







知己知彼,百战不殆
一.为什么要进行一次出色的信息搜集?
笔者认为信息搜集的最大目的就是获取目标的准确信息,了解目标的运作方式以确定最佳的攻击路线,信息搜集工作紧接着前期交互工作进行,一次出色的信息搜集可能会使后期的工作事半功倍,信息搜集的过程无疑是煎熬的,信息搜集需要缜密、详细的计划,而比这更重要的是从一个攻击者的角度去考虑问题,取得root权限无疑是令人兴奋的,但在会跑之前得先学会走才行,在正式介绍如何进行搜集前,请注意这一点:没必要对搜集的信息设定条条框框,即使是起初看起来零零碎碎毫无价值的数据都有可能在后续工作中派上用场。
二.具体步骤&思路&经验
1.1 whois信息收集&SEO综合查询
WHOIS查询是一种用于查询互联网域名、IP地址、自治系统等信息的网络查询工具。它提供了有关特定互联网资源所有者、注册人、注册商和联系方式等详细信息。在互联网基础设施中,WHOIS查询扮演着关键的角色,帮助人们查找和联系到相关的网络资源所有者。除了基本的注册信息,WHOIS查询还可以获取到域名的注册时间、更新时间、过期时间、DNS服务器等重要信息。这些信息对于网络安全研究、域名管理、网络侦查等方面具有重要意义。通过信息的整合与分析,可以帮助识别网络威胁、管理域名资产、推断网络拓扑结构等。我们一般使用工具进行站点的whois查询,笔者这里推荐的有http://whois.chinaz.com ,https://x.threatbook.cn/
,http://whois.bugscaner.com这几个网站来进行前期的whois查询,同时我们可以通过企查查或爱企查以及网站备案信息查询来进行手机号码,旁站以及厂家,上家下家,开发商,技术负责人(CTO)技术水平以及背景的搜集,对后期的威胁建模打好基础,如果运气好的话我们可以从中看到大量的网站网站信息包括但不限于注册人的电话或者邮箱,这写信息可以以便于我们后期构造字典payload来进行爆破
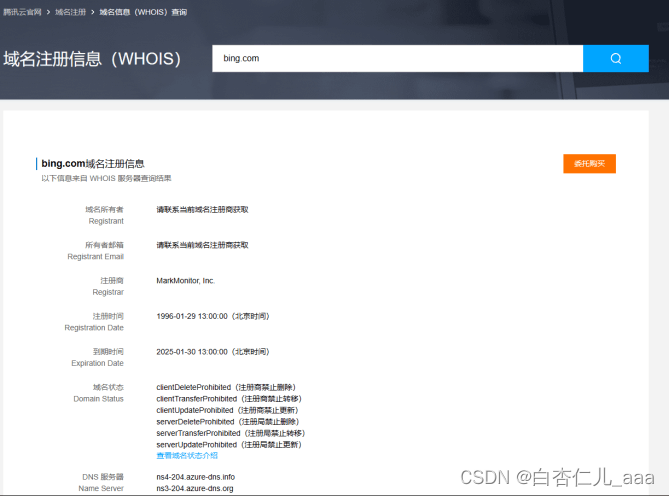
(通过腾讯云进行的whois查询)
1.2子域名以及IP查询(FOFA,Google语法)
一般来说,在渗透测试过程中,我们大多从小站入手,就像小偷偷东西需要从窗户进,而不能大摇大摆的从正门进(这不明摆着挑衅警察蜀黍吗 ( ¬、¬) ),后续的渗透测试也是一样,但在这之前,我们得先知道“窗户”在哪里,由此有了下文…
笔者一般的思路是使用FOFA等工具进行IP反查域名(FOFA语法:ip=”xxx.xxx.xx.xx”,然后使用域名反查IP(FOFA语法:domain=”xxx.xxx.com”,)这里有一个小细节需要注意:如果我们像domain=”test.test..com”,这样的多级域名无搜索结果,这时候我们不妨试试一级域名domain=”test.com”,或者使用Sublist3r工具来一遍一级域,随后整合去重。(ip查询将上述步骤反过来即可)
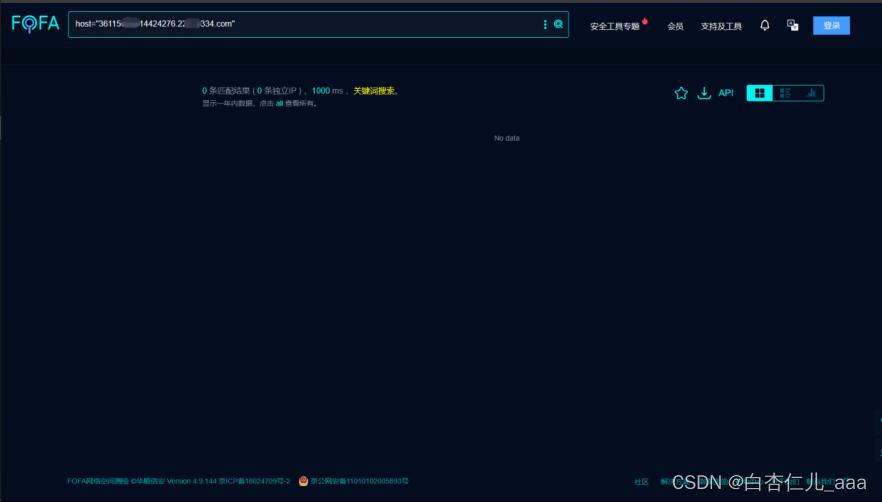
(我们搜索二级域名时什么也没有)
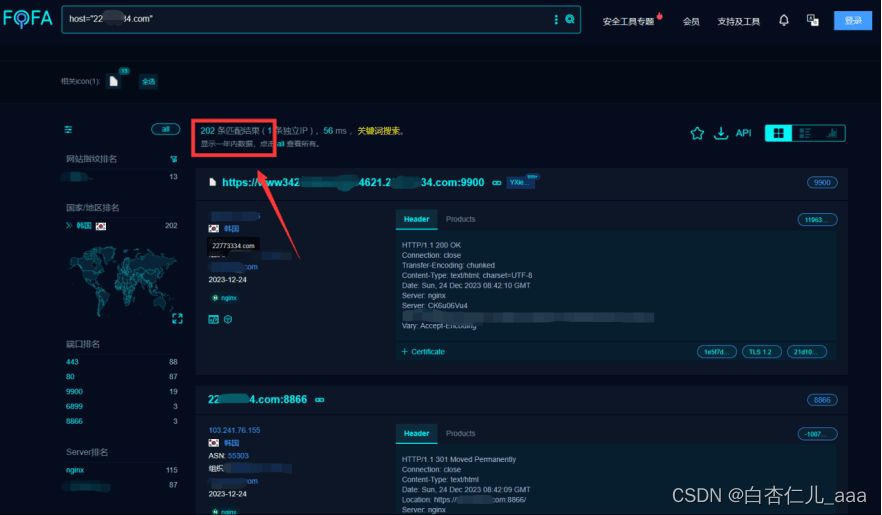
(这时我们直接搜一级域名,搜索结果大大增加)
除了FOFA外,我们还有一种方法就是去使用Google语法去进行搜索,这边推荐几条常用的命令
Google:
site:
指定域名,如:site:edu.cn 搜索教育网站
inurl:
用于搜索包含的url关键词的网页,如:inurl:uploads 文件上传,搜索关于公司有关的网址中含有login的网页,
intitle:
搜索网页标题中的关键字,如:
intitle:“index of /admin” robots.txt
intitle:“robots.txt”
intext:
搜索网页正文中的关键字,如:intext:登陆/注册/用户名/密码
FOFA:
title="beijing"
从标题中搜索“北京”
header="elastic"
从http头中搜索“elastic”
body="网络空间测绘"
从html正文中搜索“网络空间测绘”
domain="111.com"
搜索根域名带有111.com的网站
ip=”xxx.xxx.xx.xx”
搜索ip归属为xxx.xxx.xx.xx的网站
PS:在实际渗透中一般会写扫描器来进行批量导出,这样效率可以大大提高。
Tips:ip地址有时候没有waf的部署
1.3端口探测
端口开放将为我们下一步的脆弱服务搜寻提供服务,这里笔者根据项目经验推荐的扫描器是naabu(项目地址:GitHub - projectdiscovery/naabu: A fast port scanner written in go with a focus on reliability and simplicity. Designed to be used in combination with other tools for attack surface discovery in bug bounties and pentests),新版本的更新使其拥有了端口扫描引入,自动IP重复数据消除的功能,可以说是大大的提高了我们的效率,这是肯定有许多师傅要问为什么没有推荐nmap,因为nmap已经很老了,这里可以网上搞一些方法,闭源起来,给谁都不要发,保证稳定性,而且nmap指纹会被识别到,还会误报,笔者在做某些项目的时候,没有扫到一个满意的结果,一般都是看一些敏感的端口(6379、1433、1521、3306、以及3399的rdp),直接去连,但是成本比较高,不过效果也比较好。
Ps:在使用扫描器之前,笔者建议先FOFA语法过一遍,把所有资产整理出来,那些带端口的就已经差不多了,然后再验一下,就好了,自己扫一般扫不出太好的结果。
1.4目录扫描
目录扫描也可以帮助我们在短时间内快速获得目标各类域名信息,找到更多我们也许无法在网站前台获取到的有价值信息(例如:信息泄露,开放接口,文件上传点…以及后面的服务验证)但是换做别人,如果只是一把梭的话,和可能会无功而返,这时我们就需要一个思路来帮助我们获取更有价值的信息。
思路:笔者在渗透测试中一般会将dirsearch、yujian、7kbscan,扫目录的字典,扫备份的字典合成再分成两个字典(一个扫目录,一个扫备份文件),然后先进行目录扫描,如果无后缀或者没有访问情况下爆出403,后面加一个后缀爆出404,我们则可以确定访问目录,后丢弃404,保留403,然后继续扫备份字典(如果扫出来很多可以用linux提取,很方便),ps:(根据笔者的实验测试以及经验积累发现,因为是同一ip地址,有时的请求过于频繁,就会直接爆200状态码,因为有些waf会检测到在用扫描器扫描,以此来混淆视听,要绕过这东西,笔者的解决办法一般是:用某些搞来的框架的代理池,保留500以内延迟的,然后用ip轮回扫,或者在时间充裕的情况下,开低线程扫描,因为是循环扫,所以速度还可以,并不是太差。)
一些提升效率的小tips:也许笔者做的比较快吧,一些细节问题,那些习惯性用的语法什么的,全部都写好了,然后还有排序去重那些也都写好了,一个指令下去,只要等时间,然后等时间的时候笔者也要看,因为有可能会出问题,网络突然断了,代理死了,服务器封了,或者是被安全机制拉黑了等种种问题。
1.5开启服务
在整理完目录以及端口信息后,我们就可以进行目标开启服务的验证了,这一步的主要目的是找寻目标的服务,然后用已知漏洞进行测试(原理类似打nday,或者是从脆弱服务绕过然后提权例如摄像头,路由器这些,因为这些一般都是有内网的),在验证开启服务的是侯笔者一般的做法是用httpx验存活
随后,开25个线程,错误的反复请求5次,隔两秒请求一次,超时是20秒,要对验出来的目标保质保量,注意在请求的时候使用--random-agent参数(启用随机 User-Agent头,如果不加这个,他有可能会认为你是扫描器,不是正常用户,然后不返回),随后去重,提200再提链接,时间充足建议写脚本,或者是用Finger,去挨个访问,虽然时间比较慢,但是慢也有慢的好处,因为这样结果是最理想的。
1.6 CMS指纹识别
CMS指纹识别对于笔者来说其实并不常用,因为很多系统是闭源的,但还是有必要看一下的,这里笔者推荐云溪和Wappalyzer,相信大家对那个Wa紫色界面已经很熟悉了,这里就不贴图了,找到cms后我们可以用最新的nday进行漏洞的利用
1.7 CDN相关
对于真实地址与cdn以及vps的的分辨,一直是诸位头痛的问题,这里笔者通过列表排序的方法列出了几条常用的方法
1.子域名:一般主站有必要开CDN,但一些子站没有必要。如果子站和主站在同一网段,则由子站可以推导出主站真实IP。可以使用子域名扫描网站(如tools.bugscanner.com/subdomain)来检测是否存在CDN。
2.邮箱:邮件服务器一般由内部员工使用,没必要搭建CDN。可以利用服务器发送邮件时较大可能使用主IP进而套取邮件服务器的地址。
3.国外地址请求:一般情况下的国内大型网站没有必要在国外搭建CDN节点。而在利用时要尽量选用偏远国家进行请求,或者利用国外的一些公开网站进行ping检测。
4.遗留文件:有些网站可能会遗留一些文件,比如phpinfo.php等,这些文件可以用来检测服务器的相关信息,从而判断是否存在CDN。
5.扫描全网:撒大网,有可能其中之一正好在真实服务器附近,再通过各种方法筛选。
6. 超级ping/curl:从全国各地甚至海外进行ping检测,查看返回的IP地址是否相同。如果多个地址返回的是同一个IP地址,则可能没有使用CDN;如果多个地址返回的是不同的IP地址,则可能使用了CDN。
1.8 快照技术&社工技术
有时候网页内容会被删除或更改,此时可以通过快照来查看网页的原始内容,从而快速地获取所需的信息。随后进行对网站进行前域名持有分析,来推断持有人个人信息。而在某些情况下快照的结果其实并不尽人意,此时我们就可以通过社工的方法来进行信息的搜集,这项技术需要一点“魔法”,笔者在这里并不过多的赘述。Ps:还可以考虑在那个蓝色软件上买源代码然后进行审计(doge)。
1.9 信息泄露
Git目录类型:使用git init初始化git仓库的时候,生成的隐藏目录,git会将所有的文件,目录,提交等转化为git对象,压缩存储在这个文件夹当中。在线上环境未清理隐藏目录则可能造成源代码的泄露,我们此时可以通过在域名后加.bak 、.git 、.fonfig来验证是否存在信息泄露,.SVN与.ASP的原理也大同小异,这里也不过多的赘述,对于有些采用python架构的网站来说,其拓展名默认是.py如果没有配置.pyc拓展名的话那么我们就可以进行任意文件的下载,然后利用uncompyle2来对文件进行反编译,从而拿到源代码。
PATH泄露:对于path的泄露,我们也要尽量的收好,因为这在后面对于上传目录,目录遍历,敏感文件的利用有真很大的作用,这里笔者推荐一款火狐插件:findsomething,可以高效收集path。

2.0钓鱼
钓鱼时至今日早已不稀奇,曾出现在各类大大小小的攻防竞赛上,在apt中也层出不穷,钓鱼一般分为套话和等上线,在等上线之后打内网,笔者认为国内对钓鱼这方面的技术已经很成熟了,扫描邮件伪装waf厂商啊,等等各类骚操作。师傅们可以看看这篇文章渗透测试之地基钓鱼篇:Ink和Mp3伪装钓鱼 - FreeBuf网络安全行业门户
三.案例分析(皆有授权,请勿举报,仅供展示使用,无其他任何意图)
2.1 whois&社工
在某次项目上,笔者看到目标站点上有联系方式(邮箱),于是在资产里面排查后台然后采用验证码爆破后台的方式成功进入,后提权成功拿到root权限,并拿到源码

2.2目录扫描
在对某省公安厅委托的渗透测试中,笔者采用1.4的方法进行目录扫描,意外得到省内公安身份调用接口,再进行提权后可使用,预计影响人数6000余万人。
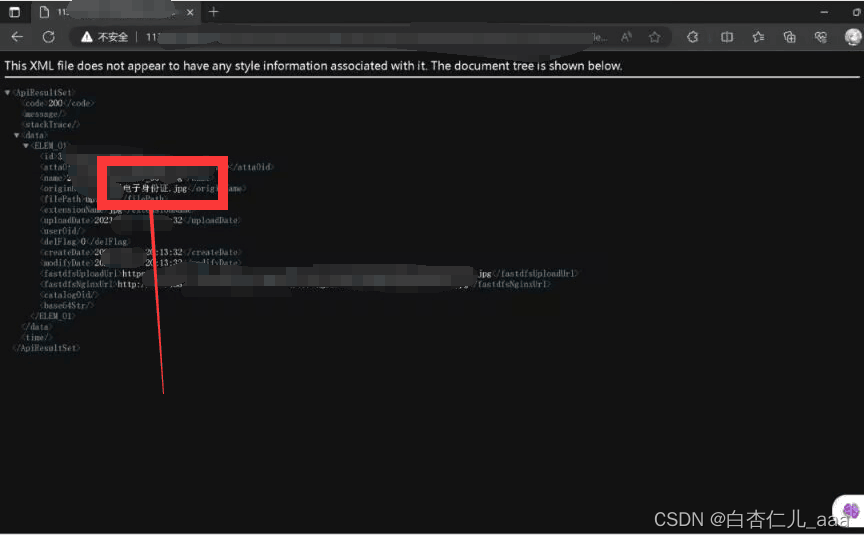
(调用接口图片)
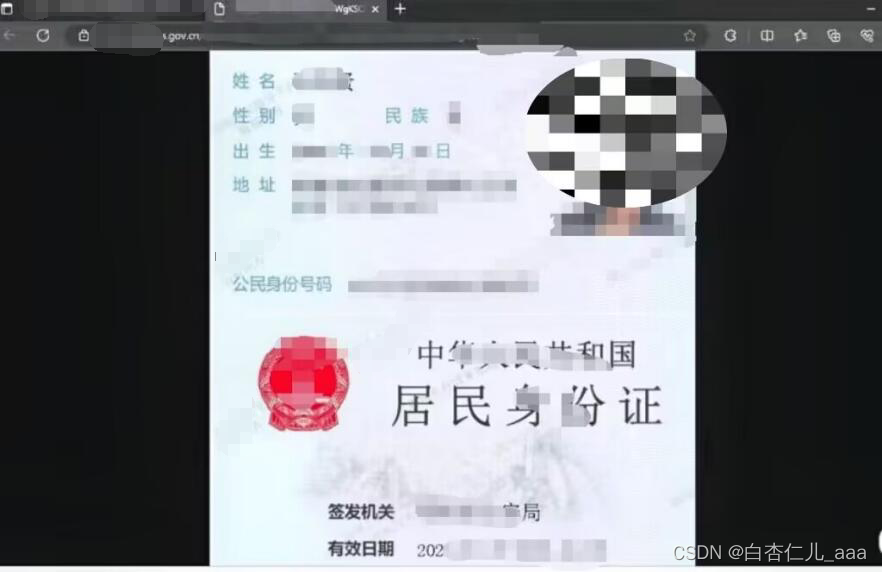
2.3服务搜集
在对某部委网站有授权的情况下进行合理合法的情况下进行测试,通过前期服务收集方法和储备0day的构造,成功进入后台。
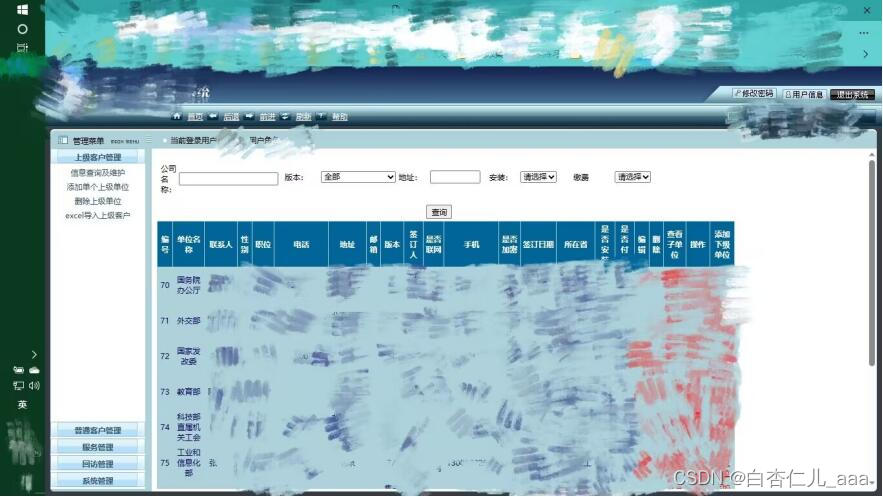
-
反思&鸣谢
笔者写这篇博客的起因是群内的一个私下玩的很好的师傅抱怨说网上的技术良莠不齐,缺乏创新,基本都是复制粘贴来的,挂着羊头卖狗肉,所以笔者想了想就打算开一个讲渗透测试步骤的博客,主要是分享渗透测试中的一些步骤思路以及创新点(从信息收集,威胁建模…开始,尽量覆盖渗透测试中的每个环节,以便于师傅们有一个好的阅读体验),笔者也想借此分享一些心得和经验技术,这种技术博客不仅对各位师傅们,对笔者说也是一个很好的学习过程。通过写博客,笔者能够更好地整理自己的思路,加深对技术的理解。同时,与读者交流的过程中,笔者也能够不断发现自己的不足之处,持续进步。最后欢迎大家在评论区积极讨论,集思广益。
首先感谢的就是我的好兄弟林宇辰(KINGBob)与南山海(n0t3),他们为我提供了许多宝贵的思路和操作建议使我受益匪浅,他们为本文的撰写提供了许多独特的思路与见解,感谢fancypig的小伙伴们,同时也感谢各位师傅在百忙之中可以抽出时间阅读,愿我们群星闪耀,共创辉煌!
Warning:本文案例仅供交流讨论,皆以取得授权且漏洞皆已修复,请勿用于非法用途以及造谣传谣,造成的一切后果与本文作者无关。















 2414
2414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









