







HW3-CNN
- Base Task
通过训练集的食物图片训练卷积神经网络,其中食物类别共有
11种,实现预测测试集食物图片的种类。
扩展:
- 利用
Transforms库中的函数实现Data Augmentation,将一张照片变换出五张不同的照片。

- 修改
CNN结构实现Residual Network。
1.作业代码
1.1 Base Code
思考:如果是模型是做
图像分类用途的话,CNN后面一般要跟一个全连接层,将其转化为预测的类别。最后预测出来的是以一个 n ∗ 11 n * 11 n∗11的矩阵,坐标 ( i , j ) (i,j) (i,j)的数表示图片 i i i是类别 j j j的概率,我们取概率最大的类别作为图片 i i i的类别。
(建议自己练习的时候也在Kaggle上,便于Data I/O)
# -*- coding: utf-8 -*-
#3.CNN
"""## Modify Task:
> 1. Augmentation Implementation:由原始数据通过简单变换处理出更多数据(翻转、变色、旋转等)
> 2. Residual Connection:Only modify the `forward` part of the model
## Import relative package
* torch:向量运算等
* numpy:线性运算等
* os:文件操作等
* pandas:数据处理、CSV文件I/O
* PIL:Image处理
* torchvision.transforms:Image文件变换处理
* torch.utils.data、torch.utils.data:数据集处理
* tqdm.auto:进度条可视化
* torch.nn、random
"""
import torch
import numpy as np
import os
import pandas
from PIL import Image
import torchvision.transforms as transforms
import torch.nn as nn
# "ConcatDataset" and "Subset" are possibly useful when doing semi-supervised(半监督) learning.
from torch.utils.data import ConcatDataset, DataLoader, Subset, Dataset
from torchvision.datasets import DatasetFolder, VisionDataset
from tqdm.auto import tqdm
import random
"""Set the seed"""
myseed = 6666
'''
torch.backends.cudnn.benchmark = True
可以让内置的cudnn的auto-tuner自动寻找适配的高效算法来优化效率。
但输入数据每次iteration都变化会导致cudnnmei每次都寻找最优配置,反而降低效率
'''
torch.backends.cudnn.benchmark = False
'''
torch.backends.cudnn.deterministic = True
使得每次返回的卷积算法将是确定的.
如果配合上设置 Torch 的随机种子为固定值的话,应该可以保证每次运行网络的时候相同输入的输出是固定的。
'''
torch.backends.cudnn.deterministic = True
np.random.seed(myseed) # 为random模块的随机数种子。
torch.manual_seed(myseed) # 为CPU的torch模块设置随机数种子
if torch.cuda.is_available():
torch.cuda.manual_seed_all(myseed) # 为所有的PU的torch模块设置随机数种子
"""## Transforms
Torchvision提供各种函数来处理image图片来实现“Data augmentation”
"""
# 将图片大小固定为128 * 128并转化为tensor
test_tfm = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
])
train_tfm = transforms.Compose([
transforms.Resize((128, 128)),
#Task 1:将每张训练图片进行Data Augmentation为五种图片
transforms.ToTensor(),
])
"""## Create DataClass"""
class FoodDataSet(Dataset):
def __init__(self, path, tfm = test_tfm, files = None):
'''super是否有必要'''
super(FoodDataSet).__init__()
self.path = path
self.files = sorted([os.path.join(path, x) for x in os.listdir(path) if x.endswith(".jpg")])
if files is not None:
self.files = files
print(f"{path}\n Sample{self.files[0]}")
self.transforms = tfm
def __len__(self):
return len(self.files)
'''如果transform中实现了五种图片的转换,__getitem__()要做怎样的改变'''
def __getitem__(self, idx):
fname = self.files[idx]
im = Image.open(fname)
im = self.transforms(im)
try:
label = int(fname.split("/")[-1].split("_")[0])
except:
label = -1
return im, label
"""Construct Dataset"""
batch_size = 64
_dataset_dir = "../input/ml2022spring-hw3b/food11"
# num_worker:告诉DataLoader实例要使用多少个子进程进行数据加载(和CPU有关,和GPU无关)
train_set = FoodDataSet(os.path.join(_dataset_dir, "training"), tfm=train_tfm)
train_loader = DataLoader(train_set, batch_size = batch_size, shuffle = True, num_workers = 0, pin_memory = True)
print(len(train_set))
valida_set = FoodDataSet(os.path.join(_dataset_dir, "validation"), tfm=test_tfm)
valida_loader = DataLoader(valida_set, batch_size = batch_size, shuffle =False, num_workers = 0, pin_memory = True)
print(len(valida_set))
test_set = FoodDataSet(os.path.join(_dataset_dir, "test"), tfm=test_tfm)
test_loader = DataLoader(test_set, batch_size = batch_size, shuffle = False, num_workers = 0, pin_memory = True)
print(len(test_set))
"""## Creat Model"""
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
# torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
# torch.nn.MaxPool2d(kernel_size, stride, padding)
# input 維度 [3, 128, 128] (channel, H, W)
self.cnn = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1), # [64, 128, 128]
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [64, 64, 64]
nn.Conv2d(64, 128, 3, 1, 1), # [128, 64, 64]
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [128, 32, 32]
nn.Conv2d(128, 256, 3, 1, 1), # [256, 32, 32]
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [256, 16, 16]
nn.Conv2d(256, 512, 3, 1, 1), # [512, 16, 16]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 8, 8]
nn.Conv2d(512, 512, 3, 1, 1), # [512, 8, 8]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 4, 4]
)
#卷积神经网络后加入一个全连接层是为了“分类”,数据集的类别个数为11.
self.fc = nn.Sequential(
nn.Linear(512 * 4 * 4, 1024),
nn.ReLU(),
nn.Linear(1024, 512),
nn.ReLU(),
nn.Linear(512, 11),
)
def forward(self, x):
# print(f"before pass the cnn shape:{x.shape}") torch.Size([64, 3, 128, 128])
x = self.cnn(x)
# print(f"after pass the cnn shape:{x.shape}") torch.Size([64, 512, 4, 4])
x = x.view(x.size()[0], -1) # 将x的形状由重新定义为 torch.Size([64, 512*4*4=8192])
return self.fc(x)
"""## Training"""
device = "cuda" if torch.cuda.is_available() else "cpu"
n_epochs = 4
patience = 300
best_acc, cnt = 0, 0
#模型
model = Classifier().to(device)
# 损失函数
criterion = nn.CrossEntropyLoss()
# 优化器
# weiht_decay:权重腐蚀,一般设为较小正数。它是一种正则化项,用于减少模型的过拟合风险。权重衰减会惩罚模型中较大的权重值,以鼓励模型学习简单的权重。
optimizer = torch.optim.Adam(model.parameters(), lr=0.0003, weight_decay = 1e-5)
for epoch in range(n_epochs):
# -----------training------------------
model.train()
train_loss, train_acc = [], []
for data in tqdm(train_loader):
imgs, labels = data
# 确保模型、数据在相同处理器上
pred = model(imgs.to(device)) # 64 * 11
loss = criterion(pred, labels.to(device))
optimizer.zero_grad()
loss.backward()
'''
网络参数量增多的时候,反向传播过程中链式法则里的梯度连乘项数便会增多,更易引起梯度消失和梯度爆炸。
对于梯度爆炸问题,解决方法之一便是进行梯度剪裁,即设置一个梯度大小的上限。
'''
# Clip the gradient norms for stable training.
grad_norm = nn.utils.clip_grad_norm_(model.parameters(), max_norm=10)
optimizer.step()
# 计算准确率
acc = (pred.argmax(dim=1) == labels.to(device)).float().mean()
train_loss.append(loss)
train_acc.append(acc)
train_loss = sum(train_loss) / len(train_loss)
train_acc= sum(train_acc) / len(train_acc)
print(f"[ Train | {epoch + 1:03d}/{n_epochs:03d} ] loss = {train_loss:.5f}, acc = {train_acc:.5f}")
# -----------validation------------------
model.eval()
valid_loss, valid_acc = [], []
for data in tqdm(valida_loader):
imgs, labels = data
imgs, labels = imgs.to(device), labels.to(device)
with torch.no_grad():
pred = model(imgs)
loss = criterion(pred, labels)
acc = (pred.argmax(dim=1) == labels).float().mean()
valid_loss.append(loss)
valid_acc.append(acc)
valid_loss = sum(valid_loss) / len(valid_loss)
valid_acc= sum(valid_acc) / len(valid_acc)
print(f"[ Valid | {epoch + 1:03d}/{n_epochs:03d} ] loss = {valid_loss:.5f}, acc = {valid_acc:.5f}")
# 若验证集的精确度有所提升则保存新模型
if valid_acc > best_acc:
best_acc = valid_acc
stale = 0
print(f"Best model be found at epoch{epoch}, saved the model")
# only save the best model to prevent output memory
torch.save(model.state_dict(), "simple_vision_best.ckpt")
else:
stale += 1
if stale > patience:
print(f"No improvment {patience} consecutive epochs, early stopping")
break
"""## Testing"""
model_best = Classifier().to(device)
model_best.load_state_dict(torch.load("simple_vision_best.ckpt"))
# Testing
model_best.eval()
predic = []
with torch.no_grad():
for ims, _ in test_loader:
pred = model_best(ims.to(device))
test_label = np.argmax(pred.cpu().data.numpy(), axis = 1)
# print(type(test_label))
# print(test_label.squeeze().tolist())
predic += test_label.squeeze().tolist()
#create test csv
def pad4(i):
return "0"*(4-len(str(i)))+str(i)
df = pd.DataFrame()
df["Id"] = [pad4(i) for i in range(1,len(test_set)+1)]
df["Category"] = predic
df.to_csv("submission.csv",index = False)
训练结果:
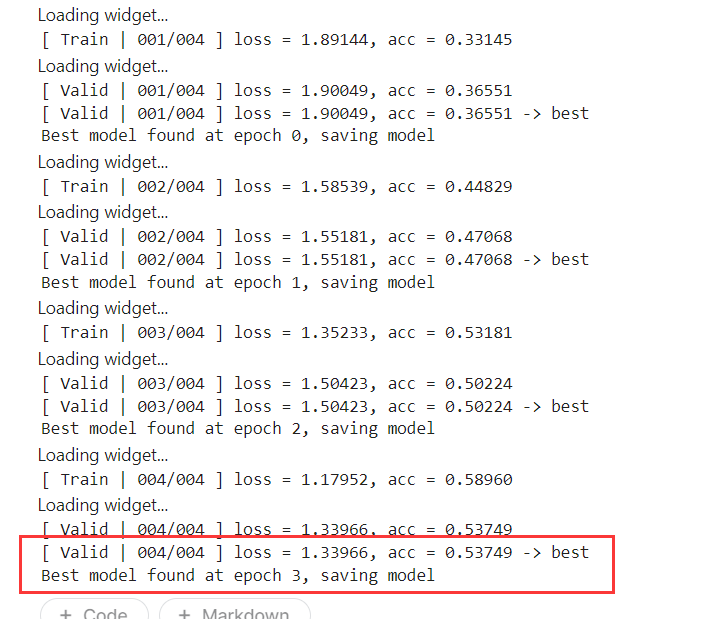
1.2 Data Augmentation
改进地方为:
- 使用
transforms.Compose创建多个数据增强变换组合,并将这些组合传递给自定义的FiveAugmentations类。- 在训练循环中,处理返回的增强图像列表,将其展平为单个批次,并相应地重复标签。
# 将图片大小固定为128 * 128并转化为tensor
test_tfm = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
])
'''Base Code
train_tfm = transforms.Compose([
transforms.Resize((128, 128)),
#Task 1:将每张训练图片进行Data Augmentation为五种图片
transforms.ToTensor(),
])
'''
# ===================================NEW===================================
# Custom transform to generate 5 augmented images
class FiveAugmentations:
def __init__(self, tfms):
self.tfms = tfms
def __call__(self, img):
return [tfm(img) for tfm in self.tfms]
# Define a list of transformations
augmentations = [
transforms.Compose([
transforms.RandomResizedCrop(128),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15),
transforms.ToTensor(),
]),
transforms.Compose([
transforms.RandomResizedCrop(128),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2),
transforms.ToTensor(),
]),
transforms.Compose([
transforms.RandomResizedCrop(128),
transforms.RandomGrayscale(p=0.2),
transforms.ToTensor(),
]),
transforms.Compose([
transforms.RandomResizedCrop(128),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
]),
transforms.Compose([
transforms.RandomResizedCrop(128),
transforms.RandomRotation(45),
transforms.ToTensor(),
]),
]
# Apply the FiveAugmentations transformation
train_tfm = FiveAugmentations(augmentations)
# ===================================NEW===================================
for epoch in range(n_epochs):
# -----------training------------------
model.train()
train_loss, train_acc = [], []
for data in tqdm(train_loader):
imgs, labels = data
# ===================================NEW===================================
imgs = torch.cat(imgs, dim=0)
labels = torch.cat([labels] * 5, dim=0)
# ===================================NEW===================================
# 确保模型、数据在相同处理器上
pred = model(imgs.to(device)) # 64 * 11
loss = criterion(pred, labels.to(device))
optimizer.zero_grad()
loss.backward()
'''
网络参数量增多的时候,反向传播过程中链式法则里的梯度连乘项数便会增多,更易引起梯度消失和梯度爆炸。
对于梯度爆炸问题,解决方法之一便是进行梯度剪裁,即设置一个梯度大小的上限。
'''
# Clip the gradient norms for stable training.
grad_norm = nn.utils.clip_grad_norm_(model.parameters(), max_norm=10)
optimizer.step()
# 计算准确率
acc = (pred.argmax(dim=1) == labels.to(device)).float().mean()
train_loss.append(loss)
train_acc.append(acc)
train_loss = sum(train_loss) / len(train_loss)
train_acc= sum(train_acc) / len(train_acc)
print(f"[ Train | {epoch + 1:03d}/{n_epochs:03d} ] loss = {train_loss:.5f}, acc = {train_acc:.5f}")
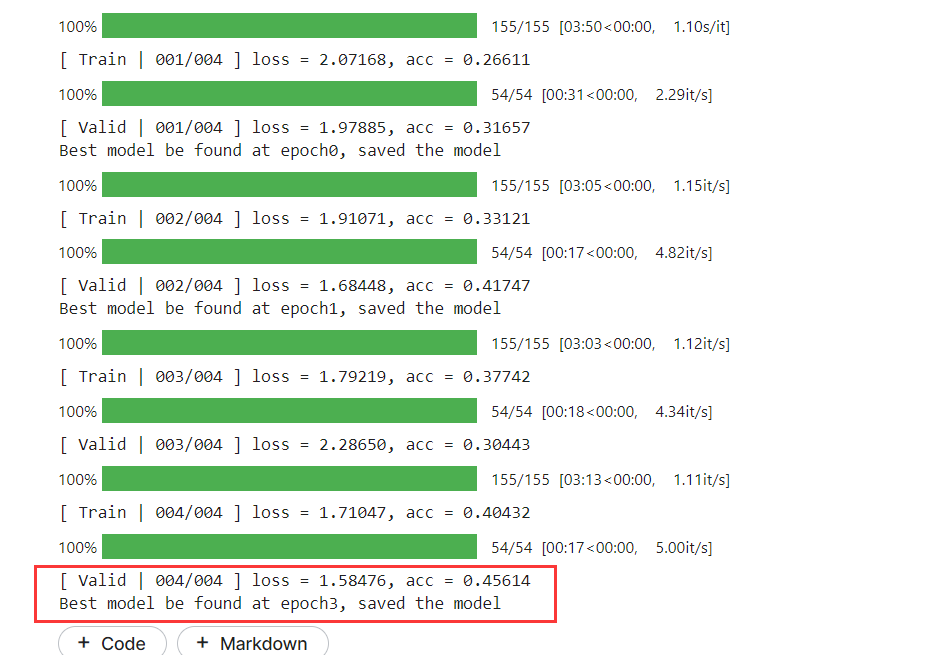
训练结果:
返现实现了
Data Augmentation之后效果反而不好,可能是图片处理的方式不合适。
也或者是在将每张图片处理出五张不同的图片之后,神经网络层数不够深,参数不够多导致学习不充分,无法学习全部特征,导致在验证集的效果下降。
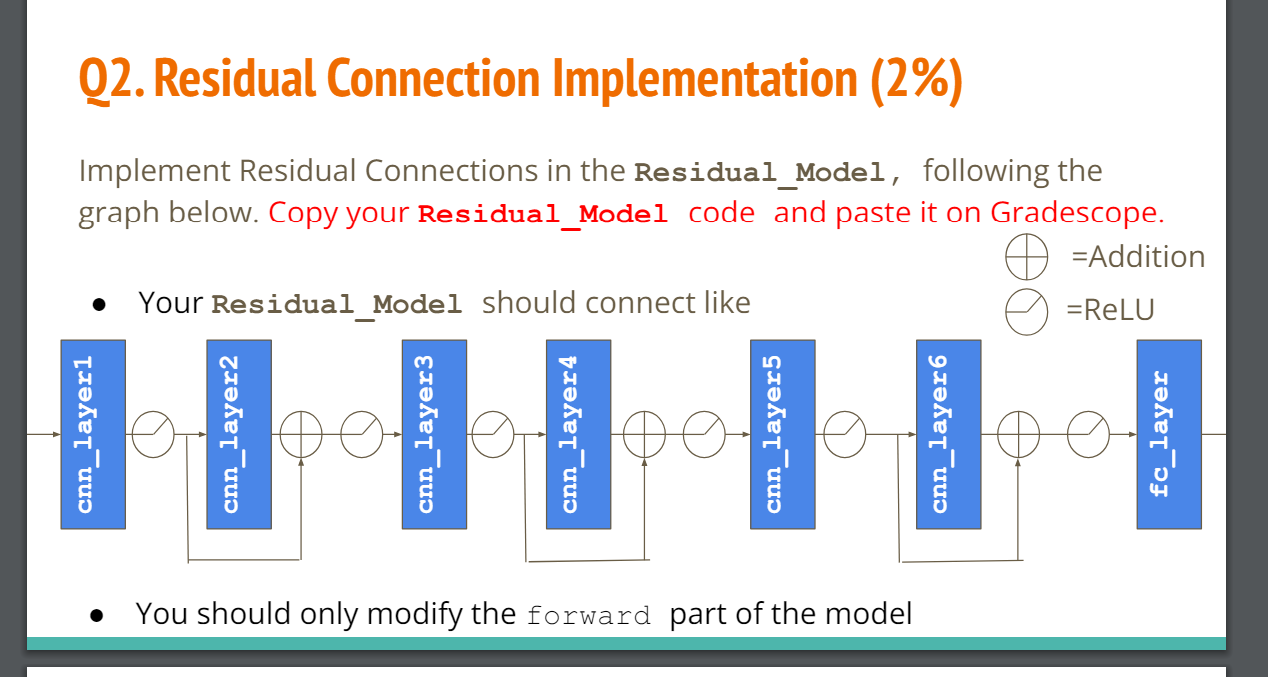
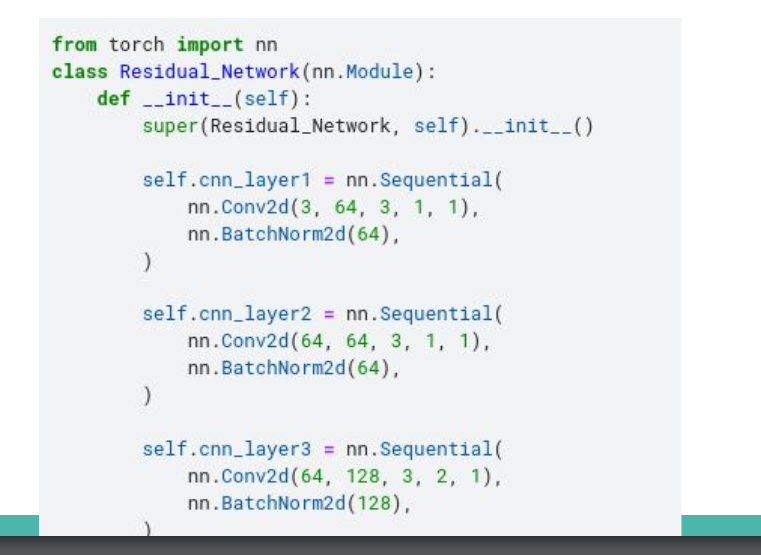
1.3 Residual Network
请参考
Homework Link中的部分参考代码&残差网络结构图,自行构造Residual_Network。(摆了)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









