可能会生成非常小的,需要调节尺寸
整体目录格式如下: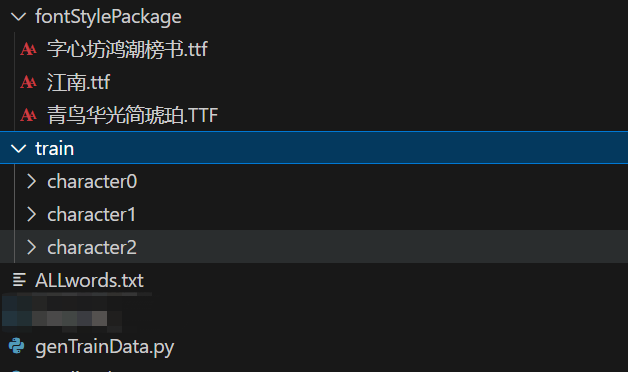
fontStylePackage放入ttf格式文件,便可以自动读取进行字体生成。
train生成数据放的地方
ALLwords.txt 下面有获取方式
genTrainData.py 生成字体代码如下;
import string
import cv2
import numpy as np
from PIL import Image, ImageDraw, ImageFont
import tqdm
def draw_text_with_font(font_path, text, image=None, write=False):
# 设置图像大小和背景色
iw, ih = 5, 5
thre = 16
image = np.ones((iw*thre, ih*thre, 3), np.uint8) * 255 # 将图像放大一倍
# 加载TTF字体文件
font = ImageFont.truetype(font_path, 72) # 将字体大小调大
# 创建PIL图像对象
pil_image = Image.fromarray(image)
draw = ImageDraw.Draw(pil_image)
# 计算文本绘制位置
text_width, text_height = draw.textsize(text, font)
x = (image.shape[1] - text_width) // 2
y = (image.shape[0] - text_height) // 2
# 绘制文本
draw.text((x, y), text, font=font, fill='black')
# 将PIL图像转换为OpenCV格式
cv_image = cv2.cvtColor(np.array(pil_image), cv2.COLOR_RGB2BGR)
# 将图像缩小回原始大小
cv_image = cv2.resize(cv_image, (ih*thre, iw*thre))
# 保存图像
if write:
# cv2.imwrite('seeStyle{}.png'.format(font_path.split('\\')[-1].split('.')[0]), cv_image)
cv2.imshow('1', cv_image)
cv2.waitKey(0)
return cv_image
def cuter_word(styleImage, ocr):
result = ocr.ocr(styleImage)
for line in result:
for idx, word_info in enumerate(line):
xbox = word_info[0]
# 提取x和y坐标
x_coords = [point[0] for point in xbox]
y_coords = [point[1] for point in xbox]
thre = 0
x_min = max(int(min(x_coords)) - thre, 0)
y_min = max(int(min(y_coords) - thre), 0)
x_max = int(max(x_coords))
y_max = int(max(y_coords))
styleImage = styleImage[y_min:y_max, x_min:x_max]
return styleImage
def draw_font(idx, jdx, font_path, text, write=False):
cv_image = draw_text_with_font(font_path, text)
# 保存图像
# print(idx, jdx, text)
fontPath = 'train/character{}'.format(idx)
if not os.path.exists(fontPath):
os.makedirs(fontPath)
im = cv2.cvtColor(cv_image, cv2.COLOR_BGR2GRAY)
if write and cv2.countNonZero(im)!=6400:
cv2.imwrite(os.path.join(fontPath, jdx+'.png'), cv_image)
return cv_image
if __name__ == '__main__':
# 调用函数并传入TTF字体文件路径和文本信息
import os
# 逐行写入到Txt文件
fontStyle = os.listdir("fontStylePackage")
fonts = []
with open('ALLwords.txt', 'r', encoding='utf-8') as file:
for line in file.readlines():
fonts.append(str(line).strip('\n'))
print(fonts)
for idx, fs in enumerate(fontStyle):
font_path = os.path.join('fontStylePackage/', fs)
print("第"+str(idx) + "种类的风格字体正在生成中。。。 ")
for jdx, text in enumerate(tqdm.tqdm(fonts)):
text = text[-1]
draw_font(str(idx), str(jdx), font_path, text, write=True)
给出字体txt文件,里面包含了2W多个字体,简体字繁体字中文汉字大全,如果不存在的话可以根据以下函数除去生成的空白图片。
链接:https://pan.baidu.com/s/1sr-IQIHGfuFODNSaIDf2Bw
提取码:87k3
--来自百度网盘超级会员V4的分享
def delWithoutWord(image):
cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
if cv2.countNonZero(im)==6400:
return True 图片全白
return False # 图片非全白运行截图



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











