







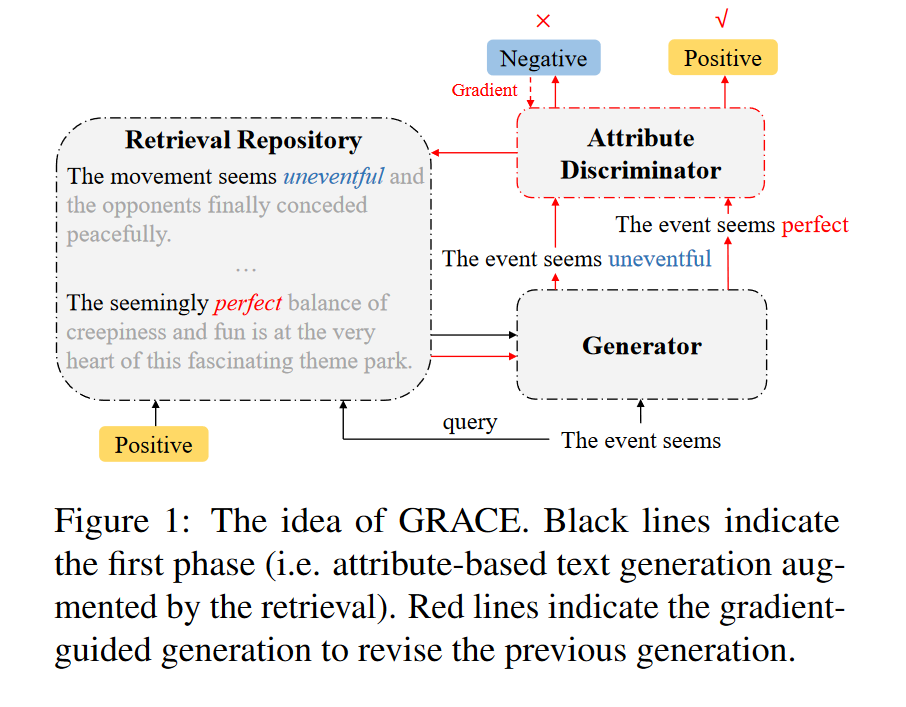
在本文中,我们提出通过梯度引导的可控检索(GRACE)来增强基于属性的生成,考虑到目标属性(见图1)。具体来说,我们训练一个鉴别器来计算给定上下文的属性分布。我们构建了一个检索库,存储了从未标注数据中提炼出的自然文本及其语义和属性信息。生成模型通过可控检索提取具有相似语义的与属性相关的信息。我们设计策略来从检索结果中分离无关属性,并将预训练语言模型(PLM)表示融入生成过程中。此外,我们提出了一个算法,该算法基于梯度迭代修正逐步生成。通过优化目标属性,算法检索出具有更强烈属性强度的信息,从而提高生成文本的属性相关性。
主要工作
(1) 我们提出了一种基于属性的生成框架,该框架利用具有可控检索的未标记语料库。
(2) 我们设计了一种梯度引导生成算法,该算法迭代地引导检索以合适的属性生成。
(3) 我们的方法在属性可控性和流畅性方面超越了情感和主题控制生成的强大基线。
方法
模型架构
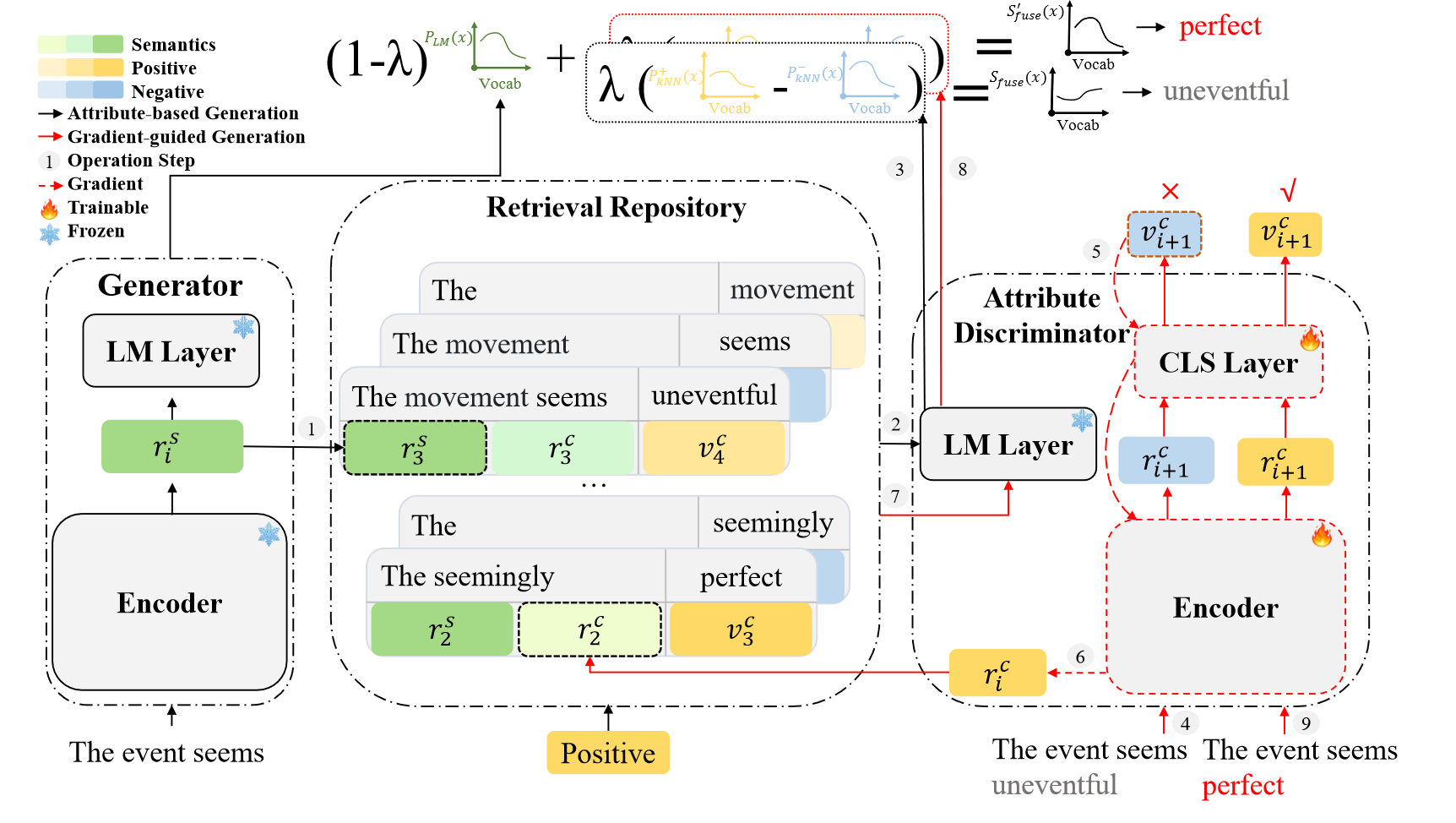
图 2:GRACE 的架构。操作步骤演示了以积极情绪为目标属性的基于属性的生成的第 i 步。给定前缀“事件似乎”,GRACE 生成“uneventful”(步骤 1 到 3),更新梯度引导生成的上下文表示(步骤 4 到 8),并接受“perfect”作为所需输出(步骤 9) 。
我们的框架包含三个部分(见图2):(1) 属性鉴别器通过一个鉴别器 D D D进行属性分类,以评估给定上下文是否满足目标属性。 (2) 检索库构建了一个带有未标注语料库的库 R R R,该库携带了上下文 X n X_n Xn到其下一个词 x n + 1 x_{n+1} xn+1的映射。 R R R支持读取操作,以提供与查询语义相似且与目标属性相关的信息。 (3) 生成器基于前缀和预训练语言模型 G G G生成句子。在每一步, G G G从 R R R检索(读取)信息,减少特定领域词汇的影响,并将其融入神经网络模型中以生成下一个词。
上述模块协作进行基于属性的生成。我们设计了一个梯度引导的检索生成框架,该框架在每一步引导生成朝向目标属性,并完善梯度引导的检索文本,其中梯度尊重目标属性。
属性鉴别器
D D D 由上下文编码器、分类层和语言建模层组成。编码器将文本传输为上下文表示。分类层将上下文表示映射到属性向量,该属性向量可用于通过附加的 s o f t m a x softmax softmax 层进行属性分类。语言建模层将上下文表示映射到单词概率分布。我们使用编码器和分类层执行分类。为了获得 D D D,我们使用预训练的语言模型初始化编码器和语言建模层。然后,我们在分类数据集上微调编码器和分类层。
检索储存库
存储库建立
在本节中,我们将讨论如何构建检索库。我们在未标注的语料库上构建了一个检索库R,这个库是利用我们的判别器D和生成器G生成的。该库包含了许多项,每一项都包含三个向量 ( r s , r c , v c ) (r^s, r^c, v^c) (rs,rc,vc),分别代表语义、属性增强的语义以及给定上下文的属性分布。
对于一个句子 X n = { x 1 , x 2 , … , x n } X_n = \{x_1, x_2, \ldots, x_n\} Xn={x1,x2,…,xn},我们定义其任意子序列为 X i = { x 1 , x 2 , … , x i } X_i = \{x_1, x_2, \ldots, x_i\} Xi={x1,x2,…,xi} 对任意的 i ≤ n i \leq n i≤n。为了构建库 R R R,对语料库中每个句子的每个子序列 X i X_i Xi,我们采取以下步骤:
- G是一个固定的预训练语言模型(PLM),我们通过 G G G中的文本编码器计算 X i X_i Xi 的上下文表示 r s r^s rs ;
- 我们将 X i X_i Xi 喂给 D D D的编码器以获得其属性增强的上下文表示 r c r^c rc;
- 我们将 X i + 1 X_{i+1} Xi+1 喂给 D D D的编码器然后是分类层,以获得其属性向量 v c v^c vc。最终,我们将 ( r s , r c , v c (r^s, r^c, v^c (rs,rc,vc)定义为 X i X_i Xi 的库项(请参见图2中的库项)。注意, v c v^c vc 衡量的是考虑当前子序列的下一个词的属性分布。
储存库检索
可控检索找到与查询相似且与目标属性相关的仓库项。为了检索给定的查询文本,我们将上下文提供给生成器G,以获得文本表示 r s r^s rs。接着,我们搜索与查询的 r s r^s rs高度相似的项,从仓库中检索出前文提到的 r s r^s rs。进一步,我们检索两组具有高属性相关性的项作为检索结果。
P k N N ( x i + 1 ∣ c , X i ) ∝ P k N N ( x i + 1 ∣ X i ) ⋅ P ( c ∣ X i , x i + 1 ) (1) P_{kNN}(x_{i+1}|c, X_i) \propto P_{kNN}(x_{i+1}|X_i) \cdot P(c|X_i, x_{i+1}) \tag{1} PkNN(xi+1∣c,Xi)∝PkNN(xi+1∣Xi)⋅P(c∣Xi,xi+1)(1)
检索的理念遵循公式1中受Krause et al.(2021)启发的启发式。在检索结果中,更高的 P k N N ( x i + 1 ∣ c , X i ) P_{kNN}(x_{i+1}|c, X_i) PkNN(xi+1∣c,Xi)指示(1)下一个词 x i + 1 x_{i+1} xi+1与子序列 X i X_i Xi之间更好的语义连贯性,以及(2)与属性c更高的属性相关性。我们设计了以下策略来对这两个概率进行建模:
• 语义检索。为了提高 P k N N ( x i + 1 ∣ X i ) P_{kNN}(x_{i+1}|X_i) PkNN(xi+1∣Xi),我们搜索与上下文 X i X_i Xi在语义上相似的项。如图2的第一步,我们取 X i X_i Xi的上下文表示 r X i s r^s_{X_i} rXis作为输入。我们根据存储项的上下文表示 r s r^s rs和 r X i s r^s_{X_i} rXis之间的相似度,搜索仓库中的K个最近项。该算法返回一组 N \mathcal{N} N,它提供辅助语义信息以促进下一个词的预测(Khandelwal等,2020)。
• 属性检索。我们选择了两个高度属性相关的子集以增加 P ( c ∣ X i , x i + 1 ) P(c|X_i, x_{i+1}) P(c∣Xi,xi+1)。首先,我们从 N \mathcal{N} N中选择项来组成一个子集 N + \mathcal{N}^+ N+,其中项的属性向量 v c v^c vc与目标属性c之间的相似度超过了一个阈值p。这个相似度是项的属性向量 v c v^c vc与c的独热表示之间的余弦相似度。 v c v^c vc衡量了考虑下一个子序列词的属性分布。因此,我们通过考虑下一步生成偏好来增加c的可能性。我们用 ¬ c \neg c ¬c表示反目标属性,并按照上述程序考虑 ¬ c \neg c ¬c得到 N − \mathcal{N}^- N−。(以下章节3.3.1使用 N − \mathcal{N}^- N−来消除检索信息中的领域偏见)。通过这种方式,我们获得了属性与目标属性最相关的项。
最终,检索操作返回 N + \mathcal{N}^+ N+和 N − \mathcal{N}^- N−。这两个集合包含了与目标属性和非目标属性高度相关的项。注意, N + \mathcal{N}^+ N+和 N − \mathcal{N}^- N−中的上下文表示在语义上与当前子序列一致。
生成器
生成器 G 根据给定前缀生成文本并考虑目标属性。在每个生成步骤中,G 从 R 中检索,从检索结果中删除不相关的域偏差,并将它们集成到生成模型中以生成下一个标记。
表示去偏
我们解决了从检索到的信息中产生的领域偏差,并旨在消除生成序列中的领域特定信息。我们将这个处理称为“去偏”。在大多数现有的基于属性的生成方法中,领域偏差存在于生成文本中,其属性与文本领域相冲突,因为基于属性的训练语料通常来自有限的一组领域(Yu等人,2021)。
在第i步生成时,G编码当前子序列以查询仓库R,以获得两组项: N + \mathcal{N}^+ N+和 N − \mathcal{N}^- N−。之后,我们将每组中的属性增强的上下文表示 r c r^c rc输入到D的语言模型层以获得下一个词的概率分布。然后,我们平均每个集合中的值,并获得 P k N N + ( x i + 1 ∣ c , X i ) P^+_{kNN}(x_{i+1}|c, X_i) PkNN+(xi+1∣c,Xi)和 P k N N − ( x i + 1 ∣ ¬ c , X i ) P^-_{kNN}(x_{i+1}|\neg c, X_i) PkNN−(xi+1∣¬c,Xi)对 N + \mathcal{N}^+ N+和 N − \mathcal{N}^- N−。最后,我们计算它们的差异,以得到 Δ P ( x i + 1 ∣ c , X i ) = P k N N + ( x i + 1 ∣ c , X i ) − P k N N − ( x i + 1 ∣ ¬ c , X i ) \Delta P(x_{i+1}|c, X_i) = P^+_{kNN}(x_{i+1}|c, X_i) - P^-_{kNN}(x_{i+1}|\neg c, X_i) ΔP(xi+1∣c,Xi)=PkNN+(xi+1∣c,Xi)−PkNN−(xi+1∣¬c,Xi)。
直觉是,当检索库在领域特定表达上丰富时,单独c的检索结果可能会产生许多不一定与所需属性相关的领域特定语言模式。然而,如果一个词在同时检索c和 ¬ c \neg c ¬c时都有高概率,那么这个词很可能对领域而不是目标属性c至关重要。如果 P k N N + ( x i + 1 ∣ c , X i ) P^+_{kNN}(x_{i+1}|c, X_i) PkNN+(xi+1∣c,Xi)较高,而 P k N N − ( x i + 1 ∣ ¬ c , X i ) P^-_{kNN}(x_{i+1}|\neg c, X_i) PkNN−(xi+1∣¬c,Xi)相对较低,这表明 x i + 1 x_{i+1} xi+1对领域不重要,但对目标属性至关重要。因此,上述操作消除了 X i X_i Xi的语义相似邻居中来自R仓库语料的领域偏差。
表示整合
我们设计了一个策略来整合去偏信息到PLM的概率中,以产生下一个词。直觉上,如果一个词与给定上下文一致并且与目标属性密切相关,则该词是理想的。我们将PLM在G中的词概率表示为 P L M ( x i + 1 ∣ X i ) P_{LM}(x_{i+1}|X_i) PLM(xi+1∣Xi),并将其整合如下:
S f u s e ( x i + 1 , c , X i ) = λ Δ P ( x i + 1 ∣ c , X i ) + ( 1 − λ ) ∗ P L M ( x i + 1 ∣ X i ) (2) S_{fuse}(x_{i+1}, c, X_i) = \lambda \Delta P(x_{i+1}|c, X_i) + (1 - \lambda) * P_{LM}(x_{i+1}|X_i) \tag{2} Sfuse(xi+1,c,Xi)=λΔP(xi+1∣c,Xi)+(1−λ)∗PLM(xi+1∣Xi)(2)
在公式2中, λ \lambda λ是一个衡量在预测下一个词时目标属性c的可控性的因子。我们考虑 λ ( i ) \lambda(i) λ(i)作为一个与步骤i线性递减的控制信号:
λ ( i ) = { λ m i n − λ 0 I ∗ i + λ 0 i ≤ I λ m i n i > I \lambda(i) = \begin{cases} \frac{\lambda_{min} - \lambda_0}{I} * i + \lambda_0 & i \leq I \\ \lambda_{min} & i > I \end{cases} λ(i)={Iλmin−λ0∗i+λ0λmini≤Ii>I
其中 λ 0 \lambda_0 λ0是在第0步时的初始比率, λ m i n \lambda_{min} λmin是最小比率,I是一个预定义的步骤数。在固定的 λ 0 \lambda_0 λ0和 λ m i n \lambda_{min} λmin下,一个较大的I允许更多步骤获得更高的可控性。
整合之后,我们对得分进行归一化,并使用现有的解码策略(例如,top-k抽样)来生成下一个词。
梯度引导的生成
我们提出了一种梯度引导的生成方法,以引导生成过程朝向目标属性。我们在每一步迭代评估当前子序列,并对其进行修订,直到其属性变得令人满意。
• 子序列评估。我们评估当前子序列是否满足目标属性。我们将在第i步生成的词 x i + 1 x_{i+1} xi+1与当前子序列 X i X_i Xi拼接,得到 X i + 1 X_{i+1} Xi+1。然后,我们将 X i + 1 X_{i+1} Xi+1输入到判别器D中,确定它是否与目标属性匹配(见3.1节)。如果它满足目标属性,我们接受 X i + 1 X_{i+1} Xi+1进入下一个生成步骤。否则,我们保存D的编码器和分类层的梯度 Δ Θ \Delta\Theta ΔΘ来帮助更新 X i + 1 X_{i+1} Xi+1。
• 梯度引导的子序列更新。我们增强子序列与目标属性的相关性,以帮助生成具有更强属性强度的词。我们优化D的编码器和分类层,根据 Δ Θ \Delta\Theta ΔΘ获得 D Θ − Δ Θ D\Theta-\Delta\Theta DΘ−ΔΘ。我们将 X i X_i Xi输入到 D Θ − Δ Θ D\Theta-\Delta\Theta DΘ−ΔΘ的编码器中,获得更新后的属性增强的上下文表示 r i ′ c r'^c_i ri′c。此外,基于 r i ′ c r'^c_i ri′c,我们采用3.2.2节的检索步骤和上述模块中介绍的3.3节的生成步骤,获得新的检索结果,并生成一个新词 x i + 1 ′ x'_{i+1} xi+1′。到目前为止,我们已经完成了一次梯度引导生成的迭代。
当 D Θ − Δ Θ D\Theta-\Delta\Theta DΘ−ΔΘ被优化以朝向目标属性时,其编码器产生的上下文表示包含更丰富的与属性相关的信息,这有助于检索与目标属性匹配的文本。因此, r i ′ c r'^c_i ri′c在检索时与与目标属性更相关的项匹配,进而帮助生成下一个与期望属性更相关的词 x i + 1 ′ x'_{i+1} xi+1′。
在我们的框架中,我们首先训练判别器D(见3.1节)并建立检索仓库R(见3.2.1节)。在第i步生成时,我们遵循3.2.2节的检索步骤,并使用G生成一个新词(见3.3节)。之后,梯度引导的生成(见3.4节)通过迭代优化生成结果,这需要调用检索(见3.2.2节)和生成(见3.3节),直到满足属性要求。
















 4566
4566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











