







前言
本文章基于黑马程序员Redis教学视频进行总结,仅作为学习所用,欢迎大家在评论区多多讨论
视频连接:B站黑马程序员Redis视频(点击跳转)
在Redis基础学习·第四期(点击跳转)中谈到Redis的五种基本数据类型,这期就来聊聊Redis中的set类型
一、set类型
- 新的存储需求:存储大量的数据,在查询方面提供更高的效率(list类型有顺序有索引存储大量数据但链表结构查询效率低)
- 需要的存储结构:能够保存大量的数据,高效的内部存储机制,便于查询
- set类型:与hash存储结构完全相同,仅存储键,不存储值(nil),并且值是不允许重复的

二、set 类型数据的基本操作
- 添加数据
sadd key member1 [member2]
- 获取全部数据
smembers key
- 删除数据
srem key member1 [member2]
- 获取集合数据总量
scard key
- 判断集合中是否包含指定数据
sismember key member

三、set 类型数据的扩展操作
业务场景一
每位用户首次注册使用今日头条时会设置3项爱好的内容,但是后期为了增加用户的活跃度、兴趣点,必须让用户对其他信息类别逐渐产生兴趣,增加客户留存度(用户粘性),如何实现?
业务分析
- 系统分析出各个分类的最新或最热点信息条目并组织成set集合
- 随机挑选其中部分信息
- 配合用户关注信息分类中的热点信息组织成展示的全信息集合
解决方案
- 随机获取集合中指定数量的数据[原集合不变]
- 推荐过了可能还会推
srandmember key [count]
- 随机获取集合中的某个数据并将该数据移出集合[原集合发生改变]
- 推荐过了不会再推,分配过了不会再分[比如给每个人分配不同任务]
spop key [count]

Tips:
- redis 应用于随机推荐类信息检索,例如热点歌单推荐,热点新闻推荐,热卖旅游线路,应用APP推荐,大V推荐等
业务场景二
- 脉脉为了促进用户间的交流,保障业务成单率的提升,需要让每位用户拥有大量的好友,事实上职场新人不具有更多的职场好友,如何快速为用户积累更多的好友?[共同好友]
- 新浪微博为了增加用户热度,提高用户留存性,需要微博用户在关注更多的人,以此获得更多的信息或热门话题,如何提高用户关注他人的总量?[他关注了哪些人?哪些人关注了他?]
- QQ新用户入网年龄越来越低,这些用户的朋友圈交际圈非常小,往往集中在一所学校甚至一个班级中,如何帮助用户快速积累好友用户带来更多的活跃度?[共同好友]
- 微信公众号是微信信息流通的渠道之一,增加用户关注的公众号成为提高用户活跃度的一种方式,如何帮助用户积累更多关注的公众号?[xx位朋友关注——共同关注]
- 美团外卖为了提升成单量,必须帮助用户挖掘美食需求,如何推荐给用户最适合自己的美食?[美食共性]
解决方案
- 求两个集合的交、并、差集
sinter key1 [key2]
sunion key1 [key2]
sdiff key1 [key2]

- 求两个集合的交、并、差集并存储到指定集合中
sinterstore destination key1 [key2]
sunionstore destination key1 [key2]
sdiffstore destination key1 [key2]

- 将指定数据从原始集合中移动到目标集合中
smove source destination member
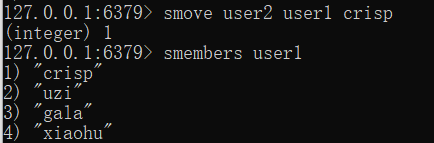


集合关系:

Tips :
- redis 应用于同类信息的关联搜索,一、二度关联搜索,深度关联搜索
- 显示共同关注(一度)
- 显示共同好友(一度)
- 由用户A出发,获取到好友用户B的好友信息列表(一度)
- 由用户A出发,获取到好友用户B的购物清单列表(二度)
- 由用户A出发,获取到好友用户B的游戏充值列表(二度)
业务场景三
集团公司共具有12000名员工,内部OA系统中具有700多个角色,3000多个业务操作,23000多种数据,每位员工具有一个或多个角色,如何快速进行业务操作的权限校验?

说明:绿色框框——业务操作;黄色框框——数据访问权限
解决方案
- 依赖set集合数据不重复的特征[将一个人对应的所有操作放到一个set集合中],依赖set集合hash存储结构特征完成数据过滤与快速查询
- 根据用户id获取用户所有角色
- 根据用户所有角色获取用户所有操作权限放入set集合
- 根据用户所有角色获取用户所有数据全选放入set集合

uid为007的用户同时拥有着rid:001和rid:002两种角色和
smembers和sismember两种校验方式的区别: - smembers:数据存储方提供数据,然后将校验的业务操作交给程序的service层来处理[耦合度低,推荐!]
- sismember:直接在数据存储方进行校验,返回一个结果[耦合度高]将业务校验操作留在了数据存储方处理[不推荐]
牢记:数据是数据,业务是业务
Redis提供基础数据还是提供校验结果?答:提供基础数据,不要融合!
Tips:
- Redis应用于同类型不重复数据的合并操作
业务场景四
公司对旗下新的网站做推广,衡量网站的三类指标:统计网站的PV(访问量),UV(独立访客),IP(独立IP)。
PV:网站被访问次数,可通过刷新页面提高访问量
UV:网站被不同用户访问的次数,可通过cookie统计访问量,相同用户切换IP地址,UV不变(用户量)
IP:网站被不同IP地址访问的总次数,可通过IP地址统计访问量,相同IP不同用户访问,IP不变
解决方案
- 利用set集合的数据去重特征(对重复的数据进行过滤),记录各种访问数据
- 建立string类型数据,利用 incr 统计日访问量(PV)
- 建立set模型,记录不同cookie数量(UV)
- 建立set模型,记录不同IP数量(IP)
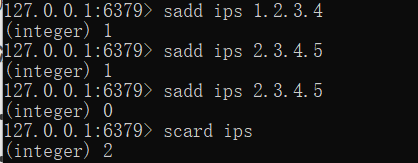
对于cookie也是一样的操作
Tips :
- Redis 应用于同类型数据的快速去重
业务场景五
**黑名单:**开放性但会过滤
资讯类信息类网站追求高访问量,但是由于其信息的价值,往往容易被不法分子利用,通过爬虫技术,快速获取信息,个别特种行业网站信息通过爬虫获取分析后,可以转换成商业机密进行出售。例如第三方火车票、机票、酒店刷票代购软件,电商刷评论、刷好评。
同时爬虫带来的伪流量也会给经营者带来错觉,产生错误的决策,有效避免网站被爬虫反复爬取成为每个网站都要考虑的基本问题。在基于技术层面区分出爬虫用户后,需要将此类用户进行有效的屏蔽,这就是黑名单的典型应用。
ps:不是说爬虫一定做摧毁性的工作,有些小型网站需要爬虫为其带来一些流量。
白名单:限定性
对于安全性更高的应用访问,仅仅靠黑名单是不能解决安全问题的,此时需要设定可访问的用户群体,依赖白名单做更为苛刻的访问验证。
解决方案
- 基于经营战略设定问题用户发现、鉴别规则——被列入黑名单
- 周期性更新满足规则的用户黑名单,加入set集合
- 用户行为信息达到后与黑名单进行比对,确认行为去向
- 黑名单过滤IP地址:应用于开放游客访问权限的信息源
- 黑名单过滤设备信息:应用于限定访问设备的信息源[识别设备]本人手机在宿舍一连校园网路由器就会报红(T=T)
- 黑名单过滤用户:应用于基于访问权限的信息源
具体操作的原理与业务场景四一样
Tips:
- Redis 应用于基于黑名单与白名单设定的服务控制
四、set 类型数据操作的注意事项
- set 类型不允许数据重复,如果添加的数据在 set 中已经存在,将只保留一份(重复会报错)
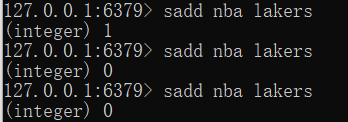
- set 虽然与hash的存储结构相同,但是无法启用hash中存储值(value)的空间[不让用!]
















 5648
5648











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









