







上一章节已经采集完人脸图片,这个章节我们将图片文件转化成数据化
我们将人脸图片训练成人脸数据模型,然后将模型用于人脸识别。我们先来说说图像和像素
图像和像素:每一个小方格就是一个像素。通过将它们并排放置,我们可以形成完整的图像。单个像素被认为是图像中最少可能的信息。对于每张图像,像素值的范围在 0 到 255 之间。
我们本次用 LBPH(Local Binary Pattern Histogram)进行人脸识别; 对每一个像素进行信息提取, 并将其与模型中的对应单元进行比较, 对每个区域的匹配值产生一个直方图。 由于这种方法的灵活性, LBPH是唯一允许模型样本人脸和检测到的人脸在形状、 大小上可以不同的人脸识别算法。
#用于存储提取到的人脸数据
facesSamples = []
#存储学生学号
ids = []
path = 'person/'
imagePaths = [os.path.join(path, f) for f in os.listdir(path)]
#判断是否有人脸图片防止下面保存
if(len(imagePaths)==0):
print("未检出人脸信息,请先采集人脸")
return
# 检测人脸
face_detector = cv2.CascadeClassifier(
'./data1/lbpcascade_frontalface_improved.xml')
# 遍历列表中的图片
for imagePath in imagePaths:
# 打开图片,黑白化
PIL_img = Image.open(imagePath).convert('L')
# 将图像转换为数组,以黑白深浅
# PIL_img = cv2.resize(PIL_img, dsize=(400, 400))
img_numpy = np.array(PIL_img, 'uint8')
# 获取图片人脸特征
faces = face_detector.detectMultiScale(img_numpy)
# 获取每张图片名字(学生学号)
id = int(imagePath.split('/')[-1].split('.')[0])
# 预防无面容照片
#x,y,w,h(代表检测到的人脸位置信息)
for x, y, w, h in faces:
ids.append(id)
#提取提取图片中人脸数据
facesSamples.append(img_numpy[y:y + h, x:x + w])
recognizer = cv2.face.LBPHFaceRecognizer_create()
# train函数有两个参数,第一个是人脸数据,里面存储多张学生人脸数据,
#每一个学生人脸数据都是数组类型,第二个参数是与第一个参数对应的学生学号,必须
#要对应,否则会识别出错,装学生学号的列表需要转为数组类型
recognizer.train(facesSamples, np.array(ids))
# 保存文件
recognizer.write('./trainer/trainer.yml')训练好的人脸数据模型是一个yml文件:
我们看看提取到的人脸数据信息如下:
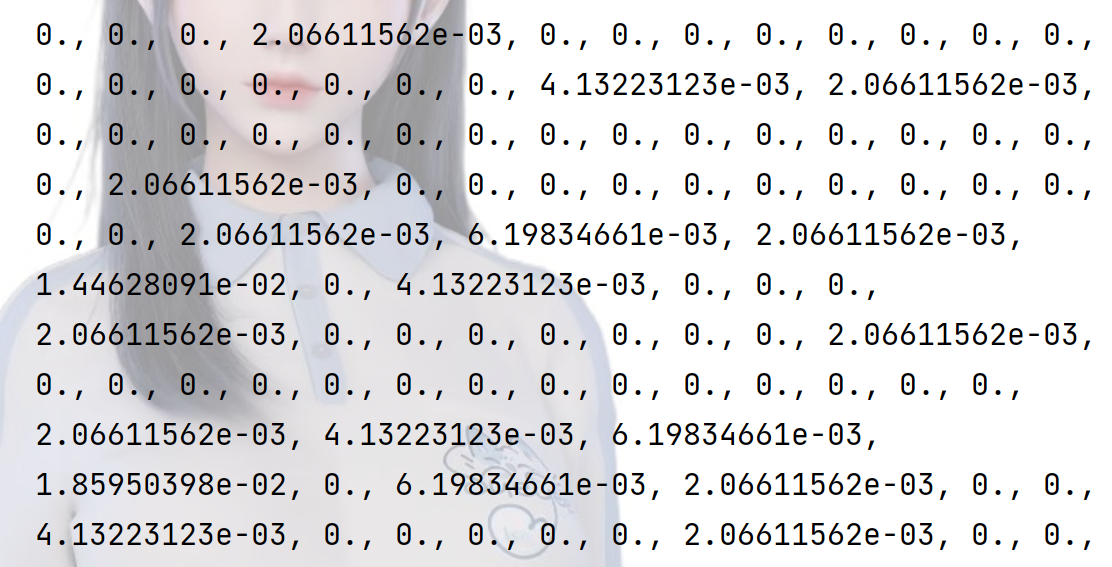
人脸数据非常多我只是截取了一部分图片
对应人脸的学号:

接下来我分享一下我编写的一个opencv人脸识别案例:地址YueXia/Face-opencv - 码云 - 开源中国 (gitee.com)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









