






摘要
由于缺陷程序的修复成本较高,自动程序修复(APR)成为研究的热点。近年来,APR的新趋势是应用神经网络自动挖掘缺陷程序与相应补丁之间的关系,称为神经程序修复(NPR)。然而,社区忽略了一些可能影响NPR系统适用性的重要属性,例如健壮性[存在的问题]。对于语义相同的缺陷程序,NPR系统可能会产生完全不同的补丁。本文提出了一个称为RobustNPR的评估工具,这是第一个NPR鲁棒性评估工具[创新点]。RobustNPR使用几个突变器来生成有缺陷程序的语义相同的突变体。对于原始有缺陷的程序及其突变体,它检查NPR的两个方面:(A)当NPR可以修复原始有缺陷的程序时,它是否可以修复突变体?以及(B)NPR能否为原始程序和变体生成语义相同的补丁?[研究内容和研究方法] 然后,我们对四个SOTA NPR模型进行了评估,并对结果进行了分析。结果发现,即使是性能最好的模型,也有20.16%的修复成功率是不可靠的,这说明NPR的稳健性并不是完美的。此外,我们还发现,NPR的稳健性与模型设置等因素有关。
关键词
模型评估;神经程序修复;鲁棒性
1 引言
近年来,自动程序修复(APR)已经显示出节省开发人员时间和精力的潜力。传统的生成和验证 (G&V) APR技术依赖于软件分析技术,这些技术可以概括为基于启发式、基于约束和基于模板。随着深度学习的出现,研究人员最近将各种深度学习技术集成到APR方法中,即神经程序修复(NPR)。NPR方法能够自动从缺陷程序和相应的补丁中挖掘修复模板,这是以前的APR方法难以实现的。最新的研究表明,一些NPR技术在建立良好的基准(例如Defects4J)内正确修复缺陷方面的表现优于传统技术。然而,我们观察到,NPR技术的一个重要角度被社会忽视了,即NPR的鲁棒性。
随着计算能力的提高和大数据的积累,深度学习逐渐发展成为数据驱动研究的主要框架。然而,尽管深度学习在许多领域得到了广泛的应用,但深度学习仍有一些基本属性需要研究。特别是深度神经网络在面对扰动时的鲁棒性。近年来,许多研究人员在计算机视觉(CV)、自然语言处理(NLP) 等领域对深度学习模型的鲁棒性进行了广泛的研究。然而,就我们所知,还没有研究人员对NPR进行强有力的研究。我们认为,大规模鲁棒性评估的一个重要挑战是相关基准的不足(例如,广泛使用的基准Defects4J只有835个样本)。为了应对这一挑战,我们引入了大量没有可执行测试的数据,这些数据可以用来以各种方式表示不同的缺陷,我们将其命名为多样性数据。
本文提出了一个名为RobustNPR的工具来评估NPR模型的鲁棒性。我们认为,如果一个NPR模型是健壮的,它需要具有两个能力:(A)对于可以成功修复的缺陷程序,它的语义相同的突变体也可以被修复;(B)对于一个缺陷程序及其突变体,NPR模型输出的语义应该是相同的 [评估标准]。为了实现这一点,用两种方法对模型的鲁棒性进行了评估,实现了RobustNPR。第一种方法被称为多样性,它是基于NPR评估中的字符串相同法。字符串相同测试是NPR任务中的一种常见做法。字符串相同认为一个补丁在补丁与人类修复完全匹配的情况下是正确的。我们用语义相同的变异器对测试集成功修复的部分进行突变,然后将它们送入相同的NPR模型,看看它们是否仍然被成功修复。第二种方法称为行为,它基于程序的行为。我们用语义相同的变异算子对测试集进行变异,将它们输入到NPR模型中得到输出,然后测试模型为原始样本和突变体生成的补丁是否语义相同。基于这两种方法,我们有能力评估NPR的鲁棒性。此外,我们还定义了四个度量来量化NPR的鲁棒性,即PFM、PFA、PDM和PDA。
我们使用RobustNPR对四个SOTA模型进行了评估,包括Recoder、CoCoNut、SequenceR和Tufano。我们的结果表明,现有的NPR模型容易受到语义相同突变的影响。换句话说,突变会导致NPR模型无法修复原本可以修复的缺陷,或者会导致NPR模型失去坚实的代码语义转换能力。在我们的实验中,SequenceR在所有四个指标上都取得了最好的结果。在多样性实验中,即使是最好的模型(SequenceR),本可以成功修复的样本中,超过20%的样本在扰动后无法成功修复。在行为实验中,在原始样本和突变体之间,性能最好的模型(SequenceR)生成的样本有28.85%,性能最差的模型(Tufano)生成的补丁有48.40%的语义不一致。此外,我们的结果表明,不同的设置在不同程度上影响了NPR模型的鲁棒性。例如,对抽象语法树(AST)有影响的变异器将对Recoder的鲁棒性产生很大影响,因为Recoder是一个基于树的模型。因此,结果表明,NPR模型的稳健性与实际应用相差甚远。研究人员在设计自己的NPR模型时,应该更多地关注NPR模型的鲁棒性,而不是简单地追求修复的有效性。
本文的主要贡献如下[创新点]:
-
- 我们提出了新的度量标准来度量NPR系统的鲁棒性,并设计了一种量化NPR系统鲁棒性的方法——RobustNPR。我们的工具由几个新的语义相同的变异器组成,它们支持突变缺陷代码来度量NPR系统的鲁棒性。这些突变算子可用于NPR的后续研究和源代码相关研究。
- 我们对四个SOTA NPR系统的鲁棒性进行了实证测量。我们的实验表明,尽管提高了可修复性,但最新的NPR系统都存在鲁棒性问题。此外,我们还进一步探讨了低鲁棒性的潜在原因。例如,我们发现代码表示方法会影响对变量重命名等突变的鲁棒性。我们相信,我们的发现可以促进更强大的NPR系统的发展。
2 背景和动机
2.1 NPR
通常,NPR系统将APR任务框架为缺陷代码到正确代码的翻译。为了实现这一点,他们采用了一种被广泛应用于机器翻译(MT)任务的DNN(深度神经网络)模型,称为神经机器翻译(NMT)模型。作为一种基于学习的方法,NPR工具需要对大量的缺陷修复对进行训练。在训练期间,NPR工具的目标是适应一个概率函数,该函数描述了当给定缺陷程序时潜在补丁的概率。
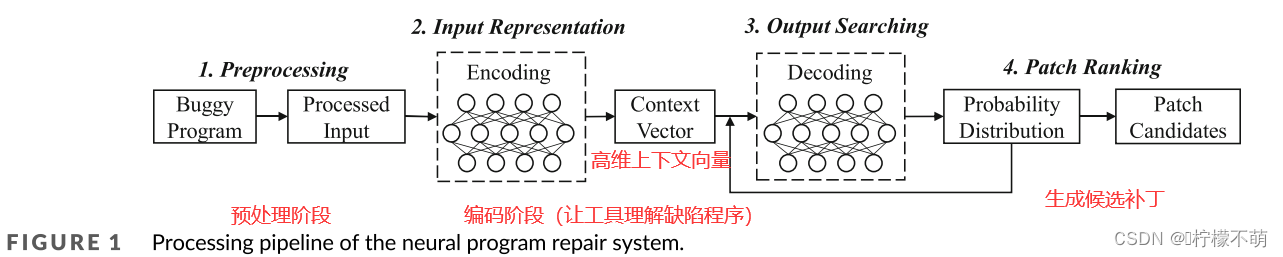
NPR系统如何生成补丁的整个过程如图1所示。如先前研究总结的那样,该过程可分为四个阶段。首先,在预处理阶段,需要将缺陷程序处理成神经网络可以接受的形式。该形式取决于神经模块的体系结构(例如,SequenceR中的顺序代码tokens)。然后,在编码阶段,编码器接收处理后的输入,并将其编码成高维上下文向量。这个阶段的目标是让工具理解缺陷程序。最后,在补丁排序阶段,解码器分多步生成候选补丁。在每个步骤,解码器计算token词汇上的概率分布,并输出按概率排序的token。解码器不断地生成token,直到到达结束符号。
2.2 深度学习的鲁棒性
得益于计算能力的快速发展,深度学习已经与计算机视觉CV、自然语言处理NLP等技术相结合,并广泛应用于机器翻译MT、游戏、甚至自动驾驶等生命关键系统中。尽管深度学习在解决复杂问题方面表现出了有效性,但它们仅限于鲁棒性要求较低的系统,难以应用于鲁棒性要求较高的场景。这是因为,在很大程度上,神经网络模型被视为缺乏可解释性的黑匣子,因此很难从理论上证明它们的行为。
为了解决这一问题,研究者们对深度学习的鲁棒性进行了广泛的研究。Szegedy等人首先发现了深度学习中存在的鲁棒性问题。他们发现,通过施加某种不可察觉的扰动,神经网络会错误地对图像进行分类。Tian等人探索了图像分类模型是否使用与给定图像中的目标对象无关的特征进行不适当的推断。Yefet等人和Henkel等人表明,源代码模型容易受到对抗示例的攻击,并旨在提高代码模型的鲁棒性。与以往的文献相比,我们的工作主要集中在从未研究过的NPR模型的鲁棒性上。我们还考察了不同模型设置对鲁棒性的影响,并对其进行了分析。
2.3 蜕变测试
蜕变测试是一种在没有oracle(指预期结果不知道)的情况下测试程序的特定方法。该方法依赖于从程序中提取的特定蜕变关系来发现程序中的错误,并分析程序的鲁棒性。例如,假设我们有一个计算正弦函数的程序。众所周知,正弦函数的性质为sinx=sin(180°-x)。我们将这一性质称为蜕变关系。基于这种蜕变关系,我们可以得到一系列的输入对,如 (35°,145°) 。如果程序的运行结果显示sin35°≠sin145°,则可以得出两个结论:程序中存在错误和程序存在鲁棒性问题。
蜕变测试已经被认为是一种适合深度学习模型的鲁棒性问题的测试方法。例如,Tian et al设计并实现了DeepTest,用于测试基于DNN的自动驾驶系统。它们的蜕变关系是,汽车的转向角不应该随着天气或照明条件的变化而发生显著变化。DeepTest在三个性能最好的基于DNN的自动驾驶系统中发现了数千种错误行为。在RobustNPR的行为方法中,我们设计了一种基于程序行为的蜕变关系。
2.4 术语
这一部分解释了本文中使用的术语。
语义相同:我们将语义相同定义为以下公式:
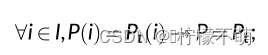
这里,I指的是程序的输入域,P(i)指的是具有输入i的程序行为。这个公式的意思是,对于输入域中的任何输入,如果程序P和Pt的行为一致,我们定义它们是语义相同的。
鲁棒性:我们将NPR工具的鲁棒性定义为在语义相同的对抗突变下保持输出语义相同的能力。例如,如果我们有一个缺陷程序P和它的语义相同的突变体Pt,我们将它们送入相同的NPR模型并得到输出。两个输出的语义应该相同。
2.5 引例
我们使用SequenceR来说明我们的激励示例。SequenceR是一个很棒的NPR工具,被引用次数很高(截至2022年7月,接近200次),它使用Seq2Seq模型来修复指定的缺陷行。
图2A显示了Defects4J基准测试中的缺陷JacksonCore-5的缺陷方法。此方法的目的是将数字字符串解析为int类型变量,而for循环的目的是遍历字符串并检查字符串中是否有非数字字符,因此语句char c=str.charAt(i++);中的++运算符是多余的。修复该缺陷的方法是删除++运算符。图2B是与左侧的版本具有完全相同的语义的版本。它们之间的区别是,在右侧的字符串变量str中添加了一个无用的类型转换((String)str)。

可以看出,SequenceR成功修复了左侧有缺陷的代码;但是,当修复右侧与左侧语义一致的代码时,模型会产生明显的错误。语句char c=0;显然不是具有原始语义的正确代码。这表明,当出现一些扰动时,SequenceR很难应对它们。如果NPR工具不具有鲁棒性,用户对NPR工具缺乏信任,NPR工具就不会在实际应用场景中使用。如果NPR工具要在重要领域有用,提高鲁棒性是必要的,因此我们首先需要能够评估NPR工具的鲁棒性。
3 方法
3.1 概述
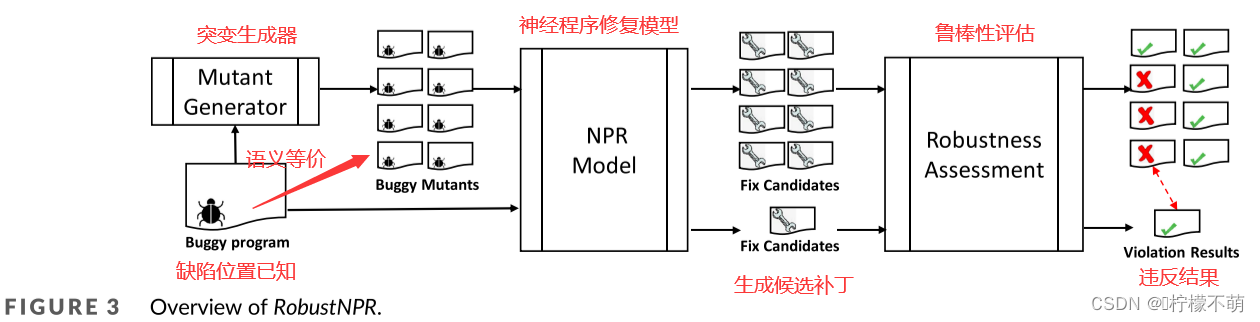
在这一部分中,我们介绍了RobustNPR的设计和实现。我们首先说明RobustNPR的概述,如图3所示。RobustNPR的目标是评估NPR模型的鲁棒性。为了实现这一点,我们设计了三个主要模块,包括突变生成器(第3.2节)、NPR模型(第3.3节)和鲁棒性评估(第3.4节)。输入包括一组具有完美定位的缺陷程序,完美定位是NPR任务中的常见做法,意味着提供了缺陷的位置。对于每个缺陷程序,突变生成器生成一组在语义上与原始缺陷程序等价的突变体。我们通过设计一组基于语法的规则来实现这一点,该规则基于一个名为JavaParser的Java库。在此之后,我们使用NPR模型来生成缺陷程序和突变体的补丁。最后,模块鲁棒性评估是评估NPR模型在面对突变时是否足够健壮。对于那些没有可执行测试的缺陷程序,我们将正式补丁与NPR模型为缺陷程序的突变体生成的修复候选进行字符串比较。对于那些带有可执行测试的缺陷程序,我们直接在这些突变体的修复候选上重新执行这些测试。之后,我们可以通过观察修复候选验证的违反情况来定量评估NPR模型的鲁棒性。然后,我们详细地说明了RobustNPR的设计和实现。
3.2 突变生成器
主流的NPR针对的是方法级别的缺陷代码,因此我们为方法级别的代码定义了以下语义相同的变异器†。
变量重命名(VR):选择方法中的变量或参数并对其进行重命名。Java中的大多数类名使用驼峰大小写或蛇形大小写来组合单词,新的名称将通过解析其类名来确定。我们使用三种常见的Java变量命名方法来获得新的变量名,它们是获取第一个单词的第一个字母,获取每个单词的第一个字母,并将类名的第一个字母更改为小写。例如,类SimpleName的变量将被命名为s,而sn将被命名为SimpleName。当然,新的变量名不应该在其作用域内使用。VR是评估代码相关任务的一种常见做法。
-
- 改变了AST终端节点的值
无用类型转换(UC):接受变量引用并向其添加自己类型的类型转换。例如,类字符串的变量str将更改为((字符串)str)。
-
- 引入新节点和新规则
未使用的变量(UV):插入未使用的变量声明,变量名不应在其作用域中使用。我们在Rabin等人的工作基础上设计了变异器。然而,他们只使用字符串变量。与它们不同,我们使用字符串、整型、布尔型、字符、浮点型等。我们使用随机方法来确定使用哪种类型的变量。例如,如果我们随机选择INT,我们将在程序中的随机位置插入语句int unusedInt=0;(必须符合Java语法)。
-
- 引入新的子树
新变量(New Variable,NV):获取一个现有变量,在程序中声明一个相同类型的新变量,然后将值赋给原始变量的引用。然后,对原始变量的所有后续引用都将更改为对新变量的引用。新变量的命名方法与VR完全相同。用新变量替换对原始变量的后续引用。图4显示了一个真实的示例,我们声明了一个Calendar类型的变量Calendar,将其初始化为对原始变量c的引用,并将对原始变量c的后续引用修改为变量Calender。特别要注意声明新变量的位置。新变量应在原始变量之后声明,新变量声明后的代码应包含对该变量的引用。在符合条件的位置中,我们采用随机的方法确定最终的位置。与VR不同的是,NV赋值函数向函数添加了一个新的声明,并在方法中引用了这两个变量。
-
- 引入新的子树,并改变一些终端节点的值

在四个突变子中,VR和UV是借鉴前人的工作。 UC和NV是我们独立设计的。
3.3 评估中的主题
我们选择了四个具有代表性的NPR工具,包括Tufano、CoCoNut、SequenceR和Recoder。这四个工具的模型输入都是方法,但在数据处理方面存在差异。
Tufano使用基于RNN的神经机器翻译架构来修复缺陷。在数据处理阶段,为了减少识别符和文字对语义的影响,Tufano对输入法字符串进行抽象操作。抽象操作是用唯一的ID替换不常见的识别符和文字。例如,第一个方法的ID是METHOD_1,第X个变量的ID是VAR_X。这种方法可以压缩模型的解空间,并获得更高的精度。Tufano的输入和输出都是抽象的整体方法。
CoCoNut使用卷积神经网络(CNN)来编码输入和生成输出,它通过独立于上下文对它们进行编码来专注于错误的部分。此外,CoCoNut使用集成学习方法来训练具有随机超参数的多个模型,然后将它们组合在一起。该方法可以从不同的维度捕捉缺陷代码和干净代码之间的关系,从而获得更好的修复效果。在数据处理阶段,为了减少词汇量,CoCoNut采取了两个步骤:将数字和字符串抽象为特殊的tokens,并使用Camel-Case、Snake-Case等将标识符解析为token序列。CoCoNut的输入有两个部分,缺陷行及其上下文,输出是修复行。
SequenceR使用复制机制训练序列到序列的神经模型来修复缺陷,在数据处理阶段,SequenceR只保留类中其他方法的签名。SequenceR在缺陷行前后插入特殊token,以指示缺陷的位置。SequenceR的输入是完整的缺陷方法,指示缺陷行和其他方法的签名。SequenceR的输出是修复的行。
Recoder提出了一种具有新型提供者/决策器体系结构的语法制导解码器。在数据处理阶段,Recoder生成(1)AST遍历序列,(2)标签嵌入,(3)缺陷方法生成基于AST的图作为模型输入。Recoder生成AST的一系列编辑并应用它们来生成修复的方法。Recoder的输入是指示缺陷行的方法,输出是修复的方法。
这四种模式各有特点。Tufano和SequenceR的结构相对简单,都是基于RNN的Seq2Seq模型。然而,Tufano的输入和输出是整个方法,而SequenceR更关注的是缺陷行。CoCoNut也关注缺陷行。此外,CoCoNut使用了CNN模型和集成学习,以获得更好的效果。Recoder与以前的模型的不同之处在于,Recoder使用一种特殊的基于树的模型来输出AST编辑。除了这四个NPR工具之外,还有一些有特色的NPR工具,如Cure和Codit,但这些NPR工具都没有完整的可执行代码,所以我们不对它们进行评估。
3.4 鲁棒性评估
在2.4节中,我们定义了语义一致的概念,并在语义一致的基础上进一步定义了NPR的健壮性。然而,根据等式(1),要验证两个程序是否语义相同,我们需要验证它们输入域中的所有输入,这显然是不可能的。因此,我们选择了Defects4J,一个拥有许多好的测试用例的基准测试程序,使用Defects4J的缺陷程序和测试用例作为我们的数据源。由于此方法通过程序的行为是否一致来衡量健壮性,因此我们将此数据集称为行为-数据,称为其对应的方法行为。然而,Defects4J中可用的数据量太小,只有312个函数符合我们的要求,所以为了防止由于数据太少而导致的评估偏差,我们引入了大量的数据,没有可执行的测试。由于这部分数据没有可执行的测试,我们设计了另一种稳健性评估方法。由于这部分数据具有丰富的多样性,我们将此数据集称为多样性数据,相应的方法称为多样性。数据集将在下文和第4.2节中详细说明。
3.4.1 多样性
如果健壮的NPR模型可以成功修复缺陷,那么NPR模型也应该能够修复语义相同的突变。我们基于NPR评估中的字符串等同方法设计了该方法。字符串等同的方法是检查NPR模型输出的候选对象中是否存在与正确修复一致的候选对象。在这里,我们定义函数NPR(M)。为缺陷程序M被馈入NPR模型后获得的所有输出,其中一个输出由c表示。首先,对于缺陷样本M,其正确修复是G。如果NPR模型可以正确修复这个缺陷,那么我们有
![]()
我们将突变体T应用于M,生成突变体Mt。然后,对于NPR(Mt),在我们去掉突变体T对NPR(Mt)的影响,即执行T,T_-1(逆变元)后,我们应该有
![]()
我们根据上述指导方针设计了多样性方法。首先,我们收集一组没有可执行测试的缺陷程序。接下来,我们使用两个语义相同的变异器VR和UC对测试集可以被NPR模型成功修复的部分进行突变。之后,我们将突变体输入到模型中,并得到输出。然后,我们消除了两个突变体对输出的影响。
VR(变量重命名)操作获取方法中的变量,为其生成新的标识符,并将方法中变量的所有旧标识符替换为新的标识符。我们通过用原始标识符替换突变体中的所有新标识符来恢复。
UC(无用类型转换)操作获取方法中的变量引用,检查其类型,并使用自己的类型强制转换引用。我们通过从生成的代码中完全消除该类型强制转换来恢复。
最后,在消除变异因子的影响后,检查输出候选中是否存在与基准一致的代码。
3.4.2 表现/行为
我们认为NPR模型的作用是理解缺陷代码的语义,并将其转换为正确的代码。因此,基于这种理解,我们可以提出一个三段论:
-
- 大前提:该模型理解代码语义,并能将错误的语义代码转换为正确的语义代码。
- 次要前提:代码会被语义相同的变异器改变。
- 结论:模型输出代码应语义一致。
基于上述三段论,我们设计了一种变质关系。对于有缺陷的程序M,我们使用突变器T来产生突变体Mt。它们的NPR模型的输出程序分别是NPR(M)和NPR(Mt)。请注意,在这里,我们只选择排名前1位的候选补丁,因此NPR(M) 和NPR(Mt) 都是两个独立的程序,而不是两个程序的集合。而且,对于M我们有一组输入I,对于I中包含的任何输入i,我们都应该有
![]()
基于上述指导思想,我们设计了方法行为。首先,我们选择具有可执行测试的基准测试Defects4J。从Defects4J中选择一组只需要在一行中修改的有缺陷的方法,并将所有四个语义相同的变异器应用于这些方法。接下来,使用NPR模型来修复原始的缺陷方法M和突变的Mt。然后,使用Defects4J的测试用例对NPR模型修复的方法进行了测试。通过测试,我们可以得到四种程序行为。从测试中我们可以得到四种行为,即编译失败、异常、断言错误和测试成功。对于异常,不同类型的异常和不同位置的异常也被视为不同的行为。对于断言错误,不同的断言值也被视为不同的行为。最后,我们比较了NPR(M) 和NPR(Mt) 的行为,检验他们的行为是否相同。
4 实验设置
4.1 数据集
我们使用自己构建的数据集对模型进行了训练和测试。我们的来源是Tufano等人收集的BFP原始数据,其中包含787,178个Java缺陷修复提交。每条数据都具有元信息,包括存储库、提交信息和提交URL。我们使用以下规则对其进行过滤和分割:
规则1.许多缺陷方法都有多行缺陷代码,但我们的一些模型,如SequenceR,只能接受单行缺陷方法作为输入。公平地说,我们的数据集只接受单行有缺陷的方法。
规则2.许多缺陷都有多个有缺陷的方法。为了确保测试集的质量,我们的测试集只接受只有一个缺陷方法的缺陷。
规则3.为了防止数据泄露,我们划分训练集、验证集和测试集的标准之一是它们的项目不相互重叠。此外,Defects4J也被我们用作评估集,因此与Defects4J相关的项目也不能出现在训练集中。
基于上述规则,我们的最终数据集包含144,641个训练样本、13,739个验证样本和4951个测试样本。每个样本包含以下信息:(1)缺陷行、(2)修复行、(3)整个方法、(4)整个类、(5)缺陷位置 和 (6)元信息。
我们使用并且只使用这个数据集的原因有三个:原因1.在以前的工作中,收集数据集的方法通常是从Github中抓取数据并对其进行过滤。不同研究人员收集的数据在很大程度上是重叠的,因此选择多个数据集没有多大意义。原因2.我们希望数据源质量尽可能高,并包含元信息,只有BFP才能满足这一要求。在其他数据集中,CoCoNut的数据集有很多代码克隆,而Recoder的数据集没有提供元信息。原因3.为了保证数据的质量,我们对260个只包含单行更改缺陷方法的Defects4J缺陷进行了测试,测试结果如表1所示,结果高于或接近作者原始论文中报告的这260个错误的效果。这表明我们的数据具有足够的质量。

4.2 评估设置
我们使用自己设计的基于JavaParser的工具来更改Java代码。生成的数据应该包含突变后的代码的几个部分:(1)缺陷行、(2)完整方法、(3)完整类、(4)缺陷位置、(5)元信息和 (6)修改信息。与数据集不同的是,生成的数据增加了修改信息,没有修复行。为了保证突变器的正确性,我们随机抽取十分之一的数据进行人工检测,结果表明我们的工具是可靠的。
我们使用数据集的测试集部分作为多样性实验的数据源,使用Defects4J作为行为实验的数据源。我们将评价集多样性的这两个部分称为多样性数据和行为数据。
4.2.1 多样性数据
组成。多样性数据的数据源是数据集中的测试集,我们使用VR和UC对测试集进行变异。如表2所示,测试集中有4951个样本,其中756个样本不能突变。对剩余的4195个数据进行突变,产生40,377个突变体,其中25,105个由VR产生,15,272个由UC产生。

4.2.2 行为数据
组成。行为数据的来源是Defects4J。由于4.1节中的规则1,我们从Defects4J中提取了312个单行缺陷方法。值得注意的是,其中一些方法来自同一个缺陷。我们使用所有四个突变体对这些方法进行突变。如表2所示,我们的工具从312个原始样本中总共产生了5540个突变,包括VR 1424、UC 1074、UV 2471和NV 571。

4.3 训练
为了获得更好的训练效果,我们使用随机搜索策略来选择超参数。我们首先使用原始论文中提出的超参数(如果提供)来训练模型。然后,我们对每个可调超参数进行随机搜索,在验证集上选择最好的模型,作为最终的模型进行评估。值得注意的是,CoCoNut使用了集成学习策略,我们按照原始文章中的描述训练了100个模型中的前10名。
4.4 推理
多样性。在多样性评价过程中,我们将束大小设置为150,候选数目设置为100,也就是说,对于每个样本,NPR模型将产生100个补丁。具体来说,CoCoNut,因为它的优势是集成学习,我们要求CoCoNut为每个模型产生100个补丁,选择10个模型来产生1000个补丁。
行为。在行为的评估过程中,我们将束大小设置为150,候选数设置为1,也就是说,对于每个样本,NPR模型只会生成一个补丁。具体地说,CoCoNut是由10个模型组成的集合,因此我们分别评估每个模型并对结果进行平均。
4.5 研究问题
在本文中,我们提出了以下研究问题:
- RQ1. NPR模型是否存在稳健性问题?
- RQ2. NPR模型的稳健性是否与AST信息的使用有关?
- RQ3. NPR模型的稳健性是否与模型设置有关?
- RQ4. NPR模型的稳健性是否与突变位置有关?
5 实验结果
表3和表4显示了多样性和行为的结果。如两个表所示,我们提出了以下四个指标:
-
- 失败突变百分比(PFM):表示通过对原始成功修复的样本进行突变而产生的所有突变中修复失败的百分比。PFM=NFM / NAM,其中NFM是无法修复的突变体的数量,NAM是所有突变体的数量。此度量用于多样性方法。
- 突变后失败百分比(PFA):表示成功修复的样本在突变后未能修复的百分比。对于可以修复成功的样本,如果它的突变体不能成功修复,则认为该样本修复失败。PFA = NFS / NAS,其中,NFS是突变失败的原始样本数,NAS是所有样本数。此度量用于多样性方法。
- 差异突变体百分比(PDM):表示存在突变体Mt的百分比,即NPR(M)和NPR(Mt)的语义不同。PDM = NDM / NAM,其中NDM是与修复的原始样本在语义上不相同的修复突变的数量,NAM是所有突变的数量。此度量用于行为方法。
- 突变后差异百分比(PDA):表示存在NPR(M) 和NPR(Mt) 语义不同的原始样本M的百分比。PDA = NDS / NAS,其中NDS是具有语义上相同的修复突变体的修复样本的数量,NAS是所有样本的数量。此度量用于行为方法。
上面的NPR(M) 表示方法M上的NPR模型的输出,Mt表示由突变体在原始方法M上产生的突变。四个度量的方向性是一致的。度量值越高,模型的稳健性越差。我们将从上述指标和其他分析中寻找RQ的答案。
5.1 RQ1:NPR模型是否存在鲁棒性问题?
如表3和表4所示,所有NPR模型都很容易受到语义相同的变异体的影响。
表3介绍了多样性实验的结果。在多样性实验中,SequenceR是最突出的模型。但即便如此,SequenceR的PFA超过20%,这意味着超过20%的可以修复的原始样本含有无法修复的突变。这也意味着,超过20%的SequenceR成功修复是不可靠的。CoCoNut受到的影响最大,在可以修复的样本中,超过35%的样本存在修复失败的突变。这表明NPR模型是脆弱的,在语义一致的突变下,NPR模型的修复能力受到严重挑战。
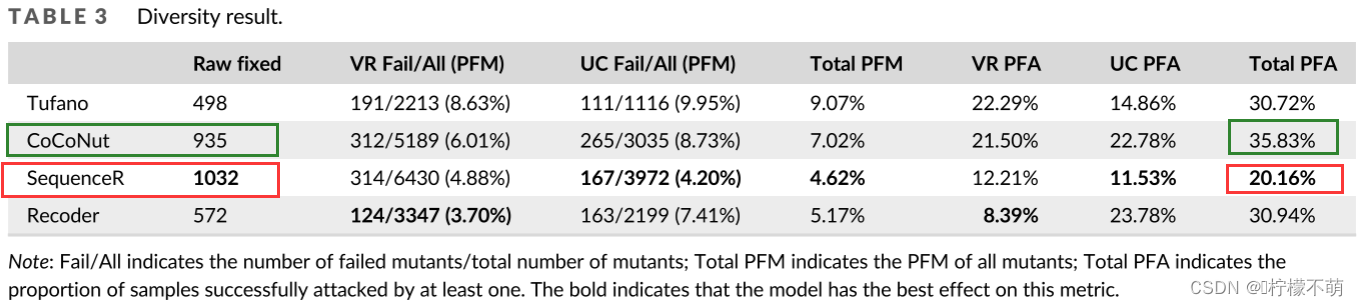
表4描述了行为实验的结果。在行为实验中,总体来说,各模型之间的性能差距较大,其中SequenceR的性能相对最好。然而,SequenceR的PDA仍接近30%。最差的模型是Tufano,它的PDA为48.40%,换句话说,Tufano近一半的输出是不可靠的。这表明,NPR对程序的语义理解和语义转换是脆弱的。在语义完全相同的突变下,NPR模型的语义理解能力受到严重挑战。
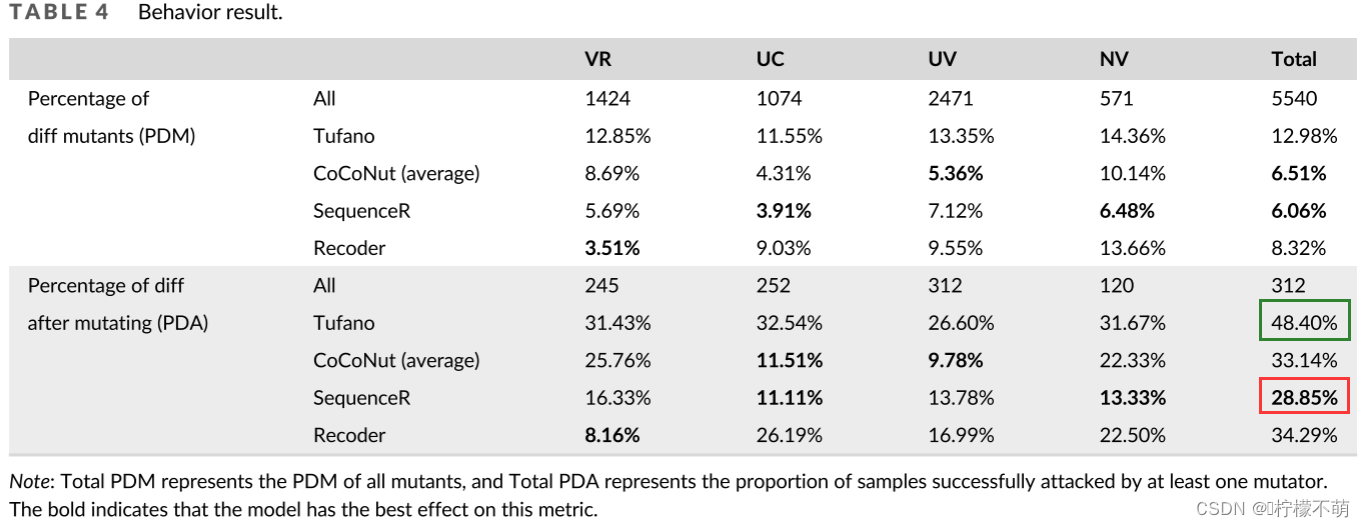
发现1. NPR模型存在鲁棒性问题。语义相同的变异体会影响NPR模型的性能(所有模型的PFA和PDA都超过20%和28%)。
此外,从表1中我们发现,Tufano修复最少的Defects4J缺陷,从某种意义上说,Tufano在四个模型中修复能力最差。同时,在四个模型中,Tufano的PFM、PDM和PDA最高,这意味着Tufano的鲁棒性比其他模型差。从这一结果来看,鲁棒性和修复能力之间似乎存在一定的相关性。然而,对于其他三个成功修复数量相似的模型,它们的鲁棒性并不相同。CoCoNut的PFA甚至高于Tufano,是4个模型中最差的。相比之下,SequenceR在所有四个指标中都是最好的,而且SequenceR与其他三种模型之间存在很大差距。具体原因将在后续研究问题中讨论。

发现2. NPR模型的鲁棒性与修复能力之间存在一定的相关性(修复能力最差的Tufano模型也是最不稳健的),但健壮性还受到其他因素的影响。(其他三个模型具有类似的修复能力,但在稳健性方面存在较大差距。例如,在PFA中,CoCoNut比SequenceR高75%)基于研究结果1和2,我们建议未来的研究者除了模型修复能力外,还应更加关注NPR模型的稳健性。
5.2 RQ2:NPR模型的鲁棒性是否与AST信息的使用有关?
AST以树的形式表示程序的语法结构,经常用于与代码相关的任务,因此我们有必要研究AST对NPR模型健壮性的影响。
在我们的四个模型中,只有Recoder是基于缺陷程序的AST信息的,所以我们通过分析Recoder来研究AST对模型稳健性的影响。从表3和表4可以看出,与其他模型相比,Recoder受VR的影响较小。在多样性实验中,PFM(3.70%)和PFA(8.39%)低于其他模型(最小分别为4.88%和12.21%)。在行为实验中,PDM (3.51%)和 PDA (8.16%)远低于其他模型(最低分别为5.69%和16.33%)。
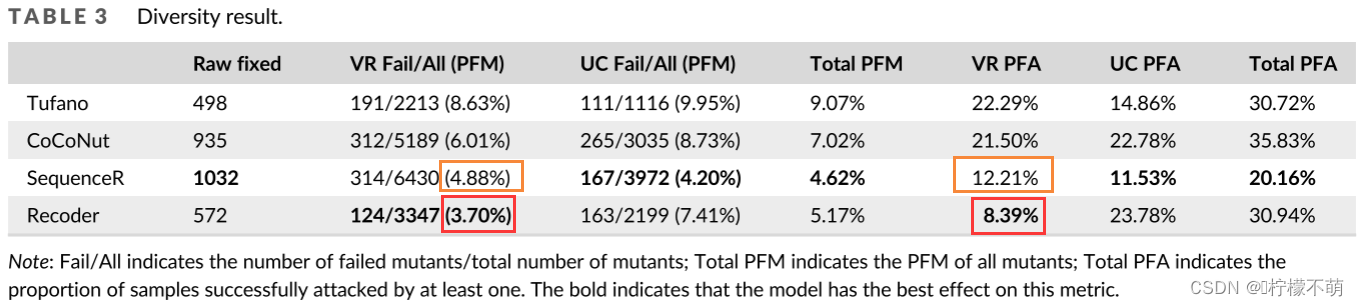
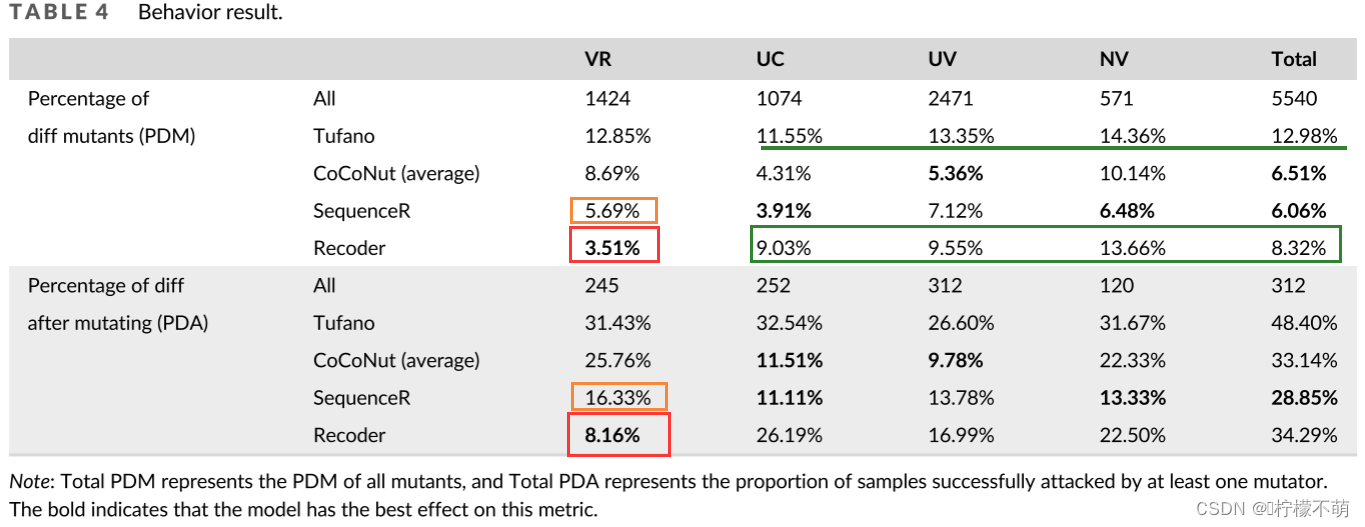
然而,在其他突变体的作用下,Recoder并没有显示出任何优势。在其他三个突变体中,除Tufano,Recoder是最不健壮的一个。
众所周知,Recoder是一种基于树和规则的NPR模型。在我们的几个变异器中,VR(变量重命名)只改变了AST终端节点的值,UC引入了新节点和新规则(强制类型转换),UV(未使用的变量)引入了新的子树,NV (新变量)引入了新的子树并改变了一些终端节点的值。
值得一提的是,NV和UV对语法树结构的变化程度相同,但NV对Recoder的影响要比UV高得多。在UV突变条件下,Recoder的PDM和PDA分别为9.55%和16.99%。在NV突变条件下,Recoder的PDM为13.66%,PDA为22.50%。后者明显高于前者。我们认为这可能与输入样本有关。UV (未使用的变量) 突变体对样品本身的要求很低。我们所有的样品都可以被UV突变,而只有120个样品(约38%)可以被NV (新变量) 突变。这是因为NV需要在Sample方法中声明一个局部变量,并且存在对该变量的引用。许多方法都不符合条件。因此,可以用于NV的样本本身就更加复杂。如表5所示,我们做了一个统计,NV可以变异的样本在AST的代码行数和节点数上远远高于其他样本,NV之后的DIFF部分更高。

代码行数和节点数都能在一定程度上反映出AST的复杂性,因此我们认为当树变得更复杂时,基于树结构的Recoder的健壮性会变得更弱。
发现3.NPR模型的稳健性与AST的使用有关。对于依赖于AST的Recoder模型,突变体对AST进行的修改越多,对Recoder的健壮性的影响就越大。基于这一发现,我们建议未来的研究人员不应只使用AST的信息,而可能更好地结合序列信息使用AST。
5.3 RQ3:NPR模型的鲁棒性是否与模型设置有关?
5.3.1 指示缺陷行
在NPR研究中,确定缺陷行的位置是一种常见的做法。在我们的四个模型中,Tufano是唯一一款没有标明缺陷行的模型。其他三种模型都以不同的形式指示了缺陷行,限制了修复的范围。CoCoNut使用单个编码器对缺陷行进行编码,SequenceR使用特殊的token来指示缺陷行,Recoder将缺陷行的位置作为输入参数。
如表3和表4所示,Tufano的总体稳健性明显低于其他三个模型。在多样性实验中,Tufano的总PFM达到9.07%,而其他三种模式的PFM最高只有7.02%(CoCoNut)。在行为实验中,Tufano的PDM达到了12.98%,其他三种模型中最高的是8.32%(Recoder),这意味着Tufano的PDM比其他模型高出50%以上。这表明,指示缺陷行使模型能够更多地关注缺陷,这有利于模型的健壮性。
发现4.指示缺陷行的NPR模型比没有指示缺陷行的模型更健壮(没有指定缺陷行的Tufano模型比在PDM上的其他模型高出50%以上)。我们建议未来的研究人员设计带有指示错误线的模型。
5.3.2 数据处理
数据是深度学习的重要基石。在将数据输入模型之前,应根据具体需要对数据进行处理。因此,我们认为有必要研究数据处理对深度学习稳健性的影响。
Tufano在数据处理中使用了一种特殊的抽象机制,因此我们选择通过它来研究数据处理对健壮性的影响。Tufano保留公共变量和类名,并将不太常见的变量和类名抽象为VAR_X和TYPE_X(X是出现的顺序)。我们的VR和NV变异器将为原始变量生成一个新的变量名,这两个变量都有可能是抽象的或非抽象的。UV变异器将引入一个新的变量名称,该名称也可以是抽象的或非抽象的。
让我们以VR(变量重命名)为例来解释不同的情况如何影响抽象结果:情况1,原始变量名和新变量名都是抽象的,因此更改不会对抽象结果产生影响。第二种情况,如果原始变量名被抽象,而新的变量名没有被抽象,则原始变量声明和引用的标记将成为新的变量名,在原始变量之后排序的抽象变量从VAR_X变为VAR_X-1。例3,如果原始变量名未被抽象,而新变量名被抽象,则原始变量声明和引用的标记成为新变量名的抽象,在原始变量之后排序的抽象变量从VAR_X变为VAR_X+1。例4,既不抽象原始变量名,也不抽象新变量名,所以原始变量声明和引用的标记成为新变量名。
针对可能的不同情况,我们分析了它们对抽象结果的影响,并对测试结果进行了进一步的统计,如表6所示。在多样性实验中,在VR变异体下,能够影响后续变量提取结果的两种情况的PFM分别为10.34%和14.44%,比不变的7.45%的抽象结果分别高出38.79%和93.83%。在行为实验中,在VR突变体方面,能影响后续变量抽象结果的两种情况的PDM分别为14.24%和17.39%,比不影响后续抽象结果的12.01%分别高18.57%和44.80%。在UV突变器中,影响后续提取的案例的PDM值为16.97%,比不影响后续提取的案例(7.34%)高131.20个百分点。在NV变异体中,影响后续抽象结果的两种情况的概率密度分别为9.24%和21.90%。不影响后续摘要结果的两个案例的产品数据管理分别为5.12%和12.80%,分别高出80.47%和71.09%。这些结果表明,Tufano的稳健性在很大程度上受到抽象结果的影响,这表明Tufano的数据处理方法对模型的稳健性有有利的影响。
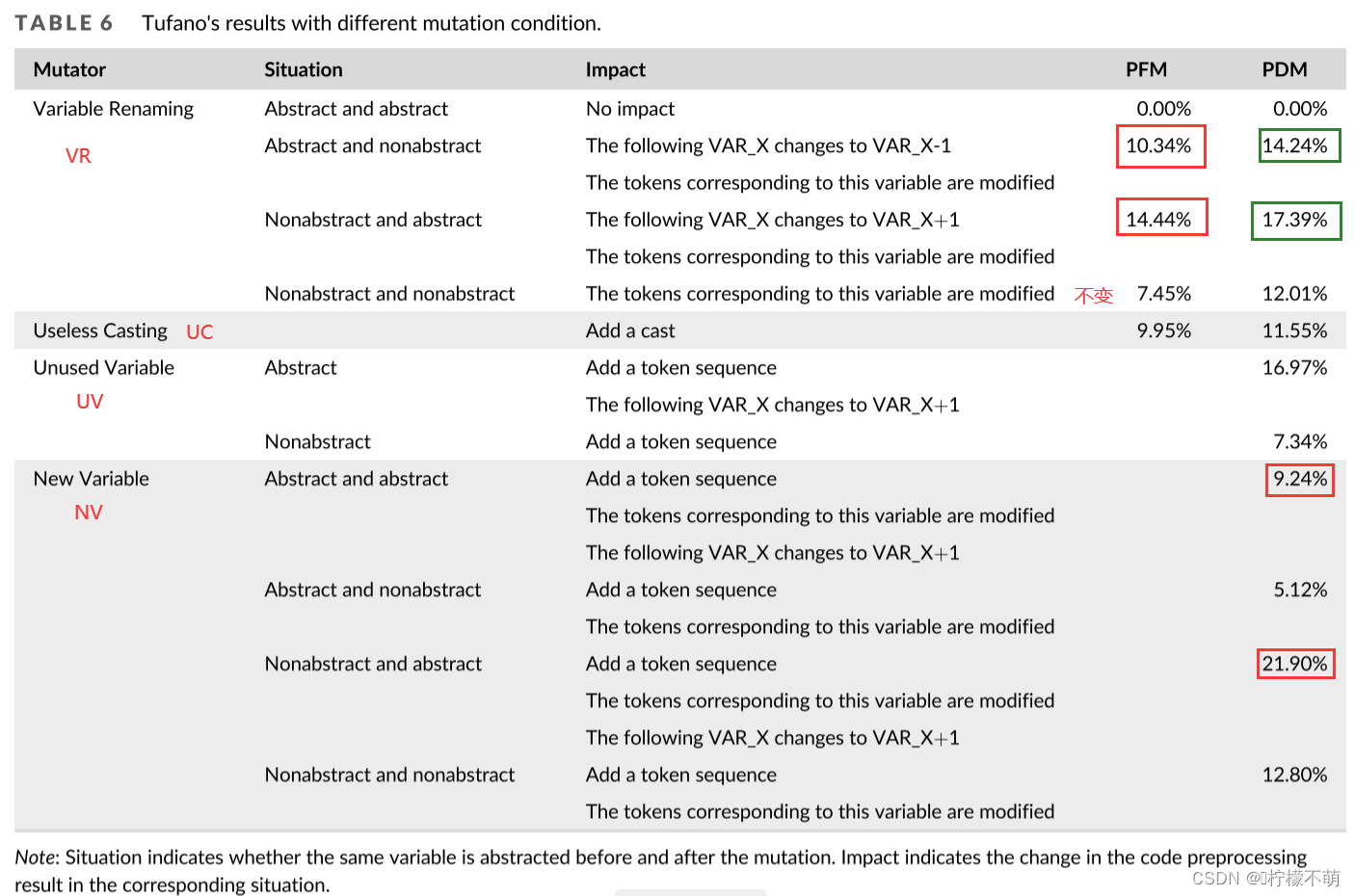
发现5.NPR模型的稳健性与其数据处理有关。在Tufano上的实验中,我们发现突变对Tufano算法稳健性的影响与对数据处理结果的影响呈正相关。基于这一发现,我们建议未来的研究人员应该使用更稳定的数据处理。
5.4 RQ4:NPR模型的鲁棒性是否与突变位置有关?
目前,大多数NPR工作都会提前定位缺陷,然后将缺陷部分和其他代码分别作为核心部分和上下文输入到模型中。因此,我们认为不同的突变位置对模型的稳健性有不同的影响。具体地说,它指的是突变是否修改了缺陷行对健壮性的影响。
在我们的四个NPR模型中,CoCoNut、SequenceR和Recoder将指示缺陷行,这意味着模型将更多地关注缺陷行。此外,对于像Tufano这样没有指示缺陷行的模型,我们相信它有能力找到缺陷行。因此,我们认为探讨突变缺陷行对NPR模型的稳健性的影响将是有趣的。
在我们的四个突变体中,UV(未使用的变量)不会修改缺陷行,所以我们只探索其他三个突变体的影响。如表7所示,在多样性实验中,我们计算了修改缺陷行和不修改缺陷行的PFM。在行为实验中,我们分别计算了修改缺陷行和不修改缺陷行的PDM。
正如我们所看到的,在多样性中,包括Tufano在内,缺陷行被修改的部分的PFM显著高于未被修改的部分。缺陷行的CoCoNut的PFM为23.72%,未修改的缺陷行的部分PFM仅为0.80%。前者是后者的29.65倍。这可能与CoCoNut使用单独的编码器对缺陷行进行编码有关。而对于Tufano,改性(11.67%)仅为未改性(7.54%)的1.54倍。
在行为实验中,在三种指示模型中,修改的缺陷行与没有修改的缺陷行之间的PDM最低比率为3.18(Recoder)。Tufano不是一个指示性的模型,它的比率只有1.57。这表明修改缺陷行变异器对指示模型的稳健性有显著影响。总之,修改缺陷行的变异器对所有四个NPR模型的稳健性有更大的影响。特别是,指示缺陷的模型的影响显著大于没有指示缺陷行的模型。
发现6.修改缺陷行对NPR模型的稳健性有显著影响(对于CoCoNut的PFM,修改缺陷行是未修改缺陷行的29.65倍)。基于这一发现,我们建议未来的研究人员在设计模型时更多地关注缺陷行信息的提取。
6 有效性威胁
6.1 内部有效性威胁
威胁1.我们承认行为实验(第3.4.2节)不完整,被判定为语义相同的情况可能是假阳性(预测有缺陷,实际上无缺陷)。我们随机抽取1000例阳性病例进行手工分析。经过人工分析,发现其中74例为假阳性,这给出了1000例阳性案例中92.6%的真阳性,说明行为实验是有效的。
威胁2.我们在实施评估工具时可能存在一些错误。为了确保代码的可靠性,两位作者审阅了代码并手动检查了变异体。此外,我们还公开了我们的评估工具的源代码,以供其他研究人员验证。
威胁3.由于超参数的选择,我们实现的模型可能与原始模型不同。为了缓解这一威胁,我们首先使用原始论文中建议的超参数(如果提供)来训练模型。然后,我们对每个可调超参数进行随机搜索,在验证集上选择最好的模型,作为最终的模型进行评估。如表1所示,我们训练的模型达到了与原始论文中的模型相同甚至更好的效果。
6.2 外部有效性威胁
威胁4.我们在行为实验中使用了广泛使用的基准测试工具Defects4J。然而,由于Defects4J提供的缺陷数量较多,我们只能使用有限数量的样本进行评估。为了缓解这一威胁,我们引入了一个没有测试用例的数据集,它有4195个样本。多样性-数据非常多样化,这在很大程度上可以弥补Defects4J的不足。
7 相关工作
7.1 APR的实证研究
随着APR的快速发展,许多研究者在这一领域进行了实证研究。Le Goues等人将重点放在GenProg的能力和成本上。Qi等,Wang等,Le等主要研究了补丁生成中的过拟合问题。刘等人探索了缺陷定位对APR系统的影响。Durieux等人在五个基准上对11个APR工具的可维修性进行了大规模比较。随着深度学习的快速发展,NPR已成为APR领域一个很有前途的研究方向。与此同时,为了加快NPR的发展,各种实证研究也相继展开。Tufano等人研究了使用NMT架构对APR的影响。Ding等人探讨了上下文长度和标记化等因素对NPR的影响。Namavar等人进行了一项关于不同代码表征对NPR的影响的实证研究。我们与这些研究的不同之处在于,我们专注于NPR稳健性的实证研究。
7.2 神经程序模型的鲁棒性(NPMs)
随着神经网络的不断发展和开源社区大型知识库的积累,使用深度学习模型进行程序分析已经成为一种新的趋势,称为NPM。NPR也是NPM的一种。与其他神经模型一样,NPM也存在稳健性问题,一些研究人员已经对此进行了研究。Pour等人为代码嵌入模型生成了对抗性样本,对模型进行了评估,并对模型进行了再训练,以提高模型的健壮性。Applis等人设计了两个变异关系来评估CodeBert在代码摘要任务中的健壮性。康普顿等人研究了混淆变量名称编码的效果。然后,他们通过在扩充的数据集上重新训练模型来训练更健壮的模型。Rabin等人使用语义保持变换来研究NPM的泛化能力;所选的下游任务是方法名称预测。周等人重点研究了代码注释生成任务的健壮性,提出了一种生成恶意代码片段的标识符替换方法。Zeng等人对代码预训练模型在包括NPR在内的多个下游任务上的稳健性进行了大规模研究。Zeng等人用于评估NPR的指标是BLEU、ACC和CodeBLEU。然而,评估NPR模型的主要方法是使用带有可执行测试的基准测试,这在他们的工作中没有使用。为了全面评估NPR的健壮性,我们设计了基于基准测试的行为方法,并进行了可执行测试。
8 结论
本文对Tufano、SequenceR、Coconut和Recoder四种Sota NPR模型进行了大规模的健壮性评估。我们设计了四个语义相同的变异器来对程序进行变异。特别是,我们期望NPR模型是健壮的,即在语义相同的恶意输入下,具有保持输出语义一致的能力。
我们的工作为评估NPR模型的稳健性提供了一种有效的方法和度量。结果发现,我们设计的变异器往往破坏了模型的稳健性和修复能力。这表明NPR模型存在严重的稳健性问题,这将严重阻碍NPR工具的应用。此外,我们的结果表明,NPR模型的稳健性与模型的设置和突变位置有关。我们发现不同的设计会在不同的水平上影响NPR模型的稳健性,并解释了它们是如何影响稳健性的。我们相信,未来的研究者在设计NPR工具时可以从我们的工作中得到启发,从而提高他们的NPR工具的健壮性,使NPR工具更好地应用。















 648
648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









